#tools-and-devops
1 messages · Page 77 of 1
Ty. I ll be checking it out.
Hello, Anyone know of a python library that compiles typescript into javascript?
hello, can someone help me
i am trying to make that when the Y position thing gets negative, it reverse the decimal part of the number

like, at the tick n°11, instead of -0.343.... , i want to make the program shows the program shows -0.657... (1000 - 0.343) but without changing the integer part
and keeping the negative thing
the code :

call the normal typescript compiler via subprocess?
anyone actually use devpi? I found that when I installed devpi on a docker container on a bare metal server with a big and fast NVMe SSD, and then configured pip to use it, my installs are now slower
it seems to be pretty consistently around 20% slower, and packages that are not yet cached are way slower, and regularly crash with random "version not found" errors that magically go away when just attempting to install again
@rich remnant does it work better in not-a-docker container?
i wonder if there's a lot of overhead somehow
yeah i doubt it too. maybe it's just janky software and nobody questions it because so few people actually run pypi mirros? 😆
well, I can try straight on bare metal, configs are already there and only need to install 2 packages really
yeah just do it in a venv
i'm curious
the "version not found" errors sound like it's just janky though
I tried to take a look at their code and it looks like the server is written using pyramid and wsgi and .. that kinda smells to me
I feel like devpi tries to do a few too many things and hasn't really been updated with the evolving python web framework landscape .. I was kinda considering looking at what the exact protocol is like for pip and seeing if I could just write a better purely pypi caching proxy with go/fastapi
local_file="${repo_dir}/${pkg_file}"
if [[ -f "$local_file" ]]; then
serve_file "$local_file"
else
pypi_url="${pypi_url}/${pkg_file}"
fetch_and_cache "$pypi_url"
fi
is it more complicated than that?
devpi is also written to be so that you can push your own packages to it, register user accounts, and all kinds of things
fwiw that could easily be 2 separate server processes, no?
maybe a devpi replacement would be a good project
especially if it's a portable (go?) binary that you can just scp onto a server
I feel like there would be a lot more need for a simple pypi local cache for build servers etc.
oh right, and it's doing some search indexing when you first start it up instead of when it gets a request .. I'm really not sure why all of this is as complicated as it is but it seems like it shouldn't be
yea indeed
if anything it's in the interest of the psf/pypa to have better tools
this kind of thing is what the world needs:
scp ./minipypi pypi-user@my-server:/var/www/pypi-mirror/
ssh pypi-user@my-server 'cd /var/www/pypi-mirror && ./minipypi --init
static config file, separate server processes (separate binaries?) for search and upload
if you want https etc just use nginx
now I apparently need to mess with some firewalls or something, apparently it was fine when the port was opened by docker but now when it's just opened directly it's blocked from outside the host, even though it's listening to 0.0.0.0
that might be your system, but interesting and good to know
what os are you using? maybe the post-install script adds some firewall exceptions
(which tbh i find kind of bad if that's true)
just installing via pip so unlikely, this is just ubuntu server
no i mean the install script for docker
must be something like that, that docker is just automatically allowed, or something
yea ufw allow 3141/tcp was necessary
I'm overall quite unhappy about all the things this experiment is bringing up 😄
indeed, also makes me want to read what exactly devpi does and try to make a simpler version
I decided to migrate to a bare metal build server since I had some extra hardware which after testing was depending on workload either as fast or faster than the 80€/mo build machine I was using
and since I had a bare metal build server with 2TB of NVMe I decided that local caches for apt & pip & npm made sense, apt is .. a mess as well, but I managed to hack together something that works .. npm was semi easy, though I've not yet benchmarked verdaccio .. but this devpi .. so far has been very painful
imo we need a standard for package repo servers and file layout
i feel like every one of these tools is solving the same problem with more or less the same constraints, but from scratch every time
indeed
maybe it's the kind of thing where once you dig into it, they're all subtly different and any unified standard would be uselessly broad and/or have too many configuration options
like a lot of "we need a standard!" standards from the 90s and 00s
well, there's some company that has a java based product that can apparently host repos for basically all of the tools
but since it's java based I already got depressed at looking at the -Xms etc. options and imagining the future of having to manage the memory arguments with little guidance
i avoid jvm applications for this reason. i am not a wizard

wow repl.it open sourced their evaluation server? that's really cool. i should host my own
GitHub
ok that is pretty cool
- community support for APK, Cargo, etc.
you could also standardize on conda if you needed polyglot stuff... but building conda packages with complicated dependencies can be nontrivial
it's like asdf-vm, it turned out that pyenv rbenv nvm etc were all more or less doing the same thing
so you can replace them all with one pluggable version manager
Manage multiple runtime versions with a single CLI tool
maybe -Xms is worth it 😛
im sure theres some guidance somewhere. after all it's not much different from setting memory limits on a docker/podman/lxc container or a vm
ok so on bare bare metal installing via devpi takes 42s vs 48s without devpi vs 58s from inside docker .. I wonder what is killing that docker performance because basically the entire reason for docker is to have minimal abstraction layers
anyway 42s vs 48s is probably not worth running this complicated mess for
my main issue with those java based things is that they just randomly start crashing later on and then you need to start tweaking some configuration values again basically randomly and hope it stays stable for long enough that you forget how to configure it again 
huh so docker actually was the problem?
true
what if you use systemd-nspawn or something, i wonder if that's any better
i've never heard of docker having so much overhead
could be something else related to the container but most things should be basically the same as the host system
python 3.9.12 vs 3.9.5 .. I find it unlikely there were huge performance differences between those
the host was just using the exact same configuration
was it ubuntu in the container as well as the host?
yea
weird
i wonder if devpi does some kind of auto-detection for cores or memory and changes something
I think all it does is start up a threadpool with 50 threads
it might have something to do with the -v /cache:/cache mounting but .. I was kind of under the impression that that should be the fastest and simplest option
I'll just benchmark the container once more for sanity
sigh
wait isn't the point of wsgi that you don't need that
or does it include its own wsgi server instead of using gunicorn
CPUs & RAM shouldn't be an issue in the container

I found the code to be hard to follow but it really looked like it literally spawned its own built-in server process with wsgi
https://github.com/devpi/devpi/blob/main/server/devpi_server/main.py this is what it runs when you run devpi-server - which is what they say you should do

GitHub
Python PyPi staging server and packaging, testing, release tool - devpi/main.py at main · devpi/devpi
or rather the main() function from that
which then goes to the XOM class main()


um hm .. well the devpi container seems a tiny bit faster now, only 52s
but still slower
I saw the import aiohttp at the top of the file and was hopeful that maybe it didn't suck, but sure seems it is just a threaded wsgi server with no gunicorn or anything helping it out the slightest
that's extremely yucky @rich remnant
yeah, like I said, when I looked at that file I was not surprised about it being slow
heck you could probably replace this with an aiohttp/starlette server and hypercorn/uvicorn. forget drop-in static binaries, even that would probably be an improvement
i now have a project idea so ty. going to write a devpi replacement in Hy
blame really explains a lot

heh
just let me know when it's done so I can use it
probably never, i am a notorious yak shaver
honestly curious if the handler needs to be any more complicated than a caching http proxy
with some basic logic to cache certain things for longer on the filesystem
I might just try to set up an nginx reverse proxy container in front of pypi and see how that does

Gist
Caching PyPi packages locally with nginx. GitHub Gist: instantly share code, notes, and snippets.
makes it look like it's extremely simple
like simple enough to still do within today, 1.5h left of the day
if I understood it right, my own image is now building, will get to try it in a few min I guess
good point and good idea
the actual pypi api actually seems a bit complicated
there is some xmlrpc stuff happening
yea but how much does a caching proxy needs to know about the api, it's just "please give me this version of this package" most of the time, right?
exactly, that's why a "dumb" caching proxy is a better idea than rewriting devpi
at least when talking about poetry install
the tradeoff is that you can't easily upload your own packages, unless you host those at a separate index url
mjea but that's for other things to worry about
there was some extra index url option
right, --index-url https://pypi.myorg.net/index --extra-index-url https://pypi.myorg.net/extra
the former is the caching proxy and the latter is your private stuff
yea something like that
could maybe even use the same nginx to cache both
if devpi is slow
I wonder why it needs the autoindex
i think that's how it does package discovery
I kinda hate it, but makes sense for available versions I guess .. sort of
you could probably write a script to statically rebuild the index upon changes, if you wanted
would prefer some .json file or something but it's not a bad thing that it works over a simpler system
yeah
i think there is a json-based manifest thing too
but maybe this is just the easiest for private hosting
maybe
I always underestimate how long it takes for github actions to upload docker images

https://peps.python.org/pep-0503/
https://peps.python.org/pep-0592/
https://peps.python.org/pep-0629/
https://peps.python.org/pep-0658/
Python Enhancement Proposals (PEPs)
Python Enhancement Proposals (PEPs)
Python Enhancement Proposals (PEPs)
Python Enhancement Proposals (PEPs)
this is why need autoindex (from 503):
Within a repository, the root URL (
/for this PEP which represents the base URL) MUST be a valid HTML5 page with a single anchor element per project in the repository. The text of the anchor tag MUST be the name of the project and the href attribute MUST link to the URL for that particular project
<!DOCTYPE html>
<html>
<body>
<a href="/frob/">frob</a>
<a href="/spamspamspam/">spamspamspam</a>
</body>
</html>
e.g. if you go to https://pypi.org/simple/ you see exactly that: a huge pile of a links
idk why they choose an under-specified, non-streamable format like html
but i guess what's done is done
i dont know why this couldn't literally be 2 tab-separated columns, one line per link
might've sounded like a good idea then

or spaces for that matter, since spaces arent allowed in names
it would have been a bad idea in 2015 too. i bet the real reason is buried in the mailing lists and probably has to do with some kind of backward compatibility
frob /frob
spamspamspam /spamspamspam
🤷♂️
probably designed based on the autoindex from apache or something
or twistd
i guess it was also to be able to theoretically support additional flags/options
e.g. 592 lets you add the data-yanked attribute to the link
and <meta name="pypi:repository-version" content="1.0"> as per 629
can't seem to figure out the right URLs to proxy or configure to --index-url or something
ah
no
I think this is just nginx having stupid https proxying by default, need to remember what that magical spell was to fix that
proxy_ssl_server_name on;
what does that do? it passes the original server name along and breaks https on your own domain?
allows SSL negotiation with "Server Name Indication"
basically initially SSL worked so it was always bound to an IP, and you just had one SSL domain served by one IP .. turns out that's a bad idea in the modern day, so they extended it with "SNI" that allows the client to say which host it wants to talk to before the SSL certificate is determined
neat

ok we're going
had to set PIP_INDEX_URL=http://pipeline-agent-11400:3141/simple for this proxy to work but now it's going
54s first install without cache
also 0 errors vs 3 crashes on devpi
45s on 2nd run .. eh, still not great .. wonder if I could optimize nginx a bit here
gzip is probably bad for packages
wait, that's off by default??
yeah, nginx proxying is kinda dumb at times
I've run into this wall like 5 times in the past year or two
it thought it was something like "tell the client that my server name is the proxied server name"
so this has to do with when it sends proxied requests?
yeah
Enables or disables passing of the server name through TLS Server Name Indication extension (SNI, RFC 6066) when establishing a connection with the proxied HTTPS server.
not exactly a helpful description
I have to tell Nginx to play nicely with the upstream server when connecting to it
when establishing a connection with the proxied HTTPS server.
i guess you're meant to take this to mean "when making outgoing proxy requests"
it didn't work with --index-url?
and yeah gzip is probably bad because wheels are zip files and source packages are tarballs
oh it's just the same but environment variable vs arg
so you're double gzipping
gzip_types application/json text/css text/javascript; looks like they accounted for this however
oh right yeah I've got that as well
does nginx unzip and then re-zip proxied files? or will it pass along compressed files verbatim?
afaik it shouldn't care about the contents of the proxied stream except for headers which it mangles to some extent
to fix redirects etc.
hmm
https://stackoverflow.com/a/33448739/2954547
https://docs.nginx.com/nginx/admin-guide/web-server/compression/

