#dev-contrib
1 messages · Page 34 of 1
So far that's the only OS that shows issues with Docker. Possibly 8 as well, not sure
windows <10 will probably work OK with toolbox
it's still worth remembering that toolbox is unsupported though, maybe at some point we'll need a feature that isn't part of that docker version
well, I don't have a machine to test on unfortunately
And yeah, the fact that it's unsupported also makes me not want to suggest it
I don't want to suggest a hack, I want a solution for our users
there is basically a compromise to be made for working on the projects on w10 home right now
try to set up docker under WSL
or download and manually set up postgres
Which we already have a functioning guide for
tbh I think the latter is less painful
Exactly
right, okay
I think we're all on the same page regarding W 10 Home's status in this. @hardy gorge I also think there's been a general consensus to keep the "Use Docker" option as the primary for the guide, especially since there's only one OS (and in fact only one version of that OS) that throws a wrench in it
the latter might be automatable as well tbh
Yeah, it does have an unattended mode
download installer, run unattended, connect as superuser and create the pydis role
I'm not attempting to dismiss the others experiences here, as I know that Ak did have issues getting everything set up. However I feel that we will be benefiting more people by keeping Docker as the primary suggestion with a "Using Win 10 Home? Do this instead!" option
I agree, I think
the entire stack uses docker so it's more useful for people to be able to use docker if they can
something about the project having to be on C: by default would be nice too, that kept me for a bit with the site not finding its files
I was under the impression that it was drive agnostic
It should be, it's Python
Well you mentioned it to me gdude
I don't remember that at all
Is it that the project has to be on C or that the site/database instance has to be on the same drive, regardless of the letter?
I could certainly see that causing an issue
it also worked when the site was ran under the bot, but then the bot didn't want to run
That's bizarre. I think we'd have to see the errors or logs in order to work that out
If you can still replicate it
my main problem with docker was that I couldn't find anything about the problems I was having, and if I did find something it was linux
could try but I wiped all the containers
Ah, no worries then
A lazier option would be to point to somewhere you can download a unix/gnu based-OS :p
Or not
I severely doubt that installing a whole new OS would make it better.
joke
Regardless, I think we can make a troubleshooting guide as we find and squash problems
Or just correct it in the code as we receive the problems
I'll totally admit, when I first tried docker it was a chore getting it to work, but it's been incredibly simplified with all the commands we have in the projects
On docker you can't use pgAdmin to inspect the database?
pgAdmin start with the container?
It being in a container doesn't mean you can't access it
Same way with a website. Just because it's on a different machine entirely doesn't mean you can't access it. It has ways built in for you to access it from the outside
pgAdmin isn't part of postgres, if that's what you're thinking
it's just a client
in the same way the site is a client
I think this will need to be discussed further first. This is an important part of our projects, so I want more input from our core developers group as well before taking a decision. We can obviously "blame Windows" for being the odd one out where it does not work, but it is one of the most used operating systems and probably the operating system that is used the most by new contributors, both for bot/site and for seasonalbot.
From that perspective, I think a guide that fits more people and works cross-platform (which is not impossible, since dockerless isn't an issue on linux/macos) should probably be the default guide. There should preferably be single, good, and general way of doing things.
I guess I also don't understand why there has to be a dominant choice
how hard is installing postgres on windows anyways
Much easier than installing docker
yeah
I use pyenv for managing venvs & postgres on system and it works flawlessly, i'm on macos though
The ideal situation for me would be a single, good, main guide that most people are familiar with, instead of multiple, different guides less people are familiar with and have to be maintained separately. We already basically have just two or three people who can even help people set up our repositories on Windows.
It's pretty easy and you could actually just do it with a Python script
Since you can specify everything needed on the command line for an unattended install
I wouldn't mess around with system dependencies from an unattended script
also would avoid too much magic
The windows installer actually has tons of questions and stuff, and unnecessary addons, etc
Postgres on windows, the last time I did, was basically download installer, run installer, check installation
Yep
And I don't think we're suggesting multiple guides, just 2. And they're ones that we essentially already have
Our current guide literally covers both use cases
Our current guide only mentions the docker way: https://pythondiscord.com/pages/contributing/bot/ & https://pythondiscord.com/pages/contributing/site/
As I've said before, I'm not saying do away with docker; I'm saying write a good, main guide that should work on all platforms; have a secondary guide for user who like to use docker.
I'm probably going to continue using docker, I like it
Whatever works
Did anyone figure out that docker logging output problem?
I basically just use docker for postgres right now because of it
I was unaware there was one
Yeah, I noticed it with the site
Running it under docker loses half of the log output in dev
It's come up a couple times here
Is there an issue somewhere?
I'm not sure
Yeah it's hard to keep track here, unfortunately
Oh right yeah
yes, docker uses a SECRET_KEY; if that changes, your session is invalidated
Oh, that was a separate problem
If you have the dev server, it reloads on every change and the SECRET_KEY changed every time
Oh, then I probably don't know what you're talking about
Hmm, oh, right, I read your sentence wrong
I probably said I'd make an issue and forgot tbh
On mobile right now
Also, there are parts of .idea that are safe to put in the repo
Has the possibility of putting run configs in the repo for PyCharm been talked about?
seems like bloat. far from everyone uses pycharm.
Far from everyone even in our contributors use it
Talking about run config, can we add to the site pipfile the commands
run = "python manage.py run"
rundebug = "python manage.py run --debug" ```?Yeah maybe we can name them differently
I'm tired of typing pipenv run python manage.py run --debug 😄
I mean it should just be pipenv run start --debug
So I'm not 100% sure how pipenv run rundebug would be that much of an improvement or necessity
Instead of using DEBUG_MODE why don’t we just use __debug__? It’s build-in.
How's it work?
No
When you regularly run Python, __debug__ is True; if you run it with - O, or -OO, you run it in optimized mode
Ahh
One O will discard things like assert statements, with two, it will also discard docstrings
So what's the story behind the site-bot dependency? Seems a little bulky to need the site up to run the bot, at least for a dev environment. If it's just about the database, would it be possible to locally switcharoo the postgres with sqlite, to decouple things a little? Or is that just a terrible idea?
You don't need the site to run the bot
But it does need it for a lot of functionality
Oh, I was told I did
Part of the point is that the site can then be used as a management tool as well
Bot tags? Easily created in the Django admin
Quite a lot of functionality does require the site
Large parts of the bot depend on the API, both for getting information and sending information off. Running bot without site currently gets you a lot of exceptions.
