#internals-and-peps
1 messages · Page 94 of 1
it's a complete mess of switches and templates, heh
But there is c++ server that can help, i can dm if you want
Not my server
In case you think it is advertising
I'm a professional C++ dev. It's not a matter of me not knowing the language well enough, it's a matter of the language being insufficiently expressive for what I want to do.
Yeah i mean, maybe there is a solution though
(and I could cheat and use macros, if I thought it'd pass code review, heh)
perfect. macros + esoteric obfuscation then, and we have a winner
macros could do it, or type erasure
but if I go the type erasure route, I lose performance.
btw, hows js in terms of speed vs python? similar i assume?
substantially faster, actually
I believe JS is faster
assuming you don’t include extension modules
because of highly optimised JIT
what makes js faster?
but that said, JS is probably a good benchmark for how fast you could possibly get Python to be through just a JIT.
and AFAIK a big part of that is that JS has had to run in browsers
i see, okay thats pretty interesting
and had a ton of corporate investment into making it fast.
yeah
whereas in Python you can just write the compute intensive parts in another language
=> no incentive to throw $$/effort at the problem
js is also dynamically typed and has objects for datatypes and all that jazz, yeah?
or does it have primitives
it is dynamically typed - but also intrinsically single threaded, which removes a lot of complexity
Yeah js has no multithreading
one of the reasons a JIT has trouble making assumptions about how Python code should behave is that another thread could be changing the type of an object.
effectively no, I’d say
But asyncio is used alot.
oh wow interesting, i didnt realise that
Has someone heard of "Jai" programming language
The devs said it will be better than c++ in game devs, but I suspect it
better in what respect? It's pretty hard to beat C++ for performance, but pretty easy to beat it for ease of use or developer time or safety
Idk, ask the devs 
This is why i suspect it being better than c++
Even in game devs
there are language that are as fast as C++. C and Rust are basically equally fast as C++, assuming they're programmed by a competent developer. And C and C++ leave some optimizations on the table that other languages could pick up - the aliasing rules make it impossible to optimize some things as well as should be possible
faster languages than C and C++ can exist.
What do you mean by "safety"?
it's very easy to write buggy C++ code. And many - maybe even most - C++ bugs are actually security vulnerabilities.
Yeah i agree on that
Well, C-Lang is worse
If we are talking about security vulnerabilities
I'm not sure that it is...
Maybe slightly, but not by a huge amount.
both of these are equally bad: ```cpp
int c[2] = {0, 1};
c[2];
std::vector<int> c{0, 1};
c[2];
what does this do wrong? as an outsider looking in, without context, this looks perfectly fine
accesses memory past the end of an allocated array/vector
(and im assuming c[2] is saying make a array of length 2?)
yep.
segfault ?
If you're lucky
possibly segv, more likely access arbitrary memory.
I can do the same in python
and yeah, the segv is the better outcome.
vector has .at() which does raise an error for out of bounds values - but no one uses it.
lul
denied!
Or something. I'll figure it out in a moment
😄
wait this is amazing
!e ```py
import ctypes
a = b"1234"
print(ctypes.string_at(id(a)+32, 15))
!e ```py
import ctypes as c
c.POINTER(c.c_void_p).from_address(id(int)+96)[0] = c.POINTER(c.c_void_p).from_address(id(int)+96)[1]
a = 5
b = 3
print(a+b)
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
2
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
b'1234\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
There
one of the big things about C++ is that you don't pay for what you don't use, and bounds checking has a cost
strings are different than bytes
and the bytes type header is 32 bytes away from its pointer
aha. okay, that makes sense
tradeoffs. tradeoffs everywhere.
Anyway, you can see how I read ... 11 bytes past the end of a python bytes object
I got all zeros cause I was lucky
make that 5000 and you'll SEGV for sure.
Honestly not sure what I'm hitting
does this get limited/boxed into the memory reserved by python, or is this literally free to access any part of the memory?
!e ```py
import ctypes
a = b"1234"
b = b"1586test"
print(ctypes.string_at(id(a)+32, 15))
print(id(a), id(b))
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
001 | b'1234\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
002 | 139800389733472 139800389734000
looks like.. I'd need to read a few hundred
!e ```py
import ctypes
a = b"1234"
b = b"1586test"
print(ctypes.string_at(id(a)+32, 1000))
print(id(a), id(b))
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
001 | b'1234\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x00\xe9\xd0}\xfa\x7f\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xffb\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x000\\N}\xfa\x7f\x00\x00\xf0\xa0N}\xfa\x7f\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xc0:\xd2}\xfa\x7f\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xf0\xc4N}\xfa\x7f\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xc0:\xd2}\xfa\x7f\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\xdaN}\xfa\x7f\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\xe9\xd0}\xfa\x7f\x00\x00\n\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xfft\x00|\x00|\x01\x83\x02S\x00\x00\x00\x00\x00\x00\x00\xb0\x1dN}\xfa\x7f\x00\x00\xc0\xe3\xd3}\xfa\
... (truncated - too long)
Full output: https://paste.pythondiscord.com/ludukaliqo.txt
what is "this"
hey guys
it's virtual memory - it can access any memory segment that is mapped into the Python process's address space and is readable.
oh, just the way of accessing arbitrary data using ctypes.string_at
fwiw b is in there, it's like, 500 characters after a
okay, so it's effectively still boxed into python reserved memory*
I can just
in general, a process can't look at any other process's memory without permission (there are ways, but you'd have to go through the OS)
AFAIK
barring attacks on the hardware itself, like rowhammer.
or spectre.
ye
!e ```py
import ctypes
a = b"1234"
b = b"1586test"
data = ctypes.string_at(id(a)+32, 1000)
print(data[:15], data[600:800])
print(id(a), id(b))
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
001 | b'1234\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x00\xe9\x01\xa9\x8c\x7f\x00\x00\x06\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xffctypes\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\xe9\x01\xa9\x8c\x7f\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xff.\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\xe9\x01\xa9\x8c\x7f\x00\x00\t\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xffstring_at\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x00\xe9\x01\xa9\x8c\x7f\x00\x00\n\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\xff\xff\xff\xff\x08\x01\x04\x01\x04\x01\x14\x01\x1a\x01\x00\x00\x00\x00\x00\x00\x10\x1e\x7f\xa8\x8c\x7f\x00\x00 \x1e\x7f\xa8\x8c\x7f\x00\x00'
002 | 140242099051616 140242099052144
Ah, you can see, I'm reading through globals()
There's a way to access this mutably, so I could make things get really weird really quickly
!e This thing that I pasted without comment above replaces integer addition with integer subtraction.
import ctypes as c
c.POINTER(c.c_void_p).from_address(id(int)+96)[0] = c.POINTER(c.c_void_p).from_address(id(int)+96)[1]
a = 5
b = 3
print(a+b)
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
2
otypes
that's intentional
I'm trying to overwrite something, one moment
have you heard of #bot-commands? 😛
or #esoteric-python actually
!e ```py
import ctypes
a = b"1234"
b = b"1586test"
data = ctypes.string_at(id(a)+32, 1000)
ctypes.c_char.from_address(id(a)+32+data.find(b"ctypes")).value = ord("o")
print(data[:15], data[600:800])
print(id(a), id(b))
print(otypes)
Anyway
could you use this to overwrite builtins as well?
Yes
I used it to dynamically rewrite python's compiled bytecode to add a "jump to end" magic call for a with statement
that is overwriting the builtin. It's replacing int.__add__ with int.__sub__, basically
Basically you can edit arbitrary ram
let me just
!e ```py
import ctypes
a = b"1234"
ctypes.c_char.from_address(id(a)+32+1).value = ord("o")
print(a)
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
b'1o34'
bytes objects are not so immutable when you oops your bounds checks
bruh
lol
at the C level, nothing's immutable. You can replace 0 with 1
that is c[5] is equivalent to *c+5 or something, I don't remember the syntax right
wtf
huh
*(c+5) but yeah.
which basically means "the memory address of variable c plus the index times sizeof *c"
times sizeof *c
yeah. In fact, esoteric C: because x[5] is equivalent to *(x + 5), and *(x + 5) is equivalent to *(5 + x), it's possible to do 5[x] instead of x[5].
