#linear-algebra
2 messages · Page 13 of 1
yeah 'propre' just means eigen stuff
🥖
yeah fortunately a lot of maths words in french are quite similar too
🥖
🥖


💩 @gray glen

damn nitro
Hi, I was watching this video https://youtu.be/LyGKycYT2v0. At around 7:38 seconds, he starts to talk about how a vector can also be thought of as a 1 by 2 matrix. I don’t understand why this is the case and how it actually relates to the dot product.
write a vector as $$\begin{pmatrix} a \ b \end{pmatrix}$$
Sascha Baer:
flip it 90 degrees
there’s your 1x2 matrix
now calculate both $$\begin{pmatrix} a \ b \end{pmatrix} \cdot \begin{pmatrix} c \ d \end{pmatrix}$$ and $$\begin{pmatrix} a & b \end{pmatrix} \begin{pmatrix} c \ d \end{pmatrix}$$
Sascha Baer:
and note how they simply give you the same number back
and that’s all there is to it
(well, except for the whole dual space thing but I’m not gonna explain that here)
Well I get that they give the same answer but I’m wondering why it’s like that which I guess is the dual space thing.
well, when you carry out the computation of the dot product, you can recognize that you’re doing nothing else than that matrix-vector multiplication in the second row
and thus you can associate taking the dot product with (a,b) (as a column vector) as applying the linear map given by the matrix [a,b] (as a row matrix)
the dual space of ℝ² (which can be seen as 2×1 matrices) is just the 1×2 matrices
Ok, one more question. Why is it more useful for the dot product to be projection*length of a vector rather then just being projection?
Ooh, was that you?
well I certainly have tried to give an answer to exactly that question about half a day ago
or so
or maybe it was yesterday actually idr
as I said there, the only reason is becasue you can do the exact same things as with your idea, except that you have way nicer properties for calculating with it
so why would you ever choose the one that has ugly properties (like not being symmetric)
also, even more pragmatically: the standard dot product is super easy to calculate. just multiply the components and add them up
measuring the length of the projected vector is harder to compute
you essentially have to calculate the standard dot prodct and then divide by the length of the vector you project onto
which will involve square roots n stuff
so basically you’re giving up both nice computational properties (symmetry, bilinearity) and easy computation… for what?
what do you hope to gain?
also, one thing that I’m not sure you misunderstood or are just communicating badly: the dot product of two vectors is a number, not a vector
I’m not pushing for all mathematicians to change what the dot product represents, I’m just asking so I can understand it better which I think I do now. Just to clarify, we happened to define the dot product as projection* direction which happened to be calculated by taking a one dimensional array of the vector and multiplying it with another? Also, is the idea of a vector also being a transformation just the idea of all 2d vectors also being able to represent two 1d vectors some 1d line? And those two vectors also represent the dot product when used to transform another vector?
<@&286206848099549185>
is a symmetric matrix one thats equal to its trnaspose? arent these all equal to their transposes?
Check the signs in B
a space of eigenvectors
does your linear algebra book not have definitions
for an operator A and an eigenvalue λ of A, the eigenspace of A corresponding to λ is the set of all vectors v such that Av = λv
it would do you good to check that this does indeed form a subspace of K^n
where n is the size of A
do not use technology
lol
ok so clearly 0 is an eigenvalue right off the bat
lemme see
gonna throw it into matlab rq to check

i think it has to be {}
alright
yeah
your eigenvalues are correct @robust swallow
now for each of those finding a basis for the eigenspace boils down to finding a basis for ker(A - λI)
@slow scroll [] works
oh ok
is that for λ=1
you should say which is which
yeah, because that isn't a basis for R^3
it has too few vectors
you'd need another eigenvector for λ=1 to get an eigenbasis
A isn't diagonalizable
an* eigenbasis
but yes
I got $(\text{Ran}, A^T)^\perp = \text{Ker}, A$ and $(\text{Ran} , A)^\perp = \text{Ker} A^T$. Is that correct?
kxrider:
g
ood?
Anyone help@with #6?
basis
i guess the simplest way would be to convert those conditions into equations in the coefficients
Hi could anyone explain me the proof for the formula of the magnitude of a vector?
What do you refer as "the formula for the magnitude of a vector"?
I’d e more interested to see the proof because it might as well be a definition
do you just mean like, for a vector (a,b) in a conventional vector space? because thats just the pythagorean theorem
yes
is that not a definition
yeah thats usually a definition
you can either see that as the definition of magnitude, or see the geometric intuition of length as the definition and then prove this formula from pythagoras
as like, a one-liner
my question is why do we use the Pythagorean theorem
if you wanna do it geometrically
yeah that's fine
then you first define length only for those vectors pointing along an axis
in which case it’ll just be the one nonzero component
and then for any other vector, it’ll be the sum of those
and you can apply pythagoras becasue the axes are at right angles
in which case it’ll just be the one nonzero component
(taken with its absolute value)
is that satisfactory?
yes thank you
just didn't quite the intuition behind it and I didn't want to just memorize the formula and go plugging in numbers because that's what the textbook said
however, bear in mind that when you procede further into linear algebra, there’ll be more general definitions for magnitudes (usually called norms) and this one’s just one possibility
the one that’s most intuitive to us
but not the only thing that makes sense
ah ok well I am only hs rn and the lin alg we do is pretty basic
this one’s called the euclidean norm or 2-norm, it’s the one that coincides with our “flat” geometry
we don't even do matrices lol
Where can I learn about Orthographic prjoections and stuff like that in euclidean spaces? I can't really imagine in, I've been reading through many sources, the drawings ive seen from my teacher were not helpful as well, are there any like a 3blue1brown animations vids out there?
