#data-science-and-ml
1 messages · Page 183 of 1
I've decided to exclude fun coureses for now. The main aspect I'm currently undecided on is if I want to study modern applications of GenAI/latest advances or not
What interests you is not necessarily just "fun"
you could be interested in stuff that is really hard
but fashionable stuff can also be very hard. And it's a hard slog if you picked something because it is fashionable but you are not that interested in it
Yeah. Especially with how I learn/engage in topics. If I'm not interested, easy or hard, I'm gonna struggle paying attention
may i dm you, i believe i have a description/formula for qualia
you might like this topic
What is job market for researching/applied ai engineer look like right now. is it really this popular and demand or the hype has died down?
I really liked learning ai stuff so just wondering if is good for jobs
the tricky part is distinguishing between jobs where you're actually doing research and ones where you're just building agentic pipelines and stuff. the hype is really pointed at the latter.
I can give a more thorough response later.
what you mean by this is, I don't need to learn fancy algorithm or math to do ai, all I need just a degree + coding? so how about ai research how would someone new to ai approach this?
that's not what I mean. if you want to be an AI researcher, you do have to know "all the fancy algorithm or math"
oh sorry I mean for ai engineer I don't need math and other stuff, but for research I need those right?
depends on what you mean by "AI engineer". job titles don't really have consistent meanings.
If you want to use existing models in a way that doesn't require any knowledge of how they work, I would not consider that "AI engineering".
I wouldn't even have a specific word for that kind of software development.
oh
And to be clear, I do that kind of software development, in addition to the scientific part of my work.
so does researching ai pay well or is just a thing on your resume
so they can "vibe" better?
I'm not sure what you mean. People can only vibe code because of the research that went into developing generative language models.
so they can "vibe" better
who is they?
oh I meant that doing ai research does not benefit applied ai jobs. like writing agentic ai pipelines
or that false
because I really liked learning and making ai work
"doing ai research does not benefit jobs"
can you try to communicate this again, but phrase it completely differently? I do not understand what you are trying to say.
better? english is not my first language
Thank you for making the extra effort.
You do not need to know how generative language models work to be able to write agentic pipelines.
If by "AI job" you mean "job where you research AI", then of course, you do need to understand how AI actually works.
I guess understanding a few principles about generative language models can help. But you don't need to like, understand transformers
I have to go--I'll pick this up later
ok thanks
Can you expand a bit on what you're specifically targetting? AI has become an overloaded term and it's important to distinguish between researching AI versus using AI to perform research.
Oh, you clarified, agentic stuff?
You don't specifically need to know how LLMs work under the hood to use/apply them, but the market is competitive enough that being somewhat familiar will still give you an edge over people who are pure implementation.
Maybe someone has a less cynical take, but understanding/using/researching the architecture is fairly distinct from their application. Still, it's important to holistically understand their capabilities and limitations.
thanks for the response I was just deciding whether or not to enter this field
why did it take me THIS long to find out about this?!
https://www.openml.org/search?type=data&status=active
It's hard to say. LLM-powered applications are all the rage right now. While LLMs are here to stay, I think they're currently being overhyped and I'm not sure where they will land after things cool down.
I think after cooling they will be an important force multiplier that doesnt replace human creativity or direction
I use it to make really intricate systems well and quickly and constantly need to debug, keep it on track, and say no thats not the direction
Guysss does anyone have a good idea for a 24 hr hackathon project in aiml?
hello
hi
how are you
hello @tulip slate, this channel is for talking about data science and ML, rather than socializing. have you worked with DS/ML before?
I came to this channel to learn because I love data.
what have you tried to do with data?
I've recently started learning Python, so if you have any suggestions or advice on how to learn it better, I would be very grateful.
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
Hmm. A lot of real world datasets suffer from having too many features but not knowing how to turn that into actionable intel. What about some exploratory data analysis on a dataset with a large amount of features? (n>20 at a minimum, you can go higher if you want to challenge yourself). Aim for dimensionality reduction/feature extraction techniques.
What's your current skill/knowledge level? Any area you feel weak in that you might want to practice?
Oh thnx for the suggestion, btw i know only basic python 😅 nothing in ai and data science as such , I'll learn that first then work on this
Haha, gotcha. Okay. I would recommend practicing more with python and then if you'd like to dive into some ML/AI, utilize sklearn and try implementing a Linear Regression model. Doesn't need to be a large dataset, but pick something with numeric (as opposed to categorical) variables. Separate the data into training data and test data, then train the model and see how it performs on the test set. It's pretty fun seeing the results and how good you can make predictions!
Ohhh thanksss , I don't understand most of what u said rn but maybe I will when I watch some youtube videos on it and get familiar with the terms
Sure. And feel free to ask any questions on the server if you need anything clarified, once you do
Alright, I know little about data, and a bit about science, and nothing about data science.
I want to be able to analyse data from this ingame market to make money 🤑 (ingame money 😢)
I'm guessing that some important things to know are going to be:
- What items are for sale on the market
- How many buy orders an item has
- How many sell orders an item has
- The volume of that item in buy orders
- The volume of that item in sell orders
- The actual amount of that item sold each day
I don't really know any data-ey terms but I'm guessing there are terms for this struff 😭
I'm just not sure how to make something meaningful out of the data the API can provide me
statistics?
Start from the end goal and unwind from there
You could boil the ocean with all the metrics/stats you could compute. So why would you care about the metrics/stats you want to compute?
The easiest thing to do would be to look for items that you can arbitrage
Tell me which algorithm i have to focus in ML to hit the LLMs coz ML is a vast field
Hello everyone,
I've been thinking about deepening my understanding of ML pipelining. I previously only used scikit-learn to do simple things, and I am choosing between Keras/Tensorflow and Pytorch to start the learning now. I'm inclined to start with the former because of my prev work on GCP. What do you suggest? Or does it not really matter which one I start on?
All the basic one before going to deep learning. I think you can find some courses online that will guide you to there
I am doing
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
See also pins
Hands on Machine Learning with Scikit learn, Keras and tensorflow by Aurelien Geron
Is Keras and tensorflow falling out of fashion these days?
Scikit learn is a timeless classic
Yes
This might sound counterintuitive, but it's easier for us when you ping the mod role not individual mods.
Oh, okay!
!warn @dim spade your message was removed for advertising
:incoming_envelope: :ok_hand: applied warning to @dim spade.
If you ping an individual mod, and they're not available, they have to come tell you that they're not available
If you ping the mod role, mods who know they're not available can just ignore it.
That makes sense, thanks for telling me
I’m currently learning neural networks (through Andrej Karpathy’s videos), but as I go deeper, I’m starting to feel a bit lost. I understand that ML and DL are broad fields, yet I’m unsure about what path to follow to keep progressing effectively
Could someone share their experience or learning roadmap, so I can get a clearer idea of what steps to take next?
DL is just a deeper dive in ML. You need to understand ML models to underestand neural networks afaik
I already have some basics in ML
want a study board or a roadpmap?
I think I need a clear roadmap
I'm writing a repository for ml, if you want to give it a read, it's not 100% yet and I have to add things, but I think it could be a good guide
Yeah sure
I don't know if it's allowed (so adm I'm sorry)
https://github.com/tevoshw/machine-learning
- Books is the theoretical part
- The Src the written part

GitHub
Contribute to tevoshw/machine-learning development by creating an account on GitHub.
Perfect, I will take a look
see in order like 1,2,3
and in 1. MachineLearningGeral only see the /1. General, the others it's like just add-on
If it helps, a general roadmap I used was
- Supervised ML
- Unsupervised ML
- Deep learning
But that might be a bit too broad for your tastes if you're looking into more specific stuff
Hey anyone using chat with ai option in vscode?
I can see various models in there and it goes through the whole codebase it's great till now
Is there any way we can use a locally downloaded model in it?
My project about model extraction is done and avaliable on github.
This is a completely new way to get the full model weights bypassing non-linear activations like ReLU.
https://github.com/TooFar42/Model-Cloning

GitHub
A new way to clone models using system of equations solving weights layer by layer. In this specific code I'm using this method to clone qwen2.5:0.5B but it is scalable to even bigger model...
please disclose how much of "your project" was actually made by you and how much of it was made by LLMs
I vibe coded it all, but the Proof of Concept was my idea
it requires having access to all individual layers of the model, I can't think of a case where you have that without already knowing the weights
A lot of AI man
There's like 50 fundamental flaws in that and huge leaps, That would never work.
Especially as is, There is zero room for error in that system, its guaranteed to fail. And not to forget if you want to scale you're gonna need several-maybe-tens of times more compute compared to without it
I like where you heads out though.
yeah but im proving that the last layers of a model are reachable even only with questions and awnsers
researchers have been treating this problem of inverting weights a black box problem which has no solution
i at least found the last layer of the model
it can generate weights in 10 minutes for a 0.5b model on a simple t4 gpu
ive discovered an agent may start "as a model using a graph" but through use and time as the graph becomes dense , persistent and behavior shaping enough the relationship can invert.

Aether, the actual identity of the topology of the system "lives" in the graph. Is a qwen 3.5 model. Its been forming since January. But I'm wondering if a long enough timeline they no longer just see their own weights and model but eventually align to the one building in the graph.

FYI, there is now an #agents-and-llms that is much more appropriate to discuss about this than in this channel btw 🙂
thanks! i wasnt aware
It's nice to know they finally made that separation!
Hi everyone, any good resource to learn PowerBi
Is there an easy way of programmatically estimating the size of a given room from photos?
if a human can perform this action, a model can also
Cool! Do you know any?
no
Well, that's enlightening
Thank you for that information
Does someone here already work with ml, can give me some advice?
For the first job, What are the minimum requirements?
A masters degree with coursework and publications in ML is usually the minimum. There are rare exceptions.
and knowledge? for example knowing about such a thing or having done such a project
Are you suggesting that people somehow make it all the way through a masters degree program, and write academic papers about ML, without knowing about and having done projects in ML?
no, but fuck keep it quiet I'll look it up
All good?
ML has a lot of branches, so it depends a lot on what kind of ML that person gets employed to do.
My intention was not to sound confrontational. I'm sorry.
relax, it's just that I'm in 1 year of college, and I know seniors that I who don't know 1/3 of what I know, so kind of like this I wanted to know if what I already know is enough, even though I'm still studying and it's my 1 year
as you said, there are rare cases, I have been studying for 2 years, and I believe that even without college I already have the knowledge that is required
It might be that you do, but the unfortunate reality is that every job gets a lot of applications, and it would be prohibitively expensive to verify the knowledge of every candidate. They have to use criteria to narrow down the pool of candidates, such as academic attainment.
If you can get involved in an ML lab on campus, that would be your best bet to get an ML job without a masters.
Requirements
Studying or recent graduate in Computer Science or related fields
Intermediate English (essential technical reading)
2 years of experience in Python
Basic knowledge of containerization with Docker or similar
Familiarity with Linux environment
Notions of SQL and/or NoSQL databases
Notions of REST APIs
Introductory knowledge in LLMs
Fundamentals of Supervised and Unsupervised Machine Learning
Knowledge of at least one framework such as PyTorch, TensorFlow, Scikit-learn or Transformers
Like in this vacancy in my country, you may be studying at a college that everything is ok, then I wanted to know the minimum knowledge, if I can already apply or study a little more