I made the assumption when I was writing the code before that python would try and allocate a and b next to each other but it looks like there's some optimizations there so I can't rely on that
because if they were pressed together, reading, say, the 6th character of the 4 character string asdf pressed up against the four character string test would give you e
C often has this issue because C strings are null-terminated, not size-prefixed
which means that you read until you see \0
unless someone forgot to tack that on, then you read into whatever until you happen upon one
that's one of the biggest performance mistakes in the entire C programming language, frankly.
Yeah
(id(a)+32 this part makes me guess it would be asdf and then another jump of 32 first?
Many libraries add size-prefixed strings but then they have to use apis expecting \n
not quite
because this is python, a is not just a string of bytes in memory
it includes the size too
I can find the structure somewhere in the repo but
each character is 2 bytes?
the "header" bit of bytes that contains all that data is 32 bytes in size
the id of an object, in CPython, is the address of that object in memory. 32 bytes after the start of that bytes object is a dynamically allocated array of bytes containing the actual contents.
so a bytes object is:
[-----32 bytes of ref count and size and stuff ------]stringgoeshereasrawdata
oh
So I basically do id(a) to get the address, which points at the start, then +32 to jump past the data I don't need
!e ```py
import ctypes
a = b"1234"
data = ctypes.string_at(id(a), 32+4)
print(data)
@torpid bridge :white_check_mark: Your eval job has completed with return code 0.
b'\x03\x00\x00\x00\x00\x00\x00\x00\x00\xc9u\x83\xc1\x7f\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00[\xf2\xb2\n{\x11\x05\xbb1234'
https://github.com/python/cpython/blob/master/Include/cpython/bytesobject.h#L5-L8 is the link to it in the CPython code.
the PyObject_VAR_HEAD is 24 bytes, Py_hash_t is 8 bytes, so ob_sval starts 32 bytes after the start of the object.
yeah, so im wondering if when you had 2 variables, would b start at id(a), 32+4 + 32?
not necessarily, but possibly.
Python does pool allocations, so its more likely. But that relies on no other ones being allocated and having space and etc
There's a common thing that shows this, actually
so close
Anyway, one of those constructions on a live interpreter will give you identical values
because one has been deallocated and leaves exactly enough space for another to show up
!e ```py
a = b"1234"
print(id(a))
del a
b = b"1234"
print(id(b))
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | 140092334993840
002 | 140092334993840
Yeah, like that
Use after free here can be used to edit a string you don't own
for example, if a is a string you own and are allowed to access, but access after it has been deleted and someone else controls b
like forgetting to change the locks on a storage unit
A lot of the recent ios exploits function off this, basically, you try and get the ios kernel to confuse two different datastructures (usually IOKit ones because they're full of pointers to good stuff and easy to get lots of), and once that happens you can get the kernel to change things that you shouldn't be able to.
Yo any one willing to help me with simple script that i maybe missing
How do i visit list of urls from excel column , i have imported cell value with Openpyxl . So what should i type in brackets driver.get(urls from excel) to get it to visit that url
@open acorn this is strictly a discussion channel. See #❓|how-to-get-help
Hey folks! I have a question regarding the is operator, and furthermore, the way Python stores references when assigning variables. I noticed after a bit of digging that the is operator will return False if the two string variables are equal but contain characters that are not alphanumeric or an underscore. I traced it back to cpython's codeobject.c file which seems to only account for those alphanumeric (plus _) characters:
#define NAME_CHARS \
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz"
Is this done intentionally? Why are non A-N+_ strings stored with unique references? May be a lower level thing, I'm not sure.
Interesting, so that works. let me do a little more digging
a = "@a"
b = "@a"
a is b
``` wouldnt@wide vector is is used for checking refrence point of objects in memory
and the memory refrence changes for that @ character
>>> id(a)
2178931147184
>>> id(b)
2178931106480
Yes, however why does that occur only when either adding a non-alnum to an alnum, or having a sequence of non-alnums?
when using alnums, it doesn't seem to produce that issue. You can change the lengths and contents of both strings but as long as they hold the same alnum text it will output a True value
>>> a = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
>>> b = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
>>> a is b
True
I'm sure it is some low level implementation that causes this, I'm just wondering. Is there a reason to this inconsistency?
Maybe a limitation of C itself
I assume it would be the same deal as how Python caches integers from -5 to 257 (someone correct me if my numbers are wrong).
It would store string combinations in order to save time that would otherwise be needed to construct the string
interesting optimization there...
b = "@@"
a = "@@"
``` also are not refrenced pointed to same objectSo with that we can determine that Python only caches alphanumeric strings, as well as the references to the individual non-alphanumeric characters. However, non-AN characters in combination with other non_AN OR AN characters will NOT be cached and therefore result in unique references.
Wow, that's interesting
Single-character strings in the Latin1 range (U+0000 - U+00FF) are shared in CPython. This saves memory and CPU time of per-character processing of strings containing ASCII characters and characters from Latin based alphabets. But the users of languages that use non-Latin based alphabets are not so lucky. Proposed PR adds a cache for characters in BMP (U+0100 - U+FFFF) which covers most alphabetic scripts.
No, that's just a PR suggesting other things to add to the cache
Gotcha
And I believe you can add whatever you want to the cache
>>> "hell" + "o" is "hello"
<stdin>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
True
>>> "hell" + "@" is "hell@"
<stdin>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
True
wow
string interning, new to me!
The key point here is that, if you're trying to understand is and id(), don't use them on immutable objects.
The relevant part as to the original query appears to be:
The function all_name_chars rules out strings that are not composed of ascii letters, digits or underscores, i.e. strings looking like identifiers:
Which refers to function:
#define NAME_CHARS \
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz"
/* all_name_chars(s): true iff all chars in s are valid NAME_CHARS */
static int
all_name_chars(unsigned char *s)
{
static char ok_name_char[256];
static unsigned char *name_chars = (unsigned char *)NAME_CHARS;
if (ok_name_char[*name_chars] == 0) {
unsigned char *p;
for (p = name_chars; *p; p++)
ok_name_char[*p] = 1;
}
while (*s) {
if (ok_name_char[*s++] == 0)
return 0;
}
return 1;
}
With mutable objects, every instance has its own state, so it's relevant whether two objects with the same value are or are not references to the same object. With immutable objects, two objects with the same value are completely interchangeable, and the interpreter can, at its discretion, optimize away objects by making them refer to previously created objects.
The answer to the "why only alphanumerics plus underscore" is that the CPython authors thought those strings would be the most likely to get reused, so they're worth caching. Other strings are deemed less likely to get reused, or more expensive to cache, so they don't cache them.
Are there any PEP guidelines (or other principles) on whether you should make your class subscriptable or not?
But the entire existence of this cache is an implementation detail. Using is or id() on immutable objects doesn't necessarily give you meaningful results, because the interpreter is allowed to cheat.
Ahh, interesting design decision!
Hm. If it's collection-like and you want to expose access to the items in the collection, you implement __getitem__, otherwise you don't
variables are refrenced
Say I have a class that parses text into ~12 meaningful attributes, any or all of which you might export to a spreadsheet, etc. But conceivably you could add attributes, depending on the project you wanted to use it for. Do you have an opinion on whether it’s wise there?
It's not. That's not collection-like
Instead, expose them as named attributes on the object
Cool. That’s how I implemented it, actually. I have a couple methods to dump the chosen attribute values to a list or dict.
I just learned how to implement subscripting in custom classes; just wasn’t 100% sure on when you would want to vs. not. Thanks!
