#data-science-and-ml
1 messages · Page 242 of 1
I actually don't know what dynamic programming is, first time coming across that term
basically you break a problem into smaller subsets in such a way that some of the subsets are repeated
then you store the result of solving each subset
so that you only need to solve it once
yeah, this task isn't that simple I think. Your original formulation ("numbers smaller than any item appearing prior to them" - so ones that become the new minumum, basically) can be solved in O(n) easily, but not this I think.
Task: for each element, find the number of elements prior to it that are smaller.
interesting one though, lemme run some experiments...
I think they just weren't clear that they needed that value for each element in the array
my gut feel is that this is quadratic time...?
but honestly I wouldn't be able to tell
Task: for each element, find the number of elements prior to it that are smaller.
@tidal bough Yes, this is the perfect wording for my problem
like okay there can defo be some element of memoization
if there are repeated elements
such that you only need to recalculate the value for the interval
but unless there is some specialised data structure applicable to this problem...can we get much better performance?
if we entirely ignore space complexity, you can create a tree table of numbers smaller than a number and locate numbers in it, giving you O(nlogn).
it would essentially be a dict, but made in a way you can find the element with the closest key, rather than an exact match
let me try to write something up, I could be entirely wrong
But, that's the same as what's happening now, isn't it? As in, there are hardly any repetions in my list as the numbers have been taken up to three decimal places
it would essentially be a dict, but made in a way you can find the element with the closest key, rather than an exact match
@pale thunder
let me try to write something up, I could be entirely wrong
@pale thunder like I don't see how that solves the problem for each element in the array
I made this challenge: https://i.ibb.co/R2jb6FQ/Pepe5040.png. Hidden in that image (a few layers deep) is a message.
{kind=link}

Can anyone crack it?
(Using python ofc)
@numba.njit
def numba_find(lst):
lst = np.array(lst)
res = []
for i, el in enumerate(lst):
other_list = lst[:i]
res.append(np.sum(other_list<el))
return res
my take on the numba-accelerated one. Still O(n^2), though.
Is it possible to retrieve data from google analytic with others key ??
hmm, interesting
so yeah, that's a decent speedup
a O(n*log(n)) solution would be a lot faster though
my take on the numba-accelerated one. Still O(n^2), though.
@tidal bough This is awesome. It takes like 10-12% of the time of the original function after the first call
though maybe it can be vectorized.
a O(n*log(n)) solution would be a lot faster though
@tidal bough I reaaaaally don't see how this is possible
but
the problem is making max work on a part of the array
oooh, right, I can tile it and then set some elements to infinity
Will look into that, is the book adapted for Tensorflow 2.0+ ?
@dreamy fractal yep
think I cracked how to vectorize it at least
I'm curious, I've been trying myself
mostly it's a problem because numba doesn't support all the function of numpy
Ok. I'd still be interested in your solution if you did manage to vectorize it
Here's the vectorized implementation:
def vect_find(l):
lst = np.asarray(l)
search = np.tile(lst,(len(lst),1))
search[np.triu_indices_from(search)] = np.iinfo(search.dtype).max # set upper triangle to infinity
queries = np.reshape(lst,(len(lst),1))
return np.sum(search<queries,axis=1)
but it has to be changed to allow also numbaing it.
(yes, the results are equivalent to the other two)
performance is pretty bad; needs numba badly.
I'll try it out. Looks quite complex and interesting.
So apparently numba does not support numpy datetime array. That's a bummer, I was trying to use it in another function where I use dates to calculate the rate of returns
Yeah, that's actually a part of the function itself. I'll just have to break the function into two parts, first to convert days to ints, then I pass that directly to the second function. And use numba only on the second function.
Or maybe convert the datetime to epoch. I'll check what works
what is this? finding an element in a vector/array?
I need to do a calculation over a list where I need to find the number of items smaller than any item appearing prior to that item.
aha
love the effort you guys put into this
i dont think numba does much for already-vectorized functions other than maybe optimizing out intermediate results
Hey, anyone knows if you can add latex Formulas into docx document? Im using this but i cant really find anything related to equations and such https://python-docx.readthedocs.io/en/latest/index.html
I made this challenge: https://i.ibb.co/R2jb6FQ/Pepe5040.png. Hidden in that image (a few layers deep) is a message.
@grizzled inlet steganography :D?
probably ;-;
Alright, earlier today I learnt about numba compiler and now I really want to try it out with this function which calculates the internal rate of return for irregular cashflows:
def xirr_np(dates, amounts, guess=0.05, step=0.05):
years = np.array(dates - dates[0], dtype='timedelta64[D]')/np.timedelta64(365, 'D')
residual = 1
#test
dex = np.sum(amounts/((1.05+guess)**years)) < np.sum(amounts/((1+guess)**years))
mul = 1 if dex else -1
# Calculate XIRR
for _ in range(1000):
prev_residual = residual
residual = np.sum(amounts/((1+guess)**years))
if abs(residual) > 0.1:
if residual * prev_residual < 0:
step /= 2
guess = guess + step * mul * (-1 if residual < 0 else 1)
else:
return guess
return "XIRR not calculated"
# test execution, result should be 0.13354
import numpy as np
dates = np.array(['2018-10-20', '2019-06-15', '2019-12-12'], dtype='datetime64')
amounts = np.array([2000, 3000, -5500])
xirr_np(dates, amounts)
However, I keep getting errors at various points. I'll post the errors in a sec. Can someone familiar with numba and numpy help me with this
This is error number one:
TypingError: Failed in nopython mode pipeline (step: nopython frontend)
No implementation of function Function(<built-in function array>) found for signature:
>>> array(array(timedelta64[], 1d, C), dtype=Literal[str](timedelta64[D]))
There are 2 candidate implementations:
- Of which 2 did not match due to:
Overload in function 'array': File: numba\core\typing\npydecl.py: Line 504.
With argument(s): '(array(timedelta64[], 1d, C), dtype=Literal[str](timedelta64[D]))':
Rejected as the implementation raised a specific error:
TypingError: array(timedelta64[], 1d, C) not allowed in a homogeneous sequence
raised from c:\users\goura\appdata\local\programs\python\python38-32\lib\site-packages\numba\core\typing\npydecl.py:471
During: resolving callee type: Function(<built-in function array>)
During: typing of call at <ipython-input-23-21511381d673> (3)
File "<ipython-input-23-21511381d673>", line 3:
def xirr_np(dates, amounts, guess=0.05, step=0.05):
years = np.array(dates - dates[0], dtype='timedelta64[D]')/np.timedelta64(365, 'D')
Hello,
in this third video I present to you the MNIST dataset deep neural network which is inspired by one of the original 1998 papers by Yann LeCun!
This classifier uses the deep learning library which I have been building from scratch during this series! Next up is showing how to deploy this model on a webserver :)

Welcome back!
In today's video I build a MNIST classifier using one of the architectures from Yann LeCun's legendary 1998 paper.
Code: https://github.com/Fedzbar/deepfedz
MNIST: http://yann.lecun.com/exdb/mnist/
Hey all. Would highly appreciate if someone can clear up some of my doubts I had regarding a project I had:-
-
Can we use a CNN to identify features from a tensor of specific/fixed dimensions? Like if the tensor has some advanced correlation with it's corresponding unique label, but it is a quite complex. So would it be manageable for bunch of dense block with transition layer as Conv (architecture like DenseNet) to find these relations with the tensor and it's label? They are used to find features among Images but would they still be useful in tensor-related stuff?
-
Is it possible to use Dense/Fully connected layers for classless prediction? Like for decoding ciphers, there won't be a specific class. rather it would depend on input itself to extract out a message. In this case, would Dense layers be recommended for these type of tasks?
-
if yes, which activation function should be used. I have limited use with softmax, adam and few others, but am unsure which one to be tried out first.
Could anyone point out the mathematical way of determining the usecase for each activation from the table below? I think something like tanh might be usable since it is used in RNN's which would have some similarities with my use-case. How then should I determine the best possible A.F without having to trial-and-error most of them?
My input feature would be of the same length after padding and there would be Word Embedding layer to represent the input in a higher dimension tensor to facilitate the model in finding relations.
Embedding would be character level and along with that all I would like to implement DenseNet architecture in the hope that it would be able to infer the complex relations. Is the whole idea workable? Is there potential flaw or caveat in this approach? 
@hidden halo "fancy" types like timedelta aren't supported by numba. you should write your functions to accept numpy arrays as inputs, using only "basic" dtypes like int and float
Ah, and the output would always be a positive Integer, in consideration with the dataset...
@hidden halo "fancy" types like timedelta aren't supported by numba. you should write your functions to accept numpy arrays as inputs, using only "basic" dtypes like int and float
@desert oar yeah, it kind of went really weird after that. I separated that part out and passed an array of days (ints basically). It compiled and worked with the sample given above. But when I ran it with my actual input, it gave an error at theresidual = 1part.
Hmm... seeing the length of my question, I think it would have been a much better fit for Stack Overflow 😅 but still would appreciate if someone can clear up my doubts 🙂
Here you go. This works with the sample I had included above, but not with my actual input. I tried printing the type and both the inputs and it is numpy.ndarray in both cases
def xirr_np(dates, amounts, guess=0.05, step=0.05):
years = np.array(dates - dates[0], dtype='timedelta64[D]')/np.timedelta64(365, 'D')
amounts = np.array(amounts)
xirr = xirr_calc(years, amounts, guess=0.05, step=0.05)
return xirr
@numba.njit
def xirr_calc(years, amounts, guess=0.05, step=0.05):
residual = 1
#test
dex = np.sum(amounts/((1.05+guess)**years)) < np.sum(amounts/((1+guess)**years))
mul = 1 if dex else -1
# Calculate XIRR
for _ in range(1000):
prev_residual = residual
residual = np.sum(amounts/((1+guess)**years))
if abs(residual) > 0.1:
if residual * prev_residual < 0:
step /= 2
guess = guess + step * mul * (-1 if residual < 0 else 1)
else:
return guess
return -2
@grave frost maybe 2-3 separate questions on stats.stackexchange.com 🙂
stackoverflow is a really bad (and off-topic) place for machine learning questions
Would numba speed up something like doing 50M list intersections?
whats the error you get with your actual input? @hidden halo
@acoustic halo possibly but maybe you should just use sets instead
Sorry i meant sets
I have already with multiprocessing, it still takes forever because the sets contain thousands of element each
hm. set intersection is already as fast as it's going to get, implemented in cpython
numba can improve looping and variable assignment overhead, thats probably it
whats the error you get with your actual input? @hidden halo
@desert oar I'm trying it out. It seems there's some problem with the input, like maybe a NaN or something. It's working with slices of inputs, but not with the whole input at the same time
ah, thats likely
Apparently that's not the case. Look at this weirdity, it's the same dataframe, if I pass it from Pandas, it works, if I pass it from Numpy, it doesn't. Even though the datatyep is same in both cases
This is the errror message:
TypingError: Failed in nopython mode pipeline (step: nopython frontend)
non-precise type array(pyobject, 1d, C)
During: typing of argument at <ipython-input-50-a46724d18b71> (9)
File "<ipython-input-50-a46724d18b71>", line 9:
def xirr_calc(years, amounts, guess=0.05, step=0.05):
residual = 1
^
# Printing the value of a sess = tf.Session(graph = graph1) result = sess.run(a) print(result) sess.close()
whats wrong ?
please help me
@hidden halo try residual = 1.0? if the input data is float dtype
although years should be ints anyway
or
can you double check the dtypes of the input arrays?
this seems to be an error associated with 'O' dtype which isnt supported in nopython mode
Not sure, I can make this work with Pandas dataframe as well, so I'm sticking to that. Maybe someday I'll figure out why this was happening.