A few basic things don't, I think
we've gone a few rounds in the past about decoupling.
I fought pretty hard for it some time back.
but we were unable to reach a consensus for a number of reasons.
Oh yeah, I remember that!
right now, as it stands, the coupling presents less of a problem than it ever has before
unless you're on Windows 10 Home ;)
...unless you're on Windows 10 Home.
😄
Haha
but if you're not, setting up the services to talk to each other is really easy.
Yeah
and also, many argued that it's good design to have the bot make API calls.
having one database that's being accessed by two services is messier.
and has more potential for fuckup
Yeah, I think that was the argument I made
That's the general advice given to people who consider that for Django in general
Let Django take care of the database and communicate with Django
yeah
However, I do think there's an option for decoupling, but it's not perfect.
It doesn't allow you to test insertions, so it's useless for database modifying things
having the bot use a second database (like sqlite) also comes with downsides, particularly with the data that it makes sense to have both the site and the bot get access to.
We can’t just extract the api app and distribute it somewhere, so people doesn’t need to run the site entierly?
My main concern is, where do you do migrations? Do you use an ORM on the bot too? How do you share models?
we have actually considered setting up a staging site
and allowing bot devs to just talk to that
We did say we did not want to make that open to all, since, well, people will abuse it
mmyeah.
so if we do it, it might be accessible to contributors only, or even to core devs only. security policy still tbd
yes
We cannot just make an archive, host it on a server, and when you want to run the bot without the site, it just pullit from the server, unpack it, and run it?
How would you run an archive?
We call that Docker I believe
Yeah
That's basically what it does: A container that contains the stuff you want to deploy
Anyway, I hope WSL2 comes out soon
and this will not be an issue anymore
In what way?
Microsoft has stated that it will be available for all versions of Windows and docker is building a Windows version of docker for it
It includes enough of hyper-v to make the virtualbox in docker toolbox not work
And we tried to use docker under it already
It does run, but you can't actually get at it from windows
docker is building
Docker is building an actual new version of Docker for Windows specifically to be run using WSL2
not has built

Docker Documentation
Overview Welcome to Docker Desktop WSL 2 Tech Preview. This Tech Preview introduces support to run Docker Desktop with WSL 2. We really appreciate you trialing this Tech Preview. Your...
can be tested already, looks like
I think @green oriole is on the insider preview so it might be worth a try then
haang on

What’s Changed Since the Tech Preview Earlier this year, we released a technical preview of our vision for the future of Docker development on Windows using WSL 2. We received lots of feedback from Windows Insiders via different channels, and collated common failure cases. ...
oh shit
Yeah i could try
24th of october this was posted
Oh, super recent
it looks like this is out, guys
I’m going to try this afternoon
Well, WSL2 is still insider preview I think
Yeah it is
Yeah i guess that was for the best
Yes it is in the preview
Further down in the article, you can read that it's still in progress
There are changes still planned to solve issues that our, as of now, still there
but, it's looking promising
Damn, that's a big time window, haha
As it appears, it requires some major updates to Windows as well
but if the preview is relatively easy to install, and if it works well with the new docker experimental wsl2 mode, then that might be a legit alternative for those poor windows 10 home users
Yup, I agree
What effect does signing up for the insiders program have?
Windows Update starts installing preview builds, ves
I asked for disadventages
That's about it
hahaha
you said EFFECTS
yeah

it's a testbed basically
but not blessings
You're supposed to give feedback in the feedback app
I don't know anyone that does though
It also enables a shitton of telemetry
More than you'd ever see in a stable build
You can't turn it off either
Anyway, if it means that they'd get beta-updates or alpha-updates by default, I'm not sure if we can recommend it. We can suggest it, though
Ah, telemetry
Windows update enforces the telemetry setting on preview builds
If you don't update, the builds expire
So it's a fair commitment
The main downside of insider is that once you activated it, you can’t roll back to main release without reinstalling windows, even if it break stuff
well you can, but you have to wait for the next stable
and turn off insider preview before it comes around
yeah it reverts eventually through updates
i turned it on once, but removed that windows install
now i get nonstop insider emails that i can't turn off
fun
You can turn it off, i did it
I used insider preview for years because I installed it literally as soon as it existed
like, w10 prerelease
it was relatively stable back then, but today.. eh
pretty sure emails stop only when you turn off insider
which requires a win10 install
ill try again though, who knows it might be possible online now
the pains of not installing corefonts
yeah it doesn't fall back gracefully, does it
yeah, no, haha
any thought on using __debug__? It could avoid setting DEBUG_MODE in __init__ in a inelegant way.
It's not really a simple option I don't think
most people will never run with -O or -OO
it's just not very obvious and it can be handy to run debug mode code when running in optimised mode anyway
But it's also handy to run the bot without debug mode when testing it, which is not possible now, without changing the code. And I'm pretty sure no one did run the bot repo using -oo when testing it.
Anyway it was just a proposition, since __debug__ variable is very often forgotten
it's definitely possible
Maybe the best way to implement __debug__ would simply to assign DEBUG_MODE = __debug__without replacing it every time in the code-source.
This way it could be still possible to run debug mode and optimised mode, by manually setting the value of D_M to True. But since it's not a common practice, changing the code to achieve it seems fine to me.
But.. I don’t want the debug mode
i want to run as if it was in production
Configuration is good
which you won't be able to do with either pipenv or docker-compose if you have to use -O, yeah
Debug mode is useful due to debug logs
Leave the choice to people
Well currently there is no choice, debug mode is activated when not on the server
You can still set the env var to run in debug mode, i don’t see the point of using __default__
I have it disabled
DEBUG_MODE = True if 'local' in os.environ.get("SITE_URL", "local") else False
weird default value there
exactly
But.. the SITE_URL is not set to local isn’t?
that's not what the conditional says
although this whole line is too long
it could just be "local" in os.environ.get(...)
This line is wierd
I don't really understand this default value, that's why I propose a cleaner set of the variable
It's probably there just to make things easier for contribs
I don't personally see a big reason to change it
is this bot
yeah
yes
yup
right, config adjustments are going to happen soon as peeps know. suggestions about how to improve configuration is always welcome especially with it coming up.
specifically on this topic though, we are making it so debug is able to be chosen to be enabled or disabled by configuration
I was gonna say, default to this, override in config
yep
Yeah there a config file, why we don’t use it?
in config.yml?