You should use it for things that are container-like: subclasses of dict or list or tuple or set, or things that behave like dicts or lists or tuples or sets, etc.
Basically, collections of stuff where the user can insert or remove elements in the fly, and where the primary purpose of the object is to contain those items.
Yeah, that makes perfect sense.
unrelated, but that + is being optimized away in the bytecode
it's going to be the same as 'hello' is 'hello'
I mean that's kind of what that shows no?
well my point is that it's like when you do x = 4999999 + 1
That's optimized before the code is ever executed.
during runtime that's going to be 5000000
At no point is there a str object that contains "hell"
why is this code not accepting any input value from the user?
class metropolis:
def init(self,Mcode,MName,MPop,Area,PopDens):
self.Mcode=Mcode
self.MName=MName
self.MPop=MPop
self.Area=Area
self.PopDens=PopDens
def Calden(self):
d=PopDens/Area
print(d)
def Enter(self):
return(
int(input("Enter the area code")),
input("Enter the name"),
int(input("Enter the population")),
float(input("Enter the area coverage")),
float(input("Enter the pop density")),
)
print(metropolis.Calden())
def Viewall(self):
print(metropolis.init())
anyone knows?
This is not a help channel, it's a channel for discussion about Python language concepts and implementation.
Check out #❓|how-to-get-help
You can see how it's different if you do this right:
>>> hell = 'hell'
>>> o = 'o'
>>> a = 'hello'
>>> hell + o is a
False
i guess only immutables are refrenced
When you do "hell" + "o", that's optimized away when the code is compiled, which is different from the optimizations that we've been looking at for immutable objects which happen when the code is being interpreted.
Some simple optimizations are performed at compile time, and constant folding is one of them.
https://bugs.python.org/issue1346238 shows where it was added.
Indeed it's referenced in the article I linked
Er, https://bugs.python.org/issue29469 actually
Ah, I didn't notice that. It's a separate topic from string interning, so I wouldn't have expected it to be there, but fair enough
They explain it's why strings longer 20 are not interned
Or rather, why computed strings longer than 20 are not interned
i.e. a = 'a' * 21
longer than 20 characters?
In [4]: a = 'a' * 21
In [5]: 'a' * 21 is a
<>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
<ipython-input-5-870f341d8bb7>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
'a' * 21 is a
Out[5]: True
Last I recall it was 4096
In [6]: a = 'a' * 4097
In [8]: 'a' * 4097 is a
Out[8]: False
In [9]: a = 'a' * 4096
In [10]: 'a' * 4096 is a
<>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
<ipython-input-10-0f9df0e048c2>:1: SyntaxWarning: "is" with a literal. Did you mean "=="?
'a' * 4096 is a
Out[10]: True
I mean that's what it was in that article. It's an implementation detail so maybe it changed since 2014...
Or maybe the article simplified down the number?
IIRC, 32 and 64 bit Python have different limits.
Would make sense
And that article was written for Python 2, so it's at least a bit out of date
It doesn't fit on my screen
>>> dis("'' * 4096")
1 0 LOAD_CONST 0 ('')
2 RETURN_VALUE
>>> dis("'' * 4097")
1 0 LOAD_CONST 0 ('')
2 RETURN_VALUE
>>> dis("'' * 4400")
1 0 LOAD_CONST 0 ('')
2 RETURN_VALUE
>>> dis("'' * 99999")
1 0 LOAD_CONST 0 ('')
2 RETURN_VALUE
>>>```smarthaha
I think that's constant propagation in play again
it's doing good
I think it's evaluating it to empty string before even deciding whether to intern it.
I know string interning is a useful optimization from a performance point of view, but it's really annoying from a teaching point of view. It causes an awful lot of confusion about identity. People get taught "is" or "id()", and they try it out themselves, and it immediately does something unexpected by telling them that two objects they created at different times are actually the same object
Another rather interesting Python string optimization
>>> hello = "h"
>>> hello += "e"
>>> print(hello, id(hello))
he 1797357577712
>>> hello += "l"
>>> print(hello, id(hello))
hel 1797357577712
>>> hello += "l"
>>> print(hello, id(hello))
hell 1797357577712
>>> hello += "o"
>>> print(hello, id(hello))
hello 1797357577712
I have discussed this 1 day ago in a other server
does that happen outside the REPL?
Id is different
And that only works on a += b, not on a = a + b
You just can't see it I think
Oops I probably missed it
Something to do with garbage collection
Memory location (id) would change after runtime
Afaik
Yep, it does. The interpreter knows that there's only one reference to the object, and that it's about to be lost if it creates a new object to hold the new string, so it cheats and modifies the old one instead of destroying it and making a new one
!e ```py
x = "he"
print(id(x))
x += "l"
print(id(x))
y = x
x += "lo"
print(id(x))
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | 140298723851376
002 | 140298723877040
003 | 140298723877104
mmm
Well that didn't do what I expected...
Yeah I just tried that. I swear it was different yesterday hahah
Yeah
I thought it was same id, same id, different id
So garbage collection can change id after you run the program sometimes
But I got the same result as above haha
I asked because sometimes the REPL does some things differently
I had an "issue" once (not really I was just wasting my time) because the REPL would close a file descriptor in some esoteric code I was writing
because it was getting rid of some variable
The garbage collection time may vary
Not really... At least, not with CPython.
At least that how I understand it 
"Up until version 3.7, Python used peephole optimization, and all strings longer than 20 characters were not interned. However, now it uses the AST optimizer, and (most) strings up to 4096 characters are interned."
This was the reason btw
Yup makes sense
Interned?
is the plural of emoji "emoji" or "emojis"?
>>> a = '😂'
>>> b = '😂'
>>> a is b
False
Cute
Emojis are clearly unique personalities
Pytohn
CPython has 2 different things called "garbage collection". Objects have a reference count, and most objects are destroyed when their reference count reaches 0. Some objects will never have their reference count reach 0, because object x holds a reference to object y, and object y holds a reference to object x. This is called a reference cycle. So Python has a second cycle collecting garbage collector that discovers dead objects whose reference counts can never reach 0 and destroys them.
\😂
So how does this explain Id being different or not
In all the examples we've been doing above, there are no reference cycles in play, so the cycle collecting garbage collector - the one that runs at arbitrary times - never comes into play
Yes, that understandable, no reference cycles, because there is no cycling in assigning objects to each other, but sometimes it show same ID sometimes not
How is this related to reference cycling
I'm not sure what's causing that, but I'm certain it's not the GC.
If someone's at a computer, can they try running ^ this and see if they get the same results?
Only other answer I know, is it has to do with variable being mutable or something
I meant this because it said "most strings" but I guess it's only about interning, yeah, I thought it meant other optimizations
Return the “identity” of an object. This is an integer which is guaranteed to be unique and constant for this object during its lifetime. Two objects with non-overlapping lifetimes may have the same id() value.
Yep, and that's true. Two objects that are alive at different times can have the same id
But that's unrelated to the strings being updated in place stuff we were analyzing

Stack Overflow
It is stated that strings are immutable objects, and when we make changes in that variable it actually creates a new string object.
So I wanted to test this phenomenon with this piece of code:
^ source
But still
It require some research
!e ```py
x = "!"
print(id(x))
x += "!"
print(id(x))
x += "!"
print(id(x))
x += "!"
print(id(x))
x += "!"
print(id(x))
y = x
x += "!"
print(id(x))
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | 140059159624816
002 | 140059159658608
003 | 140059159658608
004 | 140059159658608
005 | 140059159658608
006 | 140059159658672
There we go
FUN.
TIMES.
https://www.tutorialspoint.com/How-can-we-change-the-id-of-an-immutable-string-in-Python#:~:text=The same strings have the,() value not being reused.
Interning I guess
Strings in Python are immutable, that means that once a string is created, it can't be changed. When you create a string, and if you create same string and ...
That shows the interpreter repeatedly modifying a string rather than creating a new one.