I have another question though, if I want to implement this in a Django application, how do I make the compiled version persist? If I simply call it, I guess it will compile every time since each session is a new one.
Ok so I am using HDF5 to store and pass in my data as a generator as I have over 40,000 image array of 277, 277, 3 in which causes memory errors,
I have python class generator: def __call__(self, feature_set, label_set): with h5py.File('ANN_Dataset.hdf5', 'r') as hf: for feature, label in zip(hf[feature_set], hf[label_set]): print('hello') yield feature, label def data_iter(feature_name, label_name): ds = tf.data.Dataset.from_generator(generator(), (tf.float64, tf.int64), args=(feature_name, label_name)) iterator = iter(ds) feature, label = iterator.get_next() print(feature, label) return feature, label model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(277, 277)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax')]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(data_iter('X_train', 'y_train'), validation_data=(data_iter('X_val', 'y_val')), epochs=10) So I am passing my generator in through model.fit but I am getting such error, this is when I use return instead of yield in data_iter()python return self._dims[key].value IndexError: list index out of rangewhen I use yield I get ValueError: slice index 0 of dimension 0 out of bounds. for '{{node strided_slice}} = StridedSlice[Index=DT_INT32, T=DT_INT32, begin_mask=0, ellipsis_mask=0, end_mask=0, new_axis_mask=0, shrink_axis_mask=1](Shape, strided_slice/stack, strided_slice/stack_1, strided_slice/stack_2)' with input shapes: [0], [1], [1], [1] and with computed input tensors: input[1] = <0>, input[2] = <1>, input[3] = <1>.this is my shape of data python shape=(227, 227, 3), dtype=float64) tf.Tensor(0, shape=(), dtype=int64)
Ah silly mistake, so it seems that I wasn't passing in my label as an array, so it wasn't outputting a shape, but hmm when I converted it python class generator: def __call__(self, feature_set, label_set): with h5py.File('ANN_Dataset.hdf5', 'r') as hf: for feature, label in zip(hf[feature_set], hf[label_set]): print('hello') yield feature, np.array([label])and my shapes beingpython shape=(227, 227, 3), dtype=float64) tf.Tensor([0], shape=(1,), dtype=int64)I get the following error now python ValueError: Data cardinality is ambiguous: x sizes: 227, 1 Please provide data which shares the same first dimension.
Hi,
I have a csv file having image id's and associated labels.. like so:
ID,Location,Party,Representative/Candidate,Date 23,Camberwell and Peckham, ,,07-Mar-15
Now each id has associated with it multiple images.. like for above example: images are labelled image_23_1, image_23_2 and so on..
Im trying to figure out how to create a new dataframe having the the images with full paths with each id..
I can strsplit() the image names but how do I associate each row to its respective images? I hope I explained this well enough 😦
yes.. sorry my mistake ill edit
okay, does each ID have the same amount of images?
no, vary between 3 and 5
will that always be the case or is it something that may change?
put all images in lists with others sharing the same ids, then put those lists in a dict with id being the key
its a very large dataset of about 10,000 images.. each having their own label/class which is based on the csv file.. so Im interested in say, create a new csv for only one class which in above example is Camberwell and Peckham get the image of this id and save this data in a new df
so go over the csv, for this class, get the id ... search this id and its repsective images in folder.. and then save this in a new df
How would I associate the values of respective images in the dict?
Other than id, how else do they correspond to the labels?
@hidden halo it's a just in time compiler, so probably no way to do it
Oh. Then it wouldn't have helped with my use case anyway.
Still, it's good to know something like this exists. Maybe I'll be able to use it in other programming projects.
the id is the only connection to the images in folder..
Maybe you want to start like this @tacit eagle
camber_df = df.loc[df["Location"] == "Camberwell and Peckham"]
camber_ids = camber_df.ID.unique```Then search the folder for the ids to get paths and store them in a new df?
Dont know the code on top of my head but you should be able to search for files named image_{ID} and get a list of their paths
hmm it seems that it wasn't registering the y sizes and I split it the generator into python X_train, y_train = data_iter('X_train', 'y_train') X_val, y_val = data_iter('X_val', 'y_val') model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10)I now get python ValueError: Data cardinality is ambiguous: x sizes: 227 y sizes: 1 Please provide data which shares the same first dimension. seems like my X values of shape 227, 277, 3 didn't flatten correctly?
i have some questions abt tensorflow object detection like i have collected my data for training but im confused (coz i will use first time tensorflow object detection) that what will be in the tf records like i have 5 cards how i should arrange them like in nay order
Anyone know how to use Dense layers for predictions? like by not defining the classes parameter because I want to use it for inference/prediction....
@grave frost happy to share a sample notebook where I use neural networks for a prediction exercise
I use this notebook to predict some missing values (this was part of a hw assignment i completed in a neural net class)
Hey @willow karma!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .3gp, .3g2, .avi, .bmp, .gif, .h264, .jpg, .jpeg, .m4v, .mkv, .mov, .mp4, .mpeg, .mpg, .png, .tiff, .wmv, .svg, .psd, .ai, .aep, .xcf, .mp3, .wav, .ogg, .webm, .webp.
Feel free to ask in #community-meta if you think this is a mistake.
you cant share pdfs here?
@willow karma thanx a lot alechter 👍 , but I am making my own NN and don't think that the architecture I am planning to use has been implemented anywhere. Still, appreciate the help! 🙂
converting this file to another format and will share shortly
@grave frost not ideal but it's in a png format here: https://s2.aconvert.com/convert/p3r68-cdx67/tl4kt-9eo5h.png
{kind=link}
I've been trying to build a Facebook Prophet model for awhile with the end goal of performing a feature importance analysis on my predictors. It looks like the Prophet package does not include any built in feature_importances method that you would use with the sklearn package.
With @desert oar's help, I have been able to at least run the params method on my prophet modeling object, and I have been able to match all of my regressors to their beta components. Are these beta values enough for me to determine feature importance? I'm still assuming no since I would need to normalize these values somehow to account for the size of the regressor variables?Please help me interpret feature importance here 🙏
@willow karma I am not familiar with Prophet, but can you explain what are your beta values??
They are at the bottom of the screenshot.. I believe they are the coefficients for all my regressors. So if you think about the y = mx+b format.. these beta values represent the "m" for each regressor
Why is my model returning an X of shape 277, when I used Flatten on a shape of 277,277,3 it should be 230,187, code is above
has anyone ever had a problem with vs code where it wouldnt save your work?
It's not a problem, It's intended behaviour
Just save with CTRL + S
Or go to settings
And look for autosave or sth like that
And set it to as small value as It's possible
How much statistics do I need for DS and ML in general ?
I've finished: Measures of spread and Measures of Central Tendency ?
Pretty basic things, But I need to know what point to stop at so I can move to other Maths fields like Linear algebra or calculus
Supposed I have a PySpark DataFrame df. What is the best way to serialize it to a string? For context, I am storing it in a file and using it in a snapshot style unit test.
Hello. For the life of me i can t find openCV documentation for python... i can only see the docs for c++, which has a different api
thank you, but isn t that a tutorial (may not cover everything)? I would prefer the complete documentation (like this one https://docs.opencv.org/master/) but with more detail on the python interface... Or am i just complicating things?
https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_tutorials.html
@arctic cliff
ok, thank you!
Found this
Not all functions but I guess it cuts it
@chilly charm
You can see python versions of the functions
I'm not really sure if that's gonna help nor these functions
But you can follow up the tutorial above, I find it really cool and detailed
I found this pdf too:
https://readthedocs.org/projects/opencv-python-tutroals/downloads/pdf/latest/
thank you for all your help @arctic cliff !
@willow karma what exactly is your assignment asking btw
@arctic cliff good question. At your level, just the basics. You should eventually aim to have an intuitive + technical understanding of linear models, probability, hypothesis testing, and other topics. But that's over months and years.
As long as you are actively solving problems and not just "reading" you are almost certainly doing the right thing
Can I learn other maths topics along with Practicing DS libraries and learning statistics? Or that would be an overwhelming ?
Because I feel like I'm wasting a lot of time when I can learn more to be honest
Learn as much as you can and still retain everything
Math, stats, and programming all fit together
As long as you aren't burning out or losing focus, you can learn e.g. calculus and probability at the same time
I really appreciate your help !
Why data can't be plural. Because it's uncountable?
Kinda irrelevant but it's data science you know
I think data ARE used in the plural form quite a bit
And of course.. there's an entire Wiki article about this specific phenomena haha..
The word data has generated considerable controversy on whether it is an uncountable noun used with verbs conjugated in the singular, or should be treated as the plural of the now-rarely-used datum.
Data is defined as "information in digital form that can be transmitted or processed"
https://www.merriam-webster.com/dictionary/data
Information can definitely be counted and it is measured in a variety of units. Most commonly is bits but there is also hartley for base 10 information
Hi there, can some one help me with a Pandas question, that i cannot google properly ?
