
#data-science-and-ml
1 messages · Page 146 of 1
the gyms?
Theres so links at the bottom training agents

A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
What a mathematical formula do I use to get from -1 to 0 to 1?
hyperbolic tangent
Asymptotic
thank you
Thank you
I would not be subtracting the weights and biasis?
?
Ticket when I need for the function my apologies

import numpy as np
X = np.array([[1,2,3,4,5,6,7,8,9,10,])
W = weights
B = bias
output0 = (X,W) + B
def Exponential_definition(output):
output1 = output0**1 / output0** -1
Exponential_definition()
print(ouput1)
there's also the logistic function https://en.wikipedia.org/wiki/Logistic_function

A logistic function or logistic curve is a common S-shaped curve (sigmoid curve) with the equation
f
(
x
)
=
L
1
+
e
−
k
...
thankyou
But I think not going with something like a hyperbolic tangent may possibly work because I'm trying to measure the output for where a bomb may be using a kernel and then getting the values for that and crunching them and based on whether where the data is going a positive one will go up and negative one would go down on the y-axis my apologies
I managed to get such a function to work working my apologies
you can see how the generated captions are starting to match the processed ones. well the first one, but im starting to see paterns like that. still hammering down the hyperparameters but i think the sweet spot area seems to be 5e-5 for the the weight decayy I got to play with more.

hows your project going?
I managed to figure out what mathematical formula I need to make it so that it can go up and down or just stay in the area that it needs to other than that nothing now I don't know if I should make a for a loop for every 5 seconds take a screenshot in the game or take one every two seconds so that I can learn fast from the images giving it computer vision almost sorry
probably the latter. guess it depends what exactly you want to achieve.
DND? lol
hyperbolic tangent that's why I need because a negative number to the neural network when men going down well I would mean going up and zero and mean stay where it is sorry
I thought I copied the formula I needed to explain my apologies
i see it
Now I have to make some statements and have to figure out what I need to do to give it a crude form of computer vision taking quick screenshots converting them into arrays then quickly jump to the next one a second later my apologies
i was wondering what kind of game it was or if it was for a pre exisiting game you wanted it to learn from?
What I need an if max argument an a min argument to adjust the AI_paddles position
Pong I made from a tutorial
nice
I have to figure out how to get the network up and running and want to use a pre-trained model but that feels like I'm cheating plus I don't get any understanding out of it sorry
Any ideas of how I can make it so that can go up and down with the paddle with if statements sorry
maybe try rephrasing what you want to say using AI first and paste it, its hard to make out what you want exactly.
YUP!
u wanna see my Pong game?
I made that with custom environment to train
not the one that Gym provides
i wanna see it.
I made one for assault game, though it didnt run very well as it was going through cpu.
lol they got ya. nice man. Ive been messing around with that CTF game, its almost done. but I wanted to try something else.
320k episodes. How long did that take?
bruhh, that's fairytale now
you have good GPU come on, you don't have to worry about this
I still do. lol

which GPU u have?
4090
what have you been working on lately?
was studying about GAN
i want to make an AI driven MUD game, where AI acts as a dynamic dungeon master controlling the world, creating real-time interactions, and generating ASCII art for environments and characters. I think with all the tools and content already out there you can probably use a lot of templates or make the art using a GAN or something. seems like a lot of work though lol
does anyone know when I "Run & Save All" in kaggle, and my GPU time exceeds, are my output files that I created till then still saved?
Guys after finishing my Bachelor's degree,what should I pursue ,MS or Mtech in data science?
Someone help me
what do you wanna do after and what kind of job are you aiming for? the main difference is usually that an msc is more theory and research based
I'm aiming to become a data scientist or an AI ML Engineer
but doing research and developing your own methods, or applying what's out there?
Idk honestly 😐
But yeah I'll try to develop my new methods
you're gonna have to figure that out, since that's the key difference
it only saves for session I guess!
HI
I'm working on the AI threshold to signal where to move when it detects in the ball or the players movement and take track of its own movement too sorry
need some help loading AWS S3 into a notebook environment for an ML project https://discord.com/channels/267624335836053506/1284184828379533444
For extracting information from images, is resnet a good choice
what info u need??, text ?? pixels like CNN do??
not quite, need to extract some text written on the image

Yes sorry fell asleep
nah, i cannot use these models, i want traditional ML model
what would you consider "traditional" ML?
Does anyone know anything about OCR for batches of webtoon images for each episode using tesseract. I already have a python script that runs fine but nothing is produced in terms of text extraction.
Idk where to ask this problem of mine.
Damn
something like basic models i mean
and why cant huggingface models be basic?
it sure can be, but I am not allowed to use, as per competition rules. I am doing this task as part of a competition
How would I implement a function that test if there's a negative number a positive number and a neutral number like zero sorry
ah, that explains it
i just got a good idea. I can use the sentence transformer to create new captions from the orginal captions right? Im thinking I can double my training data for the captions that way. What do you guys think?
Mayybe not, could not align with the pictures as much, but its worth testing
well,I started training after adding the CNN. So it turns the text embeddings into a pseudo-image like structure. This gets tied into the manifold autoencoder, creating a shared space between text and images. The CNN output is projected into the manifold then heads over to the attention module which refines that connection by focusing on the important parts.. hopefully this works out ill report back. i had to make a bunch of changes though
Ay is there anyone here who likes cryptography?
well this is the data sci channel, maybe more luck in #cybersecurity ?
Hi guys]
I have cnn model which augments the data
It is a cat -dog classifer
I have around 2002 images in train and 1000 images in validation
and the image data generator has a batch_size of 16
and when I train model
model.fit(train_generator,steps_per_epoch=125,epochs=4,validation_data=validation_generator,validation_steps=66)
Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least steps_per_epoch * epochs batches. You may need to use the .repeat() function when building your dataset.
self.gen.throw(typ, value, traceback)
It gives me this error
okay well if you have 2002 images in your training set and 16 images per batch, you can make 2002/16 == 125 batches. 125 steps per epoch * 4 is 500 batches you would need
weird that it wants steps * epoch though, you should be running through all the batches each epoch generally
Yea when i configured the steps to 30 and epochs as 4 , it gives the right output
30*4 is 120 batches for each iteration
Which is less than 125 batches as per 2002/16

I've been training ML models with my laptop GPU RTX 3050, I've been thinking if I wanna learn and solve any problems, is 1 hour training is enough before fine tune it or is there any aspects that I need to look out?
it would waste my time cuz I need to wait for 1 hour only then I can have some progress cuz I can't use my laptop since 100% GPU is in training
I wanna learn and solve any problems
what does that mean
is 1 hour training is enough before fine tune
training what, fine tuning what
anyone here like do the study in deep regarding kernel trick?
if does , i wan to know the resources you're using
https://paste.pythondiscord.com/YMHA
this is something basic i've come up with
needs some cleanup i guess but it's a start
discuss.python.org and #python on Libera
and of course a certain Discord server but we aren't allowed to discuss techniques for constructing that dataset 😉
Can you tell md the discord server name in private?
||it's this one||
May I ask a question
Nope.
(jokes aside, you don't need to ask for permission to ask a question)
Is it possible to get screenshots from pie game to put into on your own network so that I can try to teach my neural network sorry
teach your network to do what exactly
also I'm not sure what pie game is
Pygame and to play pong
Sorry stt never works
Hello, im implementing Attention Is All You Need paper with pytorch from scratch. And i would like to test it by training it using multi30k dataset. The model is training (the loss decrease) but when comes to inference it just repeating the same word
If you mind you can see my implementation here. I also try to use the transformer class from pytorch to compare it. And it acts like my own implementation https://colab.research.google.com/drive/1DOGUufRoZjynd2Te2tc7R1_qBBrOCn_v?usp=sharing

wait we aren't? why?
is there some type of competition going on?
from gym.wrappers import GrayScaleObservation
# Import Vectorization Wrappers
from stable_baselines3.common.vec_env import VecFrameStack, DummyVecEnv
# Import Matplotlib to show the impact of frame stacking
from matplotlib import pyplot as plt
# 1. Create the base environment
env = gym_super_mario_bros.make('SuperMarioBros-v0')
# 2. Simplify the controls
env = JoypadSpace(env, SIMPLE_MOVEMENT)
# 3. Grayscale
env = GrayScaleObservation(env, keep_dim=True)
# 4. Wrap inside the Dummy Environment
env = DummyVecEnv([lambda: env])
# 5. Stack the frames
env = VecFrameStack(env, 4, channels_order='last')
JoypadSpace.reset = lambda self, **kwargs: self.env.reset(**kwargs)
# Reset the environment to get the initial state
state = env.reset()
# Take a step in the environment (action 5)
state, reward, done, info = env.step([5])
# Plot the state (4 stacked grayscale frames)
plt.figure(figsize=(20, 16))
for idx in range(state.shape[3]):
plt.subplot(1, 4, idx + 1)
plt.imshow(state[0][:, :, idx], cmap='gray')
plt.show() ``` The joypad wasn't resetting so I put that one liner of joypad reset now it has too many values to unpackI found this.

Ok , i tested it, i think the latest version of gym returns obs, info from the env.rest()
TypeError: JoypadSpace.reset() got an unexpected keyword argument 'seed'
So what do you think I should do?
downgrade versions?
Is aw that line too but idk where to put it
going to try uninstalling
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
from gym.wrappers import GrayScaleObservation, FrameStack
import numpy as np
import matplotlib.pyplot as plt
Ensure gym_super_mario_bros is imported before creating the environment
import gym_super_mario_bros
1. Create the base environment
env = gym_super_mario_bros.make('SuperMarioBros-v0')
2. Simplify the controls
env = JoypadSpace(env, SIMPLE_MOVEMENT)
3. Grayscale
env = GrayScaleObservation(env, keep_dim=True)
4. Stack the frames
env = FrameStack(env, 4)
JoypadSpace.reset = lambda self, **kwargs: self.env.reset(**kwargs)
Reset the environment to get the initial state
state = env.reset()
Take a step in the environment (action 5)
state, reward, done, info = env.step(5)
Convert LazyFrames to numpy array
state_array = np.array(state)
Print the shape of the state array
print("State array shape:", state_array.shape)
Plot the state (4 stacked grayscale frames)
plt.figure(figsize=(20, 16))
for idx in range(state_array.shape[0]): # Changed from state_array.shape[2]
plt.subplot(1, 4, idx + 1)
plt.imshow(state_array[idx], cmap='gray')
plt.title(f"Frame {idx+1}")
plt.axis('off')
plt.tight_layout()
plt.show()
Close the environment
env.close()
i installed this pip install gymnasium gym-super-mario-bros stable-baselines3[extra] shimmy seems like it working now. i think it was a verison error.
Just about any reasonable technique for assembling a corpus of data from this server would probably violate server rules to discuss in detail
I mean you can say self botting without explaining how to and it's fine right
this is a very specific corpus of data which should be able to be gathered within server rules as the entire thing is open source i'd think
Ty
I will try it when I get back home
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
But how can I make it work on our own network thinks of its panel being in the right space or not in the right space how can I implemented going up and down or staying the same sorry
what was the error?
did it say what packages are holding the install up?
C:\Users\AppData\Local\Temp\pip-build-env-1x9xfcg4\overlay\Lib\site-packages\setuptools
_distutils\dist.py:261: UserWarning: Unknown distribution option: 'tests_require'
maybe try python -m pip install --upgrade pip setuptools
you might need to try to build a new env? i got it working using python 3.11
why env?? on windows?
ohh haha i didnt notice that
yea its ok guys I'm going to work on somthing else I'm losing my mind on it lol
advice if I want to do this without using a tutorial?
because these tutorials are making me lose my mind
dude this generated caption cracked me up Generated Output IDs Shape: torch.Size([1, 17]) Decoded Caption: ["a polar bear is seen in this image taken from nasa's curiosity spacecraft"]
ya the tutorrial wasnt very helpful. i got it workingn with those packages on python 3.11. I'd try to make a new env with 3.11 and install what i pasted above try again

