#linear-algebra
2 messages · Page 3 of 1
But going triangular is well known to be the fastest computational method. If you're on pencil and paper though you're probably interested in the least resistant way
so elementary row operations don't affect the determinant 🤔
Adding/subtracting rows together doesn't.
Multiplying a row by k will multiply the determinant by k
🤔 but isn't multiplying a row k times just adding to itself k times?
sources said the same thing, no biggy
So quite often, especially if the entries are integers, you can do a few simple additions to greatly simplify the calculation
that helps a lot 🤔
Trying to think as to whether there's some kind geometric intuition for this
I don't know any geometric intuition for the determinant, lol. I know there is one but I don't think of it that way
You have exactly what you need when you said det(AB) = det(A)det(B)
That's the useful property
The geometric intuition for the definition of the determinant is just the area/volume/hypervolume of the parallelogram/parallelipipeds/hyperparellelipipeds formed by the collumn vectors of a matrix
the identity matrices trivially forming squares/cubes/hypercubes
Oh, yeah that makes sense
of det 1
The factoring rule would be enough to prove the effect of elementary matrix operations? 🤔
No, I don't think that's enough to prove them. Gotta actually go through the determinant logic for that
the easiest way to prove it is if you’ve defined the determinant as an alternating multilinear map. in which case it actually all becomes essentially trivial
alternating means that swapping two rows changes the sign
multilinear implies that multiplying a row by λ increases the determinant by that much; and that adding a row doesn’t change the determinant (that last bit requires a tiiny bit more thought)
you can also think it through geometrically though
swapping two rows doesn’t change the volume, and changes the orientation
multiplying a row by λ has a rather obvious effect of making it λ times bigger by stretching it in one directon
and adding a row to another one causes a shear, volumes are invariant under shears
I like that way
t!rep @half ice
🆙 | EmperorPussyPounder has given @half ice a reputation point!
🆙 | EmperorPussyPounder, you can award more reputation in 3 hours, 58 minutes and 49 seconds.
:d
repping
don't you get goodies from reps
i need halp
i had a mxn matrix, 4x3
i did reduced row echelon stuffy on it
it now is a [100,010,001,000] matrix if u get what i mean right
100
010
001
000
like that
ax=0 right yada yada, how do i know if my matrix is surjective or injective?
with linear maps that’s actually really straightfoward:
-column vectors span the entire image space (which means rank = #rows) → surjective
-kernel is trivial (which means rank = #columns) → injective
in general, a map from ℝⁿ (rows) → ℝᵐ (columns) can only be injective if n ≤ m (”tall matrix”) and can only be surjective if m ≤ n (“wide matrix”). a square matrix is either both (full rank) or neither (degenerate)
how does one "convince" oneself in part d?
<@&286206848099549185>
anyboody? 😢
The line l is tangent to a circle centered at P
this basically means "understand that it's true but you don't have to prove it"
And the tangency point is Q
ok
how do i do the next part
which is just silly
i hate this maths with these points not actual numbers
because im fussy like that
@burnt gate why can't my lecturer give me numbers like a nice man 😦
Numbers are overrated
try putting numbers in and seeing if it helps? for instance a=4, b=-3, c= 7, P = (13, 0)
gave up, I have to take my medications, don't have time to do it 😦
EDIT: I believe I have a solution
so i have like 7 conditions for a function s(a,b,c,d) and i need to find an equation that actually satisfies those conditions
the conditions are
s ∝ a/(a+b)
s ∝ c/(c+d)
s ∝ 1/[b/(a+b)]
s ∝ 1/[d/(c+d)]
0 <= s <= 1
s = 0,iff a=c=0
s = 1,iff c=d=0
a,b,c,d are non-negative integers
Could someone explain why (x+3)(x-3)=9 is not allowed?
but only factorise values equal to 0 is allowed
For me it makes perfect sense tbh, just findxvalues that equals 9
because when you are solving a quadratic equation.... lets use
(x+3)(x-4) = 0 to find that x = 4, we are dividing both sides of the equation by x+3 under the condition that x does not equal -3, otherwise we would be dividing by zero.
If the other side wasn't zero, lets say
(x+3)(x-4) = 9 then our trick doesn't work anymore. If we are trying to find x=4, then we would divide both sides by x+3 and get....
x-4 = 9/(x+3) which doesn't help us at all.
(also this is #prealg-and-algebra or #precalculus ffr 😃 )
lol fixed
Expanding it x^2-x-12=9
Did my writing literally disappear
x-4=9/(x+3)
*(x+3) so
x(x+3)-4(x+3)=9
expadnding it to x^2-x-12=9
subtracting -9 on both sides we get x^2-x-21
Solving by quadratic you would get...
(1+-sqrt(85))/2
for the equation in your first example, you could actually solve it without very much work.
(x+3)(x-3) = 9
x^2 - 9 = 9
x^2 = 18
x = sqrt(18)
basically there are many ways to skin a cat xd
@wintry steppe
i guess im not exactly sure what you mean.
(x+3)(x-3)=9 does not imply x=-3, x = 3
is what its saying
Oh yes I didnt mean that at all
I mean is it possible to find a value of x such that (x+3)(x-3)= 9 ?
yea, +-sqrt(18) like i did above
Oh right im braindead
both you and khan said it "only applicable to when its zero"
yeyeyyeye thanks anwyays 😃
one sec just to make something clear
Okay?
(x+3)(x-3) = 0
when you say x=3, you are really saying
x+3 is nonzero, and that x-3 MUST be zero because the only way to have zero on the other side of the equation is if one or both of the factors are zero.
because x-3 MUST be zero, we have x-3=0 which mean x=3.