Stack Overflow
The gzip_proxied directive allows for the following options (non-exhaustive):
expired
enables compression if a response header includes the “Expires” field with a value that disables cachin...
Compress server responses, or decompress them for clients that don't support compression, to improve delivery speed and reduce overhead on the server.
you have to manually opt in to http2 on nginx right?
yeah, and I think it'll give me pain due to ssl requirement
i dont know how ssl and http2 interact, i never bothered with http2 on my personal hosted stuff (due to low volume)
http2 requires ssl
afaik there's no way to run http2 without ssl, except in weird non-http2 proxy modes that are only supported by special software
you don't want to use ssl between your server and the client using pip?
it doesn't have a public domain name
i.e. I can't get an SSL cert that is actually valid without hacks
which is something I really dislike about the design of SSL
oh i see
yeah that is really annoying too
e.g. i dont actually need or want a domain name on my personal hosted services, but i still want encryption and i want to make sure that the server at my ip address is actually my server
yeap
im actually kind of surprised that's still an issue in 2022
SSL with IP / local domain is a pain
"just make a new root certificate and install it on every physical machine, vm, docker image, etc."
"just" 🤣
btw I was pretty shocked when I realized SSL to 1.1.1.1 works
it looks like some root ca's do offer such certs
I had never before seen SSL certificates issued to an IP
but probably not for private networks anyway

Let's Encrypt Community Support
It is possible to purchase certificates for IP addresses, but not from Let’s Encrypt. Let’s Encrypt may offer IP address certificates in the future, but as of September 2018 we do not.
is there a ca-in-a-box program out there that you can use to quickly set up your own internal ca?
well, setting up your own internal CA is relatively easy, it's the registering it as valid to every machine that is the hard part
right
on linux it seems easy enough, but if you have a lot of machines it could be a devops headache right?

The open-source step-ca project provides the infrastructure, automations, and workflows to securely operate a private certificate authority.
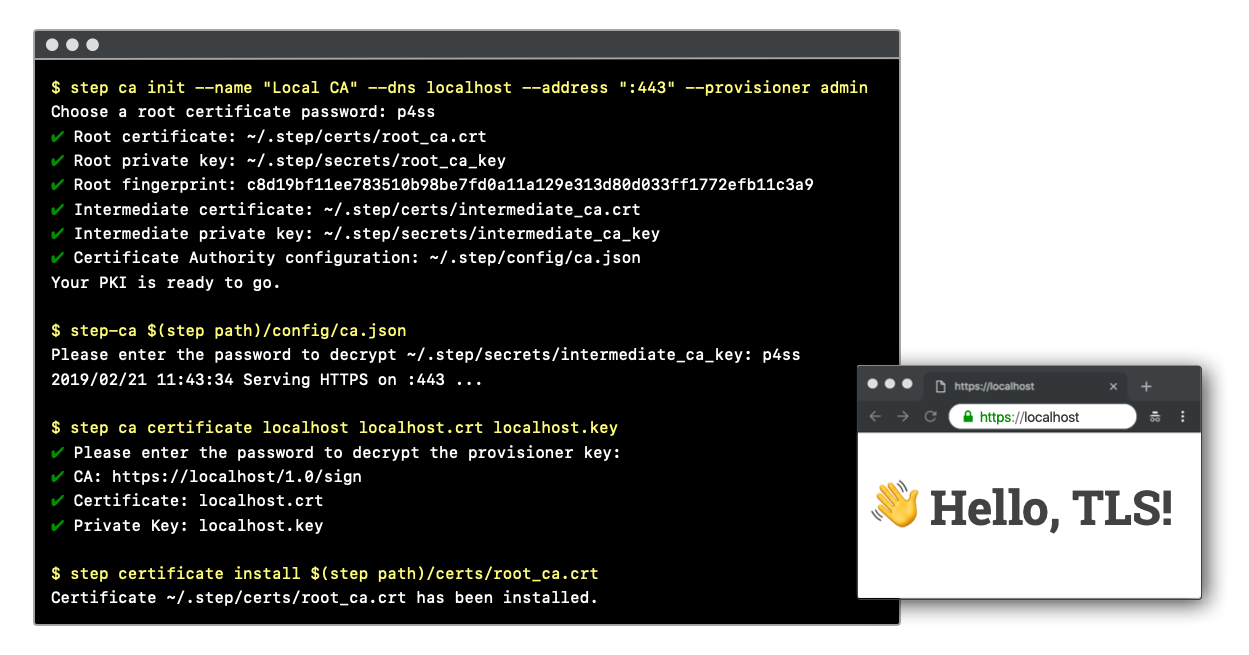
GitHub
🛡️ A private certificate authority (X.509 & SSH) & ACME server for secure automated certificate management, so you can use TLS everywhere & SSO for SSH. - GitHub - smallstep...
yeah, doing it on one machine once is easy
doing it on every machine, every vm, every docker image, every time you build something, without messing with the systems so that things start breaking on your fellow devs' machines, etc.
... that's the hard part
i think what some orgs do is they have a standard container base image that they use, w/ stuff like this pre-installed
I wish there was some DHCP flags you could configure to tell your whole network that 192.168.1.1/ca.crt is valid in your network or something
yeah and then random companies ship root certificates to make your computers vulnerable to hackers, like at worst case iirc some USB powered headphones had that going for them
but then dont you have a chicken/egg problem where you might want to check the validity of the ca rot certificate?
anyway self-signed SSL cert running with http2 I think
wonder what kind of errors I'll get next
well so much for my project! nginx is too good
welp, my build server just died
or something


not responding anymore
that sure is something
thats a new one to me
I guess time to go take a look at it in the other room, brb
literally hard locked up .. had a terminal open with htop on the physical console, it has frozen and accepts no input
No oom messages on the console
Just ded, ctrl+alt+Fx, and ctrl+alt+del did nothing too
so I intentionally left a terminal open there so if there would be errors they should be printed on the screen
panics, ooms, etc. should be broadcast there
unless linux has degraded in that respect as well in the last few years
it HAS been some time since I actually last ran bare metal linux servers
but yeah, ok .. now it's up again
ive never seen a headless linux installation break that badly before
bare metal linux is fun, particularly desktop
this is not a desktop tho, so I expected it to be more stable
argh
installed Ubuntu Server
check lsmod
find audio drivers, wifi, all kinds of stuff everywhere
136 modules loaded
13 of them sound related
bluetooth drivers are probably important for a server
drm support as well
gotta have the server ready to watch netflix
joydev
I guess "server" has lost all meaning to ubuntu
probably just means "doesn't autostart X"
now curl --insecure --http2 https://pipeline-agent-11400:3141 works at least
ah, good stuff PIP_TRUSTED_HOST also ignores SSL errors
58s

slower
maybe the cache wasn't properly saved between reboots
🤞
53s
how is HTTP2 even slower?
based on the filesystem it's only like 90-ish files that have been cached and 7.5MB so this should be like super easy
disappointing
now that I know the working configuration I might have to try that on bare metal as well
probably more I can do to tweak nginx, increase buffer sizes or something, enable session caches, whatever .. will try that tomorrow I guess
thanks for the chat, got good ideas out of it, I'll need to get some sleep now
the thing is that with essentially 0 latency and going from 500Mbit internet connection to servers with likely less than 500Mbit capacity to me to again localhost bandwidth I would expect to see some performance increase .. even when the total size is like 88 files and 7.5MB
so likely just gotta tweak nginx further
and this is why i use not-ubuntu 😆
for a server i either use the debian minimal netinstall, or void linux. freebsd has been on my todo list for forever but i've never tried it
could anyone please direct me to a good packaging tutorial using setup.cfg (not setup.py)? or any github repositories that use it which i can use as an example/template?
This is what I used
https://github.com/audreyfeldroy/cookiecutter-pypackage

GitHub
Cookiecutter template for a Python package. Contribute to audreyfeldroy/cookiecutter-pypackage development by creating an account on GitHub.
oo thank you
hey so i already have a significant part of the package written, and only need to write the setup.cfg. if i do the cookiecutter thing, will it replace everything?
Cookiecutter creates a folder with ready to go files based on your inputs. You can then copy your files into this overwriting existing basefiles
After that first try uploading the package to testpypi and installing from there just to make sure everything works correctly
gotcha, thanks
so after looking at the logs and digging into this, it seems poetry doesn't actually respect PIP_INDEX_URL for everything, it ONLY looks up the available versions there, and then continues to download the packages separately .. and it seems there is no easy way to configure that
it SEEMS they say something like I would have to configure poetry config repositories.cache http://cache.server/simple/ .. but that by itself does nothing
then they say to modify pyproject.toml to have
[[tool.poetry.source]]
name = "cache"
url = "https://cache.server/simple/"
default = true
which disables pypi completely, meaning I can't commit this to the version control as it will break other peoples' setups, and so I can't use it locally, but I could I guess use it in docker images
but even for docker images it's kinda not great
and that probably breaks poetry.lock
oh, it might also be that I fucked up the cache proxy
just noticed that one thing that was wrong was that the links returned for the packages were still pointing to files.pythonhosted.org
so I was only caching the package version index
oh yes, now I get requests to /packages/ in my access log as well
so indeed seems PIP_INDEX_URL was all required to get poetry as well to play nice, which is a relief
the performance of my nginx proxy cache is still worse
ah
it's returning 301s
mjea, lots of little issues in the configuration, the pypi infrastructure has clearly changed since the last time someone has written one of these
now it's just a question of performance .. first request is from pypi, next 3 from cache, not a lot faster

oh
that was caused by dumping results to terminal
piping to something else made it a lot faster
ok now it actually is a speedup


package caching should work too

the configuration is definitely more complex than I wanted, but .. this does seem to work and cache packages https://github.com/lietu/docker-images/blob/master/pypi-cache/pypi-cache/site.conf .. I've not yet benchmarked this much tho

GitHub
Automatic docker image build and release system. Contribute to lietu/docker-images development by creating an account on GitHub.
and to use all the caching I'm doing in Dockerfile
ARG PIP_INDEX_OVERRIDE=""
RUN --mount=type=cache,target=/home/${USER}/.cache \
set -exu \
&& if [ ! -z "${PIP_INDEX_OVERRIDE}" ]; then \
export PIP_INDEX_URL="${PIP_INDEX_OVERRIDE}"; \
export PIP_TRUSTED_HOST="$(echo ${PIP_INDEX_OVERRIDE} | awk -F '://' '{ print $2 }' | cut -d: -f1)"; \
fi \
&& poetry install
and running with docker build --build-arg PIP_INDEX_OVERRIDE=http://pypi-cache-host:3141/simple
so it's optionally used for build machine when the pipelines are configured to include this arg
pnpm / npm caching was the easiest so far really
set up a verdaccio container with
docker rm -f verdaccio
docker run -d \
--name verdaccio \
-p 4873:4873 \
-v /cache/verdaccio:/verdaccio \
-v /cache/verdaccio/storage:/verdaccio/storage \
-e VERDACCIO_PUBLIC_URL=http://build-cache-host:4873 \
verdaccio/verdaccio
docker update --restart unless-stopped verdaccio
then just have to pass the URL again via build machine to Docker and then run pnpm config set registry http://build-cache-host:4873
apt is still the most convoluted, where I set up apt-cacher-ng, configuring it as a HTTP proxy for APT, then configuring every HTTPS backend separately with some rewrite rules on the apt-cacher-ng side, and then replacing all https:// with http:// in /etc/apt/sources.list{.d/*} .. and it will cause crashes any time I add a new HTTPS -based APT repository before adding it to the proxy's rewrite configuration

Amazon Web Services
Organizations are adopting microservices architectures to build resilient and scalable applications using AWS Lambda. These applications are composed of multiple serverless functions that implement the business logic. Each function is mapped to API endpoints, methods, and resources using services such as Amazon API Gateway and Application Load B...
I typically use a gui version of git, anyone well versed with command line git?
Just ask your question(s), then we'll see
I too am having some frustration with git. Its my first time using it, and its not working the way I've been told it works
Can you be more specific?
Sorry! I asked another person in a different channel and they let me know that my filename, because it has a space and a ' in it, was telling git bash something different than what I thought
git bash was expecting more arguments cus my filename is Durin's Bane
Thank you though!
Im making a gui for git. Is this enough git to be useful for a single person project?

