#internals-and-peps
1 messages · Page 157 of 1
Yes, but not just that. It contains details about how most of the major components of the interpreter work, because contributors need to know that before they can start making contributions that touch those components
https://devguide.python.org/garbage_collector/ gives more detail than you could ever want to know about how the garbage collector works, for instance
It's sad there are no lectures online that I could watch... In any case, thanks for the advice 🙂
now I'm curious what kinds of questions wouldn't be appropriate in a public chat....
like asking for a copy of a paid book
i see....

i mean there's a shortened but still helpful realpython that pulls excerpts from the actual book
.realpython python internals
Here are the top 5 results:
CPython Internals: Paperback Now Available!
CPython Internals Book
Memory Management in Python
Python Descriptors: An Introduction
Python Class Constructors: Control Your Object Instantiation
Click the links to go to the articles.
Here are the top 5 results:
Your Guide to the CPython Source Code
Socket Programming in Python (Guide)
Inheritance and Composition: A Python OOP Guide
Python Type Checking (Guide)
Build a Command-Line To-Do App With Python and Typer
Click the links to go to the articles.
The first one
>>> [hash(-i) for i in range(100)]
[0, -2, -2, -3, -4, -5, -6, -7, -8, -9, -10, -11, -12, -13, -14, -15, -16, -17, -18, -19, -20, -21, -22, -23, -24, -25, -26, -27, -28, -29, -30, -31, -32, -33, -34, -35, -36, -37, -38, -39, -40, -41, -42, -43, -44, -45, -46, -47, -48, -49, -50, -51, -52, -53, -54, -55, -56, -57, -58, -59, -60, -61, -62, -63, -64, -65, -66, -67, -68, -69, -70, -71, -72, -73, -74, -75, -76, -77, -78, -79, -80, -81, -82, -83, -84, -85, -86, -87, -88, -89, -90, -91, -92, -93, -94, -95, -96, -97, -98, -99]
why is the hash of -1 not identity?
hash values of -1 are used to indicate errors
https://github.com/python/cpython/blob/main/Python/pyhash.c#L4
Python/pyhash.c line 4
All the utility functions (_Py_Hash*()) return "-1" to signify an error.```Anyone have opinions on this: https://peps.python.org/pep-0675/. It felt a bit weird to me as it's sort of different to what I'd usually expect a type checker to do, but I guess it makes sense. Are there other cases where type checking is used for things other than just checking types?
Python Enhancement Proposals (PEPs)
Depends on what you mean by "type" 🙂
list[int] and list[str] surely refer to objects with the same class, for example.
Also, just Literal on its own.
Some things are used for control flow -- e.g. NoReturn
LiteralString just means that the data is never user-controlled right?
This seems like a funny thing to put in a type system, as interesting of an idea as it is
Literal is different because it is a refinement of the type
There are valid cases when you want to construct SQL strings
so this type seems like an arbitrary restriction for minimal or no benefit
the correct solution imo is to not accept strings, or to emit a warning for accepting strings, and instead require a SqlQuery object much like httpx.URL (and the yarl/hyperlink equivalents)
or to have a dsl query builder
Yeah I think I agree
LiteralString is also a refinement of str, it just propagates its type through some operations
It behaves much like a const modifier
Yeah I was really surprised that this was accepted
I guess one good but completely unrelated use case is when you want to bind a type variable to a literal string
Like, you want Route("foo", foo_h) to be inferred as Route[Literal["foo"]]
I suppose it has a very narrow use case within an application to indicate that a particular variable must never be constructed from user provided input
But it seems like something you should never put into a library interface
And even within an application, the modest improvement in "injection safety" will probably just come back to bite you in the ass when you need to refactor
TIL type hints can be used as placeholders to do this kind of binding. Or is it a bug?
def test():
i: int
def test2():
nonlocal i
i = 1
test2()
print(i)
works with global too
thats clever. the i: int gets parsed into the AST (so the scoping rules apply to it) but it doesnt yield any bytecode
tbh I couldn't figure out if:
1.) this will make us have to replace all str typehints
2.) this is somehow a replacement for Literal
or
3.) if the other do not apply, what the actual use/purpose is. The way this was presented in the mailing list, sounded like they just added a massive important feature that was missed in python to the stdlib.
From what I gather from the answers here, is this is a niche feature and most either never noticed they missed it or think the type system is the wrong place for it.
How is this different to about 50 other feature request that where rejected for only benefiting a small part of the user base?
I was surprised as well
but I guess it doesn't really require any changes to Python, only a new type-checking rule
1.) this will make us have to replace all str typehints
No. Where did you read that?
2.) this is somehow a replacement for Literal
not really, it's just a way to signal: "this has to be a string literal, not an arbitrary computed string"
What's the difference between nonlocal and global
the first one needs to be from a local variable outside of a function/class inside another function/class and the second needs to be from a global variable
yes
I don't like it, but I also don't like type hints in general.
Until now, type hints told you what the function could work with, as in "I take a number as an argument". These claims might sometimes be wrong (e.g. a function thinks it can only accept integers when it also works with floats), but that's a different story.
This PEP introduces the concept of "the function will definitely work with this type, but wants to educate you", which makes me a bit uncomfortable. In the only example given (protecting against sql injections), there's legitimate usecases for using dynamic strings (when the dynamicness doesn't come from user data, but is more complex than just a concatenation of literals).
I don't like it because it is arbitrarily specific, why not extend that to allow all literals to be expressed this way? I mean they mention why, I just disagree
Otherwise I feel like this should have been just a byproduct of having Literals in the first place, not a new feature
I really hope type checkers add an option to ignore it, as pointed out there are many reasons to use dynamic strings, like one thing I can think of is data from an api, like there are many trusted sources of dynamic strings :p
Same as with any other type lol, either cast or type-ignore
I just realized, this would type check, right?
def to_literal(s: str) -> LiteralStr:
"""return original string untouched"""
result = ""
for c in s:
if c == "\0":
result += "\0"
# ...
return result
Lol
Data from a remote API run by someone else is definitely not a trusted source :)
But otherwise yes
For example, there isn't an idiomatic way of constructing HTTP paths without injection vulnerabilities
So I guess it's really just about SQL injection tho?
Also, what is the intersection of people who use type annotations and people who don't know what SQL injection is?
given that automatic type checking is built-in to plenty of ides/extensions, a lot of people
ofc, discord would 100% try and use their api to inject stuff into my db 🙃
It doesn't have to be malicious. Maybe it's a bug, maybe just an unintentional change.
Or maybe the API is relaying user-influenced data, in which case it might be malicious, but the API is not at fault
fair, ofc if you know the results of the api are user-generated you should treat it as any other user input,
maybe an api was not the best example, but there are many other sources that you could consider to trust.
Yeah, stuff like whitelisted columns
Although an argument could be made that maybe you should consider a query builder if you are doing stuff like this
Well, nobody seems to bother with that with HTTP query paths
Read that no where, but these were my thoughts as I read the pep and tried to make sense of it in light of enthusiasmus of the mailing message that presented the pep.
Also the last message of that mailing list message sounded like it will break stuff at least for a few libraries.else i cant explain that obtuse last sentence.
Whole thing just confused me as, like many said, it has nothing to do with type checking, but is implemented via it.
Really careful question:
-Removed stupid speculation-
Whole thing just confused me as, like many said, it has nothing to do with type checking, but is implemented via it.
Both the concept of a literal type (i.e. 'compile-time-compatible') and mutability are parts of the type system and something many other statically typed languages have, so I don't really see a way to agree with this. The way it has to be expressed in Python is albeit fairly strange, due to type hints being bolted onto the language 30 years in hindsight.
Could this have been a pet project of a current council member?
Lots of the changes into Python typing - maybe in general - tend to be
Maybe you could raise your concerns on the mailing list? I doubt anyone here can really answer you
Personally my only gripe with this PEP is that for some reason the author seems to have reached the conclusion that this is not widely usable enough to expand to all literals, and should only be available for string literals.
Actually there is a precedent for this feature - TypeScript lets you specify a type that only a literal string will satisfy. Although it is not a separate construct but a tricky combination of existing mechanics
Yeah your right, was stupid speculation
files: list[pathlib.Path]
for f in files:
json.load(f.open())
does this leave every file handle open? if I remember correctly, it should get closed in the __del__ for whatever pathlib.Path.open returns, which should get called pretty quickly since a reference is never created for it in this scope.
in cpython yes, f.__del__ will be called when the reference count hits 0
in pypy, i dont think there are well-defined semantics
I've never used not-cpython, so it's just as well.
mind that you can use read_text and pass that to loads instead of the open
With read only operations I wouldn't really say it's horrible to not use the context manager, but then there's not much of a reason no to
!d contextlib.ExitStack
class contextlib.ExitStack```
A context manager that is designed to make it easy to programmatically combine other context managers and cleanup functions, especially those that are optional or otherwise driven by input data.
For example, a set of files may easily be handled in a single with statement as follows:
```py
with ExitStack() as stack:
files = [stack.enter_context(open(fname)) for fname in filenames]
# All opened files will automatically be closed at the end of
# the with statement, even if attempts to open files later
# in the list raise an exception
i think this would be the recommended way to solve that problem
why? You don't need multiple at the same time
you could do ```py
with ExitStack() as stack:
for f in files:
json.load(stack.enter_context(open(f)))
well most of the time you can do this:
for f in files:
with open(f) as fp:
json.load(fp)
you only need the stack if you want them all concurrently open
fair enough
that's what numerlor was saying, i think
and there's an upper limit on the number of files that can be open concurrently. The ExitStack approach would most likely fail if there were more than 1024 file names in the list
empty_list = []
for _ in empty_list:
...
# continues on after loop
...
Does Python short-circuit the iteration protocol when it sees the empty built-in, or does it call the iterator and catch StopIteration? There'd be arguably unecessary overhead from the exception system, but it would be more consistent.
It doesn't special case that.
!e ```py
import dis
dis.dis("""
empty_list = []
for _ in empty_list:
...
""")
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | 2 0 BUILD_LIST 0
002 | 2 STORE_NAME 0 (empty_list)
003 |
004 | 3 4 LOAD_NAME 0 (empty_list)
005 | 6 GET_ITER
006 | >> 8 FOR_ITER 2 (to 14)
007 | 10 STORE_NAME 1 (_)
008 |
009 | 4 12 JUMP_ABSOLUTE 4 (to 8)
010 |
011 | 3 >> 14 LOAD_CONST 0 (None)
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/jatofeliju.txt?noredirect
It unconditionally calls GET_ITER and FOR_ITER.
