#dev-contrib
1 messages · Page 53 of 1
Can you explain the changed you've made to the site endpoint and what you mean by not working?
By default, the only allowed settings is "defcon", but you were referring to changes earlier
I added news to allowed settings
But the "news" setting does not exist yet in the database, correct?
Yes
The current endpoint is set up for "updating" and "retrieving" not for creating new entries
How defcon settings is created?
As it's rare to create new settings on the fly, there's no create (usually POST) action available
I assume using a migration
Since it only needs to be created once in the history
Yes
Okay, so I should create migration for it too?
Yes, in this case, since we only have to create it once and there's no need to create settings "on the fly", there's no need to have an endpoint waiting to accept new settings
The migration just makes sure it exists and after that you can view it or update it
Should news use Webhook or standard send?
we can probably use webhooks for those - it would be cool to show the origin of the information (like the mailing list name) as the poster, for example. and maybe a custom icon.
and there's no real risk of hitting any rate limits there because we're not gonna be posting that often
Only thing is first startup. Then this fetch all news and because these don't exist, this post all of them it can fetch (so much how is limited by site)
Also, one more question: Maybe should mail lists storaged too in bot settings in site? Then I can make commands !maillist add <name> remove.
I don't think we need to keep something like that on the site.
default-config.yml is probably good enough for that
ok
I think, as far as possible, we should avoid using postgres for caching and config.
we should use a database when we really need one
I use bot/bot-settings/news to storage already sent news message IDs
in the future, we'll probably implement some sort of caching feature in the bot, we've talked about maybe putting redis in it for a simple cache - so that we don't need to use the site for that.
Okay, PEPs is done now
are you using IDs or dates in the end KS?
IDs. Dates will be harder to follow
solid stuff solid stuff
@cold moon can you send some previews?
I'm tempted to say just include a title & a link to the content
Here is one short
okay so first off that looks awesome, good going
I mean that length is pretty adequate and not spammy, maybe we truncate after however long that one is?
For first, nothing changed, but for second: now this is in almost one screenshot
I'd rather do lines than characters
Rather than randomly guessing at a character limit
characters aren't greatest with newlines
you can see a bit of that for some docs fetched through !docs that take up a lot of space even when truncated
true
Or ask every Python contributor to create a summary of every email they send
So we don't have to fight with Discord rendering embeds differently for basically everybody
Seems ok
Okay. I try to improve code a bit and then I make PR.
Why?
Because this get so much how site give out, and when no news exist, this post all of them.
Surely we can come up with a way for it to not spam everything the first time it ever starts up
Okay, maybe so this don't fetch news that is older than bot startup time? But this may miss some news.
I don't think we need the complete past history of the mailing lists in the channel
It's not missing if our capability doesn't exist
So I should make new item to bot startup_time and then check before posting is this after this time? But there is timezones too... hmm
Does the API not provide times in UTC?
This is pattern how I get it "%Y-%m-%dT%X%z" and %z is timezone
Ok, but what does the API provide
Ok, what is your concern about timezones then?
I think I'll use datetime.astimezone(pytz.UTC)
timezones really are not an issue. we really only care about dates
as in, don't fetch anything older than todays date
time isn't super relevant
OK
Please help with https://paste.pythondiscord.com/ugomacisuk.py : this is repeating this one and same entry, not all of them. Date what is printed out is always same, but all this process is repeating very quickly without moving on.
Here is one part of output https://paste.pythondiscord.com/jusinuxacu.py
All these things that is in code will be not commited. They are just for debugging
(
(any(pep_new[0] == new["title"] for pep_new in pep_news)
and any(pep_new[1] == new_datetime for pep_new in pep_news))
or new_datetime.date() >= date(2019, 12, 1)
):
Not sure if this is a problem but this is totally unreadable.
It would also be more helpful if you could provide an example that functions on its own
Here is full code https://paste.pythondiscord.com/etucoliwuz.py . This seems looping in wrong way, because this stay printing out data["entries"]
usually there's no point for another CI check unless a change has occurred, so you'd normally be expected to commit something.
if you did and there seems to be a delay, give it 15 minutes or so to see if there's a possible backlog issue with azure.
if there's still nothing, then let us know and we'll check to see if maybe azure is down and attempt a manual test run.
In the recent PR, CI says that pre-commit hooks weren't run on the latest commit, as it detected trailing whitespace.
Address that locally, and add a commit, it'll check again for you.
Okay
What mean AttributeError: type object 'BotSetting' has no attribute 'get'? This works correctly for defcon, and I copied migration from defcon.
I was wondering the same thing
did it migrate for you locally? @cold moon
oh wait, that is a local error, thought it was the one you got from lint
i got an email on that issue ticket you commented in joe
and i was like "oh nice someone realised the allauth doesn't need monkey patching, nice to see"
now i realised, it's my own stupid issue ticket that i forgot exists
Haha, did they fix those issues?
nah not yet
Figures I guess
wait, which issues, maybe i'm mistaking what you mean
Monkey patching required to ensure no emails are ever stored
oh nah, we just missed a config option
was around since the beginning, but the docs weren't really nice to find it with
tbh we can replace the entire prereq of logging into the admin console by defining all the discord settings here too
Wait what, you can do that
Man I even dug through the code and couldn't find that
Haha
Don't forget to do it for github as well
SOCIALACCOUNT_PROVIDERS = {
'discord': {
'APP': {
'client_id': 000,
'secret': "asd",
},
'SCOPE': [
'identify',
],
}
}
oof, misindented
that's my bad for manually typing a part of it
but yeah like this
should be eq to ```yml
discord:
APP:
client_id: 000
secret: asd
SCOPE:
- identify
yaml best readability
lol
It's still weird
@patent pivot Sorry about late respone. I got this from linting. For me this migrate correctly locally
nah you get used to it
I mean, what's up with that APP section haha
APP is just the auth stuff
but i guess to avoid it mixing with every other auth config option they have (the lib is all about it i guess), it's better to call it APP
if it were I, i'd skip those and just use a single level though
Me too
Yas
i highly suspect it's a code debt thing though at this point
Yeah, I get that feeling as well
i've been playing with allauth because i've got a django project i want to use allauth with not for social connections
but as the primary django user
so i'm going to be disabling the social features
gotta make a User class, and get it so the providers pass all the correct data over to the new class on User creation
but maaan
it's hard
I'd believe it
there's something in between the social connection being established and the User class being passed values that I gotta make sense of
and it's becoming a rabbit hole
I was thinking of doing something like that in one of my projects
need custom SignupForm and LoginForm classes it seems, and a bunch of other stuff
it's almost tempting to attempt to create a singular custom oauth implementation just for discord
without allauth
I think this kind of speaks to the problems of the Django ecosystem to be honest
buuuuuut that's kinda a pain too because then i gotta do token handling and models
Like, it's a great ecosystem, but everything is so opinionated
my main issue atm is just i don't understand a lot of it
and the docs for this project is atrocious
Yeah they're awful
so i'm just code digging
¯_(ツ)_/¯
but the backend is so dymanic and without enough in-code documentation, so i have trouble finding what goes where in the chain of processes
fun
i feel like though that this would be an excellent case for me to learn proper debugging
It's getting to the point lately where I realise just how important good documentation is
like full process callback breakdowns
I'm making myself use the new IDEA/PyCharm grammar checker and it's making my docs so much better
Yeah, I get you
docs are hard
They are
Haha yeah, I agree there too
:>
i'm definitely subscribing though to a more doc-as-you-go point of view these days
compared to what things were like when i started out
"i'll add docs when it's done"

code is never done
ye
there's the small annoyance of having to edit your code ofc as your api changes during heavy dev stages
but i've also found that the best way to avoid a lot of that is to plan your optimal api first
like "how do i want to be able to use this"
then public objects don't change too much

I like apiary because you define your API in markdown and then it provides you with a test client
interesting
my stuff looks like this, as a simple example

GitHub
Client-side portion of the webmap, rewritten with Leaflet and Vue - TeamJM/webmap-client
Ah yeah, I see
when i mentioned apis before, i also mostly meant the public methods and such, rather than strictly a web api
but this works too as a point lol
Ah right, I get you
like when i laid out my own cooldown objects, i needed to write down the cases it could be used in and how i want to interact with it
then i wrote code
otherwise i'd be all over the place
Right right, that makes sense
I usually find myself planning features and then refining as I go, but that isn't ideal for large projects
Thinking of formalising it with FDD or something like that
never heard of FDD
Feature driven development
ah right
It's sort of agile based but it's built around code owners and small teams without a ton of planning meetings
sounds good to me
esp since all my projects are solo or tiny teams
here's the writeup i did with cooldowns as my initial thought btw

dzone.com
Feature-Driven Development (FDD) is one of the agile processes not talked or written about very much. Often mentioned in passing in agile software development...