Thing is i have a dataframe with columns A B C D
I want to calculate new A values depending on B and C
And i want the calculation to be based on D
for example:
df.loc[(df.B.notna() & df.C == 1),'A'] = str(df[(df.B.notna() & df.C == 1)].D)+'some text'
I know it doesn't work as intended, and i know why.
And the Question is: how to make it "indexwise", without starting a giant cycle ?
add ` around your code
to format it
not ', `
there you go
anyway
so if I understand this right
you want to take the values in column D, convert them to strings, add another string to them (the same for all the values) and assign the result to column A
and you only want to do this for the rows where column B is not null and column C is equal to 1?
is that right?
yes
df.loc[df['B'].notna() & (df['C'] == 1), 'A'] = df.loc[df['B'].notna() & (df['C'] == 1), 'D'].map(str) + 'some text'
Thanks a lot!
does it work
yep
okay
so a few things you should probably take note of:
[]notation to access columns is generally preferable to.notation (this is my opinion though)- parentheses are not needed within the
[], but they are needed around boolean conditions (e.g.(df['C'] == 1)) - you can't apply
strto a wholeSeries/DataFrame, that will convert the object to a string. what you want is to convert each value it contains, which is done with.map(or.apply)
Thx again, I'll keep that in mind
But why is [] preferable to .? Not to overlap with .something()
Just curious
IMO?
that's one reason
everything in [] is definitely a filter on contained data
also, it allows you to access, for example, columns containing hyphens or spaces
you cannot do that with .
Thx
I have these text files that need to be converted to csv files. I normally open the txt file in Excel and then convert it to a CSV in order to run my parser. However, I wanted to make a function that automatically converts the txt file to csv. But when I use read_file.to_csv via pandas the resulting csv does not work. I've made sure the encoding is the same but nothing seems to work.
Enzyme data
General question
I am new to sql and python. I’m learning both right now. I kind of like python better but I’m told sql is better for analytics/ analyst jobs
they're different.
SQL is for getting data from the database to your local environment (in a data analyst context)
Python is for the actual data analysis/science work.
you can do analysis in SQL but
that's more for dashboarding than interactive stuff
Ok. What sql course would you recommend?
I find python more interesting but I guess I haven’t had the chance to apply sql to the economy
they're really different tools
and Python is general-purpose
SQL is specialised for pulling data out of databases
Well if you can create data shouldn’t you be able to analyze it
I guess applying it to the real world is not a concept that everyone can grasp just because they can code
So it makes sense
Well if you can create data shouldn’t you be able to analyze it
@lapis sequoia not...really?
If you create a project you can’t analyze how it’s applied?
e.g. in, say, Uber
you could say that the backend engineers are the ones "creating" data
but it's up to the BI/DAs to analyse it
although I'm not sure if that was what you were thinking of when you said "create"
So who makes more money
that depends on many factors
Ok so I'm trying to fork a module from github and set it up in a local conda channel so I can install my tweaked version to my environment
I used the cookiecuttertemplate repo to get the meta.yml file and all that
and now when I try to build I get this confusing error
m = MetaData(recipe_dir, config=config)
File "C:\Users\madde\anaconda3\lib\site-packages\conda_build\metadata.py", line 868, in __init__
self.parse_again(permit_undefined_jinja=True, allow_no_other_outputs=True)
File "C:\Users\madde\anaconda3\lib\site-packages\conda_build\metadata.py", line 945, in parse_again
bypass_env_check=bypass_env_check),
File "C:\Users\madde\anaconda3\lib\site-packages\conda_build\metadata.py", line 1534, in _get_contents
rendered = template.render(environment=env)
File "C:\Users\madde\anaconda3\lib\site-packages\jinja2\environment.py", line 1090, in render
self.environment.handle_exception()
File "C:\Users\madde\anaconda3\lib\site-packages\jinja2\environment.py", line 832, in handle_exception
reraise(*rewrite_traceback_stack(source=source))
File "C:\Users\madde\anaconda3\lib\site-packages\jinja2\_compat.py", line 28, in reraise
raise value.with_traceback(tb)
File "C:\Users\madde\Documents\maddenfederico\win-64\ChemDataExtractor\conda.recipe\meta.yaml", line 45, in top-level template code
requires:
TypeError: 'NoneType' object is not callable```Second half of the cmd output
Look, a new activation function: https://towardsdatascience.com/understanding-of-arelu-attention-based-rectified-linear-unit-1da3a1d0be9f

Medium
Well-Focused, Task-Oriented Activation for Convolutional Neural Networks
Any idea what would cause a confusion_matrix to look like this? Reading a tutorial about building an expected goals model and this is the result of a LogisticRegression after a prediction across my split set.
It looks like you are essentially classifying everything as one class. Maybe you have a class imbalance issue?
Too many of one sample and not enough of the others. So the discriminator only learns one thing. Essentially, “everything looks like a nail when you hold a hammer.” That’s my first guess.
So across my 229K observations, my dependent variable is split 214,000 / 15,000
It’s late where I live so bear with me, but that means you have 214,000 things labelled A and 15,000 labelled B?
Yeah. That’s going to cause issues.
Yeah so I have 214,000 things that are not goals and 15,000 goals.
More data in general or more data that describes what makes a goal.
The latter. (Well more data is almost always better)
It’s learned that most things it sees are “not goals”. And...it’s not wrong. It’s essentially stereotyping.
Ah okay so that makes sense, it just needs more 'goals' to identify the attribution and variance that predict a goal.
Yeah.
Seems like the easiest place to start. Also might be the hardest if you have no more data.
I can always get more data from going back more seasons but the disparity would be about the same. So I wonder if I could just remove some "no goals" from the sample data set and see if that helps with the prediction.
It will improve accuracy. But, it will become less robust to outliers.
This is this trade-off you have to balance.
Ah okay so that worked. I took 100k non-goal rows out of my sample and now I get this -
prediction = log_r.predict(X_test)
matrix = confusion_matrix(y_test, prediction)
print(matrix)
[[30267 74]
[ 3888 56]]
Nice. I would try to get more day for goals.
Okay so the more goal data I get and feed into the model the more accurate it becomes in telling apart a goal vs a non-goal, but then you need to strike a balance about outliers.
Yeah. You are on the right track though.
Do i go here when i have a machine learning question (I believe its part of the data science field)
?
Yeah, I am also searching for ML
Yes, this channel is for ML
"For discussion of scientific python, matplotlib, statistics, machine learning and related topics."
@hidden halo
I have another question though, if I want to implement this in a Django application, how do I make the compiled version persist? If I simply call it, I guess it will compile every time since each session is a new one.
It should be possible. I know numba can even compile the functions at compile-time, although that's generally annoying (requires specifying types).
oh, lol, it's even simpler:
If true,
cacheenables a file-based cache to shorten compilation times when the function was already compiled in a previous invocation. The cache is maintained in the__pycache__subdirectory of the directory containing the source file; if the current user is not allowed to write to it, though, it falls back to a platform-specific user-wide cache directory (such as $HOME/.cache/numba on Unix platforms).
Ah, this looks nice. Let me give this a read.
Thanks
@hidden halo @desert oar
So, I did figure out a mostly-vectorized version that still numbaifies, but it's worse 😅
@numba.njit
def nvect_find(l):
n = len(l)
lst = np.asarray(l)
search = np.repeat(lst,n).reshape((n,n)).transpose()
used_max = np.iinfo(search.dtype).max
for i in range(n):
search[i,i:] = used_max
queries = np.reshape(lst,(len(lst),1))
return np.sum(search<queries,axis=1)
in general, the fastest by far is the version that just numbifies the normal, loop-based solution.
That's usually the case
I guess since both numba.jit and vectorisation are basically doing the same thing, that is offloading the calculation to compiled code, it's kind of redundant to use both together. It's an interesting case study, sort of
^ this
yeah, basically
...although...
I was going to check if I can parallelize it too, but I'm getting weird errors that numba can't even explain in human-readable terms:
LoweringError: Failed in nopython mode pipeline (step: nopython mode backend)
Failed in nopython mode pipeline (step: nopython mode backend)
LLVM IR parsing error
<string>:403:18: error: invalid cast opcode for cast from 'i64' to 'double'
%".345" = sext i64 %".343" to double
^
File "<ipython-input-104-cf0246779730>", line 8:
def nvect_find_par(l):
<source elided>
used_max = np.iinfo(search.dtype).max
for i in numba.prange(int(n)):
^
During: lowering "id=9[LoopNest(index_variable = parfor_index.681, range = (0, $68call_function.29, 1))]{76: <ir.Block at <ipython-input-104-cf0246779730> (8)>}Var(parfor_index.681, <ipython-input-104-cf0246779730>:8)" at <ipython-input-104-cf0246779730> (8)
the real question is what does it try to cast from int64 to double, and why?..
Yeah, I was also getting weird errors that I simply couldn't comprehend.
How do you generate these line graphs?
I have a dataset that has x,y,z , coordinateID.
I want to create a 3d plot of the x,y,z with color labels based on coordinateID.
I am able to create a 3d plot but i dont know how include color labels.
Can anyone help me out?
This is the code that generates the 3d plot of x,y,z. How do i color lable the plots based on coordinateID? (There are 9 coordinateIDs so i need 9 different colors)
How do you generate these line graphs?
@hidden halo theperfplotmodule, it's quite nice
specifically the code is:
perfplot.show(
setup = lambda n: [random.randint(0,999) for _ in range(n)],
kernels = [
naive_find,
numba_find,
vect_find,
nvect_find
],
labels = ["naive","numba","vect","numba-vect"],
n_range = list(map(int,list(np.geomspace(1,10**3,30)))),
xlabel = "N",target_time_per_measurement=0.5,logy=True,logx=True)
(the n_range is a list of n-values for the calculation; I'm using geomspace for it to obtain equal intervals between ns on the log scale)
oh, I think this is similar to the profviz library of R, I have used that. Though, that was simpler. I'll try this out
didn't we go through this yesterday
@velvet thorn lol we did?
Well i remember how the permutations work
Not the setting two variables to one thing
reeeee i know what i want my machinelearn to do but trouble implementing
how do i view the contents of a tf.data.Dataset object
@acoustic halo can you provide a link of ML?
What in particular?