python 3.11 got it
I'm getting more erroes now
OverflowError: Python integer 1024 out of bounds for uint8
Do you know what the error message means
I'm assuming that the integer is to large for something
I' don't really under stand though
# Import the game
import gym_super_mario_bros
# Import the Joypad wrapper
from nes_py.wrappers import JoypadSpace
# Import the SIMPLIFIED controls
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
env = gym_super_mario_bros.make('SuperMarioBros-v0')
the only change was python version
I see the problem incompatible libraries
you got it working? cool beans
OverflowError: Python integer 1024 out of bounds for uint8
ML/RL is my nemesis
It works when I switch python versions
i thought as much
you're a genius plunder, I cry when I think about how muych time I've spent just trying to ge through tutorials and falling into a myriad of problems
no worries man! i know the feeling
should |I keep changing python versions?
ive been pretty happy with 3.11 i cant remember why i switched to it, i found it really compatible though
so you don't know how to fix "Python integer 1024 out of bounds for uint8"
uint8 only hold 0 to 255 1024 is too large for it.
im looking on stackoverflow, but thats what It seems like
try uint16?
It's ok I'm just going to give up on coding
It always makes me mad and I end up wasting hours trying to fix a problem
Just going to focus on the coding that I absolutely need
man, polars is just insane, im seeing 10x to 20x improvements in some dags just by rewriting the pandas part in polars
and the api is so well written
I had to google it never even heard of it. https://pola.rs/

DataFrames for the new era
do you have the old pandas code and the polars you wrote to replace it so we could see the difference? I'm interested
all work stuff so not really, but there's this snippet where im consolidating and unpivotring around 7k csv files into a single dataframe
Pandas takes around 25mins, polars takes 2mins flat
I found this,. https://www.linkedin.com/pulse/polars-vs-pandas-benchmarking-performances-beyond-l6svf

by Arlind Avdullahi Introduction If you have ever done any kind of experimenting in data science, you must have heard of Pandas. To quote the corresponding Github documentation, Pandas is a “Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures simi
keep in mind polars has a purpose built method for bulk csv reading while pandas doesnt (u have to iterate over the files)
but other methods are still way ahead, the unpivot method on lazyframes is just unbeatable
This benchmark misses the point about Pandas having an arrow backend option. I'd be curious how these results would compare when using the arrow backend to pandas, such as https://pandas.pydata.org/docs/user_guide/pyarrow.html#i-o-reading
My expectations of a library performance benchmark posted on LinkedIn are not high
Because it use all your pc cores
Pandas use one core max
Pandas is fast considering this and written in C, polars is written in Rust, note that you can use similar to pandas syntax and use more ressources with dask, also pyspark but not the same syntax and not the same setup
The performance gain is for other reasons too. It creates a compute graph that it executes in one go. Unlike Numpy where you need to do one operation on the whole array, then the next (looping over it all multiple times). There is no performance difference between C and Rust, when they are both compiling with LLVM (LLVM with different makeup on).
are you talking about pandas for string operations, or pandas in general?
It also can use more than one cpu core lol
general
that's not true. pandas wraps numpy for numeric computations.
And?
so it's using more than one core for those computations.
No.
source?
There are litteraly libraries built to reuse pandas syntax but using multiple cores, man idk 2s google search it's like that
In [1]: a, b = np.random.random((10_000, 10_000)), np.random.random((10_000, 10_000))
In [7]: %timeit a + b
215 ms ± 6.49 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [8]: d1, d2 = pd.DataFrame(a), pd.DataFrame(b)
In [9]: %timeit d1 + d2
214 ms ± 1.85 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
One does not :simply use Google 
man this thing is really coming together. I just started training and its learning quickly. i got the learning rate pegged down but the number of beams and the temperature of the captions needs fine tuning

Data processing/operations
just use numpy
numpy is specifically for math, whereas numpy is for tabular data manipulation in general.
oh ok
it's less practical for dataframes
who knew applying convolution layers to token embeddings would work lol
Numpy can use more than one thread in its linear algebra library used, but it may require some configuration and depends on which build of numpy you have installed.
But this is not an optimal way to do threading, still better than no threads in many cases.
so far so good, the rogue score should start going up with more training. i feel like this is the one ! its kinda dark the reconstruction but it should lighten up and fill in next few epochs.


Not sure what your machine is, but this is about single threaded performance on mine. Can you try messing around with the thread count?
There is very little on documentation on how to make Numpy do this.
But you can try: https://github.com/joblib/threadpoolctl
GitHub
Python helpers to limit the number of threads used in native libraries that handle their own internal threadpool (BLAS and OpenMP implementations) - joblib/threadpoolctl
python -m threadpoolctl -i numpy should tell you what you need to know about which version of Numpy you have.
https://docs.python.org/3/library/concurrent.futures.html
could that work?

Python documentation
Source code: Lib/concurrent/futures/thread.py and Lib/concurrent/futures/process.py The concurrent.futures module provides a high-level interface for asynchronously executing callables. The asynchr...
I would like to see this too, my guess is that arrow does threading by default more so than Numpy.
well I just googled the first benchmark i saw, you guys can dig deeper into it
I know that it's faster although the way it's advertised is nonsense, such as: "Compared to pandas, it can achieve more than 30x performance gains."
Like 30x is pretty specific and yeah, I can get 1000x or more with enough threads vs single threaded. Thats how adding more threads works.
What you really want here is information how well it makes use of the threads.
(Also it being in Rust is irrelevant, but Rust people have to mention it)
Right.. I did see that it is abit misleading. I've never even heard of it until today. I do see people throw it around a lot for its performance.
Not just throwing something like "30x" out there makes it a hard sell, which is why they do it.
does the most recent pandas version have multi-threading?
Numpy and such always did, but with configuration / and depends on which backend your Numpy is using. It's also not an optimal approach to multithreading.
Arrow backend seems to as well, but it seems easier to configure.
if they are using an arrow backend now, it should be, I think
pandas didn't come with an out-of-box multithreading config, though
I don't think it's entirely misleading making the comparison if, by default, most people use pandas as single-threaded, it's on the pandas team to make multithreading happen
that being said, I think that the advantages of polars are much more concentrated on the lazyframes
The issue is a specific number, like 30x.
yeah, if they don't give you the machine that they have used for the benchmarks, it's problematic
If it's the world greatest super computer, 30x would be pretty bad.
yup
A scaling graph with a specific CPU and the thread count would be more interesting.
Can even config pandas to multithread to give it a more fair chance.
it would be a more honest benchmark
that being said, I still think polars would beat pandas
Probably, yeah.
it's hard to beat their lazyframe implementation, since it can optimize the whole chain of operations
Yes, that is one of the main differences. Numpy can only multithread within an operation.
It can't combine them into one.
Even without mutliple threads, this means Numpy has a larger constant factor.
a + b + c with 3 vectors can be done in a single loop, but Numpy needs to do 2 loops over the whole thing.
Each operation is indepedent.
this one seems interesting too

Dask is a flexible open-source Python library for parallel computing maintained by OSS contributors across dozens of companies including Anaconda, Coiled, SaturnCloud, and nvidia.
How can I get an output like -1, 1 and 0, from my network network sorry
tanh activation
that will bound it between -1 and 1
if you need it to be exactly one of those 3 you can just round outputs or something
thank you
Sorry speech to text never works how I needed to
Is there a way in quickly capturing and image turning it into an array then dropping that image
Into the network and delete the screenshot sorry
I'm not sure what you mean by turning it into an eye
does anyone know how I'd make an in-depth book summarizer
Taking a screenshot on the game itself then converting it into an array then taking that away putting it through output then putting it through the tahan definition thinking the output of tahan definition to see if it gets on 1, 0 -1
You'd probably use an RAG for this, depends on exactly what your goals and resources looked like
well sure but maybe you want to prioritize the speed of semantic search in the text embeddings because you want the user to ask specific questions about the book live. Or maybe you don't care because you will archive the outputs of the model and basically use it to create sparknotes pages idk.
hmm what I was thinking was there is a built-in (generic) summarizer: say gets the 5 most important ideas from each chapter. But then the user can ask it specific questions too (interact with it)
yeah a general RAG with a regular old dense KNN search algorithm would work for something like that
Can you expand
Agentic rag, regular rag, etc. and why not just feed it into long context windowv
because a model with a large context window would probably be a lot more compute to use, and be more likely to hallucinate or become incoherent. Plus an RAG doesn't have a theoretical context limit for having relevant information in the context unlike the other option, so if a person was asking questions to the model there would be no point where the model can't reference the source material anymore.
but those are pretty minor reasons in the scope of things, if you have the resources to try both and you're doing this to make a product or something you should definitely try both
I haven't heard of agentic rag I just meant a regular one 
Ok my concern is accuracy in terms of rag vs long context window
An RAG is more likely to be accurate assuming it has a good search algorithm, because it will be fed less information at a time which is more relevant to the prompt, making it easier to accurately use relevant vocabulary and stay on topic. https://arxiv.org/pdf/2403.10446
Our research underscores the efficacy of leverag-
ing RAG systems and curated datasets to mitigate
the limitations of LLMs, particularly in terms of
factual accuracy and hallucination. The ablation
studies also indicate the necessity of finetuning the
embedding model, and the limitations of finetuning
the large generative model with small and biased
datasets
you can make something for the memory, I made custom classes for mine, but there are some already out there
this is what i use ```class ConversationMemory:
def init(self):
self.memory_store = {}
def load(self, user_id):
return self.memory_store.get(user_id, {"context": [], "documents": [], "query": ""})
def save(self, user_id, context, documents=None, query=None):
self.memory_store[user_id] = {
"context": context,
"documents": documents if documents else [],
"query": query if query else ""
}
class ConversationSummaryMemory:
def init(
self,
prompt_node: PromptNode,
document_store: ElasticsearchDocumentStore,
retriever: MultiModalRetriever,
max_summary_length: int = 200,
):
self.prompt_node = prompt_node
self.document_store = document_store
self.retriever = retriever
self.conversation_summaries = {}
self.max_summary_length = max_summary_length
def load(self, user_id):
summary = self.conversation_summaries.get(user_id)
return copy.deepcopy(summary) if summary else {"history": [], "summary": "", "documents": [], "query": ""}
def save(self, user_id, context, documents, query):
if not isinstance(context, list) or not all(isinstance(exchange, dict) for exchange in context):
logging.error(f"Invalid context format for user_id {user_id}")
return
self.conversation_summaries[user_id] = {
"history": context,
"documents": documents,
"query": query,
}
self._update_summary(user_id, context)
def _update_summary(self, user_id, context):
transcript = "\n".join(f"{exchange['role']}: {exchange['content']}" for exchange in context)
summary = self._generate_summary(transcript)
self.conversation_summaries[user_id]["summary"] = summary
def _generate_summary(self, transcript):
if not transcript.strip():
return "No summary available."
try:
# Generate summary using the prompt node
prompt_template_text = "Summarize the following conversation:\n\n{transcript}\n\nSummary:"
prompt_template = PromptTemplate(prompt_text=prompt_template_text)
prompt = prompt_template.fill(transcript=transcript)
result, _ = self.prompt_node.run(prompt=prompt)
if result and 'documents' in result and result['documents']:
return result['documents'][0].content
else:
logging.warning("Unexpected response format from PromptNode.")
return "Summary generation failed."
except Exception as e:
logging.error(f"Error generating summary: {e}")
return "Summary generation failed."```
I had to build the conversationDB, but i just built it straight into elasticsearch
i recommened haystack and elasticsearch, they got really well made docs
Elastic search is for hybrid retrieval and haystack is for?
Will check it out ty 🙂
ya no worries, i just started messing around with mine again today. i built a front end for it with flask but it looks like crap i need html with latex rendering
What do you guys think so far?


