#algos-and-data-structs
1 messages · Page 89 of 1
hmmm kinda, all with opencv and that center of mass only
oh the white blocks are the ppl ic
hah yes :d
what would be a good website/app for pc to represent a tree graph, specifically for data structure?
Like a tree version of this
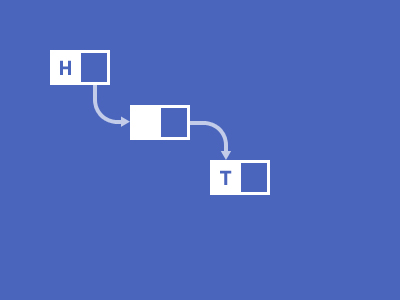
Linked List is a data structure consisting of a group of vertices (nodes) which together represent a sequence. Under the simplest form, each vertex is composed of a data and a reference (link) to the next vertex in the sequence. Try clicking Search(77) for a sample animation o...
???
i believe networkx can
or graphviz
hey so i was asking that i started with machine learning today from a youtuber named techwithtim i did the first one hour of his video and the thing was of linear regressions it \is kewl and interesting i had to download the data folder from a machine learning repository but one thing that ididnt understand was that how can put in my own values do i hv to modify the .csv file or what? and how does the computer get different values from the .csv? or it randomizes...ping if u answer me
Also can we make csv files with notepad and stuff?
@fiery cosmos if the data is small you can hardcode a csv fike else you need to write a program that writes to files. Now if you want to put your own values you indeed want to modify the csv file contents
also, next time look out for channel description, your question goes to #data-science-and-ml
hmmmmm
Ohhh
k
got it
can i make csv files with notepad
and
why does everyone's name has a substring "Gurkan"
ask there
can i make csv files with notepad
@fiery cosmos yes
ook thanks
the gurkan question i just got curious cuz i saw many gurkan's nvm
I have a doubt
So I want to check if a phrase is profane
based on a list of profane words
like the function which checks it should return the probability of its profanity
if its definitely profane return 1
and if its somewhat porfane like 0.8
How can I go about this?
Can someone pls guide me
thanks!
how do you define "somewhat profane"? What rule do you use?
I saw an example here

GitHub
A fast, robust Python library to check for offensive language in strings. - vzhou842/profanity-check
vectorizer = joblib.load(pkg_resources.resource_filename('profanity_check', 'data/vectorizer.joblib'))
model = joblib.load(pkg_resources.resource_filename('profanity_check', 'data/model.joblib'))
def _get_profane_prob(prob):
return prob[1]
def predict(texts):
return model.predict(vectorizer.transform(texts))
def predict_prob(texts):
return np.apply_along_axis(_get_profane_prob, 1, model.predict_proba(vectorizer.transform(texts)))```the predict_prob function here retuns the same
aha this is machine/deep learning
but uses a different wordlist
ohh
is there any other way
to go about this
instead of machine learning
I will learn it but not now
still in school xD
well
?
okay
and if you want another way all I see is do it from scratch(which is more pain)
I can do it
whats the other way
like how to best check for profanity
https://mystb.in/PointingModernTracy.python
This is my current profanity filter I made using regex. I want to make it more powerful though, by making the filter check for words like
if abc is a swear word the filter must detect aabc, abcc also as swear words
@limber zephyr If you want a ratio of matching with a certain profane word, you could use any of the many classic string comparison algorithms such as Lavenstein distances.
Stack Abuse
Introduction
Writing text is a creative process that is based on thoughts and ideas which
come to our mind. The way that the text is written reflects our personality and
is also very much influenced by the mood we are in, the way we organize our
thoughts, the topic itself and ...

thanks a lot man
If speed is a concern, there is a algorithm called 'Aho-Corasick' for pattern searching. There are derivatives of this that search for partial matches using that Lavenshtein algo
If you just want a quick and dirty solution, the python difflib lib has a sequence matcher thats easy to use.
https://stackoverflow.com/questions/10018679/python-find-closest-string-from-a-list-to-another-string/10018734 might be slow tho

Stack Overflow
Let's say I have a string "Hello" and a list
words = ['hello', 'Hallo', 'hi', 'house', 'key', 'screen', 'hallo','question', 'Hallo', 'format']
How can I find the n words that are the closest to "...
can I do py difflib.get_close_matches(list_of_words, possibilities_list) instead of py difflib.get_close_matches(word, possibilities_list)
@vernal venture
def match(self, input_string, string_list):
words = re.findall(r'\w+', input_string)
return [word for word in words if word in string_list]
def determine_profanity(self, phrase):
# exact word-to-word check
if self.match(phrase.lower(),self.get_grouped_profane_list()):
return True
if not self.smart_mode:
return False
# check for differences from profane words
# if smart mode is enabled and the difference is reasonable, return true
for unchecked_word in phrase.lower().split():
close_prob_matches = difflib.get_close_matches(unchecked_word, self.get_grouped_profane_list(),
cutoff=0.75)
if close_prob_matches:
return True
return False
def is_profane(self, phrase):
"""Returns a boolean value,checking if the given phrase is profane or not"""
if self.determine_profanity(phrase):
return True
return False
pf = ProfanityFilter(smart_mode=True)
print(pf.is_profane("luck hahhaha"))```This is what I did
the profanity filter prints true for the word luck
I dont want this
however if abc is a cuss word and I type in abcc
then it works
how to fix this
please help
def match(self, input_string, string_list):
words = re.findall(r'\w+', input_string)
word_list = []
for word in words:
if word in string_list:
word_list.append(word)
return word_list
# need to check for continuous elements like if words[0] + words[1] together produce a profane word
# upto three combinations```Can someone pls guide me how to do this
the commented part
need to check for continuous elements like if words[0] + words[1] together produce a profane word
upto three combinations```WHAT S THE HARDEST ALGHORITHM
given a brainfuck program, determine if it ever ends.
hey guys
how does the hash() function work?
everytime i run it to a tuple it always produce a different output
hash() calls __hash__ on its argument
if you see this there is some math going on and it will return the result after the math
bang bang bussi bang
If I put in a list from a previous function into another function as a parameter how do I make it work?
in a way that the second function edits the list
its pretty big lemme just give you the gist of it
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
and send the link
so basically I have two numbers in the list and I have to convert the integers into string using the second function
the list is made in the first function
problem is I keep getting the list as undefined
as a parameter that is
hmm I can't help you without seeing the code
alright I'll post
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
okay I'll look into it
def drawcards():
import random
Player1 = (random.randint(2, 14)), (random.randint(2, 14))
Player2 = (random.randint(2, 14)), (random.randint(2, 14))
if Player1[0] >= Player1[1]:
return Player1[0], Player1[1]
elif Player1[1] >= Player1[0]:
return Player1[1], Player1[0]
if Player2[0] >= Player2[1]:
return Player2[0], Player2[1]
elif Player2[1] >= Player2[0]:
return Player2[1], Player2[0]
return Player1
return Player2
card2str(Player1)
but you get the idea
here you are returning from the function so card2str(player1) never gets called
why do you want to do that method inside that function (the logic is what I am asking)
so that I can assign the letters to when the integers are those values
I just want to pass on the values generated by Player1 my guy
the 2 values that is
keeps giving me undefined
okay so these statements will never be executed
if Player2[0] >= Player2[1]:
return Player2[0], Player2[1]
elif Player2[1] >= Player2[0]:
return Player2[1], Player2[0]
return Player1
return Player2
card2str(Player1)
yeah for now
No they will not in any case
since the first if - else block have return
alright lets say those are dealt with
I jsut want to know
OHHH
i get it now
I get what you mean
also player one is a tuple not a list
so I can just return at the end
yes
I'll just switch those positions
0 = 1
somethin like that
then maybe it'll work I guess
thanks
I just want to make sure the values are descending for the list
also next time check the channel descriptions, if you want to get help with algorithms and data-structures then this is the perfect place, else if you have problems with python implementations be sure to check out #❓|how-to-get-help
yeah
I give up, anyone have any clue how to solve?
deadline in 40 minutes, spending ages on it.
Or a tip/general direction to take a look at would also be great.
what's the answer to the hint?
it would seem to me that an internal node cannot have more than 4 edges
that's right
I don't understand how that helps me.
