#esoteric-python
1 messages · Page 80 of 1
The Function supplied it
@formal sandal Make it work with yields.
Also where did you get z
Also, r.assign should use kwargs
That's really interesting
Keep it up
If you get it to work with yield, you should use this for async lambdas
def nsync(f):
@functools.wraps(f)
async def wrapper(*args, **kwargs):
call = f(*args, **kwargs)
i = next(call)
try:
while True:
i = call.send(await i)
except StopIteration as e:
if len(e.args) > 0:
return e.args[0]
else:
return
return wrapper```Ok
If you want @formal sandal , I can DM you a link to my source so that you can build on it or improve it
Or add some of it to yours
I think it would be more interesting if I do it on my own :)
wat
do [] work?
Not yet, I'm going to add these now
this looks a bit nicer as well
Yep, works as intended
cool
Sadly, I can't really use , as input :(
Or maybe I can
wait
Yeppp
Totally works
what's the shortest way to do an 8bit wrapping thing for brainfuck? (eg: if it's -1 then change it to 255, if it's 256 change it to 0, else keep it the same)
[[n,0],[255]][n<0][n>255]```I think this would work but it's kinda dumb
wait I just realised
>>> n = -1
>>> n%256
255
>>> n=256
>>> n%256
0
wow
_try = lambda try_clause, except_clause, catch=Exception: type("nested", (), {"__init__": lambda self, *ctx: [setattr(self, "ctx", ctx), None][1],"__enter__": lambda self, *ctx: [[ctx.__enter__() for ctx in ctx], None][-1],"__exit__": lambda self, *args: [[ctx.__exit__(*args) for ctx in self.ctx], None][1]})(type('Handler', (), {'__enter__': lambda self: None,'__exit__': lambda self, et, ev, tb: et is not None and issubclass(et, catch) and (except_clause(ev), True)[1]})(),type('Body', (), {'__enter__': lambda self: None,'__exit__': lambda self, et, ev, tb: try_clause()})())
this is suppost to catch errors by abusing context protocal but its not catching anything when i do, I get no error in the console either
_try(lambda: (_ for _ in []).throw(Exception), lambda e: print(e)).__enter__()
Pls ping me if you can help or have suggestions
is there a way to uhm, fetch the function object from FrameInfo? (in inspect.stack())
FrameInfo should have the name of the function
and then you can use that with either f_locals or f_globals to get it
might be a little more difficult for modules and stuff
!e
import inspect
a = lambda: inspect.stack()
res = a()[0]
print(type(lambda: None)(res.frame.f_code, res.frame.f_globals, res.function))
@lament ibex :white_check_mark: Your eval job has completed with return code 0.
<function <lambda> at 0x7fcb12a7b4c0>
lol idk seems to work for lambdas
that wouldnt be the same object
ah true
so, are f_locals a copy of function's locals
? I wonder if I can modify function's namespaces outside of it
f_locals is what locals returns. not a copy.
you can modify this dict however it might not always work as excepted, because the compiler cant always discern your intentions and produce the correct instructions
you can add a new name to f_locals, provided it's not already in the local scope.
but there wont be much point as you cant access it, since the generated instructions will try to look for the name in the global scope.
if the name is already in the local scope then trying to change the value associated with that name in f_locals wont do anything.
!e
g = (locals()['.0'] for x in [2, 3, 5])
for i in g:
print(i)
@formal sandal :white_check_mark: Your eval job has completed with return code 0.
001 | <tuple_iterator object at 0x7fb3933cc280>
002 | <tuple_iterator object at 0x7fb3933cc280>
003 | <tuple_iterator object at 0x7fb3933cc280>
@sick hound this might be the wrong channel for that. Try an offtopic one.
@sick hound you only run the body function when _try(...).__exit__ is called. If you want to use it as a context manager in a with block, it can't catch errors in its own __exit__.
@sick hound I have written something similar, there is a class called ContextDecorator that concerts a context manager into a decorator and allows that to work
@gilded orchid there's always n & 255
Hey everyone
why would this fail?
def f():
locals().update(x=10)
return x
f()```yeah, got it
isn't it because locals().update doesn't work in functions
I don't actually know why it doesn't work
more specifically, locals().update doesn’t work with functions
Locals are immutable in functions, I thought.
I just remember someone making a super janky work around for a lambda I made a while ago
At function scope (including for generators and coroutines), [this function] returns a dynamic snapshot of the function's local variables and any nonlocal cell references. In this case, changes made via the snapshot are not written back to the corresponding local variables or nonlocal cell references, and any such changes to the snapshot will be overwritten if the snapshot is subsequently refreshed (e.g. by another call to locals()).
!pep 558
**PEP 558 - Defined semantics for locals()**
Status
Draft
Python-Version
3.9
Created
2017-09-08
Type
Standards Track
^ here
@gilded orchid I would like to have a look if I can, haha. Please don’t tell me you used ctypes, though.
nah I didn't make it
lol alright
a=lambda x:(locals().update({'hello':'test'}),print(locals()['hello']))```
I think this was ityeah that’s bad
alright
!eval
a = {}
import('ctypes').py_object.from_address(id(a)).value = {'a': 1}
print(a)
@marsh void :white_check_mark: Your eval job has completed with return code 0.
{}
oh I forgot how to do this lol
Is forbiddenfruit on the snekbox?
I'm working on something called lambdatools, which is pretty ecoteric.
Nekit is helping me out with some of it.
Here's an example for some of you folks
import asyncio
async def coro(x):
print(x)
coro2 = nsync(function('x', lambda v: ( #create an async lambda with a parameter x
(yield coro(v.x)), #await coro(x)
result(v.x ** 2) #return x ** 2
)))
out = asyncio.run(coro2(5))```That's an async lambda coroutine.
factorial = function('x', lambda v: (
when(lambda v: v.x == 1, lambda v: (
result(1)
)),
result(v.x * v.__ref__(v.x - 1))
))```This is a lambda which references itself
So yeah
@snow beacon yes
@marsh void the reason that fails is this:
https://discordapp.com/channels/267624335836053506/470884583684964352/660115958958129163
if you disassemble the function, the instruction for accessing x is LOAD_GLOBAL, as that's what the compiler thinks youre trying to do.
locals().update works in that particular case
eval('x', locals())
:p
there really isn't much of a way to make it work aside from patching bytecode
you just have to change that instruction to LOAD_NAME or LOAD_FAST
I thought you can insert that stuff
I mean
nevermind

!eval
def f():
exec('x = 10', locals())
return x
f()
@marsh void :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 4, in <module>
003 | File "<string>", line 3, in f
004 | NameError: name 'x' is not defined
yikes
!e
def f():
exec('x = 10', globals())
return x
f()
@hollow patrol :warning: Your eval job has completed with return code 0.
[No output]
@marsh void Like that maybe?
@brazen geyser :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 16, in <module>
003 | TypeError: an integer is required (got type bytes)
this works in 3.7 but not in 3.8
not sure why. the error doesn't help much either.
line 16 is new_code_object = CodeType(
ah, there's a new param. posonlyargcount.
!e
from dis import opmap
from types import CodeType
def f():
locals()['x'] = 10
return x
old_code_object = f.__code__
bytecode = bytearray(old_code_object.co_code)
bytecode[10] = opmap['LOAD_FAST']
bytecode[11] = 0
new_code_object = CodeType(
old_code_object.co_argcount,
old_code_object.co_posonlyargcount,
old_code_object.co_kwonlyargcount,
old_code_object.co_nlocals,
old_code_object.co_stacksize,
old_code_object.co_flags,
bytes(bytecode),
old_code_object.co_consts,
old_code_object.co_names,
('x',),
old_code_object.co_filename,
old_code_object.co_name,
old_code_object.co_firstlineno,
old_code_object.co_lnotab,
old_code_object.co_freevars,
old_code_object.co_cellvars,
)
f.__code__ = new_code_object
print(f())
@brazen geyser :white_check_mark: Your eval job has completed with return code 0.
10
leave this here, from python-discussion:
In [78]: class Direction:
...: North = East = South = West = e
In [79]: Direction.North
Out[79]: 0
In [80]: Direction.East
Out[80]: 1
In [81]: Direction.South
Out[81]: 2
@brazen geyser is there a way to do this outside of a class
not that im aware of
btw i thought a bit more about your eint implementation with individual descriptor instances
can definitely see some use cases
e.g. enums where you dont want their value ranges to overlap
i thought of a use for it currently, it's not necessary, but i want to give it a go anyway
it's for the code-jam qualifier, but i can use more general desciptions:
class Token:
def __init__(self, parse_this):
self.parse_this = iter(parse_this)
def __set_name__(self, owner, name):
setattr(owner, name, next(self.parse_this))
it's odd, but i can just keep setting some attribute = token to get the next item
seems unnecessary but also real simple once it's set up
i assume i'll need some try/except block for StopIteration
doesn't seem to work inside class methods
oh huh
thats pretty interesting
you get access to the descriptor object directly
nothing happens if you assign it from anywhere outside the class definition body it seems
think that might be a bug actually
or oversight
>>> class D:
def __set_name__(self, owner, name):
print(owner, name)
def __get__(self, instance, owner):
return 22
def __set__(self, instance, value):
print(value)
>>> class Test:
pass
>>> Test.d = D()
>>> test = Test()
>>> test.d
22
>>> test.d = 324
324
>>>
so __get__ and __set__ still work as expected. it's just __set_name__ that gets left behind.
ah there's a blurb about this in the docs
https://docs.python.org/3/reference/datamodel.html#object.__set_name__
Note __set_name__() is only called implicitly as part of the type constructor, so it will need to be called explicitly with the appropriate parameters when a descriptor is added to a class after initial creation:
class A:
pass
descr = custom_descriptor()
A.attr = descr
descr.__set_name__(A, 'attr')
not sure why it's this way
seems like it'd be trivial to update class objects' default setattr behaviour to handle this.
but i suppose it wouldnt be worth the overhead
it's a lot to keep track of for me, i might mess with it more later
>>> class Descriptor:
def __set_name__(self, owner, name):
print(owner, name)
>>> class AutoSetName(type):
def __setattr__(cls, name, value):
super().__setattr__(name, value)
try:
value.__set_name__
except AttributeError:
pass
else:
value.__set_name__(cls, name)
>>> class Test(metaclass=AutoSetName):
pass
>>> Test.descriptor = Descriptor()
<class '__main__.Test'> descriptor
>>>
metaclasses to the rescue
name checks out
!e
try:
exit()
except:
print(13)
@marsh void :white_check_mark: Your eval job has completed with return code 0.