Yes this is the zero factor product property ?
uhh i didn't know it had a name but probably lol
np c:
this is the equation $$A \begin{pmatrix} x_1 \ x_2 \ x_3 \ x_4 \end{pmatrix} = \begin{pmatrix} -2 \ -8 \ -3 \end{pmatrix}$$, where A is the matrix from the top of the page
Sascha Baer:
you’re looking for the vector which transforms in such a way under left multiplication with A that you get the righthand side vector
I'd like to multiply these 7 matrices together (the X Y Z W matrix will be at the end, dw)
But you can tell it's going to get hairy pretty quickly. Would there be any alternatives to it?
<@&286206848099549185>

well all of them are rotation matrices
it’s the product of all six rotation matrices in R⁴
which in general is going to result in some orthogonal matrix with positive determinant
I couldn't find out what the last three were, they look like rotation matrices but information on that stuff is rather scarce
but yea the det will be 1
yeah... I'm trying to make a 4D graphing calculator
I may not have enough paper for all that matrix multiplication
How tho
@wintry steppe when you multiply those 7 matrices together, you will end up with a 4 x 1 matrix which contains your respective X Y Z W coords, which you shave off the W coordinate and compress 4D Coordinates into 3D. You use the W coordinate for stereographic projections
You can use quaternions
A 4d vector corresponds to a quaternion q
A 4d rotation can be represented by a pair of unit length quaternions l and r transforming q to lqr
tbh yea
Quaternions are less efficient at times but probs easier to program than all those matrices 
do you know what orthogonal means
the question is ambiguous tbh
doesn't look ambiguous to me 🤔
how many components of the vectors in W
2
doesnt say that
it could contain (x,y,1) and for all x,y it would be true
not neccessarily
like (1,1,1) is orthogonal to (1,1)
no it isn't lol
(1,1,1,1,1,1........,1) is also orthogonal to (1,1)
anyway I'm not here to argue with you
ok
uhm, what does “orthogonal” mean to you
cause under no definition of it that I’m aware of is what you said true
dimensions are perpendicular to eachother
that’s not a rigorous definition
if some vectors lives in a separate dimension from the other it's orthogonal
a proper definition of orthogonal uses the concept of an inner product
and then two vectors are orthogonal if their inner product is zero
sascha bear could you pm me
no
the dot product definition is strictly for vectors within the same space
yes
yes, it does, by the definition of what orthognal is
but the standard dot product is just one way of defining an inner product
there are vectors which are orthogonal regarding one inner product, but not another
vectors are orthogonal if their dot product = 0
that's one property of orthogonality
no, that’s the definition
anything geometric follows from that
but “the dot product” is not unique
it's the other way round
there are many different spaces with many different inner products
okay, I’m gonna go the woog way here
this is pointless
wikipedia says this btw:
In mathematics, orthogonality is the generalization of the notion of perpendicularity to the linear algebra of bilinear forms. Two elements u and v of a vector space with bilinear form B are orthogonal when B(u, v) = 0.
this is even more general
a bilinear form is a generaization of an inner product
the issue is basically, you’re not using this word like all other mathematicians are
perpendicularity we see
but I have a zelda game to play
enjoy!
which is more important than this
I'm sure it is
 perpendicular to urself
perpendicular to urself
Can anyone help me with 5,6,7?
you have to first express the e_i as a linear combination of the v_j
then just apply the fact that T is linear
like, $T(e_i) = T(\sum a_j v_j) = \sum a_j T(v_j) = \sum a_j u_j$
Sascha Baer:
What is v_j?
the vectors v_1, v_2 etc
O
i and j are just variables here for all the possible indices
okay though what is really weird in this exercise is that T seems to change definitions halfway through the exercise so…
bit confused here myself tbh
😩
Sill super confused
can a symmetric matrix have any zeros on the diagonal?
well I didn't think all the diagonals could be zero
but one on the first element [1,1] seems alright
for a 2x2
[ [0 , a] , [a, b] ]
(they're rows)
Yeah that's symmetric
I was trying to show that if I had a pair of Q-conjugate vectors then they must be independent
if i have
alph = ( a1 a2 ) # vector
beta = ( b1 b2 ) # vector
q = [ [q1 q2] , [q2 q4] ] # matrix (they're rows)
where alph, beta are dependent , and q is symmetric
then I can write
alph = k * beta
and plug this into the product
alph^T * q * beta
which ends up with a quadratic form... which can only be zero if q is skew symmetric, so I have a contradiction
that seems like it should be enough?
<@&286206848099549185> does that seem enough to prove that if alph,beta are Q-conjugate then they're linearly independent
https://marcan.st/paste/czgaGc7a.txt
I found this Python code for computing an M by M forward DCT of an N by N image. It uses non-square matrices. Since the inverse DCT is a well-defined operation, is it possible to compute the inverse DCT using some (relatively) trivial modification of this code? I am a total beginner as far as linear algebra and DSP.
wait nvm, after going back to Wikipedia I realized that you just have to replace the part with the cosine with what the DCT-III uses
I think the code is wrong, it appears to disagree with Wikipedia on whether k or n has one half added to it
So how about dem Jordan normal matrices?
where can I find more information about b here?
@wintry steppe I don't think that I follow what it means in that sentence then.
That there's a global minimizer found by solving Qx=b , I can choose any constant vector for b?
if your function has the form $f(x) = \frac12 x^T Q x - x^T b$ for some positive definite matrix $Q$ and some vector $b$, then the minimum value of $f(x)$ is obtained at the point $x$ such that $Qx = b$
Xaositect:
because the gradient of this function is $Qx - b$ essentially
Xaositect:
urgh, ok. That makes sense. Not sure what I was thinking there
(sorry wrong emoji there)
:)
Here when it says "Now premultiply ... to obtain", I'm a little confused.