I'm trying to topologically bound it, and algebraically, but cannot find a way either way
even still, consider a tree with 5 nodes. One in the middle, and 4 leaves
this has 4 leaves, and 5 nodes. This exceeds the supposed upper bound?
nevermind, I'm no longer thinking straight.
that's the closest you can get to the bound
it's exactly the bound
well, i guess all the:
o o
| |
o--o--o--o
| |
o o
type graphs also hit the bound
well i think u can try out max leaves are in a tri-ary tree
Right, I understand. Let me try to formulate a formal proof for it, thank you 🙂
u only need to show it works for trees with 3 branches
cuz trees with 2 1 or 0 are bounded by the 3 branches
ofc if they have the same height
I think you can use mathematical induction?
not sure what other way u can go about this
yeah I always try mathematical induction first to prove something xD
well usually with these types of problems induction is the way to go
I really need to hurry to solve it, so I kind-of-messily did it as such
not too pretty, but hopefully enough 😉
dont know if thats formal tho
It is definitely not.
Yeah, I should use a formal proof structure
I should probably use case distinction with induction
But I need to do 2 more exercises within 7 minutes.
bro...
gamer
In the game “Battleships”, each player has an 8x8 grid, on which they place 5 ships of varying lengths. The players take turns firing shots at the other player’s grid by giving (X, Y) coordinates.
If the (X, Y) coordinate given contains part of an enemy ship, that portion of the ship is destroyed, and the opposing player announces a “hit”. Once all portions of a ship are hit, that ship is “sunk”. A player wins once they sink all of their opponent’s ships.
Consider the following points:
· How could you represent the 8x8 grid? If there are multiple options, what are the pros and cons of each?
For the above question
I am not sure on what the appropriate data sturcture to use when storing the board
2d list?
But why @agile sundial
And by 2d u mean
[0,0,0,0
0,0,0,0,
0,0,0,0]
For example
Or?
the lists still have to be separated by commas
yeah
Why is that the best tho?
idk if it is, it's just the first one that came to mind
It depends on what information you want to store on the board
and how you're going to use it
def match(self, input_string, string_list):
words = re.findall(r'\w+', input_string)
word_list = []
for word in words:
if word in string_list:
word_list.append(word)
return word_list
# need to check for continuous elements like if words[0] + words[1] together produce a profane word
# upto three combinations```
@limber zephyr
can someone pls help me with this?
Hi
@limber zephyr What is your question
I am not sure tho @flat sorrel
then start with the generic 2d array
Ok thanks @flat sorrel
im having issues with storing and returning the value of the removed node. help ples.
You're returning the node itself, not the value stored in the node
how would i retrieve the value inside of the node then? @flat sorrel
guys tensor flow has been compiling for forever can someone pls tell me whats happening
i was tryna get bazel idk how all this happend
should i end the compile?
@fiery cosmos are you pip installing it or are you actually compiling from source?
@elfin storm your nodes should have an attribute named "value" or something like that
also I see that you're using two leading underscores to indicate a private value; one underscore is preferred
what is a good resource for learning data structures and algorithems for free?
is it a course?
it's a textbook
books
there's pdfs floating around
its on python right?
algorithms and data structures don't care what language you implement them in
it's in pseudocode
yeah, A&D textbooks usually use pseudocode
which you should be able to translate into python, given a decent understanding of python syntax
if you translate that pseudocode into python it should be really helpful for you
ayyy by the mouth of two
pog
oh lol, thank you so much
this is the one right? [https://github.com/CodeClub-JU/Introduction-to-Algorithms-CLRS]
looks like it
The almighty clrs
á
What does that have to do with python
wait
hold on
ohhh shitttt dude i thought python was just the name of the discord
didnt realize it was for the program lmfao my bad boys
it is a programming language
wait what did he post lol
His classwork
hey friends, im wanting to verify the sizes of messages im sending in json through kafka, is there a built in function to see the size of something? i know of sys.issizeof() but from my understanding thats telling me the size in memory
more or less need it to write a test as my messages will get rejected if they > 1MB
i could be misunderstanding the concept a little..
ghost ping?
hey guys new here need some help with using how ti find gcd - Euclid’s algorithm - in python
hey friends, im wanting to verify the sizes of messages im sending in json through kafka, is there a built in function to see the size of something? i know of
sys.issizeof()but from my understanding thats telling me the size in memory
@viscid kernel ...the size of the JSON?
len?
@brave oak no in bytes
@brave oak no in bytes
@viscid kernel but why?
like you mean a JSON format string, right?
yes, im shipping it elsewhere via kafka
but yeah in json
but yeah in json
@viscid kernel yeah then that's the length of the JSON string
the size of the object would be the amount of memory the Python object wrapping the data in question takes, not the size of the data itself when serialised and transmitted
@fiery cosmos It's actually quite simple
def gcd(a, b):
if not a:
return b
return gcd(b % a, a)
someone pls help me
I need list matching
or matching each word of a sentence with a list
it should also be fast
fuzz didnt work
I explained why there
pls help me
thanks!
def concat(queue) :
l = []
while not queue.is_empty() :
l.append(queue.pop())
for i in range(len(l)) :
l[i] += l[i+1]
return l
The goal is to concatenate elements of a queue
like it has to pass these tests
>>> queue = Queue()
>>> queue.push('ab')
>>> queue.push('cd')
>>> concat()
'abcd'
>>> queue.is_empty()
True
Anyone help ?
your code will add together the zeroth element and the first element, then on the next iteration it will add together the first and the second, then on the next it will add the second and the third
are you trying to implement it as a doubly-linked list like a deque
I usually make a "Block" class first then build the deque from blocks
Good idea I'll try it
@agile sundial I think thats goal lol cuz the elements of the queue are strings
sure, but try it
oh sorry , you're right it gives me : 'ab, abcd'
you could just be cheeky and use a string buffer
I wont need a list I think ? @stable pecan
no
Okay
this is what i meant with the buffer:
In [16]: from io import StringIO
In [17]: queue = StringIO()
In [18]: queue.write('ab')
Out[18]: 2
In [19]: queue.write('cd')
Out[19]: 2
In [20]: queue.getvalue()
Out[20]: 'abcd'
probably not what they want from you though
Ohh i know but like you said its not acceptable
Normally its not that hard i just need to think easy
its not that complicated
i mean you could implement it with a list -- and it's not even inefficient if you're join ing the list afterwards, but i don't know what exactly they intend for you
put if you're suppose to be popping the 0th element off, then maybe they want a deque data structure
Ohhhhh thats it
wait
I used the keyword : join
like :
return ''.join(queue)
It works
Thank u @stable pecan
np
what's the problem?
Hello, my program below display an encryption grid but is it optimized?
def grille():
alphabet = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
print(" A B C D E F G H I J K L M N O P Q R S T U V W X Y Z")
print("-" * 55)
y = 1
i = 0
for x in alphabet:
deb = alphabet.index(x)
if i == 0:
print(x + " | " + " ".join(alphabet[deb:26]))
i = i + 1
else:
print(x + " | " + " ".join(alphabet[deb:26]) + " " + " ".join(alphabet[0:y]))
y = y+ 1
grille()```
!code
Discord has support for Markdown, which allows you to post code with full syntax highlighting. Please use these whenever you paste code, as this helps improve the legibility and makes it easier for us to help you.
To do this, use the following method:
```python
print('Hello world!')
```
Note:
• These are backticks, not quotes. Backticks can usually be found on the tilde key.
• You can also use py as the language instead of python
• The language must be on the first line next to the backticks with no space between them
This will result in the following:
print('Hello world!')
but anyways, you can use enumerate to get the index of the element while looping through alphabet. That way you don't have to waste time searching for the index of each element
the usage of i and y is redundant if you follow my above suggestion
the size of the object would be the amount of memory the Python object wrapping the data in question takes, not the size of the data itself when serialised and transmitted
@brave oak right gotcha, i guess im wondering if theres a way to gauge the latter
@brave oak right gotcha, i guess im wondering if theres a way to gauge the latter
@viscid kernel yeah, so that's just the length of the string in JSON format, right
@brave oak ah ok, apologize my nativity, didnt realize that would correlate to bytes
@flat sorrel Ok , I don't often use enumerate, thank you !
np
Technically, The length of a string doesn't nessacerily corelate to bytes, it corelates to characters, which can be 8, 16 or 32 bits long, depending uuencode details. JSON only specifies that certain characters need to be escaped, so you may want: convert to string; convert to bytes; take length. For an int that would be len(str(value).encode()) I'm not sure what it will be for your JSON library.
(unicode, not uuencode — the latter is an old email helper tool)
Technically, The length of a string doesn't nessacerily corelate to bytes, it corelates to characters, which can be 8, 16 or 32 bits long, depending uuencode details. JSON only specifies that certain characters need to be escaped, so you may want: convert to string; convert to bytes; take length. For an int that would be len(str(value).encode()) I'm not sure what it will be for your JSON library.