13
@marsh void :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 3, in <module>
003 | TypeError: exceptions must derive from BaseException
eh
@thin trout does this count?
def lemon():
try:
return 'AI'
except:
return 'Too sour!'
co_consts = list(lemon.__code__.co_consts)
co_consts[1] = 'way too sour!'
new_lemon = types.CodeType(lemon.__code__.co_argcount,
lemon.__code__.co_kwonlyargcount,
lemon.__code__.co_nlocals,
lemon.__code__.co_stacksize,
lemon.__code__.co_flags,
lemon.__code__.co_code,
tuple(co_consts),
lemon.__code__.co_names,
lemon.__code__.co_varnames,
lemon.__code__.co_filename,
lemon.__code__.co_name,
lemon.__code__.co_firstlineno,
lemon.__code__.co_lnotab,
lemon.__code__.co_freevars,
lemon.__code__.co_cellvars)
lemon.__code__ = new_lemon
lemon()
Out[68]: 'way too sour!'
return doesnt call any functions right?
Call a function? 
yeah like something called __on_return__ haha
But how would you return from __on_return__ if everytime you return it call __on_return__?
return gets its own special instruction
https://docs.python.org/3/library/dis.html#opcode-RETURN_VALUE
though if you were to interpret return doesnt call any functions right? flexibly,
return could result in a function call if a trace function is set via sys.settrace
Yeah I would need return something to call a function on something, so that function can raise a error
You could process the bytecode to change all the returns
The first gif doesn't load :(
You can click on it and the press "open original"
I have no Idea how to unattach the gif...
got it
Doesn't load for me either in discord, but as a standalone file it works
Also, does this syntax make sense?
Yeah.
Because if you have a multidimensional array, you will have this with []:
array[0][1][2][3]
But:
array:0:1:2:3
Pretty cool!
The console module I wrote is itself code gore...
Its maximum indentation level is 7
code gore ain't cool heh
true
I will try to refactor that spaghetti diarrhea now...
After finishing the greeting ASCII art, of course.
On-the-fly autocompletion!
If you just press tab, the console will print you all the possible names that start with the given substring.
Then you can type more letters, and it will dynamically adjust the list
I probably have to add a space before the list to make it work for terminals or humans that don't support color.
This is also a good feature. It will only display functions if you auto-complete in a function call.
How do brackets work? Do they do something to the stack?
Yep.
I will post a tutorial soon.
But the language works: https://github.com/decorator-factory/stekk
Brackets denote a 'stack expression'.
So if you write (1 2 3 4 5), numbers 1, 2, 3, 4, 5 will be pushed onto the stack.
.func denotes a function call. It can be either a standalone expression or a command inside a stack expression.
So these are equivalent:
("hello " .print "world!" .println)
("world!" "hello " .print .println)
When the stack expression 'ends', the top element is popped from the stack to become the result of a stack expression.
If you mean [] not (), that's just a list.
@formal sandal if you want to make the autocompletion more human friendly, put it on the line below input and put the diff possibilities between [], ex [ opt1 opt2 opt3 ]
That way it’s clear on terminals without color and shitty spacing
^ I second this
IDK if this is the right place for this, but it's metaprogramming and I'm not sure where else this would go. I'm consuming some API's using Quicktype.io to generate dict to object classes and want to generate str and repl functions for these classes dynamically. (Full class code here https://app.quicktype.io?share=OhSj0FUBrFsWJ7P94BoD)
I've written a function that will eventually be a metaclass or class decorator, that returns source code for each class based on inspection, but I can't figure out how to bind the string source code to an actual function.
def str_wrap(cls):
params = list(inspect.signature(cls).parameters.keys())
new_params = []
for param in params:
param = 'self.' + param
new_params.append(param)
values = ', '.join(new_params)
new_str = "{}({})".format(cls.__name__, values)
cls.__str__ = new_str
Instrument.__str__
'Instrument(self.asset_type, self.cusip, self.description, self.symbol)'
But the method isn't actually callable.
cls.__str__ = classmethod(new_str) doesn't seem to do the trick either.
Did you try py setattr(cls, '__str__', new_str)
Isn't new_str just a string?
Looks like it
I think something like this will work, if it is really this simple ```py
def str(self):
return "abc"
cls.str = str
new_str = lambda cls: "{}({})".format(cls.__name__, values)
cls.__str__ = new_str```perhaps?Hmm it might raise error for values in that case, will need to test
But the idea is that it should be a callable
Yea, I was watching pycon vid from Cookbook author that showed how to do that, I may have to go rewatch
was using metaclasses but I don't recal how he got the eval() calls in there.
I promise a blog post once I get it figured out.
Best I can get is <bound method ? of <class 'cls'>
def str_wrap(cls):
params = list(inspect.signature(cls).parameters.keys())
new_params = []
for param in params:
param = 'self.' + param
new_params.append(param)
values = ', '.join(new_params)
new_str = "{}({})".format(cls.__name__, values)
setattr(cls, '__str__', classmethod(new_str))
str_wrap(Position)
Position.__str__
That's not how classmethod is used
It's typically used as a decorator, and it needs an existing function given to it
I don't believe it's needed here regardless
See above examples for how to do this
Here
import inspect
def str_wrap(cls):
params = list(inspect.signature(cls).parameters.keys())
new_params = [f"self.{param}" for param in params]
values = ', '.join(new_params)
__str__ = lambda self: "{}({})".format(cls.__name__, values)
cls.__str__ = __str__
class A:
def __str__(self):
return 'No.'
a = A()
print('Before:', a)
str_wrap(A)
a = A()
print('After:', a)```@crystal mica :white_check_mark: Your eval job has completed with return code 0.
001 | Before: No.
002 | After: A()
Same idea Mark had, it has to be a callable, accepts a self, and returns a string
Thanks. I need to make a test for this. I'm still getting 'str' object not callable, but out of time for tonight.
I want to make this a class decorator or metaclass at some point, but it's more of an intellectual exercise for now.
Hi everyone, I made a tutorial on basics and conditionals in stekk (my stack-oriented toylang), maybe you could take a look? (if I haven't annoyed you to death yet, of course!)
https://github.com/decorator-factory/stekk // tutorial folder
It's very cool. I didn't realise there was such a balance of nested expressions and statements that use the stack. I'm excited to see how the code block idea develops further.
Wait till you see the actual code that does something! It looks absolutely horrible.
get := {
__get_result := $N;
(
.swap
.--
{(
()#0 (.dup)#$lvalue#$name (.over)#$expr
.rot .drop .swap .rot .over .over .=
.if () {
.rot;
__get_result := ();
} else {
(.rot .swap .drop);
})
}
.foreach
);
__get_result
};
This is a function that allows you to use code blocks as associative arrays... kinda.
@formal sandal btw instead of with open, parser = Lark() thingy you can just use Lark.open
with rel_to=__file__
oh
I will probably rewrite/refactor most of the thing some day because some places are just spaghetti monsters.
So that atrocity allows you to do this:
It's challenging to make even basic functions because there are no 'local variables'
So if anyone decides to name their variable __get_result, they are screwed the second they use get.
Maybe I can do some giant brain trick to get rid of that variable, but that will be even worse than .rot .drop .swap .rot .over .over
The program looks like a transcript of some rap song
just make __name reserved
What do you mean?
to much walrus
in python, if someone were to name their variable __import__ and such, they would be screwed. It is pretty common to make __name reserved for internal usage in languages
Well, here __get_result is not an internal variable.
Hm... I have an idea.
If we ignore get (or find a trick to remove __get_result), then maybe I can make modules using dicts!
Oh, I really liked usage of return annotations to represent the stack
I guess you can write a simple analyzer to verify them
Oh, was it like Forth convention?
Yes
For side effect functions, that is a good idea to represent changes in return annotation if you can
Use ! in the name, perhaps.
Well... I don't think there's any function in stekk that doesn't have a side effect :)
Other than doing things to the stack
Have you thought of allowing string indexing on code blocks?
Hm...
Maybe that makes some sense, but that's just a code block
Maybe I can allow overloading arbitrary operations on built-in obejcts...
What operations would there be to overload?
maybe __getitem__?
Like
(get {} "getitem" [""] .overload);
Since I don't have classes or type variables, I can just supply instances of those types...
You could have a function to alter a method on the top of stack, and the you could combine several calls into e.g. a dict function.
Or maybe
subclass := {
__getitem__ := {"scary code here"};
__push__ := {
;; (dict [k, v] .push)
(.bloat .swap .~assignment .swap .drop .++);
};
}
({} .typeof subclass .embellish $N);
I don't really understand what you're overwriting.
I have a function push that appends an element to a list.
Then I might want to overwrite it to work with dicts.
Like (my_dict ["key", "value"] .push $N);
What's the {} .typeof subclass .embellish?
