#data-science-and-ml
1 messages · Page 328 of 1
I am on mobile right now but i can try another time
No worries!
I've just realised I never write my own pandas, I always refactor working pandas
Doubt regarding MobilNet:
So i am referring the mobilNet which has resisual connection and a bottleneck layer(consisting of expansion, depthwise conv and projection)
My question :
Why does this NN architecture apart from being memory and computation efficient gives advantage of learning more complex and richer function?
I think, it is due to multiple conv and filters that the function is prevented from overfitting and features that are actually to be learned are more pronounced after application of filters in bottleneck.
Anyone to help me with multi colinearity ?

Multi co linearity (TotalBsmtSF, GarageArea) >> SalePrice
I wouldn't worry about it unless you are fitting with OLS and you see high VIFs
From the corr diagram all the areas are heavily related, and house ages are also related. (for hopefully obvious reasons)
While I wouldn't worry about it, I think using just 1 of both groups would predict SalePrice uses data most efficiently
Given n=9 I would run automated AIC-based exhaustive subset selection on it - it should terminate within reasonable time
cool then
how to perform automated?
Just search for lowest(or highest if that's what your system uses) AIC
Typical modern computer should be able to do 2^9 fits without issues
Jupyter lab 3.0.16 sometimes jumps the position of the code cell on the screen when clicking on it (autoscroll a few lines), it often happens when I click on the output, then on the code, it's pretty annoying, is there a setting to change that, or it is a bug that I should feel on Jupyter GitHub?
when training and evaluating Isolation Forest on a labelled dataset i.e. 95% inliers 5% outliers, the minority class percentage should be the contamination ratio right?
What's the recommended FPS, video resolution, & video size for video input for OpenCV's VideoCapture?
I'm right now trying a vehicle tracking program using my own video file (1080p, 30 FPS), but it stutter so much and the centroid is all over the place.
Basically, I am using various BERT models to classify a certain section of patient's medical documents (electronic health records) -- however, much of the valuable information is written in a sort of 'note' format, and less so refined English.
BERT is extremely good at understanding a language, however, I can't help but think this task relies heavily on a set of key words rather than a complex understanding of the clinical language
This can be highlighted by the fact that
while the various BERT models I implement do indeed perform very well (high f1 scores across the board), there is not much different between them -- even though some have been pretrained on entirely different material
and some even employ different pretraining techniques
Does anyone know any NLP models that would be better suited for this? -- please @ me if so ! ty
@opaque stratus have you tried fine tuning your Bert model?
ye ofc
all fine-tuned on the downstream task i mentioned above
hi
so Im using matplotlib in different areas of 1 program and my issue is that the plots interfere with each other e.g.
after one plot is saved and the plots that are made after it uses the previous plot for the background 
any idea how I would fix that
delete this message, go to another channel, thank you
 but matplotlib is in the channel description so
but matplotlib is in the channel description so
oh
thought this was a help channel
my bad
but now nobody will see my message above =[
Have you tried gpt2
I've seen some people have success adding gnns to document based problems, but I'm not sure how to set that up without working through the specific data
Hi i have a question... can someone help me?
I want to create a ML Learning Curve... so ive create and trained my model (a rock, paper, scissor recognition).... but i dont have any idea how to create the learning curve....
link to colab google = https://colab.research.google.com/drive/1qwaWc4sz-6WkJVCHoJaPgOUnNwE4Hhov?usp=sharing

How to see neural network properties from pickle open ? Like features used, number of layers, etc
def classifier_data(data,time_horizon):
lagged_features=data.shift(time_horizon, axis = 0)
data=data.add_suffix('_target')
data_formatted = pd.concat([lagged_features,data], axis=1)
data_formatted.dropna(axis='columns')
return(data_formatted)
How can I drop the first of last rows of my dataframe?
The code works but it's not efficient because on dropna, it iterates over all rows to find a row with NAN but I already now where the NAN are.
You can use data_formatted.drop(axis=[<axis numbers (0 corresponds to index)>], inplace=True)
i need help about Tensorflow things. I successfuly run this model with keras tuner
def GetModel(hp):
f_choice = hp.Choice('num_filters',values=[16,32, 64, 128,512],default=16)
k_size = hp.Choice('kernelsize',values=[3,7,11,13,15],default = 3)
max_k_size = hp.Choice('pool_kernelsize',values=[2,3,5,7,11],default = 2)
dropouts = hp.Choice('dropout',values=[0.2,0.3,0.5,0.7,0.8],default=0.3)
model = Sequential()
model.add(InputLayer(input_shape=(15360,1)))
model.add(Convolution1D(filters= f_choice,kernel_size= k_size ,activation=tf.nn.leaky_relu,strides=1))
model.add(Convolution1D(filters= f_choice,kernel_size= k_size ,activation=tf.nn.leaky_relu,strides=1))
model.add(Dropout(rate=dropouts))
model.add(MaxPooling1D(pool_size=max_k_size,strides =2))
model.add(Convolution1D(filters= f_choice,kernel_size= k_size ,activation=tf.nn.leaky_relu,strides=1))
model.add(Dropout(rate=dropouts ))
model.add(MaxPooling1D(pool_size=max_k_size,strides = 2))
model.add(Flatten())
model.add(Dense(64,activation=tf.nn.leaky_relu))
model.add(Dense(2,activation='softmax'))
model.compile(loss = 'sparse_categorical_crossentropy',optimizer='Adam', metrics=["accuracy"])
return model
and get the params from the hyperband which is 128 for filter lenght, 3 for kernelsize , 2 for pooling and 0.3 for dropouts. But with the same model in different function, i have error TypeError: unsupported operand type(s) for %: 'ListWrapper' and 'int'
i have run the same process before (i using google colab free tier for this) and using tf 2.5.0. This is the hyperband process:
def hyperband_test(trainX, trainY,order):
print(order)
seeds = 20
stop_early = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=10,mode='max')
model = GetModel
tuner = Hyperband(model,max_epochs=55,objective='val_accuracy',seed=seeds,executions_per_trial=2,factor=5,hyperband_iterations=1,directory='DIR')
print(tuner.search_space_summary())
tuner.search(trainX,trainY, epochs=50, validation_split=0.4,callbacks=[stop_early])
best_hps=tuner.get_best_hyperparameters()[0]
print(best_hps.get('num_filters'),
best_hps.get('kernelsize'),
best_hps.get('pool_kernelsize'),
best_hps.get('dropout'))
filter = best_hps.get('num_filters')
kernel = best_hps.get('kernelsize')
pooling = best_hps.get('pool_kernelsize')
dropouts = best_hps.get('dropout')
return filter,kernel,pooling,dropouts
That worked. Thanks
nvm
i found it and it silly problem
the variable for filter is confused with list type with same name
So, we must define hp.Choice for each filters?
How to unite different queries results?

you can concatenate them together
!docs pandas.concat
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)```
Concatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
Similar names: pandas.pandas.concat
umm its also choice depends on your outcome
in my case i want to check what best value to fill each parameters.
concat(a, b, c, d)?
It doesn't work, I don't know why exactly
What does concat return?
pd.concat([a, b, c, d])
but choice is pretty bad since hyperparams only have chance to choose what value from the list. There are some suggestion by using minimum maximum number as threshold and find what best number for fill the parameters.
a dataframe
Hmm
Would you mind to share the working code, please?
pandas help

what do you need help with?
I have a categorical column mostly filled with integers with occasional lettering. I want to encode this data for my ML algorithm but don't know if I should use Label Encoding Or One-Hot Encoding.
If I use One Hot Encoding, I will get way too many columns since I have so many distinct labels. And if I do label encoding, I will run into the problem of ML algo considering some of the tickets hierarchal
which one would be best to use?
Or better question, how should I encode this categorical column
do these numbers mean anything mathematically? do they measure an amount of something?
mm not really
they are just identifiers
what algorithm do you plan to use? because that's a lot of classes.
actually since this is the titanic dataset from kaggle, the letter probably represents the floor level
what are you trying to predict?
predicting who dies in titanic
you don't need to encode their ticket number for that, since the ticket number is fundamentally arbitrary
here is more info

you want to select features that are relevant to who lived or died.
wouldn't the floor matter?
and that floor is implict in the ticket values
how would you check the correlation? p-value?
you can get information about their financial status from their passenger class.
im a bit new sorry
i see.
if i were to check the correlation between a column and my y-labels, whats the best way to do that?
if there's a way you can parse what deck their cabin was on out of another column, you can add that as a new column.
actually their cabin number is given, but it's missing for most rows. So you probably can't use that.
exactly
i dropped that column
i dropped name and cabin
columns
Yeah, you don't want to use their name as a feature, either.
my intuition is that sex won't matter either.
but like what if there is some weird correlation?