@chilly valve thanks, this makes sense
Could someone assist me with singly linked lists? I need help with adding nodes in between the linked list
do you mean inserting a node?
what are you having trouble with?
Creating an insertAfter function
insertAfter takes two parameters, an integer index (0 and higher) and a string value, creates a new node object
with the string value as the new node’s element, and inserts that node object after the ith element of the SLL. For
the purpose of this method the items of the SLL are numbered starting with 1, not 0. If the value of the index is
greater than the number of items in the SLL the new node is to be inserted after the last item (after the rear or tail)
and becomes the new rear or tail.
have you tried anything?
"""LIFO Stack implementation using a singly linked list for storage."""
#-------------------------- nested _Node class --------------------------
class _Node: # "inner" class
"""Lightweight, nonpublic class for storing a singly linked node."""
__slots__ = '_element', '_next' # streamline memory usage
def __init__(self, element, next): # initialize node's fields
self._element = element # reference to user's element
self._next = next # reference to next node
def setNext(self, next):
self._next = next
def getNext(self):
return self._next
def setElement(self, element):
self.element = _element
def getElement(self):
return self._element
#------------------------------- stack methods -------------------------------
def __init__(self, head = None, size = 0):
"""Create an empty list."""
self._head = head # reference to the head node
self._size = size # number of stack elements
def getSize(self):
"""Return the number of elements in the list."""
return self._size
def isEmpty(self):
"""Return True if the list is empty."""
return self._size == 0
def add (self, element):
"""Add element element to the end of the list."""
node = self._Node(element, None)
if self.isEmpty():
self._head = node
else:
cursor = self._head
while cursor.getNext() is not None:
cursor = cursor.getNext( )
cursor.setNext(node)
print('Adding # ', self._size, ' element: ', node.getElement())
self._size += 1```this was given by the professor
and your attempt at the insertAfter function?
"""Insert an element after the ith element of the list."""
node = self._Node(element, None)
currentNode = self._head
#If the list is empty, then node wil be inserted at the head
if self.isEmpty():
self._head = node
#Detemine if i is greater than the size of Singly Linked List
if i > self.getSize():
self.add(element)
#insert in the interior
counter = 0
while True:
if counter == i:
prevNode._next = element
element._next = currentNode
break
prevNode = currentNode
currentNode = currentNode._next
counter += ```and the cases for the specific function
Cases: (1) insert into empty list, (2) insert before the head, (3) insert in the interior
what doesn't work
hey @lusty sand and I are working on this together. We are having issues trying to get and set the next value. He keeps getting an error that says something along the lines of "_next dosn't allow str values"
I think we are just stuck trying to call and assign the values because the nested class and variables are private
can you provide, like, the actual traceback?
hold on, he is running his code rn
AttributeError Traceback (most recent call last)
<ipython-input-4-de4afb125b4a> in <module>
8 SLL.remove()
9 elif a[0] == "IA":
---> 10 SLL.insertAfter(int(a[1]), a[2])
11 else:
12 pass
<ipython-input-1-c99b8eff9a2f> in insertAfter(self, i, element)
102 if counter == i:
103 prevNode._next = element
--> 104 element._next = currentNode
105 break
106 prevNode = currentNode
AttributeError: 'str' object has no attribute '_next'
thank you both for helping! 🙂
well, element is a string, apparently.
if you're inserting into a linked list, you probably forgot to wrap the "element" (the element's value, really) into a Node
how do you do that?
you need to create a node with the string as a value
would either one you be available to join a voice channel w us?
I cannot
these are the samples we have been trying to work off of: https://stonesoupprogramming.com/2017/05/19/singly-linked-list-python/ https://stackoverflow.com/questions/41646430/inserting-node-at-a-specific-location-python https://stackoverflow.com/questions/46350266/insert-a-node-at-nth-position-in-linked-list-in-python

Many of my programming students get asked to implement Linked Lists as a way to learn about data structures in programming. Now I am going to be very honest about this topic when it comes to Python…
Stack Overflow
This question is a hackerrank challenge. link here: https://www.hackerrank.com/challenges/insert-a-node-at-a-specific-position-in-a-linked-list
"""
Insert Node at a specific position in a linked l...
Stack Overflow
I am trying to insert a node "item" in position "index" in a linked list, I have the following code and to me it sounds fine, but it is not working right.
I would really appreciate if someone can ...
do any of them show the wrapping of the element?
Yes,
Temp = Node(item)``` in that last link.oh it’s a little weird that the Node class is inside the List class
class _Node: # "inner" class
"""Lightweight, nonpublic class for storing a singly linked node."""
__slots__ = '_element', '_next' # streamline memory usage
def __init__(self, element, next): # initialize node's fields
self._element = element # reference to user's element
self._next = next # reference to next node```exactly!
lol yeah, i think that is what is throwing us off
I think self.next should be another instance pointer of the class, as in C
what would that mean in Python terms?
We dont' have a pointer class in python, you'd put the regular object there.
* is the operator for unpacking
self.next is actually self._next... are we allowed to switch it from private to public for this method?
@tardy rose in Python, things aren't really copied ever without you explicitly asking for that. Everything is a "pointer" in a way.
There is no private in python, but _ is used to tell other developers to treat it as if it's private
U do have a pointer class in Python as u can do **args and other things
uh that's not a pointer
that is not a pointer
Why not?
just because something uses an asterisk in one language doesn't mean all occurences of * in other languages mean the same thing 😉
the C equivalent would be ...
what. it's just not a pointer
* and ** in python have no relation to dereferencing, as simple as that
prevNode._next = element
This line seems like a problem, you are using element here, which is the string value, and not the node you made.
so how do we access the next element? When we try to call the getNext() and setNext() methods?
this is what is have rn def insertAfter (self, i, element): """Insert an element after the ith element of the list.""" node = self._Node(element, None) #-------my code starts here------ cursor = self._head if self.isEmpty() or i == 0: self._head = node elif i >= self.getSize(): self.add(element) else: cur = self._head count = 0 while count < (i-1): cur = cur.getNext() count += 1 next = cur.getNext() cur.setNext = node
- in Python is not as the same in C, but it can be used in number of places to store more info then "u can"
as such
>>> mylist = [1, 2, 3, 4, 5]
>>> mylist
[1, 2, 3, 4, 5]
>>> start, *list_, final = mylist
>>> start
1
>>> list_
[2, 3, 4]
>>> final
5
>>> start1, list_1, final1 = mylist
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 3)
>>>```this is the error i'm getting ```AttributeError Traceback (most recent call last)
<ipython-input-57-d5bf88704ca6> in <module>
51 SLL1.remove()
52 elif a[0] == "IA":
---> 53 SLL1.insertAfter(int(a[1]), a[2])
54 else:
55 pass
<ipython-input-56-d6764c06cf5b> in insertAfter(self, i, element)
98 count += 1
99 next = cur.getNext()
--> 100 cur.setNext = node
101
102
AttributeError: '_Node' object attribute 'setNext' is read-only```
You are trying to reassign the setNext method to be the node, instead of calling the setNext method with the node
^
Better explanation then mine
@tardy rose
- in Python is not as the same in C, but it can be used in number of places to store more info then "u can"
as such
How's that related to pointers?

Well it is what pointers do, and I have just realised I was only talking about dynamic lists in c as pointers and not the entire subjects, apologies
...are you thinking about vectors, perhaps?
probably, yeah
i think it's the same everywhere
vectors usually means an array of pointers.
Ok, well I am just used to calling them 2d pointer arrays, thats what I learned...
yeah, a vector is a contigious dynamic array, basically https://en.cppreference.com/w/cpp/container/vector
analogous to python's lists
Is this inbuilt feature in C++?
yup, Python lists are secretly Vectors of pointers to PyObjects
Bcus in C I had to create and manage it all by myself
Is this inbuilt feature in C++?
well, yes, it's in the standard library
Bcus in C I had to create and manage it all by myself
yeah, in C you don't get builtin vectors
I think that was why I am unfamilier with that term
okay, thank you guys for trying to help. Really appreciate it!
I'm still struggling
with what error?
so i'm using this guys code as a reference
its from a youtube
In this lecture, you learn the Python implementation of new node insertion in between two other nodes of a Singly Linked List
okay, and what is your problem?