test_bucket = bucket.TokenBucket(1, 5)
@test_bucket
def example_deco():
print("woo")
def example_context():
with test_bucket:
print("woo")
# an exception will remove the used token counter
with test_bucket:
raise OSError()
def example_normal():
try:
test_bucket.use()
print("used the bucket successfully")
except bucket.BucketLimitReached:
print("bucket usage failed, limit reached")
await test_bucket.use_next()
print("used bucket when it was available")
async def example_async_context():
async with test_bucket:
print("woo") # runs when next able to
Okay, yeah, I see
with this, i can get feedback immediately and additional ideas
So you're basically doing test driven development
before changing all my code around
Which definitely works
i technically haven't written any tests yet lol
but that's not a bad idea haha
this is just a "lets try get to this point" lol
Haha, fair
i want to know how to use it, the features possible, and what's missing
laying it out like this just gives me room to think and talk about it
since others can more easily understand
and since it's laid out in a simple manner, it's way easier to know how to approach things when creating it
rather then worry about 10000 things
or any what ifs
i'll look into this FDD though, it looks interesting
Yeah, that makes sense, I have trouble with that too
could be a nice extension to what i'm doing
I realised I hadn't really fully gotten used to a particular methodology
And, well, they exist for a reason
tbh it's not yet even half way being implemented, because during the above stage, I got a suggestion for further possible options
but as a simple implementation.. lemme see if i have any leftover code
the initial concept implementation used a standard counter
The Semaphore, like the asyncio.Lock has context managers that allow you to await something being available again
Things like
yeah it's a lock with a counter right?
There's a synchronous version as well
the issue is that it needs to be usable for both async and sync code, with all the same bucket
needs the same counter though
ah
ye
it's part of the fun 😄
not only that, but the requested additional options are to be able to specify if i'm going to wait or not even in an async context
such as ```py
async with my_bucket(wait=False):
do_thing()
but imo that's silly
since they can just use with
but they extended the idea further lol
so my main focus atm is just figuring out if there's a need for these optional contexts
i haven't had a chance to look yet 😄
oh btw, the context rollbacks i'm using ContextVars to handle lol
that's because I need to keep aware if I'm in the same cycle as when I entered the context to know if I need to bother rolling back in the first place
if you have any further ideas though, don't hesitate to let me know!
I guess you could make the bucket have both __enter__ and __aenter__
yeah i do 😄
enter doesn't wait
aenter does
i'm kicking myself for not committing any of the previous versions tbh, because i could have shown the early one that works
the current one is all over the place because of a half implementation
oh another option that was suggested was raise_exc as a kwarg
but i feel like it's probs unnecessary
Finally is my site PR fixed
@cold moon you should probably at least wait for approval of an issue before creating a PR for it. If I wanted to work on the issue your last PR was for then you just took it from me.
But the more important thing I wanted to get to is that the last point went unadressed while you set the pr to close the issue
Not sure now if I should point that out in the PR or the issue for it since it went without any discussion and has an approved review
What's included in the sentry issues? (Can we access them?) some github issues look a bit bare without much context on where the errors the issues are for are coming from
That's usually because the sentry issues themselves don't have much context (like no traceback)
Usually they do, but sometimes not.
Which issues did you have in mind?
@brazen charm since some reports contain PII and user data (for example, IP addresses on site) we can't grant public access, though if a github issue is vague we are totally okay with sharing some more detailed information
908 and 909 for example don't seem to have much on where the error is coming from
908 has a bit of a hint with the title but no idea on 909, could just be missing something but was a bit lost when I looked at it
909 we're sort of just as clueless
we don't have the extended information we usually have for that
although one sec, I'll add some more details now
added
Oh 908 was just me being a bit lazy
I merged some issues together and unfortunately it was choosing to use the manual invocation traceback (via the refresh command) rather than the 3 other events which were automatic
And I just cba to copy all those tracebacks myself
Sorry
Felt like it was adequate
@brazen charm that should clear those ones up, let me know if anything else is needed
Looks good, thanks
hi all. wanted to ask what the policy around contributing PRs is. When there's an issue, does one first announce that he's going to work on it, or just submit a PR when done?
Policies vary from org to org, but for our projects, you'd normally comment on the issue you want to take on, so people know you're working on it.
Thanks @hardy gorge
@cold moon I've got a proposal
If we make the python news channel an announcement channel people can subscribe to it in their discord servers
the only change you need to make is when you send a webhook message get the message object and call the .publish() coroutine
means that users will see this when looking at the channel
yes, we need to do this
I've tested it because I originally had fears it was not available to bots but it definitely is
just going to check if you can publish webhook messages, I think you can
okay you can
but, you lose track of the webhook author details
might be worth adding the source into the footer
oh need to check if embeds get sent as well
we probably need something like this
then when it gets relayed through news channels
Anyone that could take a look at this issue, thought I can also include the recent inventory request issue in a pr for it if it doesn't take too long depending on what's agreed upon
.issue 878 bot

@patent pivot I added both of these features.
Fantastic, I'll take a look at the site PR now, thanks!
@cold moon is there any way I can force the bot to post the latest news?
@patent pivot I replace data.today() with data(2020, 1, 1)
excellent, will give it a try, thanks
One more thing @patent pivot you gave news channel ID, but I think we need webhook too?
@cold moon when I start it up I get an onslaught of the same post, is this expected?
it doesn't seem to be publishing the news setting either
publishing was wrong word
I mean it wasn't sending the new setting to the site
it also seems to go into some sort of endless loop
I keep getting heartbeat blocks
May
while not self.webhook:
pass
reason?
I added it because sometimes this run before webhook is ready
With what I should replace it?
there is nothing to replace it with
I'm more interested in why it's not working
I have an idea, one sec
okay so
I fixed it by doing
diff --git a/bot/cogs/news.py b/bot/cogs/news.py
index db273d68..f0b15ece 100644
--- a/bot/cogs/news.py
+++ b/bot/cogs/news.py
@@ -35,6 +35,9 @@ class News(Cog):
self.bot.loop.create_task(self.get_webhook_names())
self.bot.loop.create_task(self.get_webhook_and_channel())
+ async def start_tasks(self):
+ """Start the tasks for fetching new PEPs and mailing list messages."""