I'm getting this error when using github actions


I need help dockerizing a django project with gunicorn and nginx?
it's often a good idea to carefully and with thought read through the error messages .. this doesn't seem to have anything to do with GitHub Actions as such, but simply the fact that for some reason your pyproject.toml specifies a strict python version it's compatible with, which does not include the available python version - typically you want a >= or similar in there but I'm sure poetry's docs explain that in more detail

it's easier to help people when you state the exact problem you're having
Well , I built a web app for my college club and I need to deploy the django app on my uni server.I'm a complete beginner when it comes to docker , gunicorn and nginx deployment.I need the bare minimum configuration file to deploy the web app

My .toml file looks okay I think
interesting, this should be fine
assuming it's actually the current state of the file being used by that action in your repo
I generally don't use random peoples' random actions on GH because I have no trust in them and I don't like semi-opaque things in general that make it harder to see what's up when there's an error .. I just use plain bash scripts in GH actions
either way, I'd recommend
-
you check that is the state of the file in the branch of the repo that the action is being run on
-
you check that there are no other files in the repo that that action might be accidentally using
-
maybe add
python --versionandcat pyproject.tomlin a bash script on your action to verify everything looks fine
also if you don't actually use the matrix you could just set it to use python 3.9 as the version it installs
Thank you for your help. Still getting the same error
so did you try any of those 4 things?
im not surprised that APT is super complicated. thanks for sharing the pypi caching code!
it looks like the project requires 3.9 but you only have 3.10 installed
like why use a version matrix in ci if you lock your project to one version? of course it will fail
what is the best extensions for python in vscode
What’s a good base level knowledge of git.
Being able to create a new repository, commit and push changes, pull changes, resolve merge conflicts, and create/switch branches.
So this list is good enough @tawny temple
Maybe. Depends on who's using it.
For me it's missing adding remotes (e.g. adding an upstream for a fork), stash management, and rebasing (especially interactive rebasing).
And possibly other stuff I forget
But people might be able to get by without those things.
I'm mostly happy with the git CLI though so I stick with that
Im just making this to showcase understanding git and creating a gui to add as a resume project. It is called just enough git lol. I have decided though to add helpful explinations to the terminal for example heres the explination for the init code block
os.system('cls' if os.name == 'nt' else 'clear')
print('The following line of code will initialize the selected folder as the parent folder \ your project. Your folder should be named after your project')
('The follow command will be ran: git init', end='\n'*2)
.system('git init')
('')
('Current working Dicrectory')
os.system('cd' if os.name == 'nt' else 'pwd')```Those who use both pre-commit and mypy, do you tend to use mypy with pre-commit, or do you use it separately? Pre-commit will manage it's own env - which means that some stuff mypy might want access to within a project won't be there.
I'm just curious around best/common practice, I don't have an error to reproduce.
you are talking about some framework for pre-commit hooks? because imo the isolated venv thing doesn't make sense for running mypy, as you stated
pre-commit is the framework for running pre-commit hooks, no?
🤷 confusing tool name
and yeah - but i saw this https://github.com/pre-commit/mirrors-mypy , and was wondering whether this was what most people used
do you need to use an isolated venv? i would suggest just having the hook invoke make typecheck and then write your makefile to run mypy however you need
well idk if i'd use make
or use a python script to invoke mypy with subprocess etc
but yeah i can write a custom hook for it
yeah, my point is that you should wrap your mypy invocation in some tidy script that doesn't require you to copy all of the options, and then you can invoke it from multiple places: precommit, ci runner, as needed on your local machine, etc
sure, yeh makes sense - i just saw the mirror and it got me wondering
I saw this the other day actually : https://github.com/OpenBB-finance/OpenBBTerminal/blob/main/custom_pre_commit/check_config_terminal.py#L24 , and was wondering how people typically ensured that env vars were consistent / set across systems
custom_pre_commit/check_config_terminal.py line 24
settings = {```inside the python application itself i check and raise an exception if one is missing
hm fair - rather than having them all in one place? I guess it makes sense if you don't have a mess of a mono repo as well
running everything in docker compose avoids the issue of forcing each developer to install and configure some tool to keep environment variables set up correctly
but for that purpose i use direnv if I'm not working in docker/podman
no, i do keep them all in one "env" file
running everything in docker compose
so if you're developingscript.pylocally ,you wouldn't usepython -m script?
personally i would because i use direnv
I like the idea of using docker, have some R deps and things which are annoying, so being able to just replace Rscript with a docker thing would be good i think
but other developers i work with don't, so they do make run which invokes docker compose w/ the code bind-mounted
never really got the workflow down tho
feel free to @ me in the dsci server and i can show you more detail, since you are asking about R
i'm also not at a computer yet
no worries, cheers 🙂
i touched make ages ago and it was kinda quirky - dvc repro has served that purpose for us i guess... tho perhaps for some build stuff make still makes more sense 🤔
yeah and in this case you don't need the reproducibility. the point is that you just wrap it up in a script if it's non-trivial
eg mypy -p pkg1 -m main scripts/*.py
and of course use mypy.ini or pyproject.toml
so you put this into scripts/run-mypy.sh:
#!/bin/sh
exec mypy -p pkg1 -m main scripts/*.py
and your precommit hook just does ./scripts/run-mypy
i have my mypy settings in setup.cfg 🤔
or even symlink the run-mypy script into the hook directory
never sure where i'm meant to put things sometimes, that seems to work tho
i didn't realize that was even supported, in my opinion that's a weird conflation of functionality
how so
i guess there's nothing wrong with it
personally i like keeping setuptools separate from my "project" configuration
i forget that setup.cfg is meant to be a nicer way to write setuptools tbh
Is there any way to implement hardware acceleration into your python script? Especially if it has 2D Graphics like with PyGame or PyQt5.
guys i want to check a python file version so i can install its packages how can i do it ?
tag me if you can answer me
Does anyone happen to know what's causing this when i do python3 -m build? I'm not sure where the mistake is so i don't really know what other info i can provide, so lmk if there's any other info required

(Just a blank guess)
you have
if main = __main__
?
Maybe got wrong on that. Mind failung
Does anyone know of a tool that tracks updates to packages?
i.e. package X releases new version, it notifies you via email/slack/discord etc
hmm yeah I can see that you could achieve this via a ruby script using their core code, shame there is nothing out of the box. Maybe it is a fun Ruby project to do then
is gistspy your own package? it looks like you have a bug in requirements.py on line 81. perhaps you are passing the wrong value to this lambda
tracebacks are not mysterious arcane runes to be handed to the oracle and wondered at, they are human-readable text that are meant to direct you to the source of the error
i actually figured it out, but thank you. the issue was that, my pyparsing version was 3.0.5 which apparently had this bug, so upgrading it fixed the issue 😄
ok, good to know!
and yes gistspy indeed is my own package 
When did pip get cool coloured output

Do i need to upload to pypi/github to test my package everytime 
what are you doing that requires you to upload to pypi
Wait wrong server my bad
It's a package that i uploaded to pypi and was asking if i needed to push there everytime i wanted to test it before actually publishing but ig that's a stupid question because i could just push to github and install from there to test it
Wrong server because this wouldn't be an issue if i wasn't using replit
you could also install locally from your own directory
make a venv in a separate directory and pip install /path/to/your/project
or pip install git+file:///path/to/your/project if you want (yes, git remotes can be on your local system)
thanks for the suggestions, but this wont work in my case since im using replit, but i was able to figure out a workaround with someone's help in the replit server
🤞
it's a bit hackey but it's the best i got
also i did not know this, thanks!
quick question tho. if i do this, will i need to run pip install --upgrade /path/to/your/project everytime i update? or can i do something like pip install --upgrade pkg_name
the former, pip doesn't keep track of where the package came from in that way
alright got it, thanks. better make that an alias 
you could also just not use repl.it 😉
i wouldn't want to develop a whole project in there. i just used it for sharing runnable snippets
im on mobile so that's the best option I've got (tried every mobile ide, none of them is good enough/as good as replit) 
Any ideas how I can fix this import?