Women and children first, remember?
men were a lower priority for the life boats. I would definitely keep that feature.
interesting
so you basically have to know past data to decided which features are relevant
so if you were to get a new dataset, you would proceed to research about the topic at hand?
yes, you should always get some level of understanding about the problem at hand. In one of my courses, the instructor had to make a model to predict some weird DNA thing that none of us understand, and we all did terribly.
haha i see
do you think i should just drop the tickets column and see how the model performs?
instead of thinking about this in terms of dropping columns, think of it in terms of selecting columns.
hmm
okay so pclass, sex, age, sibsp, parch, fare, and embarked are the columns i would select
i don't even think i need the id column
the id column should be the index, which pandas uses to align rows from different dataframes
but it shouldn't be a feature for sure 😄
but the dataframe is already an index no?
so its basically double counting
like when you do pd.read_csv() it automatically creates an index for all of the rows
a dataframe is not an index, no. each row in a dataframe has an index
thats what i meant
an index is assigned automatically, but you can instead pick a column that you want to use to index.
@serene scaffold has all I want to say so I don't have more input, Tawsif 🙂
bet bet thanks
Maybe you can search how the ticket numbers work and get the deck information from that or something, you can't really use those ticket numbers in raw format
do you know of any resources that talk about dealing with categorical columns that have a lot of labels?
eh not really, I learned this stuff in school
Just use one-hot
or, don't encode them at all
this gonna create like a 1000 columns
label encoding assumes all the categories exist on a scale so thats out
Thats fine
if there's a category with way too many possible values, the model isn't going to learn anything
and it still works?
just skip that feature
you don't have to use all data, if you use too much data maybe it's prone to overfitting
you don't have to use the data from every column.
1000 features is not really that many in the grand scheme of things
i'm just confused as to how to check correlation
correlation of what?
between the feature and your y_label
if each ticket number only appears once, it's just going to add noise.
you can make a matrix of what class instances with that feature belong to.
okayy i see. and then do some sort of visualizaiton?
you can just look at the matrix
lived died
1 20 5
2 10 10
3 3 15
It would look like that
Is the 1000 features actually just the unique id?
i got more questions but ill hold off, ill try it out thanks for the help.
yes, they were wanting to encode the ticket number, which is unique to each passenger. So, it wouldn't help at all.
when you are doing one hot encoding, is it good to call drop_first=True for the pd.get_dummies column? I get that it reduces the number of columns you have, but doesn't it also lose info about the columns?
I.e if you call drop_first=True for the Sex column (pretending you didn't know the other sex), you would have no idea that "male" exists
But you would have the second column still
So if a person is not female in the remaining column, you would know they are male
If it mattered it prolly can extrapolated from the fare too
so it doesn't matter about the column name?
You're trying to one-hot encode the sex right?
Theres not really any difference between using one-hot and label encoding when there are only two options, except that label means one less input
what if there are like 5 options
If they exist on a scale, label encoding
Otherwise one hot with 4 or 5 columns
where with 4 columns 0,0,0,0 would be the fifth category
what part of openai playground homepage would redirect to a page that looks like this

@waxen veldt So if you have 3 categories for instance you could use this:
goat [0, 1, 0]
pig [0, 0, 1]```
or
```cow [1, 0]
goat [0, 1]
pig [0, 0]
I prefer the first option for more than 2 categories, but ultimately it's personal preference

ah i see interesting
if you were to do this, does it not matter what the column name is? since you are essentially dropping the column name
How do you read the 3d dimensions? E.g. 4x4x512, Im guessing last is neurons in layer
It doesn't matter specifically which column you drop, or what their names are, ultimately you don't pass the actual column names into a ML model anyway. The only time you need to save the name of the column being deleted is if you plan on convering the one-hot encoding back to the category name
makes sense
idky as soon as i imported pynput.keyboard and run i get this error

This is why I prefer using all the categories in one-hot, for your sex column, you could use your drop first and rename the column something like isMale or isFemale depending on which you drop
someone help pweeez
it's a lot easier if you provide text as actual text. Whatever mouse is, it doesn't have a click method, so you may have created the wrong type of object.
You have doubly imported controller, one from pynput.mouse then again from keyboard
It's trying to use the keyboard Controller
but it worked before
ohhhhhhhh
i see
@lapis sequoia you could do import ... as ... to give them different names. Like MouseController


Now your keyboard controller will use the mouse
btw, I'm not sure that this is on-topic
Yeah definitely not
this is ai right?
Moving a mouse is not ai
no, it's GUI automation.
you can just open a regular help channel. See #❓|how-to-get-help
ok thank you
why the hell does that matter, as long as the model works?
plus LM's usually pick up a lot of things like medical stuff too
What the hell does what matter? The fact that different BERT models did consistently well?
@opaque stratus If you think it is more reliant on keywords, just try an n-gram based model, it can outperform bert in a lot of cases where there is no structured language
yes
even if its keyword based, BERT still manages to do it - hence "what does it matter"
But he's asking if there is a model better suited for unstructured language
hmmm....you seem familiar 
if something gets good accuracy, then what would be your reasons for changing the model?
Better accuracy? What else lol
well, @opaque stratus you can use something like this https://huggingface.co/fspanda/Medical-Bio-BERT2 but it won't give you much of a boost
Hi there, look for some help with the function scipy.stats.ttest_rel and my data. I have a dataframe with 4 columns and 2064 rows. The rows are separated into chunks of 86, so there is a TON of categories (see the screenshot to get an idea). I would like to find the ttest value between the group and individual columns for v_p and k_trans, but each input to ttest_rel should only contain the rows for each category (86 at a time). I could do this by for-looping over all the different categories in the multiindex, but I was hoping there would be a vectorised way of achieving the same thing. Any ideas of how to proceed?

can someone explain?

actually I realised its 72 different row-categories with each category having 28,66... values on average because patient_catg has variable number of rows per label, if I ignore that one then it's 24 different row-categories with 86 rows per category
2064 is the total number of rows
isn't it just plugging numbers into a calculator? like if you do J(theta + epsilon) = 1,01^3 and J(theta - epsilon) = 0,99^3 you just get the answer as 3,0001
and derivative of J(theta) = theta^3 is 3*theta^2, with theta = 1 that's equal to 3 trivially
I'm not sure. Sorry I can't be of more help but I don't understand the dataset
I have a question too.
I'm training a regressor, the dataset is a combination of 4 systems that produce the same data output. I concatenated the 4 datasets to have more samples.Can I train a model without testing data and only using training and validation data?
Would it be a good practice to use only 3 systems to train data and then test the model with data coming from the fourth system just to test transfer learning?
Should I test the data using cross-validation?
does anyone have a book they can recommend about time series forecasting with NNs?
It might be interesting to do four-fold cross validation and use each dataset as a fold.
Hello, I'm new to machine learning and I'm creating a crawler and it should classify if a given URL is an article link or section link. My use cases are to determine if a web page is an article link is based on the structure of Document Object Model(DOM), because an article link would always have a title and content, and for the section link it is the opposite of the structure of article link's DOM structure.
I'm not yet sure if I should use random forest algorithm to classify a web page or other algorithm to perform a DOM analysis to classify if its an article link or section link. Any thoughts?
because an article link would always have a title and content, and for the section link it is the opposite of the structure of article link's DOM structure.
Doesn't this mean that you can classify the two deterministically?
Yes, It should classify the two deterministically, but I try to focus more on classifying if its an article link. That's why I'm figuring out on what should I use as an algorithm.
don't links to sections within a page have a # or something?
Some links have # and others don't have #. That's why I try not to based on links.
Also when I collect relative links I clean all the links such as replacing from https to http, and disallowing fragments(#) to avoid duplicate links.
suppose you download whatever the link goes to. What about that document determines if it's an article or not?
An article would always have a title and content.

Sometimes section link does look like an article link, because even google news tagged this an article link https://tribune.net.ph/index.php/tag/flash/ even though it is a section link.
That's why I'm not yet sure on what algorithm should I use for this web page classification.
again, I feel like you should be able to decide this deterministically just by looking at the HTML
Well technical you can but it is much better having that third hold out test set to test your model. Remember the model will optimize on your validation set and might overfit on the specific data. Therefore the test set is your way of simulating how it would perform and thus generalize in a real world setting (and avoid overfitting). What you can do however is do the three splits and when you find the best model then do a final model on all data but that only makes sense if the model is to be deployed in a production environment. If it is for a paper it is not an option I guess.