I think this channel is only for DS, actually I read your reply wrong though😆
machine learning is data science
Anyway thanks for your response
This is the code that generates the 3d plot of x,y,z. How do i color lable the plots based on coordinateID? (There are 9 coordinateIDs so i need 9 different colors)
@balmy grottopy img = ax.scatter(x, y, z, c=c, cmap=plt.hot()) fig.colorbar(img) plt.show()
Hey there, who wants to learn together k-means clustering ? I need this for my bachelor's thesis right now. We can, of course, use a different dataset , so that this won't count as stranger's help.
Hello all. I have read Python Crash Course and I have done some other tutorials. Now I feel confident with the basics and I want to start studying Data Science. Can someone suggest me a good (free) course.
@bitter harbor what is c = c ?
Idk if you need to define it there but c is your 4th dimension
@bitter harbor can you show the plot
Look up 4d matplotlib graphs
Let's do it
@halcyon vale yeea
Anyone else interested?
My current idea is to try to detect the vertical edges and then splitting the image but I'm having trouble with that
Any OpenCV experts here?
can someone help me with cnn ??
i want to build a cnn model but i cant find a way out with tensorflow2
should i choose tensorflow1 or what else ?
please help me!!
use keras?
keras ?
Keras vs Tensorflow?
for convolutional net?
I mean...building one is pretty simple. There are definitely tutorials by the TF team out there.
yeah but its all for tensoflow1
or tf.keras
is it good for cnn ?
its easy, read up. heavily documented tho
might be slow depending on your CNN

Predictive modeling with deep learning is a skill that modern developers need to know. TensorFlow is the premier open-source deep learning framework developed and maintained by Google. Although using TensorFlow directly can be challenging, the modern tf.keras API beings the si...
yeah i would take some dogs and cats
Yeah. Keras is native with tf 2.
thank you @oblique belfry will check it out
It’s a higher level api to make things easy.
I just googled Tensorflow 2 CNN tutorials. You might could find better on your own. Because I just chose the first result I found.
but is it right to pick for a cnn ?
ohh
For cats vs dogs you can easily get accuracy 0.85+
wait is tensorflow a platform and keras is a library
is it correct ?
Sure. Let’s go with that. Lol.
Keras is an easier api to use. It uses TF under the hood. (There is a large caveat here, but that’s for later. What I said isn’t necessarily true always.)
yeah it depends upon the dataset
ohh should i implement from scratch ?
This is killing me
lol just trained that
implementing a deep CNN made with keras subclassing API, the model is huge and its training suspiciously fast. loss is increasingly negative, accuracy is increasing but fluctuating. Any idea what's causing this
it took me 10 mins
maybe because of gpu ?
Not enough data.
but i gave epochs like 250
@lapis sequoia Post more code of the model.
not enough data maybe it, wait I'll link it, its a big model
Cool
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
@oblique belfry
What’s your loss function?
thats the dataset
Is this a classification problem?
binary crossentropy
Noob question, when you fit keras model, cant you make it predict a sequence you input? Right now I am trying to do it but it asks for same shape as training data(?)
yes binary classification
Weird that the loss is like that.
Noob question, when you fit keras model, cant you make it predict a sequence you input? Right now I am trying to do it but it asks for same shape as training data(?)
@gaunt blade it has to be the same shape, you can pad the input to match your training data shape
Weird that the loss is like that.
@oblique belfry IKR
Add zeroes around it so it’s the same shape as everything else.
Ah
read up keras.preprocessing.sequence.pad_sequences
yeah essentially
the loss is now - 1 Million lmao
It’s weird that the loss is that way.
what can it be tho, should i try another metric or loss function
Reduce the FC neurons.
If you are doing classification, then no. Seems decent.
I would start with a small simple model and work from there. I might would turn off BatchNorm and dropout as I debug.
i didnt apply batch norm
I would force it to over fit on the simple model first before adding that stuff.
I saw it in the init method. My bad.
I don’t know what else to suggest unless I was at your machine. Sorry.
Hey its okay man thanks for trying xD
oh fuck
Lol. I just interpreted that as 0-1.
Negative loss is normally to do with bad labels and BCE
Note to self: read better.
I kept saying i need to fix labels and forgot
WHich is the only reason i noticed
Z = pad_sequences(Z, X)
TypeError: only integer scalar arrays can be converted to a scalar index
Where am I going wrong lol
Do np.clip or something similar to quickly convert -1 to 0.
what is Z and X?
NP arrays reshaped into 3d array I guess
ohh, how do I handle my original issue then? kinda lost hehe
Basically to give more context
It’s hard with no context.
Yeah writing up now
I did LSTM on a sequence. but now I want to model.predict in keras by giving a smaller sample to predict? I bet I am fundamentally misunderstanding some concepts lol
Basically, it works like this: sequence = [[1], [2, 3], [4, 5, 6]] , pad_sequence(sequence, 3) = [[0, 0, 1], [0, 2, 3], [4, 5, 6]]
Yeah and like I said in my first posts my main problem is, when I supply this small sample I just talked about, it wants it to be same size as training data
"Noob question, when you fit keras model, cant you make it predict a sequence you input? Right now I am trying to do it but it asks for same shape as training data(?)"
Post the full error message
Theres bunch of them depending on what approach I take but 😄
ValueError: Input 0 is incompatible with layer sequential: expected shape=(None, None, 178), found shape=[None, 1, 3]
Here's some things I do with my data, lol
y = np.array(y)
y = y.reshape((1, 1, y.size )).astype(np.float32)
I do same with abovementioned X/Z
What actually is the data?
Okay, and what is the shape of a single datapoint?
You could potentially flatten them first then pad
1, 1, 178 for example
X = X.reshape((1, 1, X.size )).astype(np.float32)
okay, so I would flatten them into 1d lists then pad them
then if the 1,1,n structure is essential, resshape it as such
So basically for each x value, flatten it into a list, then pad, then put them into a 2d array of size (num_samples, padded_size)
@acoustic halo worked like a charm thanks
np
do you know if its possible to use tensorboard on kaggle
Hmm
ValueError: `sequences` must be a list of iterables. Found non-iterable: 2
tensorboard not tensorflow, which is what I'm assuming you meant by tf @halcyon vale
What is tensorboard?
TensorFlow
do you know if its possible to use tensorboard on kaggle
anyone know how, mainly what'll logdir be
No idea
How come
[2 4 2]
is non iterable lol
Check the type, it should be assuming its a ndarray
Yeah
<class 'numpy.ndarray'>
How do I turn it into 1d array?
Isnt .flatten supposed to do that?
All i can say is that this works fine
a=np.array([2,4,2]) for x in a: print(x)
I think numpy arrays have a .tolist method of thats what you are trying to do.
I hit accuracy 1.0, what is this sorcery
Okay, I managed to do what was suggested. but now its taking into account the 0s that I added in xD
I'm looking for someone who is frequently working with kaggle datasets
@lapis sequoia Better problem than before.
Any suggestions for a course (free if possible) which covers the basics of data-science. (Sorry if this question has been asked many times already)
@lapis sequoia Better problem than before.
@oblique belfry yeah lol
I'm looking for someone who is frequently working with kaggle datasets
@analog schooner almost daily, I'm still just a contributor tho
Hey guys, I am trying to understand "Transformers" and how exactly attention works in them. I had a question - from what I have understood so far, the attention mechanism seems to focus on specific parts of a sequence to glean out information. But does it consider the data chracter-wise and seq2seq only, or does it also use relations from other sequences as well? I am trying to decide the implementation of transformers for my cipher NN, but am unsure about it's viability....
funny, i was literally just watching a talk on this
Great minds think alike 🙂
im trying to learn how they work too, albeit for different uses
as far as i understand, "attention" is a matter of making pairwise comparisons between every token in the sequence
this is the talk i just watched https://www.youtube.com/watch?v=S27pHKBEp30

Leo Dirac (@leopd) talks about how LSTM models for Natural Language Processing (NLP) have been practically replaced by transformer-based models. Basic background on NLP, and a brief history of supervised learning techniques on documents, from bag of words, through vanilla RNN...
ya, but it is also pays specific "attention" to specific tokens which tie in strongly with the query,key and value vector. So if I was doing chracter level transformation, It technically shouldn't consider other sequences but still, want to be sure before I spend all my money on it...
oh leo dirac, I saw the guy do a presentation an at online event here in my country about hyperparameter optimization, cool stuff.
@grave frost hm, as far as i can tell it only looks at one sequence at a time
But it's sharing parameters across all sequences
yeah, but what I want it to share is the relations, not the parameters... 😦
What do you mean relations
as far as i can tell the thing that gets it to care about "nearby" tokens is the positional encoding
Right, just watched the whole video, pretty informative stuff. The thing I was worried about is that it won't exactly pass on any of the relations is has observed. It does seem to be handle input and output both at chracter level, which is really great however from what I have understaood, it doesn't generalize much (or does it?) It makes a pretty comphrensive seq2seq relation but what I would really like is that the relations from the vectors be shared. But it doesn't work like that due to the QKV matrices. It's not exactly 1-on-1 as I would have preferred...
Just checked some of it's implementations, seems like a world of pain writing it all out. https://www.tensorflow.org/tutorials/text/transformer. It takes more code for the model than what I have in the dataset...
Also, I have never made a pre-trained model in my life (preferring custom models). Can anyone confirm if there is way to unfreeze all the layers of a given model i.e training it from scratch on custom dataset??
Facebook just published a paper on end to end object detction with Transformers. Very interesting.
@grave frost i'm still not sure what you mean by "relations" in this context
Also these models take days to train on GPU farms
Maybe there are smaller transformer architectures that can be trained from scratch for specific tasks
@oblique belfry do you have the link?
https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers
Code and paper

We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitl...
How do we use label encoder and how do use columntransformer and onehotencoding together?
Dont really understand how to transform categorical values
@ebon nebula can always audit courses on websites like Edx for free (e.g. GT's OMSA micromasters, or UCSanDiego)
does anyone know anything about encoding/decoding using json?
the channel you opened is probably a better place 🙂
@quiet tulip Thanks
Cool stuff @oblique belfry. Tho I did hear that DETR has some difficulty with smaller objects.
It does get rid of a lot of the manual labor of RCNN's tho.
Doesn't surprise me. I think its cool they were able to use Transformers in that way.
No idea
I personally have never been a fan of RCNNs. Cool to see a new ideas being adapted.
`import json
import requests
import csv
import pandas as pd
import fsspec
print("############################## url")
url = "https://brasil.io/api/dataset/covid19/caso_full/data/?format=json"
api = requests.get(url).json()
print("############################# json")
ds = json.dumps(api)
print("############################# json to csv")
df = pd.read_csv(ds)
df.to_csv("D:\DataScience\Python\covid_api_test_4.csv")
print("############################# done")
`
Trying to put this json api on a csv file..