+
self.post_pep_news.start()
self.post_maillist_news.start()
@@ -98,7 +101,7 @@ class News(Cog):
continue
if (
new["title"] in pep_news
- or new_datetime.date() < date.today()
+ or new_datetime.date() < date(2020, 1, 1)
):
continue
@@ -234,6 +237,8 @@ class News(Cog):
self.webhook = await self.bot.fetch_webhook(constants.PythonNews.webhook)
self.channel = await self.bot.fetch_channel(constants.PythonNews.channel)
+ await self.start_tasks()
+
def setup(bot: Bot) -> None:
"""Add `News` cog."""
basically start the tasks after fetching the channels and webhook
but that still does the infinite looping
and still no changes to the site settings
heading for tea, will investigate after
@cold moon found it, message.publish is breaking things if it isn't an announcement channel
Oh
I have a fix though
If you don't mind I can commit this stuff back to your branch
or I can send you the diff and you can implement it
You can commit
👍
okay next issue is a race condition I think but it seems the mailing list overwrites the peps
hm
the most recent message does not seem to be inserted
oh, none of them do
ah the timezones are fucking things up ```
[Python-ideas] Adding a "once" function to functools [Python-ideas] Adding a "once" function to functools
2020-04-26 14:03:16 2020-04-26 07:03:16-07:00
@patent pivot One thing: Discord.py have TextChannel.is_news() function, that returns is channel news channel. Maybe should we use this?
Sounds good @cold moon
@patent pivot What should done more on Python News?
Did you test the changes I've made?
Everything is working
Okay, I'll take a look soon then
Hmm....
AssertionError: "Are you insane? That's way too long!" does not match "Are you insane? That's way too long!"```I don't get it
is that through assertRaisesRegex or assertEqual?
may need to escape the questionmark
In [64]: re.escape("Are you insane? That's way too long!")
Out[64]: "Are\\ you\\ insane\\?\\ That's\\ way\\ too\\ long!"
Awesome, thanks
Running the bot, guess this log should be inside the if? https://github.com/python-discord/bot/blob/master/bot/cogs/help_channels.py#L649
async def check_for_answer(self, message: discord.Message) -> None:
"""Checks for whether new content in a help channel comes from non-claimants."""
channel = message.channel
log.trace(f"Checking if #{channel} ({channel.id}) has been answered.")
# Confirm the channel is an in use help channel
if self.is_in_category(channel, constants.Categories.help_in_use):
...
it's directly used in the on_message listener and logs on every message
It should be, yeah
though wait
no yeah, I thought there was another category check elsewhere
Does contributors regiews still count towards the 2 reviews or not? I guess not, since we aren’t in the organisation anymore?
they technically don't, no.
which sucks, and we wish we could give you the permissions for only that and branches.
but sadly, GitHub doesn't really allow that level of granularity (or any level of granularity) in their permissions
it's an all-or-nothing model
that said, we still welcome reviews, and they definitely count in terms of deciding whether or not to merge something
we'll probably keep the 2 review requirements informally and maybe reduce the technical requirement to 1
so that the effect is basically the same
yeah, reviews are great even if they don't technically count, they aren't ignored
please don't let that discourage you
Okay, I’ll try to do more reviwing then 
for seasonalbot here's an easy one: https://github.com/python-discord/seasonalbot/pull/401
and @cold moon 's tic tac toe looks fun but I haven't had time to review it yet myself: https://github.com/python-discord/seasonalbot/pull/397
That’s why you should always precise the reason in the commit meesage :P
@cold moon PR reviewed, I've got concerns on scaling of this solution
seems like it would be very easy to achieve a high number of API requests very quickly
@patent pivot Should PEPs use titles then? PEPs don't have IDs
yeah
Ok, then I have to parse something like: PEP <nr>: to get this nr...
right
Anyone have experience with git GPG sign in Mac? I have problem that every time when I restart my computer, looks like this don't recognise Pinentry. I have changes ready, just I can't commit.
I noticed I've been removed as a contributor. Is that because I've only contributed a little and been pretty much inactive lately? Obviously I'm fine with that if so, seems perfectly reasonable, but if it's a mistake and that's not how the policy works, I just wanted to find that out too.
(do me a favor and @ me if you respond cuz I don't monitor Discord quite the way I used to, thanks!)
@lapis hull We put a new policy in place, see this announcement https://discordapp.com/channels/267624335836053506/354619224620138496/701468988164538378
Ah, I did miss that. Thanks very much for the info and (at least in my case) I think it's perfectly fair.
🍻
No problem
quick question for setting up the config.yml file, in the contributing guide it mentions i need a limited amount of channels - there are a bunch of other channels in the config.yml file. it cool to just delete/comment those lines out?
like the extra ot channels, python discussion and what not
No, just ignore them. Let them same like they are in config-default.yml
ya know, i've been programming for 4-5 years and never used docker before
this is kinda neat
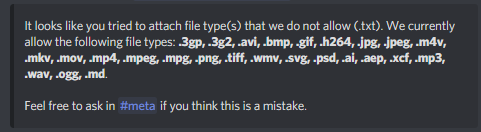
okay, so i found https://github.com/python-discord/bot/issues/889 and it seems pretty interesting to me. i have two approaches in mind, the first being a general .txt case much like how we handle .py files, so ```py
if ".py" in extensions_blocked:
....
elif ".txt" in extensions_blocked:
send a generic embed like the .py one but with both reasons (i.e. your message was too long OR you tried to upload code)
elif extensions_blocked:
....

GitHub
Problem Right now, Discord have implemented a new feature where if a user pastes something over the 2000 character limit a text file is created and uploaded. Solution After a staff meeting, the con...
i personally like the first concept, but i don't know if its too broad in how it handles the problem
It's rarely the case that we will get message above 2k that is pasted directly into discord ( which then trigger the upload behaviour described in the issue )
So I'll go with the first approach
will do
@lean hamlet you should also comment on the issue claiming it so there aren't multiple people working on it.
You should also include it as a general text file for the common extensions used around here like csv, json etc.
the issue i believe was related to the update where discord auto converted messages longer than 2000 characters into a .txt file and then uploaded it. since the bot blocked .txt files, the general file-type message didn't match. that was my understanding of the issue at least @brazen charm
for .json and .csv and whatnot, i think personally the standard that filetype isn't supported message does fine because there won't be a situation where it isn't expected
There was a discussion on #community-meta and here is the relevant but from the issue
when attachment is of type text in general
It's also mentioned in the comment.
The general message is enough but with text formats there are cases where people simply add an another extension or have to be reminded of the paste service which makes the filter a bit less user friendly
And since looking through the file isn't very viable a list of common extensions used around here should be good
@brazen charm looking over the convo i think they decided against allowing csv's because its harded to moderate those files. easier to click a link and look over instead of downloading a file and doing it. its a good point tho, i see where you are coming from
Was referring to this one https://discordapp.com/channels/267624335836053506/429409067623251969/700340985502367835
Not for allowing them but for getting the hastebin message for a majority of the text extensions instead of just txt/py
@patent pivot Got GPG again working and commited + pushed changes
oh completely slipped my mind, sorry I couldn't help with that, I'll pull the changes now and give it a whirl
I had to reinstall pinentry
ahh
hmmm
2020-05-01 13:56:20 | discord.ext.tasks | ERROR | Internal background task failed.