that's the best output I've seen you post so far nice
what's the goal for your autoencoder(?)
honestly, i havent thought to much about it but i feel like can open some doors though. image compression. I spent so much time getting it to work i really havent given it much thought
somewhere around 294
512 is the lowest i can really go on latent space, i mean without sacrificing the quality from the clip model
i'm looking for a dataset of basketball ball to recognozite it (in hand)
also what can be problematic is that polars use all available cores by default, you can set POLARS_MAX_THREADS env variable but not recommanded
one million threads 
used smthing like 32 threads in my internship company 
Not just that, pandas doesn’t not have a bulk csv reading method, it can’t easily push operations to the reading operation, it also executes everything eagerly so no query optimization
As you said it’s technically fast, but to me polars is superior for many reasons, one of them being its speed but also the clarity of the api
I have a pipeline that takes around 7k csv files and consolidates and unpivots them into a data frame, polars does it in 2 mins while pandas takes around 20 mins (both tests on my local machine)
polars syntax is kinda cool too
It comes from pyspark and spark
when it can be too verbose with pandas
Pandas can be less verbose at times, depends on what the task is. Although Polars does a nice job with the syntax overall and I think it's very popular with people who come from a "programming" background rather than a "stats" background. Pandas by contrast is inspired by R data frames.
Problem is that spark is kinda overkill for many applications, while you technically don’t need a cluster to run spark jobs, the overhead of spinning up spark on a single machine outweighs the speed improvements over pandas by a lot
Right, Spark also has a lot of other problems. Dask is more like "Spark but less complicated" if you want that, but faster core libraries like Polars and Duckdb make that less necessary
I'm looking for association rules lib in python mlextend or other, is there some arules eqivalent from R?
Polars is also much faster but likely not very significant for most use cases
I’ve never tried duckdb, how is it ? How is it different than pandas
fwiw, I do enjoy how R handles tabular data.
Yea tbf some of our pipelines could literally take hours instead of minutes and we wouldn’t really care
Maintainability is a lot more important
Which open source ML model works best for logo detection?. It'd be great if it can detect the brand archetype
YOLO , but I think it cannot detect brand archetype.
It's more like sqlite: it uses a database file (or an in-memory database), and the interface is SQL
Hi everyone, I already tried everywhere but apparently i have no luck. I started with algo trading and crypto a few years ago, now I moved on the stock market. i am using backtrader as core library to build a backtesting system. Has to be said, im not a developer but i have python rudimentals. Now i implemented a basic genetic algorithm for hyperoptimization of parameters and I'm looking for fellow students/practitioners that have a similar goal so we can join forces, exchange ideas, help each other and collaborate. Whoever is interest let me know.

Hi guys I am trying the image data generator concept here
Could anyone explain as to why is the epoch 2 trained at 2secs?
while epoch 1 and 3 are trained at 36 secs
anyone know how to display plotly charts in pycharm
how are you trying to do it currently?
it looks like you just need to set the renderer to svg

Stack Overflow
I see the following renderers are available:
Default renderer: 'browser'
Available renderers:
['plotly_mimetype', 'jupyterlab', 'nteract', 'vscode',
'notebook', 'notebook_conne...
hello everyone need some advice!
We are trying to build a real-time time series anomaly detection system. We receive sensor data via postgres sampled at 50ms (20 samples / sec). We fetch the data every 15s (300rows) and apply model inference on it using Netflix's Metaflow. Eventually the system becomes slow and the inference gets delayed (maybe due to metaflow artifact saving on disk etc..).
Wanted to know how the everyone approaches real-time time series data processing and inference, and what stack y'all use.
What we use: data ingestion: postgres, inference (15 small models parallel): metaflow, influxDB: time series storage.
The models we use: PCA, LSTM (seq_len=300)
libraries: numpy, pandas, sklearn, torch
I was trying to do it for visualizing optuna but turns out optuna has its own dedicated dashboard. which is incredible
What kind of model are you using? It sounds like like your time budget is on the order of a few seconds, that should be plenty for any any traditional statistics/forecasting algorithm + fastapi or some other simple web framework
I don't have experience with Metaflow though, I assume it offers more functionality than you could reasonably build and maintain DIY
We aren't forecasting, we just use PCA and LSTM as autoencoders for anomaly detection.
And have you actually benchmarked your pipeline to see where the slow parts are? Do you have some kind of observability tool, or at least log for each step with timestamps?
Are you unable to reproduce the performance degradation running locally or in a staging env with simulated load/data?
We did, all seems fine and expected at the start but eventually slows down. Need to check which part slows down eventually
We'd be able to reproduce that yes during development
Ok, so it seems like a Metaflow problem specifically then? Maybe you can turn on detailed logs for Metaflow and see what's happening
Yes seems so. Metaflow saves artifact for every run it creates. We delete them every 15mins and yet it seems that it's unable to keep up
Yeah but why would saving artifacts cause progressive slowdown? Seems suspicious unless Metaflow is doing something very odd
Where are you saving them? Is it a rapid dropoff in performance or a gradual decline? How bad does it get? What fixes it?
What are the artifacts -- model predictions?
Not really sure. Earlier we had same issue when data was at 1s sample rate. We started deleting the artifacts and the problem was solved
hello not sure if this is Right place to ask this, there's a lot of channels , but
i have been looking for some kind of low overhead language model that I can give my own dataset to, or just any kind of text transformer, anything that is trained on dataset and can then give a text response to text
i Found one named textgenrnn but it seems to be outdated enough to be Kinda broken, and so far I can't seem to find any alternatives for some reason
Thanks in advance !
Any parameters assigned with self keyword in the run gets saved per step includes the dataframe as well
Google's language model apparently has a huge context window, big enough for multiple books I think. Or are you asking about fine-tuning a model?
Is that Metaflow functionality or your custom code?
Metaflow's functionality and can't turn it off
Are those instance attributes themselves increasingly large? Eg if it's saving its own run history somehow
Honestly for our use case python's standard 'multiprocessing/concurrent.futures' seems good enough (15 parallel model inferences)
No they're individual
How does this work? You write a class describing how to run the model, and the Metaflow runtime runs it? Are you self hosting or using a hosted service?
Can you reproduce with a dummy class that always outputs the same prediction?
i should have mentioned that I wanted it to be local, all of google's appear to be cloud-based only
We fetch 15s data from postgres. Save it to disk. Invoke metaflow on that file and it runs the inference. Repeat.
Metaflow code needs to be separate file so we either use subprocess / metaflow runner to do it
I see. You're going to have to do some debugging and trying to rule out components
Memray might be worth using to take a look at runtime memory behavior, as would pystack. I'd be curious what a profile shows between the degrading runs and the non degrading runs you mention later.
If anyone wants an ai that plays snake game super well then here is the code for that, just run it and the ai will play the snake game for itself:
and does anyone know any ways to make the snake "smarter"
woops wrong message.
https://eval.ai/web/challenges/challenge-page/2347/evaluation
i feel like the assignment university gave us for an intorductory a.i. course is a little difficult

EvalAI
EvalAI is an open-source web platform for organizing and participating in challenges to push the state of the art on AI tasks.
this is the lowest loss ive gotten so far. I feel like somethings wrong lol

If you can easily swap it out with something a lot more simple, I would try that. If the problem is gone then you know at least which part is causing the issue. I would also stick to the simple solution (if it's working) until you need something more complex.
Otherwise it's like premature optimization, except in this case premature scaling.
i was thinking of creating a memory module for the vqvae so it could store and recall patterns or embeddings over time. i was thinking of like a memory bank that stores the latent embeddings after quantization and occasionally update them based on similarity or something. also after each caption generation, i can feed them back into the model with the image and have the system try to adjust the embeddings or the projection layers based on those divergence between the captions and orginal image
If it ain’t broke 🤷
https://discord.com/channels/267624335836053506/1284056857346048020 can someone help me..
I’m trying to clean a data but I end up getting a 1406 error “data too long for column”
Does anyone know how can I fix this?
Btw I already tried few solutions which is switching my sqlmode to not use strict
Also tried changing varchar to Text and even longtext but I still get the same error.
Any idea how can I fix this?
May I ask a question on an experiment people have probably tried sorry
just shoot it from the hip, you don't need to ask permission or apologize. whats the question?
Has anyone tried making networks that can talk to other networks trained on different data to see if there's any differences and how they treat each other in a way
And talk about the ideas or the data that they were trained on ethics one trained on. Good ethics and one trained on poor ethics to see if they can come to agreement because people train their networks in 3D simulations how to fight walk etc but have we ever thought of making no one that works that can debate against each other on which data is more accurate sorry
My apologies
Append words to a document and 'talk' back and forth
of course people have made models and put them against each other for a conversation/discussion
There really isn't that much to it, you initiate a conversation and then just put the output of one model as the input to the other model and then get its output and feed it back to the first and so on and so forth
I suppose so, but GANs sort of do it as part of a training process
Transformers and Multimodal networks can be CNN architecture that causes two 'conversations' or lines of thought that will then be decided between for optimal output.
There's also Dual-Channel CNNs, so if you specifically want that self-arugementative architecture there are 5 base models of CNNs that you could use.
I was wondering because there's many different types of neural networks I was wondering sorry
Don't be sorry. It's good to ask questions.
This is a very rough and lengthy explanation of a Dual-Channel CNN, but essentially it functions as described.
they just do be like that, dw
For those people who've made a game playing ai's what do I need to do to get it so that my neural network can start sorry
You want to begin work on a neural network- you need to decide what you want it to do. It's formulation will follow its' function. Essentially follow instructions until you cen debug it enough to train it, then when it's trained up, you double check that it does the thing you want it to do. You want the time and energy and freedom to break your code many times in a row.
Does that answer your question? If you're asking about designing a game engine maybe this isn't the best server to ask
No getting it to see the game screen and making a guess my apologies
Oh ok
so making an AI trained on a game- like they have with YOLO cv trained on GTA, stuff like that?
I have no experience with that; it looks cool
Pong I made
I'm trying to get it so that I can capture the screen so that it can make a guess sorry
I would think it would be easier to get outputs directly from the game engine by modding something like Unity- than it would to train an AI based on what's going on, on your screen.... but I really don't know
I tried to look it up, but there isn't much there and screen-capturing tons of gameplay footage would just overload your HD before you could train on it
so Idk. Sorry
Probably it's done at large universities or studios where they have money for dedicated hardware. Would be my guess
But I'm not sure exactly what kinds
stationary camera perhaps
I'm sorry how did you get your AI to play in capture the flag my apologies @rich moth
im sorry newswsanky
I'm sorry
I'm sorry
Your not wrong!! But I like to experiment. I got the hierarchical memory and vq with caption learning now running now, the train time shot up like 2 hours but lets see what happens.