Well, that's a sequence of imaginary functions...
First, I get the type of a code block.
Then I give it additional behaviour defined in subclass which is a dict, i.e. codeblock defined earlier.
That affects every codeblock?
Yep. That would affect every codeblock.
But it will be probably a pain in the ass to implement
Another cool thing would be to convert a stack diagram into a function.
LIke
([$a, $b, $c], [$a, $b, $c, $b, $a] .sdf)
Using python, it's easy
But I want to define it in stekk!
Maybe you can do this:
(3, [0, 1, 2, 1, 0] .sdf)
Then collect top 3 elements and place them according to the list.
You could allow codeblocks instead of numbers, such as {1; 0; (.+)}, where it would take the second and first and add them.
The semicolon separated ordinals are pushed before.sdf runs the rest.
What a meant was a function that does this:
(1 2 3 .f) -> (1 2 3 2 1)
So that you don't have to die trying to find another combination of drop, dup, swap, rot and over.
Oh, so not for defining whole functions, just for moving values around.
Happy esoteric new year everyone.
hello guys...
how can you make a simple "guess my string" script, obfuscating the password so that someone in a programming course would not be able to read the code and figure it out?
some of the things that goes on here I cannot even follow, so maybe anyone can take the challenge for me?
or just give me a hint on howto so i can help out a guy in the help channel
just obfuscate not encrypt?
if so you can just use importlib with custom loader
interesting idea.. sounds very overengineered. why would that work?
you could just use a hash of the string and compute the hash of the input string
and in your main script decode the file and import it
and compare
yeah hash compare will work, but i do love the importlib idea..
want to write it for me @green nymph? while i do the more sensible idea of using a hash?
http://nuitka.net/pages/overview.html
https://github.com/nuitka/nuitka
I haven't tried it myself but I heard good things.
Nuitka Home
The TL;DR ...
Nuitka is a Python compiler written in Python.
It's fully compatible with Python 2.6, 2.7, 3.3, 3.4, 3.5, 3.6, and 3.7.
You feed it your Python app, it does a lot of clever things, and s

GitHub
Nuitka is a Python compiler written in Python. It's fully compatible with Python 2.6, 2.7, 3.3, 3.4, 3.5, 3.6, and 3.7. You feed it your Python app, it does a lot of clever things, and sp...
Isn't exactly the question you asked for but in the help he was asking about turning it into an exe.
@tropic night can try, why not
as the one who asked the question, Im as confused as I was when I was born
Nuitka doesnt seem to support python 3.8
also, what do you guys mean by "hash the string"
I've got this thing that converts strings to bits in zero with form... so you could obfuscate the string from the user and compare it to one obfuscated by you before as an example
you could use something like pyarmor to obfuscate the code
https://github.com/dashingsoft/pyarmor
a hashing function is a byte sequence -> number mapping, that assigns a unique number to each sequence, but the inverse function does not exist
naturally, this is impossible, but some algorithms get close enough
use a 1d reversible cellular automata on the byte string
that's some fun obfuscation
maybe use hashlib instead of hash() to make sure it's unique
^, the default python hash() is not a robust hashing function IIRC
you could just write a C extension that does a pretty simple encryption and compile it without giving anyone the source. I certainly would not look through x86 ASM to guess some random password.
@tropic night
from base64 import b64decode
from pathlib import Path
from importlib.util import spec_from_loader, module_from_spec
from importlib.machinery import SourceFileLoader
class MyLoader(SourceFileLoader):
def get_data(self, path: str) -> str:
data = super().get_data(path)
return b64decode(data)
if __name__ == '__main__':
spec = spec_from_loader(
"secret", MyLoader("secret", str(Path('.') / 'secret.py'))
)
secret_module = module_from_spec(spec)
spec.loader.exec_module(secret_module)
secret_module.foo()
and then put some base64 encoded python code to your secret.py
just to simplify without any code imports you can do that
from base64 import b64decode, b64encode
from pathlib import Path
from importlib.util import spec_from_loader, module_from_spec
from importlib.machinery import SourceFileLoader
my_code = b64encode(
'def foo():\n print("Hello World!")'.encode('utf-8')
)
class MyLoader(SourceFileLoader):
def get_data(self, path: str) -> str:
return b64decode(my_code)
if __name__ == '__main__':
spec = spec_from_loader(
"secret", MyLoader("secret", str(Path('.') / 'secret.py'))
)
secret_module = module_from_spec(spec)
spec.loader.exec_module(secret_module)
secret_module.foo()
cool thanks @green nymph I have to look at it a bit later 😄
I wrote this obfuscator for one of the challenges. https://raw.githubusercontent.com/python-discord/esoteric-python-challenges/dae2aacfc3d96071f7708352d9c9d661e0a4df98/challenges/10-code-obfuscator/solutions/IFcoltransG.py
It's designed for code, but works with anything, really. The weird bit is that it includes the encoder in the decoder.
Incidentally, there's a bunch of unmerged pull requests on the challenges GitHub that have been there a while.
here's encryption with reversible automata:
import cellpylib as cpl
import numpy as np
def text_to_bits(text, encoding='ascii', errors='surrogatepass'):
bits = bin(int.from_bytes(text.encode(encoding, errors), 'big'))[2:]
return bits.zfill(8 * ((len(bits) + 7) // 8))
def text_from_bits(bits, encoding='ascii', errors='surrogatepass'):
n = int(bits, 2)
return n.to_bytes((n.bit_length() + 7) // 8, 'big').decode(encoding, errors) or '\0'
my_string = 'hi there'
print('initial string is: ', my_string)
my_string_binary_array = np.array(list(text_to_bits(my_string)), dtype=int)
cellular_automaton = my_string_binary_array # String is initial state
r = cpl.ReversibleRule(cellular_automaton, 90)
cellular_automaton = cpl.evolve(cellular_automaton[None,:], timesteps=100, apply_rule=r.apply_rule)
print('encoded string: ', ''.join(cellular_automaton[-1].astype(str)))
r._previous_state = cellular_automaton[-1] # Rewind automata by setting last state to previous state
backwards = cpl.evolve(cellular_automaton[-2][None,:], timesteps=100, apply_rule=r.apply_rule)
print('decoded string: ', text_from_bits(''.join(backwards[-1].astype(str)))) # Sanity Check
a key based jumbler using only stdlib (hashlib, base64 and random)
can be used to jumble any type of sequence
if __name__ == '__main__':
password = input('enter password:').encode()
result = jumble_b64(b'hello there', password)
print(result)
print(unjumble_b64(result, password))
# enter password:lol
# b'V8dsG=amGgblchUG'
# b'hello there'
I just found this ludicrous sudoku brute forcer from http://blog.cyphase.com/2012/12/07/playing-sudoku-beach/
def f(s):
x=s.find('0')
if x<0:print s;exit()
[c in[(x-y)%18*(x/18^y/18)*(x/54^y/54|x%18/6^y%18/6)or s[y]for y in range(162)]or f(s[:x]+c+s[x+1:])for c in'%d'%5**18]
import os;f(os.read(0,162))
i feel like this represents #esoteric-python pretty well
wow
lambda:(globals().update(__import__('lambdatools').__dict__),gcd:=function('*args',lambda v:(when(lambda v:len(v.args)==2,lambda v:(v.set(a=v.args[0],b=v.args[1]),when(lambda v:v.b==0,lambda v:(result(v.a))),result(v.__ref__(v.b,v.a%v.b)))),otherwise(lambda v:len(v.args)>2,lambda v:(v.set(newGCD=None),foreach('item',v.args,lambda v:(when(lambda v:v.newGCD==None,lambda v:(v.set(newGCD=v.item))),otherwise(lambda v:(v.set(newGCD=gcd(v.newGCD,v.item)))))))),result(v.newGCD))))```That is a 1-lined gcd function using lambdatools
lambda: (
globals().update(__import__('lambdatools').__dict__),
gcd := function('*args', lambda v: (
when(lambda v: len(v.args) == 2, lambda v: (
v.set(a = v.args[0], b = v.args[1]),
when(lambda v: v.b == 0, lambda v: (
result(v.a)
)),
result(v.__ref__(v.b, v.a % v.b))
)),
otherwise(lambda v: len(v.args) > 2, lambda v: (
v.set(newGCD = None),
foreach('item', v.args, lambda v: (
when(lambda v: v.newGCD == None, lambda v: (
v.set(newGCD = v.item)
)), otherwise(lambda v: (
v.set(newGCD = gcd(v.newGCD, v.item))
))
))
)),
result(v.newGCD)
))
)```(lambda f:f(f))(lambda f:lambda a,b:f(f)(b,a%b)if b else a)```That is a 1-lined gcd function that doesn't use lambdatools
8 0 LOAD_CONST 2 (7)
2 STORE_FAST 2 (mixin_remapped_p_44bef18e7a234b7e)
4 LOAD_GLOBAL 0 (print)
6 LOAD_CONST 3 ('p:')
8 LOAD_FAST 2 (mixin_remapped_p_44bef18e7a234b7e)
9 10 CALL_FUNCTION 2
``` output: `p: <built-in function print>`
how do I keep doing this shitI should probably just refactor everything shouldnt I
because I also need to make function parameters immutable
what be this @grave rover
pymixin
whats going on in that snippet
python version of https://github.com/SpongePowered/Mixin/wiki

GitHub
Mixin is a trait/mixin and bytecode weaving framework for Java using ASM - SpongePowered/Mixin
well
it stores 7 in the mixin_remapped_p variable
but somehow according to the debugger print is stored there

if I change p to anything else it somehow changes to print p: twice
@brazen geyser here's what I did
oh no
Hey @grave rover!