What is the issue?
Which one?
phosphorus
Guys, any recommendations for Final Year Project on Data Science/ML?
Facial Expression Recognition
too common
I mean they prob won't be looking for something spectacular. It just needs to show your ability to work with the data.
Any project I could work on currently? During my break?
@proud steeple you should look at conference tracks, they have clear goals to achieve, there's plenty of interesting ones and if you get good results, you can potentially get your paper published
There are plenty of AI ones, which is what I did
Hi guys I have a fairly simple problem and wondering how you guys would approach it. I'm using data about covid cases across countries and I have transformed it to track the days since the outbreak started (I consider the outbreak to start when there are over 100 infections per 100k population)...now I have a lot of countries where the outbreak started earlier and I would like to use those countries as regressors to forecast for other countries how it could look for them in the next few weeks...how would you guys approach this? I thought about using Facebooks Prophet library as that has the ability to add regression information but not sure if it would handle having a different timeline of data
The idea is that I could choose which country to forecast for and which Country to use as a Regressor
@acoustic halo I like that way, and i have also worked on certain projects but didn't have a idea to publish my own paper. I feel like publishing a paper about my own findings is not my level, i should have a phd or something else, What do you guys say abt it?
I feel like i should be a researcher to be able to publish a paper ,😞
@halcyon vale I am doing my cs masters right now doing this, you don't have to publish a paper, tracks still covers pretty much all the bases for a CS undergrad final project
Plus they are normally run every year, so youc an look up what previous years winners were and expand on them to get right rankings
Plus these papers aren't like the normal brand new concepts, they mainly are just to explain how you did well on the given task
But they are still technically publications nontheless
You'll have to find a specific conference track that interests you, so lets say i'm interested in natural language processing (which I am)
http://fire.irsi.res.in/fire/2020/home has a few example tracks
Obviously all those are NLP so you will have to search for something specific to your interests
Then you just dive in, try and get good results, normally if you do welll, you also do a short report on your methodolody and results and submit it to them
I have to use tf Datasets for the model I'm using, to match the input of the BERT Embedding Layer. But it looks like the dataset is highly imbalanced because I'm getting huge val loss and low val accuracy, tho training accuracy is almost 0.98+
so i thought of using KFold crossval but idk how to implement it since all my data is as generator objects and nested tensors and arrays inside it, what shoul i do
How did you fine-tune bert?
I would first try and confirm if your dataset really is imbalanced or not
also, how are you generating the tokens to feed into BERT?
i didnt fine tune it I imported the layer from TF Hub, Im using it as an embedding layer in my model
i believe the format that is maintained to feed into the layer is ([[word vectors],[PAD token IDs],[SEP token IDs]], labels)
this part of it is working fine, model trains and i can make preds
What model do you have on top of bert?
Normally, assuming you are doing classifications, it's just a single softmax (and maybe a dropout) on top of the CLS token output
Then you finetune the entire bert model
1D Convolution
Yeah, definitely don't do that
https://pastebin.com/qYEvCP6C
@lapis sequoia this one
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Or if you really insist on doing it with a CNN, I would first do the CLS token approach to get a reasonable baseline
makes sense
I would assume CLS token after finetuning will be pretty similar to using every word token anyway
yeah but i was trying to avoid fine tuning, its running on kaggle and i always run into probelms with TPU
I think the google collab GPUs are just big enough, fine tune on that, save the weights and transfer them over
Or is you don't mind spending a little, AWS p2.xlarge spot instances are ~50p per hour
I think they are 11/12 gb, and they should be able to handle batch sizes of 32-64
I think aws educate gives $100#
The slow way probably

can anyone help me with some simple pandas?
@acoustic halo have you taken Fastai courses? I m working on it and the APIs are great,
@coral walrus okay if I can I will,
I pass a .csv file to a dataframe
df = pd.read_csv (r'...\worksheet.csv', dtype=str)
now I want to access row 1 from column A, pass it to a variable and print(variable)
I imagine it should be easy?
df[0]
[0] gives me a traceback error, [0:1] prints all of row 1 including column names
U just need rows
df[:1, :1]
hey guys
i have a problem I couldnt ||import openpyxl||
i tried ||pip install openpyxl|| and ||pip3 install openpyxl|| both insatlled the package successfully but when I try to import it show this error:
||Traceback (most recent call last):
File "D:/Shunt/Python/PyCharm/app.py", line 1, in <module>
import openpyxl as xl
File "D:\Shunt\Python\PyCharm\venv\lib\site-packages\openpyxl_init_.py", line 4, in <module>
from openpyxl.compat.numbers import NUMPY, PANDAS
File "D:\Shunt\Python\PyCharm\venv\lib\site-packages\openpyxl\compat_init_.py", line 3, in <module>
from .numbers import NUMERIC_TYPES
File "D:\Shunt\Python\PyCharm\venv\lib\site-packages\openpyxl\compat\numbers.py", line 9, in <module>
import numpy
File "C:\Users<user name>\AppData\Roaming\Python\Python38\site-packages\numpy_init_.py", line 138, in <module>
from . import distributor_init
File "C:\Users<user name>\AppData\Roaming\Python\Python38\site-packages\numpy_distributor_init.py", line 26, in <module>
WinDLL(os.path.abspath(filename))
File "C:\Users<user name>\AppData\Local\Programs\Python\Python38\lib\ctypes_init.py", line 373, in init
self._handle = _dlopen(self._name, mode)
OSError: [WinError 193] %1 is not a valid Win32 application||
Please anybody here can help me!!
THANK YOU!!
now I want to access row 1 from column A, pass it to a variable and print(variable)
@coral walrus df.iat[0, 0]
@velvet thorn @halcyon vale helped. thanks anyway 😄
trying to figure out how to loop through cells now 🤔
@coral walrus what are you actually trying to do
Usually looping through individual cells is the wrong approach in pandas
Well not "wrong" but definitely less than ideal and not idiomatic
@desert oar
I need to read cell values from a .xlsx doc, pass the values to variables so pyautogui can typewrite the variables into a 3rd party program
A few specific cells? Or whole columns?
Because if you just need specific cells you can use openpyxl instead and skip all the pandas stuff
honestly I forgot about openpyxl until 30 minutes ago, but it works now lol
If you want to work on the whole sheet then yes pandas is ideal
Alright
Can you give an example of what you want to do specifically, in words
Or pseudocode
can I pm you?
Id rather not. Don't need to show anything secret, just eg "take cell A5 and cell D6 then add them"
Stuff like that
yeah np, give me a minute
class generator:
def __call__(self, feature_set, label_set):
with h5py.File('ANN_Dataset.hdf5', 'r') as hf:
for feature, label in zip(hf[feature_set], hf[label_set]):
# feature = feature.flatten()
yield feature, np.array([label])
def data_iter(feature_name, label_name):
ds = tf.data.Dataset.from_generator(generator(), (tf.float64, tf.int64), (tf.TensorShape([227, 227, 3]), tf.TensorShape([1,])), args=(feature_name, label_name)).repeat()
iterator = iter(ds)
feature, label = next(iterator)
feature = tf.expand_dims(feature, axis=0)
return feature, label
model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10)```
Having trouble iterating through my data, it does not grab all the 28k training data, only 1, its not iterating through the data as it should.i dont know what the problem w/ your data is, but you can simplify that generator
it doesn't need to be a class
just a function
@desert oar
when I fetch 3 columns of data from a database, I export the data to a .xlsx file
in my python script I use pandas to read the data from the .xlsx file, and I pass individual cell values to variables
the variables let's pyautogui know which values to paste into a 3rd party program
all this works now, but I'm trying to figure out now if there's a way for me to loop through the 3 columns 1 cell at a time
@fervent bridge ```python
def data_loader:
with h5py.File('ANN_Dataset.hdf5', 'r') as hf:
for feature, label in zip(hf[feature_set], hf[label_set]):
yield feature, np.array([label])
def data_iter(feature_name, label_name):
ds = tf.data.Dataset.from_generator(
data_loader(),
(tf.float64, tf.int64),
(tf.TensorShape([227, 227, 3]), tf.TensorShape([1,])),
args=(feature_name, label_name)
).repeat()
iterator = iter(ds)
feature, label = next(iterator)
feature = tf.expand_dims(feature, axis=0)
return feature, label
hopefully this change makes sense@coral walrus yeah, you can do that a few different ways. probably the easiest is something like this:
colnames = ['Red', 'Green', 'Blue']
for c in colnames:
col = data[c]
for label, value in col.items():
print(f'label={label}, value={value}')
do_something_special(value)
I'll have to store the cell values in an array then right
show me how you're loading the data
again this is assuming you've already read the data into pandas
df = pd.read_excel(r'C:\Users\brmlq\Desktop\vscode workspace\python\app\worksheet.xlsx', converters={'project_id': lambda x: str(x)})
#format df col: LIN '0000'
df['LIN'] = df['LIN'].apply(lambda x: '{0:0>4}'.format(x))
yeah, I only have to make a working loop now
TO, LIN and MGD
a1 = df["TO"].values[0]
a2 = df["LIN"].values[0]
a3 = df["MGD"].values[0]
example of how I call each cell
row 2 would be .values[1], etc.
dont bother with that
gotcha
use .iloc[0] instead
can you give a somewhat more complete but hypothetical example of how you use the data?
I couldn't make .iloc work, I only started working with pandas today 🤷♀️
again, pseudocode is fine
make up function names etc
i have no idea how pyautogui is supposed to work
.values is kind of deprecated anyway btw
pyautogui simulates keyboard and mouse input, so it'll move the mouse to a different part of the screen, left click, insert data, hit enter, etc.
@desert oar are you familiar with as/400
nope
but ok lets back up
you can just do this the really stupid naive way
if you dont need good looping performance
the whole process is super lightweight so performance won't be an issue either way
you can just do
for i in range(len(df)):
a1 = df["TO"].iloc[i]
a2 = df["LIN"].iloc[i]
a3 = df["MGD"].iloc[i]
do_special_things(a1, a2, a3)
what data types are in these columns?