#===[imports]===#
import numpy as np
import matplotlib as MPL
from PIL import Image
#===============#
#
# grabs data to turn into an array
Image = mygrab
image_array = np.array()
X = image_array
W =#values list of lists
B = # data list
output = np.dot(X,W) + B
def move_paddle(output):
prediction = np.tanh(output)
move_paddle()
print(prediction)
am i on a good value my apoliges
its a multi agent system i made in pygame . im using RL and a Q-network with an attention mechanism
interesting.
Reinforcement Learning
sorry
It's okay 🙂
Now; it's important to remember reinforcement learning is always Supervised or Unsupervised- meaning someone watches it
what moduals would i need to create a RlQ-network?
in this case it would be supervised
im sorry
for STP? Pytorch should be sufficient,,
im using numpy for this
I'm trying to make a neural network that I can use reinforcement learning in the beginning let's say a hundred games in the beginning but then I can switch it into automatic which it takes what rounds I played against it and then puts anything that could see into the network itself sorry @severe hare
Please knock this off. The bot you're using is very annoying. You've been warned before.
hmm.. what kind of bot? im just curious. hes using a chat bot or something?
What bot?
why the hell you are saying "I am sorry" always??
don't mind of normal things first of all
so far so good! if you compare to the ones above it seems to be working well. im super excited about this verison. i almost lost my mind trying to get the shapes to match up.

I don't know who I might take off and I don't want I want to be ticked off
I guess, few weeks ago also you were doing this , saying weird things recurrently
like wrong spelling of apologies and sending recurrently
Whatever your intent, it has the opposite effect. It's not genuine since it's repeated often with no appropriate message, and is spammy, and makes it harder to engage with you. I assume it's a bot, but if it's genuine, just stop and engage normally.
Okay I'm sorry if it sounds this disgenuine it is genuine and just afraid that whenever I say might tick somebody off and I don't know I'm trying to minimize that type of loss
How can I get the image so that I can teach my network
these are perfect questions for like claude or chatgpt. use the free verison and tell them what you want to learn ask it to be your professor. you can gain lots of knowledge there and also watch some youtube videos on the matter. decided what you want to use and build the conceptual idea then start to write it. you need to google some resources for Reinforcement learning and other techniques
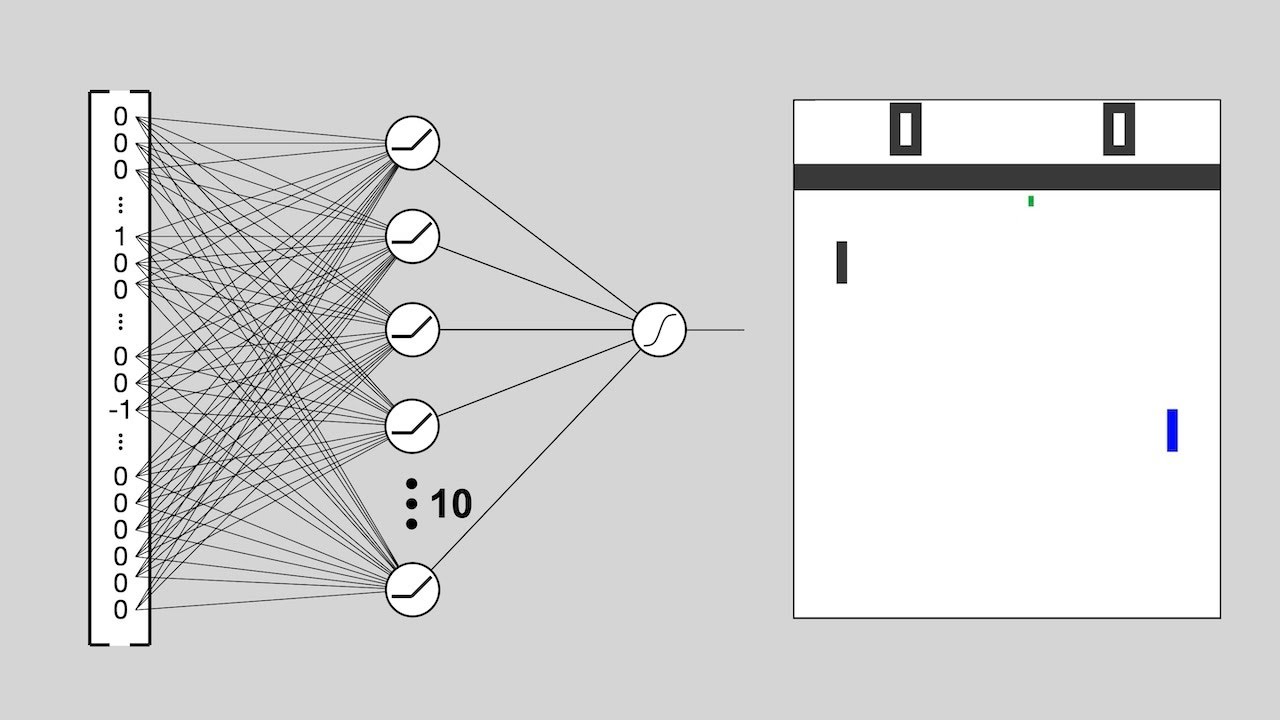
How does Reinforcement Learning work? A short cartoon that intuitively explains this amazing machine learning approach, and how it was used in AlphaGo and ChatGPT.
Part 1 of 3.
0:00 - intro
0:13 - pong
0:28 - the policy
0:51 - policy as neural network
1:32 - supervised learning
2:51 - reinforcement learning using policy gradient
4:24 - minimiz...
prediction = np.tanh(output)
move_paddle()

how do i call the def for the output
You have to 'return' prediction from the function
Thank you
I'm trying to get an image from the game subtract it from the previous image and then figure out where it is on the grid for the game now which is raking my brain
Could you open a. Help thread? #❓|how-to-get-help share your code
Done
I’m new to machine learning. I’m struggling on how to go about this project I’ve started. I collect NHL players stats of games for example a players shots. My question is how can I predict his next game how many shots he will take?
Is logistic regression a good idea to start with?
Before asking the question of which model... one thing to consider is: How would you evaluate if you have a good model or not?
What so you mean by a good model? As in do I have enough data? To be honest it’s not easy to predict the players next game due to a bunch of factors but also just the way they feel like playing that day. But from looking over my data someplayers have consistent shots while others don’t
let say you and I both trained models to predict # of shots per game. How would you decide which model is better?
If you're unfamiliar with this topic, I'd suggest going through this first: https://www.kaggle.com/learn/intro-to-machine-learning . It's short.
Sorry computer died. But will do!
fellow NHL fan here!
The captions keep repeating something to the effect of "a picture on a computer screen with shapes or something similar, which is technically not wrong, but the quality of the reconstructions really affect the quality of captions. However I let it go for a bit and the losses were decrasesing and the captions were changing slighty. I changed the learning rate gonna restart it again hopefully this corrects the image


see thats what they look like.

heres the captions of the 2nd epoch, lol

Hi!, I'm looking for a framework or library for information retrieval tasks that provides a dashboard. I want to process some URLs and I want something where I can paste an URL and then it adds it to a processing queue. Then, for each item, it performs some crawling, extracting and processing tasks, and displays the "documents" and its status in a web dashboard. Previously I've only used notebooks, is there any library to do all of these things (except the "processing" part, which I can do on my own), or do I have to combine multiple libraries? In that case, what would you recommend to the "queueing" and "storing" part?
Hey guys, I am trying to start my first ML project and I have NO IDEA where to start, does anyone have something like a youtube playlist or some sources I can look it to start getting a grip?
there's kaggle
Titanic, iris, house prices, car prices
Email spamm detection
Yea kaggle is great for beginner model building projects, try the titanic competition
Also has a rich library of datasets
when trying to scrape data from excel spreadsheets will macOS run into any complications that would not occur on windowsOS?
you don't really "scrape" from excel, since the data is already structured and on your computer.
you can open xlsx files with Python on either OS.
you know what that makes a lot more sense ty
Can I python neural network learn how to read and write in a way if you gave it your own made up language couldn't kind of emulate what I need a speaker at that language would write let's say left to right and right to left up to down
Well, I dunno... you don't see the Excel files I see... there's definitely a lot of scraping involved with the way they're formatted. 😢
oh. you're right, I treat excel files as CSVs with pages.
people who make "pretty" spreadsheets must suffer.
hii guys, do you guys help with R here?
We do not help with R here.
has anyone here have good experience with multivariate timeseries?
I've had lots of bad experiences :)... just ask the question plz
wondering what model I should use
for a project
where I have eegs
and I and doing mtsc
Maybe explain what you know, what you have, and what you're trying to do?
I don't deal with medical data, but I know other ppl here have.
from your experience what models
have worked best
I deal with financial data, and I'm more on the "data" side than "science" side.
ya just wondering in general
I hear rocket
is good
and also hivecotev2
and inception time needs a lot of data and time to be good
I don't think there's good general answers to questions like these. You mentioned EEGs: there's many papers talking about ML and EEGs. For instance (at random): https://pubmed.ncbi.nlm.nih.gov/32011262/. I'd start by looking at these to see what techniques have been used.
thx
working on implementing the random forest model to be trained with the nsl-kdd dataset -- any recommendations for resources/tutorials?
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Im working on my chat bot system and I'm trying to fine tune the module responsible for processing & embedding the data into the elasticsearch server. im trying to "clone" the datasets directly. if you guys wouldnt mind taking a look at it, let me know if you have any suggestions https://paste.pythondiscord.com/LWTQ
are there any general ideas I should know for time series?
is anyone is working on computer vision specifically on Video Inpainting and Object Removal?
i have a few questions
I am working on some projects to remove some captions and emojis.
i have some used some pretrained for removing captions but after removing it theres still some glitchy frames on it
anyone?
Hi, any ideas about deep learning models for language classification? Data is of 5-6 words, words are connected thematically, like below. I've experimented with classical models like rf, lr, etc. have given me around ~88% accuracy. When I tried out LSTM/bi-LSTM it only returned a ~30% accuracy, looking for direction/recommendations

- simpler is better
- traditional methods still work
- carefully consider your validation/testing procedure when forecasting
otherwise you pretty much need to figure out what works for your specific task
what is MTSC?
Hi guys, pls i need resource recommendations for Machine Learning
how does model learn from continuous value ?
i mean from what i can say regardless of what is the continuous value is there's must be smt like kind of pattern which caus of it
so bcuz of that im asking how does model learn from continuous value bcuz i thot that model perhaps learn another factor beyond than just a pattern