Oh God this link
interning is also confusing when you want to test efficiency qq
It's an implementation detail though so you shouldn't really rely on it for any optimization
Yep, that's why I switched to "!" in order to show off strings being modified

And the initial one is still not modified, because it's still interned (since it's a single character string, I think)
But yeah, very much implementation detail.
It's really unfortunate that everyone trying to learn is and id() bumps up against this implementation detail
>>> x = '!'
>>> idx = id(x)
>>> print(idx)
4317569200
>>> x += '!'
>>> print(id(x))
4318584112
>>> x += '!'
>>> print(id(x))
4318584112
>>> idx == id('!')
True
Yeah it's unchanged
I'm almost off to bed but I remembered something
well I'm in my bed actually
>>> timeit('"holi"', number=100_000_000)
0.9777427129999978
>>> timeit('f"holi"', number=100_000_000)
1.4292464520000294 ```Doesn't return False to me
this is an old snippet of mine
I mean...
Well, that seems reasonable enough. F strings do more work, it shouldn't be surprising that they're slower
>>> dis('"holi"')
1 0 LOAD_CONST 0 ('holi')
2 RETURN_VALUE
>>> dis('f"holi"')
1 0 LOAD_CONST 0 ('holi')
2 RETURN_VALUE ```Where are you testing your code btw @shrewd dune
mmm but does it generate the byte code every time, or is it related to timeit?
that was on my PC, months ago
LOAD_CONST and stuffs
pypy showed similar times tho! (between the 2 cases, f-strings vs regular, there wasn't a faster one) but pypy was really wacky too, the JIT is weird. Sometimes it's much faster or much slower
during the exact same test

GitHub
Upload and changes to Python 0.9.1 release (from 1991!) so that it would compile - smontanaro/python-0.9.1
That’s cool
Because they aren't the same memory space because they aren't in the set of cached strings?
So the emoji thing returns true on the !e snekbox but false on my mac
Maybe down to the PEG parser in 3.9? Or maybe just a mac thing?
What about linux
Well I assume snekbox is running on Linux
But I'm running 3.8.2 on my mac
vs 3.9 on !e
What is snekbox
Oh amusing.
Oh wow, this actually works...
if (a := 12 + 3) == 15: print("OK", a)
It's kind of ugly tho
Why did you think it wouldn’t work?
I just saw some articles mentioning the PEP, but I didn't know whether it's actually implemented.
Good to know
Is there a library that can work with IPhone? E.g simulating swipe left/swipe right on the home screen
Can someone please help me out, I want to get started to write a research paper
@prime vale Whats your rsrch paper on? How proficient are you w Python
I am an python intermediate guy
How do you need help getting started?
Do you want someone to give you ideas? Write the paper for you? Hold your hand while you piss?
You gotta be more specific
I don't know how to get started
so, I want to narrow down a topic so that I can start a research paper
.
You can search OpenCV with python. It provides face recognition or face detection, its used in Car’s lane keeping support. Very interesting topi
@unkempt roost I have used open CV to make a project, so I want to know how can I proceed to write a research paper
You can find research abstracts online
this is a channel for discussion of the language and probably isn't appropriate for your question...
also, I note that you have posted the same question in multiple channels
please don't.
to me a "primitive type" is a type that directly maps to the platform e.g. IEEE 754 floating point types usable by FPU or fixed width integer types usable directly by CPU.
I think adding syntactic sugar in the form of "methods" to these primitive types doesn't change them from being primitives.
Normally, a primitive is something that can't be broken down further in a simpler data type
Deep down in Python's objects, you may find such a primitive, but it's not the object you're interacting with directly
depends
Could you explain how it depends?
it depends on the implementation
my implementation will have optimizations so fixed width integers are preferred
Are you now talking about a language that is not Python?
I am talking about my implementation of Python
If you change how the objects fundamentally work, your implementation would not be a full implementation of the Python language standard
Which makes it "not Python" to me
no, my implementation will be a full implementation of the Python language; I don't care how existing implementations such as CPython works: as long as observable behavior is the same, i.e. the "as if" rule.
So, your floats and ints get wrapped in objects that expose an interface with methods and so on?
a primitve int will be transformed to a multi-precision int if such a transormation is deemed necessary in order for the Python program being compiled to remain valid.
That's not what I was asking
and "methods" will not require a CPython like object representation of the primitive in order to still work
In Python, you have instances of the class/type int, which are the individual int objects you work with
Those int objects give you access to the int methods defined in the class
it will appear to the Python program that int is still an object even though it isn't under the hood
Right, so what the programmer will experience is something compound that the compiler/interpreter takes care of
A primitive that also provides an interface as if it were an object
You're just not calling it that
it is a requirement that all existing Python 3.x programs remain valid when compiled with my implementation.
Yes, sure, I just don't really think that what you're exposing is something I'd consider to be a true primitive
Python objects may use such primitives internally as well
you mean CPython?
It's just that the element you interface with in your application is something that compounds both the value as well as the methods
No, your implementation
Which sounds awfully like objects to me, just emulated in a different way
I have yet to design the object semantic concept, it will be interesting to see what comes out in the wash
The way in which the language standard is defined, with objects that hold data and give access to methods, is what matters to me
Not how you fake it in your implementation
given my Python compiler doesn't know anything about Python
From my perspective, the abstract perspective of the user, it's not (just) a primitive
indeed, hence my mention of the "as if" rule
as long as observable behavior is the same
So, it's just a semantics game then. It's not a true primitive, from the perspective of the end user and the language definition, but you like to call it a primitive
it will be stored as the primitive type in the byte code
but that is a lower level of abstraction obviously
Still sounds like an implementation detail to me
indeed it is!
If you're talking about Python, it's still not a primitive type
which makes sense given I am creating an implementation! I need such details 🙂
It's still a compound type that consists of data and behavior
not a compound type, a type with meta data
Hence the discussion about if Python would contain primitives that happened earlier
my Python implementation contains no knowledge of Python itself
I don't really think that matters at all
From the perspective of Python, the language, the abstract concept, a float is not just a primitive
Whether or not you separate your logic in pieces and make sure another part of the implementation makes sure that you emulate Python's object behavior as specified in the language reference doesn't really matter
You're just putting parts of your implementation in different places, only look at a subset of what makes a "float" a "float" in python
and suddenly claim the entire thing is a primitive
in my implementation a Python float will be a generic semantic concept that maps to a native floating point type
which does not make a lot of sense to me
It also maps to behavior; the float methods
So, the Python float itself will not be your primitive
it uses a primitive internally, but that's not special
I think you need to read about extension methods to see where I am coming from. https://en.wikipedia.org/wiki/Extension_method
In object-oriented computer programming, an extension method is a method added to an object after the original object was compiled. The modified object is often a class, a prototype or a type. Extension methods are features of some object-oriented programming languages. There is no syntactic difference between calling an extension method and c...
I don't really see how this changes the conceptualisation of floats on the level of Python
because my implementation doesn't know about Python.
And indeed it doesn't have to know about Python
When I'm writing in the Python language, I do
And when I use a Python float, it comes with both the value and the methods
However you implement it
That's up to you
such knowledge is transformed into something else during compilation, an implementation detail, as you say.
Anyway, if you feel better about it if you conceptualise it for yourself as being a "true primitive", please do
but I won't really say that your implementation makes it so it's a true primitive on the level of Python
key thing is multi-precision integers are slower that native integers so I will have an optimization that allows both to be used
Sounds cool
I'm sure a lot of people will be interested in it if you really manage to pull it off
project is https://neos.dev if you are interested.
neos Universal Compiler and Bytecode JIT
for example integer literals can be stored directly as a native integer type otherwise there will be an extra level of indirection to either a native integer type or a multi-precision type that can transform at will based on the outcome of expression evaluation.