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-4-de4afb125b4a> in <module>
8 SLL.remove()
9 elif a[0] == "IA":
---> 10 SLL.insertAfter(int(a[1]), a[2])
11 else:
12 pass
<ipython-input-1-c99b8eff9a2f> in insertAfter(self, i, element)
102 if counter == i:
103 prevNode._next = element
--> 104 element._next = currentNode
105 break
106 prevNode = currentNode
AttributeError: 'str' object has no attribute '_next'
its the same one
but i dont get why he can do newnode
you got the answer here
You are trying to reassign the setNext method to be the node, instead of calling the setNext method with the node
@desert cedar this one?
like said above, you can't do ._next on a string, because strings don't have this attribute (duh). Wrap the string in a Node first.
the code you are using (or writing) has two concepts: SingleLinkedList which is the container and Node which wraps the actual data with bookkeeping information (next and prev)
Yeah, you made a node earlier in the function, use that instead of the string.
you can’t just add a string to the List, you have to add a Node
something like new = self._Node(element, currentNode) prevNode._next = new
cur.setNext(node) ?
holy shit it worked!
or that, if you have a method then use that instead of changing internal data directly
(but that code is strangely written, it is not very idiomatic for Python)
I really appreciate the feedback honestly
counter = 0
while True:
if counter == i:
prevNode._next = node
node._next = currentNode
print('Adding # ', self._size, ' element: ', node.getElement())
break
prevNode = node
currentNode = node._next
counter += 1 ```some odd reason it's skipping the if statement
counter = 0
while True:
if counter == i:
prevNode._next = node
node._next = currentNode
print('Adding # ', self._size, ' element: ', node.getElement())
break
prevNode = node
currentNode = node._next
print(counter)
counter += 1 ```so this is with the print statements and it is equating to the i variable
no, print counter and i before the if, otherwise you won’t see anything!
A3trans = ('A,Washington',
'A,Adams',
'A,Jefferson',
'A,Madison',
'A,Monroe',
'A,Quincy Adams',
'A,Jackson',
'A,Van Buren',
'A,Harrison',
'A,Tyler',
'A,Polk',
'A,Taylor',
'A,Fillmore',
'A,Pierce',
'A,Buchanan',
'A,Lincoln',
'A,AJohnson',
'A,Grant',
'A,Hayes',
'A,Garfield',
'A,Arthur',
'A,Cleveland',
'A,Harrison',
'A,Cleveland',
'A,McKinley',
'A,TRoosevelt',
'IE,Wilson,A,TRoosevelt',
'IE,Taft,B,Wilson',
'A,Coolidge',
'R',
'R',
'R',
'A,Harding',
'IE,Wilson,B,Harding',
'A,Coolidge',
'A,FDRoosevelt',
'IE,Hoover,B,FDRoosevelt',
'IA,2,Shuman',
'IA,40,Kennedy',
'A,LBJohnson',
'IE,Nixon,A,LBJohnson',
'IE,Eisenhower,B,Kennedy',
'IE,Truman,B,Eisenhower') ```it says it's appending to the linked list, but when i call the showList function. it's not showing up
r u like looping through a linked list
Hi all,
Sorry if this is the wrong channel to ask this:
I have a nested loop inside a nested loop (with all three loops having a range of 50). In the innermost loop, I have a code that takes the combo of i, j, k and runs a method, which takes 3 seconds. This means there are 125,000 combinations, with a 3 s runtime for each... how do I approach running this in a way that won't take days? Should I spawn 10 threads in the innermost loop so that the time is reduced by a fifth for each run of the inner loop? Is there an easier way that I'm missing? Thanks!
there's itertools.combinations
you need to use [ ] not ( ) if you want a list returned
and there's no point in initialising elem1 and elem2
there aren't tuple comprehensions
maybe replace the () for the tuple with [] for a list to use list comprehensions, then wrap that instde a call to tuple()?
you want a tuple of tuples? return tuple((elem1, elem2) for etc etc )
lines = Image.new("1",(w,h),1)
linesDrawer = ImageDraw.Draw(lines)
radius = max(w,h)*1.5
for point in [(radius*cospi(1/12*i*2),radius*sinpi(1/12*i*2)) for i in range(12)]:
linesDrawer.line([(w/2,h/2),point],fill="black",width=ceil((w+h)/1000))```This script is supposed to generate lines from the center of a rectangle to 12 points on a circle that encapsulates that ractangle to produce 12 equally sized angles, but the only thing that I can't seem to get to properly work is the sizing of the angles- no matter how hard I try, one side will have larger angles than another, and I can't understand why this might be happening. To clarify, `w` is the width of the rectangle and `h` is the height of the rectangle. Any ideas what I've done wrong?Here's what the code above produces, which is the closest I've been able to get https://cdn.discordapp.com/attachments/763591770369818624/768288143463284736/output.png
{kind=link}

Hey guys
is there a way to have [(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)] in one line?
here's my code
a = np.ones((5,1), dtype=[('a', 'i4'), ('b', 'i4'),('c', 'i4'),('d', 'i4'),('e', 'i4')]) print(a)
technically [(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)] is one line xD
Yeh that's what I was confused about originally lol
no i mean
I know what you mean now, dw
You're wanting it to be printed in one line, not as in coded in one line
Well, new lines are represented as \n in strings
and i want it to be [(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)]
So try just removing all the instances of \n
not sure why you want to do that but I guess...
there's no \n here....
Not in the text lol
this is numpy python structure array
str(a).replace('\n', ' ')
^^^ Exactly
!e
import numpy as np
a = np.ones((5, 5), dtype=int)
print(str(a).replace('\n', ' '))
You are not allowed to use that command here. Please use the #bot-commands channel instead.
is that what you need?
no i mean
Are you meaning print(np.ones((5,1), dtype=[('a', 'i4'), ('b', 'i4'),('c', 'i4'),('d', 'i4'),('e', 'i4')]))
As in, not having to set it to a variable first before printing it?
use slice assignment
[(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)]
Ok if you're wanting to change the result then that's not the code, is it lol
Me and Darklight have already gave you the answer multiple times
print(str(a).replace('\n', ' '))
no lol
???
the picture has the result of [(1, 1, 1, 1, 1),(1, 1, 1, 1, 1)(1, 1, 1, 1, 1)(1, 1, 1, 1, 1) (1, 1, 1, 1, 1)]
and i want it to be [(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)]
how can i change it?
Read above
Ooooh right ok I get you know, sorry lol
import numpy as np
a = np.ones((5, 5), dtype=int)
a[1:-1, 1:-1] = 0
why
it's the part of the assignment lol
Make a 5x5 array filled with 1's with column names of 'a','b','c','d','e', and types of 32 bit int; do this on only 1 line of code
The output will look like this: [(1, 1, 1, 1, 1) (1, 1, 1, 1, 1) (1, 1, 1, 1, 1) (1, 1, 1, 1, 1) (1, 1, 1, 1, 1)]
import numpy as np
a = np.ones((5,1), dtype=[('a', 'i4'), ('b', 'i4'),('c', 'i4'),('d', 'i4'),('e', 'i4')])
print(a)
it doesn't really make sense to hollow out the middle of a structured array like that but ok
is my code fine?
doesn't it already match the output?
I don't get the problem
why do you have to assign zeros?
because it is the second question
Change every value in it that is not on the edge of a zero; do this on only 1 line of code
The output will look like this: [(1, 1, 1, 1, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 0, 0, 0, 1) (1, 1, 1, 1, 1)]
a = np.ones((5,1), dtype=[('a', 'i4'), ('b', 'i4'),('c', 'i4'),('d', 'i4'),('e', 'i4')])
a[1:-1, 1:-1] = 0
print(a)
so i might be wrong on my 1st question
np
hey about that assignment again
he wants me to Create a view
does it affect to the original "a" ?
or that view is a copy of "a"
you can check that easily by printing the original array afterwards
look up numpy on what a "view" is
ok got it
just last question
Create a second view of the first view that shows only the middle 9 places; do this on only 1 line of code
The output of the 2nd view will look like this: [(1, 0, 1) (1, 0, 1) (1, 0, 1)]
oh nvm let me figure it out
is this right?
c = b[1:4][['b', 'c', 'd']]
I need some help with a question

Codeforces
I have tried using 2D DP but i failed to get it AC
so when doing dijkstra's can i stop immediately once i reach the end which i was trying to find the lowest cost to
(ping 2 reply)
@eager hamlet no, you have to process every node in the queue
otherwise there might be a shorter path that you haven't discovered yet
ok then
can anyone suggest me a good place to start learning ds and algo , im familiar with python's buit in data structures , but not user defined ones like trees etc
Hello folks, I've a question: how would you look for thousands of strings within a file ?
would you build a big regexp ? another way ?