Yep
both config.yml and env vars will be supported
well the entire config system will be overhauled anyway, as scragly said
will be an interesting issue/PR, that's for sure
we can't do relative import in a __init__.py
yeah you can
what's a relative import got to do with this?
# We can't import this yet, so we have to define it ourselves
DEBUG_MODE = True if 'local' in os.environ.get("SITE_URL", "local") else False
Idk I just read the comment
well yeah, see, there is the debug mode paradox
With debug mode, what's the purpose of all the extra logging? Some are useful but things like typing start could be controlled elsewhere as they're not needed most of the time and clutter things up a lot
you want to do debug logging when loading the config
but you need to load the config to set debug mode
it's fine, i'm sure we'll get a good solution to get what we need
Yeah, I believe in the team
what's the typing start reference numerlor?
My point was to fully exploit built-in variables
__debug__ is too special to be used imo
There are debut logging events when someone starts typing
Or at least they appear like it
https://i.imgur.com/Bb4tIoH.png for every message that is sent
Good things come in threes.
is it set in the bot? If it can be I think it should be moved from the normal debug
it's normally silenced @brazen charm

GitHub
Source code for our Discord bot. Contribute to python-discord/bot development by creating an account on GitHub.
I've got it by default and that's all I care about, disabled it but it was getting in the way of everything before that. So it should be changed if possible imo
about the doc command I'm working on, should "New in version x.y." be removed from the top of modules or stay there? https://i.imgur.com/znczmbx.png
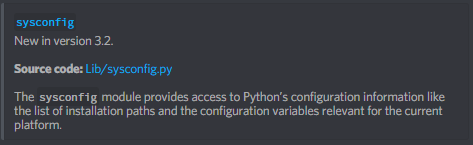
i kinda like it
ain't that the truth
we can't upgrade our python because it will cause catastrophic failure of the staff coffee machine
Any thoughts on blacking the code once the PRs have died down a bit by the way?
I wasn't a fan of it initially but I've started doing it to my projects
is this literally just using black on the code
yes
I don't think there's much of a point in trying a third time because I just can't see the consensus going differently than it has
is black's style the same as ours
no
but not that different; we've had a discussion with comparisons before
I'm not sure black would conform to some of the rules we set in the linter, like flake8-docstrings.
i think we've settled pretty well with a particular set of consistent styles
It does, I use it for flake8-annotations
and it wasn't that long ago we actually applied all the linting rules
mkay.
(Not explicitly)
black isn't a linter, it's just a code reformatter. you'd run a single pass through all the code to make it all consistent.
I mean the advantage is that you can code in your own style, right?
and then black "fixes" it
besides, everytime there's a style change, we've gotta review a massive amount of code changes and it destroys blame
you still need a linter though, yeah
yeah it would really annihilate blame
yeah, it would, that's true
blame?
some people will add it to a precommit though and then most linting is no longer necessary.
it allows you to see who changed what line most recently, yeah
okay
I wouldn’t mind it for new things but there’s no will to do it for the existing codebase
yeah I agree.
I do wonder just how many changes it'd make though
last time we tried it did a lot.
I mean my projects were mostly conformant already and I basically follow pydis style
pydis style
it just outright skipped some files
that makes me shudder a little
haha, sorry
We did try black the previous time we discussed this
Let me see if I can dig up the examples
I should have kept the branch
yeah and then the core devs subsequently shot it down
I mean hey, if it's a bad idea, it's a bad idea
@hollow lichen here's what i see as an example when i code
I think it’s a great idea 😬
it's definitely a marmite tool either way
I don't mind either way but I do agree with some of the arguments that were made against it.
my cursor shows blame for the current line
yoink
@glass pecan Oh ok, since I don't use and IDE I don't see them outside Github
we use it in gh too, yeah
can still see blame with git blame
I sometimes browse the git blame history to find the commit message of a certain decision
same
but not all historical commit messages are, well, informative
sadly.
thats why commit messages are important
yes

and also why addressing linting late is bad 
this xkcd makes me upset
:>
It's totally not okay
Yes, but, luckily, usually the git blame around the linting errors stays intact even with linting corrections and/or you can view the previous blame. It's just more work.
some people also don't realise you can put lengthy descriptions in commit descriptions after separating the summary with the body with newlines
Created main loop & timing control is almost a worse commit message than misc bugfixes because the former could really use some more info while the latter may or may not be that important.
I hope this is just the oneline log
but, randall munroe is not a dev, so probably not
yeah, true
well anyway
like I blacked django-simple-bulma in my django-simple-buefy fork and most files were untouched
but that's a fairly simple project I guess
I'm mentally preparing to be yelled at by lemon whenever my first commit drops. I'm sure I'll be breaking dozens of best-practices rules
inb4 lemon only murders people with his fistpunchers.
The reviews are there for a reason :P
he lulls you into a false sense of security, gently guiding you into doing things exactly how it's meant to be done, only for you to realise eventually that you're suddently spending way too much time contributing for pydis projects in not only your free time but your sleeping time, working time and eating time. you inevitably become the pydis slave you were meant to be
well yeah, people who don't lint aren't even human
you sound bitter, @glass pecan
not bitter, resigned
Lol. I'll invest in some body armor.
resigned to my fate
I'm not very yelly, that much is true.
I wonder how much GitHub would charge us for an enterprise server
make sure to already have a PR open and merge master like, 6 bajillion times before it's ready
probs a lot
oh, they'd charge you plenty
@past falcon you got precommit enabled?
Then we could have hooks to bounce pushes if they fail linting
that's a thing eh
yeah, true
still not worth the money
you can do hooks server-side if you control the environment
I think so 🙂 The pipenv run precommit?
I mean, I had precommit enabled but still failed the build because annotations didn't get installed properly
Gotta run them tests too
still not used to tests in bot
yeah
I've failed a few builds because I made changes to constants.
and the test got fucked up
I'm still not happy with that monolithic test file on site
literally first time i touched django personally with a pr i ended up forgetting about 100% cov
but still have no better ideas
@brazen charm keeping issues to yourself doesn’t help us fix them
@molten bough eh? don't we have a bunch of test files on site?
oh sure, but you saw the allauth test file I wrote
like 200 lines of setup and then 50 lines of actual tests
It just didn't install properly what issues are you on about?
dude we have some tests that are thousands of lines where I work :(
your 250 are a dream compared to those
yeah but I bet most of that is actually tests
not really.