Hello, I need some help connecting to a PostgreSQL database hosted on google cloud, my FastAPI project uses sqlalchemy as the ORM. When I view the details of the database instance it gives me 2 IP addresses Public IP address and an Outgoing IP address, what IP address should I use when connecting?
this situation happens all the time, I have some git repo, I commit something, but it turns out I forgot to pull something from the remote (like a workflow updates or something pushes something), and so I need to merge it now... usually at this point git pull --ff-only will fail. but if I had done git pull --ff-only before committing, git wouldn't of needed to do the merge commit. I find I delete the entire repo and readd the change if it's small so I don't have a pointless merge commit
... is there a better way, it seems weird to me git cant figure out how to fast forward in this scenario
I typically go with git pull --rebase to re-apply my local changes on top of the latest
that sounds like a good idea actually
you would have to git push --force-with-lease afterwards, though
i am a fan of rebasing, but rebase conflict resolution can really hurt your brain if you aren't very familiar with the commit contents
What's your typical solution for storing venvs specifically related to subsets of a project that you're planning to use again?
Venv directory with everything stored there?
do you have multiple envs per project? whenever i have that, it tends to be scoped to a directory, so i keep the venv in that directory
Can someone explains for me how would docker and github actions work together
Docker is a container system that wraps around Linux concepts to run applications in isolated jails, they get their own filesystem, resource limits and process trees
GitHub Actions is a CI/CD platform which runs predefined scripts on your source code whenever you make modifications
Tying them together, you're likely to see GitHub Actions used to build a new Docker image when code modifications are made, and then push that to an external server running Docker where it will be pulled and ran to seamlessly provide updates to code
so it acts like a docker-compose.yaml file right?
Not really, no
It's a set of stages
So you will have a list of steps inside the action which might be like:
- Download the source code
- Install dependencies
- Run linters and tests to check the code is okay
- Build Docker image
- Ship Docker image to production
Docker Compose is a different thing, that is a way of defining which applications you want running in Docker and provides a helping hand to get networking and whatnot with them nicer
Dockerfile is the file that defines what should be in a Docker image
again it's stages, so it'll be like:
- copy source code in
- install dependencies
- start application
yes but the list of steps you defined earlier is in github actions?
So you will have a list of steps inside the action which might be like:
- Download the source code
- Install dependencies
- Run linters and tests to check the code is okay
- Build Docker image
- Ship Docker image to production
I wonder whats the difference
soooo
github actions is a list of things to run on every code modification
which is why things like tests are in there
you don't want tests running when you start your app
the dockerfile defines a list of stages which are ran to prepare the docker image which contains all the files necessary for the application to run
👍
@rich remnant ty for the thorough comments on your nginx conf by the way
it's so hard to remember what all the nginx options do (and even if you read the docs, their purpose isn't always evident)
oh yeah, I've taken a habit of commenting stuff like that for that exact reason
I don't - storing venvs is typically not a great idea, I just use poetry to manage them
Hey I'm looking for Python developers who are interested in alpha testing a new open-source platform about to be released
Hope this is the right forum to ask - but basically anyone who is interested in new innovative stuff
Prerequisites is using vsCode as we'll only support Pycharm next month
The platform is a an IDE extension and is a productivity tool for developers
do you have link to the source code to look at?
Hey @mystic void we've only released the client side of the source code so far but will release the server side as well soon (tidying up the repo) https://github.com/digma-ai/digma
GitHub
🧑💻🔭 Digma makes observability data relevant when writing code. Digma continously analyzes logs and traces from OpenTelemetry and other sources to automatically glean insights on how your code ru...
nice! and interesting! Thanks for sharing!
Thanks! We're extremely excited about it (we're a very small team) and definitely looking for people to try it before the beta release
Hi, is this the right channel to ask about bitbucket pipelines? The problem I am trying to solve is really long build times for our repo due to us including wxPython. I am wondering if there is a way we can cache that build info so that we dont have to compile it from source on every pipeline fun
@turbid bramble i don't have an answer, but this is a good channel for that
Great, thanks. For some more information, we do have this part in our yaml, but it does not seem to do the trick.
default:
- step:
caches:
- pip
Anybody familier with AWS?
i need resources to ace AWS
I'd recommend checking out https://explore.skillbuilder.aws/learn
Your learning center to build in-demand cloud skills.
you do not have to delete the file. however you do need to pull down the other branch first and reconcile the changes locally by merging
git switch branch1
git fetch other-remote
git merge other-remote/branch2
# fix merge conflicts here, if any
git push other-remote branch2
Thank you so much, there is no need to delete the file as you said:
- Merge and solve conflicts
- Push
I added--no-ffto merge command in order to create a commit. Just personal preference, maybe I should stick to fast forward merge instead?
i use --no-ff when i specifically want the merge to be visible in history
so yeah it's just your preference
i personally like to see fewer merge commits, so i prefer fastforward merges when it makes sense to do so. but if i am merging from some "extra" repo, then i might want to keep that commit visible i history
I see, thank you so much for your help, I really appreciate it
if you want to see fewer commits, keep doing --no-ff. But instead, when you are browsing the log, use --first-parent.
that gets you the best of both worlds
Sure btw I have some questions
Could u pls answer?
Hi, i'm having an issues with setuptools failing to run bdist and bdist_wheel
https://vicky.rs/ss/20:36:51_13-04-2022.png
it's so far failed on 3.7 and 3.8 with the same error, but it's fine on 3.10
to reproduce, i'm using cross compilation on the docker image messense/manylinux2014-cross:armv7l, but i think cross compilation has nothing to do with this.
Source code: https://github.com/vicky5124/lavasnek_rs/
# To reproduce:
# get rust
curl https://sh.rustup.rs -sSf | sh -s -- --target armv7-unknown-linux-gnueabihf stable -y
source $HOME/.cargo/env
# get pip
curl -sS https://bootstrap.pypa.io/get-pip.py | python3.8
# setup cross
python3.8 -m pip install 'crossenv>=1.1.2'
python3.8 -m crossenv /opt/python/cp38-cp38/bin/python3 --cc $TARGET_CC --cxx $TARGET_CXX --sysroot $TARGET_SYSROOT --env LIBRARY_PATH= .venv
source .venv/bin/activate
# setup deps
pip install -U pip wheel setuptools-rust setuptools
export PYO3_CROSS_LIB_DIR="$PWD/.venv/lib"
# build wheel
python setup.py bdist_wheel --dist-dir ./dist/
anyone has any idea on how to fix this? i can't find anyone with the same issue providing a solution online.
(ping me :D)

How can I change git to allow me to edit commits in notepad? I need to essentially automate the git commit command.
i actually didn't know about this feature, it will be very useful when browsing merge-heavy repos. thanks!
you can do git commit -m "..." to provide a message on the command line, does that help? otherwise you can change the EDITOR environment variable
actually you can use GIT_EDITOR, VISUAL, or EDITOR (in that order of fallback). see git-var(1) for details on these env vars
what environment are you running this in? googling the last error suggests it might have something to do with pip version or similar
the docker image is based on ubuntu 20.04
pip is installed from get-pip.py
curl -sS https://bootstrap.pypa.io/get-pip.py | python3.8
and updated by itself
pip install -U pip wheel setuptools-rust setuptools
i sent the command list used to reproduce, and there you can see it installs the latest pip
My goal was to pass a commit from tkinter text widget (for git commit, for git commit -m I can use widget.get() and build the subprocess.getoutput() line)
I guess I’ll just instruct the user to do it from terminal and ensure their default editor is nano.
honestly can't really find anything useful on the error, looks as if you're building for armv7 so I guess one option is that the arm packages for something in the build chain are not up-to-date .. that happens annoyingly often for arm
happens on armv7, aarch64, ppc64, s390x and x86_64
so not that then
it's setuptools as well, i doubt it's out of date
honestly if I were you I'd probably start digging through the source on that stack trace and figure out why it is attempting to call that code, and what the Distribution object is, where does it come from, check the version history for the file, and stuff like that
if it is missing a property the code expects to be there either
- the code is calling it on mistake and you might find out why
- there might be a change somewhere in the file's version control history that explains more about what's going on
i've already done this, and the line that errors is nowhere to be seen
Version: 62.1.0 is what pip says i have installed
the traceback shows
File "/repo/.venv/build/lib/python3.8/site-packages/setuptools/command/build_py.py", line 53, in run
self.build_package_data()
File "/repo/.venv/build/lib/python3.8/site-packages/setuptools/command/build_py.py", line 126, in build_package_data
srcfile in self.distribution.convert_2to3_doctests):
https://github.com/pypa/setuptools/blob/v62.1.0/setuptools/command/build_py.py
but neither of those lines are like that in the source

GitHub
Official project repository for the Setuptools build system - setuptools/build_py.py at v62.1.0 · pypa/setuptools
https://github.com/pypa/setuptools/pull/2721 this person determined with a somewhat similar looking issue that they had multiple versions of setuptools installed
GitHub
Small patch to fix this error:
File "/usr/local/lib/python3.6/dist-packages/setuptools/command/build_py.py", line 56, in run
self.build_package_data()
File "/usr/local/lib/py...
well, i'm removing the venv every time i do this
https://vicky.rs/ss/22:52:08_13-04-2022.png
and indeed there's only 1 version installed

maybe if you look into the filesystem you can see what is the exact contents of that file, and maybe some commit hashes or similar near it in the tree
maybe it's 44.0.0 as shown in the dist info folder
seems you have a version older than this https://github.com/pypa/setuptools/commit/ca296ca8663a376f3c36c9f8fd86b10ba81366c2#diff-8055b82a058bbf8bd5c5563d909e425059dc6a1c8417ad78d6f64479f834e71bL126-L128

setuptools/command/build_py.py line 126
srcfile in self.distribution.convert_2to3_doctests):```why is pip installing that
pip 20.0.2 looks old as well
maybe not
it is what I have
though it's quite possible mine is old too
mjea my build machine has 22.0.4
but that might not be related

maybe that build folder is not the right thing to look at
looks like your environment is somehow messy
I haven't really used virtualenv for ages, switched to poetry and pipenv years ago so I don't really even know how normal virtualenv looks like anymore
poetry has it's own whole bag of issues

well it was a shot in the dark
what I find strange is the build/lib/python3.8 vs cross/lib/python3.8
why does one command use the other, and the other the other
the venv outside the container doesn't use .venv/build
idk what's going on
different architectures, the container is meant for cross compilation
well it seems like you're running 3 commands one after the other with python3 -m pip and one says it looked in build the other looked in cross
anyway, it seems like however you set up the build and cross that's your issue - you have somehow 2 different versions of stuff installed, and that's causing breakages
one probably has pip 20.0.2 + setuptools 44.0.0 and the other pip 22.0.4 and setuptools 62.1.0
brand new venv, nothing installed has /build with stuff
anyway I need my beauty sleep, good luck 👍
aha, found the solution
source .venv/build/bin/activate instead of source .venv/bin/activate
the latter activates cross, but python looks at build
good night, thanks for the help!
or not, that made an x86 build on arm
just checked one last time and actually have one more idea
maybe that source should be .venv/cross/bin/activate or maybe that PYO3_CROSS_LIB_DIR should be in cross, or similar - i.e. maybe your paths are not correct in every step .. I haven't set up an environment like that so I don't know what they should be, but this could explain the issue as well
.venv/bin/activate is ```
. /repo/.venv/cross/bin/activate
export PATH=/repo/.venv/bin:$PATH
so it already does crosshttps://github.com/messense/manylinux-cross/issues/5#issuecomment-1098560931
just so it's documented somewhere, here's the fix for the issue i was having

GitHub
I'm having an issue with setuptools failing to run bdist and bdist_wheel It's so far failed on 3.7 and 3.8 with the same error, but it's fine on 3.10 and 3.9 To reproduce, I...
hey anyone working on windows apps has used the embeddable python thing from Python.org?
I kinda wanna use it but I keep getting big files because I dunno how to add more libraries but keep it compressed
I need numpy etc.
the embeddable comes with a python3X.pth and .zip files, and i guess i should find a way to compress the numpy (other packages) stuff in there
dunno how to. stuff in there is in the .pyc format btw
I have a postgresql database on google cloud and multiple users want to connect to it (they are using sqlalchemy). can you link a good and clear guide on doing that because I don't understand a thing in the google cloud documentation
what will be the database uri of the database??
i went and whitelisted my ip but now I cannot figure out the uri
Has anyone had problems with GitHub Actions in the past 48 hours? In particular, my Pytest workflow's status badge says no status, and the workflow run filter box does not work.




is there a way to python3 -m build my package but only certain parts of it, like git add?
That kinda a suggests your package needs to be broken up into multiple ones.
can someone help me how to create notification desktop
I used win10toast to that effect.
Day 2 of this issue. Is this affecting anyone else?
Looking for someone that's very experienced with python. I want to make a live logging on my google sheet that updates simultaneously. Send me a DM pls
i am making a program which will join a meeting in teams but the problem where i got stuck is that:
how would i know that microsoft teams is opened correctly means it is no more loading ? (as my pc is not so fast)
i tried using wmi module in python but it would tell me only that process is running but that's not sufficient since teams is heavy application and takes several minutes to open in my pc.
also i can't do sleep() since it's not always absolute that teams would always takes exact same time.
ping while answering me!
I'm trying to use https://download.qt.io/official_releases/QtForPython/split-wheels/ as an index url for installing through poetry, doing it through an another source.
It got the basic information of the package correctly in the lock file, but no files were locked so on install it does nothing, am I missing something here?
I guess it expects a conforming pypi-like page? Is there no alternative could use?
wrote about some debugging and profiling tools that work with async ootb: https://uriv.medium.com/debugging-and-profiling-sync-async-python-code-13b1696ca82a
hope it's of use

Medium
gamla is a functional programming library for python.
poor snakie.