Anyone seen this? https://overreacted.io/algebraic-effects-for-the-rest-of-us/
They’re not burritos.
It soooooo cool!
Let me Tl;Dr it before you read the link:
Imagine reversible exceptions
So like- something went wrong and you're not sure how to handle it so you raise an exception. The user catches the exception and does something such that you can now continue running exactly where you were before!
You could have reconnection logic up to the user, for example instead of having a callback (un-pythonic because of Python not having multi-statement anonymous functions) passed in you can now use these and let the user determine whether to reconnect and when
ON ERROR RESUME NEXT
YESS!!!
flashbacks
Yeah algebraic effects are really promising
where can you find examples of when a certain bytecode instruction is used
like where can I find where the bytecode op ROT_TWO would be used in real code
Doesn't ROT_TWO swap the top two positions in the stack
From what I can find, it seems to be used when you swap values```py
a, b = b, a
@spice pecan :white_check_mark: Your eval job has completed with return code 0.
001 | 4 0 LOAD_FAST 0 (b)
002 | 2 LOAD_FAST 1 (a)
003 | 4 ROT_TWO
004 | 6 STORE_FAST 1 (a)
005 | 8 STORE_FAST 0 (b)
006 | 10 LOAD_CONST 0 (None)
007 | 12 RETURN_VALUE
Two loads, rot two, two stores
interesting, didnt know this was special cased
doesnt happen for [a, b] = [b, a] though 
that's because you're making a list on rhs
I think it'd still work with just [a, b] on lhs
!e ```py
from dis import dis
dis('[a,b] = a,b') # I sure do hope I can pass strings
@spice pecan :white_check_mark: Your eval job has completed with return code 0.
001 | 1 0 LOAD_NAME 0 (a)
002 | 2 LOAD_NAME 1 (b)
003 | 4 ROT_TWO
004 | 6 STORE_NAME 0 (a)
005 | 8 STORE_NAME 1 (b)
006 | 10 LOAD_CONST 0 (None)
007 | 12 RETURN_VALUE
Yeah, it's because of the list. Would probably also fail if you did tuple((a, b)) on rhs
Very interesting. When I have a bit of time again, I'll try to build a PoC in Python
there it would have to lookup the name "tuple" too tho
yeah, any deviation from tuple literal on rhs would probably break it
Could write something to look through a module's bytecode for a given instruction and then output the location in the source code
Not sure it would be massively helpful but would be an interesting exercise
ohh
it would be quite helpful for me, trying to write a bytecode guide but i can't think of examples for some of them :P
!e
import dis
dis.dis("a, b, c = c, b, a")
@surreal sun :white_check_mark: Your eval job has completed with return code 0.
001 | 1 0 LOAD_NAME 0 (c)
002 | 2 LOAD_NAME 1 (b)
003 | 4 LOAD_NAME 2 (a)
004 | 6 ROT_THREE
005 | 8 ROT_TWO
006 | 10 STORE_NAME 2 (a)
007 | 12 STORE_NAME 1 (b)
008 | 14 STORE_NAME 0 (c)
009 | 16 LOAD_CONST 0 (None)
010 | 18 RETURN_VALUE
i see
though in general i'm guessing there aren't places where you can find examples of all the bytecode instructions
interestingly it seems the rot instructions are being replaced with a single swap instruction https://github.com/python/cpython/pull/30902 (ok maybe not interesting idk you decide)
that's nice to hear, the rot names were confusing too and there are three separate ones afaik
or maybe just two separate ones
I might give it a go at some point if someone else here doesn't first 😄, can't right now though.
yea it sounds like a great idea tbh, helpful for debugging certain parts too to some extent
is this a bug in PDB? i'm so confused
(Pdb) !from bson import DBRef
(Pdb) p DBRef
<class 'bson.dbref.DBRef'>
(Pdb) !curs = coll.find({'subject': {'$in': [DBRef('group') for i in group_ids]}})
*** NameError: name 'DBRef' is not defined
kind of. it's because of the comprehension, which has its own scope
what do you mean by that?
a lot of bytecode changes are happening in CPython in python 3.11
for example the BINARY_* operators are being replaced with BINARY_OP
Yeah, they seem to have a lot of potential
I don't know of any languages where they're used besides a few explicitly designed for experimenting with them though
I think Koka was one?
the killer application i see is to streamline mixed async/sync code, but that's about it..
(which might be worth the trouble actually)

Stack Overflow
In debugging my code, I want to use a list comprehension. However, it seems I cannot evaluate a list comprehension from the debugger when I'm inside a function.
I am using Python 3.4.
Script cont...
result = raise Effect()
...
try:
do_thing()
except Effect:
continue with 42
Possible syntax without new keywords
continue with that is actually a really smart way of reusing the current keywords, it is like it was meant for this 😂
Although idk about reusing except since this would definitely be different then an exception
pretty much, it's also similar to CL conditions/restarts
I mean, it seems pretty structured to me, instead of propagating an exception you are propagating a something = yield x
there are some interesting troubles with this, for example, say I have a finally block, and in the corresponding try: an Effect arises. The finally cannot run until the event is handled and we know whether it got restarted or the call was abandonned. It is probably fine to do it like that, but I can imagine a whole new class of counter-intuitive behaviours once flow gets more complex
!e ```py
from fishhook import hook
@hook(int)
def add(_, ):
print( ,_)
print((4) + (2))
@lethal magnet :x: Your eval job has completed with return code 1.
001 | 4 48
002 | Traceback (most recent call last):
003 | File "<string>", line 4, in <module>
004 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 229, in pwrapper
005 | hook_cls_from_cls(cls, type(f'<{itos(id(cls))}>', (P,), body), **kwargs)
006 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 186, in hook_cls_from_cls
007 | update_subcls(subcls, pcls)
008 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 154, in update_subcls
009 | hook(cls, is_base=False)(body=attributes)
010 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 229, in pwrapper
011 | hook_cls_from_cls(cls, type(f'<{itos(id(cls))}>', (P,), body), **kwargs)
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/ewohuvedug.txt?noredirect
whats wrong with that?
it returns none, breaking any integer addition
!e ```py
from fishhook import hook
@hook(int)
def add(_, ):
print( ,_)
return _ + __
print((4) + (2))
@lethal magnet :x: Your eval job has completed with return code 1.
001 | 4 48
002 | 4 48
003 | 4 48
004 | 4 48
005 | 4 48
006 | 4 48
007 | 4 48
008 | 4 48
009 | 4 48
010 | 4 48
011 | 4 48
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/hebumizoda.txt?noredirect
o.O
that's recursive
yeah you're calling the function itself
!e
from fishhook import hook
@hook(int)
def __add__(_, __):
print(_ ,__)
return _ - (-__)
print((4) + (2))
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
001 | 6 48
002 | 9 48
003 | 8 48
004 | 6 48
005 | 7 48
006 | 5 48
007 | 3 48
008 | 2 48
009 | 9 48
010 | 0 48
011 | 2 48
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/diqatepati.txt?noredirect
o.O
well.... integers are added a lot, I guess
huh
!e ```py
from fishhook import hook
@hook(int)
def add(_, __):
return _ - __
print((4) + (2))
@lethal magnet :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 4, in <module>
003 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 229, in pwrapper
004 | hook_cls_from_cls(cls, type(f'<{itos(id(cls))}>', (P,), body), **kwargs)
005 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 186, in hook_cls_from_cls
006 | update_subcls(subcls, pcls)
007 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 154, in update_subcls
008 | hook(cls, is_base=False)(body=attributes)
009 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 229, in pwrapper
010 | hook_cls_from_cls(cls, type(f'<{itos(id(cls))}>', (P,), body), **kwargs)
011 | File "/snekbox/user_base/lib/python3.10/site-packages/fishhook/__init__.py", line 24, in itos
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/poxoqexogi.txt?noredirect
i like this
pretty much all algebraic effects are, yes
it's still better than goto imo
it's still structured; it just makes implicit control flow of error handling explicit
...and then generalizes it, which is the part that might make some people uncomfortable
but much like with nonlocal, you can make a big fat mess with it, but you shouldn't and don't have to
where do you see the most value of the construct?
in a program with effect handlers, most continuations would be one-shot or zero-shot. heck, some implementations of algebraic effects don't even support multi-shot (but largely for performance reasons)
it's a totally different way to write programs, especially in languages with strong static type systems that want to promote functional purity
it basically replaces monads
like you can still use monads of course, but monads have some serious deficiencies that effect handlers do not have
so it lets python become more functional where it's beneficial
in a dynamically typed language, it's still valuable because 1) you get the lisp condition system as a subset, "for free", which is great; and 2) you can write almost your entire program in a kind of sans-io style
the (2) is a kind of extreme case which you normally wouldn't do in a dynamic language
eg. i have seen examples of people using lisp conditions to parse lines of text, and i don't like it
so yeah the main benefit is much much greater control over "conditions" and implementing non-linear flow control in cases where such a thing would be valuable
personally i dont see much benefit in python specifically, although being able to re-execute a failed computation without writing a while loop would be quite nice
sans-io?
the problem in a dynamic language is that if you use effects to write your entire program in sans-io fashion, there's no type system to guarantee that you actually even know the full list of effects that your program uses, nor that you are handling all effects at top-level
yeah, your program logic never does i/o
ah
instead, your program logic emits and receives a sequence of "events"
which are then handled by an outer layer
okay
so if you are writing a client library for some rest api, you could do it like this:
class ApiClient:
def __init__(self, api_key):
self.api_key = api_key
def fetch_foo(self, foo_id) -> ApiRequest:
return ApiRequest(
HttpMethod.GET,
f'https://api.example.net/foo/{foo_id}',
)
which is totally i/o-less
you are then free to write wrappers for any i/o and concurrency paradigm
e.g. asyncio, threads, trio, etc.
in some cases, like parsing a binary protocol, you want to implement your class as a state machine + a kind of "event loop"
class CoolProtocolParser:
def __init__(self):
self.state = ProtocolState.START
def handle_input(data):
...
where handle_input updates self.state as needed and emits requests for further i/o actions, e.g. "fetch the next 5 bytes"
ah I see, I misunderstood the thing
so your code is a loop between
-
doing whatever i/o action the protocol parser requested,
-
and then kicking some data back to it in order to advance the state and get the next i/o event
yeah I've done this with generators
yeah thats one way to do it
fwiw i have literally never found a good use case for generators that i couldn't refactor to use classes
i assume you are talking about "push-style" generators with .send
hmm.. how would you implement an FSM with effects?