Regards your second question: it depends on your case and data but In general I would say no. I would rather just split your data into train, test and validation based on random sampling. Random split should avoid any systematic bias that might occur e.g. between the systems. Is there any particular reason you wanna use one system output data as a test set?
Oh and regards the third Q: cross-validation is for the training process . It is irrelevant when testing the final model on out of sample data. BTW for clarification - ppl and fields use test set and validation set differently. In my previous answer the test set is the out of sample data
Serious question: Is it possible to code an AI capable of sentience in python? if so, I'd like to try
also where would i get started neural networking
it all looks really cool
idk
@willow gull this is a philosophical question about what counts as sentience, but lots of cutting edge AI is written in python, so it's just a matter of your answer to that question.
yeh
4. Use English to the best of your ability. Be polite if someone speaks English imperfectly.
Sorry
He is my friend
My friend ask me
Something
@hoary spear You are also off-topic for this channel. If you need help with python, you can ask in #python-discussion or claim a help channel ( #❓|how-to-get-help )
No worries 👍
Not the right place to ask, but I recommend first thinking about what sentience is before trying to ask whether something can be sentient (Can you define it? Do others share that definition (what have they pondered on this)? Can it even be defined?).
Surely this is the right place to ask AI related questions considering we don't have a philosophy channel
And @willow gull, what you are thinking of is called a general artificial intelligence, and no, making one wouldn't be feasible without a supercomputer that far outperforms anything that currently exists and decades of research
Is a human as fast as "a supercomputer that far outperforms anything that currently exists"?
I'm strongly of the opinion that we have more than enough compute power (way more than enough). We are just doing it wrong.
I would say a brain does outperform a supercomputer, yes
Based on much simpler life having complex behavior that we fail to replicate.
And that creating a human-like general AI would require the simulation of a brain, which is currently impossible
Yeah
It will be around for 20-30 years later by predictions
And ASI will come in ???
I believe the biggest problem is not compute power, but rather that we are trying to catch up with millions or years of evolution (so much data and iterations (and reality is much more complex than any simulation)).
In many ways, we are data bound.
Also how do we make the AI think like human
Human thinking is so complex
Thanks to God, we can think better
This implies that an AGI must think like a human to do any human task, which could easily not be the case.
What beyond ASI 
ASI implies that it surpasses humans, but it does not need to surpass humans to do any human task.
Imagine when AI can think sooooo fast that i run out of "o"
Also it's very hard to tell what it even means to "surpass" at that point.
Like it can learn a entire new galaxy on 1 sec
It can't do physically impossible things.
If my pc run that task then ill make sure we have a double sun
They can find a way to go through atom
Maybe
So you can assume it will find something like that, but based on what? How is that better than the prediction that it can't do things that seem very physically impossible?
or instead learning what have learned they just... learn new things that human have wall to reach
Like when space become big so the expanding speed goes vroom vroom then humans will probaly stuck
ASI will know things humans can't understand, but all because a worm can't understand calculus does not mean that we can do physically impossible things.
What if they learn us that us dont know 
(just based on what we know, which is all we can go off of, everything else is just hopeful fantasy)

does anyone know, why the code is not working? it gives "error: I: conversion of 1.0001 to octave_idx_type value failed" error
how?
I wouldn't see it too much of an issue; seeing that even if we have an intelligence that can demonstrate near-human thinking capability virtually, why it won't be able to learn as a robot from our surroundings too
Well, it's hard to make any real direct comparison, because a brain is so vastly different to the Von Neuman architechture that a computer uses, you can't really say the brain is better in terms of computing performance since they work so differently, so my claim that it does outperform is dubious. That said, at being a human brain, the human brain does indeed outperform any supercomputer, unless said supercomputer is capable of perfectly emulating a brain (which currently hasn't happened)
TL;DR You can't really compare a computer to a brain, only to an emulation of a brain running on a supercomputer, and we can't do that.
if we could figure out how reasoning in the brain works we wouldn't be so data bound. trained ML models are just software encoded instincts, and instincts develop with experience thus the need for data
Hi, I am working on a time series model which should predict after how many days or months vaccination will be complete in India. I am applying Neural Prophet Model. I am able to predict vaccination dose for future but I am bit confused that how can predict days or months on which vaccination will be completed Acc. to population in India. Here is my notebook:- https://colab.research.google.com/drive/1DOaNNunweNo_GDs6GU6fQuaZCCTdbXmK?usp=sharing please help me how should I proceed further and does my approach is correct.
according to neuroscience, the most processes of a neuron are for its life-support capabilities since they are few of the most valuable cell types in the body. for the 150k cortical columns, even replicating 10x the amount would be doable on a supercomputer due to its sparse nature which makes computations a piece of cake. the real problem is processing the SDR's (basically Sparse matrices) but we don't even need FPGA's for that - current CPUs are really efficient for sparse ops.
overall, its more towards the understanding and the need of a universal frameworks that accounts for the processes in our brain like an equivalent to the 3 laws of newton for physics. previous attempts at making a framework were not very good but newer attempts lie HTM and SNNs are good for a start
previous attempts tried to explain the data for their experiments which has been conncluded to be not the best approach for complex systems - as demonstrated by General relativity.
guys, i have two columns on a Dataframe where the cells of the columns are lists []
and i need to get the index and the name of the column where has one value, like the img bellow
i tried: db[['wts_id', 'wtb_id']].apply(lambda x: x.map(set(['123456']).issubset)) to get this img but idk how i can get the index and the column where the True is and how to do a If statement to check if has any True on this Dataframe, i'm kinda bad using apply and map =/


Hi, what's the best way to make a shelve file into a pandas df?
The shelve file is in the form
key:dict
and i want the df to be made of the keys and values from the dict.
here's what i am using now but it's very very slow
import shelve
import tqdm
with shelve.open('dbfile') as db:
for key in tqdm.tqdm(keys):
df = df.append(db[key],ignore_index=True)
hello, can someone help me with darknet yolov4 on google colab?
i'm getting an error and it makes the kernel crash,
ping me if anybody can help
You should post the error message so that people can see if they can help.
alr
this is what happen

give me a sec, ill put in the code cell that i run when this happen
# import darknet functions to perform object detections
from darknet import *
# load in our YOLOv4 architecture network
network, class_names, class_colors = load_network("cfg/yolov4-obj.cfg", "data/obj.data", "mydrive/yolov4/backup/yolov4-obj_1000.weights")
width = network_width(network)
height = network_height(network)
# darknet helper function to run detection on image
def darknet_helper(img, width, height):
darknet_image = make_image(width, height, 3)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = cv2.resize(img_rgb, (width, height),
interpolation=cv2.INTER_LINEAR)
# get image ratios to convert bounding boxes to proper size
img_height, img_width, _ = img.shape
width_ratio = img_width/width
height_ratio = img_height/height
# run model on darknet style image to get detections
copy_image_from_bytes(darknet_image, img_resized.tobytes())
detections = detect_image(network, class_names, darknet_image)
free_image(darknet_image)
return detections, width_ratio, height_ratio
i re run it again but still end up with the error

OOM?
Seems to crash when trying to load the weights, if I'm reading the order of events correctly
i found a github issues and it says it can come from ipython
but i tried the solution and it didn't work
here is the page: https://github.com/googlecolab/colabtools/issues/513

GitHub
Bug report for Colab: http://colab.research.google.com/. - Describe the current behavior: Session crashes, then restarts and then crashes again for an unknown reason every time I try to run any cel...
ill drop my question in here as its less of a direct question and more of a small discussion of my options in my situation:
im writing a script that takes 16-bit grayscale .tiff images as input and is supposed to run some analysis on them
the images contain a bright spot and some background noise which should be relatively weak, compared to the spot
i want to do cross sections that go through the brightest area, plot these and display a colourmapped version of the image, where i drew in straight lines of where the cross section is happening
i already have all of that up and running but the code is in desparate need of optimization
if the intensity is just a little on the lower end, the algorithm is no longer capable of finding the brightest area and places the cross section in the weirdes places
and if rhe intensity is just a bit too high, the spot in the colourmapped image will no longer have a clearly visible maximum, but just a big yellow smudge at the center (making it hard for me to estimate how good the algorithm nailed the brightest area)
this is the section of my code that looks for the brightest area
i didnt just go ahead and look for the maximum as the background noise can create random "hot pixels" where a single pixel has a peak value that i dont want the script to bother with

so i went with averaging areas of high intensity (the algorithm would fail if multiple spots were present but there is only ever one to be analyzed)
imgarray is a 2D numpy array that came from the .tiff and can have values from 0 to 65k (all int)
and this is my colourmapping which could use some improvements too

btw i for the threshold i tried any values between 70% and 99% and no value was good for all input images
though 70% and 80% usually yield the best results if the intensity is sufficiently high
is there an efficient algorithm or function that lets me search for the square shaped area in an image of a given size, that contains the highest overall intensity?