For each word in your file, check against the list of words to match against. The words to match against can be stored in a https://en.wikipedia.org/wiki/Trie to speed up the matching process by reading your word character by character and navigating down the trie accordingly
@lilac geyser
np
Currently i'm reading a document and they give the
following hex string in their document 41d56acebac1dd44c1297ad31f6f788abb580bbeda
and i need to convert to this string TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE. Any one know what kind of string TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE is? so i can write a converter
it doesn't mention any where in their document believe me i tried
nvm i found out it's base58, took a while to convert...
anyone know how to convert base58 to hexadecimal in python?
anyone know how to convert base58 to hexadecimal in python?
@coarse bluff you have it as a base-10 int already?
or do you need help wit htaht part too
so i need to convert from hex string 41d56acebac1dd44c1297ad31f6f788abb580bbeda to this base58 TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE and i can't find a way. In the document i'm reading it tell me that one is hex string and another is base58 , now i need to write a function to convert between those 2 with the result above @@! i'm really bad at string converting at you can see @brave oak
somehow TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE is 41d56acebac1dd44c1297ad31f6f788abb580bbeda and i need to convert so i can do comparision @@!
from trongrid document owner address in base58 or hex
>>> int('41d56acebac1dd44c1297ad31f6f788abb580bbeda', 16)
96216003348366323833159490712672064757310392352474
this is the simple part
apparently there's a base58 package
you can try using that
unless you really want to write your own converter
which is 🥴
well i tried
import base58
hexstring= "41d56acebac1dd44c1297ad31f6f788abb580bbeda"
unencoded_string = bytes.fromhex(hexstring)
encoded_string= base58.b58encode(unencoded_string)
print(encoded_string)
but it came out 53oCBnvf5mnzaJpr94p1BjxNEGq5j instead of TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE
i think trongrid documents is just messing with me
well yes you can check the api https://api.shasta.trongrid.io/v1/accounts/TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE/transactions?only_to=true&min_timestamp=0&only_confirmed=True @brave oak , if you replace TVRet35bBbkiEz455NFmLvvtSRMZYCD5nE with 41d56acebac1dd44c1297ad31f6f788abb580bbeda it still return the same result
and it's in to_address of the json too
i don't know what that is base58 pretty new to me
yeah
but you could conceivably make it 12345678qwertyu
maybe they use different alphabet
okay so get a known base58 string and int
and convert it
and see if you get the expected result
if you don't, clearly the alphabet is different
well i tried
import base58 hexstring= "41d56acebac1dd44c1297ad31f6f788abb580bbeda" unencoded_string = bytes.fromhex(hexstring) encoded_string= base58.b58encode(unencoded_string) print(encoded_string)but it came out
53oCBnvf5mnzaJpr94p1BjxNEGq5jinstead ofTVRet35bBbkiEz455NFmLvvtSRMZYCD5nE
@brave oak i know that this doesn't work in python so they must be using different alphabet
this is their document i'm reading https://developers.tron.network/reference#transaction-information-by-account-address
TRON Developer Hub
@brave oak i think i found trongrid alphabet , from trongrid alphabet code in their github
const ALPHABET = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz';
can you check if this is correct ?
i finally made the conversion jesus f*cking christ that took the whole afternoon
import base58
to_base58 = base58.b58encode_check(bytes.fromhex("41d56acebac1dd44c1297ad31f6f788abb580bbeda"))
print(to_base58)
Problem
Pattern Matching: You are given two strings, pattern and value. The pattern string consists of just the letters a and b, describing a pattern within a string. For example, the string catcatgocatgo matches the pattern aabab (where cat is a and go is b). It also matches patterns like a, ab, and b. Write a method to determine if value matches pattern.
Brute Force Solution:
We could do this by iterating through all substrings for a and all possible substrings for b. There are O( n^2 )
substrings in a string of length n, so this will actually take O( n^4 ) time. But then, for each value of a and b,
we need to build the new string of this length and compare it for equality. This building/comparison step
takes O(n) time, giving an overall runtime of O(n^5 ).```
Can someone please help me understand what this brute force solution is even trying to do?
```for each possible substring a
for each possible substring b
candidate = buildFromPattern(pattern, a, b)
if candidate equals value
return true```please tag me to notify
@ebon yarrow the brute force approach is simply taking all possible subsets of the main string first. Then, for each pair of possible subsets it uses the pattern to construct back "some" string. For example, if the pattern was aabab for catcatgocatgo, then the brute force first takes a random substring. Say it takes "at" and "o". Then it constructs the pattern version of this string. "atatoato" (note, aabab). Then it compares this vs main string "catcatgocatgo". Mismatch? Keep going.
@ebon yarrow I dont know if this would help, but what I would do is take advantage of the fact that there are only ‘a’ and ‘b’ in the pattern. What I mean is, all string ‘a’s and all string ‘b’s will have the same length, respectively. So, I would first count the ‘a’s and ‘b’s in the pattern and then check to see if you can make a combination of the length of the value with a combination of {len(a) * (number of times a appears) + len(b) * (number of times b appears)} . You could easily do this by starting from 1, set the len(a) to an integer and if {len(value) - len(a) * (how many times a appears)} is divisible by (number of times b appears), there you have a set of lengths for string a and b.
Next, according to the pattern and lengths for a and b, you can get the as and bs using string slicing. For instance, in ‘catcatgocatgo’ and ‘aabab’, you have 3 as and 2 bs that make up a combination of 13 letters. Using the mentioned algorithm, you have a set of (1, 5) , (3, 2) for the lengths of a and b(because 1 * 3 + 5 * 2 = 13). Taking the set (1,5), because the pattern is aabab, you first get the first string that consists of 1 letter and save it, which is ‘c’ in ‘catcatgocatgo’. Then, there’s another a in the pattern so you get the second string with length 1, which is ‘a’. However, our previously saved value of string a is ‘c’, not ‘a’, so you break out of the loop for this set (1,5).
Checking all the sets ( like the (1,5) and (3,2) ), if any of them can pass( meaning all string ‘a’s match and all string ‘b’s match ), you return True. If by the end, none matches, you return False.
Time complexity : In the first part, since number operations take no time, it takes O(len(value)) time. In the second, in each iteration of each set, you slice the values according to the pattern and check if all ‘a’s and all ‘b’s match, so the worst case scenario for this iteration is O(len(value)). Also, the maximum number of sets we can get is len(value)/2 (Now that I think about it, if you think about a pattern like ‘ab’, it always matches so you should have a if statement saying if the number of times a and b appear is 1 each, you return True. But if you think of a pattern like ‘aab’, you have len(value) / 2 times that you get the value a and since b is just 1* any number, you can make a combination for all len(value)/2 ‘a’s. So max time complexity for number of sets is len(value)/2). To sum up, the worst case scenario is O(len(value) ^ 2), but usually it would take much less because you don’t get that many sets.
Now this is a BIG improvement from n^5
Do you want a test code?
Actually, here's the repl.it code @ebon yarrow

from collections import Counter
def PatternMatching(pattern, val):
if pattern == 'ab' or pattern == 'ba':return False
count = Counter(pattern)
n = 1
validSets = []
while n * count['a'] < len(val):
if (len(val) - (n * count['a'])) % count['b'] == 0:
validSets.append((n, int((len(val) - (n * count['a'])) / count['b'])))
n += 1
for s in validSets:
a, b = '', ''
n = 0
notValid = False
for p in pattern:
if p == 'a':
if a == '':
a = val[n:n + s[0]]
elif val[n:n + s[0]] != a:
notValid = True
break
n += s[0]
elif p == 'b':
if b == '':
b = val[n:n + s[1]]
elif val[n:n + s[1]] != b:
notValid = True
break
n += s[1]
if not notValid:
return True
return False
in this code,
print(PatternMatching('aabab', 'donaldtrumpdonaldtrumpfuckdonaldtrumpfuck'))
which is in the repl.it, you can see it returns True
You can easily see it's O(n^2) in the code.
Can someone remind me what the |l X - m l|^2 meant in K means? it is not the eucledian distance or is it?
it is
i have a feeling its the square of the euclidian distance or sth along that line
it looks like its sth that goes and minimizes distances
euclidean distance is already defined as sqrt(map(square, xs))
from my understanding k means just simply minimizes distance
formally, ||x||^2 is the l2-norm, which is basically euclidean distance
it's also called euclidean distance, for a good reason
which makes sense in this case
How can I read in a binary file and convert the byte string to a normal string but still maintain the character placement
is what normal
Does anyone know a good data structure and algorithm course i can take?
mit ocw
yeah that mit ocw algorithm course is fantastic https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-006-introduction-to-algorithms-fall-2011/

MIT OpenCourseWare
This course provides an introduction to mathematical modeling of computational problems. It covers the common algorithms, algorithmic paradigms, and data structures used to solve these problems. The course emphasizes the relationship between algorithms and programming, and int...