(one way transform)
Sounds like you've got a plan for the implementation
It still means that I, as a Python programmer, don't deal with primitives directly
speaking of integers
I just thought about it two minutes ago 🙂
how does Python accomplish its "infinite" integer sizes?
whenever I try to do bitshifts or other clever things, I always seem to hit the C 32-bit int limits
is Python dynamically allocating for integers?
it likely uses multiple C 32-bit ints
Yes, CPython ints dynamically grow as needed. is that what you are asking?
Where do you hit those limits?
language-agnostic integers sound very do-able. Language-agnostic classes do not 🙂
@weary garden python integers use an array of unsigned c ints specified by its ob_size field in the struct. Python floats already do map directly to native floats on the C level
python floats look like this in mem -> [ob_refcnt: c_ssize_t, ob_base: PyObject*, ob_fval: double]
in python2 integers mapped as you described, but that at runtime conversion caused slowdowns
and also caused the integers to have a finite size. Integers now have an infinite size and are on average much faster
I'm not sure how you would implement integers as 'true primitives' given that they are subject to garbage collection
Well, they can't participate in reference cycles, but they still need to store the reference count
It's written in Python, and it's open-source https://github.com/python-discord/bot
However, questions about the server itself are better suited for #community-meta
Python 2 had unbounded ints (called longs, but you didn't need to care about the distinction). Conversion was automatic.
ah i inferred that they were just 64bit c long values cause they were called longs
no, python 3's ints are exactly like python 2's longs.
i will say, it is still amazing to me how we've created abstractions that are so easy to grasp when behind the scenes there's so much that goes into making them work
meanwhile in Haskell: String = [Char]
🥴
im not familiar with haskell at all, am i correct in interpreting that as saying Strings are arrays of characters in haskell?
That's correct, yep
When we create a process pool, is there any way for the processes in the pool to independently send messages back to the parent process? That is, apart from whatever comes back by way of apply or what have you?
Well, it's a linked list of characters.
String is mostly used for low-performance things, and for real-world apps other string types are used
there are more than one string type?
You could pass a Queue to them, and they could put messages into the queue.
i know rust has like 3 (?)
does "bytes" count as a "string type"?
that's true! I could always apply a set_up_queue function
(in python context)
yes, bytes has a lot of stringy methods on it
bytes was called str in Python 2, in fact.
Text for Unicode and ByteString for performance, each coming with their own lazy and strict versions 
The biggest breaking change in Python 3 was changing str from byte strings to Unicode strings
yeah having read up on the differences between py2 and py3 while trying to understand unicode (oh look, someone here actually wrote what i read :P) it was a very important change
there was a pretty good talk by nedbat 👀
Yeah... I think it was a change for the better, because getting people to actually start using Unicode strings for themselves wasn't gonna happen when string literals remained arrays of bytes by default. But it also was where >90% of the Python 3 porting effort went, I'd say. Strings are everywhere in a program.
Python 2 also allowed Unicode strings to be silently converted to byte strings, and vice versa - unless they contain any non-ASCII codepoints / non-ASCII byte values. Which was a never ending source of bugs for things that worked when the developer tested them, but broke when real users used them with international text or filenames

Unicode can be confusing. Here is a “just the facts I need” presentation about how to handle it correctly.
it was very good
there's one called :heart_bean:
although i guess this is #community-meta now
Interesting, so appending a string will maintain its id... unless:
>>> hello = "h"
>>> goodbye = hello
>>> print(hello, id(hello))
h 2178279704944
>>> print(goodbye, id(goodbye))
h 2178279704944
>>> hello += "e"
>>> print(hello, id(hello))
he 2178288336560
>>> print(goodbye, id(goodbye))
h 2178279704944
why? The two operations are essentially identical
It can be hard to tell if you are preserving the id, or just getting a new string made at the same address.
sorry for replying to old messages, I'm catching up with a convo from last night...
@wide vector also, that example doesn't work for me.
(the original one showing the same id)
or maybe it does?
The one I just sent?
Sorry, it does work for me.
It should, since hello and goodbye share the same reference until hello is modified
gotcha
Just read up from last night, super interesting how Python optimizes this stuff...
They are different because the "a+b" in "a = a + b" doesn't know about the "a=" part.
ah, just a different AST I guess
yes, definitely a different AST, which produce different operations.
Why does every ast guide show how to make subclasses using the ast classes? Why do I have to subclass at all?
how often does Python language syntax change?
I assume most minor releases of CPython don't include syntax changes?
If minor means 3.4, 3.5, 3.6, then most of them have syntax changes

3.5 introduced async/await, 3.6 introduced f-strings, 3.7 made async/await hard keywords, 3.8 introduced :=, 3.9 introduced relaxed decorator rules, 3.10 introduces patma and parenthesized with
I assume none of those changes were breaking changes?
async/await becoming hard keywords is a breaking change
in 3.6 you could do async = 42, in 3.7 you can't
in general, Python doesn't follow semver
semver?
g
as for that "maintain its id"... I remember during one Python workshop I attended, we realised it also behaves differently different if you execute a saved code or if you write it in an interactive console. we had some exercise about id and one person did the other thing than the rest and they got different results 😄 I quickly tested both versions (console vs script) and I got the same difference.
but I don't remember what we were doing - it was over a year ago, late autumn 2019
This is part of the subtlety: how the code gets compiled can change how objects are allocated and shared. This is why you almost never use "is".
"is"?
There's an operator in Python called is.
ah, to determine dynamic type?
No, to check if two values are the same object.
I see.
I can't wait to start work on the implementation!
First goal: Python "Hello world!" by the end of the month.
only achievable if I can get neonumeral sorted by end of this week and libffi integrated
anyone up for object oriented skill practical test ?
when using Python in interactive mode what is the significance of the three chevrons? ">>>"?
do your own homework
dude its not a homework. i can do homework by my self 😋
great!
why is is even a thing
like 99% of the time reference equality is only ever used for None
just wondering if there were any other concerns
Hey, im french and i've make a texte about some rules and i need someone for help and correct me, bc idk if all my sentences are english. If you want help me pls DM me !
I'm a little confused by python3's float - the standard says it's an IEEE 754 floating point - C++ double and JS Number should be the same type
-12.0 % 5.0 in C++ and JS gives me -2.0
but in python3 it gives me 3.0?
and IEEE 754 fully defines floating point remainder as a standard operation, it's not just a recommended function
To differntiate between the output and the input, I guess?
>>> 2 + 2
4
>>>
just like a prompt in the terminal
although that also shows the current directory by default
It definitely shouldn't have been a keyword. sys.same_object(x, y) would have been fine.
Or just comparing ids. It should work unless you're comparing immediately created objects (like id([]) == id([]))
and, well, I'd expect id to be in sys, but we had this discussion here a bit over a billion times
yup, same old same old
if you do the math by hand you'll find that the answer is 3
is there a difference?
well... yes? one's positive, one's negative (sure they're the same value % n)
wait, no, wrong link
no, it's right, I think
remainder is not the same as modulo, and different programming languages just choose different rules for modulo
I would agree with you, except the documentation says that in python3 they're the same
x % y remainder of x / y
https://docs.python.org/3/library/stdtypes.html from the operations table
fmod(c/c++): Computes the floating-point remainder of the division operation x/y.
I guess 'remainder' was used for familiarity?..
well, fmod operates differently from Python's %
hmmm - i should look at the implementation
cuz i'm probably missing something
mod = fmod(vx, wx);
if (mod) {
/* ensure the remainder has the same sign as the denominator */
if ((wx < 0) != (mod < 0)) {
mod += wx;
}
}
they literally use fmod, and the sign bit isn't documented as far as i can tell
@red solar I meant that math.fmod has a different sign behaviour than % on floats.
i.e. math.fmod is the same as c/c++'s fmod
or I'm not sure
https://docs.python.org/3/library/math.html#math.fmod not guaranteed to be the same, it says
Hmmm... ok it's nice that it says it somewhere, but ideally it should have a note of that in the operations table for floats
wonder how hard it is to submit a patch for the docs
It is because % on int must behave the same way, and the representative of the modulo class is conventionally the smallest positive member
something something unitTest
Yep, I've seen that. I've actually grepped all uses of id in CPython (that's how few there are).