doesn't it lure you into writing spaghetti code?
yeah you could write some pretty gnarly spaghetti code with this
on the other hand, it lets you separate the functionally pure state transitions from any actual i/o
i'll trust you on that one ^^
@do
async def point() -> tuple[int, int]:
await exact("(")
x = await integer
await exact(",")
y = await integer
await exact(")")
return (x, y)
assert point.parse("(3, -51)") == ("", (3, -51))
``` 🙂not quite the thing you're talking about, but yeah
that's fun. what happens if you await integer and the next character isn't an integer?
is this something you made up, or an existing parsing library?
tests/test_basic.py line 163
def test_point_with_do_notation():```both 🙂
the control is just never returned to the function, and the underlying parser returns None
although I guess I could get some nice things if I threw an exception instead, like asyncio.CancelledError
that's wild
presumably you could have it return some kind of ParseFailure object instead, with a line/character number?
but is it caught by the do wrapper? or is it exposed to the user?
it is thrown from point.parse
but ideally, I think, it should be thrown on the await
(so that e.g. you can do backtracking)
yeah that was what i had in mind
although backtracking is hard since you'd have to wrap it in a while loop or something
maybe you'd need a way to manually step backwards
@do
async def point() -> tuple[int, int]:
await exact("(")
try:
x = await integer
except InvalidInput:
step(-2)
...
but then it's no longer "declarative"
@paper echo hmm yeah I haven't thought that through. But forward-tracking will work 😄
although hmm, you could add a contract-breaking parser like goback("old_input") that would add to the string, not subtract
I haven't read that deep, but I was imagining that if an effect is uncaught the call that generated can have have some default behaviour - for example raising an exception if it can't continue
yeah, you can have a default handler for an effect
Python could raise exceptions maybe?
try:
result = raise Effect(...)
except UncaughtEffect:
result = None
Definitely looks odd to someone not aware of it, same could be said about the match statement though (pattern matching can be pretty advanced)
What advantages would this algebraic effect system have over Python's yield statement?
This also means that if the user didn't handle the effect, and the author doesn't catch the exception, it would propagate upwards and exit 👌 (considered an error)
How would this be redone with yield?
try:
result = yield Effect(...)
except UncaughtEffect:
result = None
Now how would you propagate it up?
although yeah, it would require you to go yields all the way down
So the difference would be that it would jump down the call stack?
Yup, you jump up without destroying the callstack and then jump down again
Exceptions for control flow already have a notorious reputation and this makes it two-way so I can't really fathom how this would work without being a massive mess
Something like...
@effectful
def foo():
try:
result = yield Effect(...)
except UncaughtEffect:
result = None
def bar():
try:
foo()
except Effect as ef:
ef.resolve(42)
``` I guess? Not sure how you'd _catch_ the effect though. Since a function could throw several of them\Plus it seems like a very strange cousin of the actor model
that makes me squirm a bit, i think that'd make reasoning about how the code flows really hard
I need this behaviour: ```python
class ShouldReconnect(Effect):
...
def handle_failed():
if (raise ShouldReconnect):
... # Reconnect
else:
raise ConnectionClosed()
def connect():
while True:
try:
...
except ConnectionFailed:
handle_failed()
def main():
try:
connect()
except ShouldReconnect:
continue with True
Yeah what if bar doesn't catch it, it should continue walking up the stack
What part of it? It's just an exception you can recover from (not, catch and retry, I mean catch and continue)
This seems like an absolute clusterfunk from a lifetime/ownership point of view
Of say, context managers and finally?
i suppose its not too different from generators or coroutines
Here:
def main():
try:
connect()
except ShouldReconnect:
continue with True
what if you need to run several consecutive effects on a single run? Like, what if connect() first raises Effect1, then later Effect2 etc.?
Or is there an implicit loop here?
Also your example is like the hallmark example of IOC
The loop is inside connect()
I don't think you need algebraic effects to solve it at all
Let me add an else clause hold on
Right but what if connect produces two effects?
At the same time?
no, after you've caught the first effect
it can ask for reconnection several times, right?
Yeah, so my except ShouldReconnect can run multiple times, yes.
the idea is that you either keep the effect handlers reasonably "local" to avoid exactly this problem w/ two-way spaghetti logic, or you use them as "global" handlers in order to push side effects to the fringes of your application in a purely functional language. basically you don't really need them in a dynamically typed effectful language like python
then you can just replicate it like so: py def main(): connect_gen = connect() for effect in connect: if isinstance(effect, ShouldReconnect): effect.proceed_with(True) with a decorator to wrap the original connect
Is this something that plays really well with a strong type system so it's ideal in a pure FP language
again, they were developed as a way to encode effects that doesn't use monads
yeah, exactly
Okay so it's probably incredibly unfit for Python, heh
if you know what delimited continuations are, they are basically typed delimited continuations
for example multicore ocaml introduced algebraic effects into ocaml in order to implement its async concurrency stuff
Is that the same as partial continuation?
Yeah so I'd add the decorator all the way up the chain?
yes, i think so
Okay, I see
you could apply it locally
def main():
connect_gen = iterate_over_effects(connect())
for effect in connect:
if isinstance(effect, ShouldReconnect):
effect.proceed_with(True)
and there are research languages like koka, eff, and effekt that explore the language design space around algebraic effect handlers. koka in particular looks like a language that real live humans might actually want to use at work
there are also implementations in haskell, notably alexis king has done a lot of work on modifying ghc itself (adding delimited continuations to its internals) to support better implementations of algebraic effects
its a really promising direction in PL design/research in my opinion
If I don't want to handle a particular effect (ignoring the fact that this is the main function) how would that look like?
seems like it has the potential to make pure functional programming a lot easier to use, no fucking around with abstract category theory just to read from a file
Hmm... right, that doesn't seem possible without adding yield to every function
but, well, people somehow live with adding await to every function 🙂
if this makes mixing async and sync code easier, i'm all for it, i don't care about purity
I guess you could walk up the call stack (say hello to inspect), then find the next function ready to handle an effect
I get that, but with your proposal, how would I continue propagating it? Just yield it again?
...In fact, iterate_over_effects could itself note who is currently calling it, e.g. with ```py
def main():
with iterate_over_effects(connect()) as effects:
for effect in effects:
if isinstance(effect, ShouldReconnect):
effect.proceed_with(True)
If proceed_with is not called on an effect, it automatically propagates up the call stack
actually you might not even need inspect
iterate_over_effects could keep a stack of effect iterators. So when an effect is not handled, the previous iterator is chosen to handle this effect. and so on
like ```py
@contextmanager
def iterate_over_effects(ef):
thing = EffectThing(prev=global_stack[-1])
global_stack.append(thing)
try:
yield _actually_yield_events(ef, thing)
finally:
global_stack.pop()
def _actually_yield_events(ef, thing):
while True:
for effect in somehow_get_next_effects(ef, thing):
yield effect
if not effect.is_handled():
thing.propagate(effect)
...
def somehow_get_next_effect(ef, thing):
effects = []
while True:
while thing.propagated_events():
yield from thing.propagated_events()
effects.append(raw_get_next_effect(ef))
if not thing.propagated_events():
yield from effects
break
``` something like this maybe?..Yeah I get what you mean, cool
I am still not convinced it would be a good addition for Python, but I'd sure love to try it out
Yeah it's more of #esoteric-python territory tbh
Writing simple code is already hard enough
It might be a good idea. That's my point: I really have no idea. Is this some (in Python) useless feature that will just complicate things, or is it something like the move from goto to proper loops, try-finally to context managers, ... . Would have to try out a bunch to see if you can make code better with it.

care to name some examples?
 bot.run("token")
bot.run("token")they're changing that to in 2.0, but how is that bad? ```py
async def main():
async with bot:
await bot.start('token')
asyncio.run(main())
https://gist.github.com/wookie184/3050782b3502c2fd17491ecb00ab2177 Really dodgy but seems to just about work 😄
Takes a opcode to search for and an object to look through, and returns the shortest function(?) that uses that opcode
this looks awesome!
I didn't really know what I was doing so it's probably quite fragile lol.
hmm is there anywhere i can find updates about the bpo to gh migration
There's this GitHub repo with issues and a pile of links for organising the process: https://github.com/psf/gh-migration
does python have atomic groups or possessive quantifiers in the re module
No, but there's a PEP for it
eh what's this then https://github.com/python/cpython/commit/345b390ed69f36681dbc41187bc8f49cd9135b54

GitHub
…-31982)
- Atomic grouping: (?>...).
- Possessive quantifiers: x++, x*+, x?+, x{m,n}+.
Equivalent to (?>x+), (?>x*), (?>x?), (?>x{m,n}).
Co-authored-by: J...
Stack Overflow
Ruby's regular expressions have a feature called atomic grouping (?>regexp), described here, is there any equivalent in Python's re module?
The result of the accepted PEP, merged into 3.11.
Oh, I guess there's wasn't a PEP. In any case: coming in 3.11
Hello friends I am beginner So How can I practice python
@edgy wagon this is definitely the wrong place to dump memes from r/shitposting
wait did i accidentally
so sorry lol
@opal zenith your question was off-topic for this channel; try again in #python-discussion
the first few instructions: ```py
x = 1:
4 0 LOAD_CONST 1 (1)
2 STORE_FAST 0 (x)
y = 2:
5 4 LOAD_CONST 2 (2)
6 STORE_FAST 1 (y)
i have no idea how the rest work
I don't understand, what is the error in this code?
from statistics import mean
notes = input("Entrez votre note (exemple 5,6,10...)").split(",")
print(notes)
notes_length = len(notes)
if notes_length <= 5:
print("Le trimestre n'est pas encore finit!")
else:
result = mean(notes)
print("Votre moyenne est de {}".format(result))
Not the right channel for this. See #❓|how-to-get-help
Ah okay sorry
Which part of cpython code should I look to make changes in python REPL?
oops, the reaction earlier was accidental
but essentially,
x = 1 / 4 0 LOAD_CONST 1 (1)
\ 2 STORE_FAST 0 (x)
y = 2 / 5 4 LOAD_CONST 2 (2)
\ 6 STORE_FAST 1 (y)
finally block <-- 6 8 SETUP_FINALLY 6 (to 22)
``` is the first part, the second part is a bit confusinglike the ROT_FOUR being there is odd but i didn't take a look at the whole step by step
Trail starts at https://github.com/python/cpython/blob/main/Modules/main.c#L508
Modules/main.c line 508
pymain_repl(PyConfig *config, int *exitcode)```Thanks man
how do you want to change it?