@winter reef i read the book linear algebra and its application 5th edition and really explains it really well
thx I found it will read it, but why would you EVER use greek letters as scalaras and normal one for vectors smh
will have to rewrite
thx I found it will read it, but why would you EVER use greek letters as scalaras and normal one for vectors smh
visual differentiation
also they're called roman, not "normal"
nah, god himself descended from the heavens and decreed
"the true language of humanity is urban latin"
speaking of, ban the letter U
why
no
not ROMANL
yes
bad
what if you used numbers for scalars
@wintry steppe the book actually explains it real;ly well with the drawings, thank you so much
i got matrix AxX = B I need to find matrix X
did you try following the hint
yep. but I am not sure how it should look like
can you solve equations of the form Ax = b, where A is a matrix and b is a vector?
(and x is also a vector)
cause your thing here is just three of those, with each x being a column of X and each b a column of B
ahh sure ! haha easy! thx buddy
(make sure you understand why that’s the case)
A * [B, C] == [A*B, A*C] (matlab syntax)
Quick question, when we find the eigen values of a matrix lets say 2 x 2 shouldn't we get an eigen value of 0 everytime since the zero vector will always satisfy the solution?
Ax=\lambda * x
wait nvm
we specifically let det(A-\lambda * I)=0 so that we specify that x cannot be 0
Any1 help with 17?
I was watching this video:https://youtu.be/LyGKycYT2v0?list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab&t=152. At that part in the video, he explains why the order you do the dot product does not matter but I did not understand his explanation. Could someone please explain why order does not matter in a similair way to how he did it?
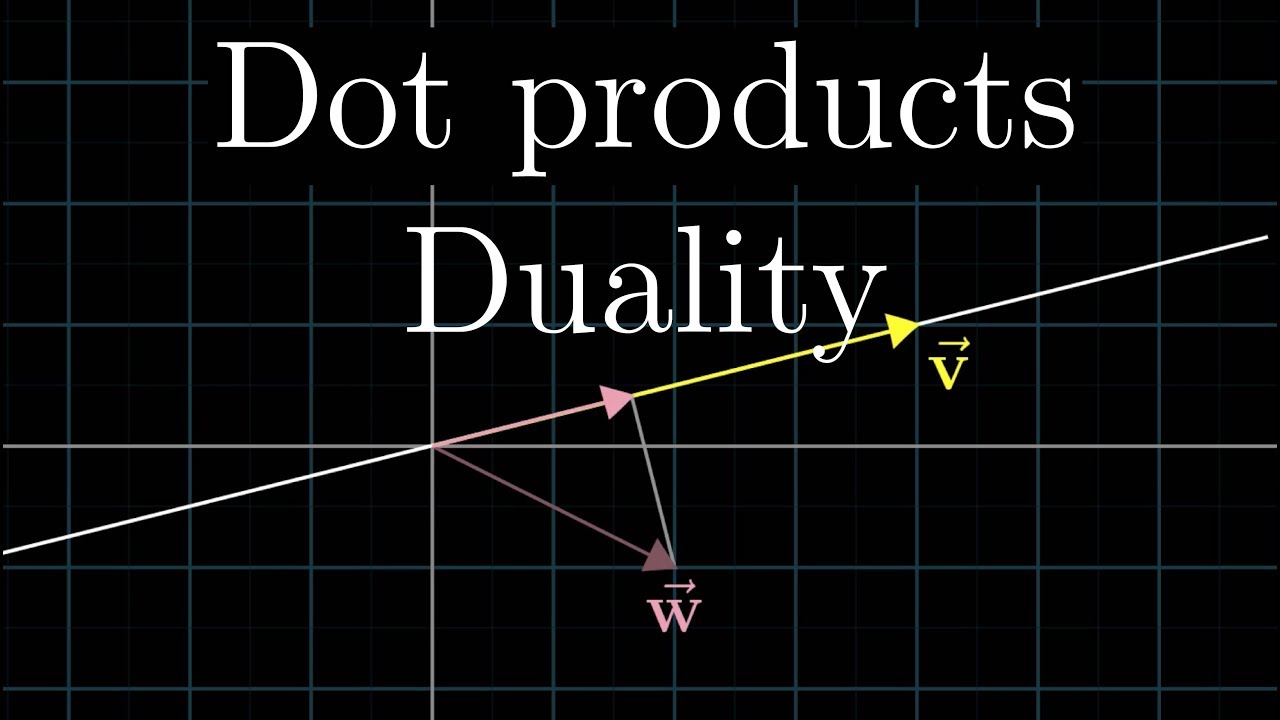
Home page: https://www.3blue1brown.com/ Dot products are a nice geometric tool for understanding projection. But now that we know about linear transformation...
well the dot product of (a,b,c)dot(x,y,z) = ax + by + cz
and (x,y,z)dot(a,b,c) = xa + yb + zc
oh hold on im watching the video
3b1b made the point that its clear that the dot product commutes for vectors of unit length, so if we start with two normalized vectors, $\hat u$ and $\hat v$, we can say that $\hat u \cdot \hat v = \hat v \cdot \hat u$. Multiply both sides by $\lvert u \rvert$. Now we have $\lvert u \rvert\hat u \cdot \hat v = \lvert u \rvert\hat v \cdot \hat u = u\cdot \hat v $. This is the projection of $u$ onto $v$. Now multiply both sides by $\lvert v \rvert$. Then you have $\lvert v \rvert u \cdot \hat v = \lvert u \rvert \lvert v \rvert \hat v \cdot \hat u = \lvert u \rvert (v \cdot \hat u). \ \$ Whether you choose to think of the dot product as a projection of $v$ onto $u$ or a projection of $u$ onto $v$, you have the scaling factor of the magnitude of the other vector that makes everything equal, i.e. $$\lvert v \rvert (u \cdot \hat v) = \lvert u \rvert (v \cdot \hat u)$$
kxrider:
@honest marlin
I'm confused on what you mean by its clear that the dot product commutes for vectors of unit length, so if we start with two normalized vectors and why multiplying one of the unit vectors by the magnitude of one of the vectors is still equal to the dot product.
3b1b made this argument for vectors of the "same length."