Well, are you sure you understand the math behind the model? Say our model is using gradient descent to find a minimum - you can imagine it as trying to find a minimum on a curve created by the loss and defined by our weights.
These are the two techniques you should be the most familiar with in order to be
successful in applied machine learning today: gradient boosting machines, for shallow-
learning problems; and deep learning, for perceptual problems. In technical terms,
this means you’ll need to be familiar with XGBoost and Keras—the two libraries that
currently dominate Kaggle competitions.
Is it still true?
XGBoost is definitely up there, sure
don't know about Keras, but nowadays pytorch is the go-to library for deep learning pretty much
Polars inntergrated with Nvidia Rapids now. https://pola.rs/posts/gpu-engine-release/
DataFrames for the new era
Multivariate time series classification
Huh, interesting. Practically speaking, I'm curious what kind of queries this would actually be useful for. Will be interesting to experiment with
for classification you really just need a way to reduce each time series to a vector embedding that you can dump into a classifier. there's probably a lot of literature on state-of-the-art ways to do this, but i'd be skeptical of things like pre-trained sequence models. that's very new tech and results seem mixed.
mhm I have gotten intresting reults from rocket based models
and also inceptiontime is another option
also this project is really for fun so I am fine with experimental methods
yeah, someting CNN based seems intuitive for "retroactively" classifying time series
i just looked up rocket, it seems like a nice methodology
random convolutional kernels are an interesting idea
ya I heard tcnn are good for these types of problems
is convolutional based
!pip aeon

A toolkit for machine learning from time series
Released on <t:1725732865:D>.
^
cool toolkit I have been using to simple test models
on my data
it is like scikitlearn
but for time series
aeon
binder Time Series Classification (TSC) involves training a model from a collection of time series (real valued, ordered, data) in order to predict a target variable. For example, we might want to ...
you might want to also look into Darts and Tslearn -- very similar ideas ("sklearn but for time series")
although Darts is much more about forecasting
ya aeon is a fork of sklearrn
with bangal
it doesn't look like a fork to me 🤔
because some political drama happened
aeon
Roles: The roles are described in aeon ’s governance document. A list of all contributors can be found here. Code of Conduct Workgroup: The code of conduct workgroup maintains the code of conduct a...
It is maintained by Tony Bagnall Matthew Middlehurst
who are apparently big names in this type of research
I have more of classification problem on my hand
I also have spectogram
data so might work with that
and make an ensemble
1 model for eeg
and 1 for spectogram

@desert oar just wondering what are your experiences been like with time series?
I haven't done time series classification since before deep learning was common for time series classification, so my experience is mostly "out of date"
ya the best deep learning option rn is inception time
if I had to do it now, I'd try something without deep learning as a baseline, then work up from there
but as with deep learning model it didn't perform that well on tiny data and had a kinda high training time
cnn based solutions
are really the forfront of ts
is deep learning quite of machine learning insprire from human brain rather than statictcal tool
no
Oh boy, at least they didn't name it -ce
The how to define deep learning
Python Game Development
Released on <t:1723463460:D>.
😭
Hi guys! I want to simply ask if anyone here had example of what I am about to post here below
I have a project to execute and I want to seek for your review below
!rule 6 9
6. Do not post unapproved advertising.
9. Do not offer or ask for paid work of any kind.
Im training a new custom model that combines BERT embeddings with a Tabtransformer for handling structured data . Im also using BYOL for self supervisted pre training. After the pre training im going fine tune it for classifcation on the AG news dataset using mixup and cutmix for regularzation . wish me luck!

As noted above, recruiting is not allowed on this server. Your post has been removed.
Okay
I am not recruiting . I was just randomly asking people's opinion if anyone has done stuff like this
Can you ask the question differently then? The last post was the job descriptions
Yeah, so a friend of mine who's running His PHD In Machine learning on Explainable AI in UK recommended me to his friend who needed help for his project
That's because I help my friend did the project In python last 6months ago.so he decided to bring this project for me if I can do it
You understand me now?
But what's your question?
Have done a lot with python including Federated Machine learning but I Judy felt like this project seems like a relatively new to me hence my asking of anyone here has done something similar based on the message iSent earlier
In summary, has anyone here done something like this before?
I'm not trying to be difficult but: Your question has no details. It's basically: "Has anyone done machine learning before?"
Which library should I use for making a chat-bot?
Depends on how sophisticated you want it to be and how much compute power you have.
It is for support and simple tasks only
what kind of tasks?
Like generating password and converting files etc.
So what library should I use?
you shouldn't need a chatbot for that
Then?
Does anyone know the best way to train a model / construct a model? I want to build an image model of trading cards for a sorting algorithm / machine I’m building. I plan to use a web cam that takes images from a fixed distance and I want my machine to be able to recognize the cards name and then use an api I have to get the rest of its data.

Have you tried it? The new version? I have the preview for it, but you can only use it like 5 times every couple days. I was stunned.
English in this context often involves proper reasoning right? Like making an essay and being able to provide arguments for your position
Currently GPT is not good at reasoning and it's not good at being consistent, so it probably fails on that account
I haven't kept up with the recent developments though, don't know how good o1 is
I haven’t tried the o1-preview yet but from what I heard they’re going to charge the o1 regular version 2000$ a month 💀
good luck with that lol
It uses chain-of-thought prompting from what I've heard, so it probably makes sense. You have to make many prompts for a single resulting prompt from what I understand
Probably very expensive to run
That’s like a month’s worth of rent
well, if it can get a job and pay some bills ill consider it
I don't think that's intended to be used by individuals at that pricepoint, it's intended to be used by businesses
Yeah I'm hoping this means there's more cool open source stuff coming out too. And people will probably focus more on making these models cheaper to run
relatable
I would think that it’ll be better at English since English is just well supporting your ideas with evidence and what not. Pretty simple stuff rather than physics and math which can be very difficult subjects.
How long should a "fast" fine-tuned mini BERT-like zero shot classification model take to label ~20k items?
is this on a GPU and what's the largest batch size you can do on that GPU
Anyone here who can give guidance and help in dsa
you're looking for #algos-and-data-structs. but remember to always ask your actual question--never ask if someone can answer a question that you haven't asked.
Hey everyone! I'm trying to get this simple - though large - VAE up and running. I've got the basics down I think, but obviously something is going wrong.
A few notes: the model is quite large - it's a work in progress but I've got big plans. Also, I know I've got an odd coding style, but I like it. Third, everything I know about ML I learned from ChatGTP and only over the last few weeks. Like I said, work in progress.
The problem: well, there's a few.
First, the model is running on my Macbook, but I'm getting a Cuda OOM error when trying to run on an A100 in the cloud (Colab).
Second, on the mac with a batch size of 2, the output images I'm generating have identical outputs for both images. Unless I'm pasting the images wrong, this means the model is outputting the same data for both images in the batch. I'm leaning towards the second because pasting an image isn't complicated, but also the outputs from the next batch are nearly identical. Slight variations off the batch previous. Correct me if I'm wrong but even an untrained, clogged and inefficient network should produce random outputs for random inputs, no?
I'm guessing the two problems are related somehow.
https://github.com/lucaswalkeryoung/multiencoded-latent-diffusion

GitHub
Contribute to lucaswalkeryoung/multiencoded-latent-diffusion development by creating an account on GitHub.
Halp Q.Q
Ahhh!! I did ! I finally got this thing running.

Hello guys !
I have 3 days to prepare for an interview, it will mostly be around Pandas and Numpy. I didn't use these two for like two years. If you were me, how would you train for these?
I thought about watching a big tutorial to refresh my memory, and then find some uni problems online and solve a bunch of them to practice, and then solve some more tricky problems on leetcode to avoid trap questions as much as I can (it's for a junior python dev position)
any other suggestions?
wow.. these are the best results I've got so far with all this experimenting


i added a mutli head latent attention to it and it increased the training of each epoch by 4 hours gotta love attention 😂 even without it like above in the images it seemed to be working really well, and much faster. ill let it run for awhile and see how it pans out. hopefully ill have some more results in the morning and nothing goes haywire. ive noticed with ther attention the captions are already getting better. Caption update - similarity: 0.19261378049850464 (below threshold).
Hey all!
I'm trying to get this very simple VAE online. It runs, but won't converge.
I'm doing this right, right? The problem is just hyperparameters?
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
What should I learn after OOP?
this is the data science channel; try asking in #python-discussion
Anyone got any ideas how to fix this? I made it through the training and eval phases but it failed the reconstructions. Also if you compare this one to the above you can see how the attention seems to really help the reconstructions of everything!



im super jazzed,
@rich moth it's easier for people to help you if you give all text as actual text. not as screenshots.
sounds good,, ill have to organize it a bit when i get back. maybe you guys can help
@spare forum Khan is a good source material for learning statistics?
I learned stats through college, idk
I did too but the class I took rely on calculator too much
I'm going to relearn it for a bit today and move on sql Tomorrow
I learned good old theory with good old pen and paper + practical work with R, python and SAS (Eww), don't know about the stats part of khan or something, I didn't search more on stats outside courses, what I searched outside college was more python, ml related
Hey, for an LSTM network,
- every node is for every independent feature/variable
2)every node has 3 gates- forget, input,output
3)with every input it computes the state, gets an output and feeds it back for the next input computation
is this correct?
Is there an important I need to separate sound into its basic components to be calculated sorry
what are the best free AI's now? I use llama
Llama 3.1 (or models fine tuned from it) are amongst the best open weights models for most tasks. What exactly are you looking for?
https://lmarena.ai/?leaderboard ranks a lot of models, both closed and open weights
tbh the only reason I can imagine not to use Llama at this point in time would be if you want a model smaller than their minimum size
have you checked out huggingface?
you guys wanna hear me new idea?
Sure, I like new ideas
a multimodal transformer that can handle text, image, video and continuous data , at the same time.
contrastive multimodal with modality dropout and crossmodality fusion
Im building the auto videoprocessor since i cant find a transformers one
have you seen https://github.com/apple/ml-4m and https://github.com/lyuchenyang/Macaw-LLM ?

GitHub
4M: Massively Multimodal Masked Modeling. Contribute to apple/ml-4m development by creating an account on GitHub.
GitHub
Macaw-LLM: Multi-Modal Language Modeling with Image, Video, Audio, and Text Integration - lyuchenyang/Macaw-LLM
no, those look interesting. thanks ill check it out.
I thinnk Im gonna use a video autoencoder with the contrastive learning setup. Im gonna try out the polars and rapids intergration for the dataframes and preprocessing and the modality dropout.
Have you tried them at all or heard anything?
haven't tried myself
their readmes + the resources linked from there contain everything I remember hearing about them and more
tbh I didn't see people have great sentiments about L3.1
in fact the more common opinion I see on it is it feels dumber than L3 and is harder to tune (maybe wait a couple o' months then it'll change)
on the other side, mistral models seem to have better community feedback
e.g. nemo 12b's very good, mistral large 123b can beat L3.1 405b, the recent mistral small 22b is apparently nice as well
oh and all recent models boast ridiculous context sizes, when the RULER benchmark disagrees with most of them