Hey! I was just in #help-croissant (check there for any additional info about my situation) and the person that was helping me there said i might want to hop over here. I am trying to implement my own repl and need to know how to both display the values of variables and (if possible) run functions. Specifically, i am looking for class object variables and functions, otherwise i'd just use print(globals()[command])
y'all is pythonw included in standard mac and linux installations
i think pythonw is a windows-specific thing
doesn't seem like it to me though since the docs do mention mac too
for anyone reading: i think the challenge here is to resolve all currently-visible names, not just the current local and global scopes
but they're really ambiguous on whether mac and linux actually have it
i can look on my mac. i guess it makes sense that you'd want it on both systems
I accidentally types ls clear and all in python REPL and it gives weird (only for me) parsing error. Maybe i will change the error msg according to my need.
!d code
Source code: Lib/code.py
The code module provides facilities to implement read-eval-print loops in Python. Two classes and convenience functions are included which can be used to build applications which provide an interactive interpreter prompt.
repl is implemented within python afaik
You are right as it gives TypeError when I type ls. I once encountered something which was using code.py but i forgot.
No it just emulates the behaviour of repl. I will explore more
Is multiple inheritance just like doing chained Inheritance?
Class Fish(Predator, Prey) == Class Fish(Class Predator(Prey))
well, Predator doesn't inherit from Prey
it's a bit complicated
maybe this can help: https://www.youtube.com/watch?v=EiOglTERPEo
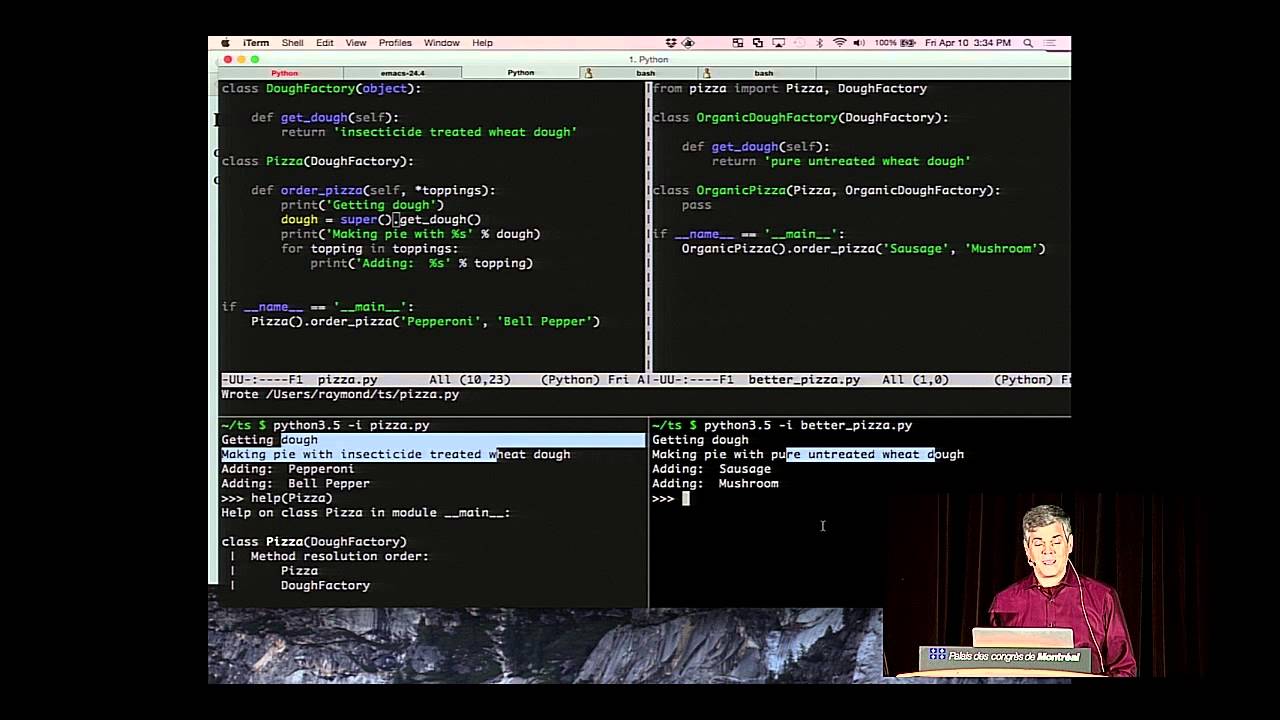
"Speaker: Raymond Hettinger
Python's super() is well-designed and powerful, but it can be tricky to use if you don't know all the moves.
This talk offers clear, practical advice with real-world use cases on how to use super() effectively and not get tripped-up by common mistakes.
Slides can be found at: https://speakerdeck.com/pycon2015 and ...
yield from generator is roughly the same as
for item in generator:
yield item
as for when you would want that, something like this:
def another_generator():
yield first_value
yield from iterable_or_whatever
yield last_value
yes, thanks for clarifying this
@unkempt rock your question is off-topic for this channel. Try asking in a help channel. See #❓|how-to-get-help
i think i found a nice use case for js-like lambdas 🙂
class Foo:
_x = 10
x = property(self => self._x,
(self, x) => self._x = x
)
finally a way to write properties that doesn't suck 😄
a statement in a lambda?
yes?
also {} should work for multi-line (multi-statement)
property getter/setter/deleter are basically defined as throw-away functions, which exactly is the point about anonymous functions
setattr(self, "_x", x) :)
you know what properties are, right?
i know you're joking but i don't think this is any better than 2 defs, and still approximately as ugly/dense as lambda
i think stacking long blocks / anonymous functions on top of each other is visually impossible to read
!e ```python
class Foo:
_x = 10
x = property(lambda self: self._x)
x.setter(lambda self, x: self._x := x)
foo = Foo()
print(foo.x)
foo.x = 20
print(foo.x)
@paper echo :x: Your eval job has completed with return code 1.
001 | File "<string>", line 4
002 | x.setter(lambda self, x: self._x := x)
003 | ^^^^^^^^^^^^^^^^^^^^^^^
004 | SyntaxError: cannot use assignment expressions with lambda
!e ```python
class Foo:
_x = 10
x = property(lambda self: self._x)
foo = Foo()
print(foo.x)
@paper echo :white_check_mark: Your eval job has completed with return code 0.
10
huh
no assignments in lambdas
you need to parenthesize them
i'm not joking. i hate the need to name throw-away functions. they're polluting the namespace and IDEs have a really hard time with the ```py
@x.setter
def x(..):
...
@x.getter
def x(...):
...
patternbut it's x already 🤔 (in this case)
and yes valid, it's obnoxious to give a name to every throwaway function
but in this particular case i don't see a problem. you can also do def _(...):
that's even worse. have 10 properties, all with def _(...) and your IDE will slowly choke you to death
there's no elegant solution with properties.. i really searched far and wide and all i found is sadness
still couldnt set the attribute with an assignment expression
answer: don't over-use properties
that's not an answer, that's giving up 😦
i have been working with some people who use async properties
i do not understand why you would do that
how is await self.current_user any better than await self.get_current_user()??
hint: it's not, it's just confusing
a great idea: some form of postfix await token, let's use 🎟️
foo🎟️
foo.🎟️bar
foo.bar()🎟️
1 +🎟️ 1
i'm fascinated and appalled at the same time
right? i didn't even know you could use @property with async def, apparently it works just fine
(foo🎟️).bar
Yup because async functions are just functions that return coroutines. I've seen some cursed stuff
Like- async properties that actually have an effect
yeah it makes sense after i saw it... but. why.
You can also use properties with generators
oh yeah this one does i/o. it looks for something in a local cache, and if it's not there then it fetches it from another service over the network
yeah, it doesn't make really sense from a reader perspective
GET are supposed to be idempotent, this wasn't...
oh lol
i mean, you're using a property to abstract away internal behaviour
but then you have to use await to ..
🤷
Then use a method 😩
exactly @paper echo 's point 😄
literally the only benefit of properties is for compatibility with an interface or another class where something is expected to be an attribute, but for whatever reason your implementation requires some kind of computation
that's it
my point was that there's no nice way to write properties at all - all cursed in one way or another (except the simplest of cases with @property decorator for getters)
and i guess maybe certain cases where you really really want to make some attributes read-only
and my point is that maybe this isn't such a bad thing 🙂
well, one time i wrote a class that was acting as a facade, mapping attributes to slices etc
it was a nice idea in principle, but writing those properties.. i was cursing all the way
another time i wrote a little wrapper class for an sqlite db, same problem
it's not an issue of over-using properties or making them too complicated - none of those examples really were complicated, just some mapping - it's just a pita to write them and an eyesore to read them
i guess i don't mind them much, but i also don't use them to such an extent
!e ```python
from enum import Enum
class Thing:
def init(self, x):
self.x = x
class SpecialThings2(Thing, Enum):
A = Thing(1)
B = Thing(2)
print(SpecialThings2.A.x)
i expected this to return `1`, not `Thing(1)`. what's happening here?@paper echo :white_check_mark: Your eval job has completed with return code 0.
<__main__.Thing object at 0x7f15c4c11c00>
Hm, maybe try doing SpecialThings.A.value.x?
You can already do this!
x = (
foo(1, 2)(await ing)
.bar()(await ing)
.baz("hmm")(await ing)
)
although it does require specially crafting these methods
Basically, when a method is called, set up a global variable with some coroutine. Then ing will read that variable
it seems to work for any attribute name though, which makes no sense. normally you access the underlying object in an enum member with _value_
!e ```python
from enum import Enum
class Thing:
def init(self, x):
self.x = x
class SpecialThings2(Thing, Enum):
A = Thing(1)
B = Thing(2)
print(SpecialThings2.A.x)
print(SpecialThings2.A.x.x)
print(SpecialThings2.A.asdfasdfds)
print(SpecialThings2.A.asdfasdfds.x)
@paper echo :x: Your eval job has completed with return code 1.