Hi guy, Please does anyone knows how to retrieve Facebook account? Someone else is currently using my account and deleted my info. Thanks
You should contact facebook support. That's your best chance
Question about pip and wheel (python 3.9.10):
pip complains that its using legacy setup.py install since wheel is not installed.
What is the best practice here for python codebases that use venvs and requirements.txt?
- Should the requirements.txt include wheel as a dep?
- Should I pip install wheel before creating the venv?
- Just ignore the message?
Would be interested in the answer here too. What I am currently doing is ignoring the message and letting pip install using the setup.py files. If that fails, I then pip install wheel
It ever failed? I thought that the wheel-way is just doing that, but then also packaging into a wheel
wheel is a packaging format for Python packages. so if you have the wheel package installed and the package you're installing has a compatible wheel, it will install the package from that wheel. otherwise, it will build the package locally using setup.py (which may not work, if you don't have the prerequisites for building that package)
It has failed before, yes. Probably just a better idea to have wheel in requirements
i need help uninstalling python3 off of my computer.
it wont let me talk in a vc cuzz i just joined the server tho
what os does the computer run that you want to uninstall python3 from?
macOS Monterey v12.3.1
I'm not sure if this is the right channel for this question. Is there anyone here well-versed in GnuPG?
It is specifically related to package and git commit signing. Small company, but we need to start implementing standards and safeguards for when we grow. Is there a best practice for this? IE: Making a primary key that doesn't expire and issuing subkeys that do?
Sorry for disturbing you, but I went on vacation and I couldn't execute those commands before. Now I've done it and I get:
fatal: refusing to merge unrelated histories when I execute git merge --no-ff other-remote/branch2. Shall I add --allow-unrelated-histories flag to merge command like so?
git merge --no-ff other-remote/branch2 --allow-unrelated-histories
Thank you in advance
I did that and it worked
it sounds like you ended up somehow with 2 totally different roots. this can happen if you try to merge 2 "unrelated" repos, e.g. you started the same project and are now trying to combine the work from both. but note that this can also happen after some really funky operations involving removing or detaching your commit history from the root commit. you can do --allow-unrelated-histories, but you should check the diff very very thoroughly to make sure you are merging what you think you are merging
I'm using Visual Studio Code to make my Python programs. Right now, I'm studying Python.
does anyone remember what the cli framework was that used type hints to do argument/flag validation?
or is that something i invented in my imagination?
maybe i was just thinking of Fire (which as far as i know does not do any validation)
i love macros:
(defmacro try-import [module]
`(try
(import ~module)
(except [ImportError]
(die 1 ~f"{module} is not available, exiting."))))
(try-import nbformat)
(try-import nbclient)
(try-import click)
compare to the version without a macro...
(try
(import nbformat)
(except [ImportError]
(die 1 "nbformat is not available, exiting.")))
(try
(import nbclient [NotebookClient])
(except [ImportError]
(die 1 "nbclient is not available, exiting.")))
(try
(import click)
(except [ImportError]
(die 1 "click is not available, exiting.")))
the generated python code is totally readable too
Hi Guys. I'm 19, in UNI and I have been given a task to create a survey with 3 content pages and 10 questions proceeding those content pages. Since I have little coding experience, so I was looking for some help
why not using google forms?
its part of basics in python
we just started a new unit
after this is c++
so this is sort of a small task
part of our final
so what's the hold up?
cant figure out how to go from one page to the other
i have the json file
and the questions are mainly ready
it may help to describe further your problem and how you display each page.
For instance, there is a huge difference between a web page and a desktop app (and other)
Hey @shy skiff!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
this is a code i found online which helped me out. I got how to go through the questions and how to display them. The 3 content pages are whats causing me problem. I can't figure out how to go through them and then start the quiz.
https://paste.pythondiscord.com/pokepaxulo
sorry, I haven't done any tkinter in years.
It's also unrelated to #tools-and-devops .
You may want to check #❓|how-to-get-help to increase your odds of help
oh ok
I'm currently using typer, idk if that's what you are looking for😅, probably not...
Yeah I'm extremely cautious with all the git operations that I perform since I'm relatively new with git at least in a more advanced level and I don't wanna mess it up badly so that I have to go back and revert changes... I wish I could send a voice message or something to explain in broad strokes how I'm pretending to interact with both remotes and see if you can provide some advice and see if you would tackle some aspects differently. I feel like if I have to write everything down I would end up with a thick message that will be hard to follow😅
hey guys
I tried to deploy my flask app with postgresql db to aws
supposedly, the instance deployment completed successfully, but when I try to access the URL, I get 502 bad gateway error ((111: Connection refused) while connecting to upstream).
I've read many different posts with such issue but could not find a solution to my problem. In one I read, that I have to configure nginx to listen on port 8000 and maybe that will help
I tried to do so by creating Procfile in .elasticbeanstalk folder in my app and writing
web: gunicorn :8000 application:application
but it did not help
I still get 502 error when I try to access the page
does anyone have any clues how to amend this?
nope i think that was it, thank you!
ahh i see it's built on click
i will definitely use it then
guys what is the most favorite code linter and formatter for python?
black?
thanks for the reply
Happy to help👌
Now that I have the same snapshot of the project with the same commit history in a feature branch for each repo remote1/feature1 and remote2/feature2, I wanna merge both features into their respective develop branch. From now on, I will only use remote1 to periodically push the content of remote2/develop2 into remote1/develop1 everytime I merge a feature branch to remote2/develop2. In order to guarantee that, should I do a fast forward merge of remote1/feature1 into remote1/develop1, right? Just to make sure that it doesn't create a new commit and thus alter the commit history of remote1 which would be different from remote2
no matter what, it sounds like you're going to have diverging histories
as long as feature1 never gets merged and pushed to remote2, there will be a divergence regardless of how it's represented in the commit graph
that said, there's nothing wrong with divergence
that sounds like a bit of a weird set up, are you maintaining a fork of something?
Not really I started in my company's remote developing a project and now I have to resume development in client's repository
So I bring back what I did in my company's repo to client's repo
I agree with that😅
remote1/feature1 and remote2/feature2 both have the same commit history "in theory"
two commits that have exactly the same content are still 2 different commits from the perspective of git history
git can detect and deduplicate commits during a rebase, idk if that helps at all
Then I don't have the same history jajaja
I will check it out and see if it helps
Thank you so much
First of, sorry for again asking about packaging packages, it is all rather decentralized and opague and I am getting lost
Question:
Any packaging tool (or rather build-backend) out there that works with pyproject.toml alone (no setup.py)
AND
which supports compiling cython files
AND
which only does building (and pypi releasing maybe) and does not try to handle my environment/dependencies/tests?
Info:
What I seem to have excluded already (but please correct me if I am wrong):
-
flit -> no cython compiling.
-
poetry -> tries to to everything, maybe the unnecessary parts can be disabled, but it seems cumbersome.
-
setuptools -> no aupport for only
pyproject.toml, heard it is coming, but don’t know when and if it is already certain that it is coming.
———————————
If there is a flaw in my thinking and you always need a setup.py for compiling and including cython files, please let me know. This is something I could not find out, or at least could not find out if the answer is still up to date.
Anyone have any resources for bundling Cython-compiled code into a pyinstaller executable? I'm finding lots of tutorials on the individual stuff but nothing about using them in tandem
that's a good question, and i think the answer might unfortunately be "no" as of right now. if you don't want to use setuptools or poetry, you might have to build the cython extensions manually and then somehow get the compiled shared library files included in the final wheel...
flit and hatch are the two "lightest-weight" pep-517 build backends and i don't think either supports cython built-in
idk about flit, maybe it would be a good feature request for hatch
or maybe hatch supports arbitrary custom build scripts?
flit has been vocal in not wanting to support it, which I understand and fits the general purpose of flit.
I may look into hatch some more.
Biggest problem currently is that we are in a transitional time, between setup.py and pyproject.toml.
The publishing process via setuptools seems to enough of a hassle for people to create those lightweight tools and I really do not want to start writing setup.py-files and pyproject.toml-files reduntantly in the same project and I don't think there is a way to actually have setup.py (setuptools) use the pyproject.toml effectively.
Future seems to be pyproject.toml for everything including misc tools, so I rather not set up my projects in a "dying" way.
||Packaging really is still somewhat a mess in python even if you follow the standard path, but extremely if you stray from it.||
Does maybe anyone have a guide how to package with setuptools (and publish) handy? Maybe one on how to integrate Cython build steps? Sadly the setuptools docs seem rather cryptic and feel in parts incomplete(or at least require very specific prior knowledge.
Right now I'm working on just making pyinstaller work within a GH action, next step is to just make GH actions compile cythonized code for different platforms, and then going to combine it all
Most pyinstaller actions I've found are out of date by 2 years so writing my own basic one is alright for now
valid on all of this. fwiw you can write setup.cfg and not have a turing-complete config file, if that makes you feel slightly better
that said i dont think setuptools is "dying" ever
it's still the builtin, default, and standard
to clarify: I meant setup.py is dying as pyproject is the new thing everything is revolving around and setuptools is also going to jump on (as I said, from what I heard, there seems to be a pep for it or so)
fwiw i still don't think it is dying, it isn't even deprecated
certainly support will remain for years and years and years because so many projects use it
there is almost 0 chance that you will be left using an abandoned tool with no migration path
On a related note, are there any GH actions for automated releases of built artifacts? Say I'm building for windows-latest, ubuntu-latest, and macos-latest, and I want each of those artifacts to be their own file in a release that's generated as part of that action
Is there also a way to specify version numbers based on a file with version info, or maybe a git tab?
devops gang
I don't think right now extension modules are going to work without setup.py, but you don't have to have redundant information in them. You can have setup.py just include setup(ext_modules=...), then define all the other info in setup.cfg or pyproject.toml. Then as stuff is implemented you can move it over.
Apparently pyproject.toml support just arrived, for most things notably excluding extension modules...
https://setuptools.pypa.io/en/latest/userguide/pyproject_config.html
https://thoth-station.ninja/docs/developers/adviser/introduction.html this looks pretty cool, but this doc doesn't explain why it's better than traditional dependency resolution
https://thoth-station.ninja/docs/developers/adviser/resolver.html#resolver it looks like they pre-compute certain dependencies somehow, and maybe that's only possible because it uses a markov decision process?
Github actions/YAML question: Does anybody knows how can I fetch a exe called ´Name 0.0.exe´where 0.0 is replaced by a version number which changes over time? I need to upload it like this:
- name: Upload artifact
uses: actions/upload-artifact@v3
with:
name: "Name *"
path: "dist/Name *"
But I guess this wont work properly
are there any resources explaining "integration of kubeflow with seldon core " in detail.
https://docs.seldon.io/projects/seldon-core/en/latest/examples/kubeflow_seldon_e2e_pipeline.html#examples-kubeflow-seldon-e2e-pipeline--page-root.
I went through their official doc but couldnt figure out much.
@small jay can you explain step by step? Do I need new software on my windows10 or do I just run the docker software using oracle vm software and launch using oracle using docker?
You need docker installed wherever you're running the code
So I don't need to run a full on vm though I do like using a full vm then using the ssh plugin on vscode and coding to the vm no matter what device in my network
Right there's no point in running a full features VM
(also vscode has docker extension)
I'm using a Ubuntu server
User the official python image in the docker
Can I use it from another device on my internal network
Sure ssh into the host computer
K
Well I use pymongo ik it limited discord.py 1.7.3 and datetime
And python-dotenv
@small jay
That's not a problem
So how do I do it and can you tell me step by step or watch me do it and you make sure I do it right?
I can't do that sort of commitment but the docker docs are the best tool
go through the guide

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
one of them
Just run the ssh command through cmd
@small jay does this server have a vc where i can screen share?
Hey if I wanted to write a program for work to scan an entire GitHub server and basically get data on each repo, branches, pull requests, etc. How would I do that?
I have git but cannot obtain any outside software besides Python packages
You could try ghapi https://mobile.twitter.com/hamelhusain/status/1357771218095546368
Do you want to see something really cool you can do with @willmcgugan 's rich library?
Checkout ghtop https://t.co/mn7oLbpw8e. It's a really fun CLI tool that demonstrates the power of rich (and other things).
Examples below 🧵👇 (1/8)
has anyone used aws/chalice to deploy serverless Python functions? any insights?
thank you, ill give it a go
Hi, is there is someone helping me, I want making own trade bot,
but I need someone can program/code to making via trade platform convertion into live update text
like readtrader.txt and nowtrader.txt
there is all source code but its too hard for me 😦
https://github.com/ccxt/ccxt