It looks like you tried to attach a file type that we do not allow. We currently allow the following file types: .3gp, .3g2, .avi, .bmp, .gif, .h264, .jpg, .jpeg, .m4v, .mkv, .mov, .mp4, .mpeg, .mpg, .png, .tiff, .wmv, .svg, .psd, .ai, .aep, .xcf, .mp3, .wav, .ogg.
Feel free to ask in #community-meta if you think this is a mistake.
disabling the referrer header breaks the strangest things
@grave rover
p: p: 7
off topic, here's a fun one
!e ```py
def a():
try:
return True
except:
raise
finally:
return False
print(a())
@distant wave :white_check_mark: Your eval job has completed with return code 0.
False
!e
def f():
try:
return True
finally:
return False
print(f())
@marsh void :white_check_mark: Your eval job has completed with return code 0.
False
@distant wave I mean, that is expected isn’t it
On one hand, yeah, the behavior is logical
On the other hand, it can really make intersting and unexpected bugs
try-finally works like this:
try:
return 1
finally:
return 2
``` ```
SETUP_FINALLY
LOAD_CONST 1
CALL_FINALLY
RETURN_VALUE
POP_TOP
LOAD_CONST 2
RETURN_VALUE
END_FINALLY
that's weird
mart are you ok
yeah
Can anyone help me understand why python's logging module creates a StreamHandler on import, but only on some distributions? weird.. (note: happens on any python3)
On Mac
Python 3.5.6 (default, Dec 19 2019, 14:59:39)
[GCC 4.2.1 Compatible Apple LLVM 11.0.0 (clang-1100.0.33.8)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import logging
>>> logging.getLogger().handlers
[<logging.StreamHandler object at 0x108fc2630>]
Linux:
Python 3.7.4 (default, Jan 3 2020, 19:27:19)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import logging
>>> logging.getLogger().handlers
[]
>>>
I can't seem to find any explanation about this.
The streamhandler is initialized whenever logging's default configuration is initialized, which happens if it's called directly or something attempts to log something at any loglevel
It's possible something run during repl startup is sending a debug log message, which then initializes the handler
It could be caused by a hashlib import, with the warning message caused by an OSX-specific openssl support difference occurring and being silenced behind the scenes.
hmm that's a good idea, thanks!
@sick hound Your function doesn't work with *args.
But it still works, so, I guess that's pretty cool
lmao ```py
numpy.array(["a", "b", "c"], dtype=object).dot([1, 2, 3])
'abbccc'```
@thin trout I'm very late but you can raise in lambdas: (0for[]in[]).throw(ImportError('nope!'))
for key, value in self.settings["credentials"].items():
self._setattr_(key, value)
I dare someone to turn this into a one liner
self.__dict__.update(self.settings['credentials'])
why do you think that
oh it does
why would it not
🤨
Lol
any(setattr(self, k, v) for k,v in self.settings['credentials'].items())
every for loop with its body in one line is trivial to turn into a oneliner
Hmm
Is this esoteric
lambda n: reduce( (lambda r,x: r-set(range(x**2,n,x)) if (x in r) else r), range(2,int(n**0.5)), set(range(2,n)))
:incoming_envelope: :ok_hand: applied mute to @sick hound until 2020-01-06 05:24 (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
wew
I have to ask what it does, so it's esoteric. Does it find primes?
!e
from functools import *; f = lambda n: reduce( (lambda r,x: r-set(range(x**2,n,x)) if (x in r) else r), range(2,int(n**0.5)), set(range(2,n))); print(f(100))
@marsh void :white_check_mark: Your eval job has completed with return code 0.
{2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97}
Looks like prime numbers
yeah
!e from functools import *; f = lambda n: reduce((lambda r,x: r-set(range(x**2,n,x)) if (x in r) else r), range(2,int(n**0.5)), set(range(2,n))); p=lambda n:[x for x in range(2,n+1)if all(x%y for y in range(2,int(x**.5)+1))]; from timeit import timeit; t = lambda s: timeit(s, globals=globals(), number=1000); print(t('f(100)')); print(t('p(100)'))
@marsh void :white_check_mark: Your eval job has completed with return code 0.
001 | 0.018206743523478508
002 | 0.14901408832520247
Let me.. just..
from functools import *
f = lambda n: reduce((lambda r,x: r-set(range(x**2,n,x)) if (x in r) else r), range(2,int(n**0.5)), set(range(2,n)))
p=lambda n:[x for x in range(2,n+1)if all(x%y for y in range(2,int(x**.5)+1))]
from timeit import timeit
t = lambda s: timeit(s, globals=globals(), number=1000)
print(t('f(100)'))
print(t('p(100)'))```okay now I can read it 😛
Well, more or less
!e ```py
from collections import defaultdict
configuration = defaultdict(dict)
configuration["test"] = [["test-2", "test", "test-3"], ["test"]]
for instance_set in configuration.values():
for instance in instance_set:
for element in instance:
if not element in configuration[element]:
print(1)
@distant wave :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 5, in <module>
003 | RuntimeError: dictionary changed size during iteration
004 | 1
005 | 1
006 | 1
007 | 1
F
Collatz conjecture in stekk! The run function will return the Collatz chain for a given N.
even := { (.dup 2 ./i 2 .* .=) };
next := {
if (.dup .even)
(2 ./i)
else
(3 .* 1 .+)
};
run := {
if (.dup 1 .=)
[()]
else
([(.dup)] .swap .next .run .++)
};
If anyone hasn't heard of it, the conjecture is that if
f(even k) = k/2
f(odd k) = 3k+1
Then for any natural number N it is true that if you apply the f to N, then to its result and so on, you will inevitably end up at 1.
For anyone interested, I added dict and importing:
https://github.com/decorator-factory/stekk/commit/526139769154538c0011b6c99c2b74ef37584473
so could anyone please explain to me in English what's going on here
!e
for [] in [()]*2:
print(42)
@tropic night :white_check_mark: Your eval job has completed with return code 0.
001 | 42
002 | 42
found this image online.. its from a few days ago
yeah.. i get the tuple.. but what is it doing
is it unpacking empty tuples in a list?
unpacked into nothing
like.. i can run it and see why its working, but why is it working...
!e ```py
[] = [()]*2
@whole kiln :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | ValueError: too many values to unpack (expected 0)
like just change the sequence to something else..
and whats going on with the element part...
does it need something that is falsy like empty elements to work?
since you are asking it to unpack 0 values
and why does it expect 0 values in the first place
for () ... -> works
for '' ... -> does not
when i think i have figured it out, i realize i do not
My example was wrong
this
it is unpacking
you give it an empty sequence to unpack for every iteration
then it's just the unpacking syntax
!e
[] = ()
@proper vault :warning: Your eval job has completed with return code 0.
[No output]
so its just unpacking and the [] is just to make it syntactical confusing?
well, the [] is essentially unpack 0 elements.
it = iter([()]*2)
while True:
try:
[] = next(it) # [] = ()
except StopIteration:
break
else:
print(42)
roughly equivalent
np
(lambda kivy_:kivy_.lang.Builder.load_string('<Widget>:\n\tcanvas:\n\t\tTriangle:\n\t\t\tpoints:0,0,self.width/2,self.top,self.right,0')or type("MainApp",(kivy_.app.App,),{"build":lambda s:kivy_.uix.widget.Widget()})().run())(__import__('kivy', fromlist=['lang','app','uix']))
any easier way to do this
@sick hound wdym
import ctypes as ct
class StructureMeta(type(ct.Structure)):
def __new__(mcs, name, bases, namespace):
cls = super().__new__(mcs, name, bases, namespace)
fields = dict()
for base in reversed(cls.mro()):
try:
fields.update(base.__annotations__)
except AttributeError:
pass
cls._fields_ = list(fields.items())
return cls
class Structure(ct.Structure, metaclass=StructureMeta):
pass
an alternative ctypes.Structure that uses type annotations to populate its fields, so you get proper autocompletion. also it will inherit fields from its parents.
e.g.
class ExampleStruct(Structure):
member_1: ct.c_int
member_2: ct.c_char
cool!
i implemented that a long time ago in my cpystructs code and then used it to make the various object structs used in cpython. i should get back to trying that.
although your implementation looks simpler (and therefore better) than mine. mind if i steal borrow it at some point? :D
permenent borrowing
Theft, liberation, what's the difference? A rose by any other name would smell as justified.
uh yeah somewhere i think
oh actually, my initial implementation of cpystructs on github doesn't use that idea. although i know i've implemented it before
class TypedStructure(ctypes.Structure):
def __new__(cls, *args, **kwargs):
cls.ensure_fields()
return super().__new__(cls, *args, **kwargs)
def __init__(self, *args, **kwargs):
print(self._fields_)
@classmethod
def ensure_fields(cls):
if not hasattr(cls, "_fields_"):
fields = typing.get_type_hints(cls)
cls._fields_ = list(fields.items())
i don't think it handled inheritence either. might be nice to see if i can use yours to simplify stuff
typing.get_type_hints(obj[, globals[, locals]])¶
Return a dictionary containing type hints for a function, method, module or class object.