Traceback (most recent call last):
File "/Users/joseph/.local/share/virtualenvs/bot-YN4ENsGd/lib/python3.8/site-packages/discord/ext/tasks/__init__.py", line 73, in _loop
await self.coro(*args, **kwargs)
File "/Users/joseph/Desktop/Python/bot/bot/cogs/news.py", line 128, in post_maillist_news
for thread in recents.html.body.div.find_all("a", href=True):
AttributeError: 'NoneType' object has no attribute 'find_all'
ahh @cold moon we have a case to handle for
for things directly used in the bot should they all be in the pipfile? bs4 was used in the doc module as it's a dependency of markdownify and was available but was just now added to the pipfile in the news pr
all imports we use directly should be in the Pipfile imo
will keep in mind if I end up needing something "new"
@patent pivot Made fix for this. I found that when threads is available, recents.p is None, but when nothing available, this is string, so checking is simple
ahh solid
okay so I think there is a race condition for the PEPs and the mailing list updating the site @cold moon
I'm going to add a lock and see if I can get any more info out of this
okay there is a better way to do this
@cold moon okay so I've made some changes locally
instead of 2 tasks running every 20 minutes (which leads to race conditions on startup) I've made it one task and mailing list messages are fetched and then after that pep messages are fetched
either way it's difficult to do it in parallel without overwriting each other but running sequentially is no issue
want me to push this back to your branch?
Yes @patent pivot thanks
@cold moon found some encoding issue ```
2020-05-01 22:01:36 | discord.ext.tasks | ERROR | Internal background task failed.
Traceback (most recent call last):
File "/Users/joseph/.local/share/virtualenvs/bot-YN4ENsGd/lib/python3.8/site-packages/discord/ext/tasks/init.py", line 73, in _loop
await self.coro(*args, **kwargs)
File "/Users/joseph/Desktop/Python/bot/bot/cogs/news.py", line 46, in fetch_new_media
await self.post_pep_news()
File "/Users/joseph/Desktop/Python/bot/bot/cogs/news.py", line 82, in post_pep_news
data = feedparser.parse(await resp.text())
File "/Users/joseph/.local/share/virtualenvs/bot-YN4ENsGd/lib/python3.8/site-packages/aiohttp/client_reqrep.py", line 1014, in text
return self._body.decode(encoding, errors=errors) # type: ignore
File "/Users/joseph/.local/share/virtualenvs/bot-YN4ENsGd/lib/python3.8/encodings/cp1254.py", line 15, in decode
return codecs.charmap_decode(input,errors,decoding_table)
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 3477: character maps to <undefined>
something with the PEP feed is messing up
specifying utf-8 as the encoding sees to fix it
i'll put a review comment on there
as for everything else though this is working fantastically, nice work ```json
{
"name": "news",
"data": {
"pep": [
"613",
"614",
"616",
"617"
],
"python-ideas": [
"XZXWXICKS2RCQLLX73NJOWCJPRY7IUX2",
"ZBB5L2I45PNLTRW7CCV4FDJO5DB7M5UT",
"YKLNQXONLLZ7OXEMUHXF5HD4PCX4SNVT"
],
"pypi-announce": [
"QNSDHPWZ6N6GZFCRTGSVIUOUBO2AHDS2"
],
"python-announce-list": [
"7O7AEHWB6ASEQDMBVALNR7ELDDQF2UJR"
]
}
}
@patent pivot Applied changes
https://github.com/python-discord/bot/pull/866
need another reviwer for this plz
GitHub
Closes #778
Implementation
as suggested in the issue.
Details
Created folders for 3 roles: Helpers, Moderators, and Admins.
When a user uses the tag command, a new method called check_accessibilit...
@patent pivot Commited suggestion
Hey, I'm wondering what the best way to set up snekbox with my local bot would be, I see
docker run --ipc=none --privileged -p 8060:8060 pythondiscord/snekbox
On the GitHub repo but do I need to modify that to link it with the bot or change the bot's config.yml. Trying to do this for working on this issue https://github.com/python-discord/bot/issues/916
That should spin up a container with snekbox listening at localhost:8060
I have this is my config.yml:
# Snekbox
snekbox_eval_api: "http://localhost:8060/eval"
I run snekbox by following the dev guide, though, but I think that does not matter in terms of listining to localhost:8060
I get this error when I try to use eval with that: ClientConnectorError: Cannot connect to host localhost:8060 ssl:default [Connect call failed ('127.0.0.1', 8060)] and also realised that I am getting some other errors, aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host api.web:8000 ssl:default [None] a few times and aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host api.web:8000 ssl:default [Connect call failed ('172.18.0.3', 8000)]when I docker-compose up the main bot.
Unless the bot is using host networking, then you won't be able to just connect to it on localhost
Connect to Snekbox, I mean
You'd either have to run the bot outside of Docker, or get snekbox running on the same Docker network and then refer to the container by name or internal address
Could I just run docker with --network host or would it not be that simple
Well, by default compose is going to be creating a network for each set of services
You could modify the bot compose file to run on host networking as well
I don't know, I'm running snekbox with the docker-compose.yml it has and it's working fine
Using localhost:8060
No issues with not being able to access the host network, since it defines a port mapping (8060:8060)
Oh, true, the port is exposed
But you still won't be able to get at that from the bot without host networking or just running it directly, unless the bot compose is configured for host networking already?
I'm not sure how it combines with using the bot's compose. I run the bot outside of a container
yeah, bot compose doesn't use host networking, I see here
Right, so the bot running in a container can't get out to use the running snekbox instance
That's right
It might be worth putting a networks key in each compose file
so then they'll all run on the same network
Ok thanks, I'll play around with it for a bit and try and work it out
The straight up easiest option for you is probably to run the bot outside of docker right now
But yeah, see what you come up with
Oh Yeah! Managed to get it working, never used docker before, chucked in network_mode: host and commented out a few lines, worked first try!
wookie I'll probably get to it today towards the night; I'm planning on implementing a shared func for unploading to the paste service along with doing the extension in there.
I think you could base it from my branch and then use the new function for the extension but the simplest would be me just waiting for your pr to get merged when it goes up and then resolving the small merge conflict
OK, I don't mind doing whatever is easiest for you if that means waiting, I'm in no hurry and I haven't started yet. I'm new to this so is your idea that I would wait until you have done and then create a branch off your branch? And the other option was us both creating out own branches now and resolving the merge conflict at the end?
I'm not that well versed with git myself so there may be a better way of doing this seamlessly but yeah for the second option just two independent branches
We can probably just go with the independent braches idea then
For making the util func for uploading to the paste service from #907, should the bot session be fetched (param/ making it into a cog or something like that) or will a simple aiohttp.request suffice?
right cog won't make much sense either as that itself would need to be accessed too
!e
You are not allowed to use that command here. Please use the #bot-commands channel instead.
or not haha
Never mind, I'm blind
Yeah I found it
Although it does kind of raise another question...
Okay so I'm looking at the !unban command
That calls pardon_infraction from the scheduler cog, cool fine, no problem there
Actually I should look before I ask, two seconds...