GitHub
This repo contains the source code for RULER: What’s the Real Context Size of Your Long-Context Language Models? - hsiehjackson/RULER
Hii Bro! Love to hear about operations research as a field/job opportunity!
Can’t tell you much about it. Check out LinkedIn
We have a few companies doing typical problems in my country and those around
Well I am pursuing master in operation research! i am from cs background!
Hmmm that's interesting given you're coming from CS background. Do you mind sharing what interests you in pursuing your graduate studies in operation research?
Idk much about the field myself. Usually it's only a few of friend with Maths, and Economics major that I've seen pursuing masters in Operation Research. I have another friend doing a dual program in Msc Collective Intelligence & Operation Research.
Hello, I was wondering why when I fit the MultiModalAutoEncoder implemented here https://hastebin.com/share/ocalenawix.python, the loss is the sum of the losses of the AutoEncoders instead of the average
The way the OR scene is here is that you have people working on the tools/products, both open source and closed source, and another group of people working with existing tools to solve problems for businesses.
I think you're a good fit for the former group, especially since you have a CS background. The solvers have tons of tricks to make them fast
The last OR course I did was in C++ and it was a nice mix of CS fundamentals and actual OR theory to implement the solvers. The very first course I did was the exact opposite. It was more about modelling the problems, the math (doing simplex and whatnot by hand). If we solved problems we ran them with Lindo. There was no coding 🙂
Anyone don't have Nvidia GPU? I'm making a gan and it's slow,any fix for this
If you don't have a GPU you can try with Google colab and when your credits are finished you can move to Kaggle
Zestar u have tried kaggle
Training nets with CPU is so slow it's never worth it
yes, why?
Ikr right so slow using CPU rn I'm tryna use kaggle we just need to change the accelerator right to GPU Nvidia t4 x2
But when I run in the top there's like a CPU bar and it's hot red and there 2 more GPU bar but it doesn't really use it it's like white not even green maybe I did something wrong?
Are you using Pytorch or Keras/Tensorflow?
Tf keras
Hmmm, it's been ages since I used that but the idea is the same. You need to ensure your tensors are on the GPU
So, you can check .device to see where that tensor (or your model) lives
Can you do that for a second?
Holon I'm bouta turn my PC on again
I assume you have a variable like model that is your GAN?
Cuz I alr spent like 40 mins
Wait
Oh dang it I just remember I deleted the whole code bruh
But what do we expect it to return?
It'll tell you if it's on /device:CPU or /device:GPU
Did you do it already?
Why is it slow? Are you training your model
Na it gave me an error
Just initialize it and do .device
Dang it bruh I delete my last code
model = Model()
model.device
Just this 🙂
Oh aight
Name error model is not defined
I think I need to make the gan model first no
I have no idea how your code etc. looks like
but in general, I think it's good to look at a basic keras tutorial because they'll cover this stuff and it won't take you longer than an hour or three
and it'll save you a lot of time in the long run
The .device part?
Everything
What are we expecting tho from it the amount of GPUs
Whether or not the tensor (or your model in general) is residing on CPU or GPU
And if what I said doesn't make sense, that reinforces the fact you probably need to read the docs a little bit. I could teach you, but me teaching you step by step isn't efficient for you or me 😄
I think ur correct
Also, it seems you're also not deep into Keras yet. I'd advise you to also just switch to Pytorch
Pytorch is way more used nowadays
Really
Aside from maintaining old things I don't think anyone is on Keras or Tensorflow nowadays
U use tf or pytorch
Tensorflow is where I started and I moved as well to Pytorch
So, that should be proof enough as well 😄
U work as a data seicentist
Yes, why?
Here's the Pytorch docs https://pytorch.org/tutorials/beginner/basics/intro.html
I see how u land a job do u extend ur intern
what do you mean?
Like how do u land a job is it from internship and then u got return offer or u just apply and do u put ur kaggle or just ur project when u apply for a position
I got my previous job by applying on LinkedIn. I got my current job because I did an internship there 3-4 years ago and I sent a messgae on LinkedIn asking them to hire me
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
I can't get this model to converge. I've tried everything I can think of. It can isolate the numbers fine, but can't seem to figure out the backgrounds. I've tried every combo of hyperparameters I can think of
And the model is pretty big compared to the scope of the task. I must be doing something wrong
MNIST
Yeah. And I apply both random horizonal and vertical flips just to keep things flexible
And - I'm doing it in RGB. This is a warmup exercise to get my sea-legs before moving on to more complex reconstruction
The following packages are causing the inconsistency:
- defaults/win-64::curl==8.7.1=he2ea4bf_0
- defaults/noarch::itemloaders==1.0.4=pyhd3eb1b0_1
- defaults/win-64::libxslt==1.1.37=h2bbff1b_1
- defaults/win-64::lxml==4.9.3=py311h09808a7_0
- defaults/win-64::parsel==1.6.0=py311haa95532_0
- defaults/noarch::pyls-spyder==0.4.0=pyhd3eb1b0_0
- defaults/win-64::python-lsp-black==1.2.1=py311haa95532_0
- defaults/win-64::python-lsp-server==1.7.2=py311haa95532_0
- defaults/win-64::qtwebkit==5.212=h2bbfb41_5
- defaults/win-64::s3fs==2023.4.0=py311haa95532_0
- defaults/win-64::scrapy==2.8.0=py311haa95532_0
- defaults/win-64::spyder==5.4.3=py311haa95532_1```
anyone faced this issue, how to resolve thisi was trying to update conda
Are you saying that subjectively the backgrounds in the autoencoder reconstruction don't look right? Or something else?
The error message says the problem: you have package conflicts. try listing all packages in an environment yaml file and recreating the environment from that
Yes? The system correctly recreates the digits as well as a small black border around it, but the rest of whatever isn't occupied by the number is just noise. It's like all the features/expressiveness the model has access to is being devoted to better expressing the digits, and the backgrounds are being ignored.
I tried switching up the loss to favor dark pixels, and that worked like you'd expect. It did start focusing more on the backgrounds, but at the cost of the digits which receded to indistinct clouds of grey.
I'm going to add an adversarial component. I'm expecting it will contribute the refocusing pressure that's required
Woah the one on the right is weird but cool
I figured it out. I was using view instead of reshape lol
geez the size of the model increased by 1.65GB. think i need to play with the learning rate a bit but let me train, that was on a batch of 8. im trying 16 now



im trying to hammer everything out before enabling the latent memory. i ran some test with and without the memory and it was worth keeping it, but its very computational as most is.
i wonder how much the quadratic complexities will add to the size of the file when I enable the memory 🤔
Yeah Mostly student here is also from math/stats background I like the curiculum and found this course pretty interesting and it's also related to data field. And i really enjoy this course!
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
I'm getting a vanishing gradient, pretty much right after the last few layers
It's a fairly deep network, compared to the problem anyway. I've initialized the weights using a smart initializer, but after the first epoch it always dies out. Any thoughts?
dang i just started the training Training Epoch 0/20: 24%|███▎ | 369/1551 [45:08<2:35:15, 7.88s/it, Loss=3.1, PSNR=16.1, SSIM=0.469, Epoch Progress=0/20] seems pretty high for just starting lol
try AdamW for the heck of it
You guys ever hear of a cross modal dynamic fusion transformer?
Q.Q
weirdly, a quick restart worked

It's not exploding gradient, that's something typical of RNNs.
Vanishing? Maybe, we'd have to see a reduction in the magnitude as you go to the first layers
It's safe to say though it isn't what it should be, though?
The Art of Designing a JSON: A Comprehensive Guide with Python

Medium
In the realm of data formats, JSON (JavaScript Object Notation) stands out like an artist’s brushstroke on a blank canvas. It’s not just…
Anybody here got a course recommendation for learning Python for data science for finance?
Depends where you're starting. Tell us more about where you're at?
I would also appreciate this!
Let’s say brand new. I know some concepts. Print, functions, some looping, lists. I’m starting from the beginning again though
I would start with a good Python tutorial and hang out in #python-discussion . Take your time and do small projects (ask there for ideas). One you can do small projects, check out Kaggle.com/learn and CS50 for AI, which will introduce some fundamental concepts. Keep doing small projects: don't rely on reading to learn.
suppose i have 2 duplicate rows in column A, both of em pointing to different values of other columns ,
so we dont need to remove them right
i want to know, in which scenario we have to remove duplicates
I don't understand, can you illustrate?
In general it safe to remove duplicates when every column in both rows has the same values. That is the default behavior of df.drop_duplicates()
for eg:
here in this ss u can see there is a column with many same values, but other column of same row are different. i wanted to know, in which case we remove duplicates
for ex, ik that if all the values are same and are occuring multiple times like shown in 2nd ss then we remove one of them but what are other possible scenarios


in short, i want to know all cases where we are good to remove duplicates
yes, that is the base case
but is there any other scenario as well where suppose the customer ID is same for both rows but 1 column of 1 row has minor difference, then what should we do
Oh, so you're wondering what to do if your natural key (ie; Pringle chips) is duplicated?
yes, u can say that
but what if other columns of that prod_name is different but natural key is same
In those cases, it's not a duplicate. You'd normally roll up the values using a groupby. Like, to get sum of sales of Pringle chips
ohhk thats what i did
but is there any way to group them in the csv file so that total rows of the file are reduced
but my concern is , not all columns can have same values
so idk if that would be possible in csv
But I think that it depend on what he want to use the data for
Do you not care about the other columns?
if it contains different data then obv
You're saying column A has the same value but columns B and C have different values. How do you want to handle columns B and C?
What can I do to promote better flow of information through a network aside from modifying it's structure? What sort sof prophylactic measures (great word) can I take?
Wdym by network here?
the main things in your control are pretty much
- defining the structure of the network
- determining which loss function and optimizer to use
- preparing the data
- changing hyper-parameters
You should check published papers to see what worked for researchers
besides that, make sure your data quality is good and make sure you're using sensible values for things like learning rate, batch size etc
@agile cobalt https://hastebin.com/share/akaqiqijix.py
You can disregard the debugging/plotting functions of course. I'm trying to implement a "basic" VAE to recreate MNIST digits. I use quotes because, while the problem is fairly simple, I'm trying to build it with all the bells and whistles because it's a prototype for a larger project. By bells and whistles I mean weight decay, dropout, regularization, that sorta stuff
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
I'm trying to get myself into the mindset of an AI scientist, which is why I asked my question. In debugging, I need to know what tools I actually have at my disposal, and, how I should act upon whatever information I undercover during debugging
Does anyone know why I can't get the json to load for the clip ViT B 32 model? Or perhaps how to force it?

I would appreciate it if you stop posting screenshots of large blobs of text. If you need help in connection to all of this text, please put it in a format that's easier to consume like the paste bin
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
you should also always provide the code that you're asking for help with.
please remember both of these things. you're welcome to ask for help here, but it needs to be done in a way that people can immediately jump into.
So, I've got some general questions
About AI
Earlier I asked about how to intervene when a model was misbehaving. Etrotta shared that there's really only three things you can control - architecture, data, and hyperparameters. My intuiting tells me that the last can help to a degree with procedural issues, but that structural issues require structural solutions. Data and training regiments fall in the middle.
Would you all say this sums it up? Anything to add?
when you say "structural issues require structural solutions", what is something that you would consider a "structural issue", and which of {architecture, data, hyperparameters} do you think is "structure"?
I truth, I barely have the bonafides to answer the question. Hence why I'm here. I guess it's true that one of the best ways to get answers on the internet is to say something incorrect.
I'm trying to build this VAE. I've tried every combination of hyper parameters I can think of. I've tried gradient clipped, weight decay, dropout, with normalization, without normalization, data augmentation this way and that - these measures hardly ever seem to have an effect.
My guess is because there's something just wrong with the model. I can't for the life of me figure out what though, because I've compared it to every example I can find online and done all the reading I can get my hands on. In theory, the machine is perfectly formed.
When investigating the issues I'm coming to see that piping the gradient through the machine is terribly fickle - or maybe I'm just really bad at this.
I dunno. I'm mostly just musing. I've been having a terrible time finding other humans to talk to about all this, so I'm just letting my thoughts out
saying "structural changes require structural solutions" sounds catchy, but it semantically overloads "structural".
when you're tuning the hyperparameters, make small changes to one at a time, so you can see how the performance of the system responds to that change. that way, you'll see when you're near the optimal value for each one. (This is also pretty much what the model is doing for each individual parameter in neural networks.)
but if hyperparameter tuning/optimization doesn't improve the model (or at least not sufficiently), then you would need to reevaluate if the model architecture is the right one, or if your data contains the signal that you want the model to pick up, or if you have enough data.
Hehe
haha
Well, specifically, all I'm trying to do is build a VAE that can recreate MNIST digits.
I must be doing something wrong, because I feel like it shouldn't be this hard
Though admitted, things got a lot better when I remembered to sigmoid the output back to between 0 and 1 god damnit
so the way it would work is you say "give me five some 7s", and it will output five images that an MNIST-trained classifier would recognize as 7s?
(and when I say "image", that could be whatever representation you'd like, including an array of pixel values)
Not a classifier
I know you're not making a classifier.
VAE. And I'm also randomly flipping and rotating the images so that there's a functionally infinite dataset. I don't think that should cause any major issue
Not sure what you're getting at then
I'm going to sign off, in either case. let me know if you make any progress.
everyone be good while I'm gone.