This is often the same as obj.__annotations__. In addition, forward references encoded as string literals are handled by evaluating them in globals and locals namespaces. If necessary, Optional[t] is added for function and method annotations if a default value equal to None is set. For a class C, return a dictionary constructed by merging all the __annotations__ along C.__mro__ in reverse order.
v2 :p
class StructureMeta(type(ctypes.Structure)):
def __new__(mcs, name, bases, namespace):
cls = super().__new__(mcs, name, bases, namespace)
cls._fields_ = list(
typing.get_type_hints(cls).items()
)
return cls
the best type of code stealing is when you learn from each other :D
🤝
@brazen geyser oh i remember why i didn't create the fields directly in the __new__. that doesn't allow for forward-referencing typehints
hmm
that's why i made it initialise the fields once an instance was being created.
but i'm not sure if there's a better alternative.
im thinking of one rn
what does __new__ do?
working out a way to come back later and fill in the field type
if name is not found yet at time of creation
oh interesting.
the issue with that is that _fields_ cannot be modified properly after it's first created
because you can't just insert spaces into C structs when you want new things in there during runtime
right, so setting _fields_ would be deferred altogether until all field types are corrctly resolved
or correctly resolvable
@gilded orchid take a look at this. it's nothing esoteric really: https://howto.lintel.in/python-__new__-magic-method-explained/
Python is Object oriented language, every thing is an object in python. Python is having special type of methods called magic methods named with preceded and trailing double underscores. When we talk about magic method new we also need to talk about init These metho...
@brazen geyser i figured that the very latest point at which that could be possible is just before struct initialisation
because it clearly can't be any later - that's when _fields_ is set in stone.
and any earlier risks evaluating it too early.
i.e, when the typehints being forward-referenced are not yet existent.
i can't believe i had the mental capacity to figure this out back then, i don't know what's happened since haha :D
originally i'd just settled for writing off forward references as a tradeoff
but now that you brought it up again some lightbulbs went off in my head
so i know that from __futre__ import annotations somehow defers annotation resolution until the end of compilation
perhaps there is a way to hook into this
aside from that was thinking about altering the bytecode of the module frame to add a callback at the end
but that's gonna be a headache and a half probably
definitely sounds like it.
fiddling with __future__ on its own is a no-go because it ties so closely to the interpreter and is very likely to be unstable
@brazen geyser yea annotations use an internal ast unparser which can parse simple expressions
there is literally a big c function that compares import string with known future tags
what should it do?
Presumably add one, rather than add negative one.
>>> dis.dis('j+1')
1 0 LOAD_NAME 0 (j)
2 LOAD_CONST 0 (1)
4 BINARY_ADD
6 RETURN_VALUE``` hm?how to make this work?
>>> def test():
__module__ = '__main__'
__qualname__ = 'test'
def __init__(self):
self.x = 12
def crap(self):
print(self)
>>> cls = __build_class__(test, 'test')
>>> cls().crap()
Traceback (most recent call last):
File "<pyshell#107>", line 1, in <module>
cls().crap()
AttributeError: 'test' object has no attribute 'crap'
>>>
>>> code = """
__module__ = '__main__'
__qualname__ = 'test'
def __init__(self):
self.x = 12
def crap(self):
print(self)
"""
>>> func = FunctionType(compile(code, '<func>', 'exec'), globals())
>>> cls = __build_class__(func, 'test')
>>> cls().crap()
<__main__.test object at 0x000001FAFFB01048>
>>>
why does this work but not that
looking at the difference in bytecode, the only thing that stands out is the use of STORE_NAME rather than STORE_FAST
and func's co_flags are set to 64, whereas test's are set to 67
what's a good way to print N strings of variable size side by side?
I basically want to have these side by side
nvm got it
what’s that lol
the solitaire challenge that's pinned
but for some reason I have an infinite card stack :P
lol
alright it works ish
now to make it a LOT faster
I should be able to use threads here but eh
dont wanna forkbomb my pc
each pile with its own thread? 😄
Are you using ncurses?
Nope
I figured I could just use zip_longest and since they have a constant width I can just use a default value in case of None
it's been going for 45 mins with a random start phase
ohno
optimized the code, lets try again
taking its time, though it already got 2 piles
I wonder how much faster it'd be if I didnt print
I saw that
[(e:=enumerate),(s:=(exit('Invalid Size')if int(i)<3 else int(i))if(i:=input('Board Size (Min 3): ')).isnumeric()else 0),(b:=[[dict(d=__import__('random').choice([0]*s+[1]*(s//3)),n=0)for()in[()]*s]for()in[()]*s]),[[[[t.update(n=t['n']+b[i+x][j+y]['d'])for y in[-1,0,1]if all(map(lambda v:v>=0and v<len(r),[i+x,j+y]))]for x in[-1,0,1]]for j,t in e(r)]for i,r in e(b)],b[0][0].update(d=b[0][0]['d']|8),[*iter(lambda h='\x1b[':all(all((t['d']&1and t['d']&2)or t['d']&4for t in r)for r in b)or[(p:=print)(h+'2J'),[p('',*[h+f'{"7"if t["d"]&8else"0"}m{t["n"]if t["d"]&4else"F"if t["d"]&2else"#"}{h}0m'for t in r])for r in b],p(f'\n{h}7mMove (wasd), Flag (f) or Clear (c):{h}0m '),[*[(lambda t,c,n:lambda:[t.update(d=t['d']^8),b[p][q].update(d=b[p][q]['d']|8)]if(p:=c[0]+n[0])>=0and p<len(b[0])and(q:=c[1]+n[1])>=0and q<len(b[0])else 0)(*(g:=lambda b:sorted([[(t,(i,j))for j,t in e(r)if t['d']&8]for i,r in e(b)])[-1][0])(b),n)for n in zip([-1,0,1,0],[0,-1,0,1])],*map(lambda o:lambda:(t:=g(b)[0]).update(d=exit('You Lose')if t['d']&1and o==4else t['d']^o),[2,4]),p]['wasdfc'.find(__import__('sys').stdin.read(1))]()][0],1)],exit('You win')]```@proper vault it had a bug
I know
what version?
the one you just posted
i meant of python
3.8.0
tf?
Python 3.8.0 (v3.8.0:fa919fdf25, Oct 14 2019, 10:23:27)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> [(e:=enumerate),(s:=(exit('Invalid Size')if int(i)<3 else int(i))if(i:=input('Board Size (Min 3): ')).isnumeric()else 0),(b:=[[dict(d=__import__('random').choice([0]*s+[1]*(s//3)),n=0)for()in[()]*s]for()in[()]*s]),[[[[t.update(n=t['n']+b[i+x][j+y]['d'])for y in[-1,0,1]if all(map(lambda v:v>=0and v<len(r),[i+x,j+y]))]for x in[-1,0,1]]for j,t in e(r)]for i,r in e(b)],b[0][0].update(d=b[0][0]['d']|8),[*iter(lambda h='\x1b[':all(all((t['d']&1and t['d']&2)or t['d']&4for t in r)for r in b)or[(p:=print)(h+'2J'),[p('',*[h+f'{"7"if t["d"]&8else"0"}m{t["n"]if t["d"]&4else"F"if t["d"]&2else"#"}{h}0m'for t in r])for r in b],p(f'\n{h}7mMove (wasd), Flag (f) or Clear (c):{h}0m '),[*[(lambda t,c,n:lambda:[t.update(d=t['d']^8),b[p][q].update(d=b[p][q]['d']|8)]if(p:=c[0]+n[0])>=0and p<len(b[0])and(q:=c[1]+n[1])>=0and q<len(b[0])else 0)(*(g:=lambda b:sorted([[(t,(i,j))for j,t in e(r)if t['d']&8]for i,r in e(b)])[-1][0])(b),n)for n in zip([-1,0,1,0],[0,-1,0,1])],*map(lambda o:lambda:(t:=g(b)[0]).update(d=exit('You Lose')if t['d']&1and o==4else t['d']^o),[2,4]),p]['wasdfc'.find(__import__('sys').stdin.read(1))]()][0],1)],exit('You win')]
Board Size (Min 3):
it happens once you enter a number
# # #
# # #
# # #
Move (wasd), Flag (f) or Clear (c):
``` this happens when you enter a number(3 here obv)
can you type '0'.isnumeric into your interpreter?
@proper vault ^
ye, windowses fault
did you try it in command prompt
yea i use some terminal codes
happens in command prompt too
iirc you need to use something like colorama to make ansi escape codes work in windows terminal
yea i'd need to add __import__('colorama').init() to the beginning of the list comp
pycharm terminal does work
pycharm does some magic to terminal stdout
i think it also uses colorama
it screws up piping in some instances iirc
i do think that bool error was bizarre tho
oh wait, I know
I was messing with builtins in that instance and replaced print
lmao
that would do it
lmao
but yea its full minesweeper in one listcomp
still working on adding the recursive clearing that normal minesweeper has
does colorama monkey patch print or something?
yes
hijacks stdout altogether iirc
ANSI escape character sequences have long been used to produce colored terminal text and cursor positioning on Unix and Macs. Colorama makes this work on Windows, too, by wrapping stdout, stripping ANSI sequences it finds (which would appear as gobbledygook in the output), and converting them into the appropriate win32 calls to modify the state of the terminal. On other platforms, Colorama does nothing.
no idea
aight
no
On windows you need to enable ANSI escapes through the windows API
But it supports 24-bit colour
I haven't tried if it supports all the useful features though
reworked the entire code for solving the boards in a faster language (kotlin/native) and gave it a maximum move depth of 200
Let's see what it comes up with
now i want to do this terminal game to add to my collection
it's part of molek-syntez which I definitely recommend as its a great logical thinking puzzle game
alternatively I could rewrite this into an engine to play the game
see pins
40 chars? that's not a lot of chars
so is it like freecell
idk freecell
you can move descending stacks --- but the stacks also need to be black,red,black,red alternating
isnt that just solitaire?