Can I ask calculus questions ?
yes ofcourse all math, algorithm, general cs is this channels topic
Great !
I'm currently studying limits, But I still don't get what can I use it for irl ?
Or in ML for example, Since I'm studying for ML and DS
limits -> derivatives -> ml
Studying Limits for ML is good, but you don't apply it directly in ML or DS, you apply it indirectly by computing derivatives for some algorithm, also I think you will see statistics more than calculus in ML or Data-science
I know a lot of statistics, Like a decent amount of knowledge
But calculus, I heard it's so important for ML
And
Could you give me an irl example about limits ?
haha import tensorflow as tf go brrr
but uh
it's mostly just for understanding backpropagation iirc
backpropagation ?
Yeah gradient descent algorithm which has calculus in it.
I will take a look at it
multi var calc go brrrr
Could anyone help me with this??
Given a set of n distinct non-negative integers, we wish to find the k smallest integers in the set and output them in sorted order.
Three possible algorithms are suggested for solving this problem. For each algorithm, analyze its worst case running time and state that running time in terms of both n and k.
(a) Given n unsorted integers from the range [0, n2 − 1], output the k smallest numbers in sorted order using radix sort. We assume that integers up to O(n^2) can be stored in a computer word.
(b) Sort all n integers by Insertionsort, and output the k smallest numbers in sorted order.
(c) Build a heap on the n integers and call Extract-Min k times. For this part, you may assume that you can build a data structure heap on n items in O(n) time.
hi, is there a program to test a pseudocode?
Test pseudocode? No, pseudocode isn't code. It can be written in whatever form you like. I don't think AI is there yet @mossy kettle

I mean, pseudocode is almost identical to Python, so maybe do just little tweaks like spacing and colons?
@FuckYouMath2411#3292 do you know what these algorithms are specified in a, b, c?
U mean radix sort, insertion sort and heap sort of extract-min?
yes
Did they ask you to code or just explain?
just state the running time
a. idk about radix sort you can google it up
b. insertion sort has O(n^2) worst time complexity, and after sorting you are taking K- elements which will take O(K) time, so O(n^2) is bigger term than O(K), hence the worst case running time of the algorithm is O(n^2)
c. building a heap of n-numbers takes O(n) worst time complexity and then you are calling K-times a extract min operation where each operation takes O(log n) worst time complexity totalling O(K log n), now among O(n) and O(K log n), O(k log n) term is bigger hence the worst case running time of the algorithm is
O(K log n)
ohhhh, is it like actually the worst case running time is just the time of using those algorithm to sort items?
as most of the time, it would be larger than the time of log(k), which log(k) is the time to take the k-elements
Do I interpret it correctly?
as you can see in c building the heap cost us O(n) time whereas extracting k-items cost us O(k log n) time which is greater than building the whole heap itself
So the final goal is to express the worst case time complexity of "Extracting K-items from a list"
maybe the sorting takes more time, or maybe extracting those k takes more times after doing some "smart" algorithm
okay thank you very much
;compile python
Given an integer product, find the smallest positive (i.e. greater than 0) integer the product of whose digits is equal to product. If there is no such integer, return -1 instead.
Example
For product = 12, the output should be
digitsProduct(product) = 26
i need some help in finding a good algorithm for this
I would start with prime factorization
though you would have to special case 4, 6, 8, 9
right because 22 > 4
the first thing i did was check if the number was prime or not
cuz if it was prime it should return -1
yeah, that makes sense
@rare dawn how large can that product be?
i just keep dividing by the largest digit i can
that also works 👍
Have the user input a list of columns for a table
Have the user input a data type for every column: int, float, string size 255
In a loop have the user input the values for each row
Ensure the string size doesn't exceed 255
Print the results when the user is finished
for the second sentence, how do you know when the user has already input every column include int , float , string size 255?
you check if you can cast the input given to the datatype that you have taken
if not you raise error
do you mean by type(a) ?
a = input("....") a is going to be a string how do you know if a is either int , float, string size 255
yeah you do
try:
casted = int(a)
except Exception:
print('invalid data')
you don't need a check for string, since you take input itself as string
btw is string size 255 bytes or length?
import numpy as np a = int(input("Size of array:")) lst = [] for i in range(a): my_array.append((input("Values:"))) my_array = np.array(my_array) print(my_array)
i got this already i dont know what to do next
What do you want to achieve @void cliff
Uh, strings in python are weird
Oh you are the same person lol
You don't want to get the size in bytes of string in python
(Tommy)
Every strong stores an additional 49-80 bytes of memory like hash, length, length in bytes, encoding type, and string flags
and the string itself depends on how long it is
Basic OOP question: Why is it not necessary to define 'other' in population_density()? Isn't population_density() computed with everything belonging to self?
` class something:
def population_density(self) -> float:
return self.population / self.area
def has_higher_population_density(self, other) -> bool:
return self.population_density() > other.population_density()
`
other is defined
def has_higher_population_density(self, other)
ignore oop, just think about functions
other is an arg that is past to this function when it is called
@fiery cosmos do you mean other is passed to population_density() (so now other is used instead of self, becoming when called population_density(other))?
its just a function
ignore oop
def hello(arg1):
print(arg1)```same as this
you call with hello('hi')
it prints hi
wouldn't it then be population_density(self) > population_density(other)?
well id assume 'other' in this case is supposed to be another instance of that class
and therefore they both have their own population_density() function
@fiery cosmos So when defining other inside a method it can become an instance and have then it's own functions (substituting self with other)?
what
no
do you understand basic python functions or are you starting with classes
ok, this is literally the same scenario as a standard function i posted above. other is an arg. when you call has_higher_population_density() you need to call it with has_higher_population_density(arg1)
for instance here i will give an example that has its own functions...
!e python def test(other): print(other.split(',')) test('hello,world')
You are not allowed to use that command here. Please use the #bot-commands channel instead.
same idea, and you can access the split of the 'string' object
so in the oop you posted, they are passing an object into other, and inside of the function, they can access the any methods on other
namely in this case, others population_density()
I get a bit more now, but I'm not sure about self.population/self.area in relation to other.population_density(), does it return other.population/other.area?
'string1' and 'string2' are both instances of string class
they both have their own unique split method
in the code you posted, has_higher_population_density is a method of class something
so for instance, lets say python one = something() two = something()
now i can call one.has_higher_population_density(two)
it will run ones has_higher
other will be 'two'
two(other) and one(self) have their own unique .population_density()
one = something()
one.population_density()
two = something()
two.population_density()```no different than like here outside of the function
Construct a square matrix with a size N × N containing integers from 1 to N * N in a spiral order, starting from top-left and in clockwise direction.
Example
For n = 3, the output should be
spiralNumbers(n) = [[1, 2, 3],
[8, 9, 4],
[7, 6, 5]]
can anyone help me with the algorithm to solve this
That sounds like something for the help channels 🤔 But you can write a function like a small state machine.
@fiery cosmos I don't completely understand that, but I can't wroking anymore on it today. Thanks for everything though, I really do appreciate your help! Once I've studied more on my own I'll definitely refer back to what you explained.
time
Hi guys, i have a question:
What is the best practice? What is your opinion about this functions.
I have 2 function, the first return True or False, if can make the action.
The second, it's the same of first, but create and save the file, and return the route of the file.
The function are very similar but the return it's diferent, it's a good practice
Hi guys, i have a question:
What is the best practice? What is your opinion about this functions.
I have 2 function, the first return True or False, if can make the action.
The second, it's the same of first, but create and save the file, and return the route of the file.
The function are very similar but the return it's diferent, it's a good practice
@fiery cosmos ...don't think that's a good idea
instead of catching the error and returning False, don't return anything and just let the caller catch the error.
Good evening, I am hoping someone can help straighten me out here. I am writing a blackjack program for school and I am having some issues with things as I have them. If the player chooses to "stay", the program ends and doesnt continue into the dealer section, if the player chooses "hit" it turns into an endless repeat of the current total. I have rearranged things and changed some things that I thought were causing an issue, but I havent had much luck. If I fix a problem, it causes another.
and the total never gets changed after the inital 2 cards.
Good evening, I am hoping someone can help straighten me out here. I am writing a blackjack program for school and I am having some issues with things as I have them. If the player chooses to "stay", the program ends and doesnt continue into the dealer section, if the player chooses "hit" it turns into an endless repeat of the current total. I have rearranged things and changed some things that I thought were causing an issue, but I havent had much luck. If I fix a problem, it causes another.