001 | <__main__.Thing object at 0x7f59af95e9e0>
002 | 1
003 | Traceback (most recent call last):
004 | File "<string>", line 13, in <module>
005 | AttributeError: 'SpecialThings2' object has no attribute 'asdfasdfds'
Huh
i do, and i don't see properties being a good case for multiline lambdas, or lambdas in general
they have very little to do with setattr
you can implement a property with setattr
and that will allow you to use a lambda if you want that so much
the way you showed wasn't implementing a property though
!e ```py
class Example:
x = property(lambda s: s.x, lambda s, x: setattr(s, "_x", x))
e = Example()
e.x = 10
print(e.x)
@spice pecan :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 6, in <module>
003 | File "<string>", line 2, in <lambda>
004 | File "<string>", line 2, in <lambda>
005 | File "<string>", line 2, in <lambda>
006 | [Previous line repeated 996 more times]
007 | RecursionError: maximum recursion depth exceeded
not as easy as it looks like, is it
If only I remembered the semantics of setattr and had a pc at hand
you're still using property and setattr is just a different way to say x = property(..), which is no different from what i wrote
I'm aware that I'm using property
The recursion issue is me returning x instead of _x
In the getter
!e ```py
class Example:
x = property(lambda s: s._x, lambda s, x: setattr(s, "_x", x))
e = Example()
e.x = 10
print(e.x) ```
@spice pecan :white_check_mark: Your eval job has completed with return code 0.
10
Here, a working property with a setter and no statements in a lambda
sure, that works
that would work around the assignment issue in lambdas, which is one issue
try asking in #python-discussion
Regarding setters that are more complicated, I'm firmly on the side that they should:
a) be a named method to not mislead the caller in terms of computational cost
b) if there is no significant cost overhead, but a setter needs multiple statements, there's is either little difference between a regular def with a decorator and a function style property with a ml lambda in terms of visual noise (arguably in favor of def)
c) if neither apply, reconsider if you need properties
furthermore, I think that in a lot of cases, properties should instead be replaced with custom descriptors, because a lot of common use cases are very similar and can be generalized to a good extent
So no, i don't see properties being a good use case for lambdas. There are other cases that would be valid, but not properties (at least not IMO)
I should note that I'm firmly in favor of named functions than ml lambdas in general, so I may be biased, but excluding a subset of callbacks and a few other cases where giving a sensible name to a function is not applicable, I don't see much use for them in a readable codebase
maybe that's because lambda isn't very readable to begin with
Not python lambdas specifically, ml lambdas in general
I don't dislike the python notation, and when passing a function to, say, reduce, simple lambdas are a very legitimate tool to use, be it python, c# or js
i dislike the python notation and its limitations
key word being simple, most of the time (in my experience and the code I've seen) ml lambdas can be safely and beneficially replaced with a named function. There are a few exceptions that I've mentioned above, but other than that, js-esque callback spaghetti is not something I'd like to see spreading in python source code
callback spaghetti is also very doable with named functions, just thinking of twisted
i don't think crippling lambdas makes a big difference in readability. instead of crippling them or having them js-free-style, code blocks could also be doable
i mean, there are many ways to produce unreadable code. arbitrarily limiting people by special-casing unnamed functions doesn't solve anything. having clear but still flexible guidelines on code layout like PEP8 does solve much more
when i write code in ml/haskell-style languages, i tend to make lots of named local functions anyway
i have a really hard time reading through nests of anonymous -> functions in those languages
Enum has weird behaviour with multiple inheritance, since you inherit from Thing it constructs a Thing for every member so what you're effectively doing is assigning A to Thing(Thing(1))
If you do A = 1; B = 2, etc. it will automatically construct Thing(...) with that value
Take a look at the docs https://docs.python.org/3/library/enum.html#timeperiod here, they demonstrate it.
Right above it is also the https://docs.python.org/3/library/enum.html#planet planet example, which might or might not also be applicable to your use case.
You could always write a descriptor manually instead of relying on the property syntactic sugar, though a Python IDE struggling with properties sounds mighty strange.
yes, i know that.. what's your point? the problem with properties and IDEs is that using in a property named throw-away functions rapidly pollute the namespace and instead of 1 you have 4 things with the same or similar name. not the IDE is "struggling" but the programmer is "struggling"
ahhhh, interesting
yes, i think the planet case is relevant. i remember reading this once before, but never "filed" it properly in my brain
@stone field it seems that they are removing this behavior in 3.11
Enummembers are instances of theirEnumclass, and are normally accessed asEnumClass.member. Under certain circumstances they can also be accessed asEnumClass.member.member, but you should never do this as that lookup may fail or, worse, return something besides theEnummember you are looking for (this is another good reason to use all-uppercase names for members):Note This behavior is deprecated and will be removed in 3.11.
so is there any way to write what i wrote? or do you have to first subclass Thing and override __new__ to be idempotent if you pass it a Thing in its first argument??
hello, do you think that in the future, it would be possible to (even uniefficiently) convert python bytecode to asm?
there have been attempts already to compile python to machine code, see e.g. the Nuitka project
and Numba, which actually does operate on python bytecode and JIT compiles to native machine code
(i think Nuitka operates on source code)
so yes, it exists
numba is awesome
you're looking for nuitka then
or pyinstaller
i haven't worked with nuitka before though, so i can't really tell how well it works
so, instead of an EXE
just pure code?
meaning instead of giving some file, just prints out some assembly code
no, numba only works for a limited subset of python, specifically designed for numerical programs
example: ```py
def test():
return 5
nuitka supposedly does work on all or most python code
With the Python compiler Nuitka you create protected binaries out of your Python source code.
could that return: test: mov rax, 5 ret
i dont think its that good
you mean nuitka or numba?
either / both
I believe nuitka loads stuff into a c level library
is there a way to see the generated machine code in numba?
yeah nuitka might compile to C first, i dont remember. would have to check the website
@winged yarrow remember that python "bytecode" is also specific to the standard implementation of python (called "cpython"). other implementations like pypy and graalpython exist and do not use the same bytecode at all
pyjion does actually operate on cpython bytecode right? it's like a plugin bytecode interpreter for cpython?
Yes
numba's performance optimization is pretty significant for the area it's designed for
It compiles what it can and offloads the rest to the interpreter
yeah pretty cool stuff. i wonder how it compares to pypy on "plain python" tasks (where pypy tends to kick cpython's butt)
doesn't graalvm also support native ahead-of-time compilation?
@winged yarrow https://stackoverflow.com/a/61859833/2954547
Stack Overflow
In a bizarre turn of events, I've ended up in the following predicament where I'm using the following Python code to write the assembly generated by Numba to a file:
@jit(nopython=True, nogil=True...
I believe you can get the compiled il in Pyjion
so i was thinking
why not, even if SUPER unefficient, to literally transpile cpython bytecode
for example it has 3 stacks (i think)
so instead of optimizing, literally: mov chosenreg, [stackregweuse] dec stackregweuse instead of pop chosenreg
nvm that's stupid
im pretty sure this is how numba works
cpython bytecode -> llvm
and thereon to machine code
Interesting, as far as I can tell it seems to refer to this behaviour, where since instances by default are instances of the same underlying Enum type you could access the members through each other:
>>> class BareEnum(enum.Enum):
... a = 10
... b = 10
...
>>> BareEnum.a.b
<BareEnum.a: 10>
which in 3.11 has changed:
>>> BareEnum.a.b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "python3.11/enum.py", line 169, in __get__
raise AttributeError(
^^^^^^^^^^^^^^^^^^^^^
AttributeError: <enum 'BareEnum'> member has no attribute 'b'
I can't find a BPO issue associated with this very quickly and it's not listed in the changelog either, but custom member types still seem to work as expected:
>>> from datetime import timedelta
>>>
>>> class Period(timedelta, enum.Enum):
... day_0 = 0
...
>>> Period.day_0
<Period.day_0: datetime.timedelta(0)>
>>> Period.day_0.total_seconds()
0.0
>>> Period.day_0.days
0
Something has definitely changed, though I'm not exactly sure if this kind of name sharing was truly 'supported' behaviour in the past (as self is the member type):
>>> class Test:
... def __init__(self, x):
... self.x = x * 2
...
>>> class TestEnum(Test, enum.Enum):
... x = 10
... y = 20
...
>>> TestEnum.x
<TestEnum.x: 10>
>>> TestEnum.x.x
20
>>> TestEnum.y.x
40
vs 3.11 where it just fails as self.x is attempted to be set again:
>>> class TestEnum(Test, enum.Enum):
... x = 10
... y = 20
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib64/python3.11/enum.py", line 484, in __new__
raise exc
^^^^^^^^^
File "/usr/lib64/python3.11/enum.py", line 237, in __set_name__
enum_member.__init__(*args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<stdin>", line 3, in __init__
File "/usr/lib64/python3.11/enum.py", line 177, in __set__
raise AttributeError(
^^^^^^^^^^^^^^^^^^^^^
AttributeError: <enum 'TestEnum'> cannot set attribute 'x'
@stone field thanks for investigating. i don't think i've been this mystified about something since i started trying to learn about monad transformers
i guess it's too much to ask that enums be fully magical
it seems like Enum is really really complicated and maybe tries to do too much
The python enum module is fairly strange to be fair, in hindsight this feature could maybe have been achieved with something like this instead:
class MyEnum(Enum, member_type=T):
...
i had no idea enum was so cursed wth
that's what i was thinking, or similar
alternatively enum members could be defined as a dict of values, or flagged with some wrapper function
or all class-level attributes are naively frozen as enum members 🤷♂️
i don't know why they did the _sunder_ thing
enum member could have just been its own type
That's what they changed it to in 3.11, by the looks of it
from enum2 import Enum
class Status(Enum):
ACTIVE = 1
CANCELED = 2
ON_HOLD = 3
UNDER_REVIEW = 4
Status.ACTIVE # instance of EnumMember
Status.ACTIVE.value == 1
seems like that would have been easy enough 🤷♂️ and just not support the Status(int, Enum) trickery at all
that, or, you just slap on all the associated methods and if there is a name clash then that's your fault 😛
i guess the sunder stuff was specifically added to support the Status(int, Enum) trickery?