GitHub
A JavaScript / Python / PHP cryptocurrency trading API with support for more than 100 bitcoin/altcoin exchanges - GitHub - ccxt/ccxt: A JavaScript / Python / PHP cryptocurrency trading API with sup...
Is there a way to efficiently use virtual envs? I use python -m venv env_name for virtual envs. And if I have multiple packages I'm working with, I create a new venv for each package to isolate them. But a lot of these have many common requirements, and they get duplicated. This sucks especially for giant ~1GB dependencies. And I don't have a lot of disk space. Is there a way to isolate envs and still reuse the same package?
Maybe you could get away with using symlinks. However, I've never tried this; I'm not sure how finnicky the packages are regarding where they're located. Furthermore, I'm not aware of any tool that would do this automatically for you, and it'd be quite tedious to manage manually.
Actually, there is a tool called pipx that will automatically install each package in an isolated environment. Maybe it will take care of sharing common dependencies? Not sure.
Thank you for the reply. Will look into pipx. But in this case, what is the best practice to manage packages? Do people just repeatedly install huge dependencies, over and over for similar repositories? Or is there a way to have a common env and still somehow manage the isolation? 🤔
An example would be working with / contributing to different Github repos for deep learning, each having its own dependencies and purpose, but many of them having a dependency for pytorch which is ~1 GB.
With virtualenv (3rd part venv manager) I know it's possible to create a venv that also uses the system-wide Python packages. I suppose that would be one way to share dependencies, but installing system-wide packages is not ideal. And like I said, you could try symlinking what you need.
I don't usually work with large dependencies, so reinstalling them over and over in different venvs has not been a problem regarding disk space.
why when I run this tree -I 'node_modules' i get this error Too many parameters - node_modules ?
Hi Everyone! 👋
My company is a heavy user of Python, and we needed a simple code profiling tool for performance-critical parts of our production system. We wanted something extremely light-weight and focused, but didn't see anything available "off-the-shelf", so we created Mocha!
More info here: https://github.com/mocha-dev/mocha. Please give it a star if you find this project interesting!
git question
git rm --cached <file> vs git restore --staged <file>
i'm confused abt the difference between these 2
they both seem to remove files from the staging area and make them untracked
the latter is what the git cli recommends when you do git status

The latter can't remove the file from the remote repository, whereas the former can
ic ic, but when these exact flags are used as above, do they do the exact same thing?
https://stackoverflow.com/questions/65434544/whats-the-difference-between-git-rm-cached-git-restore-staged-and-gi This explains the difference quite well, imo. To summarise: There are slight differences between them, except where the <file> is not already committed. Using either git command on an uncommitted, but staged file, will essentially do the same thing. In any other case, the former removes the file from the cache but leaves the working tree copy (hence why you have a deleted file in stage and an untracked copy of the same file) and the latter will just reset the files changes to that of the working tree copy
Stack Overflow
I have come across the following three ways in order to unstage the files that were staged by the command 'git add'
git rm --cached <file>
git restore --staged <file>
git reset <file...
 tyty
tyty
sorry if this is a dumb question, but why would one prefer one over another of version = attr: [pkg].__version__ and version = 0.0.1 in setup.cfg?
I looked at this page - https://packaging.python.org/en/latest/guides/single-sourcing-package-version/ - and there seem to be a lot of different ways to write versions, but no clear guidance about when to use each of them
hello. An error occurred during the Kubernetes installation process. I'm a Windows user. I would like to get help.
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
- Check output of 'journalctl -xeu kubelet', try passing --extra-config=kubelet.cgroup-driver=systemd to minikube start
- issue: https://github.com/kubernetes/minikube/issues/4172

GitHub
sudo minikube start --vm-driver=none --docker-opt bip='172.18.0.1/24' o minikube v1.0.0 on linux (amd64) $ Downloading Kubernetes v1.14.0 images in the background ... 2019/04/29 16:...
I've read this article, but I'm a Windows user and I don't know how to solve it.
I have a vm instance on google cloud, and when I connect to it using SSH and run a script the script terminates when I close the terminal. How can I prevent that? I want the script to run until the vm instance is stopped
Use tmux, then you can connect to running tmux session with tmux a
ok thanks
depends on whether you want the source of truth for the version to be setup.cfg or __version__
this new terminal app warp looks good
Hello everyone! I wonder what the best practices are on doing package releases to pypi and simultaneously on github! From what I've seen so far there are tools for automatic changelogs and release drafts as github actions but is there a way to use the automated release number as the pypi version number? To my understanding for pypi releases I have to make sure the correct version is hardcoded in setup.py. Any hint/example or guide would be much appreciated!
travis_tag = os.environ.get('TRAVIS_TAG', '')
if travis_tag and travis_tag.startswith('v'):
version = travis_tag[1:]
else:
version = '0.0.1.dev0'
setup(
name='blabla',
version=version,
nothing stops you from setting up version from CI env variable
oooh nice, why didn't I think of that. This helps a lot, thank you!
Hmm I still need to know how to get the latest release number from github as an env var, this project uses a script for it - I wonder if there's an easier way? https://github.com/cjolowicz/cookiecutter-hypermodern-python/blob/main/tools/prepare-github-release.py
GitHub
Hypermodern Python Cookiecutter. Contribute to cjolowicz/cookiecutter-hypermodern-python development by creating an account on GitHub.
Google github ci predefined variables
Thanks, I think I found it
GITHUB_REF_NAME The branch or tag name that triggered the workflow run. For example, feature-branch-1.
On an unrelated note, why is prefixing with "v" common? Any particular reason I should use the "v" prefix too?
More distinctive looking in commits and other things. That is it.
If it is with v, then it is clearly version and nothing else
makes sense - thanks a lot for your help!
is there any reason why python3 -m pip install . would be changing the permissions of the directory it was invoked in?
I'm building a python package using pyproject.toml with setuptools. My build command python3 -m build works fine, the above install command works fine, but after the install is executed, I no longer have permission for my project's root directory...
I tried that too, same result
weird. did it change the owner or the permission bits?
I'm not sure
...check?
hmm, OK
so I'm actually trying to wrap a smaller Python package into a larger C++/CMake project. I just tried running the commands again from the command line, and it seems to not be messing with permissions, the weirdness only happens when the commands are invoked as part of the CMake buildsystem
I wonder if this is a CMake issue
Anyone got any opinions on kubernetes manifest templating tools?
From experimenting:
kustomize seems a bit too limited, patching seems a bit error prone and it is difficult to validate patches
Helm is more capable but adds a layer of complexity, it's still error prone and requires YAML filters, can introduce external dependencies (which we wanna keep minimal), and validation is still hard
At the moment strongly considering ytt - mainly YAML with some pythonic scripting
Cue also seems good but maybe a little too complex for current needs
Anyone know any others that are worth considering?
Not sure if this is the right channel, but I was wondering if there was any formal language/context free grammar libraries (other than pyformlang) that gives me an abstract type for Grammars/Production Rules/Non terminal etc. My goal is NOT parsing and NOT NLP which seems to be what most libraries are suited for. It's more about exploring the language a grammar produces.
Has anyone have any problem deploying to heroku recently?
I'm getting an Internal Server Error when I try to connect my Github to Heroku
It used to work before for my other apps
Just tried deploying to render.com. They can only support up to 3.7. My app is made for 3.10. Dang it
There has been some issues with OAuth tokens recently with Heroku and Travis CI. https://github.blog/2022-04-15-security-alert-stolen-oauth-user-tokens/

On April 12, GitHub Security began an investigation that uncovered evidence that an attacker abused stolen OAuth user tokens issued to two third-party OAuth integrators, Heroku and Travis-CI, to download data from dozens of organizations, including npm. Read on to learn more about the impact to GitHub, npm, and our users.
Using the cli works though (for me at least)
Sometimes I miss the "e-16" at the end and I think that number is substantially non-zero. But what if we made numbers printout tinier if they were really close to zero:

Hi I just a newbie could anyone of u share with me where u started ur python learning saga,and can someone recommend some resources to easily start python youtube videos preffered
Works for me too. I guess I'll just do heroku cli for now
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
ok, so with alacritty terminal you generally want to use tmux to manage panes, windows. but what if you want to connect to remote machine via ssh and use tmux there to keep process running even when disconnected. tmux in tmux is not so good ides i think. any thoughts?
There are ways to keep a process running after you disconnect from the window, is there any specific reason you want to do it with tmux?
This is the way i know. What are the other ways?
use systemd
it is default proper system to run stuff as a daemon
i will look into it. thanks! so what i want is to ssh to vm, start a process (acutally it's a python s cript). disconnect from vm. connect to it again. and hope the process still runs and i can see the output etc.
i am reading some online materials on it. not sure if i got it right. just to explain better what i am after. i want to start a machine learning python script. then disconnect, then connect and be able to inspect the running script to check the output, that with tmux would be just in tmux window. then decide if i want to keep the script running or stop it, etc. i've read about systemd, nohup, disown, but a bit lost now 🙂

@subtle quarry if you want the terminal output, a multiplexer (tmux/screen/byobu) is the only way
you can either get a terminal that does split panes or choose a different escape key on your machine than the remote host
If it's only console output those are definitely your options. If it's gui output there's xpra (and maybe others...).
What is your usecase?
Hello, I am currently ingesting data from different endpoints of an API. Basically I have 3 different group of processes: data ingestion from API(json), spruce up ingested data and eventually load useful data into the db. The thing is that I wanna use pydantic because it's getting a bit tedious to validate ingested data but I'm not sure about a good conceptual approach to include it in my existing project
I would like to make data ingestion flexible by means of a config file so that whenever a field name change, it can be easily adapted
Hi, I'm doing a research for a tool for python monorepo handling. I come from js world where there are many tools for this task (lerna, rush, nx to name a few), that handle installing, package dependencies, version bumping, publishing.
I've found Pants for python, but I've failed to find any functionality related to linking, publishing, and version bumping of packages (maybe I haven't searched hard enough).
Can anyone recommend me a tool for that?
By any chance u a launching it in Alpine image?
If yes, then switch the image to something else. Debian based one for example. It will speed up 50x times building ;)
docker/Dockerfile line 42
RUN export YARN_CACHE_FOLDER="$(mktemp -d)" \```it looks legit.
Give a check to CPU load then. May be where u a running, u a having unsufficient CPU resources
its something around 215s
yeah I also tried running with buildkit and made a small difference
Perhaps just to use some form of caching to speed up the process? 🤔 Since u a using docker... u could use docker registry as caching storage.
docker build url/blabla with cache from url/blabla & docker push url/blabla
then next build will pull the image of previous pushed version, and will try to use whatever possible layers as caching source
uhm so you're suggesting to use FROM: prior to that python setup.py bdist_wheel
or something like this: https://vsupalov.com/buildkit-cache-mount-dockerfile/

vsupalov.com
A quick demonstration of what a BuildKit-using Dockerfile looks like, so you can make use of those cool new BuildKit features.
no, i suggest this
- docker login $docker_registry -u $docker_username -p $docker_registry_token
- docker pull $image_name:test || true
- docker build -t $image_name:test . --cache-from $image_name:test
- docker push $image_name:test
- docker run $image_name:test pytest
yeah
uhm well it didn't make a difference whenever I change some .py file inside of the project even with the cache it will take same amount of time to do sdist 😦
uhm I wondering if its possible to use a previous wheel/whl/dist as a cache
yeah, it should be possible
Hi, Is there a way to change vscode autocomplete from using abstract images for classes,func,etc to actually letters?
i though there was a parsing channel.
is there an API or Module for python that allows you to do this:
inputString = "I am saying \"abcd\""
#do somthing
verbs = ["am", "saying"]
subject = "I"
#etc.```
i want to parse the grammar
give an input string and get the list of Verbs, the subject, etc.just googling "python identify verbs"
what is the secound value of the tuple (word, ???)
anything u wish
if it is already declared u can check the type with function type(obj)
hello, i ned help. How can i make a frase repeat a lot of times with different characters
and after a time print another word
is there a way to get a breakdown of timings in an OpenGL frame?
I wrote a script to parse the first page of the pypi package search
since pypi removed the actual search API and never gave us a replacement, I feel scraping it is entirely justified
https://gist.github.com/greyblue9/38e2f171c0247eff5a60a6480be932a1
maybe someone can do something cool with it, right now it just does pprint which isn't the greatest ux
searching for "gif" on pydroid3