TO and MGD are ints
LIN is converted to string
because I've added leading zeros to it
ie 0010 not 10
if I read directly from .xlsx/csv python will interpret 0010 as 10
@fervent bridge it looks like your data_iter is creating an iterator, pulling the first item off the iterator, then just returning it. is that supposed to be a generator with for feature, label in ds: yield tf.expand_dims(feature, axis=0), label ?
@coral walrus yeah just try that
actually you can use .iat[i] instead of .iloc[i]
iat specifically only returns single values
so it can help you catch mistakes if you accidentally pass a list or something like that
whereas .iloc will silently return different output if you pass a list
so a1 = df["TO"].iat[i]?
yep
.iloc and .iat are positional accessors. they access data by row/column number, starting from 0
.loc and .at are label-based accessors. they access data by row/column label, which varies depending on the dataframe
to give you a more complete example of what I want to do btw
say this is my .xlsx file
pyautogui must first grab the value of A2, then B2 and finally C2
once it has used all 3 values
it must loop to the next row
A3
does that make sense?
yes
so do what i suggested
for i in range(len(df)):
a1 = df["TO"].iloc[i]
a2 = df["LIN"].iloc[i]
a3 = df["MGD"].iloc[i]
pyautogui.whatever(a1, a2, a3)
can you explain the bottom line for me?
🤷♂️ it's "do something with the 3 values you extracted"
like i said i have no idea what pyautogui's api looks like or how it's used
you can do this too, idk
for i in range(len(df)):
for colname in ("TO", "LIN", "MGD"):
val = df[colname].iloc[i]
do_something(val)
don't think about this too hard
I just have to try things out for a while before I get it, my bad
you're fine 🙂 all i'm saying is, it's pretty forgiving. now that you know how to get values you can just do whatever you want with them
and the pandas part is basically done
TypeError: 'numpy.int64' object is not iterable 🤔
@desert oar had this error a while ago, I think I asked numpy to turn the value into a string but I forgot how
for i in range(len(df)):
a1 = df["TO"].iat[i]
a2 = df["LIN"].iat[i]
a3 = df["MGD"].iat[i]
pag.leftClick(1633, 286)
pag.typewrite(a1, a2, a3)
17, so pag.typewrite(a1, a2, a3)
[Running] python -u "c:\Users\brmlq\Desktop\vscode workspace\python\app\import pandas as pd.py"
Traceback (most recent call last):
File "c:\Users\brmlq\Desktop\vscode workspace\python\app\import pandas as pd.py", line 17, in <module>
pag.typewrite(a1)
File "C:\Program Files\Python38\lib\site-packages\pyautogui_init_.py", line 588, in wrapper
returnVal = wrappedFunction(*args, **kwargs)
File "C:\Program Files\Python38\lib\site-packages\pyautogui_init_.py", line 1626, in typewrite
for c in message:
TypeError: 'numpy.int64' object is not iterable
yes it looks like you didn't use typewrite correctly
also you just wrote pag.typewrite(a1) in the traceback, is that intentional?
you'll need to review the pyautogui docs to see what arguments you're supposed to pass there
what I did last time was convert the dataframe/numpy element to a string value
what input does typewrite expect?
just start there
it looks like .write expects a string as its first parameter... did you mean to send a string?
i dont see docs for .typewrite
makes no difference to me if it's an integer or string value
as long as it can read it
yes.
you gave the wrong kind of data to pyautogui.typewrite
this has nothing to do with how you want to handle the data
here, i dug up the source code https://github.com/asweigart/pyautogui/blob/master/pyautogui/__init__.py#L1602

GitHub
A cross-platform GUI automation Python module for human beings. Used to programmatically control the mouse & keyboard. - asweigart/pyautogui
but this error only occurs when you're asking typewrite() to write the value from a variable that comes from a numpy array or pandas dataframe
no, it doesn't
it occurs when you give it a goddamn number
Args:
message (str, list): If a string, then the characters to be pressed. If a
list, then the key names of the keys to press in order. The valid names
are listed in KEYBOARD_KEYS.
interval (float, optional): The number of seconds in between each press.
0.0 by default, for no pause in between presses.
if I create a variable var1 and assign it the value of 5
and I ask typewrite to write var1, it'll write 5
do you know the difference between a string and a float
try pyautogui.write(5) and pyautogui.write("5")
both of those work?
its a legitimate question, some people find themselves neck deep in programming projects without basic knowledge, or trying to transfer specific concepts from other languages that dont apply in python
I've solved this problem before. there's a conversion happening when you fetch numpy/dataframes data.
I just don't remember what I did last time, I'll figure it out
there is no conversion
you literally just need to convert it to a string
pandas loaded your data as integers
https://github.com/asweigart/pyautogui/blob/master/pyautogui/__init__.py#L1626
it's clearly trying to iterate over message, in the exact line where your error comes from
GitHub
A cross-platform GUI automation Python module for human beings. Used to programmatically control the mouse & keyboard. - asweigart/pyautogui
you can't iterate over native python floats or numpy floats
I don't disagree with you
sounds like you just need to specify a converter in read_excel for the column w/ your message in it 🤷♂️
or convert the value inside your loop
for i in range(len(df)):
a1 = df["TO"].iat[i]
a2 = df["LIN"].iat[i]
a3 = df["MGD"].iat[i]
a1 = format(a1, 'd') # or use whatever format spec you want
pag.leftClick(1633, 286)
pag.typewrite(a1, a2, a3)
there's nothing special or magical happening here
I understand
maybe you need to call int(a1) first because it's a numpy int64 and maybe format will get confused by that
that is the only unusual thing i can think of here
I want to use random forest algorithm to classify my products based on their description. How can i use the description column here?
@long badger either you use it as a categorical feature, or you find some way to convert it to something useful, like a vector embedding
If I use it as categorical feature, it will not emphasize on the words in the description column right? I will just consider the entire thing.
correct
I want to do it on the words
if the descriptions are all different then it will be useless as a categorical feature anyway
ok, have you heard of a "bag of words" model?
yeah.. descriptions are differnt
I was thinking if there is way to split that description or something
I am not aware of it.. I will check it out
I am kind of beginner
yeah
well.... bag of words doesnt work very well with random forest
because you end up with very big sparse representations
oh
that doesn't work well with the "randomly select features" part
what would you suggest I look into
vector embeddings
okay
so let's say in your text corpus you have 1000 unique words. if you use binary bag of words that means you have 1000 binary features
Thanks
tf-idf is still going to be sparse
so you need a denser representation e.g. using vectors from word2vec
for a whole "document" typically you would average all the vectors in the document
that's a super basic approach but it's a sane default
@desert oar pag.typewrite(''+str(a1)) did the trick
that's uh, one way to do it
why not use format like i showed you? or just str without the ''+ part
format works just fine, I just prefer to format inline and not add extra lines 😄
it doesn't accept +str
ohh yeah, that's a good idea
i have some questions about neural networks, some weeks ago i started getting into machine learning etc and id like to do a small project. for that id need the neural netwotk to recognise an object on my screen (it wouldnt change much, still isnt the same every time). how many train pictures do i need to train it to be somewhat reliable? hundreds? thousands?
it depends entirely on the problem at hand, the easier it is to discriminate the object from the background and the other objects, the less data you'll need
using pre-trained models can also reduce the amount of data needed by an order of magnitude and make the model much more robust
isn't there that one off the shelf model that people fine tune? yolo?
i guess maybe that wont transfer well to a computer screen
thx, also, does running code from collaboratory not work with for example looking for things on my screen or would it be the same as if i ran it on my pc
yolo or faster r-cnn are the two most common models for generic object detection
depending on whether or not you need real time inference
it would, at best asap lol otherwise it woudlnt be worth it to automate it
the definition of "real-time" here is definitely a stretch depending on what you want to do, faster r-cnn can still run at a few FPS
unless you want to do like 30+ inferences per second, faster r-cnn would probably be fine
aight ill look at the things you proposed, then come back soon, ty for the help
nah its a simple task, like it has to check once every 3 secs
Does anybody have any idea if it is possible to take a pre-trained model and instead of fine-tunining it's last layers, unfreeze all it's layers and have it train on custom data?? I would use something which has a smaller architecture, but is there even a way to accomplish this??
Depending on the model, Bert for example, you do train the entire model on new data
Yeah, but how exactly do you do that?? Is there a way to unfreeze all the layers? or do the authors provide a repo where you can simply run the code by specifying a few parameters??
Both, for instance the transformers library has a bunch is pretrained models, stuff like Bert by default isnt frozen
Intact I can't think of one that is frozen
hmm.. I have trying to search any resource for helping me train those type of models from scratch but couldn't find any. Would you happen to know any handy resource for that kind of stuff?
I mean, you don't want to fully train a pretrained model, but in essence you just train them like you would any other model that wasn't pretrained, you train on top of the prelearned stuff, the only real difference is you only train for a few epochs, maybe around 3-8 at most and use a low learning rate
Actually, I have never pre-trained a model in my life. So, I was curious whether the dev does have some control over which layers to unfreeze during the fine-tuning. If there indeed is some mechanism where it unfreezes all the layers of the model, then mission accomplished. So my question was indeed there is such a mechanism?? Because it seems to me that if there indeed was such a way, then there should be many resources online describing it. That made me doubt whether something like this is doable. Of course, I could always take the hard way out and go back to lower-level code but then it would become cumbersome.....
You just want to use the same architecture
On new data
Also I still suggest not using bert itself, verbatim
Maybe start with a smaller simpler transformer architecture
as for your actual question, idk how pytorch and tf models are stored on disk but im sure theres a way to "clear" all the weights and start over
@desert oar No no, I wasn't planning to use BERT at all since it would be a total disaster (BERT studies the sequences from both directions which is probably not what I want) Though clearing the weights file idea seems clever but would be null if there isn't a already-implemented-and-written way to unfreeze and train all the layers....
I'm working on a module and there are two models that are used by a few functions, so I just load them in the global scope. But then you can't change what models the functions are using. Is there a solution that doesn't require me putting the whole thing into a class?
In fact one of the two models is BERT
BTW Which resources are you using to train your model? It is my understanding that BERT takes days to train even on a cluster of GPU's....
Can you give an example @serene scaffold
It's on my github. One sec.