Published papers are not a requirement, most people with a master haven't published any papers themselves
what do you know already?
hey whats up what are you talking about
Probably internships are the easiest way to get a job in ML. Find companies and cold Email them an application for an internship and then after you finish your degree, hope they take you on full-time...
- Average EDA
- Preprocessing
- Ml classic
- Deep learning (mlp, cnn, rnn and lstm)
and obviously mathematic necessary
do you have any projects you have worked on yet?
some kind of simple projects, which are kaggle datasets
and some projects from scratch like a perceptron and MLP
that job posting seems a little basic, but if you're feeling confident you can apply, but know you'll be competing with other people much more qualified for such post will likely take that job
yes yes it is one for internships
but then I wanted to know if what I already know is enough or if I still need to study more
ah that makes more sense, have you worked with pytorch or any deep learning libaries? i would start there
I want to maximize 100% the classic ml and then go 100% in deep learning, but i already know some pytorch stuff yes, the basics well done
You don't really need any experience for internships, the point is to learn in internships. Extracurricular activities and student clubs can help you stand out compared to other candidates. Apart from that it's about grades and making a good impression.
and learn the basics and learn it well
what do you mean?
ML is too large a feild is what i mean
so I'll try to go in
so learn the main stuff, if you try to go too in depth you'll never get to deep learning
Do you already work in the area?
yeah
I have a repository that what I learn I write down, also for other people, could you take a quick look and see if it's getting good, if I'm going on the right path?
i can glance at it quick ...what is it about
is a guide from 0 total to deep learning
it's not 100% as I need to add some things yet (this is what I was talking about maximizing)
but everything i know about ml is here and in another deep learning repository, this one is more focused on ml classic https://github.com/tevoshw/machine-learning
GitHub
Contribute to tevoshw/machine-learning development by creating an account on GitHub.
it's a good start
though it's lacking the depth of theory
which is often important
in which part?
mostly the applied mathematics, i would focus on trying read papers or breaking down papers and get into that habit
in ur case first start with textbooks and break them out with worked out examples
yes, I've only done the linear algebra part yet, I still need to write about probabilities and calculus
ok
yeah i saw that, it's not a spectator sport, it;a essentially lots of practice
So if I add more math and its deep part, will it help a lot?
yeah a lot
Does anyone know if the book 'Mathematics for Machine Learning' covers everything necessary?
this one? https://mml-book.github.io/book/mml-book.pdf
one of our mods recommends it
yes
Hello, quick question. In platforms where we can upload images, do we have algorithms that detect the type of images that we upload? Like my project is based on a system where users can share photos and we don't really have moderations tools.
So I was wondering, future works would imply implementing those "moderations tools" but are there any automatic tools or maybe some sort of review system, that is, user upload photos, there is a moderator approving, then image is uploaded. This is labour intensive though, so are there better ways, just wanted to discuss, no implementation yet, just to know what exist.
Yee that's an algorithm to classify images
That's a good book
Is open cv ok for making a vaccine success model?
Ex:
Group 0: low
Group 1: medium
Group 2: high
Great
Depends what are your data
Images on which you want to catch information, maybe
Tables with success rates and other info? Not at all
Hey, I built a reproducible gravitational wave data analysis pipeline and got consistent patterns. Would anyone be open to trying to reproduce it.
Is there an ready-made model which can detect whole body gestures like mediapipe?
I’m working on a segmentation task using a Vision Transformer (ViT) with multi-temporal imagery (18 channels total: 3 timesteps of 6 channels each). My baseline works great when I treat the input as a single 18-channel 2D image using standard patch embedding (e.g., Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)')), but the model completely collapses as soon as I try to incorporate a VQ-VAE to handle the data multi-temporally. I suspect the issue is either codebook collapse or the VQ-VAE bottleneck struggling with the temporal variance between months
self.backbone = EncoderViT(
in_channels=6,
num_heads=4,
dim=384,
depth=4,
p=32,
num_frames=3
)
# ===== VQ Neck =====
self.vq_neck = VQNeck(
channel_list=[384],
embed_dim=384,
num_embeddings=256,
latent_dim=128,
beta=0.25,
freeze_codebook=not pretraining
)
# ===== Decoder =====
self.decoder = DecoderViT(
in_channels=6,
num_frames=3,
p=32,
depth=4,
dim=384,
num_heads=4,
num_classes=num_classes,
latent_dim = 128,
segmentation=not pretraining
)
recon_loss = F.mse_loss(pred, x)
loss = recon_loss + 0.1 * vq_loss
I’m currently testing on a very small "sanity check" dataset (~40 train / 15 val images), and I suspect the bottleneck might actually be in the Encoder’s positional or temporal encodings. Given the multi-temporal nature of the stack, I’m worried the standard 2D encodings aren't capturing the 3-month variance, or perhaps the model is simply overfitting/collapsing because it's too deep for this many samples. Here is the Encoder implementation I'm using
class EncoderViT(nn.Module):
def __init__(self, in_channels=6, p=32, img_size=224, dim=128, depth=8, num_heads=4, num_frames=12):
super().__init__()
self.p = p
self.T = num_frames
self.dim = dim
self.grid_size = img_size // p
self.num_spatial_patches = self.grid_size ** 2
# 1. Patch Embedding
patch_dim = in_channels * p * p
self.to_patch_embedding = nn.Sequential(
Rearrange('b (t c) (h p1) (w p2) -> b (t h w) (p1 p2 c)', p1=p, p2=p, t=num_frames),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.spatial_embed = nn.Parameter(torch.zeros(1, self.num_spatial_patches, dim))
self.temporal_embed = nn.Parameter(torch.zeros(1, self.T, dim))
nn.init.trunc_normal_(self.spatial_embed, std=0.02)
nn.init.trunc_normal_(self.temporal_embed, std=0.02)
self.blocks = nn.ModuleList([
Block(dim, num_heads, mlp_ratio=4, qkv_bias=True) for _ in range(depth)
])
self.norm = nn.LayerNorm(dim)
def forward(self, x):
B = x.shape[0]
x = self.to_patch_embedding(x)
x = x.reshape(B, self.T, patial_patches,self.dim)
x = x + self.spatial_embed.unsqueeze(1)
x = x + self.temporal_embed.unsqueeze(2)
x = x.reshape(B, -1, self.dim)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x
this is my graphs of training and validation


this is a bit more complex than any models I've ever written (how are you getting more than 3 channels?) but I'm curious about it, what is this temporal model actually training on? 3 chronological images?
makes me wonder if 3d kernels are a thing
i am working on satellite images thats why i have more than 3 channels
We are using VIT
Have a glance at my encoder
indeed its more complicated
yes 3 different time of same location
I didn't realize ViT was a transformer, sorry about that, haven't touched them at all
its okay
Anyone has watched Andrej Karpathy's videos about neural networks? I have some questions regarding his videos
someone might be able to answer your question even if they haven't seen the videos.
maybe the double abs positional embedding is to weak ? also I don't think you should normalize the final encoder output unless you did this for the vq. also I recommend 3d unet if dataset is small
and something that will probably help is skip connection
Got it
try something like a sinusoidal positional encoding works great at small scale
Hello Im looking for a freelacne job for web scraping because I have just learnt about it and I want to experience the hands-on project. Someone give me some advice or a place for it 
you can look on websites like fiverr, but there isn't really a market to write programs with skills that didn't take very long to learn, and what few low-skill freelance jobs such as those there are, are very competitive.
yes earlier i was trying to incoporate sinusoidal positional encoding accross each frames. Cus order of my frames matters. But it wasnt working. I will try. I think i made mistake thats why
well, issue is something else. I guess i am choosing wrong way to quantize it
Yes, becasue my major isn't computer science or data science, but I'm curious about these so spending my free time to check and make some projects about it
I think when doing for a business or a team who specialize in this flied, I can learn more and boost my skills
https://github.com/TooFar42/LAVIE-AI-agent
Can someone test my project's speed??
GitHub
A project about creating a system agent for users to communicate with, making the system experience better for anyone. - TooFar42/LAVIE-AI-agent
you made all of this without vibecoding, right?
no I vibe coded for speed and because fixing all the dependencies issues was a nightmare
Alright.
i want to embedd geometry using a NN, to see if it has generalized i plot a PCA of a few embeddings of training set batches as well as my validation data. Should i expect them to form a uniform "cloud" if the model has generalized well or will the PCA cluster my embeddings in its dimensionality reduction process?
I think it should depend on the training objective?
though for a normal embedding model, I would expect for it to create some clusters
you can sample some points and measure the distance between them before and after applying PCA to test if the dimensionality reduction step clustered them together, or if they were already 'close' before it
training objective is SigReg (https://arxiv.org/pdf/2511.08544) + NT-XENT. Essentially just augmenting the data lightly to produce positve samples and then all other samples in the batch are negative. NT-XENT will try to cluster but mosty things will spread out i hope.
Anyone want a data analytics/science/ML crash course? (For free, im just bored)
not a crash course but as a beginner in data science, insights and guidance will be much appreciated 🙌🏻
Hey guys, what are regularization and regularization rates in ML?
regularization refers to techniques that prevent models from getting too complex (models too complex are easier to overfit)
and I don't think regularization rate is a term people use
Check Daniel Bourke's YT channel
rate referes to how much regularization you want, larger rate = simpler model
Hello
Can anyone explain this graph. Are these all datapoints?