All unit vectors have length 1, and using unit vectors allows me to talk about things in terms of projections like 3b1b. All i did was manipulate the equation
u dot v = v dot u (with hats over the vectors)
So is u a different vector from u-hat in your explanation?
u hat is a vector that points in the same direction as u, but has a length of 1.
v dot u hat just means v projected onto u and
u dot v hat just means u projected onto v
maybe it would be easier to think of u hat and v hat as vectors with the same length, not necessarily 1, and |u| and |v| as just scaling factors on the first vector in each product.
whyyyyy texit whyyyyy
there is another definition of dot product that makes this easier to explain. $$u\cdot v = \lVert u \rVert \lVert v \rVert \cos \theta$$ where $\theta$ is the angle between the vectors. If you align $u$ on the x axis, then its easier to see that the projection of $v$ onto $u$ is $\lVert v \rVert \cos \theta$, where $\theta$ is the angle $v$ makes with the x axis. $ \ \ $ If you instead align $v$ on the x axis, then the projection of $u$ onto $v$ is \lVert u \rVert \cos \theta$. Now compare these projections along with this definition with 3b1b's...
I understand that algebraically, the explanation makes sense but I can’t seem to think of it visually
Well the thing is, projection is a visual thing, but dot product really isn't that i know of. Other than that it should be zero when the vectors are perpendicular
I guess what I really don’t understand is if the projection of one vector onto another is bigger then the vector being projected onto and why when he scales up vector v by 2 and projected it onto w in the video, then you have a larger projection and you are multiplying by the length of w. I understand that when w is normalized, it makes sense but if it wasn’t, then why would the projection of 2v onto w and multiplying it by the length of w be the same as projecting w onto 2v and multiplying it by 2v.
Sorry, I’ve got to go. Could anyone please DM me if they know the answer?
@gilded plover projecting w onto 2v is the same as projecting w onto v. The only thing we take from the vector we are projecting onto (v in this case) is the direction of v. In the dot product, the extra factor of 2 doesn't just go away, but it scales the whole product by two
any hints for (a) (or (b)) implies (c) in qn 3? i’ve shown that a and b are equivalent, but cant seem to figure c out
i cant think of how to use qn 2 fully, because in the primary cyclic decomposition, there may be multiple subspaces with the same irreducible factor
alpha is normal and it’s a positive definite form, so there’s the fact that alpha and alpha* are simultaneously diagonalisble. i saw some stuff on stackexchange, but they said to use lagrange interpolation, which we didnt learn, so there has to be an easier way
Let me draw your attention to the snipping tool, good for copying parts of the screen
okay sorry bout that!
Otherwise Isry I don't know how to answer, but there's smarties on the server
i was guessing maybe the polynomial expression of alpha* is the same when the cyclic subspaces have the same irreducible factor, but am not sure how to argue that
so, any hints?
Just want to know if this was correct
your algebra there is a bit off. I think in line 2 you accidentally wrote λλᵏx when you meant Aλᵏx
bad proof.
major argumentation hole
and also wording
you also need to show that λᵏx is an eigenvector of A
which is another one-liner
but it has to be done to be rigorous
you attempted to do a proof by induction, but neglected to state the base case, however trivial it may appear
and to prove $A^{k+1}x = \lambda^{k+1}x$ you cannot start with $A^{k+1}x = \lambda^{k+1}x$
Ann:
you do not start with X to prove X.
here‘s how I’d write the same thing more cleanly:
Assume $x$ is an eigenvector of $A$ with eigenvalue $\lambda$. This gives us the base case $A^1x = \lambda^1x$. Now assume the statement holds for $A^n$. Then
$$A^{n+1}x = AA^{n}x = A\lambda^nx = \lambda^nAx = \lambda^n \lambda x = \lambda^{n+1}x,$$ which was to be shown.
Sascha Baer:
@thin bloom
Ok so for a proof you never start with the statement that you want to prove
@dusky epoch For the base can I use k=1?
Since k=1 is assumed true by the question
Also @broken hawk
the base case is trivial but for a proof by induction you at least have to state that
like “base case n=1 holds by assumption” is enough
Ok so for a proof you never start with the statement that you want to prove
i mean honestly
how was that not blindingly obvious
eh, I messed that up a bunch. I usually intended to write sth like “I want to prove X=Y” and then just wrote X=Y
Can I start with what I want to prove and "convert it" using what I know is true to another statement that is true? @dusky epoch
it’s the algebra mindset
where you start with an equation
and then deform it until you get what you want
but really what you have here is sth like
A = B = … = C = D
so you should start from one side and try to get to the other
an equality chain
or you can start in the middle and show that it’s both equal to A and to D
ok
this for me often ends up looking like
A = B … = C
‖
D = … = E
(where the goal was C=E)
but you can’t just write C=E because you don’t know that yet
also, one more thing
if C=E is wrong
then you can derive true things from it
ex falso quodlibet
so starting somewhere and then showing a true thing is not a proof
1 = 0
0 = 1
1+0 = 0+1
1 = 1
(however, starting somewhere and then showing a false thing is a counterproof)
ok so if they asked prove A=D I have to use A=B=...=D therefore A=D? Rather than A=D=C=B since A does = B A=D must be true?
you cannot say A=D
even if I showed that A=D implies something true such as A=B
read through ann’s example above
just because X implies Y and Y is true does NOT mean that X is true.
where she shows that 0=1 implies 1=1
and yet we know 0 doesn’t aqually equal to 1
from true things you can only derive truth
from false things, you can derive everything
you don’t know whether what you wanna prove is true
so deriving anything true from it tells you nothing
deriving something false from it does however tell you that it’s wrong
you need to go either
true statement ⇒ … ⇒ thing you want to prove
or
thing you want to disprove ⇒ … ⇒ false statement
Alright I understand now.
here‘s another humorous false proof
assume 1=2
invite the pope into your room
there is now a pope in your room
there are two people in your room
since 2=1, there is now one person in your room, and in particular, as already stated, one pope
since you are in your room, and there is one person in your room, and one pope, it follows that you are the pope
so from a false statement, I derived something ridiculous
@dusky epoch @broken hawk Thank you.
cool examples
@broken hawk So never start from what you want to prove since it can lead to false conclusions
never start from something you want to prove, because you will never be able to tell if it was true
what if I did start from the proof and ended up getting statements that I knew were true?