@grave frost all transformers work from "both ends"
Im not sure why you wouldnt want yours to
Isn't your project encrypted documents of finite known size?
there are legitimate use to unfreezing the entire model without clearing weights, and you can do that with a parameter in tensorflow, i'm sure it's the same with torch
That would be if you wanted to train on additional samples right?
yes, perhaps i misunderstood
My impression is that they want to reuse an existing architecture but train it from scratch
is it possible to [...] unfreeze all it's layers and have it train on custom data??
i was referring to that comment i guess
https://github.com/swfarnsworth/pseudobert/blob/master/create_rels.py
There's the bert model and the spacy model getting loaded, but I'd like for people to be able to swap those out for models trained on other domains.

GitHub
Contribute to swfarnsworth/pseudobert development by creating an account on GitHub.
Ah
OK let me look at what you did
what scikit-learn does for example is define a standard interface for models
.fit .predict et al
so the user can always provide an object w/ those methods and it will more or less act like a scikit-learn model
ducks and quacking etc
so yeah
is this meant to be a command line tool? or a python api?
if its a command line tool you'd probably have to have them specify a model by name or file path
which you'd then load inside your code
e.g. instead of nlp = spacy.load('en_core_sci_lg') at top level, you'd load that inside main based on the model name the user provided, and you'd then pass the nlp object around to functions
likewise with bert and bert_tokenizer
is this meant to be a command line tool? or a python api?
@desert oar
I guess a command line tool but I like when stuff I write can be used both ways
yep
then having your functions accept nlp as a parameter is good too
because users can just write nlp = spacy.load('en_core_web_md') instead if they want
But then the function signatures are going to get so bloated 😢
another option is to wrap it all up in a class, like i think you were suggesting
class Pseudofier:
def __init__(self, nlp=None, bert=None, bert_tokenizer=None):
self.nlp = self.load_default_nlp() if nlp is None else nlp
self.bert = self.load_default_brt() if bert is None else bert
self.bert_tokenizer = self.load_default_bert_tokenizer() if bert_tokenizer is None else bert_tokenizer
then pass around an instance of Psuedofier
Ds model signatures are usually a bloated mess. Just too many knobs to turn usually. Don't worry about it too much
that too
class Pseudofier:
default_nlp = 'en_core_sci_lg'
default_bert_path = './scibert_scivocab_uncased'
default_bert_tokenizer_path = './scibert_scivocab_uncased'
def __init__(self, nlp=None, bert=None, bert_tokenizer=None):
self.nlp = self.load_default_nlp() if nlp is None else nlp
self.bert = self.load_default_brt() if bert is None else bert
self.bert_tokenizer = self.load_default_bert_tokenizer() if bert_tokenizer is None else bert_tokenizer
@classmethod
def load_default_nlp(cls):
return spacy.load(cls.default_nlp)
@classmethod
def load_default_bert(cls):
return tfs.BertForMaskedLM.from_pretrained(cls.default_bert_path)
@classmethod
def load_default_bert_tokenizer(cls):
return tfs.BertTokenizer.from_pretrained(cls.default_bert_path)
im not sure its really a benefit tbh
i guess if you like namespacing things
otherwise you'd just have top-level load_default_* functions
and your "internal junk" would take up the first 3 parameters instead of the first
alternatively you can move all the top level functionality into Psuedofier as methods
so e.g. _pseudofy_side becomes Psuedofier._pseudofy_side
and Pseudofier.pseudofy_file etc
so you can pull all the stuff you need off of self, and the user doesn't need to pass around this weird object
The whole thing seems a bit confusing. There are NMT's which generalize to data but take days to train on multi-gpu even on simpler architectures and then you have transformers whose use-case isn't exactly fully understood. I am like stuck in the problem. The main factor remains that I don't have enough computational power to try both of them. I guess I can just randomly choose one of them and start training. It's all pretty much unexplored territory. Do you guys think that transformers are good enough to handle direct seq2seq relations?
you still didnt explain what you mean by "direct seq2seq relations"
transformers are for mapping between sequences, yes
encoder/decoder, thats what they call it
https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/img/encoder.png so you have inputs and outputs, you run the multi-head attention step on the input sequence and the output sequence separately, then you use those together in another multi-head attention step
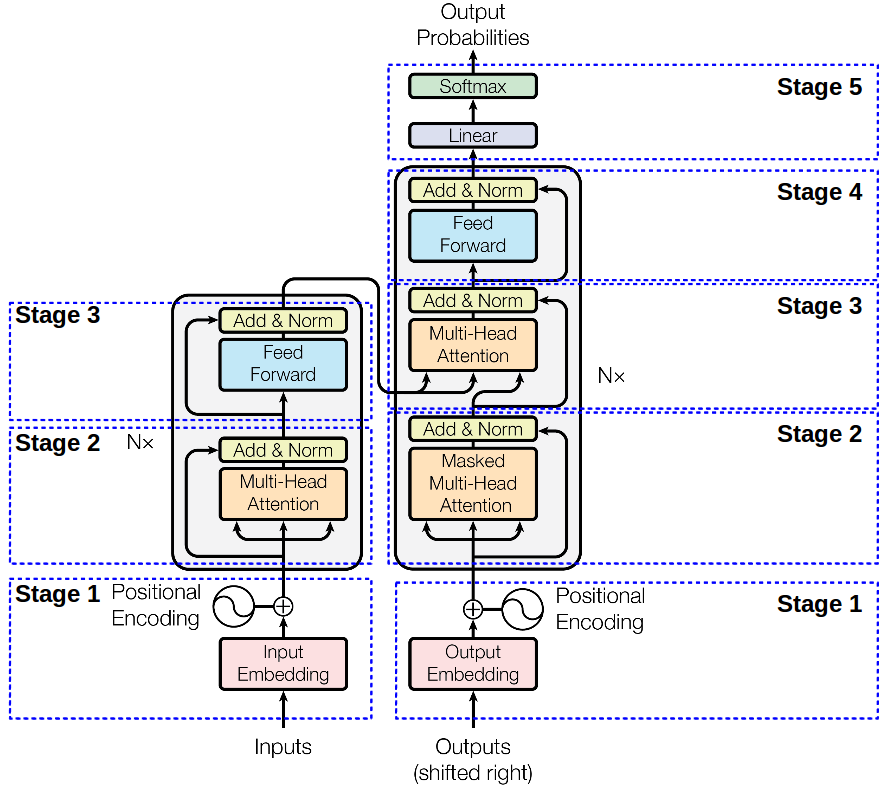{kind=link}
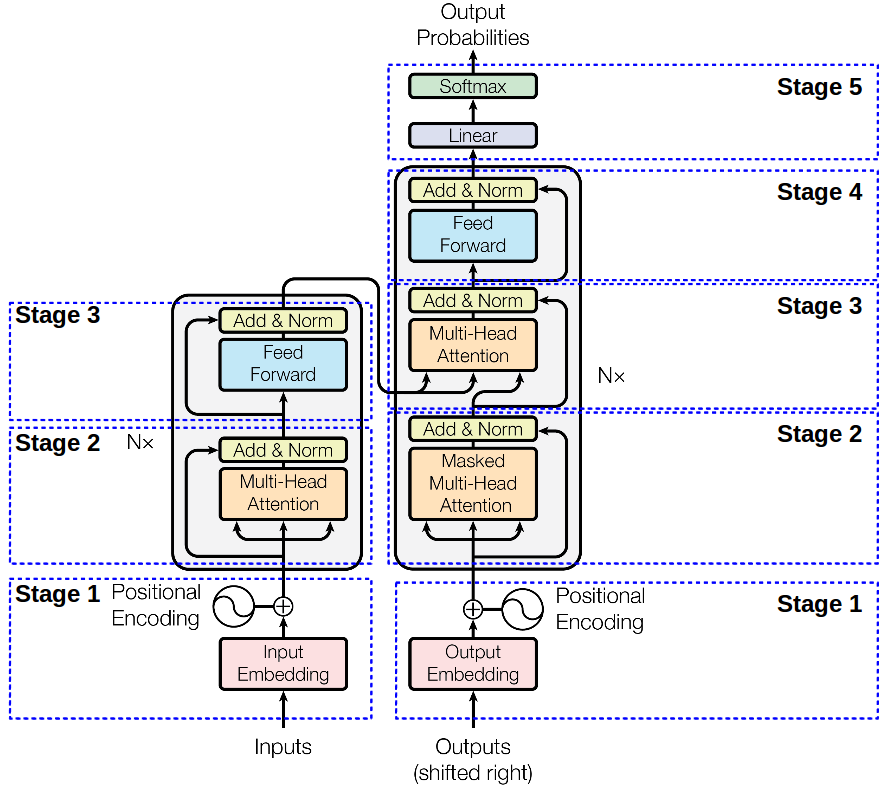
the example in the video i sent you want translating english to french
is that not seq2seq?
No, the thing is that finding direct seq2seq relations is much more tougher. See, transformers work on Attention mechanism but the fact remains - they donot find static relations between the seq tokens. Rather their vectors are much more generalized to other tokens too which is perfectly fine for NLP tasks. However, since ciphers have a much more complex relations it seems all very uncertain. Looks like I would have to experiment ot find it all out...
i still dont understand what you mean
you want relationships between tokens or sequences?
i mean, im not exactly an expert here. maybe someone else knows what you mean and can point you in the right direction
no, relation b/w tokens to tokens. not sequences...
i see
but you want to use the contextual sequence information to learn that relationship?
i actually have a similar need albeit in a very different problem domain
id be curious if you find something
yes, but it should be on a token level rather on a sequence one...
yes
i wonder if the embeddings generated by transformers can be used for tihs
there is also this https://research.fb.com/downloads/starspace/ which i havent used but ive been meaning to try it for something at work
StarSpace is a general-purpose neural model for efficient learning of entity embeddings for solving a wide variety of problems.
I have tried embeddings in Keras But after visualizing them on 15 dimensions, it doesn't seem to have any correlation. Maybe I will try bumping them to 600-700 dims and then seeing the result, but if the relation is there, it is kinda complex.....
Visualizing with 100 dimensions
well isnt the problem that the input and output embeddings live in entirely different spaces?
also conceptually i wonder if you could use the QKV matrices directly for this
or if you could/should now go ahead and train a model that directly tries to map input vectors to output vectors
how did you produce those vectors btw? id be curious to see the code
@fervent bridge it looks like your
data_iteris creating an iterator, pulling the first item off the iterator, then just returning it. is that supposed to be a generator withfor feature, label in ds: yield tf.expand_dims(feature, axis=0), label?