Hey guys anyone active here ?
I can think of a brute force approach that could probably be optimised with a bit of clever thinking, though this isn't really an AI approach
yeah i could also think of brute forcing it but it would slow down the code significantly
and idk if i have much to gain from it
If you just start with a square the size of the image and slowly decrease it until you reach peak brightness
It shoould end up with the optimum solution
unless you do have two large blobs
What is “Letter Distribution” and what is “Word Distribution” in NLP dataset while preforming Exploratory data analysis(EDA)?
can you tell me how to perform it i am new to data analysis and this dataset is my first nlp dataset
i mean it depends on what you are trying to do but effectively its counting the frequency of each letter/word
if i will share my dataset can u help me just like an example on cloumn 2 ,index 0
because i am stuck on this issue from 2 days


Another think you could try is filtering out the noise
it is already being filtered out, some noise seems to remain
particularly these annoying hot pixels
How large are these hot spots of noise? if they are 1x1, they can easily be filtered out
usually 1x1
just check the pixels left and right , above and below
if >2 are dark then its noise
good idea! ty!
You could literally just count the occurence of each word/letter for each tweet, and figure out whether they mostly occur in negative or positive tweets
You'd likely be better off using words
meaning (i didnt get what u mean about"better off using words")
Letters on their own probably wont reveal much insight, for example does the letter "e" have a positive or negative sentiment?
What about the word "bad", that generally is used in negative sentiments
no i havent done it before
then you should probably start by looking at an NLP basics course
would suggest you go through a bit of supervised learning before you go through NLP and sentiment analysis
Worked with a similar dataset before
Remember to threat the special chars right
Anyone familiar with XGBoost?
Good resources for building a dahsboard ?
Start with the book "deep learning with python", there is a good example on NLP.
Send me a DM if you decide to use BERT. I did a project on bert and it took me 2 weeks to figure it out, lol.
Maybe I can save you some headaches.
Yup
what is it?
I am getting Linear regression accuracy as 100 percent...is that possible? Or maybe I messed up with data sets?
An efficient implementation of gradient boosting. Here is a fine article about it https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d

Medium
The new queen of Machine Learning algorithms taking over the world…
oooooo
In theory it is possible but I wouldn't have confidence in that performance (without knowing anything about your project)
Try running your model again. If it's an outlier, it'll show.
I had done a dumb mistake... figured it out 🙂...now it's showing around 90 percent accuracy
Thanks for the link!
When using XGBoost for regression, do you process the data as lagged features? Or do you just slice the columns out of the dataset and set it to the target
It's confusing because some tutorials are shifting data into lagged features and other just separate dataset into features and targets and train the model directly
It depends on your regression problem. Is it time series data? And by lagged features do you then mean making a sliding window? So that features from time t is predicting a target from t+1? (Which is one time unit into the future) . Maybe a short description of what you are working on and trying to predict would be helpful
Yes, it is a time series problem.
The model is a wind turbine and I have temperature, wind speed, power generated, position of vane, etc. I want to build a regression model to predict power output with a time horizon of 12 hours.
I did this, I have a function that shifts the data and concatenates the two dataframe on axis one.
So I end up with Dataframe ( [Features (not shifted),Targets(Features but shifted)])
All the sample code I found online are toy codes predicting boston housing prices but they don't do sliding window to preprocess data, which is confusing.
where can I get started making AI?
Then the Boston demo project probably isn't a time series problem? And therefore they don't need to do sliding windows
ok then
So, for a time series problem using XGBoost I would need to slice the target data out of the features dataframe and do sliding window only on the target data pull out of the dataframe and use my target data unshifted?
Yes a robot should be able to, which is kind of the point. How many people are working on online learning with a real physical robot? Not many compared to the gigantic amount of people just doing say, deep learning (which can't do online learning, too slow, needs too many iterations, and i.i.d. stuff).
Also correct, with good priors we can reduce the total amount of data needed. But the question is how to encode those without something like an genetic algorithm finding them. Some have spent decades trying to hard code in all human logic only to give up in the end.
Basically, learning to learn is very important step for the robot which is still unsolved.
speak english please i just woke up 
Informations, logic, it all comes after
Wen we start living we don't learn by looking at data
We learn by interacting
Doing so we learn how to learn
For example, reading and understanding
heh
That is data, but yes, there is a feedback loop not present in the type of machine learning most are used to working with which makes it a very different problem (and much more difficult).
this whole conversation is confusing ngl imma just sit back and eat my grapes
Sorry, I know that is data, I meant, we don't learn by reciving data and analyzing
I agree
To start overcoming this I had to design a whole new algorithm
so about how accurate can an AI be?
It's unconscious yeah. We go backwards, reach reasons from conclusions. The conclusions are already present unconsciously. Consciously is when we go the other way around, reasons to conclusions. And for some reason we are self aware of that part of the process.
Reasoning is still to ahead
That's not the first thing to do
Reasoning is a skill
i just wanted some resources 
Shh we're in the middle of a philosopical AI conversation!
By the way
What kind of resources you need?
something just to start making an AI
i learn quick so that should be all I need
fastAI
k ill look it up rq
https://docs.fast.ai/
this one right?
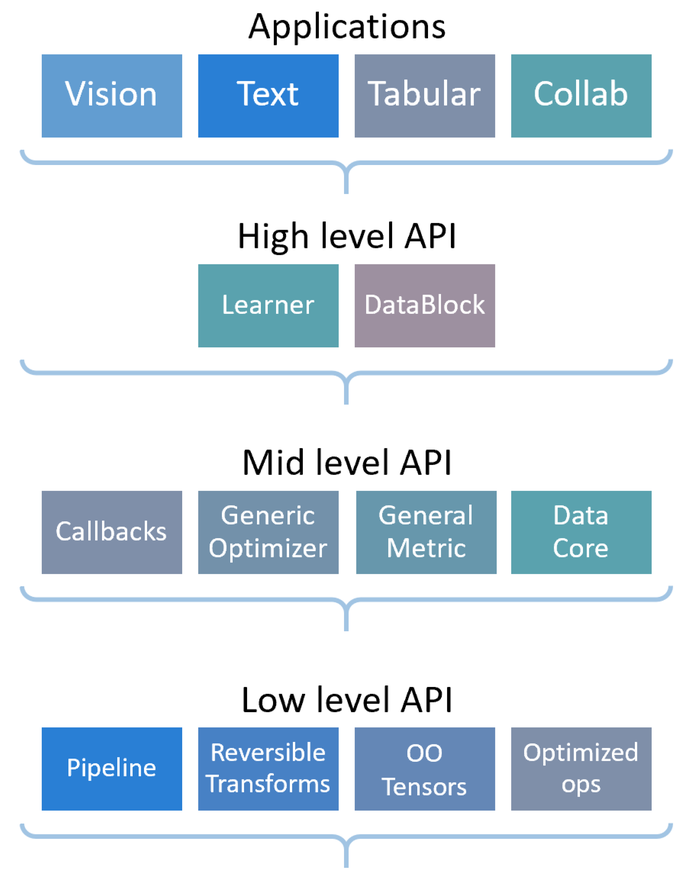
fastai simplifies training fast and accurate neural nets using modern best practices
Yes
mk
Yeah, first comes something more like RL or UBL. Then reasoning somehow intermingles with that later and in different ways in different organisms (or not at all).
RL is just a building block
Alone cannot lead to something "cool"
Yeah which is where something like a genetic algorithm comes into play or UBL.
Entropy maximization, etc
In my experience genetic algorithms were pretty much useless
In my experience, since we are here, they created something interesting. But we can't employ one in reality without well, letting it do its thing for a couple of million years and that would require at least robots that can sustain themselves.
My problem was, that don't were flexible enough
Running a "search" for everything is "expensive"
I designed something that could adapt in a couple of frames
(if the task is simple)
And, if there are not too many layers to handle
Have you done such a task in real life on a real robot? There is this funny thing where ML algorithms that work in simulations do not translate at all to reality even in a very simple setup (by that I mean, untrained, learning only from reality).