I wont do this again but what if this happened?
as we’ve said about five times now
if you conclude something true, this tells you nothing about the original statement
put another way
if you ever see a true statement, then everything after that will be true
if you ever see a false statement, then everything before that was false too
but it does not go the other way
(before/after within the same chain of logical argumentation)
black being “unknown”
whats the T thing
shorthand for the word next to it

Im sorry I dont understand what the picture really represents.
$\top$ and $\bot$ are the logical symbols for true and false, resp
Ann:
the squiggles are statements
the two columns are independent
the columns are arguments
each is a sequence of statements, e.g. your calculations or what not
in which every line follows from what came before
if one line is known to be true, then everything afterwards is guaranteed true as well
if one line is known to be false, then everything before it is guaranteed false as well
but you never know anything in the other direction (the black lines)
the statements there could be true or false
So we're reading from up to down
yes, same as the equations in your proof
So how does some statement we dont know lead to something true?
here in your ”proof”
anything that would go after that last line is true too
anything above, we can’t conclude just by looking at this
OHHH
every line follows from the one above by a logical implication, but this doesn’t help
So if I started from false statement why don't i know if the next one is false or unknown?
which can be true so can I start off with a false statement and end up with something ture?
ok let me work on this proof again
I'd reword, don't say "we don't need to calculate for the base case" so much as "the base case follows from the definition"
If I solved for the eigen vectors of a 2x2 matrix and got complex eigen vectors do these eigen vectors span the space ?
They are distinct eigen vectors
if they are linearly independent, then yes, because any two linearly independent vectors will span a 2D space
however, if x is an eigenvector, then 2x is too
so getting two eigenvectors doesn’t mean anything yet
if they have different eigenvalues, then they’ll be linearly independent,a lways
(but you can have linearly independent eigenvectors with the same eigenvalue)
I got x1 = [5 3-i] and x2 = [5 3+i]
uh
that statement makes absolutely no sense
that’s like asking whether apples fit inside bananas
if you’re working in ℝ², then [5, 3+i] doesn’t exist
if those are the eigenvectors of your matrix, then your matrix simply doesn’t have eigenvectors over ℝ
with linear algebra, you always have to pick a field (e.g. ℝ or ℂ) and then you stick with it
So the original question was "Find the eigenvalues and corresponding eigenvectors for each matrix below. Do the eigenvectors form a basis for the space? " A=[1 -5; 2 -5]
and what is the space?
is this a matrix over ℂ that just so happens to have real entries, or one over ℝ
Codomain C but range of R?
what?
that makes 0 sense
I don't understand your question
appearance bananas but looks apples?
I did
i said repost
Oh
i don't want to scroll a mile up
Find the eigenvalues and corresponding eigenvectors for each matrix below. Do the eigenvectors form a basis for the space?
A=[1 -5; 2 -5]
it’s an ill-stated question if it doesn’t state what “the space” is anywhere
seen as a real matrix, A has no eigenvectors
seen as a complex matrix (which so happens to have real values as its entries), it has your two linearly independent eigenvectors and they span ℂ²
I think she means C^2 then
Therefore the two eigenvectors are linearly independent and are basis for the space
C^2
Hold on.
can the linear combination of the eigen vectors span R^2? I understand its complex but we can make the complex part be zero with the right linear combination of the eigen vectors
that’s not how it works
R^2 isn't even a subspace of C^2
like, yes, if it spans ℂ², then ℝ² is a sub_set_ of that
also, "complex part" isn't a real term
but it’s not, as ann just said, a subspace
and you can’t span something which isn’t a vector space
R^2 isn't a subspace of C^2?
hmm
but its a subset of C^2
yes sorry not the "complex part" I meant the imaginary part
it’s not a subset of ℂ² because the scalars in ℂ² are complex numbers, and so if x is a vector in a subspace, i*x is too
but i*(1,1) is not in ℝ²
right
So the question can't be answered?
Since we don't know what its really asking for?
Can I just assume that they're talking about C^2
@thin bloom i think complexification allows for vector spaces over R to have complex basis vectors
k so in conclusion these 2 complex vectors are basis for C^2 which will include the set of R^2
soo.
not a basis for C^2. We have two basis vectors over R, not C. It takes 2 basis vectors over C to span C^2.
your eigenbasis here just spans R^2
ok then ignore what i said. i don't quite know how to talk about this 
what are the elements of a curve?
anyone know any noob friendly vids on matrix transformation? Having a difficult time understanding how to go about it

In the 3blue1brown video https://youtu.be/LyGKycYT2v0 he explains how the dot product can be though of as a 2x1 matrix. He then goes on to solve for what the numbers in it are. I know that u hat’s x and y position encode a transformation but how do we know it is the transformation that we want? In the video, he says he needs to find a 1x2 matrix that takes 2d vectors to numbers but how does he know it will be u hats x and y position?
Home page: https://www.3blue1brown.com/ Dot products are a nice geometric tool for understanding projection. But now that we know about linear transformation...
in order for a transformation to be what you want it to be, it needs to send the basis vectors where you want them to be sent
Could you elaborate?
doesn't 3b1b say this pretty often in his linalg videos
a transformation is determined by what it does to a basis
Yeah but how do we know where the basis vectors should end up? He’s trying to explain why the dot product is also just a transformation but how do we know that the x and y positions should be as they are when they are projected?
He explains that as well at 9:00, since by symmetry the projection of î onto û is the same size as the projection of û onto î, which is just the u_x.
Right, I get that. What I do not understand is why we know that those are the coordinates that are the dot product/projection.
How do we know that the x and y coordinates are the ones we are looking for? At 8:31, he says we need to find the matrix that defines projction*lenght but how does he know that the x and y positions are the correct ones?
Consider thje link diagram : A ---> B. Ralph as a 2/3 chance of starting at page A and a 1/3 chance of starting at page B. Once per min, he click on a random link, if possible. What is the probability that ralph will be on page B after four minuteS?
not familiar with link diagrams, or what that is supposed to represent.