In hindsight there's a lot the enum module could do but I imagine most of the weirdness is historical baggage
i still don't know Status(SomethingComplicated, Enum) is even supported or not 🤔 i admittedly don't understand the TimePeriod example
as with most weirdness
i see how subclassing works with the tuple, but what a strange way to set things up
normally you would want to define your class and then set up an enum separately
For example, it wouldn't be too trivial to make Enum work like this by default:
class MyEnum(Enum):
ACTIVE
CANCELLED
ON_HOLD
UNDER_REVIEW
whereas currently this would be achieved with explicitly using auto()
you could do it with variable annotation syntax!
but yeah i don't have any complaints against auto()
class MyEnum(Enum):
ACTIVE: int
CANCELLED: int
ON_HOLD: int
UNDER_REVIEW: int
Runtime annotations are just all around worse descriptors
those are fighting words 😛
i agree, except that type checkers still don't know how to handle descriptors properly
at least mypy doesn't
i don't think pyright does either. there's some kind of special dataclass protocol now to work around this
also there's no reason why auto() even needs to be a descriptor. e.g. in the case of attrs, the attr.ib() things aren't descriptors, they are actually just dumb placeholders that get stripped off entirely when the class is created
the attrs decorator just iterates over class members, it doesn't leave any dynamic descriptors in place after the class is returned to the user
I'm not entirely sure auto() actually is a descriptor, but yeah it doesn't need to be
https://github.com/python/cpython/blob/main/Lib/enum.py#L143-L148 doesn't look like it is
maybe as a concession to type checkers, attr.ib and enum.auto should be descriptors, with their __get__ method required to return the same type as the annotated instance/class attribute
Lib/enum.py lines 143 to 148
_auto_null = object()
class auto:
"""
Instances are replaced with an appropriate value in Enum class suites.
"""
value = _auto_null```The mypy Playground is a web service that receives a Python program with type hints, runs mypy inside a sandbox, then returns the output.
from __future__ import annotations
from pathlib import Path
class DirectorySize:
def __get__(
self,
obj: Directory,
objtype: None | type[Directory] = None
) -> int:
return len(list(obj.path.iterdir()))
class Directory:
path: Path
size: int = DirectorySize()
def __init__(self, path: Path) -> None:
self.path = path
mypy --strict --show-error-codes --show-column-numbers
main.py:16:17: error: Incompatible types in assignment (expression has type "DirectorySize", variable has type "int") [assignment]
Found 1 error in 1 file (checked 1 source file)
auto() is intercepted by the custom namespace class, and then swapped out as the class is built.
Not a problem that I'm currently experiencing, but is there any support (native or otherwise) for circumstances where two dependencies themselves depend on irreconcilable versions of a shared dependency? is this something the core devs plan to address?
hey, are all updates made in python basically PR's merged to the cpython repository after verification by core devs
When did python made writing super(clsname, self).__init__() optinal?
Can I get that pep or a stackflow answer when It is proposed?
**PEP 3135 - New Super**
Status
Final
Python-Version
3.0
Created
28-Apr-2007
Type
Standards Track
I believe @verbal escarp worked on justuse for things like these issues
meep?
oh, yeah
I don't think I have heard anything about any plans to make it work. As in, from what I know there is no dedicsted effort.
in justuse?
It seems like a quite tricky problem, but with the complexity of the import system it has to be possible, surely 😅
we released a new version few days ago
i also ran mass tests against all conda packages with 1148 of 1321 total successfully automatically installing without manual interference
although, working on the showcase gave me a little headache with some unexpected bugs showing their tails
so i wouldn't recommend it for production yet, but it's getting there
however, there's one problem i don't think i can solve without breaking too much
i wanted to not only make it possible to have different dependencies installed in parallel but also be able to load them into the same program
which would require dropping the import caching, which would work except for one crucial package - numpy is forcefully refusing to play along
and without numpy, much of the rest of the sci stack is useless
i mostly made peace with the import caching by now
yes
now let me read what the question was
oh, almost certainly
yeah that's not too hard to do imo
i've spent too much time with import hooks
what is?
.
that is definitely doable
did you try it? 🙂
if you think you found a solution, make a POC for numpy and show me
importhooks + custom finder and loader, getting the parent frame to see which module is trying to import the package, using importlib metadata to get the version it wants
yeah, that's the easy part
ye
and now for the caching
it would have to install the packages on first import and then cache it
sys.modules would use the same name for both versions
Odd,I thought numpy supported the new multi-stage init for extensions
oh right... would need to solve the problems sys.modules...
bingo.
i did play with custom shadowing of sys.modules and sys.paths to serve whatever each module is expecting, but that only gets you that far
also the parent frames might not work due to importlib calling with frames removed
don't know about that, also probably not related to this problem
numpy actively checks if it has already been loaded to actively prevent reloading
which includes loading of multiple versions
why would that not work?
/pypi numpy
!pypi numpy

NumPy is the fundamental package for array computing with Python.
because there are packages that modify other packages which are looking them up in sys.modules etc
it's a bloody mess
right
Aah, right. Might be fixed when it realizes it has to support subinterpreters 🤷♂️
the other possibly viable solution would be to modify the name dropped in sys.modules and keep track of the version that way, like (numpy, "1.21.0")
or somesuch
but even that is problematic because it would need extra lookup and in the scenario where one module is trying to find another, there's ambiguity
sigh
i'm thinking the only actually viable solution is to work with software components à la jupyter
properly isolated sub-programs each with their own modules
communicating via msgpack or somesuch
at least in this case justuse does solve the "oh no we can't install different versions at the same time" problem
there's another problem i need to solve before justuse hits 1.0, which is "from which python version am i trying to load"
nvm. just rambling ^^
but i'm serious, if you do figure out a way to load different versions of numpy in the same program, i'd love to see it
i gave it a serious shot and couldn't make it work
In an experiment I just did in 3.7.9, str.__str__ returned the same object in memory. Is this specified behavior?
i mean shouldn't it do that just like how +int just returns the same object but incref'd
for immutable types, it's ultimately inconsequential whether equivalent instances happen to be the same in memory, so they might have chosen not to specify that str.__str__ has to return itself.
It's not required, but it's an obvious optimization.
kinda confused do i have to use my irl name in cla?
i used mine
i would imagine that's the expectation
like can i use my internet name instead (MaskDuck)
i'm not sure how agreements like that work when people are using pseudonyms
it might depend on various local laws / legal precedents
maybe that's a good question for the mailing list or discourse forum
we don't have many users here who work on python in an official capacity
IANAL, but I don't see how pseudonyms would be a problem: a CLA is supposed to stop you from suing the project later for using your code. As long as the code you contribute can be linked to the CLA (signed by the same user), I don't see how you would be able to sue successfully.
I signed it with my alias, I reached out to them and they said it was fine.



while type(obj).mro() is working, I wonder .mro() cannot be found in the dir(type(obj)). Why we can't find its method from dir(type(obj))?
class A:
def method(self):
print("A.method() called")
class B(A):
def method(self):
print("B.method() called")
b = B()
obj1 = dir(type(b))
print(obj1)
"""
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__',
'__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'method']
"""
obj3 = type(b).mro()
print(obj3)
"""
[<class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
"""
you can find it in dir(type) though
also every type is an instance of type
Hi I want to implement something like sorted(obj) or len(obj)
Basically I want to be able to do run(obj) and the obj must have __run__ to run or smth should I just do
def run(obj, *args, **kwargs):
return obj.__run__(args, kwargs)```The PEP 8 song, but I kind of made it overly dramatic (hopefully this belongs here well enough)
Yeah
I'd recommend #community-meta
do i ask about MRO stuff here?
ok i'm gonna assume yes
can i use a type's MRO to check inheritance? like is MRO a version stable feature?
you mean calling the .mro() method?
>>> mro = atomics.INT.mro()
>>> mro.index(atomics.INTEGRAL)
1
>>> mro.index(atomics.ANY)
2
i have this type
ANY
│
└───BYTES
│
└───INTEGRAL
│
└───INT
└───UINT
i want to check that it inherits like this
can i do this by checking that INTEGRAL and ANY appear in .mro(), with INTEGRAL being first, and also check that none of the other types appear in the mro?
would that be reasonable?
Seems easier to check __bases__ directly
oh no way
i had no idea that existed 🙂
should i be accessing it directly as __bases__ or is there an equivalent non-magic method?
hmm tbh i think i still want mro(), since you can hide stuff in __bases__ by inheriting indirectly
i assume issubclass isn't appropriate because of __subclasshook__, right?
it's also quite verbose to do it that way (i tried in #unit-testing )
ah i see
grrr why is printf-style string interpolation documented in library/stdtypes.html but format-style string interpolation documented in library/string.html
i can never remember where to find these things
It's documented there since string.Formatter has an extensible version of the logic. But all three spots (str.format, string, f-string syntax) do link to each other at least...
In [8]: from types import FunctionType
In [9]: FunctionType.__init__
Out[9]: <slot wrapper '__init__' of 'object' objects>
In [10]: FunctionType(5)
TypeError: function() missing required argument 'globals'

!e it's a bit tedious
from types import CodeType, FunctionType
new_fn = FunctionType(
CodeType(1, 0, 0, 1, 8, 67, b"|\x00d\x01\x17\x00S\x00", (None, 1), (), ("n",), "", "foo", 1, b"\x00\x01"),
{},
)
print(new_fn(41))
@quick snow :white_check_mark: Your eval job has completed with return code 0.
42
It's a bit less cryptic with kwargs
1Run python -W error test.py
6Traceback (most recent call last):
7 File "test.py", line 8, in <module>
8 import pandas as pd
9 File "/opt/hostedtoolcache/PyPy/3.9.10/x64/lib/pypy3.9/site-packages/pandas/__init__.py", line 11, in <module>
10 __import__(dependency)
11 File "/opt/hostedtoolcache/PyPy/3.9.10/x64/lib/pypy3.9/site-packages/numpy/__init__.py", line 155, in <module>
12 from . import random
13 File "/opt/hostedtoolcache/PyPy/3.9.10/x64/lib/pypy3.9/site-packages/numpy/random/__init__.py", line 180, in <module>
14 from . import _pickle
15 File "/opt/hostedtoolcache/PyPy/3.9.10/x64/lib/pypy3.9/site-packages/numpy/random/_pickle.py", line 1, in <module>
16 from .mtrand import RandomState
17 File "mtrand.pyx", line 19, in init numpy.random.mtrand
18ImportWarning: can't resolve package from __spec__ or __package__, falling back on __name__ and __path__
Getting this weird ImportWarning for PyPy
How can I fix this? I am getting the warning only in GitHub CI. This is working fine locally
Does anyone here understand Pypy?
I don't quite understand the details of it. I get that there is an interpreter written in RPython. And that It is a tracing compiler, but apparently the tracing is done on the interpreter. So what is the difference between that and say writing an interpreter in a JIT runtime like Java? People talk about Pypy like it is special and unique but that conflicts with my current understanding.
hi, please ask your question in #type-hinting
Oh sorry
oh, but also what hsp says. 🙂
hm, what do type checkers use internally?
moving my answer over there...
for future readers: #type-hinting message
what is a member_descriptor, there are no docs on this class whatsoever

so further investigation means that it is an instance of types.MemberDescriptorType
some thing on builtins, let me try to find out exactly what
The type of objects defined in extension modules with PyMemberDef, such as datetime.timedelta.days.