I see
https://transfer.sh/pO7jG/SolitaireSolver.jar
@zealous widget here's something that should allow you to play it
whoops wait
main class typo
[(e:=enumerate),(s:=(exit('Invalid Size')if(int(i)if(i:=input('Board Size (Min 3): ')).isnumeric()else 0)<3else int(i))),(b:=[[dict(d=__import__('random').choice([0]*s+[1]*(s//3)),n=0)for()in[()]*s]for()in[()]*s]),[[[t.update(n=t['n']+b[i+x][j+y]['d'])for y in[-1,0,1]for x in[-1,0,1]if all(map(lambda v:v>=0and v<len(r),[i+x,j+y]))]for j,t in e(r)]for i,r in e(b)],(f:=lambda x,y,v:(t:=b[x][y]).update(d=t['d']^v))(0,0,8),[*iter(lambda h='\x1b[':all(all((t['d']&1and t['d']&2)or t['d']&4for t in r)for r in b)or[(p:=print)(h+'2J'),[p('',*[h+f'{"7"if t["d"]&8else"0"}m{t["n"]if t["d"]&4else"F"if t["d"]&2else"#"}{h}0m'for t in r])for r in b],p(f'\n{h}7mMove (wasd), Flag (f) or Clear (c):{h}0m '),[*[(lambda t,c,n:lambda:[f(*c,8),f(p,q,8)]if(p:=c[0]+n[0])>=0and p<len(b[0])and(q:=c[1]+n[1])>=0and q<len(b[0])else 0)(*(g:=lambda b:sorted([[(t,(i,j))for j,t in e(r)if t['d']&8]for i,r in e(b)])[-1][0])(b),n)for n in zip([-1,0,1,0],[0,-1,0,1])],lambda:f(*g(b)[1],2),lambda:exit('You Lose')if(t:=g(b))[0]['d']&1else f(*t[1],4)if t[0]['n']else(r:=lambda i,j,l:[[[f(*c,4),r(*c,l+[c])if t['n']==0and c not in l else 0]if not(t:=b[i+x][j+y])['d']&4and not t['d']&1else 0]for y in[0,1,-1]for x in[0,1,-1]if all(map(lambda v:v>=0 and v<len(b[0]),(c:=(i+x,j+y))))])(*t[1],[]),p]['wasdfc'.find(__import__('sys').stdin.read(1))]()][0],1)],exit('You win')]
i added the recursive clearing
Board<C : Card<C, S>, S : Stack<C, S>> surely there's a better way to do this
What does that notation represent?
it'd be like uhh
Board[C:=Card[C, S], S:=Stack[C, S]] where C and S are defined recursively
Hey @grave rover!
It looks like you tried to attach a file type that we do not allow. We currently allow the following file types: .3gp, .3g2, .avi, .bmp, .gif, .h264, .jpg, .jpeg, .m4v, .mkv, .mov, .mp4, .mpeg, .mpg, .png, .tiff, .wmv, .svg, .psd, .ai, .aep, .xcf, .mp3, .wav, .ogg.
Feel free to ask in #community-meta if you think this is a mistake.
oh right
https://transfer.sh/H4rHm/SolitaireSolver.jar @zealous widget here's the jar to solve boards yourself
This is a python server 
yes
but I did solve the problem in python
it's just that I rewrote it in Kotlin to actually see any results :^)
then he wanted to play it so I reworked it to allow him to play
@rugged sparrow that is disgusting
and i was proud of mine mess baby until i saw that
class BoopBoop():
def BorpBif(BepaBip, BupBup):
BapBif = BepaBip
Bip = ""
BopBip = Bip.join(BapBif)
BepBid = "urgle"
BufBip = (BopBip+" "+BupBup+BepBid)
print(BufBip)
def Bobbup(Blup):
BupBup = Blup
BefBip = {
"BabBab":"a", "BadBab":"b", "BabBap":"c", "BabBad":"d",
"BebBeb":"e", "BedBeb":"f", "BedBep":"g", "BebBed":"h",
"BibBib":"i", "BidBib":"j", "BidBip":"k", "BibBid":"l",
"BobBob":"m", "BodBob":"n", "BodBop":"o", "BobBod":"p",
"BubBub":"q", "BudBub":"r", "BudBup":"s", "BubBud":"t",
"BaabBaab":"u", "BaadBaab":"v", "BaadBaap":"w", "BaabBaad":"x",
"BoobBoob":"y", "BoodBoob":"z", "BoobBoop":" "
}
BepaBip = (BefBip["BoobBoob"],BefBip["BodBop"],BefBip["BaabBaab"],BefBip["BudBub"],BefBip["BoobBoop"],
BefBip["BodBob"],BefBip["BabBab"],BefBip["BobBob"],BefBip["BebBeb"],BefBip["BoobBoop"],BefBip["BibBib"],BefBip["BudBup"])
BoopBoop.BorpBif(BepaBip, BupBup)
def BipBop(BaapBip, Bup):
BupBeep = (BaapBip*Bup)
BepBep = (''.join(sorted(BupBeep)))
Blup = (BepBep[len("ba")]+BepBep[len("Boof")])
BoopBoop.Bobbup(Blup)
def BopBid():
Bup = len("Bap")
BoopBip = "BabBoop>>>"
BaapBip = input(BoopBip)
BoopBoop.BipBop(BaapBip, Bup)
if __name__ == '__main__':
BoopBoop.BopBid()```mine is beautiful code cereal as my friend called it
does it need anything to run? didnt work for me
what error?
[(e:=enumerate),(s:=(exit('Invalid Size')if(int(i)if(i:=input('Board Size (Min 3): ')).isnumeric()else 0)<3else int(i))),(b:=[[dict(d=__import__('random').choice([0]*s+[1]*(s//3)),n=0)for()in[()]*s]for()in[()]*s]),[[[t.update(n=t['n']+b[i+x][j+y]['d'])for y in[-1,0,1]for x in[-1,0,1]if all(map(lambda v:v>=0and v<len(r),[i+x,j+y]))]for j,t in e(r)]for i,r in e(b)],(f:=lambda x,y,v:(t:=b[x][y]).update(d=t['d']^v))(0,0,8),[*iter(lambda h='\x1b[':all(all((t['d']&1and t['d']&2)or t['d']&4for t in r)for r in b)or[(p:=print)(h+'2J'),[p('',*[h+f'{"7"if t["d"]&8else"0"}m{t["n"]if t["d"]&4else"F"if t["d"]&2else"#"}{h}0m'for t in r])for r in b],p(f'\n{h}7mMove (wasd), Flag (f) or Clear (c):{h}0m '),[*[(lambda t,c,n:lambda:[f(*c,8),f(p,q,8)]if(p:=c[0]+n[0])>=0and p<len(b[0])and(q:=c[1]+n[1])>=0and q<len(b[0])else 0)(*(g:=lambda b:sorted([[(t,(i,j))for j,t in e(r)if t['d']&8]for i,r in e(b)])[-1][0])(b),n)for n in zip([-1,0,1,0],[0,-1,0,1])],lambda:f(*g(b)[1],2),lambda:exit('You Lose')if(t:=g(b))[0]['d']&1else f(*t[1],4)if t[0]['n']else(r:=lambda i,j,l:[[[f(*c,4),r(*c,l+[c])if t['n']==0and c not in l else 0]if not(t:=b[i+x][j+y])['d']&4and not t['d']&1else 0]for y in[0,1,-1]for x in[0,1,-1]if all(map(lambda v:v>=0 and v<len(b[0]),(c:=(i+x,j+y))))])(*t[1],[]),p]['wasdfc'.find(__import__('sys').stdin.read(1))]()][0],1)],exit('You win')]
^
SyntaxError: invalid syntax```do w/out walrus
I could, but if it’s a part of official python, why not
many people are 3.7 @rugged sparrow
That's fair
im only 3.6.6 😦
I'll rewrite Tonight to use a dictionary
why not use
a = 1;a + a #into
(lambda a: a + a)(1)
semicolons is cheating
you only use the second line
@proper vault I actually think imma do a different method
[[[[[t.update(n=t['n']+b[i+x][j+y]['d'])for y in[-1,0,1]for x in[-1,0,1]if all(map(lambda v:v>=0and v<len(r),[i+x,j+y]))]for j,t in e(r)]for i,r in e(b)],f(b,0,0,8),[*iter(lambda h='\x1b[':all(all((t['d']&1and t['d']&2)or t['d']&4for t in r)for r in b)or[p(h+'2J'),[p('',*[h+f'{7if t["d"]&8else 0}m{t["n"]if t["d"]&4else"F"if t["d"]&2else"#"}{h}0m'for t in r])for r in b],p(f'\n{h}7mMove (wasd), Flag (f) or Clear (c):{h}0m '),[*[(lambda t,c,n:lambda:[f(b,*c,8),f(b,c[0]+n[0],c[1]+n[1],8)]if c[0]+n[0]>=0and c[0]+n[0]<len(b[0])and c[1]+n[1]>=0and c[1]+n[1]<len(b[0])else 0)(*g(b,e),n)for n in zip([-1,0,1,0],[0,-1,0,1])],lambda:f(b,*g(b,e)[1],2),lambda:exit('You Lose')if g(b,e)[0]['d']&1else f(b,*g(b,e)[1],4)if g(b,e)[0]['n']else r(b,f,r,*g(b,e)[1],[]),p]['wasdfc'.find(__import__('sys').stdin.read(1))]()][0],1)],exit('You win')]for e,p,b,f,g,r in[(enumerate,print,(lambda s:[[dict(d=__import__('random').choice([0]*s+[1]*(s//3)),n=0)for()in[()]*s]for()in[()]*s])((lambda i:int(i)if i.isnumeric()and int(i)>2else(exit('Invalid Size')))(input('Board Size (Min 3): '))),lambda b,x,y,v:b[x][y].update(d=b[x][y]['d']^v),lambda b,e:sorted([[(t,(i,j))for j,t in e(r)if t['d']&8]for i,r in e(b)])[-1][0],lambda b,f,r,i,j,l:[[[f(b,i+x,j+y,4),r(b,f,r,i+x,j+y,l+[(i+x,j+y)])if b[i+x][j+y]['n']==0and(i+x,j+y)not in l else 0]if not b[i+x][j+y]['d']&4and not b[i+x][j+y]['d']&1else 0]for y in[0,1,-1]for x in[0,1,-1]if all(map(lambda v:v>=0and v<len(b[0]),(i+x,j+y)))])]]
``` @proper vault @next mist @marsh void here is one with no walrus'sbless you, haha
i used a single loop for loop to make my local vars
instead of walrus's
which means this function now does nothing to the global scope
Thanks I hate it
youre welcome
I am getting some anxiety from just looking at that
(0for()in()).throw(Exception("heck"))
precisely
Lmao
It's nicer on the player if they're running from a repl if it's an exception and not a call to exit.