It's saying that this will be one of many terms from that product, rather
than that being the result of the whole product?
$$
d^{(k)T} Q(x* - x^{(0)}) = \beta_k d^{(k)T} Q d^{(k)}
$$
Is one of the terms from
$$
x* - x^{(0)} = \beta_0 d^{(0)} + \cdots + \beta_{n-1} d^{(n-1)}
$$
rie:
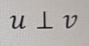
u and v are orthogonal
oh thank you
I have this function: https://i.imgur.com/vq3XX16.png which is a linear transformation
https://i.imgur.com/gA13Ycj.png I am given this vector. I need to find another vector v2 such that f(v1) = f(v2)
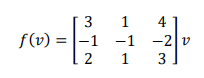
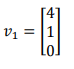
Not sure if it exists? Did you multiply this 3x3 by v1?
well then make a systeam of linear equations
find a non null vector v in ker f and v+v1 can be your v2

[-1, -1, 1] seems to be in ker f
Ok, so Ker(f) would be when the multiplication results in [0, 0, 0]?
yea
So for that function, I would do for example in the frist row - 3x + y + 4z = 0
first*
yes
except for all them after row reduction
but 3x not -3x
hey guys im currently taking a course in lin alg however it was supposed to be lin alg with proofs.... since our prof seems to be perpetually behind on the material he always skips over theorems and proofs. Do any of you guys know of any good online notes that cover lin alg proofs, or maybe a textbook that focuses more on the proofs and less on applications?
If you're savvy, linear algebra done right is always a recommendation
If you're less savvy, done wrong is also good
yea id like something that will challenge me as im really thinking about doing a math minor
@winter reef @brittle juniper when I finish row reduction and I get 2 rows (started with 3), I can set Z to be whatever I like?
[3, 1, 4] => 3x + y + 4z
he means like [x,y,z]
but that doesnt work like that
not sure what's the right way, ask tuong, but like you should find basis of this system and find general solution
If that's what its called in english
I'm just asked for one example of v2 where f(v1) = f(v2) and v1 != v2, I took the Ker(F) proposal, it is my understanding that KerF leads to the 0 vector
tehn as Tuong suggested, [-1,-1,1] seems to work
hence the row (3, 1, 4) is 3x + y + 4z = 0< and so on for all rows
you only need a non null vector of Ker(f), you don't need to solve the whole thing to find one
yeah but I don't really feel like guessing on the test s:
plus I'll have to show how I got one?
I think
for example you could just notice that 1st column + 2nd column = 3rd column and deduce a non null vector of Ker(f) from that
am I doing anything wrong? I just took f(v) and reduced the 3rd row like you said the 1st and 2nd is 3rd
I mean I did it a bit differently but after reduction I still have 2 rows that need to be 0 and 3 variables
The way I understood it is that because the 3rd row is 0
well do whatever you prefer, i have no idea what's this "reduction" method you're using
just regular stuff like R3: R3 + 2*R2
OK, after solving this there's another question - I am given that [2, 2, x] is a member of Im(f)
and I need to find such an x
the way I understand the image is the span of all results of the bases acting in the function
so if I find a base, say [0, 1, 1] is a base to my transformation
do I input [2, 2, x] and expected [0, 1, 1] ?
Hello!
I had a question, if we were given the square of the matrix how would we find the original? Thanks!
square root
you can define a square root on matrices, the specifics depend on whether the matrix is diagonalizable though
if it isn’t, apparently you can, but I don’t know how
if it is diagonalizable, then you diagonalize it and take the square root of all the diagonal values
like, you define $$\sqrt{A} = \sqrt{Q^{-1} \Lambda Q} = Q^{-1} \sqrt{\Lambda} Q,$$ where $$\Lambda =
\begin{bmatrix}
\lambda_1 & 0 & \cdots & 0 \
0 & \lambda_2 & & \vdots \
\vdots & & \ddots & \
0 & \cdots & & \lambda_n
\end{bmatrix}$$
and
$$\sqrt{\Lambda} =
\begin{bmatrix}
\sqrt{\lambda_1} & 0 & \cdots & 0 \
0 & \sqrt{\lambda_2} & & \vdots \
\vdots & & \ddots & \
0 & \cdots & & \sqrt{\lambda_n}
\end{bmatrix}$$
Sascha Baer:
my god I actually got those matrices right first try
if A is a real matrix (and you want the square root to be real too), then symmetric positive semidefinite is a sufficient (but not strictly necessary) condition that this is definitely possible
@pliant niche
@broken hawk why would you try to sqrt a matrix though
does this behave nicely with characteristic/minimal poly stuff?
linear transformations
they want me to multiply and subtract, but it dont tell me what T and S is
they do
does say
is T (2,3)??
in the above exercises
minimal poly is preserved under similarity, so it would be whatever square rooting does to the diagonal matrix
ty guys
which honestly I don’t feel like thinking about
I don’t think it would behave very nicely
but uh, square rooted matrices came up somewhere in an exercise once hang on
for T^{-1} = T^k would it be true that like
I think that was in analysis
the k-th root exists and equals T
thought volume stuff used exterior forms
yea, right, this exercise (lemme translate real quick)
Let $n \in \mathbb{N}$ and $A \in \mathrm{Mat}_{n,n}(\mathbb{R})$ a symmetric positive definite matrix. Compute the volume of the ellipsoid $$E = \left{ x \in \mathbb{R}^n \mid \langle Ax, x \rangle \leq 1 \right}.$$ You may assume as known the volume $\omega_n$ of the $n$-dimensional unit sphere.
Sascha Baer:
to solve this, you take the square root of A, which is also positive definite and symmetric, then because it’s symmetric it’s self-adjoint, so you can turn that inner product into ⟨√Ax, √Ax⟩, and then you have youself a diffeomorphism given x ↦ √Ax, so you can do substitution
this is the only time I’ve ever seen the concept of square rooting a matrix come up in practice tho
I didn’t even remember it was a thing, and was therefore rather hopelessly lost on this exercise
in hindsight it seems fairly straightforward
incidentally this is why √|det A| shows up in the volume formula ultimately :P it’s really |det √A|
so complex eigenvalues
what about them?
