#databases
1 messages · Page 167 of 1
They just don't know better, and that's okay. No need to be so harsh
@mystic trout what is the point of this table? You should be able to have a row for each username.
Relational databases and SQL you can think of as Excell sheets.
Each sheet in Excell is a table, and each excell file is a database.
Rows and columns in Excell have the same meaning in SQL.
and this code is prone to sql injection
a user can enter malicious sql code as the username
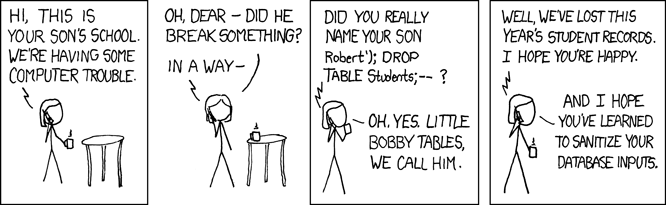
test; DROP TABLE ...;--
@mystic trout if you tell us more about how you want to use the table we can help you figure it out in the best way possible
And if you have a table for each username it will become very hard to query the data
I need each user to have his own table, his name will be as the name of the table and his password as a field
you can have a single table and store the username in a column and the password in another column
There's what's called a WHERE clause that will allow you to filter out results.
is vscode good for sql
if thats true then i wont be needing popsql or any other editor amiright
Why would you need another editor?

Sqlite3 using Python:
If I have a list of data(user_ids), is there a way to update the relative "points" data at once?
for ex)
cursor.execute("UPDATE main SET user_elo = (?) WHERE user_id = (?)",
(int(user_elo), member.id))
like this, but without having to bring out all the elements of the list and doing them one by one. Possible? if so, how? Ping for reply.
There's an executemany method
!d sqlite3.Cursor.executemany
executemany(sql, seq_of_parameters)```
Executes a [parameterized](https://docs.python.org/3.10/library/sqlite3.html#sqlite3-placeholders) SQL command against all parameter sequences or mappings found in the sequence *seq\_of\_parameters*. The [`sqlite3`](https://docs.python.org/3.10/library/sqlite3.html#module-sqlite3 "sqlite3: A DB-API 2.0 implementation using SQLite 3.x.") module also allows using an [iterator](https://docs.python.org/3.10/glossary.html#term-iterator) yielding parameters instead of a sequence.!e
import sqlite3
with sqlite3.connect(":memory:") as conn:
cur = conn.cursor()
cur.execute("CREATE TABLE foo(bar INTEGER);")
cur.executemany("INSERT INTO foo(bar) VALUES (?)", [(1,), (2,), (3,)])
cur.executemany("INSERT INTO foo(bar) VALUES (? + ?)", [(4, 3), (5, 10), (6, 50)])
cur.executemany(
"INSERT INTO foo(bar) VALUES (:bar + :baz)",
[{"bar": 4, "baz": 3}, {"bar": 5, "baz": 10}, {"bar": 6, "baz": 50}]
)
print(cur.execute("SELECT * FROM foo").fetchall())
@brave bridge :white_check_mark: Your eval job has completed with return code 0.
[(1,), (2,), (3,), (7,), (15,), (56,), (7,), (15,), (56,)]
Is there any such thing as a temporary value?
Like having SQL set a value to 5 for an hour... and then automatically setting it back to LAST_VALUE
Edit - maybe with events?
hmm... so after already changing the value...
/* code to set value here */
/* code to reset value in 5 hours */
CREATE EVENT resetNumber
ON SCHEDULE AT CURRENT_TIMESTAMP + INTERVAL 5 HOUR
DO UPDATE myschema.mytable SET number = LAST_VALUE;
``` would something like this work? Only thing... I dont know what `SCHEDULE` isfeel like u could just do this with variables but im not sure
i am using firestore and i have this line of code:python passcode = db.collection('Members').document( i.name).get()But i am getting this error:python asscode = (db.collection('Members').document( TypeError: 'NoneType' object is not subscriptable
db is defined here: db = firestore.client()
Can you show all the code?
who, me?
i will show relevant
definitions:```python
cred = credentials.Certificate(
"thing here that works.json")
firebase_admin.initialize_app(cred)
db = firestore.client()Relevant for loop:python
for i in guild.members:
passcode = db.collection('Members').document(
i.name).get()
if passcode.exists:
await i.send(f'As the backend of the **"Website"** nears completion, everybody will need a passcode to sign-in. \n **Here is yours:{passcode["passcode"]}**')
print(f'sent direct message to {i.name}')```
if u need morre, just ask
What confuses me is that the error you're getting should only happen when you try to use X['Something here']. Do you know if i.name if None?
ok, lemme debug
um, now the firebase side worksz?
i only moved a print statement
how can i track daily messages?