So this set of vectors can at most span R^4 because to span R^4 you need at least four vectors?
it can span at most R^4 because they only have four components
right away we can tell one of the vectors is useless because you only need four linearly independent vectors to span R^4, you have 5 vectors, so one is a linear combo of the others
assuming that four are independent
thank you. how can i tell which four are independent assuming that there are four linearly indpendent ones?
you can form a matrix with them and do the RREF if you want
pretty sure you only have to go as far as getting to upper triangular form for you to see which one is redundant
ok will do. thanks just making sure i understand.
its a little cut off but:
thats a graph of links where R(A)=R(C), R(B)=R(A), and R(C)=R(B)
It says the pagerank vector is, unsirpisngly 1/3,1/3,1/3
and i found the altered transition matrix to be
0 0 1
1 0 0
0 1 0
not sure how to do the next two parts though,,,
I'm not certain of the content, but I'm guessing Px is just a multiplication?
Then P²x, P³x...
There should be a pattern in the powers of P
@placid oracle
yes thats what i was notiicng
does my altered transition matrix seem correct though?
because i just used the normal matrix as there was no need to change it since it was already stochastic
also, its basically cyclying through the order of x_0 for every power
so how does that relate to the sequence approaching r in the last question
Yes I like it
hi guys
hi
I'm trying to find a matrix to change basis from A to B. I'm pretty confused. Is it inv(A)*B ?
Think about it
I mean inv(A) get me to standard basis and then applying B gets to that basis?
Given any 2 matrices, when can you transform them into each other by a change of basis?
Wait do you mean that those are your basis?
yeah those are both bases
Oh ok
I think what you said is correct
It's either that or it's inverse
Ie B^-1 A
I tried that and then tried to check it but maybe i made a mistake. didn't seem right.
X is the matrix your changing the basis of
ah
Fixed
eh i'm so confused. how can i even check which one is right?
i don't really understand what this question is asking, A and B aren't similar matrices, so there definitely isn't a change of basis between them
A and B are your basis
ah crap. i was trying to create an example so i could practice.
what does similar mean?
@slow scroll you can definitely do a change of basis between those 2 basis
it means two matrices can be written as a change of basis of each other.
If $I_{\mathcal{AB}} is the transformation that sends a basis $\mathcal{B}$ to $\mathcal{A}$, then
$$T_{\mathcal{AA}} = I_{\mathcal{AB}}T_\mathcal{BB} I_{\mathcal{BA}}$$
cmon texit....
Anyway, similar matrices share properties like trace and determinant, thats why your example with A and B doesn't work (unless i just don't understand what ur asking).
hmmm
You don't understand what he's asking
Given any 2 basis
You can do a change of basis between them
He's asking what the change of basis matrix.is
ohh....
wouldn't they both have to be invertible?
so in this case, if the matrix $A$ is a transformation that sends the basis, $\mathcal{A}$ to the standard basis $\mathcal{E}$ to, call it $I_{\mathcal{E A}}$. And if $B$ is a transformation $I_{\mathcal{E B}}$, then the transformation that sends $\mathcal{A}$ to $\mathcal{B}$ is $I_{\mathcal{B E}} I_{\mathcal{E A}}$. You get $I_{\mathcal{B E}}$ by inverting the matrix that describes $I_{\mathcal{E B}}$.
kxrider:
hmmm. makes my brain hurt
does this make sense at all?
i'm just trying to find out how i can check if i've found the right matrix.
and also to see if i understand it.
A change of basis matrix from $A$ to $B$\ is a matrix $P\in\GL_2(\bbR)$ such that $P^{-1}AP=B$ iirc
Tuong:
what does GL_2 mean?
?
err thats what i thought he was talking about at first too, but i think A and B are matrices that send a particular basis to the standard basis, and he wants to compose them so that one basis is sent to the other or somethin like that 
oh nvm
it will be conjugation because it's inverse is the change of basis matrix for the inverse transformation.
they're supposed to be matrices that send the standard basis to them A sends the standard basis to A which is the new basis.
same with B
yeah
this is supposed to be what A represents
it's just what you conjugate by to get the matrix of a transformation in a different basis (as it's name would suggest)
im gonna suggest that you watch this video if you haven't already https://www.youtube.com/watch?v=P2LTAUO1TdA&t=520s
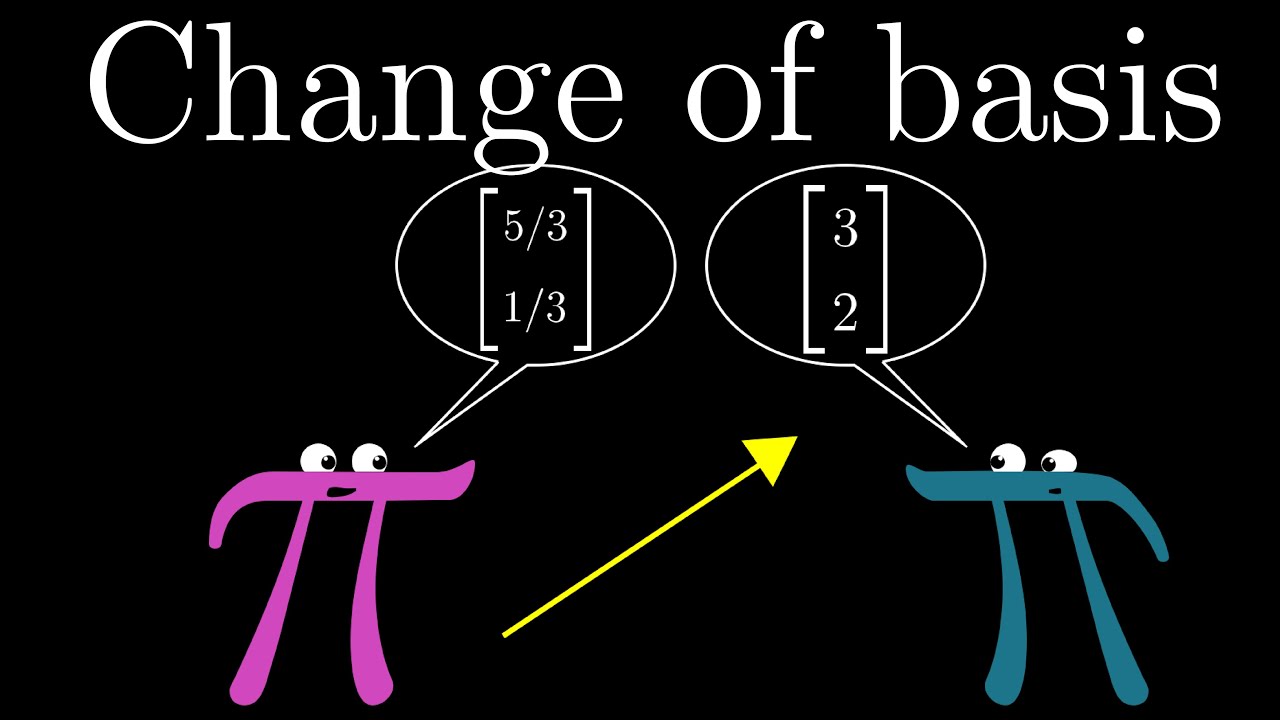
Home page: https://www.3blue1brown.com/ How do you translate back and forth between coordinate systems that use different basis vectors? Full series: http://...