Not yet, working on Gym
Some days I "ship" multiple version of the algorithm
I'm working really fast in this stage
Cool, yeah, if it does not even work in simulation then it won't IRL, so make sure it works there first, not waste time with a physical robot yet.
(And setup)
It works
But there's currently an annoyng bug
Have to rething a function
What kind of "experiments" have you been doing?
@iron basalt
Or, are you just trying to figure out where to start?
In behavioral science, a T-maze (or the variant Y-maze) is a simple maze used in animal cognition experiments. It is shaped like the letter T (or Y), providing the subject, typically a rodent, with a straightforward choice.
T-mazes are used to study how the rodents function with memory and spatial learning through applying various stimuli. Start...
Cool
All the gym stuff, but those are much easier than real life stuff like that (but a good sanity check on a new algorithm).
I agree
I have a couple of bots
It would be fun mounting the algorithm on them
I'll do it
We also specialize in machine learning that is very fast and needs little memory, while still out performing other much most costly algorithms.
So we run our algorithms on stuff like the pi zero.
What do you mean by "we" are you part of a research team or something?
I think that my algorithm would work there
Yes, but I don't feel like revealing identity at this time.
Yea, actually some of the main things to overcome in terms of speed is just being able to process the camera data at all.
Gotta use the little integrated GPU to at least downscale.
Oh that would be painful I think...
(I mean, making a learning algorithm work with images on a pi zero)
Yeah, some of the models don't perform well. I am working on a transfer learning problem and I will "enhance" the model with a mathematical model to see how it works.
Yea ours does online learning on a pi zero at about 70 fps. It required not using the python pi camera library because it was too slow (made our own).
But the model is of course very small. Which kind of helps us push the algorithm forward though. Do more with less.
While also still running it on a big beefy machine to see how it scales.
I wish you best luck
If you have something cool to say send me a dm, always open to learn something cool
if we do develop a close enough simulation of a brain - what's stopping it from doing online learning provided the robot is connected to the servers?
@grave frost By the way, I think that this might interest you: https://www.epfl.ch/research/domains/bluebrain/
EPFL’s Blue Brain Project is a Swiss brain research Initiative led by Founder and Director Professor Henry Markram. The aim of Blue Brain is to establish simulation neuroscience as a complementary approach alongside experimental, theoretical and clinical neuroscience to understanding the brain, by building the world’s first biologically detailed...
It aims to recreate a virtual "biological" brain
It is something big
looks good on the POC part
I know
it really doesn't matter what theory we take for WBE - its just different paths for the same goal
So you know how a biological organism must obtain food to stay alive? All interesting behavior comes as the result of that need. A robot has no such need by default so one would need to craft such a need that would lead to something interesting. Which is not very easy to do. But other than that, yeah sure. But I don't think we need tons of compute power to even do this. We don't need to simulate it at such a fine detail level. We only need the motifs (and maybe a few details like micro columns, grid cells, etc).
the more important thing is to keep the funding flowing 🤣
hm. we could easily "replicate" this need by knowledge. i.e the more objects in the world it can predict exponentially more the reward
basically how humans do it
Not sure how easy that would actually be to implement, nor if it would give the type of behavior desired (on its own).
But if you think it can work, please try it.
(And maybe write something about how it went, and if you think you just did it wrong, or the idea was wrong)
(Or maybe it needs a little something more)
hello guys , need a little help , anyone here know about datasets in h5 files , need to finnish a project and dont have much time , a little help is appreciated
basically how DL's probablity distribution represents the "confidence" of predictions? A reward for creating a model of the world (like how balls bounce, how carpets roll, how the sun appears from a certain point, how the notes in a music piece change etc.) and predicting it reasonably correctly & confidently would give it a positive reward and would endow human like behavior.
That is, if its brain is reasonably complex to atleast match human level abilities
like I am in much of a position to do that lol 😁
So you are rewarding it for having a good world model. We already have a pretty good world model in our algorithm (dare I say beyond SOTA), but it's just that, a world model. There is still missing the part where it learns to use that model for something interesting.
Hence stuff like the T-maze. Can it use the world model to navigate the maze?
I currently believe that anything that forces the robot to switch locations will result in interesting behavior simply because getting from A to B is difficult in a real world environment, especially a dynamically changing one.
(And will make it use its world model)
I believe complicating it would yield more complex behaviors; A reward for learning the model of the world + a reward for meeting basic requirements (surviving, obeying human implemented instructions etc.) + ...
the more we add, the closer we simulate a human being in a hope that it would gain that much intelligence atleast, if not ASI
Yea, there is the possibility that it's just a ton of different things in a giant mix. Our current robot learns the world model, and also gets a reward for finding the cheese (T maze), and also for finding unique states.
Well we have multiple versions, thats the RL one.
gridworld?
No, real life T maze. https://en.wikipedia.org/wiki/T-maze
In behavioral science, a T-maze (or the variant Y-maze) is a simple maze used in animal cognition experiments. It is shaped like the letter T (or Y), providing the subject, typically a rodent, with a straightforward choice.
T-mazes are used to study how the rodents function with memory and spatial learning through applying various stimuli. Start...
does sound like a great test for a POC
(and more complex mazes too)
what fundamental theory are you using for the "brain"?
Jeff Hawking
something proprietary/new?
It's new and proprietary yes
well, do send us a paper here!
When it does that maze like it's nothing I will def. send you something to look at.
Until then, we change stuff so rapidly (daily), that it would be a bit of a waste of time to write a long thing about it (since it can become completely outclassed the next day).
but the basics are near/like HTM? so what would be different?
It's more like Jeff newer stuff. Or actually we bounce off of each other*
We cite each other*
ooh, sounds pretty interesting 😉 now I am curious about your real identity, but that's for another time ig 🙂
note to self: check Jeff's citations for patterns
anyways, do update us on any new progress 
Does anyone know how I might utilize my GPU to train tensorflow models and speed up the training process?
are you using colab or your own local system?
IDLE locally
REPL
Just training on those MNIST images. First time doing this.
You need to install Cuda toolkit, Cudnn and tensorRT for faster inference
is that available via pip?
Also first of all you need to install NVIDIA drivers
Just latest drivers or drivers specifically for ML?
no
you need to install them from official nvidia website
just latest drivers
https://www.tensorflow.org/install/gpu
steps are well described here
TensorFlow
you also need cuda and cudnn
Yeah, thanks, it's all at that GPU support link
yeah sorry i was scrolled up and didnt notice they sent the link yet lol
Now if this gosh darn training would stop running on my CPU so I can test my GPU!
I didn't realize 5 epochs would take so long.
Just close IDLE you say?
you can use ctrl c to cancel it
hmmmm....
thats the standard keyboard interrupt key for cancelling any python programs
Not a bad idea
and even most non-python programs as well
In Linux I'm familiar with this but am on Windows rn and that hasn't always been the case. Will try it, though.
Do I need to specify the GPU when I re-run it, or will it default to the GPU if it's available for use?
it should default to gpu
okay thanks
i wouldn't recommend using IDLE for advanced stuff btw
it would be better to switch to a proper editor/ide like vscode or pycharm or something
Thanks, but I'm aware. Just trying to get comfortable with the basics of setting up a DL model. I'm also working in Windows atm when I normally do work in Linux.
setting up / training a DL model
yeah linux is much better for that stuff imo
Yeah, I'm being a little stupid right now.
I am using Pandas to pump data into a csv. Is it at all possible to format a column in the dataframe using split? What do I need to Google by chance?
I think this will do it. Thanks. https://stackoverflow.com/questions/14745022/how-to-split-a-dataframe-string-column-into-two-columns
@austere swift Do you know how long it should take to train this MNIST dataset with 5 epochs using something like an RTX 3080?
depends on model size
This is going to take a while. I did not expect it to take this long.
It's just the basic tensorflow tutorial.
on my A6000 (which is about equivalent to a 3090 in terms of compute speed but double the vram) takes like 4s per epoch
thats on a basic dense model though
Then it seems like there's something wrong then.
how long is it taking?
This will take over an hour at this rate.
how big is the model
also check task manager and see if your gpu memory is being filled
It does appear that the GPU is using almost all 10GB of memory
It's this model below. I'm not sure. I think it's like 128 images or something.
https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/quickstart/beginner.ipynb#scrollTo=DUNzJc4jTj6G
But it's those low-res MNIST images.
that should not take that long
thats smaller than the one i was saying took 4s per epoch
yeah, and a 3080 isn't that much less performant than a 3090
let me test this code on my 2080 super and see how long it takes
Okay, thanks.