I know the 90 anti clockwise rotationmatrix has eigenvalues i and -i
Can we diagonalize matrices that don't have real eigenvalues?
nilpotents?
uh, I don’t know of any nice characterization
there definitely are not nilpotent ones
e.g. $\begin{bmatrix} 1 & 1 \ 0 & 1\end{bmatrix}$
Sascha Baer:
this is not diagonalizable
You can jordan diagonalize that one
yes, every square matrix over ℂ has a jordan normal form
that’s not what diagonalizable means though
over ℂ, yes
Even the ones without real eigenvalues?
yes, they’ll just have complex ones
🤔
that’s why “over ℂ” is important
the matrix may be completely built with complex numbers
we’re no longer in ℝⁿ
we’re in ℂⁿ now
and it works in ℂ but not ℝ because in ℂ the characteristic polynomial always splits into linear factors
ie there are always enough eigenvalues
Quick example of how to do it with the anticlockwise rotation matrix in R^2?
Characteristic equation would be lambda^2 = -1
well it would now no longer be an anticlockwise rotaiton in ℝ²
for one
but some other transformation of ℂ²
🤔
some double rotation I reckon
based ont he fact that it diagonalizes to $$\begin{bmatrix} i & 0 \ 0 & -i\end{bmatrix}$$
Sascha Baer:
because those are the eigenvalues
and the change of basis matrices?
effort
apparently it’s $\begin{bmatrix} i & 1 \ -i & 1\end{bmatrix}$ (source: mathematica command EigenSystem)
Sascha Baer:
and yea, I need to go to bed too
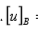
can someone explain this symbol and what it means?
or at least what it's called so I can read about it
It might be the vector u represented in the basis B
it’s what auvera said
vector u represented in basis B
(note that for this stuff there’s many notations)
would det (A^-2) be equal to 1/sqrt(det(A))
$\det(A^{-2}) = \frac{1}{(\det A)^2}$
Xaositect:
o shit thanks
yes, it would
$\det(A^{-2}) = \det((A^{-1})^2) = (\det(A^{-1}))^2 = \left(\frac{1}{\det(A)}\right)^2$
Sascha Baer:
What are the common uses of the Jacobian matrix?
it fully describes the derivative of a multi-dimensional function, so the same as the common uses for the derivative
really, the jacobian is the multi-dimensional derivative
ex= 5b^T.... Do i multiply by 5 then transpose? or Transpose this multiply by 5?
convince yourself that it doesn’t matter which way round you do it
Thank you @broken hawk
Also, when i transpose does it matter the order? Left to right? up to down? or is it fine as long as im consistent?
@steel cobalt when you transpose, you reflect it along the main diagonal. so the first row becomes the first column and vice-versa
top left remains top left
what order you write stuff down is irrelevant, of course, only how it looks in the end matters
also, @sour garden consider if the matrices consisted only of the max value
then in their product, every cell would be m*max(A)*max(B)
so this is an upper bound
Ah
Anyone here well-versed in mathematics related to machine learning?
It's in #help-7|zen1thxyz
Hello all, i'm a new member of the discord and have a question regarding the combination of linear algebra and computer engineering
Would I refer to a question channel or ask here?
Here's fine!
Okay, cool. I'm a Computer Engineering major taking Linear Algebra and I have a project where we have to use linear algebra in a real world application
My project idea was to somehow use matrices to represent or manipulate finite state machines / determinite finite automata
Fundamentally it sounds really simple, but I don't have enough knowledge of linear algebra to know if there's any potential in the subject
can I not send images in this discord?
you can
Hm, wasn't letting me earlier
this is a state transition table / also known as a moore machine
Technically speaking it's a deterministic finite automata where the final state is represented by the double circle
(in this case S1)
I wanted to use linear algebra as a way to express these state machines
So in this case if you are at S1 and input a 0 into the machine, you end up at S2.
If you are at S2 and input a 1 you remain at S2
This is a very fundamental DFA
Similar idea, but a little easier to see how to apply the linear algebra, check out Markov Chains
Markov chains were exactly what inspired me to begin this project actually
because they appeared very similar
Ah, then I see where you're coming from
the problem is, our linear algebra teacher is a statician and already taught markov chains and stochastic matrices
so it would be difficult to have a project that would impress him
I was thinking about a potential fallback idea, nested markov chains / stochastic matrices
I am not sure if "nested" is the right term, but that's what came to mind
Ideally, if we have a stochastic/probability matrix P and an initial market state Xo, we can simply multiply them 'n' number of times together to find the market Xn
but this bothered me because it follows the assumption that the probability matrix never changed over time.
and i know in real life application the probability matrix WILL change over time, unlike in an ideal world
sorry if I'm just randomly spitting info
The professor never answered my email, but here's a basic example. Assuming we have 7 different stochastic/probability matrices, one for each day of the week, and we are given the market state Xo that starts on sunday, can we find the market state in exactly 3 weeks 4 days from now?
Is there some sort of algorithm or computation we can do besides multiplying 25 times in a row manually?
Just re-posting for visibility here.

Intuitively thinking, I wonder if I just have to find a w that makes one of those norms 0...
Right?
@little cairn I believe what you are looking is adjaceny matrix
I know they're a numerical way of expressing the relation of the edges between vertices
I dont the exact stuff but
I'd look in that direction
@little cairn
If you know calculus, systems of differential equations are easy enough
@half ice I'm relatively versed in systems of differential equations but how would that apply to my problem?
And which problem are we talking about, the nested markov chains or the finite state machines?
I have not used eigenvalues before.
I'm solving systems of differential equations in other classes like Circuits 2 and Systems and Signals
as I said, computer engineer major
So linear algebra is still a bit foreign to me
Let's say you have two variables, x and y, each functions of t. Assume they satisfy
x' = 2x - y
y' = x + y
Then you can write them in this form:
[x'] = [2 -1] [x]
[y'] [1 1] [y]
I'm following, just keep typing
The solution to both x and y depend on the eigenvalues/eigenvectors of that middle matrix
I vaguely remember eigenvalues as subtracting \lambda across the diagonal of a matrix... though I am not sure what you mean here
The biggest application of this is easily control theory, where the eigenvalues of such a matrix are used to determine if a system is stable
If you don't remember how to do, that's k. But this is a pretty large linear algebra application
I can definitely do some research on spare time. Thanks.