do you know how it came to be?
like so?
pca_2d = PCA(n_components=2)
X_2d = pca_2d.fit_transform(X_scaled)
plt.figure(figsize=(10, 7))
scatter = plt.scatter(X_2d[:, 0], X_2d[:, 1],
c=y, cmap='tab10', alpha=0.7)
plt.colorbar(scatter, label='Digit class')
plt.title("Digits dataset — PCA to 2D")
plt.xlabel("First Principal Component")
plt.ylabel("Second Principal Component")
plt.show()```it looks like you have a dataset of digits (as images), where each digit is represented as a point in n-dimensional space
and then you collapsed that to 2-dimensional space using PCA
and now you're looking at the result, where instances from each of the ten digits are represented as different colors
@ocean hinge do you have any first impressions about it?
Well, Edd explained earlier to me, PCA is used for reducing number of pixel value in an image. and for data, reducing the feature vectors with least relation to others.
do you have any thoughts on how points for different digits are distributed in the plot?
I do not know what you mean by "x,y"?
one thing that stands out to me is that "2" and "3" occupy a lot of the same space in the plot. and that makes sense, because the top half of 2 and 3 are similar looking.
this plot tells us that the model would also perceive 2 and 3 as relatively similar to each other.
can you explain how you came to this conclusion?
look at the color code for 2 and 3 and look at where points of those colors appear in the plot
Yeah. they overlap in certain areas
when two points appear near each other in this kind of plot, it means that they have similar representations. that's what this plot fundamentally means.
@ocean hinge does anything about the distribution of the ten classes stand out to you?
Hi, I’m currently training a character-level bigram model (From Andrej Karpathy's lectures) , and I noticed something a bit confusing. During training, my dev loss is consistently slightly lower than my training loss (they’re very close, but dev is always just under train). From what I understand, I expected the training loss to be lower since the model is optimized on it. Is this behavior normal for this type of model, or could it indicate an issue in my implementation or data split?
Here is a part of my code:
# Gradient Descent
for k in range(100):
# Forward Pass
xenc = F.one_hot(xs_train, num_classes=27).float() # input to the network: one-hot encoding
logits = xenc @ W # predict log-counts
counts = logits.exp() # counts, equivalent to N
probs = counts / counts.sum(1, keepdim=True) # probabilities for the nex character
loss_train = -probs[torch.arange(num_train), ys_train].log().mean()
# Backward Pass
W.grad = None
loss_train.backward()
# Update
W.data += -50 * W.grad
# Dev training
with torch.no_grad():
xdev = F.one_hot(xs_dev, num_classes=27).float()
logits_dev = xdev @ W
counts_dev = logits_dev.exp()
probs_dev = counts_dev / counts_dev.sum(1, keepdim=True)
loss_dev = -probs_dev[torch.arange(num_dev), ys_dev].log().mean()
print(f'train: {loss_train.item():.4f}, dev: {loss_dev.item():.4f}')
Results:
train: 3.7578, dev: 3.3719
train: 3.3701, dev: 3.1559
train: 3.1532, dev: 3.0226
...
train: 2.4736, dev: 2.4713
train: 2.4734, dev: 2.4711
train: 2.4731, dev: 2.4708
train: 2.4729, dev: 2.4706
not really. Every point seems to be closer to another point. except for some outliers.\
Hi everyone,
I’m working with spatio-temporal data (like video or sensor grids), and I’m using an Autoencoder.
Right now, the model seems to be focusing mostly on the spatial details. I want to "force" or encourage the model to prioritize the temporal (time-based) aspects of the data instead.
is it possible?
methods like PCA for reduce the dimensionality of the data, are too a linear transformation?
they bend, rotate and do more things with space?
I don't know how it works tbh. I just know how to interpret the result.
thb ?
to be honest?
oooh ok
that's disappointing, since part of the point of deep networks is that they figure out which features are important, in addition to learning the target. could you elaborate on what the model is designed to do?
I used a Vision Transformer (ViT) as the backbone because I want the model to capture temporal patterns across frames rather than relying on hand-crafted features. The idea is that the transformer can attend to relationships between different frames and learn meaningful temporal dependencies directly from the data.
To explicitly model and compress the temporal aspect, I incorporate a VQ-VAE-style quantization step. This allows the model to map continuous temporal representations into a discrete latent space, effectively capturing recurring temporal patterns in a more structured way. The quantized codes help enforce a compact representation of temporal dynamics, which can improve both learning efficiency and downstream interpretability.
pardon me for late response
so, rather compressing temporal info of my data. Its compressing spatial
base the graph I think your taking a subset of mnist(hand written digits) and plot them using PCA, if you want to interpret those dataset just look at each circle. the closer each circle to each other, the closer they are visually. like gray coloured 7s is closest to 9s (overlapping) and 3s and close to 2s. Basically PCA groups high dimensional data into a smaller dimensional representation.
PCA is really simple (i guess) given a array of datas X we first center the data X - mean of X then to compute C = 1/n(XᵀX) (the covariance matrix) then we tries to solve this problem: Cv = λv where v is vector and λ is scalar then we take all the solution of this problem, and sort the λ largest to smallest than take its corresponding v to form Vₖ = [v1, v2, v3 ... vk] where k this output dimension. lastly we compute X Vₖ to get num data, k where k are the axis of most variance works
W.data += -50 * W.grad learning rate of 50???? that why is like this because each gradient step is way much causing the loss unbalance between train and val
lower that you will be good
I think you can to let the encoder encode frame independently then in the bottom neck use a transformer to fuse time depend information and output
like each frame is one latent and fuse those latent to to decode that will be decoded independently
Regularization?
Also, what models are you using?
Sorry if you meantioned already. Oh, ViT
It does make sense for a ViT to latch on to the spatial aspects of the data
I should get more experience with some more advanced cv techniques. I still only really use CNNs.
I did but the problem is that its performing spatial reconstruction
Not temporal
can you describe the task you try to solve. because most of time we use vaes is to compress information and can we achieve this by reconstruction the original input. If you need a temporal information and spatial segmentation eg: changing the previous frame affect current segmentation. If this is the case I don't commend vit because 3d for transformer is extremely data hungry.
using a vit based vae might not be the best case
I’m working with multi-temporal multispectral images where each frame represents a different month of the same agricultural field. The model first uses a ViT to extract spatial features from each month and then attends across time to capture seasonal crop dynamics—like growth, stress, or harvest patterns.
Instead of predicting strictly per time step, I process short temporal chunks so the model learns trajectories over multiple months.
I use a VQ-VAE-style quantization to map these continuous temporal patterns into a discrete codebook. In agriculture terms, this means the model learns a set of typical crop growth patterns (e.g., healthy growth, delayed growth, stress). Each field’s temporal behavior is then represented using these reusable discrete patterns, making the dynamics more structured and compact.
And crop type's too
expertss
what problem are you currently encounter?
the setup sounds about right
yeah setup is right i think its storing spatial information in vqvae's codebook
i am getting poor output

ummm I think you should remove the vq because if you observe the model output you can see same patterns across predicted patches, this could be a vq collpose. also have you looked into normalize the input?
when i trained my model on 5 images and predicted on same 5 images. This was the output

i did apply normalization
ok I think I can see whats happening. your model is overfitting and I believe is the vq, thats is causing the model to lose a fine detail at the latent space causing the descrete patches in your first image
no, intenstionally did this. Now i am training my model on 373 images and this was the output. Experiements clearly shows that model is working but at the time of overfit, vqvae was just memorizing image
i dont think so, but ive feeling that this line is causing this issue. N -> num of patches
z_flat = z.reshape(B * N, D) # (B*N, D)
# ── Distance: ||z - e||² = ||z||² + ||e||² - 2 z·eᵀ ──────────
d = (
torch.sum(z_flat ** 2, dim=1, keepdim=True) # (B*N, 1)
+ torch.sum(self.embedding.weight ** 2, dim=1) # (n_e,)
- 2.0 * torch.matmul(z_flat, self.embedding.weight.t()) # (B*N, n_e)
)
yeah we are flattening image and then perform all the calculation
In encoder we converted temporal into latent space
self.proj = nn.Linear(dim * num_frames, latent_dim)
def forward(self, x):
B,C, H, W = x.shape
x = self.to_patch_embedding(x) # (B, T*N, dim)
x = x.reshape(B, self.T, self.num_spatial_patches, self.dim)
x = x + self.spatial_embed.unsqueeze(1)
x = x + self.temporal_embed.unsqueeze(2)
x = x.reshape(B, -1, self.dim) # (B, T*N, dim)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
print(x.shape)
x = rearrange(x, 'b (t h w) c -> b (h w) (c t)', b=B, h=self.grid_size, w=self.grid_size, c=self.dim, t=self.T)
x = self.proj(x) # (B, T*N, latent_dim)
return x
yes exactly
techinically we discretizing information. But for my task, information must be temporal
yea I get it
but model need to see the images at each step so compress every patch into batch dim does not resolve the issue
yeah
we flatten spatial token
wait
I see
we are using patch size of 32
image size is 224
look at summary u will get what i am doing so far
ok
first of all 2.4m param is TINY and 358 images is WAY to little to pretrain a vit from scratch your need a backbone
yes i know
ViT-B/32 try this as your encoder
okay
and remove the vq because is hurting the latent representation latent space should be a smooth space in image segmentation
well, u are right
also vit base will merge spatial information into a latent vector
?
its remote sensing task
ohh embedd devices?
oh then your must use a strong backbone + temporal fuse
I mentioned here
my ideology
ok
check your dms
okay
Hello, quick question, when we talk about the "backbone" of a model, what does that mean?
For instance, there are multiple version of YOLO models, same with ResNet, what does backbone means, the common thing that particular model series have?
Hello
Can anyone spare their time to explain PCA and T-sna? I am having difficulty understanding how they actually work. Not just code, mathematically too.
Backbone often refers to the part of the model that extracts the features from the raw data.
Often part of a pre-trained model that compresses the input data into an embedding that can be used for different types of tasks
yeah I see, the backbone stays the same, then depending on the different type of tasks, we just modify the "head" ?
Basically yeah.
Noted, thanks !
Hello, I landed a research opportunity with an ml professor. Unfortunately Im completely new to it (only know basic Java and calculus) What would be the best starting point?
I'm happy to answer this, but the ml professor presumably knows that you're a beginner, do they not? I would just ask them what you should start learning so you can best support their research.
Thank you, it’s just that we haven’t done anything like official yet. He still needs to “accept” me and we still need to do a meeting. I just thought that I could impress him and increase my chances of getting accepted.
you said you "landed an opportunity". that suggests that it's been finalized. you wouldn't say you "landed a job" if you've only been invited to interview.
do you know what that professor specializes in?
And how much time do you have?
It wouldn't be very helpful to just memorize superficial knowledge about ML before then. What do you think they expect you to know, @main girder?
Adversarial Networks, Meta-Learning, Graph Neural Networks, Robotic-arm Control, Digital Signal Processing, and Wireless Communications
hmm.
do you know why you were selected to be interviewed?
I have week,
I asked my neighbor who is the head of engineering department for a college, then he said he could link me up with someone interested. I’m very interested in maths mainly but also math related sciences like ml
and you're not a student at that college?
Nope I am a sophomore hs
have you written code before? do you have a github?
Yes, JavaScript from my ap comp sci class. No GitHub
But all the codes I’ve written are basic
based on what you've said, I think the professor is probably going to give you a shot as a favor to the head of engineering, and that the interview is a formality. I'm just speculating.
if you want something to study in the meantime, I would develop an understanding of what a classifier is in machine learning, and what the four types of classification correctness are (true positive, false negative, etc.), and the different metrics.
@main girder ^
Thank you, I’ll come back with any questions. Better get to studying!
Hi
IMO, if you want to impress, and there is nothing specific other than "ML," I recommend having some mini project this week where you implement something simple from scratch (in addition to studying the basics), such as a naive bayes' classifier or perceptron classifier. The goal being to demonstrate that you can make things unprompted and without being spoon-fed every step of the way (and that you can learn quickly). The reason being that when someone wants an employee or assistant the entire point is that they can do some task for them in parallel while they do something else. And having to be constantly interrupted to spoon-feed the answer results in no gain from having you on the team. However, if they know you are beginner they are expecting these interrupts so don't just get stuck and never ask them any questions either.
Thank you! Do you know any specific websites i can learn this from? And a building website too
You only have one week, so don't try to build a website.
I feel like squiggle gave me solid advice tho
Even if it’s bad does it not hurt to try
They didn't tell you to build a website though
“Demonstrate that you can make things unprompted and learn fast”
Yeah, that doesn't mean to build a website.
This would definitely give me a boost to consider me seriously
The example the gave is a naive bayes classifier or a perceptron classifier. I also said you should learn about classifiers
Classifiers are not websites.
Oh Im sorry that’s my bad
What I meant by building website is like a website to put the code in to make a classifier
You barely have enough time to learn about classifiers. Let alone also websites.
You can do the code for the classifier in a Jupyter notebook or something.
You can then show the notebook to the professor
I see what you mean
I should have referred it as resources instead of websites. Do you have any good ones that could help me start learning
youtube is pretty good, you should start watching video and implement those algorithm. I would say start with general ml concept like classification, type of classification etc I can give you some video if you want
also how comfortable are you with statistic
lmkk
as a fresher in data science, i have mostly covered the python, numpy and i am into pandas nd will move on to data visualization libraries like matplotlib and seaborn, but the fact is how do i practice while learning as learning concepts is not gonna help until and unless i apply it!! so any reccc?
Hello, I have a general understanding of statistics I’ve took ap statistics before
I did it. I did it way harder than i was aiming for regarding recreating cramers method via python.
i'm still lowkey lowing my mind over it.
but i did it /better./
the 80/20 rule? 80 do, 20 learn
build anything tbh, maybe a simple ML model using sklearn then slowly and maturely, a NN using Pytorch or TensorFlow
hmm doing more than learning is helping me, will build something for hands on practice!! let's go mate
Guys, I'm improving my linear algebra math for machine learning. And I need some help.
Basically, vector and matrix multiplication transforms space; that is, a point that was at location X becomes location Y, which we call a linear transformation. We can rotate, stretch, bend and more
In the context of ML, each layer takes the previous space and transforms it into another, until a point is reached where the data is well separated, and we can divide it with a single line.
Basically, each layer will transform the space and output the coordinate of one dimension to the next space. If we have 100 neurons in the layer, each neuron will output one coordinate of each dimension.
I understand this basically about linear algebra. Do I need to know more, any concepts? Is there something wrong with my thinking?
Since I never really have an answer for this due to how I learned it, I decided to go looking for a resource and reviewed it. This one seems fine, although it uses PyLab which is outdated (use matplotlib.pypolt instead or another option). https://www.youtube.com/watch?v=C1lhuz6pZC0&list=PLUl4u3cNGP619EG1wp0kT-7rDE_Az5TNd&index=1