Never mind, I get it now
Was just a lot further abstracted than I thought
Okay, actual question this time:
Currently, when we attempt to ban a user, the bot checks if we have an active ban infraction on them, using the utils.has_active_infraction() function. Cool, great, that all works. The issue is that we now need to know if there's a temporary one already there. My problem is working out how to check if they have an active infraction and also whether it is a temporary one without doing it in two API calls
I'm thinking I'm going to make another utility function
You can just fetch all the active ban infractions of an user
Yeah, I think I worked out in my head how I need it done
and then you can see if it returned any, and if they are temporary
Yeah I think I'm just waffling on the how
Won't there be a scheduled task for unbanning the user, scheduled everytime the bot starts?
You can probably check there and see if there is such a task
If it is, they are probably being temporary banned
Otherwise yes you need to fetch the infraction from the DB
I'm thinking I want the infraction from the DB so I can return it to the crap hold on, have to restart my rig
Taking the information from the scheduler sounds a bit messy to me, a database call doesn't really hurt
True, we rarely do it anyway
Finally can try to get back on this... stupid morning
I was way overthinking it
Question: When we do:
active_infractions = await ctx.bot.api_client.get(
'bot/infractions',
params={
'active': 'true',
'type': infr_type,
'user__id': str(user.id)
}
)
Does that just return back a dictionary?
Yep
Is it too redundant to have two different functions for this? We have has_active_infraction() which just returns a Bool value depending on if they have an active infraction of the given type, and then I'm writing get_active_infractions() which will return the dictionary gotten from checking instead of the Bool value
It'd be going in the utils.py for the moderation folder
I just know it ends up not being very DRY
I think this has_active_infraction should return infraction dict, when infraction exist, otherwise empty dict. Changes will not big in uses of this function because empty dictionary is false and not empty true.
No meaning to have 2 functions
True but the issue I have with that is that has typically is something that returns a Bool
Since it's just checking if it exists or not
Rather than actually retrieving or getting the thing
Okay, then yes, this should be renamed to something else.
I mean has_active_infraction is just len(get_active_reaction()) != 0, it will have some redundant code and will force you to do two database fetch
Yep yep
I'm just now wrapping up my implementation. Just adding a few log traces for clarity and what not
Satisfying to be putting in PRs again
Is the Sorry, an unexpected error occurred. Please let us know message needed when handling unexpected errors when sentry already does that?
There needs to be some sort of feedback for users still. Perhaps the exception message could be remove though.
I don't particularly feel a need to change it.
Is there a char limit on the paste service itself?
Not sure if there should be a hard limit on the size in the util func for it, or just handle it before it's called
I think I documented it in the function
There's a size limit for the request
And then there's also a character limit?
Something like that
Joe would know the details
It was decided just to hard code a reasonable limit.
can only see
except Exception:
# 400 (Bad Request) means there are too many characters
log.exception("Failed to upload full output to paste service!")
in snekbox if you meant that; and a len check before that
Yeah. Not as well documented as I thought
I tried to look through my message history, couldn't find exact numbers but I believe it was discussed somewhere.
But I can clarify that there is indeed a request size limit and a character limit. The former is a higher limit than the latter. So you could spend a while to upload e.g. a 100 megabyte file before you get a 400 response, or you could try to upload 1 gig and immediately get an error response.
so should be good to just let it be handled outside of the func and if something unexpected gets through the site will refuse it?
Yes.
There should still be limits somewhere though
The site's limits are quite high
alright, thanks
Is it easy and free to run @stable mountain locally to run python bot to make a contribution?
Oh, okay
Did you make some really good contributions to the bot and got the top role you have?
Something like that
How much knowledge do you need?
For what?
Like, database, discord.py (obviously..), website, api etc
Depends on what you're going to work on
Design, importantly
Some features would need more knowledge than others
Oh, okay
Not everything inherently interacts with the site, for example
oh, k
If nothing else, it's worth thumbing your way through some of the issues the repo
Take a look at them, see if they're something you'd be interested in looking into.
You don't even necessarily have to tackle it right away, but just thinking out "okay, how would I approach this?" If you find yourself having trouble coming up with how to do it or you realize you need to understand more about a certain library, go learn it and come on back
There's always stuff to work on here
There's plenty earmarked as "good first issue" and stuff like that. Also, don't get discouraged. If you get stuck, have questions, etc., just let us know
oh sure
Were other text formats also supposed to be here https://github.com/python-discord/bot/pull/925 ? The issue talks about that a list of them instead of just .txt; don't know the actual stats but I think other extensions also cover a lot of text files that'll just get removed with the generic message
I'm on the same issue
How about make it a simple code-block with no special formatting?
like this?
r'a't'h'e'r than this?
@clever wraith I started contributing to the bot without any specific knowledge around the lib it uses apart from the common ones like requests that are used in some of the internal libs, think I'm doing fine so far. There's also the review process by other collaborators and core devs which will help you all around with the code itself, issues/prs in general etc.
majority of those 100 are tests
Hem, if I solve more than half of them, is there a chance I can impress the mods?
or at least a big amount if not majority
What does it take to have the contributors role?
I'd focus more on quality over quantity. We want good, functional, well written code. Ideally, tackle one at a time, learn as you go
There's no rush with all this
most of those issues also aren't trivial
@brazen charm The generic message still talks about using the hastebin. And this specific issue is more talking about when the user has a message of over 2k characters, and then discord suggests to upload it as a .txt file
Yeah, also that
A fair number of them are about unit tests, which I still need to learn...
the generic message is just... generic without the paste site or anything https://i.imgur.com/lOiuqwe.png
There are some really good links at the bottom of the test readme hmlock if you want to dive into this
Yeah I know, I just keep getting distracted. Speaking of, I have errands I have to run, I'll be back.
Num, I'll look at this when I get back from that, shouldn't be too terribly long
(Or if any of the other folks want to give their 2 cents that'd be grand)
@clever wraith sentry is just for logging production errors and then some stuff around that, no need to concern yourself around that when developing afaik
You could add more metrics, but that's really trivial
Should I use Docker if I want to tinker with the bot? Or would it be easier without it?
what kind of tinkering?
Just to figure out how it works and how to add new features.
Docker is generally going to be easier than setting up everything else
But it can be a bit finicky to get up and running at first
also depends on OS
^
@celest charm what OS are you running?
Pipenv was very easy to set up with pycharm for the bot, but will probably want docker for the site/db if the os is right
I'm on Ubuntu 18.04
Docker is easier unless you want to mess with snekbox right now I think
I thought snek was simpler in docker?
if both bot and snekbox are in containers then docker is easier, if bot is on host then docker is easier right?
It's in another docker service so it won't be available unless someone sets up a custom network definition in the compose files
if bot is in container and snek isn't I'd understand
ahh right
i forgot docker doesn't do that by default
It's a security feature
right, that's true
#esoteric-python message
^
There seems to be some issue with stack inspection. Is this intentional?
!e
import inspect
print(inspect.getframeinfo(inspect.currentframe()))
# code_context is None, which isn't right
print(inspect.currentframe().f_back)
@celest charm :white_check_mark: Your eval job has completed with return code 0.
001 | Traceback(filename='<string>', lineno=2, function='<module>', code_context=None, index=None)
002 | None
Did you test it in a repl, in a file, or in a python -c when it worked?
It works as expected when run from a file or ipython, but not from a normal python repl.
Yeah, snekbox doesn't run it from a file either
yeah snekbox literally runs python -Iqu -c <code>
Maybe this could be fixed by creating a temporary file and then running it. But such usage of !e is quite rare so it's not critical, I guess.