@final fjord your control flow is wrong.
conceptually, it should be something like this.
during the player's turn:
- check what actions they are allowed to take, based on their total
- if there are any valid actions, take player input to determine what action to take
- execute the action
- loop
you can see that you never update player_total.
I see some of it, I fixed where I was not updating the total.
i think it should be
"if total less than 21:
do you want to draw a card
etc
etc
elif total > 21:
print(you lost)
else:
print(you won)
right
"while total less than 21:
etc
etc"
so i generally have the right things, just in the wrong order
thank you very much @brave oak I think I have worked out the kinks
there is another thing that was tripping me up. I used the top tuple for simplicity, but how could I use the bottom format and have integers assigned to "J,Q,K,A"
the instructions said to use a tuple of strings, but It was not obvious to me how to use that.
can i do
cards = ("A" = 11, "J" = 10, "Q" = 10, "K" = 10)
no ig
you can do it like
card_map = dict()
and then set card_map["J"] = 10 and so on..
ok
ok cool, thank you very much
I mean, sure - when you find a pair of matching chars, delete them. Proceed until either both words end or you end up unable to match a letter to the other word.
complexity would be O(n^2) or so
sure, or at least changing it
oh, there's actually a really simple way
for each character in the first string, count the number of this character in the first and second strings, make sure they match
then the same for each char in the second string.
hmm, now that I think of it...
I wonder if the following is true:
x_1 + x_2 + ... + x_n = y_1 + y_2 + ... + y_n
x_1^2 + x_2^2 + ... + x_n^2 = y_1^2 + y_2^2 + ... + y_n^2
...
x_1^n x_2^n + ... + x_n^n = y_1^n + y_2^n + ... + y_n^n
Is the only solution of this system "y is a permutation of x"?
no, not this
a system of n equations for n variables
like, for n=2:
x_1+x_2 = y_1+y_2
x_1^2+x_2^2 = y_1^2+y_2^2
are the only solutions (x_1,x_2) and (x_2,x_1)?
for this system, wolfram tells me it is
but I wonder if it's true for arbitary n
because if yes, it's a way of checking anagrams
compare the sum of character indexes, the sum of squares of character indexes, the sum of cubes, and so on
if and only if they are all equal, the words are anagrams
def my_cool_anagram_checker(a:str,b:str)->bool:
# In Soviet Russia, we don't use "sets" for this.
n = len(a)
if len(b)!=n: return False
def sum_k(s,k):
return sum(map(lambda char: ord(char)**k,s))
return all(sum_k(a,k)==sum_k(b,k) for k in range(1,n+1))
>>> my_cool_anagram_checker("hello","asdas")
False
>>> my_cool_anagram_checker("hello","heoll")
True
summing can be done with loops too 😛
hello, I am still new to algorithm.
I am planning to build a recommendation system, maybe just a basic one
Can any one give me some helpful recommendation on how should I start and what method should I use, things like that.
I plan to use the feedback and ratings for others users as the data for the recommendation
Seems like that would be a better fit for the #data-science-and-ml channel @ocean yacht
hi
Can someone please explain why sometimes tuples are used instead of lists?
tuples are hashable, which means you can use them as keys in a dict, for some algorithms, especially combinatorial ones, you also put tuples representing choices into set to prevent duplicate choices
Can you dumb that down a little.. I haven't learned hashes, dicts and algorithims yet haha
sometimes the immutability of tuples is a great property, and it makes them better than lists in some cases
When you wank to fix some sequence which you don't want to modify later on you can use tuple
Can you give me an example of where tuples would be better than lists?
idk maybe like a constant value or sth
The Global Coding Challenge is a inter-university online coding competition between students across the globe.
Hi!
Can somebody help me, please?
I was working with an exercise and the numbers which were generated by the program weren't going to a list I made...
@gray heath Can you provide the code
Can someone please explain why sometimes tuples are used instead of lists?
@brittle narwhal conceptually they're different
tuples are used to group data where position has inherent meaning
lists , on the other hand, are used to group data of a common type
at least, theoretically.
so the example I always use is a 2D point: (x, y)
if you reverse the order ((y, x)), it's a different point entirely
on the other hand, if you had a collection of points [(x1, y1), (x2, y2), (x3, y3)], position does not give any point meaning beyond "first", "second", or "third".
and in particular, note that it makes sense to append to a list because you'd just be adding another object of the same type
but not to a tuple because each field has a meaning, and you'd be changing the meaning of the tuple itself.
:incoming_envelope: :ok_hand: applied mute to @tepid python until 2020-10-24 01:37 (9 minutes and 58 seconds) (reason: burst rule: sent 8 messages in 10s).
@brave oak I can see where you're going but if you sort a list, you're imposing a specific order, but you wouldn't convert the list to a tuple when you do that.
The most significant difference between a tuple and a list in python is that tuples are immutable. This just means that after creating a tuple, you cannot change its elements.
Lists, on the other hand, are mutable, meaning the elements of a list can be changed (mutated) after creating it.
One downside of mutability, and hence a reason why you might use a tuple in place of a list, is that care needs to be taken when dealing with mutable data. If you have two references to the same list, modifying one will also modify the other.
This is often desirable behaviour, but can also cause really hard to track down bugs.
Because you have to understand not just the value of the data, but the network of references that exist within the data.
Also, mutable objects are not hashable, which essentially means that they cannot be added to sets, or used as dictionary keys.
When you add a key to a dictionary, it uses a hash (a number calculated based on the value) to decide where to store it in memory. Later, when you look up the key, the hash is used to find it. But, that means the hash has to be the same as it was originally, which means that the value of the key must not have mutated.
Sorts
what sort of sorts
@brave oak I can see where you're going but if you sort a list, you're imposing a specific order, but you wouldn't convert the list to a tuple when you do that.
@oblique panther yes, but there still is no meaning inherent in the order; semantically, it’s the same data type.
note also differences in type hinting.
for tuples you usually specify one type per field, in line with the idea that each field has its own unique meaning
on the other hand, you do not (and cannot, actually) do the same for lists
of course, this distinction has a lot more meaning in a statically typed language (especially a more functional one).
in Python, you can choose to be guided purely by practicality (mutability).
is there any algorithm for some games of life?
for example having some swarm and each individual is moving on its own to some food
I got a question, the only way i can think of is sort by merge sort or other sort that with O(nlogn) time, could we sort it in O(n) time?
You want to sort m students’ names in the alphabetical order (i.e., a < ab < b). The lengths of their names are not necessarily identical, and the sum of the lengths of names is n. Let A be an array of their names, A = [A1,A2,...,Am], and for any name Ai, it is an array of characters, Ai = [ai1,ai2,...]. The characters are from extended ASCII code, so there are 256 possible characters.
Design an algorithm that sorts the names in O(n) time. Provide the time complexity analysis of your algorithm.
"the lengths of names is n" if this mean that N = len(A1) + len(A2)... then you could check out Radix Sort. the time complexity is O(m*k) which m is the number of student and k is the largest length of student's name
@bronze sail I think it would depend on how complexity of your games. if there is no obstacles on the way then just simply calculate the angle between the swarm and the food the let the swarm head towards the food follow the calculated angle. if there is wall of any obstacles between then perhaps apply some path-finding algorithms (swarm is the starting point and food is destination)
@wispy sierra Thanks for your help, but I thought the total running time of radix sort is O(d(n+k)), where d is number of digits, n is number of integers and k is values of the digits can take, so if I use radix sort in this question, isnt it be O(256(m+k))?
yeah as you already know the upper-bound which is a constant you can achieve O(n) sort
check this algorithm too
https://www.geeksforgeeks.org/counting-sort/

GeeksforGeeks
Counting sort is a sorting technique based on keys between a specific range. It works by counting the number of objects having distinct key values
So if we have k as the largest length of name, which means we need to run k times to compare (ith time is to compare the position ith of each name, goes backward so from (k-1)th->0th), for each time, we use counting sort to sort the array, which takes O(n)
In conclusion, we will have O(nk) @cobalt sedge in fact, it would be O(nk*256) as inside the counting sort , u ll need to run through the characters to find position but as 256 is constant so just ignore it
Have a look here https://www.geeksforgeeks.org/radix-sort/
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
thanks for ur help 🙂
Sorry for keep asking question, but I am really confused with this course...
So I want to ask, according to this question, is it mean that with the best solution is shortest job first? if thats the case, I think I can come up with an algorithm, but if not, I think it will be the big challenge for me again...