So you're saying this as a new project idea entirely or this can apply to one oft he ones I mentioned?
the project is a semester-long project so I have plenty of time to pivot if need be
New idea. Just in case you need something else
I spoke to the head of the computer engineering department and he said he found no useful scenario upon which I would want to describe a finite state machine as a set of matrices
There's always machine learning, too.
That's interesting and very based in computer science
There's matricies in there
^Can confirm my machine learning class has been more linear algebra than coding
Haha. Good to know
I'm in embedded systems design not machine learning, unfortunately
So my future, at least according to most professors, consists of coding in C and C++, along with the fundamentals of various processor assembly languages
in order to configure various microcontrollers to perform specific tasks
I would be surprised if they don't teach you control theory in your courses
Control or more EE
but
yeah no a lot of EE/CE is linear algebra
There is too applications where u want to describe a graph as a matrix
maybe not a FSM though
Actually maybe even FSM
discrete time event systems comes to mind
eh idk
Ive read a lot of spectral graph theory where you built undirected graphs of data points
and use eigenvectors of graph laplacians to do optmization problems
That's really all the documentation I could find, was using complex linear algebra for deterministic finite automata minimization algorithms
So you're a CE
but in terms of just straight up representing the finite state machines as matrices? not much out there.
i'm a junior year CE, I learned about finite state machines in Digital Logic Design class
There's prob not an application there
FSM are used for just organizing the shit
Like 1 instruction might take 5 computer cycles
and the control unit is a giant FSM that sends the correct data direciton signals to the muxes
for pushing shit around the data bus
there is n o point in describing that into a amtrix
so you agree that FSM's and linear algebra are two concepts that can be combined, but really don't have a purpose to?
no
Im saying
For the purpose that you're doing it
as a CE
no
it doesnt
but there def is
Well It's a project for my class LINEAR ALGEBRA, I just need to find a project idea
in other cases
It's not a project for control theory, or computer architecture or anything
im pretty sure the only reason the professor allowed me to do this project was becuase he didn't understand FSM's on a high enough level that he could tell me how to use them with linear algebra
He has a PhD in Math/Statistics I believe, so obviously FSM's are not his strong suit
give a presentation on how the determinant of a matrix and the eigenvalues of a system of equations is related to determining if there are solutions
its simple
and 99% of the class wont know it
and its 100% linear algebra related
Did you read my previous proposition regarding markov chains and stochastic matrices (nothing to do with FSM's) for a new project idea?
I will take yours into consideration but my question was simple
We learned about the fundamentals of markov chains, the probability matrix P being multiplied by the initial market state Xo 'n' number of times to find the market state Xn
But the probability matrix, in reality, can't possibly be unchanging, and so I designed a scenario in my head where there were 7 probability matrices P1...P7, one for each day of the week
We are given the initial market state Xo, on Sunday (so P1), now find the market state exactly 3 weeks and 4 days from now
Is there a way to do so without multiplying the probability matrices literally 25 times over (25 days total)?
I hope whatever I said made sense
when they go from matrix to matrix, what exactly does the middle information mean? like r2+r1 or r1+2 r2
@slow scroll thank you
np
how come in my initial example there are still two rows are you add them?
er, sorry, bad question
it's more like i'm unable to understand what r1 and r2 are exactly referring to
in my head, it refers to [1 -2] + [-1 3] = r1+r2
So when you're doing elementary row operations
ye, so you replace row2 with row1+row2
^
The idea is that all of these operations preserve solutions to the underlying equation
What you're doing is exactly that thing where to solve a system you take one equation and add another to it
is it a rule that tells me to replace row 2 with that sum? - why couldn't I replace row 1?
ahh, thank you
the goal is to zero out the values in each column below the pivot
in general, for some arbitrary elementary row operation, r1+r2 = r3, and I replace one of the rows with r3 to make my matrix more simple
if that makes sense?
Exactly
ya np
now I have a question for the room
I'm trying to think about matrix inverses when you have non square matrices
Like if A is 8x3 and B is 3x8 and you're trying to make them so AB is I_8
And I know you can totally do that via svd and everything
But now I have to try to do min | I_8 - f(A f(B)) | where f is a nonlinearity and the minimization is via gradient descent
And the optimization tends to get stuck at a lot of different local optima and just generally act badly
So I'm thinking like, if B has rank 3 at most, then AB has to be a 3d subspace of R8 right? Because the only vectors that can get projected into R8 via A are coming out of B which has the image R3 best case
So then isn't AB singular? How does that affect the optimization? How do the nonlinearities affect the whole problem? I know that if for example your hessian is almost singular, gradient descent goes poorly, and I have the intuition why, but I'm having trouble reaching the same sort of understanding of why it might be hard to solve the min problem above

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Someone tell me how the area that these two lines form is not 12.
Base is 6, height is 4, tell me how the area is supposed to be 7.5 and not 12.
The 7.5 is probably about the area enclosed by the two lines and the x and y axis in the first quadrant
Where do you mean?
this one
Yea that
So triangle formed by the blue line - the small area of the red and blue line on top?
that's not really a triangle
You get my point
i do
good thanks
I'm involved too!
yw
(uh, what)

Mathematics Stack Exchange
Please give me some ideas! Thank you for your help.
@ember zenith I would try representing x in the u basis to try to get a simple matrix for A
Or even better, use u as the input basis and v as the output basis
what's even the difference between algebra and linear algebra?
in a plane (r3) u have Ax +By +Cz=D
what does the D represent
on a image
Ax+By+Cz is the planes normal
@languid gale linear algebra is the study of finite dimensional vector spaces and linear transformations between them, (abstract) algebra studies all kinds of different structures (not just vector spaces)
i guess regular algebra is just the study of calculations
ah ok thanks
Is there like a point of using cramer's rule?