Not an issue you could influence afaik
is that the pipenv hash check failure you get at random?
could other people run into this problem?
is there anything we can do to prevent future contributors from experiencing that issue?
My setup is different from the guide and had a few issues at the start so I really don't think it's something you could fix
One thing that bit me setting up the bot was that the contributing guide suggested to put
site: &DOMAIN "web:8000" in the yaml file, but what it turned out to want was
"pythondiscord.local:8000"
yeah, this is one of the things that annoys me - it's because we have multiple approaches to how the containers should speak with each other.
the bot can set up a site in the docker-compose which you need to access via the docker container name
or you could be setting up site seperately with the other guide
in which case you'd want to use pythondiscord.local
we should just have a single way to do this, and imo, it should be the latter way..
but the former is undeniably convenient if you have no intention of ever working on site
Ah, ok. Yeah I'm one of those dockerless win10 homers. @green oriole saved the day though and helped me soldier through it, I have something functional now ^_^
but rest assured that we're aware that the setup isn't perfect on every platform and we're thinking about how to improve it.
yeah i didn't think w10 home would be such an issue, as even if you're working on having bot and site separately worked on, you can easily run both together using the project name env var
it'll probably change a lot over the next year, in various ways.
@hardy gorge I'm working on testing the pep command among other related commands, how would I mock the http get? I can't seem to monkeypatch bot.http_session
It depends how exactly it's being used
Why can't you mock it?
If you're importing it somehow you can mock out the import
rather than the definition
Do you pass a MockBot?
yep
Because that one has a mocked http_session attribute ready to go, if I'm not mistaken
Let me check
apparently not
Are you using the latest version?
>>> from tests.helpers import MockBot
>>> bot = MockBot()
>>> bot.http_session
<MagicMock name='mock.http_session' id='140019569944336'>
AttributeError
Right, so
The problem is that http_client is a custom attribute we set on our bot, not one that discord.py provides.
That means that when trying to access it, it doesn't follow the right specifications and it will throw that error to indicate "You're trying to access an attribute that should not exist"
You can get around that by explicitly setting that attribute on that mock
if it ever happens again
>>> bot.something
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/unittest/mock.py", line 593, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'something'
>>> from unittest.mock import MagicMock
>>> bot.something = MagicMock()
>>> bot.something
<MagicMock name='mock.something' id='140019542812112'>
I think the README has some more info about that
give me a second to rewind and check again, could've sworn I had the attribute error trying to assign a mock 👀
hmm, that could be it
One more thing I wanted to ask, a lot of (stdlib) module descriptions end like this https://i.imgur.com/dTczax1.png should the last line be removed if it ends with a :?
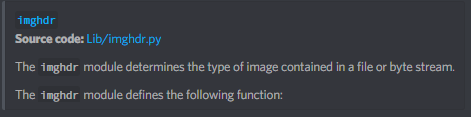
don't see any problems with that
How do you restart docker itself? Had to restart my pc after putting it to sleep
on linux, sudo systemctl restart docker - at least on most distros
Yup I have to do that command every time I resume my VM otherwise containers cannot connect to the internet 🤷
whats this mean?
thanks
i have no skips locally 🤔
oh, maybe we need to set a fake token
we do, weird
oh now I see why
The skips are the 10 lists/dicts in constants we do not yet validate
mhm
should all the constants be global level or would it be okay to have a class attribute? For example I have a tuple of around half a dozen strings I end a search on, where would I put the declaration of that if it's pretty much only used in one method? Did it on the top so far but the class attribute makes more sense to me here
I prefer to have them at the top since they can all be in one place in all possible cases then
Yeah I think consistency needs to win out on that
Can I please get assigned  https://github.com/python-discord/bot/issues/600
https://github.com/python-discord/bot/issues/600
GitHub
Write unit tests for bot/rules/links.py. Implementation details Please make sure to read the general information in the meta issue and the testing README. We are aiming for a 100% branch coverage f...
Done
thank
I'm having a bit of an disagreement with PEP 8 E131 and flake8, it wants hanging indents like this
search_end_tag = search_start_tag.find_next(
lambda tag: any(attr in tag.get("class", ()) for attr in SEARCH_END_TAG_ATTRS)
or tag.name == "table"
)
but I think this makes more sense and is clearer on the intention
search_end_tag = search_start_tag.find_next(
lambda tag: any(attr in tag.get("class", ()) for attr in SEARCH_END_TAG_ATTRS)
or tag.name == "table"
)
Should I just go with the one that passes the linter? Or reformat it even more
maybe just refactor your multiline lambda into a function and pass that?
I agree
that code is just too much to handle for reading 
Also I disagree that the second is clearer. I rescind this, I misread the code originally
@sleek mason are you sure the bot token is the issue? maybe you're making requests to the prod API or something
hmm it's possible yeah
did you follow the new guides?
Should the any also be broken up? Thinking how it could be done but can't think of a clearer way that doesn't loop over it and checks itself instead of using the builtin
i did all of the config changes in the contrib guide, i'm pretty sure
lemme double check
the guide on our website, right?
yeah
We're a large, friendly community focused around the Python programming language. Our community is open to those who wish to learn the language, as well as those looking to help others.
@brazen charm for example ```py
def predicate(tag):
x = any(attr in tag.get("class", ()) for attr in SEARCH_END_TAG_ATTRS)
return x or tag.name == "table"
Though give `x` a better name@sleek mason you're docker compose uping in the site repo?
Or just turn it into a for loop
or just letting the bot run both
i'm doing exactly as it says here.
is there any particular way i need to do it, perhaps?
I made this to avoid the empty tuple check, or should I just use the any
@staticmethod
def match_end_tag(tag: Tag) -> bool:
if tag.name == "table":
return True
tag_attr = tag.get("class", None)
if tag_attr:
for search_attr in SEARCH_END_TAG_ATTRS:
if search_attr in tag_attr:
return True
return False
ah fuck i need to make it "pythondiscord.local" in there don't i
yeah
that won't resolve if the bot is running under docker
i definitely changed that according to this before but apparently it just didn't save like that? fuck knows
if you get a mention in the other server again, then that's a no haha. give me a moment
yup, that's worked.
good!
i swear my previous issues with setting up the bot were because of a misconfiguration of that
it must just be a me problem
happens.
just hope i'm not going senile :D
okay well, thanks a bunch. now i can get working on whatever bot/site stuff i can without harassing everybody with @everyone mentions
(but i swear i definitely changed that to "web:8000" before. i specifically remember doing it. oh well.)