i've watched it 10 times lol
i have a tiny brain 😉
but it is the best one i've come across. guess i should probably watch again
tl;dr $\begin{pmatrix} 1 & 5 \ 3 & 2 \end{pmatrix} \begin{pmatrix} 1 \ 0 \end{pmatrix}$ = \begin{pmatrix} 1 \ 3 \end{pmatrix}$. $ \ \ (1,0)^T$ is written in the basis of $A$, and the transformation you gave converts it into the standard basis, i.e. the wacky way we would think of this choice of basis when we see it.
kxrider:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
yeah i think i get it up to that far. just can't seem to put the rest together. anyway i'm a little closer to getting it i think.
think about it: whenever you are even defining a basis, you are trivially using the standard basis to describe it, so in a sense, anytime you talk about a different basis, you are transforming it to the standard basis to make sense of it.
This is honestly one of the most trippy topics I've come across in LA so far, so ur certainly not alone if you are confused xd
yeah it's like every time i think i get it i try it in a problem a week later and i'm lost. thanks for the help so far though. think i just need to rewatch that 3b1b vid.
aight np.
Typically, is a Intro to Linear Algebra class easier than, say, Diff Eq. or Calc IV?
yes
Depends on how you lean. It's conceptually heavier than what you might be used to, whereas Intro to DEs is more methodology-centric.
Aye, taking 261 (intro to linear algebra), 254 (calculus IV), and 256 (diff eq) in my first year in upper division CS. Already taken the first three calc classes.
If 261 is easier, then I'll stack it in a term with a harder CS class
Are there any good books for linear algebra by chance anyone would recommend
there’s two suggestions in #books-old but I’m sure if you have more specific wishes (in particular about what approach to linalg you need) people can find sth better
I just remembered those channels and was gonna delete lmao
Hoffman and Kunze is a bit old school but basically the correct linear algebra book
At least for the old school treatment. I hear "Linear Algebra Done Wrong" is the modern correct linear algebra book but I haven't seen it myself
I see thank you very much! I'll check them out
the name “linear algebra done wrong” is clearly a play on axler’s book (linear algebra done right), are they in some sense doing “opposite” approahces to the theory?
Axler's got this imo overdone to the point of stupidity anti-determinant thing going
in the preamble he never actually explains the title. he just says he first wants to get some other comments out and then never says the actual thing
to be fair we covered determinants only at the very end of linalg I and I didn’t feel like I ever missed them
What Axler doesn't like is, to be fair, valid. A lot of linear algebra courses do this thing where they're like "Okay a determinant is where you give me a matrix and I bash some stuff out"
we did a very matrix-lite course though
we introduced determinants as multilinear alernating maps with det(id) = 1
And then when it's time to prove that linear maps C^n -> C^n have eigenvalues, a geometric concept, everyone's like lmao tfw det(tI - A) is a polynomial so it has a root gg
Doing it that way is pretty shit, since like, the "input a matrix output a number through this algorithm" doesn't have much conceptual content in itself and then it's used to prove something of substance
Is there a specific math background that would be helpful for linalg by chance? Or is it something I could probably jump into and be fairly alright? I'm just rebuilding my foundation for Calc, haven't had the chance to look at what linalg entails exactly quite yet as finals just finished up
Now there's a correct way to do determinants and that's what you talked about, it's what Hoffman-Kunze kinda does as well. Axler's solution is to avoid determinants altogether
linalg can easily be done as your first “rigorous math” class
however
depending on the book used it wuold help to get a bit of background in proving things
He waits until much later, after he even does stuff like characteristic and minimal polynomials, and then he's like okay we're always working over C so det = product of eigenvalues
and in stuff like set theory notation
other that that?
high school algebra suffices and is barely needed
it’s a very “basic” subject
And he does some other stuff that's not in my taste coming from algebra. Since he only thinks of R or C, he never distinguishes between polynomials and their functions, etc
one thing I can absolutely recommend is to watch 3blue1brown’s series on it just to get a bit of an intuition for how to imagine things
for the most basic definitions
As for applications I'm going into pchem if that really matters at all (granted I really have no problem with just learning more for the sake of learning)
I love 3b1b
basically the reason I asked for that is because there’s, very broadly speaking, two different “linear algebra”s
there’s theoretical linalg, and there’s computational linalg
I'm doing computational chemistry specifically
the latter is uh, boring
but extremely useful
in a lot of applications
the former explains what the hell the latter is doing
and is very rich in nice mathematics,imo
and quite accessible
Yeah I wasn't sure if there was a different approach in learning that's better suited based on actual applications of it, but I feel like a nice conceptual understanding of it would help me a lot
chonk, supposing you already know proofs, maybe try lay's linear algebra book, its more of the applied type
I'll give them all an overview thanks guys!