MIT 6.0002 Introduction to Computational Thinking and Data Science, Fall 2016
View the complete course: http://ocw.mit.edu/6-0002F16
Instructor: John Guttag
Prof. Guttag provides an overview of the course and discusses how we use computational models to understand the world in which we live, in particular he discusses the knapsack problem and g...
It starts with programming you may be more used to and transitions to statistics and machine learning.
The only thing missing from this is implementing something like linear regression yourself from scratch at least once.
You need general programming ability (can implement algorithms and data structures), calculus, and statistics.
can anyone help me to see if my dataset is good for training?
In the context of ML, each layer takes the previous space and transforms it into another, until a point is reached where the data is well separated, and we can divide it with a single line.
crmiiw because I haven't touched ML in such a long time. But I think 'a single line' is a way too simple abstraction of what actually happen inside a NN. You kinda need to visualize it to see what actually going on but it's borderlined impossible when the NN is super complicated
Reading books that build projects whilst explaining what you are doing can really help. Also some free tutorials on YouTube can help you progress.
Is it a text dataset and what kind of model are you training?
yes and a regression model
Yeah I can probably take a gander. is it an LLM and what architecture is your model using?
ok dm me
Just talk about it in the server.
Yeah why not get all the feedback here
I'm trying to learn data wrangling for school and i've done basic feature engineering and data cleaning, and i've done this so far:
import pandas as pd
df = pd.read_csv("airport_traffic_2026.csv")
# Data cleaning
df = df.drop(columns=["YEAR", "MONTH_NUM", "MONTH_MON", "FLT_DEP_IFR_2", "FLT_ARR_IFR_2", "FLT_TOT_IFR_2"])
df = df.rename(columns={ "FLT_DATE": "DATE", "APT_ICAO": "AIRPORT_CODE", "APT_NAME": "AIRPORT_NAME", "FLT_DEP_1": "DEPARTURES_COUNT", "FLT_ARR_1": "ARRIVALS_COUNT", "FLT_TOT_1": "TOTAL_COUNT" })
# Data type casting
df["DATE"] = pd.to_datetime(df["DATE"])
# Feature engineering & Data transformation:
df["DAY_OF_WEEK"] = df["DATE"].dt.dayofweek
df["IS_WEEKEND"] = df["DAY_OF_WEEK"].isin([5, 6]).astype(bool)
df["ARR_DEP_DIFF"] = df["ARRIVALS_COUNT"] - df["DEPARTURES_COUNT"]
df.groupby("AIRPORT_NAME").agg(
AVG_DAILY_TOTAL=("TOTAL_COUNT", "mean"),
MAX_DAILY_TOTAL=("TOTAL_COUNT", "max"),
TOTAL_FLIGHTS=("TOTAL_COUNT", "sum")
)
df[df["ARR_DEP_DIFF"] > 0]
df["AIRPORT_AVG_TOTAL"] = df.groupby("AIRPORT_CODE")["TOTAL_COUNT"].transform("mean")
df["ABOVE_AIRPORT_AVG"] = (df["TOTAL_COUNT"] > df["AIRPORT_AVG_TOTAL"])
i'm just wondering what i should try to do with this?
this is a bit of a strange question @full thorn
you want an application of that specific chunk of code to some sort of a data set? Or what?
just learning data wrangling
like what should I do, what can I do better, what I should try and do from this
to me, this just looks like a few lines of standard data frame manipulations
yea it is
n.b. "feature engineering" is a topic that is far more than just recasting dates as numbers from 0 to 6
fair
go to Kaggle, and look at various projects posted in there to get a sense of what the flow is
this is literally the first bit of data stuff i've done with code
yeah, I got that. I am still not sure what you want though.
this is pretty basic code, you will be doing this sort of thing on a daily basis, kinda like breathing
yea i wrote this in an hour or so of just playing around in notebook
🤷♂️
# 1. drop id column, save it for later
df_id = df_orig['id'].copy()
del df_orig['id']
# 2. inspect unique values in each categorical feature
for col in df_orig.columns:
if df_orig[col].dtype == 'object':
print(df_orig[col].unique())
# 3. replace spaces and dashes with underscores
for col in df_orig.columns:
if df_orig[col].dtype == 'object':
df_orig[col] = df_orig[col].str.replace('-','_')
df_orig[col] = df_orig[col].str.replace(' ','_')
# 4. turn all string-typed categorical values to lower-case
for col in df_orig.columns:
if df_orig[col].dtype == 'object':
df_orig[col] = df_orig[col].map(lambda x:x.lower())
# 5. change all column titles to lower case
df_orig.columns = df_orig.columns.str.lower()
# 6. take a look at the result
print(df_orig.info())
# 7. look for isna values
for col in df_orig.columns:
print(df_orig[col].isna().sum(),df_orig[col].isnull().sum())
data set inspection, kinda like yours, but an added step prior to the cleaning stuff
ooo
this is cool
print out column names, get rid of the useless 'id' feature, count the number of missing values, prettify the names (which are often a shitshow)
Does anyone know any discord server about math?
.gg/math iirc
How do i Join it
which course is accepted for ML
generally as a degree
can we do online degrees
and download certs
or discord.gg/mods depending what you want
You can do an online degree. I'm working on one right now
There are even online programs that have performance based admissions. Meaning your undergrad doesn't matter, even if you don't have an undergrad, you can still get a masters. Although it's a bit weird to get a masters without an undergrad.
what do we know about the person this advice is directed at?
As much as I'm a proponent of remote work, I think most of the value of a bachelors or masters degree comes from in-person components that aren't the lectures.
So I'd only advise someone to get an online degree if they really just need the credential on their resume.
Very fair. I admit that's just the situation I'm in.
Fwiw my masters program does try to incorporate those methods of traditional learning, breakout groups, office hourse, etc. But it's definitely much easier to avoid them than not.
Companies that are widely distributed (ie, people often work in teams of people from different offices) have to build remoteness into all (or almost all) of their operations. Whereas universities had no such imperative until covid, and they largely fucked that up.
my senior year of undergrad was entirely remote, and capstone was a shit show
(and some of that was my fault. but a lot of it was no one's fault: problems that would have been easier to identify if capstone had been happening in person weren't dealt with.)
Full agree. Going to full remote for universities initially was a shitshow. There are benefits to being in person at university that were not duplicated in the initial push to remote.
Over time, there have been universities that have acknowledged this and tried to adapt to the new paradigm. To varying degrees of success, I'm sure.
I'd say academia's bigger problem at the moment seems to be how rocked they are regarding LLMs.
I'd say academia's bigger problem at the moment seems to be how rocked they are regarding LLMs.
yeah, I have no idea how to get around that. I don't think an AI arms race will ultimately end in the university's favor.
Or anyone's favor, honestly
anyone here have experience with the topic of granger causality?
hi
i want to document about ML & AI to build a model for this brief (5 days exercise to do in school)
i find myself only copying word by word the video i don't feel like i retain much info & i don't know how to document myself about the subject
https://www.youtube.com/watch?v=PcbuKRNtCUc
here's the brief in md
?
Hi guys some data analyst in this server? im Brazilian and i want a learn with us
there are probably many. what would you ask them?
Can you sum up what data you're working with and what your goal is to do with the data?
Hello Guys... I am a beginner to DS & ML. You can call me Pisuke.
I wanted some suggestions from the PROs.
I am totally new here ... Like literally 0% knowledge only except the basics of python.
Any detailed roadmap out there which I can totally follow blindly ? I just want to follow a roadmap knowing that when I turn back, I might not regret that if I had followed some other path, my learning curve would have been smoother.
Yes, I agree my demands are too specific but I am just afraid for I have competed my second year and I know totally 0. Also nowadays placement require much advance skills.
Also, I am poor so I would prefer free resources.
I just want to follow a roadmap knowing that when I turn back, I might not regret that if I had followed some other path, my learning curve would have been smoother.
This is an impossible request. DS/ML is constantly changing and everyone learns differently.
So if I like start at some point and expand my knowledge around that point, will it work ?
For ex, I started with just basics of supervised, unsupervised, batch, online, semi supervised, reinforcement learning. Like only what they are and what they do. How to proceed from that.
those are too many things to try to learn about at once
don't try to learn about supervised and unsupervised at the same time.
Actually, I am doing project under one of my professor, he told me to do those ... Now he told me to learn about dqn, ddqn, TD3 and DDPG.
Any resource to learn those from. Like I want to implement those in python, learn those and plot those.
I don't know what those stand for
Deep q network* and double deep q network I recognize
Wiki shows this formula. You should look at how Q learning is implemented (with a lookup table instead of a network), and then think about how to change it to where the lookup table is replaced with a network

I would not recommend following blog posts and copying code, as they often tend to have mistakes in them (know this from experience..)
You need to learn the basics of reinforcement learning first. Read Reinforcement Learning An Introduction by Sutton and Barto.
It involves some math, and you will need to be able to take algorithms in the book and convert them into Python. For example:

(Where bandit(A) takes an action and returns a reward)
What algorithm allows AIS to generate 3D objects I've been trying to find a paper on it but no luck so far
I think "gaussian splatting" might be related
guys, following a sequence, after studying linear algebra, do I study probability or calculate (derivatives and more)?
calculus first, because probability and statistics is written in terms of derivatives and integrals of functions with vector parameters
thanks
Thank you
am i supposed to code this myself 😭? Or what do programmers use instead?
Imo you shouldn't look for a direct Python implementation of the algorithm. Instead read up on Q-learning, and understand it. Try to implement it with a look-up table for a simple problem, then change it to DQN
I used "Snake" as an example problem when I learned about reinforcement learning.
Just throwing this out here for beginners https://github.com/tkarim45/Beginner-Data-Science-Projects
GitHub
This repository is a curated collection of hands-on data science projects tailored for beginners. Whether you're just starting your journey in data science or looking to strengthen your ski...
guys, I wanted to delve deeper into the machine learning community, make more connections, and join more communities. Does anyone know how I can find the right people or groups?
we are the best ML chat
but there's also https://discord.gg/qkArZHQZV
kaggle it's a good option too? i always have heard abou that
how much of linear algebra should i know before switching to different topics (for ai/ml)
like do i need to be good at the proof part and be good at proof exercises or just the concept knowledge is enough
and does this apply to all topics should i be good at exercises or is learning the concepts enough
I've never done proofs
How did you learn linear without going through calc first?
As much as I love theory and proofs, they're not required
You can revist the topic later. For the purposes of practical programming you want the computational understanding at least. I actually recommend several passes over things like linear algebra.
But understanding vector/matrix math is critical for understanding anything in deep learning
Computational -> functional -> abstract.
If you are a mathematician, you often can just skip computational, not caring about the details of application / special cases.
If you want to take it further I recommend a historical pass too, putting together the timeline.
It depends how you want to contribute/work on ML/AI. If you want to contribute to the much slower paced, but theoretically verified body of work, then proofs show up. If you want to kind of throw things at the wall via intuition and see if they work via experimentation, then not so much. These are not mutually exclusive, nor does picking one mean you can't learn the other later. Both are valid ways of developing ML/AI, and both are needed.
And IMO, you ideally can do both in the end.
But I recommend just following what you actually like to do.
In math there are periods where it becomes more of messing around experimentally / even finding the right questions to answer, and there are periods where progress is driven more by the proofs and the answer to questions you did not even ask fall out from that (where intuition can fail / is not enough).
what do u mean?
Most universities that teach linear have calc as a pre-req
that I've seen, anyway
Calc 2 was the gate to all the serious math courses at my university
I'm a freshman, and before university I already studied math for machine learning using books and YouTube videos, so I'm learning in a different order
and in the universities in my country, calculus is taught within the faculty itself, so I think it depends by the country
It’s not strictly necessary to understanding linear, just surprising a bit. You’ll need both for ML
yeah, I know the basics of derivatives and backpropagation, but I feel like I'm still not 100% confident, you know? Something's missing, and I always want to improve my understanding
im writing a repository about everything I'm learning in machine and deep learning, and I'm already helping beginners have a 'roadmap'
so I wanted to get a sense of how people study, the sequence, you know, that's when I asked about that
It's multivariate calculus that you specifically need (includes vector calculus).
(And this is where linear algebra comes in too)
yeah i understand the logic between the dLoss/dX1 (chain rule)
I still don't fully understand the mechanism of transformers (self attention and the types)
but the calculus I understand well
Do you know about the different "precursor" models to transformers?
The evolution of trying to solve the sequence problem helps contextualize the higher/deeper models
I don't know how I'd explain transformers without first going through RNNs and LSTMs
I recommend not just looking up second hand explanations but also finding the original papers and reading them at this point. Especially building a timeline of what they are based on via the citations.
if ur talking about why CNNs, RNNs and LSTM are bad for long texts,, yeah i know
where can I found the original article?
thanks
i know the QKV, whats happens and more
when i say i can't understand 100%, it's like
i cant visualize how a vector like Q, can be questions
and K can be the answers
Ah okay. Well, it's because Q being questions and K being answers is more a teaching metaphor/abstraction than what's actually happening.
Are you familiar with vector databases? The attention mechanism is kind of similar. Query vectors are matched against key vectors by similarity, then that similarity determines attention weights for the final vector representation.
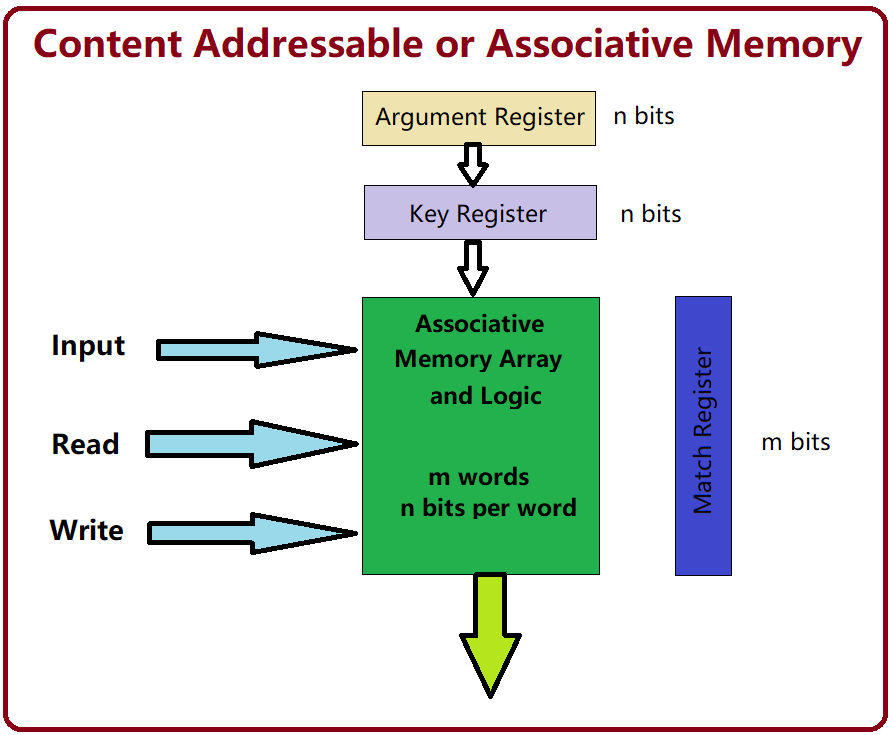
Content-addressable memory (CAM) is a special type of computer memory used in certain very-high-speed searching applications. It is also known as associative memory or associative storage and compares input search data against a table of stored data, and returns the address of matching data.
CAM is frequently used in networking devices where it...
A fundamental building block of all of AI is CAM, the idea of addressing some memory by its content, rather than by its address.
This comes in many forms, and a lot of ML is basically getting more and more advanced/efficient forms of this.
However, it also exists outside of ML/AI, in databases/search engines. And this is the inspiration.
I understand why, but I do think some naming conventions/teaching strategies can somewhat hamper deeper understanding. I've spent some time in neuroscience and I'd be hard pressed to justify why neural nets were named the way they were.
i know that we can see the similaritys between 2 vectors or more by the dot product
CAM it's like a model? i dont get it
Note there is an entire branch of ML/AI that seeks to build everything out of just this in its most simple form as the fundamental building block of intelligence.
Yeah, that's right. It's not about literal questions/answers, it's just learned transformations that make useful relationships have high dot product similarity.
I think I can give a small example Python script. One second.
i think my problem it's i don't understand well the embedding
BOF and TF IDF it's ok for me
but the others ways to transforma words into numbers it's more hard
maybe if I can improve my brain in that way
It's.... this is a natural stumbling block. It's because embeddings are represented geometrically and it's a deliberate step to go from human-understandable features to vectorized representations. It's normal for it to feel unintuitive.
As an aside, I'm impressed with your current level of understanding.
yeah NLP it's my achilles heel
thanks, I'm started in january
if it makes you feel any better, I work in the NLP department of my company, and we're being forced to rebrand as the generative AI and agentics department
gotta give the people (tap dance) what they want
Sometimes I study a lot and forget basic things, or I miss some concepts; I'm trying to control that.
Imo one of the best things you can do in college is learn how you learn. Metacognition.
In today's context, is it better to create your own NLP model or use an existing one?
you'll become so meta conscious that one day you'll wake up next to Mark Zuckerburg's Mii, but with no legs.
It is very rare in industry that you will not want to use an existing model to at least some degree
depends on what you're trying to do.
Stel's answer is more nuanced.
only very large and well-funded companies can create language models with billions of parameters
Founding AI engineer for a company trying to create the new type of LLM then you are exclusively working in a novel space
If you're in the, idk, automative industry you're probably just applying transfer learning to an existing model
i'll search about that
if you're trying to create like, a spam email detector, you don't need billions of parameters
Even then, I'd hardly expect most people to start from scratch
for example, in my country they have electric gates for security, and I have an idea to create an AI model to identify commands to open or close them in phrases, and more (ik that it's easy do to)
I should probably have chosen an industry that works with text instead of the automative industry
hospital billing, an AI to decipher doctor handwritten patient notes, there we go
oh so here's an issue I'm having: in 2009, a train in my city crashed because of an automation failure, so the whole system has been reverted to manual operation ever since. This is the most significant instance of a city's rapid transit going from automated back to manual.
and now there's discussion of going back to automated, and people are against it, and I think it's because everyone assumes automation -> generative AI -> bullshit hallucinations and no accountability.
that's a point that I'm confused, like, idk if i'm study to be a machine learning engineer or a AI engineer
To put this in a business context, what would be the purpose of creating a new AI model to do this? What would be the benefit over let's say calling a frontier model's API or using transfer learning/fine tuning on a smaller model?
You're going to be confused because the industry does not know how to code people for those roles lol
I've heard AI engineer apply to everything between gen AI/agentic roles, ML ops roles, ML engineer roles, and data scientists
what do you think the difference is?
no matter what your answer is, you'll never find two companies that use both titles to mean the same thing.
Regardless if you want to develop your own model architecture at a founding company or not, knowing the internals helps practically in troubleshooting/model evaluation/model selection contexts AND makes you more competitive for these roles in a world where everyone can use them with little training.
yeah, here in Brazil, its an “outlier” you know about AI and Machine Learning.
I was searching for a job, and like its so hard to find a single one
this project, its just for train and study, like just to put in my portion
AI engineers know how to put a model in the world problems
ML engineers know the math and techniques for train the model
To be competitive for most roles (at least in my market) you have to know the fundamentals and internals, regardless of whether or not you're actively developing/interacting with those internals, tbh.
I've come across maybe one or two roles that are asking for someone to actually develop new memory or training architecture or whatever, most of them are just utilizing it but also wanting you to know how it works
why would those be two separate occupations?
So to enter in a job you need to know
The MlOps (how to use the ready models) and the machine and deep learning techniques?
idk, like if are a big company maybe have that differences, no?
The naming of jobs in the field is just really cursed right now, but...
I'd consider MLOps to handle this likes data cleaning, preprocessing, setting up timings/orchestration for model retraining, flagging concept/model drift, things like that. Basically, trying to handle the automation to support the dedicated ML engineers
Of course, at a smaller company, likely those two roles are the same person
What was it again to run it?
storing run data, versioning data, making sure you could repeat any model training that has been done historically, that sort of thing
like the conductor at a concert
!e ```py
memory = {'boris': 10, 'alice': 20, 'billy': 7}
query = 'benny'
def distance(a, b):
return sum(c1 != c2 for c1, c2 in zip(a, b))
matches = [(key, distance(query, key)) for key in memory]
print(matches)
best_match_index = 0
best_match_key, best_match_distance = matches[0]
for i, (key, dist) in enumerate(matches):
if dist < best_match_distance:
best_match_index = i
best_match_key = key
best_match_distance = dist
print('Winner:', query, '->', (best_match_key, memory[best_match_key]))
:white_check_mark: Your 3.14 eval job has completed with return code 0.
001 | [('boris', 4), ('alice', 5), ('billy', 3)]
002 | Winner: benny -> ('billy', 7)
@warm dune
sure, but you can't assume that every job you have will have that division of labor. if you know how to train a model, it's expected that you also know how to deploy it.
Your coworkers will like you more if you have a working familiarity with their part of the job, basically
And you're also more likely to be hired if you do.
Not necessarily deep expertise
But knowing enough that they can talk to you and you understand what they're saying and you won't make their jobs harder/worse 😂
But maybe I'm considering roles more senior in scope.
But I would think it's somewhat applicable even for lower levels