I was still disappointed that I couldn't demonstrate destructuring of dicts.
:(
it could be done
save file to a hash of the code .py
run that file
all snekbox evals happen in the same container so we can't save to the same file every time but it could be done
GitHub
Easy, safe evaluation of arbitrary Python code. Contribute to python-discord/snekbox development by creating an account on GitHub.
though at the same time
nsjail is write blocked isn't it
hm would be tricky
actually wait no it wouldn't
just write before running nsjail yeah
since it has access to the snekbox file system
!e ```py
import pathlib
print(pathlib.Path.cwd())
@patent pivot :white_check_mark: Your eval job has completed with return code 0.
/snekbox
yeah
Alright, I'll figure out how to set up the bot and will move on to the snekbox if noone else decides that it's an important issue
I followed all the steps in the tutorial, and after running !tags I get this error:
HTTPException: 400 Bad Request (error code: 10014): Unknown Emoji
Traceback:
bot_1 | File "/usr/local/lib/python3.8/site-packages/discord/ext/commands/core.py", line 83, in wrapped
bot_1 | ret = await coro(*args, **kwargs)
bot_1 | File "/bot/bot/cogs/tags.py", line 146, in tags_group
bot_1 | await ctx.invoke(self.get_command, tag_name=tag_name)
bot_1 | File "/usr/local/lib/python3.8/site-packages/discord/ext/commands/context.py", line 132, in invoke
bot_1 | ret = await command.callback(*arguments, **kwargs)
bot_1 | File "/bot/bot/cogs/tags.py", line 239, in get_command
bot_1 | await LinePaginator.paginate(
bot_1 | File "/bot/bot/pagination.py", line 199, in paginate
bot_1 | await message.add_reaction(emoji)
bot_1 | File "/usr/local/lib/python3.8/site-packages/discord/message.py", line 928, in add_reaction
bot_1 | await self._state.http.add_reaction(self.channel.id, self.id, emoji)
bot_1 | File "/usr/local/lib/python3.8/site-packages/discord/http.py", line 225, in request
bot_1 | raise HTTPException(r, data)
bot_1 | discord.errors.HTTPException: 400 Bad Request (error code: 10014): Unknown Emoji
What's the issue?
Unfortunately the tutorial isn't very precise with what roles, channels, and emojis the test server needs
Well, I guess I can ignore the trashcan bug
Maybe I should just edit it to say "look at the config and add everything there"
No big deal.
I replaced it with the cross_mark that'sbelow the trashcan in the config
The config is 577 lines long, so that seems kinda daunting.
it does get placed on a lot of stuff so I'd recommend fixing it
well you'll need to configure the majority of it, but the emojis are at the top
Yeah our config system kinda sucks and we want to rework it but haven't really gained any momentum.
Maybe it would be better if emojis had some fallback values or something
The idea we had was to set up the server with everything
So the bot would create any missing channels, emojis, roles, etc. on start up
"be the change you want to see" they say
I should try to get something going on that issue
But I don't feel like investing the time right now
So it goes
I'll edit the docs for now
is this some sort of issue with my browser or is the pydis hastebin behaving a bit weirdly?
the syntax highlight works properly on the save with its detection, but it seems to force the .py extension for that and only shows .py syntax highlight for subsequent loads
for example https://paste.pythondiscord.com/payujoxiha.css with https://i.imgur.com/MtLVkzg.png and https://hastebin.com/jakedufoda.css with https://i.imgur.com/c6syzmJ.png


{kind=link}
{kind=link}
{kind=link}
@patent pivot seeing as you're online, is the py forced there?
we force py, yeah
we had a reason, but it was because the service is primarily for python code uploads
well, that makes my issue suggestion and a file extension param to the upload func rather useless 😛
is the first normal syntax highlight something that can't be avoided?
I have a plan
mainly considered it because of this issue, to remove the syntax highlights with .txt https://github.com/python-discord/bot/issues/916
What's the behaviour now?
still seems to be "broken" as before for me, with the above link having no syntax highlight regardless of the extension... tried forcing a refresh if that changes anything
yes same as before, but guessing it is an issue on my side now
excellent
was a bit surprised by that
I can't remember exactly why we did it
@tawdry vapor any reason you used the broad except here? https://github.com/python-discord/bot/blob/master/bot/cogs/snekbox.py#L81
we had python default because the syntax detection was fucky and the prime reason for paste.pydis was to have only code uploads
there is a next evolution of the paste site in the works
this asks for a filename on upload to gather syntax
@brazen charm Cause I felt like no matter what the exception is, failing to upload the file shouldn't prevent the message with results from being sent.
Do you think the exception handling is adequate here https://github.com/python-discord/bot/blob/077a1ef1eb4eb07325dde5b6b625a84ccb5669ee/bot/utils/__init__.py or should it be wrapped in the except with raise_for_status
Yeah it should raise for status
If not, then can't the JSON retrieval fail if it's a bad status?
Can raise for status be controlled on the session too?
I forget
If so then you can rely on the session to have it set I guess.
it should return something if we get the request through afaik
It may not always respond with JSON
So deserialization may fail.
I don't know the specifics of this API
I'm just speaking generally
It did return json with a message for some invalid requests I did
I've seen stuff where HTML is returned for 500s for example. And that obviously would not parse as JSON.
Also I didn't see this returns errors in JSON so disregard what I said about raise for status
But to be safe I think you should catch exceptions for json deserialisation
Could be deserialization failing or even just wrong content type. They might be two separate exceptions, I don't remember.
This is why i just did except Exception. A lot simpler.
this hastebin seems to be letting through more than the one I tested it against, but should still be always json unless something goes very wrong
In [78]: r=requests.post("https://hastebin.com/documents", data=b"\0\1\2\3\3\3\3\3\3\0\0\0\0\0")
In [79]: r.status_code
Out[79]: 500
In [80]: r.content
Out[80]: b'{"message":"Error adding document."}'
In [81]: r=requests.post("https://paste.pythondiscord.com/documents", data=b"\0\1\2\3\3\3\3\3\3\0\0\0\0\0")
In [82]: r.status_code
Out[82]: 200
In [83]: r.content
Out[83]: b'{"key":"yapikogese"}'
Can we really rely on such guarantee
It doesn't hurt to add a catch all
It would suck for users to not have their output shown due to a non-critical function failing.
And making callers handle other errors would be a weird design considering the function already catches some errors.
was more against it because of the messages that would get discarded with the exception when raise_for_status is used but if it's permissive like this then might as well not do it
but if everything goes right with raise_for_status then excepting ClientError should be enough
What would be discarded?
the json contents when the corresponding exception is raised for status code 500
You don't need to use raise for status, i took that back
try:
...
except ClientConnectorError:
...
except Exception:
log.exception(...)
return
if "message" in response_json:
...
By the way, doesn't the first except need a continue? response_json may not be defined in such case.
except Exception could also be a continue rather than return
We'd be just catching json errors with the Exception right?
In theory yes
excluding the connection errors like ServerConnectionError that I don't know when get raised from the docs
I appreciate that in most cases having broad except clauses is not ideal, but here I think it is.
If you can catch more specific exceptions to provide better error messages than go for it
But ultimately there should be a broad catch somewhere
It can be narrowed down to ClientErrors and JSONDecodeErrors
OK, but what if something else is raised? Something you missed or some really weird shit happens? Would that be a good reason to prevent the user from getting their results?