It seems as tedious if not more to use cramer's instead of just subbing
@ionic island it gives an explicit solution to a system of linear equations. I remember it being theoretically useful in that I've seen the solution it provides being used to prove other statements. Also you can easily program a computer to calculate the solution to a system since the rule only relies on taking determinants, which is very easy to program. Though I'm sure there's more efficient algorithms which give a solution, though they're likely more complicated
If you have a determinant finding algorithm, you have an equation solving algorithm.
But yeah, row reduction is faster.
Determinants uwu
multilinear algebra 
multilinear algebra is cool
ultralinear algebra 
mega-ultra-fabulous-deluxe++-golden-collector-edition-linear algebra
Let $C$ be a curve of order 2 in $\mathbb R^2$, i.e., the solution set of a 2nd degree polynomial equation of two variables x and y.
Let $T : R^2 \to R^2$ be an invertible linear transformation. Show that $T(C)$ is again a curve of order 2.
LiberaVeritas:
Intuitively, T is a bijection so it preserves degrees of freedom
I'm not sure if I agree with the definition of 2nd order functions
Lines can be dependent on two variables, would that mean they're 1 or 2 dimensional?
do we assume standard inner product and solve? or is there a way without assuming that?
i think that will hold for any complex inner product
ok how
well a complex inner product needs to be:
- positive definite
- conjugate-symmetric
- linear in your favourite argument (first if you're a mathy, second if you're a physicist, it's just a convention but you have to pick one)
ok
you need all three properties to prove that x nonzero and ||x+y|| = ||y|| implies Re(<x,y>) < 0
||isthishidden||
||yes, double pipes means spoilers now||
And yeah it seems like that is quite obvious
i am of course interpreting the norm ||-|| to be induced by the inner product <-,->
Me too
Otherwise how would that makes sense
Wait it is really simple lol
It holds for every kind of inner product
yeah, i noted that above
ok so for positive-definite: how does it work for complex numbers? what does it mean for a complex number to be 'positive' ?
the standard interpretation is that <x,x> has to be a nonnegative real
Any norm is like P -> R+
and it equals zero iff x is zero
oh <x,x> is real?
that's what positive-definiteness means for a complex inner product yeah
Also any inner product, too
at least, under most conventions
Norms are defined to lie on real numbers, too.
wtf. in my textbook it just says <x,y> returns a scalar (basically an element of any field).
but apparently in the special case <x,x> is a positive real. (if x is not the zero-vector)
??
well, usually when they say scalar they mean specifically the field your v.s. has as its field of scalars
Especially because it is a norm
Maybe some norm is going to a field
But it's going to have a notion of inequality
>=0
but the entire inner product, as a function V x V -> F, needs to satisfy the three properties i noted
Yep
and the positive-definiteness requires that <x,x> be a positive real for nonzero x
(And usually F is Z or R unless explicitly specified)
so regardless of whatever the field the vector space is over, when we take <x,x>, it returns a real?
weird
No
It returns a field where inequality is defined
That's what norms are
Iirc this is related with distances as well
Since ||a||+||b|| >= ||a+b||
ok so in my textbook they define norm of x to be sqrt(<x,x>) . the only way this makes sense is that <x,x> is a real then
Yep
whenever the field is the reals or the complexes, posiive-definiteness means what i've said here
when you're working over other ordered fields you can try to use the order and it'll probably work out
but then what is sqrt() of an element of that ordered field then (norm) ?
when you're working over a not ordered field you can sometimes have some notion of inner product but it usually forgoes positive-definiteness
if a field is ordered, then is sqrt() defined on it?
no, it would have to be like quadratically complete or whatever
And it doesn't have sqrt
which amounts to "sqrt is defined"
also what do you mean by Z, abastro
because that usually refers to the integers
whatver im just gonna assume <x,x> is a real, for the purposes of my course
usually if sqrt doesn't exist you don't use the norm as much as you use the norm-squared
because it satisfies almost all the same rules
it's just convenient to toss the sqrt in when you're working with reals or complexes because then it coincides with our intuitive notion of length
Yep
so under (e) under INNER PRODUCT PROPERTIES we see that there are 2 versions given: one for real scalars, one for complex scalars
so i dont think assuming <x,x> is real is appropriate
(otherwise they would have just stated the real case)
my tb considers the scalar to be complex numbers
You can easily deduce that <x, x> is real, though
how
it's equal to its conjugate
Let's say I have a complex number z, and it equals its own conjugate...
Vsauce music starts playing
hey guys michael here for Vsauce. Is layovah's linear algoobra textbook retarded? Let's find out
nah seems it was a misconception of mine
it makes sense to still state the two cases
for (e)
one case is that the field is R. other is C.
in both cases <x,x> returns a real
but it the way to arrive at the stated property <x+y,x+y> differs in both cases
since <x,y> does NOT equal <y,x> when field is C.
that's why it is careful to say "in the real case"
<x,y> will equal <y,x> when <x,y> is real
thanks for the help guys
might be prudent to note that the RHS becomes a negative real because x is nonzero
yup will edit and refine
but other than that, you're gucci
👍
is anyone able to help me out with this? im so bad with vector spaces 😢
the circle around the + and * are just to indicate vector addition and multiplication
to do the first part, take two elements of V and add them and see if the result is in V again
an element of V looks like (x,1)
so you can take two elements, (x,1) and (y,1) and try to add them
and see if the result looks like an element of V again
Would this be the correct notation to define V
V = { (x,1) | x,y e R}
I dont understand what it means by set of ordered pairs of (x,1) then to define (x,y)
these operations are something you can do to any ordered pairs if you wanted
but we want to check how V behaves when it uses them
the results of these operations might land in V or they might not, you'd have to check
so it states (x,y) + (x',y') = (x+x', yy')
so the addition of the y components of two vectors have to equal their... multiplication?
yep
Sorry if im asking a lot of questions its just like really abstract to me
What exactly is the point of the whole ordered pair (x,1) again?
what does it serve in the problem...