@chilly burrow
If we're throwing out suggestions, Zill's applied engineering mathematics covers applied linear algebra in a chapter
if a 3*3 matrix has three distinct eigenvalues does that mean that there must be an eigenbasis?
@astral junco
Each eigenvalue represents a subspace of vectors. Each subspace has a basis.
It sounds like you have 3 one-dimensional subspaces
ah maybe i'm not forming the question right due to a lack of understanding
i guess i don't really understand what this is saying
anyway if i find three eigenvectors that are linearly independent does that mean that there is an eigenbasis?
yes
hey is this right
-5x < -45x + 200
-5x + 45x < 200
40x < 200
x < 5
? its linear inequalities.
That’s fine 👍
do you happen to know how to do compound inequalities?
Yeh
50<10(x+2)<180 this is one of my problems and I am not quite sure how I am supposed to solve it if you dont mind could you explain it to me
So am I removing the 2 and subtracting it from both sides?
wut
I am confused sorry
okay and that removes the parentheses right?
Yep
Thats what I was having trouble at thank you
No problem
then can I divide everything by 10?
Yep
3<10x<16?\
Well
👌👌👌
Ez
Yeah its not so hard once you figure out what you are doing

haha
Okay I am sorry I know im helpless but this problem is confusing me. Yeast, a key ingredient in bread, thrives within the temperature range of 90°F to 95°F. Write and graph an inequality that represents the temperatures where yeast will NOT thrive.
and above yea
Yeh
I got the graph I think but the inequality is the part confusing me

👌👌👌
I guess I was supposed to put an open point because it was equal too
Yep 😂
That one is on me lol

How do I work a word problem lol.
Oh boy word problems
would it help if you saw the problem?
Probably 😂
3x+5=>-19 and -5x-3>-18
3x=>24?
I guess my calculator is bad xD
XD
3x=>-24
x=>-8
Yep x=>-8
I was just fixing it lol
-5x>-15
Yep
then divide by -5
Ez
X>-3
I knew them pesky negatives lol
XD
what it said I got it wrong
yeah which side is open left or right?
I thought it was left but it said right side had open circle.
Yehhh

So x>3 x=>-8

-8<=x<3
So its not open circle on the left side?
fuck me
I am dumb
it just now hit me lol
Hadeth we fucced up
Open circle means it cant be there closed circle means it can I just got hella confused
I always fail on the easy stuff
😂
👌👌👌
Yeah I did one right lmao
Ezzz
Ayyy
Okay this one combines all my 3 worst things in compound inequalities
Kevin is baking bread for a family function. The initial temperature of the oven is twice the room temperature. He knows that yeast, a key ingredient, thrives within the temperature range of 90° F to 95° F. So to facilitate yeast growth, Kevin decreases the temperature of the oven by 44° F.
Which inequality represents the given situation?
oh god
Where do I even begin lmao
what does that even mean
IDEK
I want to die lmao
Would it help if I gave you the multiple choice anwsers?
answers?
yes
It will take a second because you cant copy them for some reason you have to manually write them down
hard work
A.90<=2x-44<=95
B.90<=2x+44<=95
C.90=>2x+44<=95
D.90=>2x-44<=95
That was a doozy lmao
I am pretty sure its not b or c
Okay c and d don’t make sense
yea so its a?
oh god try it
It was right oh thank god lol
I cant get any more wrong or I get a 70 which means I will have to do this satan work again
NO

I should have done this from the start lol
I suck at these line graphs
I think its D
Yeh
IT WAS B
WHAT
Oh god I will have to do it again
this was the explaination On the graph, the numbers to the left of x = 2 and to the right
of x = 10 are shaded. Therefore, the compound inequality will be an "OR" inequality, or a disjunction.
it tricked us
They have done it again
they are out to get me the entire school system is out to get us man lol
XD
god I hate the noise of failure
Every answer I get wrong it makes a noise and a part of me dies with it lol
the shame
I know will you fall on your sword with me partner?
yes
Activate seppuku

I blame the questions
No I am saying I don't blame you this is a huge honor to be bestowed upon
It’s 1:39 am
Damn do you live in asia?
Ohh red light district?
I think the only people that live there are prostitues and homeless people so I just insulted you
And I don't apologize
It kinda makes sense
Your next to both france and germany you were fucked from the start lol
aight gn thanks for helping me
have fun withsatan’s work
You know I wont
Does Repeated eigenvalues Imply Linearly dependent eigenvectors ?
no
Does a zero eigen vector imply anything?
I understand that now its not invertible
@native lodge
That's all it implies
I forget what zero means
Zero eigenvalue is actually equivalent to non invertible
ok
About the eigenvectors
Without knowing more info about the matrix you're working with
Question asks if the eigen values of a matrix A is 1,1,0,2 what conditions does the matrix A meet for it to be diagonalizable
yes
That's it
so I answered using the eigenvalues you must be able to obtain 4 linearly independent eigen vectors
Ok so like stating that the repeated eigenvalues must produce 2 linearly independent vectors?
for each eigenvalue λ, there must be as many linearly independent eigenvectors as the multiplicity of λ when considered as a root of the charpoly
this is the condition for diagonalizability
so in your case, dim(ker(A - 1I)) must be 2
is dim(ker(A-1I) same as nullity of A-1I? I dont remember
Ok thank you
👍

i'm trying to figure out if a vector is in the range of a linear transformation.
sry if this is stupid, but if the vector isn't in the kernel of the transformation then wouldn't it have to be in the range?
no
the kernel is part of the domain, the range is part of the, uh, range
I guess you use range the way I use image?
ok thanks. i'll have to read up on the difference between range/image think i'm confusing the two.
the way I use them (but they're not quite standardized) is that the image is precisely those that are actually hit by the function, while the range is more generally all the things it could hit, like the entire target space
gotcha yeah. a lot of new terms to memorize. probably gonna have to retake lin alg from the beginning to get any sort of understanding of it lol
hmmm from every resource ive heard from, the range is the same as the image and the "co-domain" is the target space
same for me.