Observability is becoming a part of the dev-tools stack - what you need to know to add it to yours https://betterprogramming.pub/the-observant-developer-part-1-1939d53fd5a4

Medium
Like tests, observability tools provide a way to validate code assumptions, without the added cement.
:incoming_envelope: :ok_hand: applied mute to @distant widget until <t:1651604673:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
Include GitHub Actions to auto-publish as new version tags are created. This must also include updating the CHANGELOG.md file with the list of commits
Guys where can I find a solution for this? Also, could someone please recommend a few sources to understand Github Actions from? Finding a hard time to even find a good Youtube channel
I would definitely not recommend looking for resources to learn CI infra on youtube...
anyone have phone # validator
twilio, authy
Suppose that my project has a migrations folder, where migrations are numbered in order (like mysql043.sql). Suppose that two developers branch out from some version of master and each adds their own mysql044.sql. What would be a good way of detecting and resolving this? Are there some numbering tricks maybe?
Does anyone python for Grashopper? If yes what do you think about its application in Grashopper2 will be the same or shall we see something spicy?
Hey, I've made a crontab (through crontab -e on a user called dan), it looks like this:```
-
-
-
-
- /bin/bash /home/dan/Chief-Ron/dump.sh >> /home/dan/Chief-Ron/cronLog.log
The cronLog has been created, but it is empty. The backup file has not been created. Here is the bash script:bash
#!/bin/bash
- /bin/bash /home/dan/Chief-Ron/dump.sh >> /home/dan/Chief-Ron/cronLog.log
-
-
-
CONTAINER_NAME='chief_ron_db'
DUMP_FILE="dump_date +%d-%m-%Y"_"%H_%M_%S.sql"
USER='dan'
cd /home/$USER/Chief-Ron
set -e
. ./colours.sh
cd /home/$USER
if [ "$( docker container inspect -f '{{.State.Running}}' $CONTAINER_NAME )" == "true" ]; then
echo "${BLUE}Starting database dump"
if [ -d 'database-dump' ]; then
cd database-dump
else
mkdir database-dump && cd database-dump
fi
docker exec $CONTAINER_NAME pg_dump --data-only -U postgres postgres > $DUMP_FILE
DUMP_SIZE=$(ls -lh $DUMP_FILE | awk '{print $5}')
echo "${YELLOW}Dump size - $DUMP_SIZE"
echo "${GREEN}Database dump completed"
else
echo "${RED}$CONTAINER_NAME isn't running"
exit 1
fi
Number them in Unix time of creation.
Or just deal with conflicts when they come up. I will say, I think you have a database problem if you have that many migrations
aren't there migration frameworks that let you specify actual dependencies for migrations? instead of relying on a static order
or maybe that would cause more problems than it solves
Yeah that sounds good.
There's also some thing where you can't merge into master if you're behind master, but I forgot how it's called
like, so that you don't get new and unexpected behaviour after you merge
Okay so I've been working on running my flask app using gunicorn wsgi with nginx on a container on my VPS
Most tutorials haven't been that much helpful and the docs are very confusing, can someone help me do that?
Till now I've got docker and gunicorn installed, but nothing more, im not sure how to make my container and how to run my flask app using gunicorn in it
It's probably best to break this down into separate steps:
- Figure out the command to run your app using gunicorn
- Add that command to your dockerfile, and make sure you can build the container
- Expose the container's ports and make sure you can make your requests correctly
- Use NGINX to forward those requests
Where would you say you are at this point
I finished following this tutorial https://dev.to/ishankhare07/nginx-as-reverse-proxy-for-a-flask-app-using-docker-3ajg
Here is my file structure in the photo
I will send the code rn, but just keep in mind im trying to link it to my actual domain and its not showing anything
One more issue is that when the person here lunches the container cluster it launches seperate containers where for me itt just launches 1


DEV Community
Get a docker cluster up and running with nginx setup as a reverse proxy

listen:80;
server_name test.frenchnoodles.xyz;
location / {
proxy_pass http://flask-app:5000/;
proxy_set_header Host "localhost";
}
}
version: '3.1'
services:
nginx:
volumes:
- ./nginx.conf:/etc/nginx/conf.d/default.conf
image: nginx:1.13.7
container_name: nginx
ports:
- 80:80
flask:
build:
context: ./
dockerfile: Dockerfile
image: flask:0.0.1
container_name: flask
volumes:
- ./:/code
environment:
- FLASK_APP=/code/main.py
ports:
- 8080:5000
command: flask run --host=0.0.0.0
networks:
my-network:
aliases: flask-app
FROM python:3
RUN pip install flask
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello my world'```Well here are all the files
Ok I think there's a bit of confusion here
When you run an nginx container, that does networking inside the container
I think you want nginx running on your server, not in a container
You'll probably also want to change your command to run gunicorn instead of flask (and install gunicorn in your dockerfile)
To clarify, while doing it that way is a valid approach, it means you still need to manually expose your server's 80 port. This gets confusing because you are now managing networking in two different systems.
Compare that to running NGINX on your server directly, which will manage exposing the ports, and sending traffic to your container
It would just mean your proxy_pass would point at localhost:port instead of flask-app, and you'll need to expose your flask app port on your system
Oh- how do I do that? I'm sorry but gunicorn confuses me a lot lol can u tell what the command is to make it work inside the yml file
Well my plan was to make it so that each subdomain will get u to a certain container using those exposed ports (that are supposedly only exposed INSIDE the VPS)
I'm not quite sure on how to do that
The most simple command would be gunicorn main:app inside your code directory (where main is the name of your file, and app is the name of the variable). You'd need to install gunicorn though, which can be done via pip install gunicorn. The docs on their site go into depth about all the configuration options (of which there are many)
Yeah, that would definitely be very complicated if you ran NGINX inside a container
Look at it this way, you can only bind your 80 port to one NGINX instance. From that NGINX instance, you can distribute your traffic to different containers based on the domain
If you have your NGINX instance inside a container, then you can only distribute traffic to containers on the same docker network, and in most cases that will only be the containers in the same docker-compose (unless you manually override the network)
RUN pip install gunicorn to Dockerfile ig
flask:
build:
context: ./
dockerfile: Dockerfile
image: flask:0.0.1
container_name: flask
volumes:
- ./:/code
environment:
- FLASK_APP=/code/main.py
ports:
- 8080:5000
command: flask run --host=0.0.0.0
and change
command: flask run --host=0.0.0.0
to
command: gunicorn main:app
ig now I have to research on how to install nginx normally outside of the container
@heavy knot Are you fine with entering a quick call? ScreenSharing could make it a tad easier
Discord VoIP is blocked in my country, and I'm hopping off soon
Oh its fine then
There's the NGINX quick-start guide, but yeah it can be a pain in the ass
Can you send a link?
btw is this correct? to make the switch to gunicorn
It should work in theory yeah, just don't forget you need to be inside the code directory
Or you could reference it as gunicorn code/main:app
Let me double check that
might be code.main:app
I mean, the second one to merge gets a merge conflict, right?
if you want to be more explicit about it, alembic is the way to go, but it's likely overkill until you get to like 10+ developers
you're talking either about only allowing rebases through the github PR UI or non-fast-forward pushes
just so you know, this is executing every minute
my guess is set -e is causing some command to exit failure that you're not seeing. it also looks like you're assuming a working directory, which is probably causing the mkdir to fail
you need to 2>&1 to see stderr
I didn't really know in which section to post this, but I think a Console Color library maps the most usefull for Tools and other, I think
I have been making my own console color package as I have this whole mantra of using as little third party libraries as possible for my project. So instead of using colorama I've written my own.
Therefor it is also a "no dependency" package, meaning I only rely on the Standerd Python Library.
As the colors is modeld with using RGB values, I have also taken the liberty of predefining all 140 HTML named colors, which can be used as Fore and Back-ground colors.
It uses a similar syntax to Colorama:
from AthenaColor import Fore, Style
print(
f"""
{Style.Italic}{Fore.SlateGray}AthenaColor Example:{Style.NoForeground}
{Fore.Red}This is an of {Style.Bold}EXAMPLE{Style.NoBold} nested styling{Style.NoForeground}
{Fore.SlateGray}As you can see, the color needs to be manually returned here{Style.NoForeground}{Style.NoItalic}
"""
)
But also allows for nested layouts:
from AthenaColor import ForeNest, StyleNest
print(
StyleNest.Italic(ForeNest.SlateGray(
"AthenaColor Example:",
ForeNest.Red(
"This is an",
StyleNest.Bold("EXAMPLE"),
"of nested styling"
),
"As you can see, the correct color returns here by itself",
sep="\n"
))
)
The github link: https://github.com/DirectiveAthena/VerSC-AthenaColor
The PyPi link: https://pypi.org/project/AthenaColor/
And the the documentation I am still working on ... definitly not a debt I am just pushing forwards and forwards: https://publish.obsidian.md/directiveathena/Content/Programming/AthenaColor/AthenaColor



GitHub
Python Package used to print rgb colors to the console - GitHub - DirectiveAthena/VerSC-AthenaColor: Python Package used to print rgb colors to the console

Ah, looks like this is the error: dan@vmi840593:~/Chief-Ron$ cat cronLog.log tput: No value for $TERM and no -T specifiedI just appended 2>&1 to the end of the cronjob
@lusty forge pretty weird to output colors in a cron, FWIW
Ah yeah, that was the issue. The script was intended to be used through bash
I have a sorta long question but it's better explained on stack overflow, am I allowed to just send the stack overflow link here?
probably? I'd just do it @wispy arrow
Alright
Stack Overflow
I've been working on my VPS lately in a goal which is to have nginx handle all traffic in a reverse proxy to containers which contain my projects, which most importantly are flask and ran using gun...
have you... done any of those 4 steps?
Currently I'm trying to figure out making a docker image that only contains the flask app
then im gonna try to implement gunicorn into the equation
and when that works, ill start working on the nginx side of things
ok... let us know if you have trouble writing your dockerfile
currently im following this tutorial https://blog.entirely.digital/docker-gunicorn-and-flask/
I setup the dockerfile but its giving me a "jinja2" error which im not sure where it originated from