Everything else that can be raised should be caught in development, as the ClientErrors encompass every exception that aiohttp gets with the requests and json only has that
I personally don't feel comfortable with that and don't see the advantage of keeping it narrow when the goal is to catch every exception
It just creates a risk of missing something
I'm going to go for today, but I don't see a reason to catch Exception when we have those two with aiohttp's defined hierarchy and json just having that one exception. The broad except trades errors when developing for some unlikely or impossible situations in which users will not get an output but an exception. Will think about it tomorrow but other opinions would be welcome
thanks for the continue btw, removed the return but got indents mixed up together and didn't consider that
The broad except trades errors when developing for some unlikely or impossible situations in which users will not get an output but an exception.
I don't understand what "trades errors" means.
To reiterate, I do not believe that under any circumstance a user would prefer to be shown only an exception rather than their output with a missing paste link.
The exception is only useful for the developers. We will log the exceptions and that is enough.
Sure, it may be an unlikely scenario but better to be safe than sorry. I don't see what we lose by using a broad except.
If it required some complex solution then I would have let it go.
Also, aiohttp would have to be doing something like ```
try:
do_ALL_request_stuff()
except Exception as e:
raise ClientError(e)
for it to be safe to catch only `ClientError`. In other words, it'd have to be wrapping every possible exception in a `ClientError`.@patent pivot Think I saw where you were going with the forced py after a few users posted pastes with extensions like makefile or cofeescript; would it be possible to force the py in the url when it's generated through the site ui but then leave the syntax highlight to the actual extension?
went to cofeescript after saving with a random sentence
hmmmmm
works for me
i definitely made the change
haste.prototype.lockDocument = function () {
var t = this;
this.doc.save(this.$textarea.val(), function (e, o) {
if (e) t.showMessage(e.message, 'error');
else if (o) {
t.$code.html(o.value),
t.setTitle(o.key);
var n = '/' + o.key + '.py';
window.history.pushState(null, t.appName + '-' + o.key, n),
t.fullKey(),
t.$textarea.val('').hide(),
t.$box.show().focus(),
t.addLineNumbers(o.lineCount)
}
})
}
ah works now, may have been some caching as I didn't reset it at first
right
Are looped warnings/exceptions fine with sentry? For example with the error discussed above where it retries request 3 times and logs a warning/exception when it fails during that
Yes. Sentry will see it's the same error and increment a counter.
thanks, just wanted to make sure; will probably go with the Exception when I get to it after I considered some stuff
@hardy gorge Should cog name PythonNews? And we have one problem: We will lost commit history when I rename file.
why will we?
Renaming a file should not cause loss of history
hmm
maybe
Okay
It will cause GitHub to not display history
The commits will still be in the git history
I think git mv should normally work; not sure about GitHub
You can still jump to the commit where it was renamed and go from there if the file doesn't have the old history
Python PEP repo had same issue: They wanted .txt rename to .rst, but they reverted it because they lost history
I don't know how critical history is for this though
A git mv for me preserves history locally; maybe it's a GH restriction
I can understand it for PEPs but not so much this
I can still use all the blame tools as normal on the command line
I just found out that PythonNews.channel is not even required. I removed it. @hardy gorge Everything is now fixed
Git will automatically detect renames if a file disappeared and another appeared with exact same content, and git mv makes that more explicit, so you can edit the file afterwards, but the commit will be the exact same
Using git log --follow file show full history
otherwise there is nothing more than renaming
I need some advice
I'm working on code block detection
If someone has pythonx=1 as the first line of their code, this is valid Python
But currently it will delete that line for some reason
Cause it starts with "python" so it thinks it's a failed attempt to specify a language for the code block
What approach should be taken?
Remove the line? Strip out "python"?
Do nothing?
Doing nothing is the safe approach, in terms of not breaking the code
But if they didn't intend to have "python" as part of their code then it would have been desirable to remove it. I suppose there's no definite way to know the intention
Not exactly but that is actually another problem
It's related though
I mean someone could have meant this without a code block language
pythonx=1
print(pythonx)
or this, but with python as the code block language
x=1
print(x)
There's possibly a way to determine if such name is referenced elsewhere with AST parsing but that sounds complicated.
hm
If python was meant as part of the codeblock, wouldn't it typically be on its own line?
x = 1
that has a space between ``` and python
Yeah, but maybe people fucked it up
true
I guess there's only so much we can do
This is for the "preview" it generates, right?
Yeah, exactly for that
People are not meant to copy that as-is (although they do) anyway, since clients on some platforms will strip indentation in embeds
In the embed with the example itself
Do you mean the part with the escaped back ticks?
yes
That's typically what people copy
since it has the markdown escaped and ready to copy
I didn't notice the indentation was messed up. I guess it's fine on my client
How does this show up for you?
!int e
embed = discord.Embed(description="""\`\`\`python
for i in iterable:
print(i)
\`\`\`""")
await ctx.send(embed=embed)
```python
for i in iterable:
print(i)
```
We could still have the preview with a section of their own code, to make it obvious what it adds
I think it will work in non-escaped codeblocks
Yeah it will
But maybe that's confusing, that the unescaped and escaped are different?
Instead of a print it could be a comment like # your code goes here...
I just tested it with the actual detection and it does lack the indentation on my client
Anyway, that's enough confirmation
I don't know, we already limit the character count and most snippets I've seen that trigger this already get truncated
That means that they shouldn't already use the "preview"
(Although they sometimes do)
If the preview makes it clear that it's just an example then they'll be less likely to use it
And it won't be as confusing seeing broken, unindented code
Yeah, true
I will consider that
But for now, I need to figure out what to do about this first line stuff
This code runs if the first line starts with "python" or "py"
# Check if there might be code in the first line, and preserve it.
first_line = content[0]
first_space = first_line.find(" ")
if first_space != -1:
content[0] = first_line[first_space:]
content = "".join(content)
# If there's no code we can just get rid of the first line.
else:
content = "".join(content[1:])
I'm leaning towards not removing the line in the else, but spaces are another issue as you showed
If it has python = 1 and we remove python then it becomes = 1 which is invalid.
That would mean that if we simply don't use their code at all, we'd not run into this
If we basically reduce it down something similar to !tags codeblock
Yeah, I thought that you suggested only changing the escaped block
But still using their code for the fancy final preview
Yeah, I did, but maybe it's just better to have curated example where the escaped syntax matches the output
May be confusing otherwise
That would simplify the code too 😄
It would basically be able to trigger !tag codeblock after a detection
It isn't already asserting that there's a line break after the ```python ?
Well I don't think it should be that simple
It should still parse original code to determine where they went wrong
Like missing a code block entirely, or incorrect backticks, or missing a language when we detect that it is actually Python.
Yes and the generic tag is not that nice to throw in someone's face without telling them why it shows up in the embed
@green oriole Yes. This parsing is for displaying their original code in the code block previews.
Okay
I agree that pasting the code in the middle is too noisy, it does make the screen scroll a lot of you have the badly formatted code, the bot message, and then the correctly formatted code, which happen pretty often
I wouldn't mind just replacing it with a generic example
I do like the specific message we try to give the user about what they didn't do right
With tests that work on snekbox's paste upload, should they be removed (and possibly new tests made for the util function) or adjusted for the new behaviour?