@brazen charm Hmm that looks too convoluted
This may be the best IMO ```py
def predicate(tag):
for attr in SEARCH_END_TAG_ATTRS:
if attr in tag.get("class", ()):
return True
return tag.name == "table"
The `any()` would still be too long I think, if its variable was given a proper name.Downside is it doesn't return early on the name comparison
If it's a marginal performance gain then it's better to sacrifice it for readability
the default tuple feels a bit hacky to me for some reason
I think it's OK
when i try to git push --set-upstream origin zen-command i get myself a jolly good ```
ERROR: Permission to python-discord/bot.git denied to kingdom5500.
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
am i forgetting anything or has something changed? :DThat's trying to push to our repo rather than a fork
Maybe you were not given appropriate permissions on github
I cannot check for you though. Maybe @patent pivot can
ay up
will have a look
nope I don't see anything @sleek mason
you are in all the required teams
plus it's a read error, not a write one
how queer.
this isn't a permissions error, it's a key thing presumably
You need it when you create a new branch
2fa?
keys bypass it
I thought ssh disregards 2fa
yeah it does
I mean you need it on your account right?
i have it.
Ah okay
ssh git@github.com approved: Hi kingdom5500! You've successfully authenticated, but GitHub does not provide shell access.
i have no idea either.
origin git@github.com:python-discord/bot.git (fetch)
origin git@github.com:python-discord/bot.git (push)
looks fine and spicy to me
Yup
yup.
hold on
you arne't in the staff team
what
what tteam are you in then
you are only on the esoteric challenges team
hm
Aha
fixed @sleek mason
not sure why that happened, could've borked during transition to staff team i guess
lol
oh well haha
¯_(ツ)_/¯
Big tangent in #python-discussion if anyone is around
It's not technically rule breaking I think? So don't wanna ping mods
I don't know about you but it looks like a part of the tag is missing here
!f-strings
In Python, there are several ways to do string interpolation, including using %s's and by using the + operator to concatenate strings together. However, because some of these methods offer poor readability and require typecasting to prevent errors, you should for the most part be using a feature called format strings.
In Python 3.6 or later, we can use f-strings like this:
snake = "Pythons"
print(f"{snake} are some of the largest snakes in the world")
In earlier versions of Python or in projects where backwards compatibility is very important, use str.format() like this:
snake = "Pythons"
# With str.format() you can either use indexes
print("{0} are some of the largest snakes in the world".format(snake))
# Or keyword arguments
print("{family} are some of the largest snakes in the world".format(family=snake))
thanks for the review btw @exotic ember, changes have been made :D
What's the difference between and standard endpoint and an extended one?
For infractions? The data it includes in the response
If you look in the viewset for infractions, you can see that a normal request only gives you back the user ids for actor and user
#### Response format
>>> [
... {
... 'id': 5,
... 'inserted_at': '2018-11-22T07:24:06.132307Z',
... 'expires_at': '5018-11-20T15:52:00Z',
... 'active': False,
... 'user': 172395097705414656,
... 'actor': 125435062127820800,
... 'type': 'ban',
... 'reason': 'He terk my jerb!',
... 'hidden': True
... }
... ]
yes, I would like some help with https://github.com/python-discord/bot/pull/508 because I'm drowning. I looked at the post_infraction code, but don't understand where set an extended endpoint
GitHub
If the user has not changed its nickname, display None, otherwise display its current nickname.
closes #337
In the extended endpoint, you'd get back the full user information for the actor and user field
So, the 'user' field now gives you this information directly:
#### Response format
>>> {
... 'id': 409107086526644234,
... 'avatar': "3ba3c1acce584c20b1e96fc04bbe80eb",
... 'name': "Python",
... 'discriminator': 4329,
... 'roles': [
... 352427296948486144,
... 270988689419665409,
... 277546923144249364,
... 458226699344019457
... ],
... 'in_guild': True
... }
That means you don't have to make a second query if you're interested in more than just the user's id
You can access expanded routes by modifying the endpoint url:
### Expanded routes
All routes support expansion of `user` and `actor` in responses. To use an expanded route,
append `/expanded` to the end of the route e.g. `GET /bot/infractions/expanded`.
instead of
await self.bot.api_client.get(
'bot/infractions',
params={'user__id': str(user.id)}
)
``` I should put `expanded` somewhere?ty, I was close then 🙂
The endpoints are documented in the viewset files over at the site repo
This is the one for infractions: https://github.com/python-discord/site/blob/master/pydis_site/apps/api/viewsets/bot/infraction.py
ok
I added expanded and it looks like it break management.py
TypeError: unhashable type: 'dict'
Can you paste the full traceback?
nop, the error_handler does not help 😦
Did you change the endpoint for the whole cog? If so, you'd need to change all parts that rely on the response. My suspicion is that various parts now expect a bare ID, not a dict.
Now, @tawdry vapor is working on two moderation related PRs that change quite a bit, so changes throughout the cog may lead to problematic merge conflicts.
Well they're actually done; just need review
In any case I do not mind resolving conflicts if it comes down to that
Though I did not touch the management cog IIRC
I have to say I'll gonna run out of time for finishing https://github.com/python-discord/bot/pull/508
GitHub
If the user has not changed its nickname, display None, otherwise display its current nickname.
closes #337
What do you mean?
I'll no more have time to deal with it
Next week I'll be very busy IRL, and I also got other projects in python.