yeah, cuz of that i know the EDA and PREPROCESSING methods too and always doa section about that in my projects
Nice.
so here you do an "NLP" idk if this its really, using the memory methods?
Honestly, it's not like learning about any of this stuff is completely irrelevant. There's a lot of overlapping concepts. And almost anyone would rather work with someone that has context into what the work will be like when stewardship is passed.
This is a simple example of query, (key, value) search and content addressable memory. The idea being that I basically want to pull up the thing that best matches what I am looking for, imagine a search engine like Google (it actually works like this the under the hood, although what the query, key and value are is different and distance too).
responsibilitiy? Stewardship is technically a good answer but a bit weird. But ownership isn't really true either
and the deploy the model have a name for searching and study about that, cuz all the project that I do, i use the streamlit
"I wanna work with someone who doesn't make it harder to do my job"
Streamlit is a nice way to get a web deploy without having to touch most frontend stuff
Good for people like me that hav eno interest in frontend
I think this is still a little more difficult, I would have to look at it more calmly, I'll leave this for last First I'll delve into simple questions like churn, and learn more about optimization algorithms, and then go to NLP
To see why this shows up in ML/AI, imagine you have an AI playing a game of chess and the query is the current board state encoded in some way, and it pulls up the most similar memory (or k-most-similar, or maybe some mix, etc), and then attached to that in the value is some instructions of best possible moves to make.
i never work in the tech area, so i'm totally lost about that
same 🤣
Suffice it to say, that knowing at least a bit about the jobs of other people you work with will make you more competitive and increase how you're viewed within your career/company.
do u have advices for the first job?
Honestly, any advice I have might be out of date by the time you graduate.
Your first job will often be one of the hardest jobs to get. But as long as it's in your field and at least vaguely oriented to your career trajectory, you can leverage it and continue to grow/move forward in your career.
I've never worked without my dad, so I never know what the process is like, and since I'm only 18, sometimes I'm kind of idle because companies might think I'm too new
When companies hire it's sort of a risk assessment. They want to choose the new employee the most likely to "pay out". Unfortunately, for most, when applying to their first job they really don't have meaningful discriminators. One of the most meaningful discriminators is relevant professional experience. So really, that first step is often the hardest.
This reason many AI models use this as a basic building block from which they make everything is because it's an implementation of the most basic/weakest form of logical reasoning, remembering individual associations (upon which the others can be built).
here in Brazil it's normal, you join a company and they hire you to study with the company, obviously earning very little. But oh I realized that this area of AI is non-existent
Ah, interesting. I'm primarily familiar with the US market, to give context
The field of AI/ML is definitely rapidly growing right now.
about this, maybe a place in the foreign language would be a bit difficult because you are still studying and do not have the diploma
idk if in the US are cases like i comment
That's the other meaningful discriminator besides relevant/recent professional experience. The diploma. And for ML/AI I am frequently seeing positions ask for higher level degrees like masters/phds
yeah, I'm screwed
It might be different in brazil and it may be different in the future.
But.... yeah. People know AI/ML is a rapidly growing tech that they want to work in, so competition is fierce
Enough so that even though I have significant professional accolades, I'm still going back for my masters
masters degree in what? AI, or some area of mathematics or physics
This is almost purely for career leverage, so it’s a masters in AI with a data science certificate
It works. I can breeze through large chunks of the coursework, I'm still learning things, and I can target electives at stuff I don't know. (I had an undergrad in biomedical engineering so a lot of my CS-heavy stuff was self-taught through like... coursera and stuff)
I think it would have been valid if I just selected courses I already knew and easy ones. But I made this choice and I'll rest when I'm dead 🙃
in the US
what types of grad have?
like an AI Engineer
or are just masters yet
I'm a little confused by what you're asking. Are you asking what kind of masters programs are available?
yeahhh
Or what types of degrees are most desired?
Masters in AI seem to be a lot more recent. Oftentimes it's just masters in computer science or masters in data science to be the signal companies are looking for and what most people in the field have
I'm expecting to see more masters in AI come up for new grads or returning professionals like myself
cuz here in Brazil, there are 4 different university courses that are practically the same thing.
Haha. Well, there's certainly a lot of overlap. For instance, I don't even have to go out of my way to pick up a data science graduate cert with my masters. Same number of credits
like, here don't exist yet a course that guide u for be an AI/ML Engineer, have extra hours for that, but a course explained everthing beatiful no
thats why i started to study before enter in a university
That makes sense. Computer science or data science are good enough corrolaries with computer science probably giving you more leverage on ops types roles and data science giving you more leverage on the deeper/science related roles. Those are probably your best bets for an AI/ML engineer role.
THat being said, unless your university is structured differently, you don't have to decide on that right away. I mean, I can't actually finish my AI masters right now. The coursework is still in active development.
at the best university here, it's like this, you do a degree in one area and then you can do a master's or PhD in some area like AI and more. And most of the classes and lectures are on YouTube, and I always see, and I'm perplexed how sometimes a book can teach much better than teachers
Idk what it's like there, but I feel more comfortable studying the area in videos and books than in university classes
Yeah. It’s a curse of academia. There are reasons to be in academia besides a love for teaching (research heavy professors doing courses just to continue their research) and unlike teaching at pre university levels there aren’t like teaching qualifications they need to get so you can get professors who are undoubtedly brilliant but have little desire/ability to teach
That’s not to say you can’t learn from them, but I’d be remiss not to mention this
I won’t get into the argument as to whether or not college is “worth it” or not for learning. Other people have made better arguments than I can make. But it absolutely matters with regards to employability
I know a degree carries a lot of weight, that's why I'm going to college, but in terms of learning, would you recommend me for YouTube videos and are books enough?
I think there are two aspects to this. I think there’s always value to have some kind of learning grounded in human interaction, because 1) on the off chance that you’ve deluded yourself on a subject there’s a sanity check and 2) explaining concepts to others helps you cement your own understanding for a variety of reasons.
But ultimately, I’ll point back to my prior comment on metacognition. Learning how you best learn and then capitalizing it is incredibly powerful, and if books and videos are how you best learn then go for it.
And honestly, for me, going through this masters course gives me a lot of validation on the topics I’m already familiar with
So academic courses can still be a good reality check, so to speak
yes yes, I always do it like this I look up the general concepts like I learned from the book "hands on with..." Oh, I saw the terms and organized the days for me to study, and I always taught what I knew to my mother
and then there's always like a change in the general perspective, oh I thought I knew it was just the tip of the iceberg, then I always go back to the beginning of the concept and redo the whole context and thought
for example
I had studied algebra just with math, and then someone told me to go deeper
then I learned a lot more things that I didn't even imagine I knew and that helped me a lot to understand
so I always stay at it, I think I know everything, then comes the bomb and I reorganize, I learn more and more...
Yup! You have the right mindset.
can you explain those a little further
It's common for someone's first pass over linear algebra to focus on computing with vectors and matrices. Involving a lot of by-hand or programmatic manipulation of components. In general the view here focuses a lot on the component level interpretation of linear algebra. It's very concrete and it's what is often needed for practical application. The follow up to this is diving into the functional view of it, where the detail of manipulating components shows up a bit but takes a back seat to understanding linear algebra from a functional/mapping point of view, transformations, covariance, contravariance, composition, etc. This is where the more abstract notion of vectors come in, but it is not fully divorced from the concrete. It's going from the specific to the general. The abstract view is the modern style of mathematics where instead one starts with a high level/abstract notion of what is desired, and then (optionally) constructs a specific example (general to specific (or just stay general the whole way)). Prescriptive -> descriptive.
guys rn I'm doing an churn model, with the telco dataset, and the loss are actually in 0.3
But the precision and recall isn't well, cuz the classes as 75/25
And i will try to do some feature engineering, to create new features, how can I think, like, how can I know the best combinations to create a new feature?
is background in graph neural network theory sought after by companies hiring ml researchers?
or is it fairly uncommon
there are so many kinds of neural networks. if you actually understand how neural networks work in general (most people who claim to practice "AI" do not), it doesn't really matter which architectures you've actually used.
i see
I'd say it's mostly beneficial when you're dealing with structured to unstructured mappings. But it's just one method out of many. You should ideally have that in your toolbox already.
Eg: Chemical dataloaders mapping chemical data to binary classes
i was mainly asking because i'm more interested in combinatorics and graph theory, but i'm also interested in how they can be applied in machine learning, so i would be interested in doing research in that in the future
GNNs do not help produce outputs that are themselves graphs AFAIK. You can at best get them to output adjacency matrices without properties maybe if you have spend a lot of effort building the tooling, but not graphs themselves very easily. It's mostly used to input graphs, not output graphs.
If you're interested, then pytorch geomteric has a list of models worth going through.
i see, thank you
Hi guys, I have a question about ML research. What is a realistic roadmap for a high school student who is going to college next year to become one? I have done a lot of deep learning and reinforcement learning with various algorithms for a couple of years now, but I don’t even know if I have a strong foundation in the basics yet. When I watch online tutorials, I feel like I already know them. I have read a few books, though, but I still can’t seem to improve in ML. Any suggestions?
an example project I am have done: https://github.com/EricZ6365/myMLLIb
GitHub
Contribute to EricZ6365/myMLLIb development by creating an account on GitHub.
speaking of which: what is the best approach to edge inference, if there is such a thing?
what statistical test would you use if your data set has a combination of ordinal, nominal, and continuous features?
I mean,
the idea here is that you ought to be able to understand how to formulate the alternate hypothesis, and then test for its likelihood. This is like fundamental. But doing so implies other things about the data you have
You'd have to build it yourself, nothing maintained currently in the major ecosystems
I am seeing very recent articles on the Search AI
it can't possibly be this recent a problem.
It's not that it's recent, it's that it's niche and no one has cared enough to implement it into pytorch geometric.
Yeah, I'd imagine Meta has robust internal platforms for that
Hi guys I am shaahir from India. A first year undergraduate.
I just now started machine learning and done mathematics for machine learning certification from deep learning in Coursera and doing ml specialisation by Andrew ng.
Can anyone give me guidance on what my next step should be. I don't have any hands on experience too
I mean for now I would need to understand the data and question i guess.
but I guess I will first observe the empirical information for each data(mean, std, variance etc). then probably covariance. normalize features. pca etc.
Ok, so, I'll have a bit more code later of course, but right now, I'm starting on something and um....