Not having assertSameObject is a flaw on the unittest side, I'd say.
because it's a relatively common case in the stdlib
wait
and they end up doing assertEqual(id(a), id(b))
then you don't get nice logs showing the difference
(which pytest does by default (using magic (yes, I do nest parentheses sometimes)) when you do assert a == b or assert a is b)
There's no assertIs?
Also pytest good unittest bad
it used to be py.test
what about nose2?
although, let's be honest, at least we aren't trying for anything like Chai.js
The less I see of those tests, the happier I'll be.
var expect = chai.expect;
expect(a).to.equal(b);
expect.number(2).when.being.added.to(2).to.be.equal.to(4)
driver.get('http://chaijs.com/');
expect('nav h1').dom.to.contain.text('Chai');
expect('#node .button').dom.to.have.style('float', 'left');
are you kidding me?
I mean, it makes sense, but holy cow do we really need to type that much?
i'm not sure there's a reason to use nose2 over pytest. pytest is very powerful, and very actively maintained.
the only problem I have with pytest is (AFAIK) you can't use fixtures in test parameters
which is a bit 😔 but not a dealbreaker
It's just a prompt - and the prompt changes to ... for continuation lines.
You can also set it to whatever you want really using sys.ps1 right?
hello
Apparently!
pypy is amazing
expect for the fact that it is not up-to-dated with python itself
latest version is 3.7, while python itself is 3.9
It's nearly impossible for it to stay completely up to date with CPython. They can't start adding features introduced by a new version of CPython until after CPython decides what new features they're adding
The fact that it's only 15 months behind is pretty damn good, all things considered.
why it is not that popular though ?
It's faster than CPython at running Python code, but slower than CPython at running C extension modules. Lots of important, performance sensitive things are written as C extension modules, so being slower at the things that need to be fast isn't great.
as long as it adheres to the topic of the room
take a look at the channel description and pinned messages. tl;dr is this room is specifically for conversations about the python language itself
being able to start work on my Python implementation this weekend is starting to look promising as I have nearly sorted my multi-precision arithmetic library out: https://i.imgur.com/iiq3ONo.png \o/

@weary garden you're creating your own implementation?
yes
I am creating it from scratch
Sounds awesome
project website: https://neos.dev
neos Universal Compiler and Bytecode JIT
Hey @light condor!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
!code-blocks
GDB online Debugger
Online GDB is online ide with compiler and debugger for C/C++. Code, Compiler, Run, Debug Share code nippets.
I cant figure out how to make this not the question!
pls help!
@light condor what do you mean? "how to make this not the question"?
@light condor oh, you are asking in #general. it should be there
sorry I mean i cant figure out how to make it not repeat the question if u get it wrong
Hey @eternal solstice!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
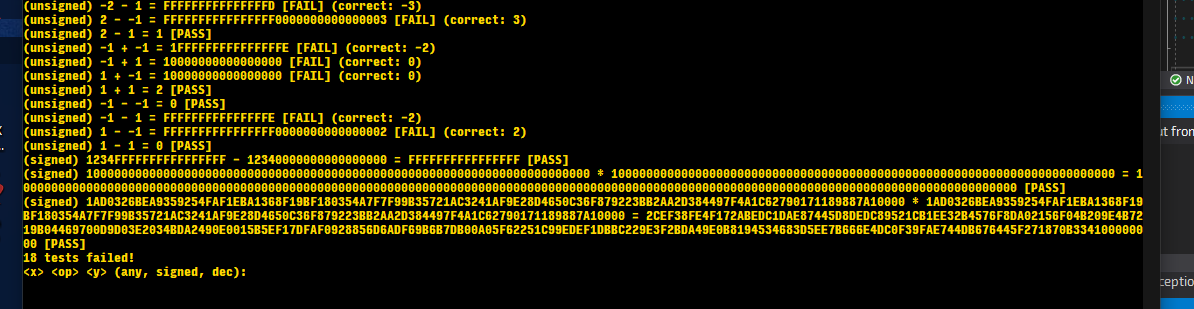
down to just 18 failing tests! \o/ my large signed multiply (base 16) works! https://i.imgur.com/i4heqTk.png all signed integer tests are passing; just need to sort out unsigned integers and what negative numbers mean for unsigned
I'm used to test output that's quiet for pass and loud for fail, so it's easier to tell what's going on.
big signed integer base 10 multiplication passes: https://imgur.com/a/ftuKT0L

{kind=link}
{kind=link}
@spark magnet that will be the case when I move to gtest; for now I want to see everything
@weary garden You won't use your own testing framework? 🙂
okay, I don't actually know how the parser works, but in theory, would it be possible to have => lambdas?
no as that doesn't interest me
I guess yes, that shouldn't break anything.
thank you
I'll expect the PR by close of business tomorrow
oh wait, it's Saturday
😐
@gleaming rover It's friday
I meant it'd be Saturday "tomorrow"
yeah, I mean
ah yes okay
when I said this the "tomorrow" would have been Saturday
gotcha
There's a suggestion on python-ideas right now to allow def in place of lambda
I think that'd be an improvement.
lst.sort(def k: k[0]) is a slight improvement over the current status quo.
just replace that : with a -> and remove the def and you have nice looking lambdas !
🙂
There's a lot more opposition to that.
😦
the arrow makes much more sense than the colon does
changing it to def makes it less annoying than lambda
the best argument in that thread is "If Python didn't have anonymous functions and we were adding them for the first time now, there's no way we'd use lambda"
I think that's very, very true. And I think, if Python didn't have anonymous functions at all today and we were adding them for the first time, allowing def without a function name seems like a way we might add it.
yeah
lambda seems out of place
I mean, it makes sense, because it's a lambda
but it feels like writing kleisli arrow into the async category f(): instead of async def f():
anonymous_function x: x + 3
if Python didn't have logging and we were adding it for the first time now...
I'm taking donations 🙂
Python probably wouldn't have lambdas at all, I would guess?...
like Haskell: \
Or rather-- if lambdas were proposed, they would cause controversy larger than patma
You're joking, but agda actually allows you to use λ
the Python logging module isn't just problematic because of the camelcase - it's architecture, and the fact that it's implemented in Python, make it pretty slow
which is the motivation for https://github.com/brmmm3/fastlogging
This doesn't seem like a good way to install it 🤔

or anything
the latter is fine, right? It's basically what pip install . would do.
well, sure - there's pip install fastlogging for that, heh
it is in PyPI
though the PyPI description reuses the github readme, heh
Why does Python have so many ways to format strings? You can use .format(), f-strings, etc. It's kinda contradict with "There should be one - and preferably one obvious way to do it" rule for me.
legacy code
Because it's an important thing that almost every program needs to do, and people kept coming up with better ways to do it.
it's not as though only f-strings would exist if there were only one way to do it - instead, only the old % style formatting would exist, and people wouldn't be any happier.
Oh
@unkempt rock Python is 30 years old. new ideas come up.
Ok
I've been wondering that for quite a bit of time
Thanks yall for the clarification. Really appreciate it!
!zen only one
The Zen of Python (line 12):
There should be one-- and preferably only one --obvious way to do it.
The Zen of Python (line 13):
Although that way may not be obvious at first unless you're Dutch.
So I guess nobody is Dutch enough to get string formatting right.
Yeah. Maybe except for Guido himself xD
I'm not sure if the only-one-way is always the best approach
Sometimes it's like a distribution: there's one most-common way, and there are other, more niche ways.