@cobalt sedge for your question, whether shortest job first is a No as ex: L = [5,3,1], P =[100,1,1], it 's gonna produce false result
@cobalt sedge Hmm my gut says that you need to sort the array and then find the result
wait no I still need to consider priorities
ah so ig you need to sort based on the priorites
the one with the least priority should be kept at last
@bronze sail I think it would depend on how complexity of your games. if there is no obstacles on the way then just simply calculate the angle between the swarm and the food the let the swarm head towards the food follow the calculated angle. if there is wall of any obstacles between then perhaps apply some path-finding algorithms (swarm is the starting point and food is destination)
@wispy sierra I was wondering actually how to implement just lifegame, should I store foods in list, or maybe in numyp array, but then it will not be constant 😛
since the value of L increases from left to right
@fiery cosmos if sort by priority, it would fail for the example in the problem
for me, we ll sort based on value (P[i]/L[i]) (priority per unit), then yes greedy based on the sorted array 😛
@bronze sail my question is what u want your player to be? a swarm??
I don't think it would fail for your test case
however I am trying to find one
Oh oops now I see the fault in mine
I am assuming P is the same for any order of processes
which is false
@bronze sail my question is what u want your player to be? a swarm??
@wispy sierra not swarm, each should decide for its own where to go. I am using something set that stores position to check if they colide, lets say they are attracted to closest food
found it, i was inspired by this game https://youtu.be/-ujaymURIFo?t=92

Promotional video for the Android simulation game Cell Lab: Evolution Sandbox.
Cell Lab is available for free in Google Play Store,
https://play.google.com/store/apps/details?id=com.saterskog.cell_lab
A forum to discuss the game is available at http://cell-lab.forumatic.com
some bacis, food finding alorightm actually, that what I am looking for 😄
What would be the answer according P[i] / L[i] sorting in this case?
L = [5, 3, 1] P = [1/6, 1/11, 1/2]
according to brute force solver the optimal sequence is (1, 2, 0)
mine one is (2,0,1) I think
yes you are right
@bronze sail got no idea what the video is about! but it looks great except the bgm is terrible @@
bmg? @wispy sierra you just control params of that bacterias, so they eat and grow 😛 game of life simple
Oops,typo *bgm: background music 😛
@bronze sail you may want to start to code some draft version so we could see how could we improve the implementation 
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
@wispy sierra https://paste.pythondiscord.com/zapizahobo.rb, so for not it only spawn food and players, nothing is moving yet :d
nothing special yet 😄
Thanks for all your help, so i need to sort it by P[i]/L[i] right?
Hello, I can't understand the code of merge sort algo?anyone help me?
which partt
it is called merge sort after all
Ya
@fair prairie the splitting part is pretty easy did you understand it?
def merge_sort(arr):
# if you have an array of length 1 it is already sorted
if len(arr) == 1:
return arr
# else find the mid of the array
mid = len(arr) // 2
# sort the left part of the array
left_sorted = merge_sort(arr[:mid])
# sort the right part of the array
right_sorted = merge_sort(arr[mid:])
# now merge the left and right part by calling merge function
sorted_arr = merge(arr[:mid], arr[mid:])
return sorted_arr
now the merge function will look like this(not the shortest one)
def merge(left, right):
# this will be populated and will be sorted
merged_arr = []
# i and j represent the start indices of left and right array
i = j = 0
# traverse both the list until one of them becomes empty
while i < len(left) and j < len(right):
# here the right array element is samller so append it
if left[i] > right[j]:
merged_arr.append(right[j])
j += 1 # don't forget this
else: # the left array element is smaller so append it
merged_arr.append(left[i])
i += 1 # don't forget this
# append the remaining elements of left array if any are left
while i < len(left):
merged_arr.append(left[i])
i += 1 # don't forget this
# append the remaining elements of right array if any are left
while j < len(right):
merged_arr.append(right[j])
j += 1 # don't forget this
# finally return the sorted merged array
return merged_arr
@(@fiery cosmos thx
Sorry for keep asking question, but I am really confused with this course...
So I want to ask, according to this question, is it mean that with the best solution is shortest job first? if thats the case, I think I can come up with an algorithm, but if not, I think it will be the big challenge for me again...
@cobalt sedge
So can i do this?
i think u need to call merge on both halves of the array and have something that appends the halves together at the end
or maybe thats what ur Mergesort line does
Hey i have one dumb question,
So where does the learnt data of AI is stored??? is it database like SQL or some virtual memory and it changes every time device is changed???
if ur talking about machine learning u can kind of think of it like doing regression for a function
basically when u "train" u tweek the parameters of ur function until u get ur desired accuracy
like u know when u had a bunch of data points and u had to find the line of best fit, thats kinda what machine learning is doing
The data that is learnt is stored in form of sequences like NumPy arrays
ahhh ok ok
so the learnt model data is transferable right?? we can use it on another models too right ?? or it wont work
yes you can use it on other models
those are called pretrained models
where you utilise the already learnt parameters
Awesome then :)
Which is a good book to study DSA?
An interactive version of Problem Solving with Algorithms and Data Structures using Python.
Thanks 🙂
Also don't forget the CLRS textbook
^ great book
CLRS is pretty information dense, I wouldn't recommend it for starters. It's an awesome resource though, https://en.wikipedia.org/wiki/Introduction_to_Algorithms for context
yeah, it's not meant for an introduction to programming
Khan Academy actually has a great algorithms course for beginners. It's free and was put together with the help of Thomas Cormen -- who is the C in CLRS.
it's in js, right?
yes
Hey could someone help me with my selection sort function
Discord has support for Markdown, which allows you to post code with full syntax highlighting. Please use these whenever you paste code, as this helps improve the legibility and makes it easier for us to help you.
To do this, use the following method:
```python
print('Hello world!')
```
Note:
• These are backticks, not quotes. Backticks can usually be found on the tilde key.
• You can also use py as the language instead of python
• The language must be on the first line next to the backticks with no space between them
This will result in the following:
print('Hello world!')
def selection_sort(alist):
count = 0
for i in range(len(alist) - 1, 0, -1):
max_pos = 0
count += 1
for j in range(1, i + 1):
count += 1
if alist[j] > alist[max_pos]:
count += 1
max_pos = j
count += 1
temp = alist[i]
alist[i] = alist[max_pos]
alist[max_pos] = temp
count += 1
return count
so this is my function
and this is my tester function
def test_01_selection(self):
nums = [23, 10, 49, 12]
comps = selection_sort(nums)
self.assertEqual(comps, 6)
self.assertEqual(nums, [10, 12, 23, 49])
what issue are you having?
first, im supposed to have . Expected: 14 but my Actual is 6
hey guys is anyone good with using bfs or Breadth-First Search for binary search treea
@kindred flame what code have you written so far?
just bunch of random tries
can you tell me in your own words what a breadth first search is?
def bfs(self, node: Node) -> Generator[Node, None, None]:
"""
Insert Docstring here
"""
q = queue.Queue()
if node is None:
return
while not q.empty():
yield q.get()
print(node, ",")
yield node
for n in RBtree.bfs(self, node.left):
q.put(node.right)
yield n
#for n in RBtree.bfs(self, RBtree.get_sibling(node)):
#yield n
#print(node, ",")
#if RBtree.get_sibling(node) != None and RBtree.get_sibling(node).value == node.parent.right.value:
# yield RBtree.get_sibling(node.left)
# print(RBtree.get_sibling(node), ",")
#yield RBtree.bfs(self, node.left)
y r u using a generator in a breadth first search
@wraith valve it's a good idea, actually
like u can just enqueue and dequeue to keep it simple
a generator is simple
alright lets say I have a tree like this
14 (root node)
7 21
3 10 17 25
as I understood it, we devide that input layer by layer so 1st level is 14 then 2nd is 7, 21 and third is 3,10,17,25
so it will output something like bfs = [14, 7, 21, 3, 10, 17, 25]
can we do it without the queue ?
I would use a queue
how tho
is there a reason you don't want to use one?
the queue would be for storing nodes that you haven't visited yet
but when i try it my code freeze
adding a node to the queue isn't the same as visiting it
can we add object types to queue ?
you can add any object to a queue, and types are objects <- this is a true statement that you can ignore
are you asking if you can add Node instances to a queue?
yeah
so if i can add it how can i make it work then
so first of all is this first bit correct
q = queue.Queue()
if node is None:
return
I am defining my queue
did you implement a queue class yourself?
and then if we dont have any nodes anymore we stop yielding right ?
because there's one in the standard library
no I just have import queue