yea, as said, not everyone uses them the same
image seems pretty clear tho
I think it’s only range that’s ambiguous
I’m linear algebra, I have learned that a 2x2 matrix represents a 2 dimensional transformation and that the columns can be interpreted as where they take I hat and j hat so when you do vector matrix multiplication it’s just scaling the new I hat and j hat and then adding them which is pretty much what you do when you have a vector. But now I’m confused with matrix multiplication. Both vectors can’t represent where I hat and j hat land because then the result would always be the second matrix applied so what is an intuitive way to think about it?
think of it as applying the rightmost matrix first. that’ll transform not just your basis vectors, but also the rest of the grid. so now there’s two new vectors that can be considered “i” and “j”. and then the second (left) matrix will move those to its columns
Ok, could it be thought that the transformed I hat and j hat are now just vectors in a new, normal I hat and j hat space and then that space also gets transformed?
So whenever all of space gets transformed, it is still inside another normal vector space?
what does “normal” mean
the image of a linear transformation will again be a vector space. if the function is surjective, it will be the entirety of the target space, otherwise some subspace
basically, if you apply the function encoded by $\begin{bmatrix} 1&2 \ 3&4 \end{bmatrix}$, then the vectors (1,0) and (0,1) will move to (1,2) and (3,4), respectively. and then you take (1,0) and (0,1) again, and transform those. and if you multiply the matrices, that’ll tell you where the original (1,0) and (0,1) land when you first apply the right and then the left transformation
Sascha Baer:
Well I learned that a matrix could be thought of as transforming the entirety of vector space since changes to I hat and j hat change all vectors. By normal, I just mean j hat is (0,1) and I hat is (1,0). I’m imagining something like a bunch of vector spaces stacked on top of each other like paper. The first matrix transforms that one on top and then applying the second one transforms the one below it which also affects the top one.

just divide through some norms
I proved that each left eigenvector is orthogonal to a right eigenvector with a different eigenvalue
But how do I normalize each left eigenvector
What does that even mean
well, if you do $b_i \cdot a_i$, you’ll get some value
Sascha Baer:
divide $b_i$ by that value
Sascha Baer:
Cosack:
no, you showed that $b_i \cdot a_j = 0$ for $i \neq j$
Sascha Baer:
for $i = j$ it should be nonzero, that was part of the exercise
Sascha Baer:
So if I normalize them
it works for even i = j
I still get nonzero answers
Whats the point of normalizing it then
your goal is $b_i \cdot a_j = \delta_{ij}$
Sascha Baer:
not $= 0$
Sascha Baer:
But isnt $\delta{ij}$ = a number
Cosack:
it’s 1 if $i=j$ and 0 otherwise
Sascha Baer:
because orthonormality is just nicer to work with than only orthogonality
I can’t tell you what’s the point in this specific example
but in general, it’s nicer to only work with 0s and 1s, than with 0s and random numbers
Probably helps with this
i guess
Looks like a2 is the same as a1
just opposite direction
Thats cool
uh, do you have distinct eigenvalues?
either way, that’s not a basis
you should have (1/2, 1) and (-1/2, 1)
yea that’s not what you said
“opposite direction” usually means just - on everything
Oh
Opposite x
Well
I see what you mean
my bad XD
Also a question
I found that you can just find left eigenvectors of A
by doing right eigenvectors of A transposed
but when you do that
Doesn't work because matrix multiplication requires certain dimensions
you cant do (2x1) x (2x2)
that’s what you just said, no?
I said you just do A transpose
I’ve never worked with left eigenvectors
ah, yea that makes sense
but then I can't satisfy
so you’ll get the following:
yea, give me a sec I’ll write it up
so let’s say $\hat b_i$ is a (right) eigenvector of $A^T$
Sascha Baer:
then $(A^T \hat b_i) = \lambda \hat b_i$
Sascha Baer:
now transpose both sides of the equation
and you’ll get $(A^T \hat b_i)^T = \lambda (\hat b_i)^T$
Sascha Baer:
and $(A^T \hat b_i)^T = \hat b_i ^T A$
Sascha Baer:
so, a left eigenvector of $A$ will be the transpose of a right eigenvector of $A^T$
Sascha Baer:
yes
So if I have
and lets call it bi
bix = 2
biy = 0
if i transpose it
x and y are the same still yea
bix = 2, biy = 0
Cause for this part
I can assume that x = first value, y = second value
from left-> right or top->down
or is that wrong
here’s where you’ll need that normalization :P
basically all you have to check is that B is diagonal in the sense shown below
it’s weirdly worded
yea. by fundamental theorem of algebra, char polynomial has at least 1 root, so u get at least 1 eigenvector. then u use properties of the hermitian-ness to show that its eigenvalue is equal to its conjugate, so it has no imaginary part
@feral crow
Thanks!
and probably some invariant subspace stuff so u can take quotients without messing anything up
to get the orthogonal basis
But if the left eigenvectors are always equal to the right eigenvectors
How can they be orthogonal
nvm
The two eigenvectors with the same eigenvalue
are orthogonal
@woeful hawk I don't know what it is you need, but this channel is empty atm so good enough
What's R(-theta)
is that just R times -1
full question for context
dont know how to do e
R(-theta) is like f(-x)
What all have I covered?
@fringe cave a friend already helpe me thanks
Yeah I have.
But I kinda just have a basic knowledge.
I don't know if there are a lot of complex techniques and stuff.
Just do the gaussian stuff and get it so that you can more easily see what changing k does
Like, get it into a triangular form or something, you know?
Triangular form?
Alright, so, you know how you can add and subtract the equations from each other
You mean reduced echelon form?
ye that's even better
Oh, okiii.
triangular is just a slightly different type of the same thing
Echelon form wouldn't work too well I fear since you can't exactly fully remove the kz, but if you manipulate it to find x or y or something from, say, the top two equations
it would help
should work
U blu
So I should learn about the triangular form then?