I just want to warn I may not be able to finish this PR
How should exceptions be handled? Did this https://paste.fuelrats.com/narekeramu.py for https://github.com/python-discord/bot/issues/381 but not sure if it's correct, with the scope of the handling and how it's logged
Hey hey, not being pushy at all, I know its a large-ish PR, but wondering if there was any word on https://github.com/python-discord/bot/pull/519? 😃
GitHub
redirect_output has been adjusted to run the delete_invocation inside a task as the help command will wait for that to run before sending the help or doing anything else.
pagination has been adju...
not sure I can do a full review, but I'll point out stuff I see
👌 cheers
also, assuming the deps automatically use d.py 1.2.4 (~=1.2 should use the latest version, 1.2.4?),
https://github.com/python-discord/bot/blob/master/bot/patches/message_edited_at.py
patch got fixed in commit
https://github.com/Rapptz/discord.py/commit/6ed5a21a78182bfa31e3757866bf3975af4b606c
If we were to rely on that we'd have to change the pinned version anyway
Otherwise, I think existing venvs won't be updated
since 1.2.3 would technically still match the criteria
but I don't know the details of how pipenv locks
Actually yeah cause pipenv locks, it will lock to 1.2.4 anyway
I think what I am saying is only relevant in like a requirements.txt, which we don't use
But would still be a good idea to make it >=1.2.4, ==2.*
The way we pin should allow for patch upgrades, but we do need to relock the environment. Regardless, people will have to update their local env with the new lockfile.
So, we should not have to update the dependency pinning in the Pipfile.
thanks kosa, points all make sense, couple I'm not sure how I didn't pick up 😂
I'll wait til it's all in so I can do a bigger commit rather than dribs and drabs
This isn't really the right channel @mental edge, I think you want #303934982764625920
oh, I see!
This channel is for discussion of projects related to this specific community
my apologies and thanks for letting me know!
All good, all good
DeprecationWarning: The object should be created from async function resolver=AsyncResolver(),
DeprecationWarning: The object should be created from async function
family=socket.AF_INET,
This is from __main__.py
So, sort of related... A while back I wrote a Chrome/Vivaldi plugin for Hastebin (what Python-Discord's Code Uploader is powered by). Not sure if anyone wants to use it or maybe modify it to be more specific to this community, but if anyone's interested here's the link:
https://chrome.google.com/webstore/detail/hastebin/jnjbjegfekjhdodgjblogcemdmdajocl
And it's open source:
https://bitbucket.org/GeoDoX/hastebin/src/master/

This extension automatically generates and opens a Hastebin link.
...related to what?
feels off topic for this channel. maybe you meant to put it in #303934982764625920
as for the paste service, we're writing our own version of that already, @patent pivot is more or less done.
yep, working on CI stuff now
Oh nice, will that be under django as well?
No, flask
Separate to pydis site
I hadn't learnt django when I started writing it
open source when 😠 😠 😠
!sooncounter
Aha okay
@hardy gorge Yeah, not a concern with pipenv perhaps. But what I was saying that generally, not pinning the patch version I think means that if pip (?) needed to, it would downgrade/not use the latest discord.py patch version since technically it'd be allowed by the version specification. 🤔
Yeah, that's true, I guess. It will obviously only do that during a re-lock, since everyone should sync --dev from the lock file, but it's something that could happen when we relock for something else.
More generally, though, isn't this the same thing that could happen with any of the things we've pinned to a patch version?
It's true, but the point of the specifier is that the versions should be compatible
Although we've had problems with misbehaving devs before..
I guess the point is that we'd updating the patch version specifically for a bug fix we'd then rely on. If we'd then resolve down again without noticing it, we'd go back to a version that has the bug we used to have a work-around for.
Yes but generally we don't care about patch versions
In this case we'd be directly relying on a fix in that version
@flat marsh
@jade tiger
@dusky bloom
@lapis hull
Hey guys. For your contributions during the Hacktoberfest event, you've been awarded the <@&295488872404484098> role! That means you've been added to the Contributors team in our GitHub organisation and can enjoy some new permissions in some of our repos.
You now have write permissions on bot, branding, site, seasonalbot and flake8-annotations. This doesn't give you the right to commit to the master branch and pull requests still need approval from core developers, but you don't have to work in a fork anymore.
You'll also find you have a colorful new role. Please make sure you read through the Contribution Guidelines, which can be found here: https://github.com/python-discord/meta/blob/master/CONTRIBUTING.md
Thanks a million for contributing to our repos during the event and congratulations.
GitHub
Issue tracker for suggestions and other questions relating to our community - python-discord/meta
Cheers 👌 lots of fun, learnt a lot
Woohoo, thanks! It was really satisfying to be able to contribute in even a real small way to something that's helped me 
Hey, sorry to ask, but could someone review my PR? https://github.com/python-discord/bot/pull/500 I've been waiting 15 days 😉
GitHub
This PR fix #389
Split the token_remover in two functions, one that checks that there is a token in the message (is_token_in_message), and the other takes the actions (deleting the message, etc.)
T...
I've been waiting a long time too, but don't worry, they'll get around to it :>
They have tons to do
Looking at the PR it still looks like they're waiting on some requested changes
You need to make sure you mark those as complete if they are
Ofc! Just saying in case developers are also waiting for me to change things ^^
I forgot to resvolve one requested change
I'm going to update the branch real quick so it's in sync with the master branch, so you might want to pull after I do that. I'll try and find time to look at it soon after
looks like https://github.com/python-discord/bot/issues/636 can be closed
Good spotting it
Everyone is waiting for reviewing 😄 We did not make it easy 😉
you can also review 😛
Been looking on one issue that mentions a proxy user object but I've found 2 functions that create them that differ a bit in behaviour, is that intentional? Feels like they could share single function for creating them
one in moderation/utils https://github.com/python-discord/bot/blob/master/bot/cogs/moderation/utils.py#L33-L48
and the second one in watchchannels/watchchannel https://github.com/python-discord/bot/blob/master/bot/cogs/watchchannels/watchchannel.py#L27-L40
Probably not intentional, no
That's odd
Yeah that's really strange, I'm unsure why you're getting that. Working fine on mine
@nocturne hare Okay, apparently it's an issue wit hpydis.com versus pythondiscord.com
You can log in using the latter, but not the former
Can you make an issue on the site repo?
if I'm copying the behavior of this in a new class
user.avatar_url_as = lambda static_format: None
would this be fine or should I specify the argument like above or the same ones as User.avatar_url_as takes?
@staticmethod
def avatar_url_as(*_, **__) -> None:
return None
Was originally looking for stats.pydis.com is that gone now?
Also made a poorly formatted issue, but at least documented
It's weird to me that some classes inherit from parent classes but don't invoke the super().__init__()
Why?
I don't know. I think it's because I feel like there are some necessary bits that aren't being properly initialized if it isn't called.