Is an ordered pair the same thing as a vector
vectors are elements of a vector space
we do not know that V is a vector space
so we can't call them vectors yet
V is a subset of all ordered pairs
specifically, it's the ordered pairs where the right side is equal to 1
Then didn't your fundamental example of two vectors lets say u=(1,2) v=(3,4) yielding (4,6) prove that 6 != 1?
well (1,2) didn't come from V
i just pulled it out of my ass
you need to check, if $(x,1),(x',1) \in V$, is $(x,1)\oplus(x',1)$ also in $V$?
tubular:
Am I correct to say its closed under addition for all ordered pairs of (x,1)? because for all numbers x, (x,1) + (x', 1) will always equal (x+x', 1) ?
if the second part of the ordered pair can only be 1 @maiden dagger ?
then (x+x', yy') is always sufficede
becuase 1*1 is 1
However it cant be closed under scalar multiplication where c(x,y) = (cx,cy) because take c=2 for instance, then we have (2x,2*1) and that falls out of the ordered pair (x,1)?
because now we have (cx, cy) where cy != 1
That is, for all scalars C that are not 1
It made sense to me for a second, but now that I think about it, wouldn't (x,1) oplus (x',1) = (x+x', 2) ???
Therefore.... not 1*1? and not closed under addition?
I felt like I had it for a moment then lost it
I think its just weird how the professor can define (x,y) + (x',y') to equal (x+x', yy')
I know you can basically define anything on an abstract level but hm.
I understand. No worries.
Thanks for your help @maiden dagger I understand that you can arbitrarily define addition in any way
tubular:
kind of a general question,. are systems of linear equations useful in real life problems only if there are unique solutions?
Not necessarily? I am not sure if I am understanding your question correctly @placid oracle but you can form a system of equations with free variables (infinitely many solutions) that can be used to describe many real world models
can i have an example ?
Yeah, this pic right here
you have water flowing between pipes and meeting in a network
if you try and solve this, you'll find that you are unable to find a unique solution. There are 5 variables and only 4 known values
i dont rlly know network flow but i just got it for some reason.. if one is free it could still work
thank u , i was confusing myself
yes
This could be the model of a water pipe network, and its a useful application in real life because one can alter the free variable as they please (maybe according to costs, output needed, etc)
So it has infinitely many solutions, but in the end it is still useful.
that makes sense! thank u sm 😄
Np 😃
@little cairn is this true? In a network flow problem with m branches and n nodes, the flow rates through at least m−n branches must be known in order to study the system using Linear Algebra techniques.
I am not sure, that seems like a bit of a technical approach, but using the above example it would appear to be true
we have 9 branches and 4 nodes, 9-4 is 5 upon which we have 5 unknown flows and 4 known flows
So it might be a contradiction? Although like I said I do not entirely understand what it means to "study the system using linear algebra techniques"
because we can study the system using linear algebra techniques, despite having only 4 known flows.
In other words, it is saying we must know at least 9-4=5 known flows to study it using linear algebra, however, it is clear by the problem above that we can still represent the system as a set of linear equations with a free variable.
Despite only knowing 4 branch flows, not m-n (5)
thats what i was going for too, the "linear algebra t4echniques" part is kind of a weird way to phrase it
@little cairn dont you mean it appears to be false?
After thinking about it, Yeah
At first I thought true but upon further inspection, it could be interpreted as false if you consider the use of free variables as "linear algebra techniques"
Yeah it seems a little vague
@little cairn I think the directions of the arrows might give information.
is there a vector space that doesnt have a span ?
the span of all vectors in the vector space is itself
if you meant “basis”, that’s trickier. you need the axiom of choice (easiest in the form of Zorn’s Lemma) to prove that every vector space has a basis
there are many vector spaces where you can’t “write down” the basis
ah yes, maybe i used the wrong vocabulary cus there's the theorem of the basis existence that says "all vector spaces admitting a finite span admits a basis"
yea, that’s much more straightforward
not all vector spaces can be spanned by a finite set though
easy example would be the space of all polynomials
which has a basis (1, x, x², x³,…) but it’s infinite in size
EZ Clap
how to find nonsingular change of variables??
How do you relate the number of pivot columns to the dimensions of a matrix if all the columns are linearly dependent
for ex an 8x6 matrix, how many pivot columns does it have>?
That is indeed false. However, it DOES mean that detA ≠ 0
@broken girder it's literally false for 1x1 matrices
How do i figure out if this is true/false?
so
counterexample
do you know def of linear dependence
@placid oracle
also of a vector and scalar and vector space
When Ax=0 only has the trivial solution
@placid oracle the book def
do you know what that means
also
that's not the entire definition
I'm guessing you don't know what that means
not really
Ok so that would make that statement false?
no not anything. A set of vectors aren't linearly independent if you can write one of the vectors as a linear combination of the others. e.g.