@desert oar Yeah its just returning the first item not all 28k training sets
I tried to do yield in the data_iter as I had before but its returns an error
also when I change data_loader to a function instead of class it says generator must be callable @desert oar
just don't call it
tf.data.Dataset.from_generator(data_loader, ...
instead of
tf.data.Dataset.from_generator(data_loader(),
there's an args keyword argument
X_train, y_train = data_iter('X_train', 'y_train')
ValueError: too many values to unpack (expected 2)```@odd yoke @desert oar
Woah nice it worked @desert oar @odd yoke
had to pass data_iter directly into the model.fit instead of splitting
Thanks guys
How do I get the quantile function (or an evaluation of it) of a multivariate pdf?
scipy has the following method, but I'm not sure I understand the input and output correctly:
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.mstats.mquantiles.html
WARNING:tensorflow:Model was constructed with shape (None, 1, 227, 227, 3) for input Tensor("flatten_input:0", shape=(None, 1, 227, 227, 3), dtype=float32), but it was called on an input with incompatible shape (None, None, None, None).```@desert oar Should I worry? python (None, None, None, None).
It trains but I see that it does so to fast?, Loss is incredibly low at 0.0089
dropped to 0.0020
Looks wrong to me
Yes worry
I'm on my phone now so all I can say is, read the docs more carefully
Am I able to ask a statistics question ?
Wow. How do you even get a shape (None, None, None, None)?
@tidal boughyeah that's what I want to know for some reason its converting all my values to None
Before going into my model the shape is fine, after going into the model it returns all value as None
Seems to happen in flatten
None in shapes generally mean variable length
17/Unknown - 2s 91ms/step - loss: 0.1901 - accuracy: 0.9412```this is what I am getting during training
Seems to fast of training ? to low of a low everytime the lose drops by about .06
and accuracy to high.
shape=(None, 1, 227, 227, 3) how can you have an input layer of None
how bigs your training set?
class MnistModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(input_size, num_classes)
def forward(self, xb):
xb = xb.reshape(-1, 784)
output = self.linear(xb)
return output
model = MnistModel()
Could someone explain this the video isn't too clear
and I'm not familiar with OOP
but the tutorial for OOP i'm taking didn't cover super()
yet
alright
wait
I thought inheritance is like
class Case():
def __init__(self, a, b ,c):
self.a = a
self.b = b
self.c = c
def something(self):
print(f"{self.a}, {self.b}, {self.c}")
A = Case()
A.something()
I thought that A.something() is inheriting from the class method or something
oh wait
so inheritance is just that
class MnistModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(input_size, num_classes)
def forward(self, xb):
xb = xb.reshape(-1, 784)
output = self.linear(xb)
return output
model = MnistModel()
So the class MnistModel will have the properties of nn.Module as well as the custom methods?
Yeah. super is confusing when I first saw it. There are many tutorials and blogs that don't use super.
The only time I've seen it so far
is in the PyTorch tutorial
for ML/DL
maybe I'm just not deep enough into the tutorial
Anyone know the best way to input an image into a ml model?
Use Tensorflow tf.data.Data API for ml models
@sudden cedar what's your model like g
I'd suggest reading up the input pipeline stuff but I normally convert my images to numpy arrays
usually you would use a tool like opencv imread to read the image and convert it into a numpy array and input that into the model
yeah just any package that can read the image into an array, there are multiple
@inland ruin .shape is not a function
it's an attribute, containing a tuple
[0] gets the 0th element of the tuple
@desert oar @bitter harbor I tried this after and it gives me no shape error, I flattened my Features before passing them into the model.
def generator(feature_set, label_set):
with h5py.File('ANN_Dataset.hdf5', 'r') as hf:
for feature, label in zip(hf[feature_set], hf[label_set]):
feature = feature.flatten()
feature = tf.convert_to_tensor(feature, dtype=tf.float64)
feature = tf.expand_dims(feature, axis=0)
label = np.array([label])
label = tf.convert_to_tensor(label, dtype=tf.int64)
yield feature, label
model = tf.keras.Sequential()
model.add(tf.keras.layers.Input((154587)))
model.output_shape
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(generator('X_train', 'y_train'), validation_data=(generator('X_val', 'y_val')), epochs=10)```@bitter harbor After further troubleshooting it seems that converting np.arrays to TS objects automatically adds and extra dim
So it seems as I was converting and then expanding it gave it two extra dims
inputs = np.array([
[13930, 11977, 1003, 174, 3], [15370, 13930, 1027, 585, 3], [11618, 15412, 1848, 631, 3], [10781, 12266, 1846, 253, 3],
[14524, 12266, 1038, 1157, 3], [13871, 12266, 555, 781, 3], [12266, 14814, 1610, 192, 3], [12266, 12206, 1415, 295, 3],
[13930, 10140, 19, 1118, 3], [11618, 13485, 101, 799, 3], [11278, 13930, 1306, 612, 3], [11278, 13930, 1843, 612, 3],
[12266, 12451, 735, 817, 3], [11140, 12266, 1847, 201, 3], [11618, 10785, 1441, 266, 3], [12266, 13158, 1440, 429, 3],
[12266, 11049, 2148, 74, 3], [12266, 10747, 213, 308, 3], [12953, 12266, 1554, 1416, 3]
], dtype='float32')
targets = np.array([
[1117], [1216], [2120], [2004], [1330], [838], [1718], [1531],
[2204], [1139], [1404], [1945], [1039] , [1941], [1557], [1616],
[2224], [2250], [1928]
], dtype='float32')
plt.plot(inputs, label="inputs")
plt.plot(targets, label="Targets")
plt.title("Scatter diagram")
plt.show()
So here is what i'm using to plot
and I'm just curious to know what the plotted graph means
So I have no idea what this is
I managed to do this
there really isn't a learning rate thing
Hello everyone
Could you give me some direction as to create this in a Jupyter notebook
@desert parcel Yeah, what you're plotting isn't useful.
Do you manually calculate loss at every iteration?
If so, you just add that loss to the list of them. Then you plot that list to see how loss changed by iteration.
Ok so it definetly has to do with the shape being outputted, but I don't see where its going wrong
def generator(feature_set, label_set):
with h5py.File('ANN_Dataset.hdf5', 'r') as hf:
for feature, label in zip(hf[feature_set], hf[label_set]):
feature = feature.flatten()
# feature = tf.convert_to_tensor(feature, dtype=tf.float64)
# feature = tf.expand_dims(feature, axis=0)
label = np.array([label])
# label = tf.convert_to_tensor(label, dtype=tf.int64)
yield feature, label
def data_iter(feature_name, label_name):
ds = tf.data.Dataset.from_generator(generator, (tf.float64, tf.int64), args=(feature_name, label_name))
for feature, label in ds:
# feature = tf.expand_dims(feature, axis=0)
yield feature, label
model = tf.keras.Sequential()
model.add(tf.keras.layers.Input((154587,)))
model.summary()
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(data_iter('X_train', 'y_train'), validation_data=(data_iter('X_val', 'y_val')), epochs=10) ```
If I comment out expanding my features it returnsValueError: Input 0 of layer sequential is incompatible with the layer: expected axis -1 of input shape to have value 154587 but received input with shape [None, 1]```if I expand my dims then it runs but wrong as before
@desert oar
This is the shape before expanding python tf.Tensor([0.67058824 0.6627451 0.61176471 ... 0.68235294 0.66666667 0.62352941], shape=(154587,), dtype=float64) tf.Tensor([0], shape=(1,), dtype=int64)
This is the shape after expanding and before running, python tf.Tensor([[0.7372549 0.72941176 0.73333333 ... 0.66666667 0.65882353 0.67843137]], shape=(1, 154587), dtype=float64) tf.Tensor([0], shape=(1,), dtype=int64)
Does anyone have any recommendations on how to ensemble the results from two neural nets?
So far I have tried averaging and weighted averaging of the softmax outputs
These are for ensembling sklearn models though right?
i think it works with keras
This look like throwing all the NN outputs into a LR model
Posts and writings by Joel Grus
Bar plotting never loads ?
@arctic cliff is there any code before that?
Absolutely
hey anyone could help to create an array. I'm a bit lost atm 😆
a regular array? if so: yes haha
A Python list([1,2,3])? An array from that library that's rarely used? A numpy ndarray?
y'all know of any dataset with lots of date columns ?
I have a dataset with 2 date columns @modern canyon
Same code
One in vs code
The other is in jupyter
I want the x to have only 2 values as I gave to it
BROWN_MUSHROOM.plot(x="lastUpdated", y=["buyPrice", "sellPrice"])
for the x I want to use the index of the dataframe
how can I do that?
BROWN_MUSHROOM.index, Ig ?
it iterated over the index
and raised a keyError
KeyError: "None of [DatetimeIndex(['2020-07-25 14:06:34', '2020-07-25 14:07:13',\n '2020-07-25 14:08:04', '2020-07-25 14:08:44',\n '2020-07-25 14:09:34', '2020-07-25 14:10:23',\n '2020-07-25 14:11:04', '2020-07-25 14:11:53',\n '2020-07-25 14:12:43', '2020-07-25 14:13:23',\n ...\n '2020-07-25 21:45:43', '2020-07-25 21:46:43',\n '2020-07-25 21:47:43', '2020-07-25 21:48:44',\n '2020-07-26 15:09:14', '2020-07-26 15:10:44',\n '2020-07-26 15:12:53', '2020-07-26 15:16:33',\n '2020-07-26 15:22:34', '2020-07-26 15:29:53'],\n dtype='datetime64[ns]', name='lastUpdated', length=526, freq=None)] are in the [columns]"
How many rows do you have
So you want to list every date ?
so like
i want to use my index column for plotting
this is what i wanted to achieve
but i was just wondering how did they reference the index
so the default for the x is the index of the dataframe
i was just wondering how did they reference the index
I misread that
i was just wondering how did they reference the index
@idle otter Of the dataframe itself ?
yes
Np
I thought that's what you were trying to do? Reindexing your dataframe ?
Isn't plotting refrencing the x values to the dataframe index by default ?
yes
im just trying it on a line graph
my goal was to make a scatter plot
and it doesnt work on the scatter plot
it works the way i want on a line graph
I see !
So your problem is with the scatter plot ?
yes

Stack Overflow
I am trying to create a scatter plot from pandas dataframe, and I dont want to use matplotlib plt for it. Following is the script
df:
group people value
1 5 100
2 2 90
1 1...
ah