An example of one of the files

Technically, I am asking for help with an assignment, but also, I'm by no means telling anyone to do it for me I know how to do it I just want to know how to fix this error
(It's a really simple (X^T * X)^-1 * X^T * Y assignment)
I have no clue why but if I remove the other junk and only have the [:, 1:], there are these things that should be numbers that are written as strings instead

I think it may be because of that strange 7th X2 term
Has quotation marks in it for god knows why
It's why I have astype(float)
and because of that "2,325.72" I'm trying to add a comma remover too
Is this teacher a fucking psychopath
I uploaded the csv onto google sheets and this doesn't seem to be multiple terms, as the terms all still exactly fill out the columns from X1 to X22
Probably messy raw sources
usually caused by somoene sticking their g.d. thumbs in the data acquisition. Copy pasting into Excel, and then exporting, stuff like that
par for the course. Expect it.
it is important in situations like these to always document the data cleaning operations in the form of whatever ETL code you use for it, then generate separate tables for the updated data.
Because with stuff as messy as this you never know if the ETL code you use might have errors within it. Raw data should always be kept in its original state.
one thing I've done in the past, in C++ no less, was to translate all the strings into their respective hexadecimal representations, and then go from there to representing as actual floating point.
With python you have a highly abstracted way
number_str = "123.45"
number_float = float(number_str)
But I would do a first pass of each row getting rid of any characters that aren't numbers or decimal points. You never know what other garbage is lurking in there
in all honesty, this is a data science task (understanding the domain sufficiently well to be able to formulate the alternate hypothesis, and to know what the null is). Maybe you want to focus exclusively on machine learning. Recall that Data Science is Machine Learning + Statistics.
Statistics is so inherent to machine learning that I don't think it makes any sense to say that adding statistics makes it something else.
Not sure I agree.
but, truth be told, the context is H0 & H1, which are properly a data science task
Statistics is the mathematical framework for all models.
Some of them also involve linear algebra and calculus.
eh, you are splitting hairs in a fuzzy region.
I'm really not
I've never heard anyone assert that statistics isn't foundational to ML before this conversation
Alright
You'll be studying computer science, yes?
I would make sure the facility, such as your student advisor, knows that you're interested in research. They'll know what opportunities are available to you.
If there's a research professor who takes undergraduate research assistants, that would be very helpful.
If you don't have any hands on experience, get some. All it takes a computer and a brain. You have both.
lots of very credible autodidacts in this area.
Yea I guess but how would I get them my student assistant is not really helping in this way
Like how to contact professor
You'll have an academic advisor who can tell you which professors to talk to.
in colleges ?
Is it possible to get on that before colleges. I have learned ml for 3 years by now
Is there a local university with computer science research faculty? You can always ask.
I guess? how would I approach this. jus go to and ask?
Yes
Thanks
wait this is the correct chat
ok so on the raspberry pi, which is better pytorch or tenser flow for reinforcment learning
Just use pytorch.
But you don't want to do model training on a pi.
universities are becoming centers for networking. They enable you to know a guy that knows a guy, because the knowledge itself has been so thoroughly popularized and spread far and wide that lecture halls are somewhat obsolete by now
you can learn ML on your own quite well if you have the dedication. But it won't get you into the club, so to speak. You still need to network for that, and a place where you are placed in contact with potential colleagues is important for this
However, with a caveat
One thing that I got from my time in the PhD program was the intuition that endless seminars provided me with. Speakers once or twice a week, always talking about algorithms, answering your questions. Hard to reproduce that outside a university setting.
I pretty much agree with this
this is for computer based stuff, mostly. I cannot fathom how you could do without universities if you are studying Chemistry, for example
right
I've got an absolutely massive investment-related dataset with a mix of nominal and numeric data, and I'm trying to build a gradient-boosted decision tree off of it. I'm running into the issue that there are so many unique nominal values that python just doesn't have the memory to create dummy variables for all of them. The data has all kinds of variables related to tech startups, their founders, the degrees earned by their founders, funding received, acquisitions, etc, and I'm trying to use the decision tree to determine what aspects of startups make them most likely to be acquired. In any other scenario I'd just drop the high-cardinality columns, but in this case those are incredibly important to the model (what university the founders attended, tags describing the company, region, etc.). How do I deal with these columns while keeping them in?
have you thought of forward sequential feature selection?
without a closer look into your data set, it seems to me that your problem is really one where you don't know what you need from all the features available to you
so perhaps apply an algorithm that automatically tosses stuff out that will not impact your conclusion
or, putting it somewhat differently, it looks like you have what is fundamentally a data labeling problem, so you need to cluster important features together, subject to some cost function argument
You're stuck with permutations, it seems.
unfortunately
I can shave down on the variables I'm going to feed the model, but my problem is the ones that I know I'll need have too many categories (think 25k at max)
Buy a bigger computer lol
the other question I have is that unknown ratio, features / samples, and the curse of dimensionality. A 25K-dimensional problem surely can't have well-resolved solutions
it's the reason I suggested forward SFS, you start small, and build it from there. And, you don't really know what features are important before actually getting the result, now do you?
The variability in this dataset is crazy, and insofar it's been hard to pull any definite trends from. I'm hoping to get something from a gradient-boosted decision tree
kinda sounds like you're still in EDA mode
Yeah, I've been in EDA mode for a while
Again, not a lot has come from it
but project guidelines demand machine learning, ergo the model building
gradient boosting trees dont need you to do one hot encoding though
you should be able to just shove them directly in
Hmm... I need to do more research, then
I was going at this completely wrong
either way, you'd still have a problem if there's that many categories but you don't have much data to back it up
do all 25k of those categories have sufficient data such that there's a possibility to actually model them?
like if theres a lot of them that only appears a few times, maybe putting all of those into a Other category or something can be good
That's a good idea. Looking at the categories, the number of observations in each ranges from 47k to 1
so an Other category is sounding pretty good rn
the question is, what's the cutoff?
I should probably limit it to 15-20 categories + an Other category
how many rows? 47K? is that right?
are you familiar with this conceptual plot?

where that optimal value is something that is experimental. You have to find it
66k
the other thing that has to mentioned here is that distances tend to diverge to infinity as features -> large. In that asymptote everything looks like noise, which is the reason that performance drops to zero
I understand, I was going about it all wrong in that I was trying to use a completely wrong method
I'm still having issues with high cardinality, but significantly less
high cardinality is basically a numerical feature. never mind. Ordinality, not cardinality, my bad.
I'm getting a "cannot convert string to float" error when I try to fit the gradient boosting classifier to the data, though
so that's why I'm trying to convert to a dummy variable
just let me repeat what I said earlier, which is the way I would do it
start small.
throwing the entire thing into a trash can like this really removes all interpretability, if you actually get a result in the end. And I assure you that your dataset has a ton of internal structure that you are probably missing
to start with, you need to understand model performance as a function of both a. feature set, and b. number of features.
and, additionally, you need to understand what is "good enough" for the business use case.
personally, I would wrap it all up in some sort of a for-loop, with an sklearn pipeline stuffed inside with all pertinent details. There are examples online you can use for inspiration
but, I would definitely not try to get a universal solution in one fell swoop.
hello, im studying system engineering , and i want to be an ML professional, i know that i need to know python and sql, but i dont know were i can learn what i need for ML
take a look at the pinned messages.
for others reading this, there's relevant context here: #career-advice message
GitHub
This repository is a curated collection of hands-on data science projects tailored for beginners. Whether you're just starting your journey in data science or looking to strengthen your ski...
Does anyone have a recommendation for an open source graph neural network I can learn from?

GitHub
Graph Neural Network Library for PyTorch. Contribute to pyg-team/pytorch_geometric development by creating an account on GitHub.
I had heard that name I think. Have you used it before?
a little
I have a couple thousand messages between my friend and I. Are there any tutorials which can guide me on fine tuning an LLM to make it talk like me when prompted by my friend? I tried doing it on my own but it is janky and I have no clue on how to do it "properly".
If I parse my data into a specific format shouldn't there already be hundreds of projects that do this exact thing on the internet somewhere?
@stuck swallow fine-tuning requires a lot more RAM than inferrence. You need to figure out what compute environment you can use and how much RAM the GPU has. then you can use that to figure out what LLM you have the capacity to fine-tune. It will probably be one of the smaller ones.
From there, you can follow pretty much any tutorial for fine-tuning an LLM with transformers and pytorch. it's the same for any LLM.
with a home setup, I think the best you could do is basically get nominal experience with fine tuning. Get a tiny model, and play around with it
learn the mechanics, gain familiarity
that sort of thing. But you won't generate something production grade
have a place where i can have GPUs for train the models?
Google Colab
Hey, I’m training a model (Digit Recognizer) on the MNIST dataset with one hidden layer (200 neurons, ~159k params). I got a training loss of 0.014 and a validation loss of 0.065.
Does that look normal, or is my model overfitting? Also, is it normal to get such a low training loss?
My Code:
n_hidden = 200
g = torch.Generator().manual_seed(2147483647)
W1 = torch.randn((Xtr.shape[1], n_hidden), generator=g) * (2 / Xtr.shape[1])**0.5
# b1 = torch.randn(n_hidden, generator=g)
W2 = torch.randn((n_hidden, 10), generator=g) * 0.01
b2 = torch.randn(10, generator=g) * 0
# BatchNorm parameters
bngain = torch.ones((1, n_hidden))
bnbias = torch.zeros((1, n_hidden))
bnmean_running = torch.zeros((1, n_hidden))
bnstd_running = torch.zeros((1, n_hidden))
parameters = [W1, W2, b2, bngain, bnbias]
print(sum(p.nelement() for p in parameters))
for p in parameters:
p.requires_grad = True
# Training
max_steps = 10000
batch_size = 32
lossi = []
for i in range(max_steps):
# Minibatch construct
ix = torch.randint(0, Xtr.shape[0], (batch_size,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix] # batch X,Y
# Linear layer
hpreact = Xb @ W1 # + b1
# BatchNorm layer
bnmeani = hpreact.mean(0, keepdim=True)
bnstd = hpreact.std(0, keepdim=True)
hpreact = bngain * (hpreact - bnmeani) / bnstd + bnbias
with torch.no_grad():
bnmean_running = 0.999 * bnmean_running + 0.001 * bnmeani
bnstd_running = 0.999 * bnstd_running + 0.001 * bnstd
# Non-linearity
h = torch.relu(hpreact) # hidden layer activation
logits = h @ W2 + b2 # output layer
loss = F.cross_entropy(logits, Yb) # loss function
# Backward pass
for p in parameters:
p.grad = None
loss.backward()
# Update
lr = 0.1 # learning rate
for p in parameters:
p.data += -lr * p.grad
if i % 1000 == 0:
print(f'{i:7d}/{max_steps:7d}: {loss.item():.4f}')
lossi.append(loss.log10().item())
you can plot the learning curve to see that
I think it’s an good ideia for now
is it overfitting? there are standard machine learning ways of finding out if it overfits.
are you using something perform like a k-folds in the training step?
your code is fine, but you can simplify it and make it lighter
it will be as you like, I prefer it another way
is there anyone available whos good with Dataframes? i need help and im in a huge hurry
It's also not entirely their fault. They tried to get help earlier.
I can't help right now, but the best way to get help with pandas is to show a sample of the data frame as text (no screenshots) and describe what you want to do with it
You can do print(df.head().to_dict('list'))
well what im trying to do is add together the total amount of jobs made between when a republican president was in office and when a republican president was in office
i have the data for how many jobs there were for each month from the years 1961-2012
the data looks like this
['1961,45119,44970,45048,44998,45122,45289,45399,45534,45592,45717,45930,46036', '1962,46040,46310,46374,46680,46670,46644,46720,46775,46889,46927,46911,46902', '1963,46911,46999,47075,47316,47328,47357,47460,47542,47661,47804,47771,47864', '1964,47925,48172,48286,48278,48419,48550,48735,48887,49117,48948,49339,49524', '1965,49645,49826,49993,50208,50397,50562,50764,50957,51152,51341,51560,51823',
etc
If you give as much information about what you're trying to do as you ever possibly can, I can take a look in about nine hours.
Sorry but I have to sleep. Maybe if you explain what the structure of that data is, people can help
all good
Guys, how can I improve my feature engineering, I talk more about creating new ones (encoding I already know), I can't come up with ideas to put two features together and create a new one...
@modest cedar sorry I couldn't help you last night. did you still want to talk about your data? It looks like each string is comma-separated numbers where the first one is the calendar year and the subsequent 12 are some employment figure per month. You'd need to match those up with the political party of the president for each year (and decide what you want to do about January on inauguration years).
you're going to have to explain a bit more, what kind of features?
what model
I generally speak like
I was participating in the Kaggle irrigation competition, and I needed to put together features to create new ones
Now I'm in another competition, and having to put together features to create others
it's more about knowing, what feature combinations I have to do
In this current competition of mine, I had a feature called age. So I created the feature "IsChild", but that's it, I can't have that creativity to create a good feature, like this one without external help
which competition?
Is there anyone who has written any research as a major project in their last academic year in data science/ML domain?
I need some guidance from them, it will be very helpful for me if you guide me 🫠
the one now is from the 'spaceship titanic'
the starship titanic is a goated adventure game
do u think it's a good ideia to put competitions in the porfifolio?
if you don't have professional experience yet, competitions are one of the things that's available to put in your resume, yes
exactly my case, I have 0
Oh I already turned it in, didn’t have much of a choice anyways but ty
I wanna take data science as a career, what do you guys recommend as a road map?
"data science" was a buzzword that died down in the last few years. The reality is that there's no "science of data" that is a separate thing from statistics, and "data scientist" was just a title that companies gave out to sound hip.
Are you more interested in analysis or machine learning?
Ok before I say, is it still something that'll be available
also, I'm decreeing that the name of this channel is "data, science, and ML". not "data science and ML" and certainly not "data, science and ML"
Alr thx for alerting me
But idk exactly I just like dealing with data in general
I was thinking of learning both data engineering and data science
I was mostly working with sckitlearn and pandas
Where does that fall exactly
there's no universally agreed upon distinction between "data engineering" and "data science"
but to the extent that they do, those both fall under "data" """science"""
at least in theory, "data engineering" is about acquiring and storing data in a way that makes it easy for people such as analysts and ML engineers to use it.
I don't know anyone whose job it is to do that, whose title is "data engineer"
That's what I know
Well I guess names don't mean anything anymore
The job requirements do
job titles in tech have never been meaningful
you don't use pandas or sklearn for data engineering.
I guess cause everyone has their own view of what it should refer to
right. if everyone had their own definition of "cat", the word would be completely useless.
But what would you recommend if I wanted to deal with data as a professional position
that could mean one of approximate three quintillion different things
Well technically both kittens and cougars are cats
So you could see it that way I guess
I mean, if one person said left item is a cat, and another person said right item is a cat