???
Lib/datetime.py lines 593 to 597
# Read-only field accessors
@property
def days(self):
"""days"""
return self._days```that doesn't look like a member descriptor or all properties would return this type, no?
there's probably a separate C implementation
then why am i getting this class for attributes defined in python?
you aren't
I am
can you give an example?
lemme see if i can make a smaller example
Modules/_datetimemodule.c line 2652
{"days", T_INT, OFFSET(days), READONLY,```There is also a Python implementation that gets used if the C implementation isn't available, but that's very rare (maybe pypy uses it?)
This isn't much to do with the Python-level __slots__ mechanism either
oh I see, yeah it makes sense that the __slots__ implementation would use this type
!e ```py
import inspect, types
class Message:
slots = ['content',]
obj = getattr(Message, 'content')
print(type(obj))
print(inspect.ismemberdescriptor(obj))
print(isinstance(obj, types.MemberDescriptorType))
@white nexus :white_check_mark: Your eval job has completed with return code 0.
001 | <class 'member_descriptor'>
002 | True
003 | True
is it mis-documented?
I don't know, what documentation are you looking at ?
(Also sorry for not believing earlier that you'd see this type for Python-defined attributes)
types.MemberDescriptorType and inspect.ismemberdescriptor have the only docs about it
Oh yeah, would be reasonable to mention there that it's also used for __slots__. Also, those two places in the docs should link to each other.

please report a bugs.python.org bug 🙂
Also, those docs don't really say what the difference is between a GetSetDescriptorType and a MemberDescriptorType. Seems like it's that MemberDescriptor refers directly to an object stored on the underlying C structure, while GetSetDescriptorType has a getter (and optionally setter) function that computes the value. So __slots__ are MemberDescriptors, because the getter just returns the object at some fixed offset from the start of the instance definition, but int.real is a GetSetDescriptor, because it has a getter with some logic in it.
!e print(type(int.real))
@white nexus :white_check_mark: Your eval job has completed with return code 0.
<class 'getset_descriptor'>
is that possible now? new issues couldnt be opened because of the migration to gh issues
!pep 588 still a draft ¯_(ツ)_/¯
This issue tracker will soon become read-only and move to GitHub.
yeah the migration got delayed a few times
oh
the plan is now that it happens next weekend
neat, i'll try to remember to make a issue
5 + 10 == add(5, 10)
0 + .1 == add(0, .1)
"foo" + "bar" == concat("foo", "bar")
[1, 2] + [3] == concat([1, 2], [3])
# Why not extend to...
range(5) + range(10) == chain(range(5), range(10))
# And perhaps as a default implementation
IteratorA + IteratorB == chain(IteratorA, IteratorB)
Isn't this what you would (perhaps naively) expect?
no, chain isn't a sequence -- you can't index it
that is, if i could add two range types, i'd probably expect a range type to come out, not a chain object
Humm, that's fair, you would need an intermediate object for that one so that you can keep __contains__ and __getitem__, but expecting range + range to just give you another range would be weirder since start end step would make no sense... At the same time, Idk if looking at typeshed is enough, but I did a search for __add__ and I could only find one example where adding two objects would give you a completely different object: xml.dom.minicompat.EmptyNodeList() + xml.dom.minicompat.EmptyNodeList() gives a xml.dom.minicompat.NodeList and that was it, so probably not the way to go
!e
that doesn't always hold for arithmetic operators
d = {"a": 1, "b": 2, "c": 3}
a = d.keys()
b = ["c", "d"]
print(type(a), type(b))
diff = a - b
print(diff)
print(type(diff))
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
001 | <class 'dict_keys'> <class 'list'>
002 | {'a', 'b'}
003 | <class 'set'>
but yeah, it'd be a bit strange
If you chained two itertors though, you would still have an iterator, just not the same one x)
i create a RangeSet when adding two Ranges in real_ranges -- for convenience
Is there a pythonic method to get many attribute from a list, ex:
x[1,4]
output: [2,5]```
numpy support list as index, ex:
```x[[1,4]]```
and if there isn't, is there any plan to have it in python?by "attribute", it sounds like you mean "element". "attribute" refers specifically to something else in Python.
There isn't a pythonic way to do that, unless it can be achieved via list slicing. I doubt there are plans to add it since it sounds like most of the use cases are scientific computing, in which case they'd use numpy anyway. It's an interesting idea though!
The best solution I can think of is [x[i] for i in [1, 4]]
thank you
Can I follow this issue? and may be add it to source code of python?
you would first have to suggest it on the python-ideas email list and see if there's any interest, and find a cpython core developer interested in sponsoring a PEP. my guess is that the idea wouldn't make it past the first stage, as the community is tending towards making fewer changes to the language going forward.
That's ok
thank you
I made a suggestion on python-ideas a few years ago and got a resounding rejection. I'm still emotionally damaged tbh
I have experienced something like that in django community.
But I love community, It let others like me help the world and learn too much.
How does pypi and pip work?
I want to make a pypi but only good design codes are allowed
I'd look into https://bandersnatch.readthedocs.io/en/latest/. There are also some PEPs about how PyPI works
If you want to just host your own PyPI with a few hand-picked packages, there are existing solutions such as pypiserver and devpi
!pypi pypiserver
A minimal PyPI server for use with pip/easy_install.
i didn't know about this one
the docs also show that you can use any file server with auto-indexing (eg twistd) but then you have to manage the file layout yourself
Note of caution: pypiserver proxies to global PyPI by default
I would personally announce it in a big red sign but I'm not a maintainer
does it cache locally at least? otherwise what's the point?
isn't one of the other ones also a locally-caching pypi mirror by default?
The point is that you can add your own packages
Or, well, disable the proxying
i see. depends on your use case then
You can try using operator.itemgetter
!e ```py
from operator import itemgetter
getter = itemgetter(2, 3)
print(getter([1, 2, 3, 4, 5]))
@spice pecan :white_check_mark: Your eval job has completed with return code 0.
(3, 4)
!e 5 + 10
@unreal parcel :warning: Your eval job has completed with return code 0.
[No output]
!e
import inspect, types
class Message:
slots = ['content',]
obj = getattr(Message, 'content')
print(type(obj))
print(inspect.ismemberdescriptor(obj))
print(isinstance(obj, types.MemberDescriptorType))
@unreal parcel :white_check_mark: Your eval job has completed with return code 0.
001 | <class 'member_descriptor'>
002 | True
003 | True
@unreal parcel is there something you are attempting to demonstrate?
sometimes you need a good amount of defiance to keep going. when i suggested the idea for module reloading in justuse and justuse in general, the feedback was "that'll never work. other attempts by smarter people have failed, why do you think you could succeed?" or "why would you even WANT to do this?!"
it helped me to have figured out a good amount of stuff before approaching people about the idea, so i knew it was doable
but still, getting told by people you otherwise respect to give up is pretty heavy
apropos reloading. i think i have a feasible solution to the question of signature compatibility
assuming there's a hierarchy of generality for types - iterable > container > list, numerical tower etc
if one is trying to automatically update a module and want to programmatically determine if the incoming version is signature-compatible with the previous one, one could say that all parameters may become less general (previous signature said a: iterable, now a: list is okay, but not the other way round)
i'm thinking that once annotations are at struct-level you can't make compatible changes anymore without changing runtime behaviour
but this is where generics could make a difference and be quite useful
i was pondering whether only input parameters may become less general or it should be all parameters. for input parameters it's clear (thinking of numba or other trans/compilers that rely on specific types)
but if you're working with code that relies on specific types, it may break behaviour of the calling code if the return type becomes less specific
When you get some defiance in some cases it may mean you are doing something major so yes I agree... Many good ideas do encounter resistance initially since people have their comfort zones and change esp major ones can be uncomfortable in the beginning but once you get over that you get the benefits of the changes
it still hurts when you get blown off by people you like and respect
Yeah it does
maybe it would be better if ideas could be discussed anonymously - then people wouldn't hold back with negative feedback, but it also would be easier to detach personal feelings
(of course trolling and insults would still need to be moderated)
I think so and unfiltered feedback is nice if constructive....I had worked with people who filter themselves excessively since they wanna be liked
You can just make a rule to ignore ad hominem and filter it internally if somebody does that their arguements are logically weak and it is on them to be civil and logical.
humans 😐 oh well.
Yeah why we like computers
exactly 😄
Nobody insulted me worse than the Rust compiler tbh
what did it say? ^^
Bug in documentation: https://docs.python.org/3.11/c-api/memory.html#customize-memory-allocators
The description says that there are four fields, but in fact there are five of them.

send a PR and I'll merge it 🙂
i am too lazy(

@feral island judging by your obvious fascination with type checking maybe you're the right person to ask
in justuse i'd like to realize a signature-compatibility check for reloading modules and automatic upgrading, so i'm thinking that stricter types (future version) are always compatible with more general types (past version)
now i figured i can use the numeric tower for this purpose, which at least cover the numbers, which is a big chunk
but i have no idea how to go about container types
Yes, sounds like you need the same kind of check that type checkers perform in subclassing. But you need it at runtime, so you need to implement the same kinds of compatibility checks with runtime type objects
There are libraries that provide something like that (I've heard of pytypes, pydantic, beartype; my own pyanalyze has it too), but not sure how well that will integrate with your library
It's definitely not a simple problem if you want to be fully general
how would you go about list[float] => list[int]?
do you recursively unpack the types or is there a mechanism built in somewhere for this?
typing.get_args helps
But note that strictly those two types are not compatible, because list is invariant
that's undocumented o.O
yeah, no text there
it's documented together with get_origin
ohh, i see
admittedly that's confusing
hm.. let's say we have ```py
def foo(X: list[float]):
return X
which becomes in the next version
```py
def foo(X: list[int]):
return X
you would reject this change as incompatible?
yes, because if a user passed f([1.0]) that will now fail
what about the other way round?
argument type compatibility should actually be checked the other way around: you can broaden but not narrow
though in the case of lists, because of invariance strictly you can't change it at all (https://mypy.readthedocs.io/en/stable/common_issues.html#invariance-vs-covariance)
well, there's a problem. if you're at the bottom of the typing and you're making the assumption that you can apply numba or cython, broadening would kill that assumption
I don't understand that, maybe I don't understand your use case
my assumption would be that you want to be able to reload without breaking existing consumers. Then applying normal subtyping rules makes sense
i think i'll take your advice and will special case a degradation from fully annotated to partial annotation, breaking the promise to numba
thanks 🙂
@feral island is there something that can handle issubclass(Sequence, list)? this raises a TypeError: issubclass() arg 1 must be a class, but the other way round issubclass(list, Sequence) will return True
try collections.abc.Sequence instead of typing.Sequence maybe
weird traceback
@verbal escarp , and whoever else is interested in the types of things and how they fit into the data model
my assumption had been that if I want to get the class name of some object (any legal python reference) 'o', I could do one of two things:
- if the object is an instance of
type, reado.__name__ - otherwise, read
type(o).__name__.