I guess it doesn't really matters here, but it is cool to know, not putting a space between keywords (0for()in() instead of 0 for () in ()) works in all major python implementations, except micropython, which is kind of fun
So, if you are doing esoteric for micropython, you need spaces everywhere :D
sad
Such a flawed implementation smh
It does what it sets out to do.
why does micropython require spaces
does it use a lexer like my js expression parser?
const lex = c => c.split(" ").map(s => s.trim()).filter(s => s.length) this requires spaces around every token lmao
print ( "hello world" )
yes except that wouldn't be valid for my thing
space inside a token?
Spaces around a token are required
well i mean my parser requires this sin ( max ( 2 3 x ) / 3 ) * PI
yes
@thin trout I'm saying my custom parser requires spaces like that and was asking if MicroPython was the same
μPython doesnt have unicode name escapes?
Nope
I've finally completed visualization of token matching through BRM

GitHub
Bicycle Repair Man - Rewrite Python Sources with Your Additions - isidentical/BRM
bruh
thats cool
yo this is cool as fuck coding: brm-utf8
gives me so many ideas for absolute shitcode :)
The reason I wrote this is supporting dead peps, which contains tons of shitcode
interface Foo:
pass
print(Foo.__abstractmethods__)
for i indexing e in some_iterator:
print(i, e)
for i in 3:
if i > 1:
print(i)
!pep 245
**PEP 245 - Python Interface Syntax**
Status
Rejected
Python-Version
2.2
Created
11-Jan-2001
Type
Standards Track
!pep 212
**PEP 212 - Loop Counter Iteration**
Status
Rejected
Python-Version
2.1
Created
22-Aug-2000
Type
Standards Track
etc.
I posted the project about implementing these on the chanel if you would like to see actual implementation
!pep 315
**PEP 315 - Enhanced While Loop**
Status
Rejected
Python-Version
2.5
Created
25-Apr-2003
Type
Standards Track
this one seemed pretty interesting actually
I seems more dumb than interesting to me tbh :D
Wasn't this guy Raymond Hettinger, one of the first python dev?
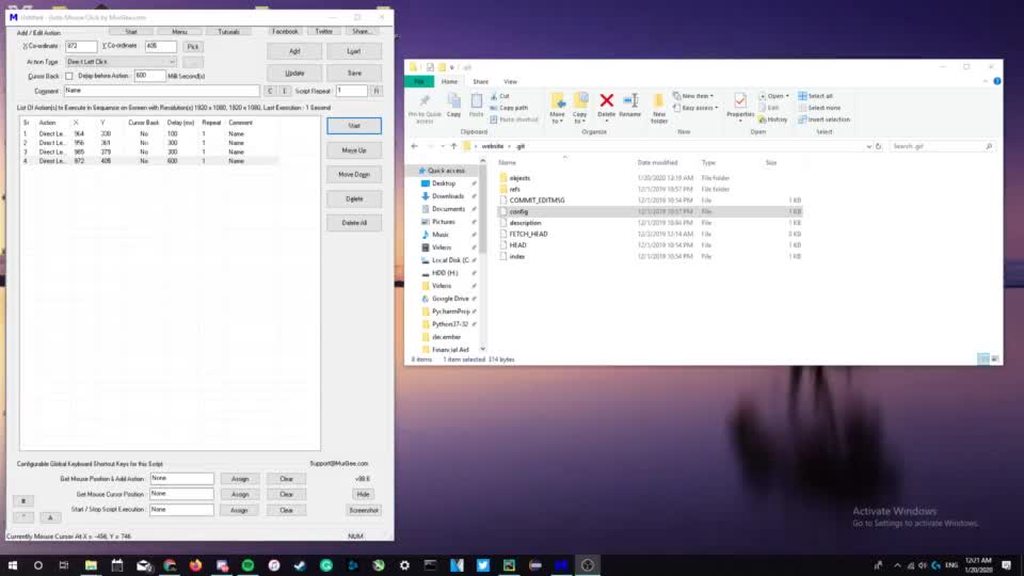
Anyone know how this program does this?
It sends click requests without moving the mouse at all
and if it's possible in Python
it is easily possible, there's a module on PyPI that you can install with pip called pynput (just to name one option) which lets you control the mouse and keyboard using python. it's got nothing to do with #esoteric-python though :D
(@valid stone)
i'm not sure if it'll be able to do it without moving the mouse as in the thing you sent, but i don't see why it shouldn't (and if pynput doesn't do it, there will likely be similar modules that can)
@marsh void for 315 you can probably do something like that in brm,
@pattern("name", "colon", "newline", "indent", "(.*?)", "dedent", "name", "(.*?)", "colon", "newline", "indent", "(.*?)", "dedent")
def indexing_transformer(self, *stream_tokens):
stream_token = iter(stream_tokens)
if next(stream_token).string != "do":
return
next(stream_token) # colon
next(stream_token) # newline
next(stream_token) # indent
setup, dedent = self.until(token.DEDENT, stream_token)
statement = next(stream_token)
if statement.string != "while":
return
test, colon = self.until(token.COLON, stream_token)
newline = next(stream_token)
indent = next(stream_token)
body, dedent = self.until(token.DEDENT, stream_token)
return (*setup, statement, *test, colon, newline, indent, *body, *setup, dedent)
oh, ok
@brisk zenith I think the issue is the moving without the mouse part. I already coded something like it in Pyautogui but I don't like the fact it takes control of my mouse.
I've used pyninput too and can't seem to find a way to do this either
@marsh void Maybe I'm doing something wrong but ctypes still moves the mouse when clicking.
maybe the original position is stored and the mouse is just moved really quickly
Not too sure but I really doubt it. There's almost no delay or lag in my mouse in the video. When I tried what you said, there were always slight hiccups
from looking around I can't find too much on it
https://pypi.org/project/PyAutoIt/ there is this that might work, but it can't click on specific coordinates

Yeah I tried that too couldnt get it to work with coorindates. Also had to select a window each time which seems overcomplicated :/
maybe it's sending messages to the window?
!e
from sys import getsizeof as size
print(size(()))
print(size(list()))
@marsh void :white_check_mark: Your eval job has completed with return code 0.
001 | 40
002 | 56
What is #esoteric-python ?
hell on earth
^
!e
from ctypes import *
(c_void_p*52).from_address(id(int))[16]=cast(CFUNCTYPE(py_object,py_object,py_object,c_void_p)(lambda s,*_:s),c_void_p)
print(5())
@proper vault :white_check_mark: Your eval job has completed with return code 0.
001 | 5
002 | <string>:3: SyntaxWarning: 'int' object is not callable; perhaps you missed a comma?
not mine
!e ```py
from ctypes import *
(c_void_p52).from_address(id(int))[16]=cast(CFUNCTYPE(py_object,py_object,py_object,c_void_p)(lambda s,_:s),c_void_p)
x = 5
print(x())
@pure dew :white_check_mark: Your eval job has completed with return code 0.
5
you gotta trick the parser
I find the warning more appropiate
>>> import ctypes
>>> import sys
>>> string = 'waaaaario'
>>> ctypes.memset(id(string) + sys.getsizeof(string) - len(string) - 1, ord('m'), 1)
2189490438368
>>> string
'maaaaario'
>>>
mutable strings :P
@brazen geyser chances it segfaults? heh
Just don't put it in a dict key.
>>> def pointer_to(string):
pointer_type = ctypes.c_char * len(string)
return pointer_type.from_address(id(string) + sys.getsizeof(string) - len(string) - 1)
>>> pointer_to('a')[0] = b'z'
>>> 'a'
'z'
lel
This is actually pretty useful for avoiding
n= list(str)
n[::2]='5'
''.join(n)
And similar
3.8
same result in 3.8
>>> 'a' + 'a'
'aa'
>>> 'a'
'z'
>>>
'a'*3 works correctly too
🤷♂️
Would it be possible to get a variable which is a pointer to a list member
I would think you could if you can get pointers to things
But I have no idea how to even start trying it myself
You might be able to get an attribute, but a variable would be much harder.