I would love to get it out of text blobs thats part of the issue. I want a console for it with latex, not its current format. I dont know how todo that.
remember that the creation of this emoji required the permission of the PSF
(iirc)
strange to me that more data nerds arn't night people
do you know of any good channels? for developing and coding? looking to colab with other people.
https://github.com/search?q=label%3A"good+first+issue"+label%3A"help+wanted"+language%3APython+state%3Aopen&type=issues&ref=advsearch was suggested to me @rich moth
GitHub
GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.


its a bit strange, ive tried 1e-4 to 7e-4 and the loss stays about the same but the other metrics seem to change a bit.


Hello guys , I Was workin on A diffusion Model For Generating Synthetic data and i have it locally , to improve its performance more and more , i wanna do Federated Learning . what should i do to in order to simulate lill of the Federated Learning Effect . (I never worked with federated Learning , so ill be glad if someone could give me the steps)
I think the author could have used a better name to denote "cumulative reward" 😳

I mean it's not that uncommon
e.g. we have np.cumsum
I see. Still, I think the wording for reward is a lot more vulgar somehow lol. Like, type cumulative or just put tot for total.
Or do whatever you want it doesn't really matter, more of a funny thing
maybe aggregate? though idk if there are subtle differences between that and cumulative
this is an ongoing thing, the numpy and scipy people are renaming the functions. in the image, they're replacing cum with cumulative to make it more explicit

they already removed "cumtrapz" and now it's just part of "integrate" as "cumulative trapezoid"
I don't understand what you're saying. If you need for people to read the text that is in your text blob screenshots, then please copy and paste that text into the paste bin.
And please also always share the code for whatever you're asking for help with.
I have this dataframe. Using python to manipulate and clean data that i web scraped. now i have a problem. as you can see the Fighter consistently has a name 'Max Holloway' and all the other columns has his correnponding data. I want to only get his side of data and delete his opponent i.e. the other name in the Fighter column. is there any way to this this without having to manually go through every single cell?

is it like regex?
Maybe you can filter your df for fighter columns where the name you said is inside that column? And then add a column with the name
df[df.Fighter.str.contains('Max Holloway')]
yes that is correct. but how would i get its corresponding data from other columns? for eg forst row the second set of ## of ## is the corresponding data, where as in second row the first set of ## of ## is the correnspnding data in each of the column
oh wait I see what you mean now
lemme think
I would maybe first split the information in fighter column. You can try "split" if format is always the same "name1 surname1 name2 surname2"
use .str.endswith() to make a new column that's either 'left' or 'right' (or just any binary value that could indicate left or right)
then use that column to decide which side of the info you should take
Split string with df.fighter.str.split(' ') first two entries are person A second two persona B
so make 2 seperate tables where max holloway is in right and in another is in left? and just loop it with split and combine those two tables?
anybody working with tensorflow & pytorch
Have before, just not right now, what's up
If the format of first column is fixed, split it and obtain two different columns. Then I would get two different df respect if max Holloway is in column in a or B and then put again them together
@severe hare i am confused i ma trying to be an ai engineer?
>>> import pandas as pd
>>> df = pd.DataFrame([['apple orange', 'orange apple'], ['2 5', '1 3']]).T
>>> df
0 1
0 apple orange 2 5
1 orange apple 1 3
>>> df['right'] = df[0].str.endswith('apple')
>>> df
0 1 right
0 apple orange 2 5 False
1 orange apple 1 3 True
>>> df2 = df[1].str.extract('(\d) (\d)')
>>> df2
0 1
0 2 5
1 1 3
>>> df2[1].where(df['right'], df2[0])
0 2
1 3
Ahhhhhhh. finally got the solution. ive been stuck on this part for the past 2 days
yes used similar logic and got it
how do i make a code block in here?
ill share it with you guys
```py
code
```
!paste if it's too long
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
def extract_max_holloway_stats(row):
# Check if Max Holloway is first or second in the 'Fighter' column
fighters = row['Fighter'].split(' ')
if fighters[0] == 'Max' and fighters[1] == 'Holloway':
# Max Holloway is first, so we take the first part of each stat
for column in ['Sig. Str.', 'Head', 'Body', 'Leg', 'Distance', 'Clinch', 'Ground']:
row[column] = row[column].split(' ')[0]+' '+row[column].split(' ')[1]+' '+ row[column].split(' ')[2] # Keep the first part (before the space)
else:
# Max Holloway is second, so we take the second part of each stat
for column in ['Sig. Str.','Head', 'Body', 'Leg', 'Distance', 'Clinch', 'Ground']:
row[column] = row[column].split(' ')[-3]+' '+row[column].split(' ')[-2]+' '+row[column].split(' ')[-1] # Keep the second part (after the space)
return row
# Apply the function to each row of the DataFrame
max_holloway_significant_strikes = max_holloway_significant_strikes.apply(extract_max_holloway_stats, axis=1)
the .apply function was what i was missing. it apparantly interates each row of a df independely into a function
.apply is not what you're missing as it's as slow as a normal for loop
also, use slices?
if ...:
row[column] = row[column].split(' ')[:3].str.join(' ')
else:
row[column] = row[column].split(' ')[-3:].str.join(' ')
right. ill modify it
whats a better alternative?
anything else, if you're using .apply it's the same as for-looping over the rows
same for numpy.vectorize
both are just convenience wrappers around python loops
give me an exampke
wdym
>>> import pandas as pd
>>> import numpy as np
>>> ser = pd.Series(np.random.random(10**6))
>>> ser.apply(lambda x: x + 5) # takes a few millisecs
>>> ser + 5 # instant
>>>
that's a pretty trivial example, but the same concept applies
lambdas are faster than for loop???
nope--if you use apply, it's executed as a for loop under the hood.
no, what I'm saying is .apply() is just a python loop underneath
and python loops are slower than np/pd/friends functions that operate on entire arrays (like ser + 5 that adds 5 on an entire series), because these loop in C
same for np.vectorize, that's also just hiding a python loop beneath so you're not getting any speed boosts if you use that
shit. was with you till you started mentioning C hahaa
must be some DSA stuff that im unfamiliar with and yet to learn
but i got that apply is just a glorified for loop
I wonder what a degraded for loop would be like
no
np/pd/friends have parts that are written in C, and stuff like ser + 5 use that code, that's what I mean by "it loops in C" - they're written in C, so faster
and .apply() takes any arbitrary function and loops in python, like for i in range(len(ser)): ser[i] += 5, which is slow
rangelen 🤮
I mean you can't modify it like for v in ser: v += 5 I'm pretty sure
you can't
okayyyyyyyyy
when I was new to python, I was confused by that behavior. there's even messages about it somewhere deep in this server.
(im)mutability strikes again
anyways thanks for your help @jaunty helm and @remote carbon
Considering I have a zero shot classifier using Transformers that takes in a json string representing a product and tries to map it into a category > subcategory > microcategory, how would you guys recommend I limit the number of labels I pass into the zero shot classifier?
@jaunty helm I found it (I wasn't even staff at the time) #python-discussion message
Do yall have a good server rec for LLM's and prompting specifically?
I'm running into an issue with my local LLM, where it seems like sometimes the LLM forgets important context to the conversation. For instance, I tell it it's role, and my role, in the conversation. Then by the end of it's first response to my prompt, it assumes my role and resonds to itself as if it were the user. You know, generating part of what my response should be at the end of its response.
so basically you're roleplaying?
Essentially. I don't know the best ways of interacting with it in general I guess, maybe roleplaying isn't what I need. Of course there are many ways to use generative AI. For instance, in this specific scenario I'm wanting it to essentially annotate python code and explain why things are being done.
All of this, of course, is just to supplement the research and understanding process
Problems with LLM's and hallucinations - all things should be independently verified. I understand those disclaimers
impersonation usually means at this point of the conversation, it's most likely that your character makes a response.
if we exclude the possibility that the model is just bad, this happens usually because it was shown an example where it happened, i.e. if this is your first message
(First Message) AI(as Bob): You and Bob walk into a room. It's eerily quiet, and you feel as if something's watching you.
```you basically told the AI that it's ok for it to make a move for you(walk into a room) and it's also ok to tell you how you should feelI'm using llama-cli and have been running it in -i interactive mode. So I guess that plays into it needing to be some sort of interactive experience
it might also happen if you make it generate a very long response
in a 2-party conversation, one side can only go on for so long after all
Yes, I see. I am trying to make it verbose (as needed), but also given the python excerpt, it already has a lot to deal with
Just as point of discussion, in academic lectures and presentations one side does go on and on for quite some time without back and forth. Or, say, a corporate presentation
https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
This is the model I'm using, and it does say it's trained to "act as helpful assistants"
So I should be using it for the way in which its model was trained, presumably
that's (probably) specifically not what the AI was trained on though
I'm not sure how llama-cli works exactly, but if you're having a conversation, chances are you're using an 'instruct' model, which are models specifically trained on query-like data, e.g. data that's like this
System Instruction:
You're an helpful assistant who will answer the user's questions.
User Input:
Are apples or oranges better?
Assistant:
...
that does seem to be an instruct model
yes indeed, if you look in tokenizer_config.json
"chat_template": "{% for message in messages %}\n{% if message['role'] == 'user' %} ...,
```you can see that there are defined "roles", which are basically specific to instruct modelsSo I will need to approach it in a way that it was trained for. Assistants should be able to give long form responses upon request. Will just need to do more testing
I mean you could just tell it to do that
like The above is python code written to scrape a website. Explain in great detail what each step does, and why the code author might have chosen to write this way. or something
also zephyr is super old, almost 1 year now?
if you want something of a similar size, the Qwen2.5 family just released and many think it's very good
I've done a bit of iterative testing using the user/assistant method previously, but as I mentioned it would sometimes assume my own role in its generated responses. Of course, this happens during an expectedly long response, which I thought might have something to do with its attention
Yeah it's been a bit since I first messed with this stuff. I remember it was a PITA acquiring models tbh. Sometimes there's time consuming hoops to jump through to get access to models. I found a couple I could acquire (all legitimately, of course), and with that I started messing around and testing it
I mean, I have been getting quite informative responses out of this model
Just trying to get better at prompting it for now. Of course always getting a shiny new model could be nice. But another thing to keep in mind, I'm not running the beefiest of hardware so I am definitely limited on what model sizes I can use. When I built my PC I was not preparing for all these possibilities
qwen2.5 has a 7b, which is the same as zephyr, so you definitely can run that
I have been getting quite informative responses
that's nice, though what I'm saying is models got a lot better in the span of a year
PITA to get models
imo now it definitely isnt; if I want to get a model, I 1) find a quantization someone else probably already made, 2) download it, 3) open upkoboldcppto run it, and boom
I'll give it a shot.
https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-GGUF/tree/main
For the zephyr, I ended up downloading its model repo from hugging face and I converted it to gguf manually via llama.cpp
llama.cpp/convert-hf-to-gguf.py /path/to/zephyr-7b-beta --outfile /path/to/zephyr-7b-beta.gguf --outtype q8_0
In this repo I actually see q8_0.gguf files, but I see 3 of them? Any idea what the difference could be?