For example https://github.com/python-discord/bot/blob/master/tests/bot/cogs/test_snekbox.py#L56 needs to check a different logger, but then it doesn't feel needed at all in snekbox tests specifically
making new tests for the func shouldn't be too hard but not sure if i should keep those in in that way, or reduce them to just test the base behaviour of the method snekbox has like len limiting
The test should be moved
If you can salvage stuff from it then go for it
There should be tests specifically for testing the utility function
And then snekbox and who ever else calls the function should have their own tests related to it (which may just amount to asserting it gets called). The callers should only test what they're responsible for. Snekbox is not responsible for the internals of the utility func so it should not test internal behaviour (if anything, it'd be mocking it at this point).
so i saw something about how having eval in your bot can be dangerous. I heard that @stable mountain did it with snekbox. Can someone explain how snekbox works cuz it's not that clear to me, sorry...
Snekbox basically run code in a sandboxed environment using a tool called nsjail

GitHub
A light-weight process isolation tool, making use of Linux namespaces and seccomp-bpf syscall filters (with help of the kafel bpf language) - google/nsjail
To be short, this tool allows you to make restrictions about what the process will have access to, snekbox place the whole filesystem into read-only, limit PIDs, memory and run time
Is there an explanation on how to set it up for your own bot? Because I tried doing something with the eval() command but I heard that's dangerous.
it's complicated.
Oh
the solution we're using is open-source, but getting it running with your own bot isn't trivial
GitHub
Easy, safe evaluation of arbitrary Python code. Contribute to python-discord/snekbox development by creating an account on GitHub.
essentially, the bot is making a webrequest to our eval API (which we wrote ourselves, that's snekbox), and that API has several layers of sandboxing
it also enforces certain defensive measures like limiting execution time
put all of this together and you get reasonable safe (but probably not completely unbreakable) eval
but it's literally thousands of lines of code
The problem with executing Python code is that, well, you're executing Python code. If someone knows their way around Python and their code gets executed in the same process as your bot, it would be trivial for them to totally take over your bot and/or steal your token.
While eval does not have the power of say exec, it still comes with major security risks
if you're able to set up snekbox on a server of your own and write some bot code that talks to it, it's not impossible to get this working on your bot. but it's not something we're willing to provide lots of help with because there's only a few of the core devs who truly understand this system and those devs are very busy.
so it's pretty much left up to you to figure it out yourself. but all the code is open source, so.
If you know your way around docker, pulling the image and running it isn't super complicated, though.
I will try. Thanks guys :)
It's well described in the README
I think you'll have to figure out the API requests it takes yourself
could look at our snekbox cog
Yes.
I don't think setting up snekbox is as difficult as it used to be; Mark did an amazing job making it accessible, but do note everything we say in the license: use it at your own risk. We've tried our best to make it safe, you'll have to do your best to deploy it in a safe manner, and even then there are no guarantees given.
I will try. Just in case, who is one of the core devs that do understand this system just in case i want to contact them later, or is that classified?
like I said, we won't be offering support with it so I'd rather not say. If you must ask someone, ask me.
alright.
Snekbox is really easy to setup, it is a docker image
python-discord/snekbox on the docker hub iirc
You just need to send it a request with the code as an header, and it will respond with stdout and the return code
@tawdry vapor any ideas on how to set up common tests for the unixcmd/pythoneval API endpoints?
i attempted to store them in a separate "common" class, but even though i'm inheriting both SnekAPICommonTests, SnekAPITestCase, for some reason the common tests aren't being run (and I'm not sure what I'm doing wrong)
I can't answer that but I did just peek through changes, should we not namespace these to like /eval/python and /eval/unix or something
It would sound more logic to me
I'm not sure how unittest discovers tests and resolve them
Maybe a decorator would work better, by attaching the functions, dynamically, because here it isn't really owning the functions
@patent pivot that's the better idea, yes
i'll work that change in tomorrow
it will also make the tests much easier
@clever wraith On one hand, I think such a problem signifies that the API resources themselves should be merged into a single class that can be tested. On the other hand, those resources are already very simple and keeping them separate allows for separate documentation. If you can think of a good way to merge the resources, then do that. It will remove the issue of trying to apply the same tests twice.
If you can't find a good way then you can use subtests to loop through the two endpoints or something.
@patent pivot oops, forgot to change this. Applied suggestion
okay, testing locally this does all look good now
I've approved, someone else might request changes but I hope this is it
So i'm writing some unittests for a file, and I can't seem to hit a branch even though I feel I should hit it.
~/.../pydis/bot >>> pipenv run report -m bot/cogs/antimalware.py ±[A9●][test_antimalware]
Loading .env environment variables…
Name Stmts Miss Branch BrPart Cover Missing
---------------------------------------------------------------------
bot/cogs/antimalware.py 38 0 17 1 98% 62->exit```
<https://github.com/MrGrote/bot/blob/test_antimalware/tests/bot/cogs/test_antimalware.py>
<https://github.com/MrGrote/bot/blob/test_antimalware/bot/cogs/antimalware.py>
I believe that the `test_message_with_allowed_attachment` test should hit this case.
Adding a print on line 61 shows that embed.description is indeed falsy here, and the code inside the if doesn't get executed.I've had weird branch coverages issues before too that i could never solve
I don't know what's up with this
By the way, subclass unittest.IsolatedAsyncioTestCase so you can make your tests async rather than using asyncio.run
Alright, thanks for the tip
I think for the sake of your sanity, don't worry too much about the coverage issue
It doesn't seem to me your test is actually missing anything
You assert delete isn't called and that is good enough
I think I missed something and it automatically requested reviews from people?
That's standard
It does that when the PR is created
Just picks a few people from the team
Ah okay
It confused me when it first did it
Also had partial coverage with on an if like that, didn't manage to figure it out even with a few test cases to make the condition false
Any thoughts on the format of this before I proceed with tests? https://github.com/python-discord/bot/pull/886
GitHub
Fixes #829
Description
The entire system has been rewritten with the following main features:
Detection in messages with multiple embeds and normal text messages between them
Instructions state ex...
Haven't looked at the code, but for the first and 3rd point in the criteria; is REPL code ignored to keep the valid python check direct and simpler or a design decision?
I don't think the language needs to be all lowercase, the example provided in the PR description (PYtHon) highlights fine:
print("test")
for x in range(3):
# ...
print(x)
Only other nit is that I'm not really sold on enforcing that a code block specifies a language
Damn you're right
I got mislead by the WYSIWYG editor not making it green
😠
@brazen charm Sorry, I think my phrasing was ambiguous. Neither Python nor Python REPL are ignored. Everything else is.
@woeful thorn Can you elaborate on your reasoning for holding that opinion?
Keep in mind it's only suggested if we know that it's Python code. It also ignores blocks with fewer than 3 lines. I agree that for shorter blocks it's not always necessary. I could up the line threshold if you prefer.
I don't think it's worth enforcing, the primary benefit of using codeblocks is that it preserves formatting
Plus syntax highlighting doesn't even work on mobile
At least on iOS
If code has no syntax highlighting I will 100% copy it over to my editor.
If it does have syntax highlighting I may end up just viewing it in Discord, but I still often copy code over.
That's fine. I don't think it should be mandatory
It's a convenience thing for readers.
It isn't really mandatory, they can just delete the message.
I think suggesting it would encourage good habits
@tawdry vapor Believe you can do split(n, count+1) and then compare than len-1 is equal or bigger, without checking the last item (if that looks better)