Most of the times you want f-strings. More rarely, you'll want .format because you can dynamically choose the template. In very specific circumstances you'll need a different thing altogether -- you don't want to format URLs or SQL queries yourself; and sometimes you might want to use a templating engine.
when would you use template strings https://docs.python.org/3/library/string.html#template-strings 😛
I actually used that once
Yeah
It depends on the situation to choose what to use, doesn't it?
What is that 👀
I guess the one-way mentality is about not having two competing ways, where one doesn't supersede another.
Python lambdas do be quite lame :(
I used it for substituting stuff when generating docs: https://github.com/decorator-factory/python-fnl/blob/master/fnl/docs/__main__.py#L16
basically, it's an ad-hoc documentation generator for my toy markup language.
and the documentation is written in the language itself.
Kind of like a bootstrapping compiler.
hmm why templates over str.format?
Because {...} is part of valid CSS. Although later I moved it to a separate file.
so I guess now it's just inertia lol
template strings are safer in the presence of untrusted user input. That's a good reason to use them.
Why are they safer?
str.format lets you access attrs, so there could be unwanted leaks?
it's safe to use untrusted user input as a template string, but isn't safe to use it as a format string. The latter leads to something called a format string injection attack.
generally format() and fstrings are better than % and concatenating
f-strings should be preferred where they can be used.
ok
hi guys! any1 home?
I am trying to deploy a django app but im having trouble 😦
gunicorn works when i use it inline with bash command: gunicorn -b /path/to/projectname/projectname.sock projectname.wsgi:application
but not when running on systemd service
also the systemd service says its running fine 😦
this is a channel for discussion of the language.
gunicorn is actually a python specific deployment thing but sure.
discussion of the language itself
i.e. where it's going, the pros/cons of its syntactic choices, differences between various implementations, etc.
I was investigating using the socketserver package, and noticed something a bit odd
https://docs.python.org/3/library/socketserver.html#socketserver.BaseRequestHandler.handle
for datagram services,
self.requestis a pair of string and socket.
I don't quite get why it's a string and notbytes?
Ah, the documentation is wrong, it is actually bytes.
Probably missed in the Python 3 transition, when str was renamed to bytes. You should submit a PR to fix it!
Great idea!
might be a dumb question but
are functions even useful
im learning about them rn and idk what I would use them for
😂😂
hopefully functions aren’t too important later on😅
i always have trouble with them
They're very important. As you get further into programming, you want to make bigger and better programs. You'll learn all of the major building blocks in only a few months, and after that everything is about how to combine those blocks together to make bigger and better and more interesting and useful programs. Functions are an incredible important tool for packaging up some little piece of functionality and wrapping a bow on it and giving it a name, so that you can reuse it elsewhere, and build future things that rely on that functionality without needing to copy and paste it or rewrite it.
Oh wow
I understand, I just need to practice, but parameters, returns, and calling functions just don’t match up with my brain
You'll get it. Like everything else, it takes time and practice to sink in.
Yeah
I’ve tried learning it 3x over
Idk why but its the only thing I struggle with
Hopefully I can get it right by tomorrow
Trying to build a program without functions is like trying to build a house without boards. It's possible, you can do everything yourself with some trees, an axe, and a saw, but it's much harder, and the end product won't be as good.
I see
The boards are like functions that someone has put in the time to get nice and reusable, and leveraging them lets you do more, better, faster than you could do without them.
Makes sense a little
What are the main issues on Python ? Like a memory leak in Nodejs
@prime vine Depends on what you're using Python for and what you're comparing it to.
For anything but the absolute simplest code, functions are essential. You would have used functions already, for example len() to get the length of a list.
@deft spruce Functions are probably the single most useful tool you'll ever learn in programming.
is there any library to differentiate qr code engraved on a metal surface?
this isn't a help channel #❓|how-to-get-help @cosmic edge
For example a simple flask api vs express api.
And memory leak in Nodejs is kind of a general issue. It appears in every type of applications.
I wish I knew memory leaks in nodejs before prod. It's really hard to debug those things and it always appears in prod.
I am trying to learn Python, so I am preparing myself for something I should know before going all out.
does the python interpreter do constant folding for string concatenation and if so, does anyone know how it does the folding? I was reading an interesting blog post on the accidentally quadratic blog on tumblr that was by someone who fixed constant folding of string concatenation taking O(n²) space instead of O(n) space in C# and VB.net and I wondered if Python was doing that also:
https://accidentallyquadratic.tumblr.com/post/187336866277/accidentally-quadratic-constant-folding
(asked here because I believe it's relevant to python internals)
Nice. But how did he implement the Ropes technique?
not sure tbh
if C# is open source then one could browse through the old PRs and figure it out though
I would if I wasn't on my phone

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
I'd think the part of Python that deals with string concatenation is written in C, but idk
There are cons which not worth the pros.
Look at the link.
pretty sure the pros outweigh the cons in this case
There's a Python example. Wow
maybe, but I have a hunch that I'd need to implement that c++ code in normal C
would need to check the source code for this though
With this implementation, you are giving away cpu over memory usage.
Right?
What's your use case for that?
It doesn't seem to be that much memory, and this would be done when making the bytecode, which we generally want done quickly iirc
I see.
if you want to profile it I'd be happy to help analyze the results
But are you planning to implement it to your source code or the compiler itself?
- there's no python compiler per se, just an interpreter (not totally sure if I'm using the terms right feel free to correct me)
- I was planning to implement it so that it'd be used by python to make the bytecode and stuff, so definitely not my source code but rather in the python repository
but all of that is moot if a core dev or someone who knows better how this string concatenation stuff works says it's not worth implementing
it seems it's best for larger strings that are modified more frequently anyway, so there are definitely rooms for different use cases
Has there ever been a suggestion to specify the type of the variable a for-loop iteration is given to?
So that you can do conversions for example with less work and enforce the type
for variable: int in some_string_of_numbers:
...
```For exampleit would attempt to convert the value to an int before assigning it to the variable
to prevent having to do something like ```py
for variable in some_string_of_numbers:
variable = int(variable)
what about
for variable in map(int, some_string_of_numbers):
Fair, it would probably be more syntactic sugar than anything else
It's interpreter my bad.
But yes, this technique has been there for a long time
Someone could have Merged it if it's worth implementing.
It does constant folding through the AST optimizer. https://github.com/python/cpython/pull/2858
I'm not an expert on nodejs, but as far as I'm aware JS doesn't have any way of implementing RAII patterns. And I'd claim that without those, you just cannot do resource management in a sensible way. C++ has constructors and destructors, python has context managers & with-blocks to deal with that.
default to try-finally?
Try-finally is the only option JS has for management, but it simply isn't in the same ballpark as RAII when you are looking for encapsulation and composition of management logic.
@supple venture tbh, try/finally or with statements get nested and messy pretty quickly if you have several resources.
Like, a connection pool, a connection and a cursor
I guess you could do
class ExitStack:
def __init__(self, *callbacks):
self.callbacks = callbacks
def __del__(self):
for cb in self.callbacks:
cb()
and it would work in CPython, but it's a hack
I meant contextlib.ExitStack and contextlib.AsyncExitStack. Those are the core python solutions for situations where there is a dynamic set of resources you need to manage. Exactly for those you mentioned: connections, cursors, etc.
The point I was trying to make is: Languages like Python and C++ have first class concepts for defining managed resources, and for dealing with them as a consumer. JS doesn't. Thus I'd bluntly claim that @prime vine won't see the same level of memory leaks in python compared to nodejs.
huh, I didn't know these things existed, thanks
Test cases for my arbitrary precision arithmetic library floating point implementation are correctly failing as my test result has a higher precision than the machine floating point type (double): that's a win! \o/ https://i.imgur.com/J9iCMxp.png
{kind=link}
thanks!
How does it work? Is it binary floating point or decimal floating point? If binary, is the user in control of how many mantissa bits and how many exponent bits are used, rather than always using the 53/11 of an IEEE 754 binary64?