4s
per epoch
so it should be 4s on your 3080
are you running the code exactly how it is?
Wait, why does it say "Utilization: 0%", but then the graph shows it almost full?

Yeah, character for character
windows shows utilization for different gpu "engines"
the cuda engine isnt on there
in most cases
so it wont show it
oh okay
Well, I know my GPU can handle some massive 3D files, so I don't think it's a GPU hardware issue.
what cuda and cudnn versions
11.4.0
use 11.2
oh i didnt even know 11.4 came out
its in the https://www.tensorflow.org/install/gpu
It came out in june
TensorFlow supports CUDA 11.2 (TensorFlow >= 2.5.0)
Doggamnit
okay
does it matter which version of 11.2 I use?
okay
like 11.2 vs 11.2.1 doesnt make a difference
Okay I'll just download latest 11.2 then
yep
I did install / re-install the latest drivers AFTER installing CUDA. Would this wipe out the CUDA installation?
okay
Does it matter if the cuDNN version is newer than that specified on that GPU support page?
the problem is the link takes me to the latest version
yeah okay i found it
@austere swift Do you know if it's going to be a problem if there is an 11.4 folder in addition to the 11.2 folder inside the CUDA directory?
there shouldnt be
okay
i personally have 4 cuda installs
So tf should just get the proper version?
yes
okay
alright, let's test this bad boy out
Okay, well, I guess we'll see if everything is hunky dory in a moment.
the epochs should take like less than 10s
So, this seems kind of weird to me:
The loss function for the untrained model has returned different numbers every time.
Should I be concerned?
no that's normal
okay
@iron basalt a gedankenexperiment - suppose you put a healthy human baby in a building full of insane people and suppose it's brought up completely by them. do you think despite being normal and having no defects, the baby would still be like them and act like them?
if you think from a human perspective, it seems the only reward we got early on was replication. if we learnt to say something the way parents say then the baby would usually get a human equivalent of reward.
We have knowledge distillation for approximating algos. It seems that suppose your model can 'learn' enough from it's 'parent' in a compute efficient manner (just like knowledge distillation). Thus, supposing a parent to be a sufficiently intellgent algo say a GA. then on simulating the movement of the GA with the least tries would be deserving of a huge reward.
it kind of feels like cheating, but suppose it sees enough amount of mazes and learns to replicate its so-called smart parent enough. Wouldn't it generalize pretty well to the mazes - hopefully enough to do online learning and understand enough about maze topology to atleast solve it at a PoC level?
tbh it depends on the algo you would end-up using. but I think the idea of a having a critic/parent would be a simple idea to perform this computationally effectively while having it evolve complex policies from its parent to be rewarded upon succesfully mimicing a parent enough to navigate the maze and get the cheese.
I would think dervivatives of this raw approach might serve you well for having a simple model that can learn with a simple reward that basically defines "intelligent" atleast at a naive level.
BTW sorry for the long wall of text 😅 just had a suggestion that might be helpful
@austere swift Still not done with first epoch yet.
Steps get progressively slower
on step 1291 out of 1875
What other specs of your system?
Ryzen 7 5800X CPU, RTX 3080, 32 MB DDR4 3200 RAM. nvme 1TB SSD
Python version 3.9
32 MiB 
A lot or not enough?
32 mb ram
yeah, 32 mb ram
32 mb
I’m pretty sure you have that wrong lol
megabytes
are you sure
100% sure, yes
Lol yeah
gigabytes my bad
Anyways that should run fine
Yeah, I don't know what the effing problem is.
It runs AAA games at ultra settings perfectly fine
I was just double checking it wasn’t like a 10 year old dell optiplex or something stupid like that
lol no
I've got like 15-20 tabs open in Edge, but that shouldn't be the issue.
It's only using 10.3 GB of system ram atm
jesus
That does seem like a lot doesn't it?
okay i've scrolled up to read the fullest of the context
i think nvidia-smi is the only way to know for sure if your model is indeed using your GPU
hmm so it is being used
real solution: use linux
I could switch over to Linux. I'm thinking of trying that. I have Ubuntu installed on this machine.
I'd have to download all the drivers again, though.
Okay, eff Windows. I'm going to get onto Ubuntu.
Windows should still be able to run this, though.
I don't like not being able to do this in Windows also.
it's just a matter of how much hassle you're willing to go through to get it working on 🪟
Wow, got onto Linux and now my display settings are effed up. WTF!!!

It doesn't even recognize my main monitor
Anyways i think we are getting off-topic to this channel here
for linux related stuff #unix exists!
my favourite channel
I've no idea if you fixed this already but you're doing something wrong because I was able to train on mnist with my laptop CPU in no time
I'm just entering the code as it shows up in that tutorial
into the Python REPL
Python 3.9
I have not fixed it yet. I'm installing CUDA drivers in Linux right now.
@austere swift Runs all 5 epochs in about 10s in Ubuntu first try
windows is shit
:)

.
i've had a ton of random bugs in windows that just were gone in linux
It would probably still be running in Windows if I hadn't stopped it.

Medium
Money-free make your home more secure just using your pc



“Data Analysis with Python: Zero to Pandas” is a practical, beginner-friendly and coding-focused introduction to data analysis covering the basics of Python, Numpy, Pandas, data visualization and exploratory data analysis. You can earn a verified certificate of accomplishment by completing assignments and doing a course project.
i want to ask about Earlystopping strategy. Some people said that put val_accuracy with max objective and some using val_loss with minimum objective. In hyperband original paper, they using val_loss as earlystopping objective. But most tutorial around web using val_accuracy as objective. What is the drawbacks and your suggestion about the strategy? I using val_loss to follow the original implementation with 10 patience.
there won't be a big difference in using val loss or val accuracy as the early-stopping metric
the thing is, they are kind of loosely correlated, and mostly whenever val loss increased, accuracy decreases (not a hard rule, but most of the time this happens)
but as far as i know, the loss can be bigger than 1 but cannot be 0 and accuracy must lie between 0 to 1. There's some test i done using both, and val_accuracy have tendency to give higher outcome in accuracy and F1 compare with val_loss.
then ig you can go with val-accuracy. a lot depends on the nature of the dataset for these kinds of things, so...
i'm lack of scientific reference for this...
and also about usage Batch Normalization instead dropout
Can a fresher with intermediate python along with average-level dsa get a job as a data engineer? given that all the backend stuff will be learned. what are the projects that one have to do, I mean whether python projs or projects with backend stuff like that in kaggle.com. please share your opinion
@fathom slate what is a fresher?
hey, i need some pointers for a keras model i've build that i want to train with a generator
i'm using tf.keras.utils.Sequence for the generator
class DataGenerator(Sequence):
def __init__(self, data:np.array, batch_size:int=1):
data = scaler.fit_transform(data)
#sample = data[np.random.choice(data.shape[0])].astype('float32').reshape(-1, 1)
self.data = data
self.labels = labels
def __len__(self):
return 7
def __getitem__(self, idx):
# yield [imgs, cols], targets
return np.array(self.data[idx:idx+2]), np.array([1,1])
for now it should just return two samples with a single label to make it work
the issue i run in is ValueError: Input 0 of layer sequential is incompatible with the layer: : expected min_ndim=3, found ndim=2. Full shape received: (None, None)
what's happening here?
a person looking for job without any experience. atleast, that's what they call in my country.
I don't think it's likely that you could get a job as a data engineer without a degree.
Go ahead and ask your question. Even if there's someone here who knows dask, they shouldn't need to interview you to get to the question.
I think you got me wrong here. I like to restate that "a gradute who's just completed his/her bachelor's programme applying for their first job would be considered as a fresher."
ay, that's an indian term
yea, kaggle would serve you well even if you can't score well in the comps
indeed it is
Restate? I don't recall you saying that earlier. Anyway, I can't comment on the job market in India.
you would need to be quite competitive if you areindeed in India, due to the low demand for indian jobs and high supply - especially in DS which almost everyone i s doing
Thank you for A2A
keep in mind tho that kaggle doesn't have "backend stuff". kaggle is purely DS/ML which may perhaps not be much of an achievement because 1. its not widely recognized among indian HR 2. it doesn't gurantee knowledge in managing databses, sql etc. which are often crucial skills.