I mean I know that's not actually the case but I just kind of associated it as just being part of the process
Oh, I never thought about the domain thing
Yeah whoever has access to the oauth app will need to add another url
but uh
maybe that domain should redirect
because mixing domains will give you two sets of cookies
stats.pythondiscord.com redirects to pydis.com for some reason
Does the webhook no longer post issue comments or is it just slow?
ah okay, there it is
Logistical question
I'm working on the issue where we're going to suggest someone uses the hastebin instead of muting them for huge blocks of code. My question is, does it make more sense to put it in the anti-spam cog itself or in the rule/newlines.py file?
Oh well crap, I just thought of something
I don't know if I can do what I wanted to do
I believe!
It shouldn't go in the rule
I was going to use the codeblock_stripping() method from the bot/cogs/bot.py file but I guess I can't do that if it's in the class and not a class or static method? And yeah, fair point
I'll make it fit in the anti-spam cog
Likely just add an additional check to see if the rule that's being called out is the newlines one and then toss it to a function that handles the check for a codeblock
But now I am kind of trying to work out about the accessibility of the method
If there's no reason they can't be static methods, then you can make them static methods
I'll have to make 3 of them into static methods, but that doesn't seem like it'll cause any particular conflicts from what I'm seeing...
Okay, yeah I think that's what I'll have to do. Thanks, I guess I just get scared to change the hard work that everyone has put into this thing. Need to Hem up and do this
Actually one last question: What would make more sense here, a class method or a static method? Because my hesitation is due to it referencing other methods in the class. I would think in this case a class method makes more sense...
Yeah, class method
Okay, got it
Sorry, just had to work it out
to make sure I don't mess up anything, how do I sync my branch (with a pr open) to the master? The things I need to edit moved so the current conflict can be thrown away
got the git gui but never worked with is so probably command line
git checkout master
git pull
git checkout [branch_name_here]
git merge master
Do I make a commit to throw away the conflict or how does it work there? (Gotta reset my pc so hang on a minute)
I'm not sure. I do most of my git stuff through PyCharm and have been spoiled by it
Have pycharm so could try that too, only used it to commit so far though
In PyCharm, in the top right hand corner you'll have some git icons.
Hold on, making sure I'm going to say all this correctly
Oh okay, forget that. Bottom right of the screen.
You'll have Git: Your Branch Here
If you select that, you'll be able to select the origin/master branch, and then you can select Merge with Current
That'll update your current branch as well as prompt you to resolve any conflicts
oh that's neat
Like I said, I have been spoiled to death by this
Thanks
Happy to help
Guess I'll also look into pycharm git tools too
The most useful thing I found (and I'm not sure if this is in the community version or not), but if you select VCS > Git > View Pull Requests, it makes it stupid easy to compare and checkout current PRs
@brazen charm if you have a conflict git will abort the merge, go in a conflict state and ask you to fix the merge in those file. If you open the file you are going to see something like
<<<<<<< HEAD
lemon = lie
=======
lemon = ai
>>>>>>> lemon-true-origin```You need to delete all those lines and replace it with the most relevant things for you (you can even mix them like `lemon = (lie, ai)`). Then you commit your changes and redo the comment that triggered the conflict.Or you can cheat and use a GUI 😄
git is nice until I have to actually do something and then it's scary because I'm thinking I'll break something 😄
If you break something that's okay, git history is rewritable
yeah but don't do thatl ol
rewriting history on a repository that others use is really unfun
Yeah avoid breaking git as most as possible
but you can solve pretty much everything without rewriting history
If you haven't pushed yet rewriting is okay
at least I can hide in my fork
Well, it will appear on the PR and on the pydis repo after 😄
Rewriting is useful sometime, like it avoid having to download UI-toolkit everytime you clone a repo 🙃 😄
Please don't suggest rewriting git history as a practical solution. It's really really not
I meant.. Only rewrite if you haven't pushed and there is no other way around
If not.. Don't do it
Technically, we suggest using amend in the contribution guidelines, but it rewrite the history
The main point, like you say, is to get your history tidy before you push (or open a PR from a fork).
I use -amend all the time, almost on every PR, but not after I've pushed
Fair enough
Questioning my idea on how to tackle this issue. The methods in the bot.py file are overkill for what is needed for this. I'm trying to figure out a reasonable way to pare it down
what issue?
Oh ah.... one sec, snagging
GitHub
When an user posts a codeblock that takes up a majority of the discord message view, it can become difficult to view the code while also communicating with the helped user which usually results in ...
I wonder if it'd be nice if one of the bots could post issue info if you said eg bot#439 in this channel
It's the one where I'm having it suggest using the hastebin rather than muting the user, yeah
Well the issue is that I'd never remember what the issue number I'm working on is
PyCharm can track it
.issue 439 bot
So my initial idea was to just use the methods from the bot.py file. However those methods are for specifically detecting ill formatted code, not any python code in general

{kind=link}
{kind=link}
{kind=link}
You're good
@green oriole How about detecting if a mention was used to trigger the embed and only if it was invoked for another user and a mention was not used, but an id, it will add a ping outside of the embed?
I was thinking of something like that, I was just searching if you can easily detect if d.py converted it from an ID or a mention. I guess we can just use a string input and handle the rest ourselves?
I think it's easier to just look at the ctx.message.mentions list and see if it's empty or not if a target was used
if user and not ctx.message.mentions
Yeah that make more sense
I feel like I'm on the cusp of an idea
log.trace() is only written when you're in debug mode right?
Don't think it is
I think I don't run my bot in debug mode but I see the trace @mellow hare
trace level is 5, so I think it's above debug
Gotcha gotcha
@hollow lichen what do you mean by it doesn't give a link?
It could give a link to the file named __init__ in the bot repo
These are the built-in levels: https://docs.python.org/3/library/logging.html#levels
TRACE is the lowest level we use, used to trace things through the code
BTW can we make (I don't thing we can but..) a type hint for trace so IDEs stop complaining about trace not being defined?
And for bot.api_client?
Thanks for the clarification, I thought each log level was separated by 1 level
IDEs complaining? Sublime and PyCharm both don't complain for me
I'm not sure that a type hint would help and we don't use type hints outside of function annotations
Sublime doesn't complain for me either, but I don't have a lot of plugins
Hmm PyCharm complain for me
It say something like no member api_client for Bot
Anyway
Should I edit the issue?
Yes, that's fine
So I think I know what's partially throwing me off.