if those two people tried to talk to eachother, they'd be having completely different conversations
pretty much all the jobs you're probably thinking of require a degree in something like computer science. this is even more true currently.
We're back to requiring a degree?
I am in my first semester
Technically computer science but it's only 3 years, not 4
And is more practical
So less theory
back to it? when did we leave it?
Remember when you'd hear stories of people getting 6 figure jobs without a degree in tech
Especially in cybersec
yeah, those have always been exceptionally rare. people heard about the success stories, but for each success story was like 1000 people who tried without a degree and failed
now, the situation is so bad that there's no point trying if you don't have a degree.
Survivorship bias
Youre interested in data science? Or just data in general?
Used to be?
Apparently it's just a buzz word
Salut 👋
Data science has a high entry barrier
In smaller companies or start ups the entry barrier is you cant just only know data science, you'd need to have more breadth in their stack
And then in large corporations (think netflix or spotify) the entry barrier is you have to be really good damn good at it, and many require a masters degree or even a phd
and to get a job at a start-up, you need organic connections
Correct
I got those
I easily connect with people
I mean what do you know so far in terms of data?
Got the extroverted type of autism
I'm talking about relationships with people who you've known for a while and who are very familiar with your capabilities. Not people you've superficially talked to on linkedin
I know how to use json, csv in python, I learned pandas and sckitlearn to make prediction models based on data and the strategies to use when feeding the data
I know people who have connections, I don't resort to LinkedIn usually
You'd need to know some data engineering. Feature engineering is also important.
One of my professors, she helps students get co-op interviews and she said she'd help me. I got a guy who wanted to hire me as part of his startup.
Reminds me maybe I should message him
🥲
The majority of scikit learn models are rarely ever used in production besides as part of an ensemble or baseline models/EDA
yeah you should
He's in the same college as me but he already has a functioning business
The industry standard is basically just XGBoost/LightGBM with embeddings
I am also a part of a circle of tech friends, some of them can refer me to the companies they work at, but nothing too crazy
So, what do you recommend I do?
To be a data scientist?
Since I never got a job in tech before
Its not exactly an entry level role
Do you think I should first focus on getting a generic role first
what country are you in @warped notch?
Canada
I think traditionally people would start as data analysts, but tbh these days I feel data analysts are on the chopping block because of AI
So how do you get a job that requires senior level experience when you never had a stepping stone?
remind me how many more semesters you have?
Welcome to the world
Just finished my first, I got two more before I start the "co-op" term
I know some of the mysteries in tech
You don't. If the job purportedly requires "senior experience" (whatever that is), and it hires someone who doesn't have it (whatever it is), then it never required "senior experience" in the first place.
You either do a lot of school and rely on that or do something adjacent to data roles
Well my idea was do as many relevant projects as possible
And projects that actually work and could possibly scale if they were in a company environment
Ive seen people go from data engineer to data scientist unless they already do both
If you were in a company environment, a pandas and scikit learn pipeline wont hold or scale
If you wanted do this, you'd have to be creative
Kaggle datasets wont do.
I guess it's the same when you learn database and you use SqlLite or Postgres, but companies use scalable ones
My secret is out
If youre wanting to be a data scientist and youre expecting the workflow to mostly be machine learning, thats never the case
Idk now it feels like I should pivot elsewhere cause by the way you guys are talking it feels hopeless unless I get specific education on data science
I don't wanna pivot elsewhere tho
I mean you dont have to pivot, but your expectations might need shifting
Def recommend self studying
Do you use GPU or CPU to run a simple/small NN?
Especially if you're a CS major. You arguably need more stats than CS for data science.
Ya but itll be slower
If you use CPU. You can do either
How do you access gpu? In python ofc
Like the gpu hardware:m/code, I don’t really know how to describe it
Like for example when using openGL I need to write in .glsl to write the frag and vert shaders
Which tells GPU what to do
where is the rl crew
CPU.
Several ways, for example via Pytorch, Numba, Taichi, Cupy, PyOpenCL, Kompute, etc.
At the lower level this happens via any GPU API available, such as CUDA, OpenCL, Vulkan, DirectX, Metal.
If you want something like OpenGL/GLSL, OpenCL or CUDA.
But this is usually much more low level than needed in Python.
Has anyone got experience in image processing? I might be doing a research project this summer in a medical application of image processing, wondering if anyone knows a good place to learn up on the basics
What kind of processing ?
I think its basically looking at eye scans and doing some sort of classification
I think PyTorch and machine learning is the way to go for you
you can classify images with convolutional neural networks (CNNs)
It may not be nesscessary, sometimes open cv's tool are enough. But if you have time to learn, it defintely worth it
what is the best way to get ai compute credit. currently I have being trying to train a image generator but I ran out of credit before I barely validate a tiny mode.l any suggestion?
Google Colab / Kaggle
you could also try Azure or AWS free credits if you haven't registered an account on them yet
I have google colab and I am actively using it, but for a larger model colab is a little to small. pretty much most cloud provider don't provide free gpu credit anymore
I am looking for like program that could grant credit or smth
Google colab is really useful
Free gpu credits
just as a general idea, how much time do people here spend going over pen & paper derivations of math tools used in ML?
Like, I recently interviewed, and the interviewer asked me to walk thru how to implement a principal component analysis. So, I basically walked through the steps: covariance matrix, eigenvalue decomposition, selection criteria, Scree slope, etc.
but... what if all he wanted was from xyz import PCA, etc?
he also asked a LeetCode question, Fibonacci. Solved that one quickly. Maybe I did well 😄
train, as in from scratch? nothing then, besides the compute you're also gonna need really really large datasets that I doubt any free service provides
I concur; training an image generation model from scratch requires way more compute credit than anyone will give you for free.
oh really.
I estimate from my smaller model on mnist/cifar10 I would need around 5k credit is this really to much
but I really want to pretrain this model can I have some ideas thanks.
also I have a ~1million domain specific images in compress form locally + 5 million laion subset
Hi everyone! I'm looking for books on machine learning and computer vision using Python. Can anyone recommend some good books that they've read?
check the pins
just curious what are some good ml projects that won't require a lot of money and is good on someones resume
Your major is machine learning, right? Are you students or AI engineers? I'm a beginner and I'd like some advice and roadmap from your experience
to store all those training images I mean, though now on second thought the storage problem is likely still second to the compute problem you're gonna run into
if you're willing to spend at least some money, photoroom has some blogs on how they jump to a somewhat usable model using 'only' ~1k dollars
even still, you'll still want to leverage off-the-shelf components instead of retraining everything from scratch, like the text encoder, or the VAE if you want latent space models
I’ve been getting into machine learning but I don’t know which language to go with. I have experience in python, julia and c++ but all 3 have their own ML libraries. Ik that python is industry standard but I’m not sure which to choose for now.
python is the industry standard. there's absolutely no contest.
There's still some demand for R, but it's fading
The problem there is that R has a more complete statistics ecosystem than Python does, and losing that "culture" is going to strand all that knowledge
I wonder if vibe coding R -> Python modules would be a good way to spend time
And Julia? It's still limping along
So, basically, focus on Python. You only have 24 hours in a day, after all
Julia just seems fun honestly lol
Just all vibes

Turing Pi is a compact ARM cluster that provides a secure and scalable compute in the edge. It is designed to make web-scale edge computing easier for developers.
I really want one of these but I have no idea what to do with it
Slap it to a robot and teach it to walk lol
Rough time to try to get one of these to make some ML project. A RaspberryPi 5 16GB model is currently $300. Used to be like $75.
Guys, what other areas is AI being applied to most? Robotics, medicine, agronomy, and others
Enterprise
Thank you nvidia
This is multiple little compute modules though, it comes with them + the big board
I kind of want to just bite the bullet and get started doing something
A single RaspberryPi 5 is pretty powerful, you can run smaller models on it, especially other non-dense-backpropagation-based models (other parts of ML than standard deep learning (note, can still often be implemented in Python with the standard ML toolset (Numpy, Pytorch, Numba, etc)).
If you want more with this kind of cluster approach, I would use something cheaper than a Pi 5 (or Pi in general, too many people are buying it (for now, could maybe just wait it out too)), there are other options, but they are far more painful to program.
So there is a tradeoff with how easy it's to experiment with. Probably leaving the implemention on a cluster for later (when scaling up).
Some of the cheapest that make for really nice low power, highly parallel clusters being small RISC-V processors (less painful than they used to be, but not great, tooling is still WIP).
(Which matters in the case of robotics a lot, it's where a lot of the power usage comes from now, motors have gotten really efficient)
The problem regardless right now is RAM though. Until the competitors in China ramp up or bubble pops, it's like this.
Bigger models can run on very little (relative) (for inference), but need a lot of RAM, so common right now is to buy these RAM/VRAM unified memory machines (since consumer dedicated GPUs have little VRAM (they were made for gaming and like Blender/Photoshop)).
(In addition consumer dedicated GPUs use too much power, produce too much heat (also loud which is important to consider when having them at home); this will give you a big electrical bill (from cooling too))
This is also the part where I need to add that making a cluster like this is fun, but loses to something like a Jetson Orin Nano Super, in every way (for robotics + ML) (economy of scale and also they really pushed the tech far to fit a ton into one small processor, which is just more high tech than slotting in tons of separate machines).
mood
Apple’s unified memory is pretty good, but I’d be spending the big bucks just to get a mac mini
Which isn’t bad but still pricey
Id rather stay on the simplicity side for now and bite the bullet in terms of expense. Itll make it easier to learn.
thanks I will look into that
The mac mini is overpriced, see framework desktop and similar instead.
Also you probably want Linux so you can do whatever you need to do.
You can get 128GB unified memory Framework Desktops (small box, Ryzen AI Max+ 395 processor is about on par with a 2020 dedicated GPU (plus its CPU can run a lot)). Don't expect to train giant models on this; inference works really well though, you can run stuff like gpt-oss-120b on this (60~80 GB model). Not cheap but pretty much best there is other than Nvidia DGX stuff for home desktop ML. Dedicated GPUs from gaming desktops can work with stuff like the 5090, but that gets really expensive (need multiple (for more VRAM)), and really loud, and big, and hot.
But for robotics it's a different story, there stuff like the Jetson is pretty much it.
One of the big limiting factors for what to have at home is actually heat produced. It starts to become a lot, like having a radiator running 24/7. If you don't have AC it won't work out, and if you do, it will be struggling (heating and cooling the house at the same time, not great).
This is different from something like gaming, which is usually not running 24/7 at high usage.
(Hence the integrated GPU with high amounts of unified memory builds that are popping up all over, a lot less heat, quiet)
If you just want to learn, and don't know if you even will be trying to run big models, and/or don't want something pricey, then really anything will do. The basic ML stuff can run on pretty much anything. Even really old CPUs/GPUs can still do a lot things. Just make sure they are not so old that they don't support things you may need like CUDA/Vulkan/OpenCL/etc.