You'll have to save a count for every message, or if the messages are all in your database you can do so with some smart SQL queries
!d discord.Message.created_at I am trying to insert that info into a postgreSQL column but it errors:
asyncpg.exceptions.DataError: invalid input for query argument $2: datetime.datetime(2021, 9, 6, 7, 26, 20,... (can't subtract offset-naive and offset-aware datetimes)```
created_at```
The message’s creation time in UTC.What is your column typed as?
TIMESTAMP WITHOUT TIME ZONE
Sorry for caps
This is ow I created it lol
CREATE TABLE IF NOT EXISTS modmail (
user_id BIGINT UNIQUE,
created_at TIMESTAMP WITHOUT TIME ZONE,
channel_id BIGINT
);```Right, so you're saving an aware timestamp in an column that's naive.
It always worked for me I think
That's the error, either make the datetime naive, or change the column
Discord.py datetimes used to be naive.
How can I make a datetime naive I am not really good with datetime
I would honestly recommend changing the column to be aware
Besides, who's created_at is this?
Um what?
How can I am a colun aware, never heard of something like that
?
How can I?
if it has a timezone
aware = knows what timezone it is for
naive = doesn't have tz info, assumes system time zone
Yeah I asked in sql server they said I should use TIMESTAMP WITH TIME ZONE instead of TIMESTAMP WITHOUT TIME ZONE
Hi everyone! I have some images stored on AWS S3. I would like to store the image paths in an sqlite db. Then build an api to do get requests that displays these images. I am a bit lost in how to do this and hope someone can point me in the right direction. I am not sure how to store the image paths in the database and connect them to S3. I hope I explained this clear enough, any help would be awesome! 😀
Traceback (most recent call last):
File "C:\Users\eyal2\AppData\Local\Programs\Python\Python39\lib\site-packages\discord\client.py", line 351, in _run_event
await coro(*args, **kwargs)
File "c:\Users\eyal2\OneDrive\Desktop\Python\Bot\bl\system.py", line 42, in on_message
if word in msg.content:
TypeError: 'in <string>' requires string as left operand, not tuple
@commands.Cog.listener()
async def on_message(self, msg):
rows = await self.db.execute("SELECT words FROM blwords WHERE ? = guild_id", (msg.guild.id,))
data = await rows.fetchall()
for word in data:
if word in msg.content:
await msg.delete()
await msg.channel.send("Stop swearing!")
code ^^^^^^
word itself is a tuple likely. Have you tried printing it?
no. ill trry
@digital wharf i got this ('shit',)
Which is a tuple, so check word[0]
!e print(type( ('shit',)))
@digital wharf :white_check_mark: Your eval job has completed with return code 0.
<class 'tuple'>
what the heck
i did nothing and now something is broken
<coroutine object Command.__call__ at 0xb43a6f60>
main.py:107: RuntimeWarning: coroutine 'Command.__call__' was never awaited
print(list(cur.execute('SELECT * FROM messages')))
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Ignoring exception in command archive:
Traceback (most recent call last):
File "/home/pi/.local/lib/python3.7/site-packages/discord/ext/commands/core.py", line 85, in wrapped
ret = await coro(*args, **kwargs)
File "main.py", line 110, in archive
textshowcase.write(dumps(list(cur.execute('SELECT * FROM messages')), indent=4))
File "/usr/lib/python3.7/json/__init__.py", line 238, in dumps
**kw).encode(obj)
File "/usr/lib/python3.7/json/encoder.py", line 201, in encode
chunks = list(chunks)
File "/usr/lib/python3.7/json/encoder.py", line 438, in _iterencode
o = _default(o)
File "/usr/lib/python3.7/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type coroutine is not JSON serializable
I didn't make it aysnc
You forgot to await something
Do u guys have any database I should Lear
Besides SQLite
Since I already know that
postgres
!e print(type( ('Hi',)))
@sudden tangle :white_check_mark: Your eval job has completed with return code 0.
<class 'tuple'>
Does anyone know a really good introduction to using Databases/SQLite within Pycharm ?
No but the official docs are usually good. You can also follow intellij instructions since it works the same as pycharm.