We have a try block that spans just under 100 lines
that is a long try block
And I think it only needs to cover like
1 specific line
https://github.com/python-discord/bot/blob/master/bot/cogs/bot.py#L243 Then alllll the way down to line 341 before we see the except
GitHub
Source code for our Discord bot. Contribute to python-discord/bot development by creating an account on GitHub.
If I'm understanding correctly, it really only needs to be on line 287
Yeah that's wierd. You can try logging which line the SyntaxError occurred and do some testing if you want to make sure only that line should be covered
Yeah might make a note about it but honestly, I'm mainly trying to distract myself from not being sure how to fix this.
The solution I have in mind really only works if their code is formatted correctly, i.e. using the backticks, having py or python to make discord's markup trigger, that stuff
I guess my real question/call for help is, what part of the on_message() listener in the bot.py file tells it to actually consider it valid Python code
This line actually tells if it's python or not: py tree = ast.parse(content[0])
That's what I thought
The try except block isn't responsible to detect if it is valid code?
However I don't think it's the good way to test if the code is python, since any SyntaxError cancel it.
If an exception is raised it mean that it is not python code
So if no exception is raised, it mean it is a pythonic code
So just add an else after the try except?
(and move the if before the try except)
I also don't understand what does DEBUG_MODE has to do with this part of the code.
No idea, it's beyond the scope of what I'm trying to do
My bad, it's always trigged when in debug mode, the not is not for the two conditions.
this block would need to be flatted anyway.
The DEBUG_MODE is messad up, it deactivate some feature, enforce others
We should have a better debug config
Define "messed up", since I don't have issues with it
We're already planning on removing the conditional loading of docs and verification
Like, it disables all filters but enforce the codeblock warning
There isn't any logic in what the debug mode changes
it does not disable filters, it restricts them to one channel
There was a logic to that, but recent changes removed the necessarity for those things
I think we have an issue asking for those to be removed
The reason was that we used to have a special testing channel on this server and wanted to make sure the testing bot did not activate things it shouldn't active
That channel was removed two weeks ago
Yeah only on the filters
About the debug mode, like, it disable some feature, enforce some, restrict others..
I think we could have something more customizable as it isn't very user-friendly (when I started contributing I spend half an hour trying to understand what was going on)
Everything related to the old dev-test channel can be removed, since we don't use a staging bot on this server anymore
@woeful thorn I asked yesterday about whether my changes to the newline spam thing should go in the rules or in the antispam thing itself, and I was wondering if you could explain why it shouldn't be in the rules. Because to me, this is a modification of the rules itself, and this could be most easily handled there
What are you changing?
If there's a "too many newlines" spam detected, but it's Python code, then instead of muting them it tells them to use the hastebin
With how we have the antispam cog, all of those kinds of checks about what kind of rule is being violated is being delegated out to the individual rule files
And that's where it's easiest to control whether a given one should be counted as a rule violation or not
The behavior of sending it to pastebin should not be in the rules, which is what I assumed you were asking about
Hi I have a PR that's pretty fast to review https://github.com/python-discord/bot/pull/619
GitHub
#618 must be merged first.
The moderation modules were a bit bare in the logging. Most of the new logging is trace logging, but there are some debugs and warnings too.
Not sending it there, merely telling them to use it instead
But you're still probably right, as we still want it to go through the deleting process... I think I just under-estimated what all would be needed in it along with what I knew how to do
Hmm, question about log.info, my pylint has been screaming about not using f-string for it
it screams at me for thispy log.info(f"Re-applied {infraction['type']} to user {infraction['user']} upon rejoining.")and want me to do thispy log.info("Re-applied %s to user %s upon rejoining.", infraction['type'], infraction['user'])is there a convention / consensus on this?
I found this SO https://stackoverflow.com/a/34634301 and to quote from it

Stack Overflow
For the following code:
logger.debug('message: {}'.format('test'))
pylint produces the following warning:
logging-format-interpolation (W1202):
Use % formatting in logging functions and p...
Formatting of message arguments is deferred until it cannot be avoided. However, computing the arguments passed to the logging method can also be expensive, and you may want to avoid doing it if the logger will just throw away your event.```Does that mean the latter is better?
@gusty sonnet Basically what it's saying is that if you let the logger do the formatting, then log messages that will be discarded (eg the level is debug bur you just want info and up) will not actually be formatted, saving a little time
I see, so it's like of an internal thing for logging, yes?
Do we have an overall consensus for this however, it's safe to disregard it right?
It's safe, yeah, and if we don't already lint for it then I guess you can just format ahead of time
But I guess it depends how the others feel
We typically prefer the former over the latter, since the increase in readability weighs more strongly than the small increase in efficiency the latter has for us.
I had the exact same question a couple of months ago and that was the consensus back then, anyway
If I commit a suggestion, it is going to trigger a CI build right?
And what if I know committing the suggestion will fail the linting because I'm going to get an unused import?
suggestion as in a review?
Yep
This one to be precise https://github.com/python-discord/site/pull/300#discussion_r342435083
GitHub
Hi, this PR add a new offensive message model needed for python-discord/bot#617.
This PR closes #222.
ah, commiting and pushing for that will trigger it afaik
The problem is that the push is done by github, so I can't remove the import before
Should I apply the suggestion and commit after, or should I make the changes myself?
I'd make the commit yourself.
Then it'll either detect that the proper change has been made and the suggestion will close or you close it yourself. Either way, its solved, and that's what matters
Yes. If you're able to use commit the suggestion using the GitHub-feature you should (to give the author of the suggestion some credit), but if that's not really possible, just make the changes locally.
You should only use a suggestion if you feel it's an acceptable change and won't cause any issues.
At least in my eyes
Just add them as a co-author to your commit
That’s all GH does
You can attribute a commit to more than one author by adding one or more Co-authored-by trailers to the commit's message. Co-authored commits are visible on GitHub.
Oh huh, neat
@hardy gorge
We typically prefer the former over the latter, since the increase in readability weighs more strongly than the small increase in efficiency the latter has for us.
If it helps, we use the C/printf style string formatting for logging within CPython, but for 99% of practical purposes, I think it's fine to use f-strings. Particularly in cases where it affects the readability.
I feel like I just have a mental block for the C style
The % stuff always just kind of messed with me
I don't like it either
I think they should just conditionally allow print to have any letter prefixed or suffixed.
tprintx? why not.
haha
how about some kprinty
pprintt
iprintd
did you now.