What's the difference that makes it so
Attributes can have getters and setters
Ah
But would it need be possible to abuse this thing https://discordapp.com/channels/267624335836053506/470884583684964352/669294218811932706
ctypes could do it
It depends on what you'd do with the variable.
hey
@brazen geyser @rugged sparrow i'm guessing it's because sometimes simple operations get optimized ```py
import dis
dis.dis('1 + 1')
1 0 LOAD_CONST 1 (2)
2 RETURN_VALUE```
ah constant folding
maybe this is well known, but I've come up with a tiny, fast way to get an array of bits from a byte
nope
just bitwise
get_bits = lambda b, l=8: ((n, int((b & 2 ** n) > 0)) for n in range(l - 1, -1, -1))
returns a generator of (bit_index, bit_value)
change l to whatever bitsize you want to parse as
although, it does give them backwards fixed
a much more boring solutionlambda b,l=8: zip(range(l), map(int, bin(b)[2:].zfill(l)[::-1]))
I was trying to use an fstring f'{bin(n):0>8.8}', but that does not let you use variables for the format afaik
huh, never knew that

function call overhead and other python meandering is slower than a string conversion and any operation on it
lambda b,l=8: zip(range(l), map(int, f'{bin(b)[2:]:0<{l}.{l}}'))
fstring version. whether to use > or < is questionable
here i was thinking i discovered something awesome
it is quite neat, I used similar pieces of code in C and such (at least until I found out about structs and their wondrous uses for accessing specific

{kind=link}
{kind=link}
{kind=link}
fstrings are fast
faster than bitwise?
lambda b,l=8:enumerate(map(int, f'{bin(b)[2:]:0<{l}.{l}}'))```ye, that is better
magic
that one's 336 nsec
well, we both call int() (which you do not need btw, bool is a subclass of int
i'm still using mine because it looks best
oh wait
but if it parses the same
i = lambda s:int(i)if(i:=input(s)).isnumeric()else i
``` whats yalls smallest safe integer inputooo you know what would be interesting to golf?
an input that converts what you put in into its relevant type
so "{'hi':1}" would become {'hi':1}
(obv no eval tricks)
What types would it need to work with?
as many as you want
I would presume every valid python literal
lambdas would be hard...
btw this means to make a string youd acc need to type "a"
i = lambda s='':__import__('json').loads(input(s).replace("'",'"'))``` this is kinda cheating lmaoJSON doesn't eval then?
Ah. Those are important.
handles the hardest type tho
dictionarys
as long as its keys/values arent any of those types
Another challenge: golf a lisp parser.
what do you want as the output? cons cells?
Some sort of abstract syntax tree, I suppose.
Python lists would be fine, if there's a way to support x . y
And all the fancy Common Lisp syntax isn't necessary.
Basically, a tuple parser with spaces instead of commas, plus \``, ',,` and brackets.
That formatting was not how I intended it.
It's a cons operation.
oh
It basically appends to the front of a list, but it works if y isn't a list.
Lists in lisp are singly linked, and a cons cell is just a pair, generally containing the first item in the list, and the rest of the list.
x to y
I like it better than Python lists, but you can't do as many nifty syntax abominations in Lisps
Or Haskell.
Is that the syntax, or the standard incomprehensibility of the operations themselves?
both
Lisp, Haskell and Forth all take forms that would normally be syntax, and turn them into ordinary yet labyrinthine functions.

thats some of the cryptical concepts behind Lens/Optics
well i mean
you can define your own operators in haskell
i really wish i had the discipline to actually sit down and really learn haskell
ah yes, enslaved transparent bricks
@pure dew
def get_bits(n, l=8):
for i in range(l-1, -1, -1):
yield (n>>i)&1
how bout some bit shifting
how fast is that
>>> get_bits = lambda b, l=8: ((n, int((b & 2 ** n) > 0)) for n in range(l - 1, -1, -1))
>>> get_bits_2 = lambda b,l=8: zip(range(l), map(int, bin(b)[2:].zfill(l)[::-1]))
>>> get_bits_3 = lambda b,l=8: zip(range(l), map(int, f'{bin(b)[2:]:0<{l}.{l}}'))
>>> get_bits_4 = lambda b,l=8:enumerate(map(int, f'{bin(b)[2:]:0<{l}.{l}}'))
>>> def get_bits_5(n, l=8):
for i in range(l-1, -1, -1):
yield (n>>i)&1
>>> from timeit import timeit
>>> timeit(lambda: list(get_bits(255)))
5.1405962000000045
>>> timeit(lambda: list(get_bits_2(255)))
2.7823927000000026
>>> timeit(lambda: list(get_bits_3(255)))
2.9149553999999966
>>> timeit(lambda: list(get_bits_4(255)))
2.6694615000000113
>>> timeit(lambda: list(enumerate(get_bits_5(255))))
2.128367200000014
>>>

tf
!support
get_bits_5 = lambda n, l=8:((n>>i)&1 for i in range(l-1,-1,-1))```thanks
imo it's better to leave out the enumeration
that way it can be used with/without based on preference
fair
f=lambda n,l=8:enumerate((n>>i)&1for i in range(l-1,-1,-1))``` fixed spaces you have wasted hahaf=lambda n,l=8:(n>>i&1for i in range(l)[::-1])
f=lambda n,l=8:((l-1-i,n>>i&1)for i in range(l)[::-1])
``` for the enumerated variantsmart
what's faster, maps or generators?
generally, generators AFAIK
ic
but it does not make enough of a difference to worry about
>>> data = [None] * 10
>>> timeit(lambda: any(map(bool, data)))
1.0028259000027901
>>> timeit(lambda: any(map(bool, data)))
0.9498011999967275
>>> timeit(lambda: any(bool(i) for i in data))
1.8893212000039057
>>> timeit(lambda: any(bool(i) for i in data))
1.8412518999975873
>>>
genexps operate using python bytecode whereas (i think) map operates on the C level.
>>> dis('(bool(i) for i in [])')
1 0 LOAD_CONST 0 (<code object <genexpr> at 0x0000014912E69030, file "<dis>", line 1>)
2 LOAD_CONST 1 ('<genexpr>')
4 MAKE_FUNCTION 0
6 LOAD_CONST 2 (())
8 GET_ITER
10 CALL_FUNCTION 1
12 RETURN_VALUE
Disassembly of <code object <genexpr> at 0x0000014912E69030, file "<dis>", line 1>:
1 0 LOAD_FAST 0 (.0)
>> 2 FOR_ITER 14 (to 18)
4 STORE_FAST 1 (i)
6 LOAD_GLOBAL 0 (bool)
8 LOAD_FAST 1 (i)
10 CALL_FUNCTION 1
12 YIELD_VALUE
14 POP_TOP
16 JUMP_ABSOLUTE 2
>> 18 LOAD_CONST 0 (None)
20 RETURN_VALUE
>>> dis('map(bool, [])')
1 0 LOAD_NAME 0 (map)
2 LOAD_NAME 1 (bool)
4 BUILD_LIST 0
6 CALL_FUNCTION 2
8 RETURN_VALUE
>>>
I remember map being slower for getting the first element of a tuple in a list
probably lambda overhead
I tested with operator.itemgetter
>>> first_tuple_elem = lambda t: t[0]
>>> list_of_tuples = [(1, 2, 3)] * 100
>>> timeit(lambda: all(map(lambda t: t[0], list_of_tuples)))
11.444330099999206
>>> timeit(lambda: all(t[0] for t in list_of_tuples))
7.270005300000776
>>> timeit(lambda: all(first_tuple_elem(t) for t in list_of_tuples))
15.800058400003763
>>>
this is kinda interesting as well
oh forgot to add
>>> timeit(lambda: all(map(first_tuple_elem, list_of_tuples)))
9.059378099998867
based on this i think we can generalize as follows: if applying a callable, use map. if applying an expression, or if the callable can be reasonably deconstructed as an expression, use genexp
@proper vault
>>> from doublescript.structs import PyTypeObject
>>> class Test:
pass
>>> struct = PyTypeObject.from_address(id(Test))
>>> struct.tp_mro
(<class '__main__.Test'>, <class 'object'>)
>>> struct.tp_mro = ()
>>> Test.__mro__
()
>>>
:p
PyTypeObject borrowed from https://github.com/fdintino/python-doublescript
>>> isinstance(Test(), object)
False
>>>
now it actually works for real this time
havent messed with builtins.object
Nice
>>> struct = PyTypeObject.from_address(id(int))
>>> def int_iter(self):
yield from range(self)
>>> func_type = ctypes.CFUNCTYPE(ctypes.py_object, ctypes.py_object)
>>> func_pointer = func_type(int_iter)
>>> struct.tp_iter = func_pointer
>>> [*12]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
>>>
forbiddenfruit doesnt handle tp_iter yet
>>> PyTypeObject.from_address(id(object)).tp_mro = ()
>>> isinstance(object, type)
True
>>> isinstance(object, object)
False
>>> PyTypeObject.from_address(id(type)).tp_mro = ()
>>> isinstance(type, object)
False
>>> isinstance(type, type)
True
>>>
thats interesting
isinstance(..., type) bypasses the mro
@tropic night
yes, as i noted lastly in python-discussion. ... bla bla bla bla... except for type 😄
well ordinarily type would be considered an instance of a class too, by virtue of being an object.
just think it's interesting that isinstance(thing, type) willcan return True even if there's nothing in the mro
@brazen geyser doublescript is again something that messes with C and memory and only works on CPython? heh
!e
from dis import dis
def ok(string: str) -> None:
print(string), dis(string)
ok('a if a is not None else b')
ok('(a,b)[a is not None]')
@marsh void :white_check_mark: Your eval job has completed with return code 0.
001 | a if a is not None else b
002 | 1 0 LOAD_NAME 0 (a)
003 | 2 LOAD_CONST 0 (None)
004 | 4 COMPARE_OP 9 (is not)
005 | 6 POP_JUMP_IF_FALSE 12
006 | 8 LOAD_NAME 0 (a)
007 | 10 RETURN_VALUE
008 | >> 12 LOAD_NAME 1 (b)
009 | 14 RETURN_VALUE
010 | (a,b)[a is not None]
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/asorarocih
A !dis command could be nice
I mean, upload it to the paste service
oh, I can do that then, haha
What I'm seeing from this is that if else is faster.