@raven ridge it is binary floating point with support for dynamic mantissa size
Does the user choose the mantissa size, or is it automatically adjusted?
both
it is a template; you can specify a fixed size mantissa or it can be dynamic based on argument precision for operations
That seems rather strange to me. That gives you two ways of adjusting the precision: either moving the floating point, or adding or subtracting significand bits. How do you automatically decide when to do which?
for an operation I decide on the appropriate mantissa size based on the precision of arguments unless a fixed size mantissa is specified.
it is implemented in terms of 64-bit words; I checked it works with an IEEE 754 128-bit implementation although I need to source some unit tests for high precision tests
I don't think that really answers my question... I can understand how you can choose in advance a number of mantissa bits so the operation doesn't lose precision, but then it seems like what you'd have is a fixed point type, not floating. I'm not seeing how you choose between these two different ways of adjusting the precision - floating the point vs adding more mantissa bits.
there aren't two different ways
if a fixed size mantissa is specified then that is simply a hard limit on how much the mantissa can grow during an operation; there is only one algorithm though
Ok, sure. But if the mantissa is allowed to grow then you have two choices of how to handle multiplying by two: you can make the mantissa one bit longer and set the extra bit to zero, or you can increment the exponent by 1. When do you do each of those?
mantissas only grow by word-size (64 bits)
i.e. mantissa size is a multiple of 64 bits
obviously I also have a separate exponent and mantissa normalisation similar to how IEEE 754 works
Ok, so if you're going to multiply by 2**64, you have two choices for how to represent that: increasing the exponent, or adding another word of mantissa bits set to 64 zeroes. How do you choose which to do?
increasing precision of mantissa does not change the exponent
I guess it could do, might be something to think about during optimization phase which I will start in earnest once all my tests pass
It would if you added new LSBs, or shifted after adding the bits. i guess you're instead adding new MSBs and setting them to 0?
no, the exponent doesn't change if you add LSBs, it would if you add MSBs which might be an optimization to do (see previous comment)
but I tend to renormalize after every operation anyway
also, this is still a work-in-progress so may still have bugs and isn't yet fast enough
currently using karatsuba for multiplication.
i also have repetend support in the mantissa
the number grows if you add LSBs - adding a new least-significant zero is multiplying by two, just like how in base 10 you can multiply by 10 by adding a 0 at the end of a number
no, adding LSBs simply makes the number more precise, it doesn't change the exponent
it doesn't change the exponent, but it makes a bigger number
no it don't
unless you also modify the exponent
1.xxxxxxxxxxxxxxxxxxxyz // y is an LSB, adding z doesn't make the exponent bigger
(for a normalized mantissa)
taking this to base 10, if you've got the number 50 already, and you're representing that as 5 * 10e0, you can multiply that by 10 to get 500 in two different ways. You can either add a digit to the end of the significand, making it 50 * 10e0, or you can increase the exponent, making it 5 * 10e1.
that isn't what we are talking about, we are talking about changing precision for a non-fixed size mantissa.
well, it's what I'm trying to talk about, heh - you've got two different ways to represent a change to a different power-of-two as the multiplier - you can choose to modify the exponent, or you can choose to modify the mantissa (possibly by adding extra LSBs set to 0, in the case of multiplication by a power of two)
and I'm trying to understand when each of those approaches is taken - when an operation results in the exponent changing, and when it results in the exponent staying the same but the mantissa growing more or less precise.
those two things are orthogonal. adding extra fractional places to the end of a mantissa to support a higher precision result of the subsequent operation is unrelated to normal normal/sub-normal exponent based binary floating point math.
godlygeek you work with?
Work with who/what?
I believe there are tools that exist that simplify floating point expressions to minimize floating point error, but I think in general if you'd want to always guarantee correct representation you'd have to have some analysis on the error propagation on your floating point operations?
Hello, guys. I want to ask about FORTRAN. Somebody knows how to embed code from fortran to python ? and is it make a sence? Just i have discipline related with fortran and computional math where we are solves equation via that lang... Also I heard that such lang can adopted to GPU that to make pararell computations)
Yes this is certainly possible with C FFI.
Thanks) also me interested how faster fortran for CUDA than CuPy? did somebody comparisons?
Is there something particular about the C API that changes between versions that makes things that rely on C extensions not work between varying versions of Python 3.*?
I've noticed that there are some packages that work for a specific Python version, say 3.6, and don't work for versions 3.7+.
Do you have some examples? What doesn't work?
I think tensorflow is a popular example for this.
https://stackoverflow.com/questions/52584907/how-to-downgrade-python-from-3-7-to-3-6
It's not really that they don't work on the new version, it's that the C API doesn't make ABI stability guarantees across minor versions, so they need to be recompiled for each new version. The same source code works, but it needs to be compiled again, and the maintainer of the package hasn't yet done that, or hasn't yet uploaded the new build to PyPI
there is now a limited version of the C API that makes ABI stability guarantees, so if an extension chooses to use only that subset it's possible to avoid needing to compile again for each new version.
Ah that is neat, thank you for explaining it to me.
@raven ridge i don't understand why these projects don't build wheels. It's not hard: https://pypi.org/project/coverage/#files

https://docs.python.org/3/library/math.html#math.fsum is an example of an iterated sum algorithm that tries to minimize floating point error.
Wow! I didn't know the math library had this.
I think lots of projects don't automate it, and upload them by hand. Which requires manual work from the maintainer on each new release. And is often dependent on them actually testing with the new version, and that requires that all of their dependencies have been packaged for the new version, recursively...
@raven ridge i should hope tensorflow has the resources to automate this. seriously, it's not that hard.
Yeah. I'm surprised at how long it takes before the ecosystem stabilizes after a new interpreter version is released, but it's not so surprising considering that it requires a lot of different actors who don't work in concert.
more things starting to use the limited ABI would help.
If I build a package using pep517, do I need to ship both the wheel and tar.gz or only the tar.gz is necessary?
Only the .tar.gz is strictly required, but it's preferable to ship the .whl as well. They're faster for your users to install, and safer in that they don't run untrusted code at install time
anyone read this book? does it give solid idea about ML and how to use it

it is specifically for python
No
I don't read this book
Any one here good with web scraping, I need some help
wrong room, this is about advanced discussion on the python language itself. try #❓|how-to-get-help
You guys think I can achieve something like this
Let's say I have a API that uploads a video to a servee
I also have a python script that checks if a file is uploaded or some change occured
Then it takes the video file that is uploaded
Does something let's say with FFMpeg
And upload it to the server again
And delete the old file
I know I need to know somethings about asynchronous programming
But is there a other way
I am making something like youtube
Now am in backend
Hello @eternal root, you should ask in #web-development
I don't think it's related to web development. It's more like server side processing
Hmm I think that would fit in the channel topic
I've had a look at pep 646 (variadic generics), and one thing struck as interesting.
Could the type unpack syntax Generic[*Ts] also be used to define fixed-length tuples generic over N? So something like tuple[*[T]*N] for a homogenous tuple of length N.
From my toying around with PyRight's typing_extensions, it looks like Unpack[Ts] (3.9 syntax compatible type unpacking) only supports TypeVarTuple, and not any unpackable sequence.
I am thinking I can get away with a fixed sized exponent.
we're looking forward to hearing about the Python implementation
me looking at this even tho i don't even know advanced python
what is #internals-and-peps even for
Its for the python language itself, not necessarily about advanced programming concepts
uhhhhh ok
How the language works, why they chose one feature over another feature, the differences between different implementations of Python, etc.
@spark magnet I can't start on the Python implementation until I have sorted out my multi-precision math library.
I am making a Python implementation
Why not language-meta as a name?
We tried a lot of different names, and there's not much appetite for trying more, but you can suggest one in #community-meta if you'd like
Oki
@eternal root u will need something more og a VCS graph to do that, that only replaces if u get that new data. FFMPEG can read URL resources.
Unlimited cloud storage using py,c and fvid