But this seems to not always work. consider this traceback:
.Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <listcomp>
File "/tm/tmp_py_src_dm6qwlre.py", line 123, in printr
val_type_name = class_name(val)
File "/tm/tmp_py_src_dm6qwlre.py", line 28, in class_name
name=getattr(ty, "__qualname__", ty.__name__)
AttributeError: 'SourceFileLoader' object has no attribute '__name__'```And I recall having to special case SourceFileLoader once when I wanted a similar string (in this case, "SourceFileLoader") and some extra care was required
so, am I crazy ?
I will give complete code if anyone is interested to see
i wanna see
ohnI think I figued out where the problem was
I was trying to do something besides just simply check if isinstance(o, type)
now it works since I've reduced this function down to one line of code:
old code
def isinst_object(t):
from types import WrapperDescriptorType
return isinstance(t, type)
try:
return isinstance(
object.__getattribute__(t, "__str__"), WrapperDescriptorType
)
except AttributeError:
try:
object.__getattribute__(t, "__mro__")
except AttributeError:
return True
else:
return not isinstance(t, type)
``` new code:
```py
def isinst_object(t):
return not isinstance(t, type)
and this is where the exception was happening
def get_class_or_module(t):
return type(t) if isinst_object(t) else t
def get_class_or_module_name(t):
tym = get_class_or_module(t)
return "{module}.{name}".format(
module=tym.__module__,
name=getattr(tym, "__qualname__", tym.__name__)
) if not inspect.ismodule(tym) else (
tym.__name__
)```I had been assuming the logic in isinst_object lived up to its name
!e minimal reproducer:
import importlib.machinery as mod
o = mod.__loader__
print(o)
print(o.__name__)```@lusty scroll :x: Your eval job has completed with return code 1.
001 | <_frozen_importlib_external.SourceFileLoader object at 0x7f4d51ff59f0>
002 | Traceback (most recent call last):
003 | File "<string>", line 4, in <module>
004 | AttributeError: 'SourceFileLoader' object has no attribute '__name__'. Did you mean: '__ne__'?
I swear there is something weird about one of those loader classes though
ah it was just that some __spec__s have a loader "type" instead of a loader "instance" in their __loader__ property
nevermind, nothing to see here
>>> issubclass(list[int], Number)
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
File "G:\Python398\lib\abc.py", line 123, in __subclasscheck__
return _abc_subclasscheck(cls, subclass)
TypeError: issubclass() arg 1 must be a class
kneejerk moment
>>> type(list[int])
<class 'types.GenericAlias'>
especially with this
does this qualify as a bug or..?
I dont think so, it doesn't make much sense to use issubclass with parameterised generics, it would be more appropriate for a issubtype but python has no constructions for this internally that would allow for this I think
well, the answer for issubclass(list[int], Number) is clearly False, not an exception
but list[int] is not a class, it makes as much sense as issubclass(3, int)
i would argue that it is a class in the sense that you can do ```py
listint
[1, 2, 3]
without problemsbut you could also do
>>> list[int](["foo","bar","baz"])
["foo","bar","baz"]
list[int] doesnt really mean much at runtime, so what would be the utility in allowed it as a first argument to issubcalss
also, type() agrees with me
it clearly says "class"
if it's not a class, one of the above is clearly lying
Humm, that is a good point, I think it gets weird when talking about the types from types. ..., because in that case this is also a bug issubclass(lambda x: x, int)
wait, nvm lambda x: x would be an instance of lambdatype
Wait no, that just means that list[int] is an instance of the class 'types.GenericAlias'
i'm confused 😄
For X to be a class, type(X) should return type disregrading metaclasses
what's the difference between class and type anyway?
i thought python3 got rid of the distinction?
In python, classes are instance of type, conceptually classes layout new types, but it is not the same kind of "type" per say
Conceptually yes, I think, but only classes are actual instances of type in python
list[int] is conceptually a type
so basically it's the same issue with the numeric tower and the built in float/int types?
and "instances" or terms of it are stuff like [1, 2] [3, 4, 6]
you can't check float vs int without mapping to numbers.Integral etc beforehand
you could also build something that's instantiable but that has no place in the type hierarchy because it isn't built by type?
Maybe? I think that issue is similar but parallel, but I dont know
there's so much duplication and confusion 😐
Can you build something that is instanciable and inst a type? If so I wasnt aware xD
typing.Sequence vs. collections.abc.Sequence is another instance
In the future typing.Sequence will be removed so there is at least that
no clue. if so, i'd be looking at low-level wrappers like numpy
low-level wrappers lead to the most annoying and confusing things
I think the type on generics implements __subclasscheck__ blocks issubclass just like isinstance is blocked
well, i realized it now https://pastebin.com/rXfYn5KW via catching TypeError
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
but it's not as elegant as it could be
sorting kwargs is the last missing bit i think
are you trying to implement your own typechecker...?
no, i'm implementing a compatibility checker for auto-reloading modules and auto-upgrading packages
type-checkers are more specific, also using icontract in conjunction would be beneficial
type compatibility is a rough test that suggests that there may be issues with a direct upgrade
why not use an existing typechecker for the type compatibility?
rather, why do you need a runtime type checker?
because i need to compare the signatures of two different callables, any typechecker i know only compares the values that are passed into a single one
because i'm loading the module, then test for compatibility and throw away the module if it doesn't hold
if TYPE_CHECKING:
Foo = ;"some complex alias"
else:
Foo = Any
# or:
Foo = defaultdict(lambda: SomeType) ;"SomeType is not subscriptable at runtime"
now your checker doesn't quite work
if you have
class A:
def f(...) -> ...:
...
class B(A):
def f(...) -> ...:
...
then the typechecker will verify whether the signature of B.f is compatible with A.f
yes, you can shoot yourself in the foot if you really want to :p
isnt that what you're trying to reimplement 🤔
not really..
Example: tkinter.Event is advertised as generic in the stubs but at runtime it's not generic. How else do you use it as a generic?
my idea is 1) load the module 2) load the modified module 3) crawl both modules for callables and compare their signatures for compatibility
i don't check what's passed in, that's the job of beartype
right, but when you encounter something like ```py
v1
def foo(bar: Event[int]):
...
v2
def foo(bar: Event[str]):
...
i don't care about the instances
foo.__annotations__ will be the same in both versions, that's what I meant
or are you planning to crawl the AST?
i haven't planned to, no
hmm.. at this point i'm not even sure if Event[int] and Event[str] would be different in my implementation
...you'd also need to know the variance of the generic to know if Some[Child] is a subtype of Some[Parent](or vice versa)
So you need stubs anyway, if e.g. the class is from a C extension
because i only look at container types
i dont see why you cant use an existing type checker
checking whether one callable is a subtype of another is very much within their capabilities
yep
I wish that was exposed x)
You can import mypy and just use its internals
although, granted, it's very hard to use
i asked a couple times, nobody could give me a solution so i did it myself.. if you have a better solution, i'm all ears
Is there an easy issubtype?
mypy is very stateful with lots of different objects, I haven't found an easy way
i don't insist on my solution being the best, i just haven't seen any for exactly this problem
from mypy import api
inp = f"""
f1: Callable[[int, float], str]
f2: Callable[[float, float], str]
f1 = f2
"""
results = api.run(["-c", inp])
print(results)
would check whether f2 is at least as general as f1
from mypy import api
from typing import Callable
inp = f"""
from typing import Callable, Any
f1: Callable[[bool], str]
f2: Callable[[Any], str]
f1 = f2
"""
results = api.run(["-c", inp])
this is a problem
isnt tho
it is, because i want to forbid broadening
can't you just check if the signatures are equal?
yeah exactly
no narrowing, no broadening... means they're equal
signature equality is meh :p
although you might want to allow new optional parameters, idk
well, i think narrowing signatures is quite natural in python development and once very specific types are hit, it gets difficult to make compatible changes anyway
but narrowing is not backwards-compatible
I think I completely misunderstand what you're trying to do
okay, let's say you're working on a jupyter notebook or you have a service running somewhere which is auto-reloading a functions-only module when you're modifying it (either by hand or via git commit)
ah, you mean backwards compatible with functions calling the new functions..
🤯
coding with the time dimension is tricky
Ipython has functionality to auto reload imported code upon change on lfs
maybe callbacks from the future? 😆
i know
Ok
I use it a lot for development, vim/ipython/pdb life
I work on remote systems, very rarely do I have access to an ide
yeah, i like working with jupyter too, but i'm also thinking of standalone services like servers or bots
think of a discord bot that would auto-reload when you're pushing a commit
tornado has this option
it's very useful if you are developing in a docker container because you can bind mount your code and don't have to restart the container, which can be slow
how does it work with changing signatures?
i don't think it works in a repl
it literally restarts a running server if it detects file changes
easy way out then ^^
GitHub
Tornado is a Python web framework and asynchronous networking library, originally developed at FriendFeed. - tornado/autoreload.py at stable · tornadoweb/tornado
as for ipython, i eyeballed the code a while ago, and it does not follow aliased names
so it's still limited
coming from my experience with an MMORPG, restarting the server always took very long and nobody was really happy when it happened
it would've been nice to only reload the game logic, for example
outside of splitting everything up into microservices of sorts, i don't see a viable alternative there
that's why i'm a bit obsessed with this problem ^^
but i also see the issues about "backwards compatibility" and it's giving me a headache
maybe it could be feasible to check for compatibility breaks this way and then register wrappers of some sort either for warning the user or type conversion
so the user would first get NotCompatibleWarning and it would fall back to the previous version, then they could explicitely enable a type converter
whats the spec of hash? (side topic, where do i find those specs) is it just to return a unique number like id?