Yes, you can. Focus on learning about DB systems, SQL, python, Scala, functional programming, etc. Kaggle is not a necessity for data engineering.
why using a cnn instead of a capsnet?
guys i get this error
Unable to allocate 288. MiB for an array with shape (23, 1640597) and data type int64
What can i do
All i did was try to upload a dataset to pandas
Hey guys, say I have a table of people with multiple datapoints such as their hobbies, favorite store, and favorite car. What algorithm is the best to rank the closest matching people to any record in the table
what os
Windows
This only happens with pycharm
When I do it with Jupyter lab I don't get any errors but the program just crashes
what python version 32 bit or 64 bit?
can you try changing the dtype to uint8 or would that mess up some data
Let me see if they will work
How do you general work with large data sets
The one I am working with is around 4gb
let me see if I get this
np.zeros((156816, 36, 53806), dtype='uint8')
-------------------------------------------------------------------
MemoryError Traceback (most recent call last)
<ipython-input-26-9392083af14d> in <module>
----> 1 np.zeros((156816, 36, 53806), dtype='uint8')
MemoryError: Unable to allocate 283. GiB for an array with shape (156816, 36, 53806) and data type uint8
hmm
let me try something
works now

:)
I changed it to always overcommit mode
idk how to do that on windows tho
on linux it's echo 1 > /proc/sys/vm/overcommit_memory
no idea
is there any way to change it in windows?
that so post should have for windows
I don't think making it uint8 would do anything tho u can try
I was trying to follow the method, but it doesnt give me the option run as admin
um if you right click does it not show Run as Administrator?
But it works normally
So I'll try it with that
Yeah it doesn't give me the option when I right click
¯_(ツ)_/¯
maybe i can break the data down into smaller chunks
thank you for your help @undone flare I really appreciate it. I am not very at tech haha
hmm yea maybe
or you can remove something which won't help you much in data analysis
right I am just using a corelation matrix and removing all the attributes that dont make much sense
when are you joining google brain? ( ͡° ͜ʖ ͡°) ||/j||
Guys, I have a question, I seem to have the concepts mixed.
When talking about regression, regression estimates based on the correlation of the features while time-series estimates based on extrapolation, correct?
Then, if regression uses correlation, why it is considered in machine learning a "regression" problem and not a classification problem.
I know it's super basic but I'm a little bit rusty.
is this why when training LSTM networks, 2D data must be converted into a 3D dataframe? To work the problem as regression in one time step and as a time-series problem in multiple time steps?
hey guys
in my jupyter notebook
it's not showing gpu
i already downloaded nividia cuda
also tensorlfow
show gpu - 0
i have RTX gpu
pls treat as urgnet
@bitter kayak no one is replying : (
it's urgent please
i also have lot's of work today
i'm in stress
cuda errors are the worst lol
use colab my dude
what
i already have my own gpu
?
if it's urgent hire someone, this is a discord
try pytorch-- it comes with its own cuda binaries so it should work even without you installing cudatoolkit
unless of course you are missing drivers for the card itself-- at which point, download the drivers
Ubuntu wouldn't boot today after installing the CUDA drivers. Managed to get it resolved (at least for now), but it seems like the common thread here is Nvidia. The immortal words of Linus Torvalds never rang truer than now.

ah drivers already downloaded
im working on a project involving using reinforcement learning on battlegrounds with hearthstone. im trying to code an environment for it in openai gym but i cant figure out how to deal with mouse control. anyone got any advice?
any video?
you'll recommend
Sounds like you're coding game hacks.
it's a masters project that i have no intention of releasing to the public. would this be a problem? i never considered the ethical issues...
If it breaks terms of service, it's not really something people are supposed to be chatting about in here.
Maybe you should consider a project that can't be so readily used for unethical purposes.
I'm just saying your project may have more future value if it had some market potential. I know people make money off game hacks, but it's not really something you can talk about out in the open in a lot of places.
well my other idea involved detecting network intrusions using a system log. This seemed like it had already been done numerous times though
Can someone help me in #help-pineapple, just me being a idiot, but i dont know how to fix
need some advice for object detection modeling. Which is better for large datasets: Gluoncv, pytorch, or tensorflow?
i wanted to build a ordinal log regression model but i cant find a working guide. i tried using from statsmodels.miscmodels.ordinal_model import OrderedModel for statsmodel but it seems like it is no longer supported. Anyone know how i can run a ordinal log reg in python?
even from mord import LogisticAT doesnt work
anyone here know how to write good airflow pipelines? do you have a repo you can share? thanks!
0 indexing mate
i have 2 GPUs they show up as gpu0 and gpu1
well no, there's tools that predict % of winning a battle that hearthstone-sponsored streamers use
with an in-game overlay
Blizzard doesn't consider that cheating
how can i solve then?
solve what
if you're using tf try tf.config.list_physical_devices('GPU')
if they show you anything but False then you're good to go
and ensure that your tf is built with cuda
check this by doing tf.test.is_built_with_cuda
0 gpu found error
have you checked if your tf is built with cuda?
Does anyone have experience with Apache spark (Pyspark). Have some small general doubt
Or if anyone is currently working as a Data Scientist or for a company that's into retail analysis ?
i don't how can i ?
i am new to ML
pls help
What would you like us to do?
Hey guys, I am using Gekko to try to solve a Mixed Integer Optimisation problem for a hobby of mine and it is worked somewhat well I think, as in the answer is at least reasonable but when I try to read the debug... Well because I only learned it a surface level I am not sure how to read it and some things seems weird? That is mostly when I increase the domain the optimisation has to go over but regardless, does anyone has like a solid article that would point me in the right direction for understanding well the results bellow?
And the weird things are for example:

It is a maximisation problem, why is Iter 2's obj lower (less negative) then the first one
and also, if I set one of the equations which just says a couple of variables have to be lower then X, where if those variable's are higher then X it has no change in the answer, to a very high number... Say from 100 to 100000, the obj gets even lower. Still the solver only shows me 2 iters
But then if I increase the Max_Iter option to 1000000, it goes back to giving me the previous answer, although still only showing 2 iters and with the first iter having a higher (more negative) obj then the second one
Anybody encountered this?
NotImplementedError: Layer ModuleWrapper has arguments in `__init__` and therefore must override `get_config`.```
From what Ive read it can pop up if theres a custom layer, but I dont think Im using any
```py
model=Sequential()
model.add(Conv2D(128, 3, activation='relu', kernel_initializer='he_uniform', input_shape=(256,256, 1)))
model.add(MaxPooling2D())
model.add(Conv2D(64, 3, activation='relu', kernel_initializer='he_uniform'))
model.add(Conv2D(32, 3, activation='relu', kernel_initializer='he_uniform'))
#model.add(MaxPooling2D())
model.add(GlobalAveragePooling2D())
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer=
Adam(learning_rate=0.01),#,momentum=0.9, clipvalue=0.5),
loss='binary_crossentropy',
metrics=['accuracy'])```I found that the problem is in GlobalAveragePooling, but i dont see how its a custom layer
Solved: mixing up layer and model from keras and tf.keras
Anyone have any good resources on formatting a column in a Pandas data frame? I have a column where each row is a list and I was to extract a value from each list item.
guys i have a img like this and i'm trying to make it be clear and easy to be read by tesseract to convert it to a string text, i tried to resize it, but looks like what could help it be better is about to change the dpi, but i cant find someone using PIL or opencv to change the dpi of one image, someone can help me with that?
i tried to use opencv to do some things with this image, but nothing works
How do i resolve conflicts between pip and conda?
This is usually due to pip uninstalling or clobbering conda managed files,
resulting in an inconsistent environment. Please check your environment for
conda/pip conflicts using conda list, and fix the environment by ensuring
only one version of each package is installed (conda preferred)
is the conflict arising from a venv that was created via conda?
i'm in the base env
or are we talking system's pip and conda clashing
and trying to run conda pack
this
i'm trying to pack base env
basically trying to move my conda installation to a different drive
@royal crest how do i fix this? update the two conflicting pkgs via conda?
this github issue here (https://github.com/conda/conda-pack/issues/98) says: " the package cache no longer has a copy of the packages in the environment. So unfortunately, the same mechanism conda requires to clone an environment is needed be conda-pack to turn it into an archive"
Who can help with yolov3. I need to check coordinate of middle of pickture what that found. Idk how to teach ai but I need teach and download ai to my pc and use in my bot
what is the point of factorplots when you can individually call violinplot, barplot, boxplot, etc
and all of them have the hue argument right? so what would be the point
Is it better to fit small chunks of data with higher batch size or bigger chunks of data with small batch size for gpu
wdym "chunks"of data
I wont be able to just fit 560000 images instantly, so I only fit 10k and move on to next 10k and so on
Pls help
I have all picture what is need
Wait, I didn't got it
Could you explain better?