When I did this conversion myself, it only created one .gguf file (denoted by --outfile argument)
Actually, they wrote about it it seems.
For large files, we split them into multiple segments due to the limitation of file upload. They share a prefix, with a suffix indicating its index. For examples, qwen2.5-7b-instruct-q5_k_m-00001-of-00002.gguf and qwen2.5-7b-instruct-q5_k_m-00002-of-00002.gguf. The above command will download all of them.
Oh no, I tried running the model and it's giving me errors 😱 , guess I have to start doing the dreaded action of troubleshooting
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 3840.00 MiB on device 0: cudaMalloc failed: out of memory
This seems like a typical response for me trying to run models that my GPU cannot handle
Oh wait, this might be another classic user error. Think I picked up the wrong quantization
Update again, seems like downloading the lower quantized version still gives me a similar error. I cry
Seems like it's requesting more bytes of RAM than the zephyr model was

Is machine learning all about statics equation
pretty much all of ML involves statistics in some sense or another.
#❓|how-to-get-help Open a help thread
I cant. Send message
Mee not PC ım used phone
I was thinking about it would be so cool learn machine learning
But actually it is so boring
I don't have to code any single thing
All I have to do just learn about the statics mathematical algorithms
And the all the project are so boring for machine learning
Yeah, if you do very basic stuff it's boring I'm sure
Like predicting the cost according to your house
I look at machine learning like being a scientist
It's a developing field. If you read white papers you see how people apply what others have learned, and attempt novel things to improve performance on specific applications
If you think one application is boring, then dont focus on that application (unless, you need to for pure learning aspects)
I'm trying to finish off this little VAE for MNIST digits. I've got down to about 50 MSE loss. That's pretty frickin' close. The output is just a tiny bit fuzzy
Any advice? More input/output features? An adversary maybe?
do you have any other metrics besides the loss? the loss on its own is quite a meaningless number
What metrics would you like?
HA!
Got it down to 12. This means that the sum of the squares of the distance between target and source pixels is 12, right?
For 1024 pixels (32x32) I'd say that's pretty fuckin' close
Now - do you think I could get it below 1...?
So apparently, manually setting the "ctx-size" (prompt context?) allowed me to run the quantized model. I suppose the default value set inside the model was too high, not exactly sure what it does but clearly it's of importance
By the way, I got qwen2.5 to work with the proper quantizations and configuration in my inference with llama-cli. Thanks for the recommendation to update. So far, seems to be well organized in its responses and following my rules/prompt context very well.
How do I go about analyzing the gradients and activations in a neural network? And, how do I intervene when I find something that isn't working?
I've got a big project in the works, maybe y'all would want to weigh in
My ultimate goal is to build a system for making furry art with ai. But, I'm tired of people calling me a thief for using models trained on other's art without permission.
So the question is now "how to teach an AI what a furry looks like without actually showing it any furry art."
Here's the plan. I'm going to use a dual-encoded VAE to learn to capture what animals look like from photographs. I'll autosegment them by using what's caught by a "shared features" encoder. Then, using some fancy tools like implicit functions, I'm going to cast the images into 3D voxel grids and compare that against the photo. Sorta like a 2D-to-3D VAE. The issue here is that the VAE can only compare what it generates against whatever is visible in the photo.
But, I can compare the partially constructed animals to identify what features they have in common. With enough examples, it should be able to build an internal knowledge of what every animal looks like. Doing this, I build 3D models of every animal I can think of.
Then, using self-supervised autosegmentation, I break 3D models of animals into parts. A furry character is, for the most part, an animal head with a human torso, and either human or animal legs (like a werewolf). If I can teach an AI to understand the underlying rules of anatomy, I can start removing segments from models and train a system to rebuild the missing peices. If I focus enough on generalization, it should reach the point where it can accurately rebuild any missing segment of any animal.
Then, I'll take a 3D model of a human and of an animal, swap the human's head for an animal's head, and remove the neck. I'll have the AI rebuild the neck based on what it knows about anatomy to recreate a convincing realistic depiction of an anthro character.
in case you're interested, this general approach is sometimes referred to as "zero-shot learning". maybe that helps you find other related references on the matter, but the general idea is fine
Sick, thanks
What do you think of the approach? At least mostly sane?
yeah
i'm not sure the segmentation part is necessary, but the rest is pretty in line with zero-shot
I appreciate feedback like this, pointing people to similar technologies/areas of research. Hard to know till you know
Is this where I can talk about my pyspark issues, fordata eng
Sure, this is as good as anywhere else. If it's just a problem, you can also ask in a help thread; #❓|how-to-get-help
What did you expect?
Any idea what this behavior is illustrating? I am messing with my prompt to get my LLM to explain/annotate python code. The same python code, each time. Pretty much what I've noticed is 99% of thd time, my "AI assistant" is skipping over an entire class definition that exists in my python excerpt. But the thing is, it's not skipping over a different class definition in the code. I've been changing my prompt (not to explicitly address this, but still) and it has remained like this. I'm not sure exactly what I could put in my prompt to affect this, because the job I've already tasked it with was annotating the entire code. not sure how the attention makes it ignore a class in the middle of the code, but not everything else
do u guys have any thoughts on how can i achieve something..
like im basically trying to get specifications of fruits dk if "specifications" is the write word for it but something like
{
"apple" : [
"keeps the doctor away", "contains vitamin B, C, and A", "good for hair growth"....
]
}
and so what kind of libs should i use to achieve smth like that
im guessing i might need a whole alot of data on fruits?
ig i might need to do some web scraping to get all the data available on fruits???
idt i would be needing any ml libs for that like if i could get the data in CSV format or smth like that Pandas can handle that??
i expect machine learn automatically from there past experience
That is the ultimate goal still.
But it's not so simple because it becomes a question of what to learn, and how to learn it.
is it all about statics
That's because statistics is about inductive (and abductive) reasoning which is when you have incomplete information (which is pretty much always the case in any real world problem). And then based on only a small part of the whole (a "statistic"), you make inferences about the whole (from specific to general).
When a machine learns, you can't possibly have all the data. You only observe a tiny sliver of the world. And so a lot of machine learning is dependent on statistical methods.
Why yes - statistics is all about statistics. Very insightful XD
That's a bit like saying gardening is all about plants XD
This is also why even if you have some super intelligent AI, it can't work magic. It can only do what it can given the information it actually has. In media they often ignore this, as if being smart enough suddenly means you have all information (see the Sherlock Holmes series for example).
And this is why intelligence is also strongly linked to your ability to collect (useful, high quality) data.
Gonna have to nit pick with you on this
You're not wrong of course
But that glosses over the nature of a runaway super intelligence
Specifically, that it's intelligence is self magnifying - it's ability to spot patterns has excelled to a point where it can now design better, faster learning, more insightful ways to learn
Consider the layered sine wave. What looks like noise can be broken into multiple smaller sine functions. This is the essence of neural learning after all. There's a limit to how many functions a neural network can use in its approximation of whatever the target function is, yes, but after a certain point
When looking to extract "meaning" from data, how you extract and emulate it is often more consequential than how many neurons you have to do it. Meta learning and self-supervision tactics are already showing incredible promise in this regard - better, less rigid, more self-organizing methods of extracting meaning\
A super intelligence is using it's intelligence to find better ways to extract meaning which translates to greater intelligence. After long enough, how many neurons you have is... less relevant. And from a human perspective it's entirely moot
*how many neurons, how much data you have, etc
I feel like this might be missing my point. The intelligence will still need to collect a bunch of data, and if it's smart, it's will certainly do so, and in the most effective way possible.
And there are certain things it can't possibly know without observing everything, which as far as we currently know is not possible.
but how machine learning find a way to slove a problem like objection classiffier just using some statics algorithm
This falls under pattern recognition. It may be easier to explain it with spam email detection. If I give you a dataset with a bunch of emails where some are spam and some are not (and they have been labelled as such), you can predict whether an email is spam or not based on the text input, and this involves statistical methods. For example maybe you find that certain email containing certain keywords are more likely to be spam (correlation).
Things might start being more interesting for you once you start dealing with different data types, like images.
But the fundemental ideas are the same.
And it does not make sense to overwhelm a beginner with how to deal with more complicated data types at the start. But it comes with the tradeoff that it may more boring at first.
but that sounds like we are training the machine though some statics data it learning from their past experience
So past experience usually refers to the case where there is some agent (a being that can do reasoning and has some goals) that takes some actions, and from that it gets some result (the experience), which is data, from which it can learn (in some way store / encode), and make inferences from (induction, abduction, analogical), to make better decisions. Machine learning is an important part of machine intelligence for real world problems (where you don't have perfect information).
is hnads on mchine learning is good book
IDK. But some people here may know some good ML books.
https://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738 Is at least not bad. I can confirm this one being good. Although maybe pretty hard for a beginner, it ramps up really fast in difficulty curve.
Amazon One Medical
Get care and request prescriptions from an online or in-person doctor. Now offering ongoing primary care and 24/7 telehealth.
But if you manage to get through this book, you have a pretty solid understanding / foundation.
Whichever way you get into ML, it's probably fine, because math is math, it's not going anywhere. It's not like learning a programming language from a book that is outdated in a year due to a new language version release (math builds on the old).
But learn it in terms of the math if possible, learning specific libraries / programming languages is shallow knowledge. Although you do need some of that to actually make something.
suppose i am making a chess game it woulds take a thousands of statics model to predit a paricular move
?
nice, have fun w/ it
manually setting
ctx-size
ctx-sizeis context size, which is how much the model can remember, if you set it higher then it takes more vram ofc; qwen2.5 boasts 128k maximum context(in practice it should be less, like 32k or 64k), so maybe the default uses that so the resources usage blew up
So I made some improvements in the architecture on how I integrated the CLIP embeddings directly into the Vector Quantizer. I also made the switch to diffusion models (Tricky inspired me) for the decoder instead of the typical deconvolution layers, I implemented a conditional diffusion process to denoise the latents step-by-step. I just started the training see how it goes.
guys, can u recommend free course for beginner to learn data science with diploma 🙂
https://www.freecodecamp.org/news/all-the-math-you-need-in-artificial-intelligence/
So guys this is the maths free code camp is saying learn for ai/ml stuff, is this all i need or more for ai/ml
Please check someone
And also tell what's the best approach to learn maths, like doing that on paper notebook or direct code

freeCodeCamp.org
By Jason Dsouza I’m an AI researcher, and I’ve received quite a few emails asking me just how much math is required in Artificial Intelligence. I won’t lie: it’s a lot of math. And this is one of the reasons AI puts off many beginners. After much res...
Nobody can tell you the "best approach to learn" anything, that's a highly personalized question. We all learn best in different ways
Last line is beautiful
Btw is this all topics for ai / ml or i need more?
🤷♂️ i dont know, leaving that answer for somebody else
more what?
Is there more maths other than the freecodecamp is telling that required for ai / ml