(1, 0, 0) (0,1,0) (2, 0, 0)
2(1,0,0) = (2,0,0) therefore those vectors are not linearly independent
Forgot about that, but still makes sense. ty
np
same topic...
its tru
z is not in the span of {u,v,w} which is the same as saying x_1 u + x_2 v + x_3 w can never equal z which is equivalent to saying that z cannot be written as a linear combination of {u,v,w}. A set of vectors are not linearly independent if you can write one of the vectors as a linear combination of the others. You cannot do that here
Ok thats much simpler than I thought .. I knew how to do it once you realize that z cannot be written as a linear comb of the vector
that reasoning suffices, but to tie this back to the whole Ax = 0 thing, suppose that z could be written as a linear combination of {u,v,w}. Then you have
x_1 u + x_2 v + x_3 w = z, x1, x2, x3 non zero
which means you have x_1 u + x_2 v + x_3 w - z = 0 @placid oracle
hmm
makes sense
i just sometimes have trouble making sense of span in these questions
One more thing, its related and just clarifying: If the columns of a m x n matrix are linearly independent, then the number of columns is greater than the numbers of rows, right? Since if a set contains more vectors than there are entries in each vector, then the set
is linearly dependent.
i think you have it the other way around
i mean dependent**
ohwait i read that wrong lol
no i wrote independent instead of dependent mb
easier to rewad^
saying its false^
yeah its false. You can have mxn matrices with n<=m that have linearly dependent columns
ok good, thanks for ur time 😄
np c:
Hey uhh I was wondering why
when they rewrote it as a linear combination
it's a 4x1 vector
when there's only 3 variables
because usually if you wrote out the general solution wouldnt you rewrite everything as a linear combination of the free variables
i just don't get what they wrote there :0
oh wait nevermind
i got it
i don't think there is any reason why you can't do that. I'm not sure why he did that though
It's just the classical shit to test you on your basic knowledge of vector spaces : take a vector space you know, change some op, is it still a vector space ?
yes but u = ( u1 , u2 )
and when we multiply u by scalar it will be ku = (ku1,ku2)
not sure why there is zero in ku2
the operations aren't necessarily the classical ones
he defined scalar multiplication differently
but yeah it's pretty abstract when you're just starting
👌
how the equation will be when converting to system of equation
1x-2x+3x or 1x-2y+3z ?
When I see that, I think of rotating the vector counter-clockwise, and scanning it "down" the matrix
x - 2y + 3z
2x - 4y + 6z
3x - 6y + 9z
Note if you carry that out like a matrix multiplication, that's what you get as a vector
thanks, that helped me
could bisectors possibly help here?
can someone please explain this to me?
please hep mee
am i suppose to factorise ?
but it becomes too complicated
quadratic forms are very closely related to symmetric matrices
every quadratic form can be written as $x^TAx$ for a symmetric matrix $A$
tubular:
in particular, the form $q = \lambda_1y_1^2 + \lambda_2y_2^2 + \lambda_3y_3^2 + \lambda_4y_4^2$ can be written $\begin{bmatrix} y_1 \ y_2 \ y_3 \ y_4 \end{bmatrix}^T \begin{bmatrix} \lambda_1 \ & \lambda_2 \ && \lambda_3 \ &&& \lambda_4 \end{bmatrix} \begin{bmatrix} y_1 \ y_2 \ y_3 \ y_4 \end{bmatrix}$
tubular:
and if there are off-diagonal terms you wanna split them in half
anyway, so what's happening in this question is that you want to diagonalize the matrix corresponding to the form they wrote out
@novel palm does that help?
what does diagonalization do?
@ember zenith
Still looking for it?
nah im good
just forgot how it related to initally diagonal matrices
you know like bisecting the photosynthesis
Hello
http://homepages.inf.ed.ac.uk/rbf/CVonline/LOCAL_COPIES/AV0405/REDSTONE/AxisAngleRotation.html
in the example provided, it writes ([a, b, c]) ([d, e, f] · [g, h, i]) (1 - cos θ), where I replaced number with alphabet to avoid confusion
is it equals to this?
[a * (dg)(1 - cos θ), b * (eh)(1 - cos θ), c * (f*i)(1 - cos θ)]
AxisAngleRotation
how do you calculate (x * n) in the last part?
the dot product of two vectors should be a scalar
hi, i'm struggling to visualise linear algebra, and concept like vector space
How did you do to visualise those ?
In this pic how does he arrive at the line with x3 and x4 from x1 = and x2 =
i dont understand how he factorizes
he multiplies these vectors by x3 and x4
and you kinda add them side by side in a sense
they have to be equal, as you can see in line 3 theres x3 = 1* x3 + 0* x4
same with x4, so its not listed in linear system on the right
yes that i understand but how does he do from x 1 = -3x3 - 2x2 and x2 = 2x3 + x4
to arrive at the equality below
x1 is in first row, so you take first row from vectors on the other side
the first row in first vector is just -3 and in second one -2
multiplied by x3 and x4 respectively you get x1= -3x3 -2x4
row by row
second one you look 2nd row of vectors from RHS and set it equal to x2
i gonna send u an other pic
EZ Clap
ye waht about it?
WutFace
encore un français
ill let baguette onion answer your question
ui
oui
ya comme qui dirait un ptit problème dans leur truc
ok en gros je comprends pas comment il arrive à factoriser x et y de l'equation u = (x,y,-x-y)
normal c'est faux ptdr
vas-y qu'est-ce que tu mettrais?
bah en gros je prendrais deux vecteurs qui verfient u et qui soient libres par exemple (2,3 -5) et (7,9,-16)
Vu qu'ils sont libres ils génèrent automatiquement E d'où le fait qu'ils soient une base
ça marche ui
mais en essayant d'appliquer la même démarche que la leur, tu remplacerais (1,-1,0) et (0,1,-1) par quoi?
pas forcément besoin de se casser la tête à ce point
je comprends pas leur demarche justement
c'est quoi la méthode générale pour arriver à une combinaison lineaire de x et y ?
enfin là c'est plutôt obvious $$\begin{bmatrix} x \ y \ -x-y \end{bmatrix} = x\begin{bmatrix}1 \ 0 \ -1\end{bmatrix} + y\begin{bmatrix}0 \ 1 \ -1\end{bmatrix}$$
ah
emeric75:
oui la je comprends
au lieu de chercher deux vecteurs libres de nulle part, autant essayer de suivre ce qui est suggéré par z
mais dans un cas plus général je sais pas si je saurai refaire
le plus souvent ça se limite à ça (avec éventuellement réarranger certains vecteurs en amont dans certains cas)
et puis bon le cas général c'est comme tu l'as fait au début
se casser la tête pour sortir une famille libre et génératrice 'ex nihilo'
👌