Am i alloweed to ask questions in here
Yes
Ok
I am trying to scrape data off of a website
im using bs4,requests,beautiful soup and im getting cloudflare errors when sending the request
Tried having my useragent set to chrome, any thoughts?
I don't think that's the right channel
Oh> sry
has anyone worked with FHIR
Now I'm doing a system of automatic closure of advertising and I need to train artificial intelligence to find a cross and then click in the middle. Please help make ai and download to your computer and use it.
How i can teach bot and download and use on my pc
Wait, I think that using ai could cause problems
Crosses aren't just used for ads, even for general purpose UI
It's better to download the image of commonly used crosses in ad
(like the one in youtube)
and use them as masks in OpenCV
But it could be better to handle the thing by manipulating the page's source
@lean pebble
Hello! I am trying to find the optimal language model for a document classification task. These documents are long, however, the important sentiment is just a few sentences or less. I tried 6 BERT models, and all showed similar high F1 scores, which implies that the domain-specific pretraining of these models did not affect performance. This tells me that the optimal model would be able to really understand a small set of key words and phrases rather than need a complex understanding of the domain-specific language. Anyone have any suggestions or ideas of where to find this model? please @ me if so, thank you
Hello, I am just getting started with NN, and wanted to code up a simple NN with just using numpy. The network architecture looks like the below picture. But I'm stuck at the updating the parameters in the gradient descent part. i.e :
W1 = W1 - alpha * dC_dW1
b1 = b1 - alpha * dC_db1
W2 = W2 - alpha * dC_dW2
b2 = b2 - alpha * dC_db2
# Where W1 & b1 represents the matrix of weights and biases in layer 1 respectively,
# W2 & b2 represents the matrix of weights and bias in layer 2 respectively.
```Since there are 9 weights and 4 biases, do I have to calculate the equation for derivative of cost function with respect to each of those 9 weights and 4 biases, and then vectorize them? That's 13 equations to code up, is this really how it's done if you want to code it from scratch?
Don't know what kind of documents you're dealing with, so I'll suggest you a general-purpose language model
clinical documents
clinical notes
but the point is is that it doesnt matter how well the models understand the grand schem,e of the documents
it is just all coming down to a few sentences of information in them
like
general BERT trained on general english text outperforms BERT trained on clinical documents
Look into LDA for document classification.
yes Mister Stelercus
thank you
Dumb question, if we have a small data like 15 of them, and we feed it to the ML algorithm. The accuracy will be like 100%? or else
yeah may overfit, or it could do horribly lol
15 samples is not enough for a model to learn
even if you doubled that you could see a huge improvement!
that's what I afraid so far lol. For categorical variable, what ML model do you recommend?
Is machine learning really used for this sort of thing? Does it yield better results than more classical methods of odds prediction?
I guess it makes sense that there would be "intangibles" that wouldn't be captured so readily by more classical methods. Interesting. Looks like I'm going to move to Vegas and become a bookie!
:incoming_envelope: :ok_hand: applied mute to @magic dune until <t:1627066391:f> (9 minutes and 59 seconds) (reason: newlines rule: sent 114 newlines in 10s).
!unmute 555944200047296513
:incoming_envelope: :ok_hand: pardoned infraction mute for @magic dune.
:x: There's no active mute infraction for user @magic dune.
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Alright thx
Won't happen again
How would you resize Matplotlib.pyplot figures? I've been looking at this forum: https://stackoverflow.com/questions/332289/how-do-you-change-the-size-of-figures-drawn-with-matplotlib, and tried out the solution but my figure plots don't get sized appropriately 😦

Stack Overflow
How do you change the size of figure drawn with Matplotlib?
I am currently making a k means cluster code which is only using numpy and matplotlib I want to color code the clusters can someone tell me how to do this
what's your code?
when ever I use df.describe() and specify the percentiles, it always includes the 50th percentile. I don't want it to include that, how do I make it not?
so what do you mean by your figures dont get sized appropriately
Well the figure doesn't get scaled with size 800px in height by 800px in width hence why I wrote this: py fig, ax = plt.subplots(figsize=(8, 8), constrained_layout=True, dpi=100)
I am currently making a k means cluster code which is only using numpy and matplotlib I want to color code the clusters can someone tell me how to do this?
help pls
what size does it get scaled to
when I display it on the web browser, it's sized at about 100px x 100px

Try one of the help channels
I did #help-pineapple
But when I check it out in my project file directory, it's sized at 800px x 800px...

but this guy just a question in the channel
Ok
which scoring function should I use with SelectKBest when I have categorical input and numerical output?
Why do we use resisual nets in NN ...it doesnt make sense to me in how the improve NN if ur just teleporting data so as to skip some layers?
gradients like teleports tho
Is there a great book related to machine learning as pdf form or anything?
I am currently making a k means cluster code which is only using numpy and matplotlib I want to color code the clusters can someone tell me how to do this
My code:https://paste.pythondiscord.com/gabaporile.apache
pls help me
Hi Everyone - I'm new to python and am tinkering with pandas. I have a two datasets with a primary key - foreign key relationship
On the dataset with the foreign key, I want to lookup data in the linked table and do a calculation
And then add that as a column in the original dataset
ok
I'll look up those docs
thanks!
A follow on question - my keys are named dissimilarly
it looks like merge takes a single key, finds that on both tables, and joins on that
This is my fave: https://www.amazon.com/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1492032646
Looks like it was free as a pdf at some point but not anymore
Then how do you know how to pair them up??
Will have a look at it ty!
If I were doing SQL you can say something like INNER JOIN Foo ON Bar.ID=Foo.BarID
Ohhh you mean the column containing keys has a different name
yes 🙂
Lol I thought your actual keys were different haha
??
I think the right on / left on params do that
pd.merge(df1, df2, left_on='UserName', right_on='UserID')
That's some good advice, i was renaming my columns like a plebian haha
for your reference, pd.merge has a how keyword argument where you can pick between inner, outer, right, etc., but "inner" is the default. DataFrames also have a join method, but that's only for joining on the index for some reason.
Thank you, i did find that argument super useful. I usually just do an outter merge and filter/subset afterwards because they're small reports
While it's on my mind, do you know the best way to make a helper column that checks for nan in a different column, and fills in based off whether or not it's occupied?
you just do df['column_name'].isna() and that gives you a boolean series.
My case is the large set is production data, the medium set is shipment data, and the small set is consumption data. I'd like a column called "stage" with the value produced, shipped, or consumed based off whether it shows up
In [4]: df
Out[4]:
0 1 2
0 0.471273 0.800411 0.899211
1 0.214583 0.581962 0.752713
2 0.611297 0.909228 0.658377
3 0.512379 0.329779 0.843706
4 0.323153 0.020822 0.234330
In [5]: df[0].isna()
Out[5]:
0 False
1 False
2 False
3 False
4 False
Name: 0, dtype: bool
I'm a noob. Idk how to code properly and definitely dunno about NN. Is there any online server or something where I could just add my dataset and it will be able to make predictions ?
I'm not sure, but you'd at least need to know enough about AI to effectively select what kind of model is appropriate for your data and the intended use case.
if you want to identify null values, .isna(). if you want to fill them, .fillna().
if column A is 20 rows, B is 15, and C is 10.....
whats the best way to create a column D that has 3 possible values, "A is present", "A and B are present", "All are present"
I suppose
that means that for all rows for which B and C are present, A is present
and for all rows for which C is present, B is present
exactly
okay then
it steps down
(df['A'] * 4 + df['B'] * 2 + df['C']).map({7: 'all', 6: 'A and B', 4: 'A'}) should work
wait hold up
what do you mean by this
how can they have different sizes
in an outter merge
where the presence of data indicates its stage
and i want a label for stage. Maybe df["all"] = df[df["C"].notna()]
then df["all"] = "all" .... then i'll append them ill play around
I don't think this would work because df[df["C"].notna()] is going to be selecting a subset of rows
maybe this will work for you:
def is_present(a,b,c):
if not math.isnan(b) and not math.isnan(c):
return "all are present"
elif not math.isnan(b) and math.isnan(c):
return "a and b are present"
else:
return "a is present"
df['D'] = df.apply(lambda x: is_present(x['A'], x['B'], x['C']), axis=1)
ofc! i love lambda functions.