Blog entirely.digital
Do you want deploy your Flask app quickly and easily? Do you want it to be stable, robust and able to handle lots of requests? Then this article is for you.
your versions of flask and jinja2 don't match up. how'd you install those?
I didn't install Jinja2
I just installed flask from the requirements.txt using flask==1.0.2
I tried fixing it by changing the python version to 3.9 (which I still want anyways)
same error
changed the flask version to Flask==1.1.2 and added Jinja2==2.11.2 which now gives me a new error ImportError: cannot import name 'soft_unicode' from 'markupsafe'
I solved all of these, implemented gunicorn, but am getting the error "no module named wsgi"
(this has moved to #help-chili )
Tried setting up quake/guake/drop down mode for alacritty on MacOS with hammerspoon as per this https://world.hey.com/jonash/alacritty-drop-down-guake-quake-style-terminal-setup-on-macos-6eef7d73
But hammerspoon gives me error in config reload. Any other way to set it up?
I ❤ my terminal As a programmer I spend a good chunk of my working day in a terminal and have up until recently used iTerm2 for MacOS. It is pretty nice, but I also use tmux (if you haven't heard about it, check it out immediately). Using tmux I have no need for all the extra crap that is bundled into iTerm2 like tabs, panes, keyboard ...
How can I make my pypi package popular?
- Make it super cool needed / attractive to dev eye (besides business value, it should be having other things nice, like... properly set collaboration with other devs)
- Publish articles about it in dev places
who can tell the steps using devops (for instance Git). I mean what the developer should do after cloning the repo, create a new branch or what?
https://learngitbranching.js.org/?locale=en_US go through this tutorial, it will be better
An interactive Git visualization tool to educate and challenge!
thank`s but maybe you misunderstand me, I asked about action in real-time project, where the developer should clone the repo and perform action on it
The dev would do what they need to do
It's like asking what you should code after creating a python file
your question is so unspecific, that it is the only thing I can recommend. Although now I can probably guess that you ask... how DevOps stuff affects end results for developers workflow?
Developer git clones his repo and just works in any branch (preferably not in master branch)
Once dev pushes code to remote
your CI CD pipeline is supposed to be triggered.
At least CI for all branches
and CI+CD for master and merge requests (in small amount of devs situation, it is triggered just for all branches too ;b)
the amount of times staging is deployed, depends on the amount of devs, it can be even just manual triggered deployment (one click in cloud git gui) 🤷♂️
setup for the devs, docker-compose to raise dev environment to work in one command and document it in README.md.
Make sure that all actions with docker-compose are done in 1 command (2 at maximum when it is more comfortable so)
yeah this is my way) I asked unspecific question and suppose it has easy answers
oh yeah, and if your devs for some reason use raw SQL to create database, make sure they have it git version controlled in migrations preferably. Using their language ORM migrating libraries or at least using stuff like FlyWay.
if you don't what you seek, you get don't know what ;b
Asking the right questions, and writing test to functionality supposed to be implemented, is like a half work done 😉
Ok so on my flask app, I have a "return redirect('/home')
Which does NOT work only when used with nginx
I remember I once fixed this by adding something to the nginx configurations I just don't remember what
hi, is it possible to use Heroku Pipelines with docker images instead of connecting it directly to github repo's branch?
You can use the heroku cli to build and push your image
oh, so pipeline doesn't continuously deploy its apps, it has to be me doing it exactly the same way like I would do without the pipeline?
I'm not too familiar with the heroku pipelines but I was looking at deploying with docker the other day and know it is possible via the cli
ah, I've done it through cli to regular apps, but I want to connect apps into a development-staging-production pipeline
and I need to connect the pipeline to github to be able to use temporary apps for development and I'm not sure how it will affect deploying process of the other apps
thank you for trying to help though! 🙂
still up, if anyone knows something about that ⬆️
I'm not familiar with pipelines but I have deployed a docker image to heroku, maybe it's the same with pipelines.
You need a Dockerfile and a heroku.yml at the root of your repo
heroku.yml
build:
docker:
web: Dockerfile
thank you
do you maybe know whether deploying simple docker to heroku is any different than deploying docker with docker-compose.yml included?
I want to dockerize a django + postgres hosted on heroku, and from what I understood I must create a docker-compose.yml file and put postgres info there
Well AFAIK you cannot do that, but there are other ways to achieve it.
- Use a hosted postgres dB (elephantsql, a plugin that heroku provides, are some places you can find a free one but not suitable for production environments).
- Deploy a postgres dB instance on heroku via CLI and forget about it.
- Create a docker image that contains both your application and the dB.
I would prefer the first one as it is easier and provides a GUI to visualise and interact with the dB.
I mean, I'm using postgres provided by Heroku, they have it in their resources
I just want my django app dockerized and deployed to heroku, but I'm having problems cause I don't know how to deal with the heroku's postgres in dockerization
so I guess it's option 1 from your response
do I need docker-compose.yml with db mentioned in it in that scenario?
@ripe tendon https://devcenter.heroku.com/articles/build-docker-images-heroku-yml#configuring-add-ons

heroku.yml is a new manifest for defining your app. This article is specifically about using heroku.yml to build your Dockerfile.
ooh, I just realized that heroku.yml is doing docker-compose.yml work
I totally missed that when @cosmic breach wrote about heroku.yml
thank you to you both! I will focus on the heroku.yml article now 😊
So I have setup my github actions to replace my code when I update it in the VPS
But now I also need this code to be updated in my docker container and im not sure on how to do that
I think i have to automatically stop the old container, build a new image and then run it
But idk how to do that from the .yml file
there's couple of things here
replace my code when I update it in the VPS and this code to be updated in my docker container are 2 seperate things?
@wispy arrow
Not really
I need the code to be in my vps to then use that code alongside the pre existing dockerfile that is in their same folder to create that image
ah
you don't use any docker registries then, right?
how do you push your code to the vps? can you ssh to your vps?
when using (not self-hosted) github actions, picture it's running the commands from an xy location/server
on macOS, how do y'all test k8s changes locally?
I'm using Lima, but it's kinda clunky
@brazen forge I use linux&kind
I know you said macOS but I found one small tool to make use of virtualization framework

GitHub
A set of utilities (vmcli + vmctl) for macOS Virtualization.framework - GitHub - gyf304/vmcli: A set of utilities (vmcli + vmctl) for macOS Virtualization.framework
thanks! I'll check this out
Can you not use minikube for something like that, or am i missing something?
Nope, images are stored on the VPS itself
I push the code to the VPS through SSH-ing with github actions and putting the new code in and removing the old one, but for it to work properly I need the image to be rebuilt and the container re-ran and idk how to do that
Hi
I'm making a pixel drawing engine
It's draws like this
pixels = {1: True, 2: True, 3: True, 4: True, 5: False, 6: True, 7: False, 8: False, 9: False, 10: True, 11: True, 12: False, 13: False, 14: False, 15: True, 16: True, 17: True, 18: True, 19: True, 20: False, 21: True, 22: False, 23: False, 24: False, 25: True}
from pixelgfx import canvassystem as engine
from pixelgfx import x5ready as readys
canvas = engine.Canvas(5)
canvas.writepixels(pixels)
is it hard? (i maked a drawing app for it)

Anybody know how to make the universal “py3” wheels in cibuildwheel? The ones that work for 3.7/3.8/3.9/3.10 without having a separate .whl for each
I.e., how cibuildwheel itself is distributed
Can anyone tell me how to implement the built in plugin supports for PyQtWebEngine, with the Pepper Plugin API, how would you make a plugin, how would you add them to your PyQt Web Browser and how would you make an extensions GUI button for removing and disabling plugins? I found some documentation, I how this can help some of you guys to at least make it a bit easier to help me: https://doc.qt.io/qt-5/qtwebengine-features.html#pepper-plugin-api
heey guys, is there anyone who knows how to host python (flask) app from windows to heroku?

because i need help to fix this somehow
You use windows_events, but it's specific module for Windows System.
I do use it on my Linux laptop, but somehow it refuses to work on macOS for me
I get error when I try to run my docker with nginx (for static files) and gunicorn on heroku.
```2022-05-08T16:49:45.929917+00:00 heroku[web.1]: Starting process with command /opt/app/start-server.sh
2022-05-08T16:49:46.985586+00:00 app[web.1]: 2022/05/08 16:49:46 [warn] 6#6: the "user" directive makes sense only if the master process runs with super-user privileges, ignored in /etc/nginx/nginx.conf:1
2022-05-08T16:49:46.985598+00:00 app[web.1]: nginx: [warn] the "user" directive makes sense only if the master process runs with super-user privileges, ignored in /etc/nginx/nginx.conf:1
2022-05-08T16:49:47.249413+00:00 app[web.1]: [2022-05-08 16:49:47 +0000] [7] [INFO] Starting gunicorn 20.1.0
2022-05-08T16:49:47.249973+00:00 app[web.1]: [2022-05-08 16:49:47 +0000] [7] [INFO] Listening at: http://0.0.0.0:8010 (7)
2022-05-08T16:49:47.249974+00:00 app[web.1]: [2022-05-08 16:49:47 +0000] [7] [INFO] Using worker: sync
2022-05-08T16:49:47.257186+00:00 app[web.1]: [2022-05-08 16:49:47 +0000] [16] [INFO] Booting worker with pid: 16
/\ 2 same lines here
2022-05-08T16:50:18.095907+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch
2022-05-08T16:50:18.139573+00:00 heroku[web.1]: Stopping process with SIGKILL
2022-05-08T16:50:18.371317+00:00 heroku[web.1]: Process exited with status 137```
I use following commands:
nginx.default
server {
listen 8020;
server_name example.org;
location / {
proxy_pass http://127.0.0.1:8010;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /static {
root /opt/app/movies;
}
}```
start-server.sh
...
(cd movies; gunicorn movies.wsgi:application --bind 0.0.0.0:8010 --workers 3) &
nginx -g "daemon off;"```
Does anyone know how to deal with this? I've heard that I can't specify ports that I'm running servers on on Heroku, but how do I do it without specifying them directly?
is the R10 error caused by gunicorn movies.wsgi:application --bind 0.0.0.0:8010 that bind part? or listen 8020 part in nginx.default?
I can run the docker locally without any problems
I suppose this is the answer:
https://stackoverflow.com/questions/37636580/heroku-node-js-i-have-a-server-which-uses-multiple-ports-how-can-i-get-herok
"opening ports in Heroku is disabled and not allowed"
@ripe tendon you're hardcoding 8020 instead of using $PORT
you're right, I just read about using $PORT
the next problem was if it's possible to do nginx -> gunicorn -> django "pipeline"
nginx takes in requests, replies to ones that go to /static and forwards the rest to gunicorn
in the code above nginx proxy passes them to 8010, where gunicorn should be listening
locally it works, but heroku gives you just one port ($PORT)
answers in this link say some stuff about it, if you're interested -- I passed, since it's not necessary in my case. I dropped nginx, will do with gunicorn alone, since it's for showcase only
thank you for your help 🙂
Any good tutorial for CircleCI?
Are there any tools for generating Python code out there? I spent a long time searching and found one called genpy, but it was like half-finished so I had to extend it a lot
subprocess.Popen('export universal_var', shell=True).wait()
subprocess.Popen('echo $universal_var', shell=True).wait()```Hey guys I imported subprocess and this is my script lets call it script.py. I am setting a variable and exporting it but when I run the script and then open a terminal and echo $universal_var it outputs nothing
Not really familiar with Unix's commands, but wouldn't that just set it for the current session?
You could manually construct ast objects, then call ast.unparse() to generate code from that. However the node structure is liable to alter with different Python versions.
Yeah I tried this but it’s extremely cumbersome
I’m curious if anyone’s ever done something big with it
you can pick whatever port you want for the nginx -> gunicorn communication. as long as you serve your website (via nginx) on $PORT, heroku is happy. I'd actually use a unix socket rather than a TCP socket/port for this
heroku's recommendation is to not bother with nginx: https://devcenter.heroku.com/articles/django-assets
Learn how to configure a Django application on Heroku properly to use static assets.
@craggy locust what are you trying to generate? like, protoc exists for protobuf...
as numerlor says, those env vars die when the shell exits. subprocess.run takes an env argument, which is what you probably want https://docs.python.org/3/library/subprocess.html
are you sure? cause I've been getting errors about not being able to bind to the set port (8010)
and I don't know anything about unix sockets and this is not a priority right now so can't use it unless very easy
and I am not sure but I think nginx has some more profits (from what I know nginx is highly encouraged by gunicorn) than just statics
oh, maybe they restrict you from binding to other ports
I suppose unix sockets would solve that?
like half the reason to use heroku is to not have to think about things like nginx
yee I'm a newbie so I don't have the full image
if you want the optimization of serving static assets from nginx, maybe you should just get a VPS instead
it's just my junior portfolio project showing that i can do a basic CRUD and CI/CD pipeline
otherwise, I'd stay on the heroku rails and use their recommendation (of not bothering with nginx)
can I use unix sockets to communicate frontend and backend?
like, I would normally put django on 8000 or something and react on 3000
but I suppose heroku would do fail to bind on one of those ports