The image paths in S3 are just strings / urls I guess. Store them as a TEXT column? Your question is quite wide
when i removed the json.dumps a sqlite db it works fine
🤷♂️
Guys i made a role-based API with python and firebase authentication
If anyone want it tell me
How can I get all of the post_ids which have all of a list of given category_ids ?

For example 4 should return 1001 and 1003
5, 6 should return only 1001
WHERE?
select * from post_category where category_id in (5,6)
Is this what you asked for?

What is PostgreSQL In ? The IN operator is used in a WHERE clause that allows checking whether a value is present in a list of other values. In Operation helps to reduce the need for multiple OR condi
I would use an subselect like:
select *
from rel_post__category
where category_id = 5
and post_id in (select post_id from rel_post__category where category_id = 6)```That's an OR not an AND
Hello, why is aiopg.create_pool returning None when I run it using loop.run_until_complete ```py
import aiopg, asyncio
from constants import POSTGRESQL_URI
loop = asyncio.get_event_loop()
pool = loop.run_until_complete(aiopg.create_pool(POSTGRESQL_URI))
print(pool)
loop.run_until_complete(pool.close())```
any help/suggestion after executing the SQL query we get the data from our database we get a number of records in that data sometimes data may be corrupted so after that how do we validate data is corrupt or not in SQL
i need a help this

thanks for you
async def result(ctx, result):
result = str(result)
Team_A_channel = client.get_channel(870969338901954606)
Team_B_channel = client.get_channel(870969338901954607)
Team_A_members = Team_A_channel.members
Team_B_members = Team_B_channel.members
Team_A_members_id = []
for member in Team_A_members:
Team_A_members_id.append(member.id)
Team_B_members_id = []
for member in Team_B_members:
Team_B_members_id.append(member.id)
Team_A_members_mention = []
for member in Team_A_members:
Team_A_members_mention.append(member.mention)
Team_B_members_mention = []
for member in Team_B_members:
Team_B_members_mention.append(member.mention)
winning_team_lobby1 = ""
if result in ['Team A', 'team a', 'Team a', 'team A']:
winning_team_lobby1 = "Team A"
cursor.execute("UPDATE main SET Price = user_elo + (?) WHERE user_id IN [?]", (elo_win, Team_A_members_id))
db.commit()
user_elo doesn't change even after i use the cmd. no errors as well. what wrong? ping on reply
Does anyone here use hiedisql
I assume there is a sql syntax error being swallowed somewhere. That insert query looks wrong
Try looping over the member ids, inserting one at a time. There's probably an efficient way to pass in the list but I don't know it
Hi I have a table in my db which stores how many times someone joins a server but I'm having some issue incrementing the number, can someone explain to me why that is. This is my codepy joincount = await self.bot.get_member_guild(member.id, member.guild.id) count = joincount[2] + 1 async with self.bot.pool.acquire() as conn: await conn.execute("UPDATE membersguilds SET joincount=$1 WHERE member=$2 and guild=$3", count, member.id, member.guild.id)and this is the errorpy Ignoring exception in on_member_join Traceback (most recent call last): File "/home/snowyjaguar/.local/lib/python3.8/site-packages/discord/client.py", line 343, in _run_event await coro(*args, **kwargs) File "/home/modmail/cogs/events.py", line 200, in on_member_join count = joincount[2] + 1 TypeError: unsupported operand type(s) for +: 'NoneType' and 'int'Do I need to do int(joincount[2] and if so could i then just get away with joincount[2] += 1 instead of the whole thing?
nvm I fixed that issue but I know have a issue where it is trying to incriminate my guild ID as I have a composite pk made from the member ID and the Guild ID
@gusty mulch the actual error message suggests that joincount[2] is None, and this happens on the line above the sql query
the error messages are not meant to be mystical texts, they're supposed to be there to help you
my table goes Member ID | Guild ID | Joincount. Both member and Guild are pk's and joincount is set as a big int data type with a default value of 0
so that would be when it's pulling the data from the db?
no, it's the line above
it says it right in the error message
File "/home/modmail/cogs/events.py", line 200, in on_member_join
count = joincount[2] + 1
yes, that is when it's declaring joincount and pulling/adding stuff to the db (or so i understand)py joincount = await self.bot.get_member_guild(member.id, member.guild.id) # <------ here count = int(joincount[2]) + 1 async with self.bot.pool.acquire() as conn: await conn.execute("UPDATE membersguilds SET joincount=$1 WHERE member=$2 and guild=$3", count, member.id, member.guild.id)
nvm I think I found the issue in a different file where i'm declaring get_member_guild
okay this is how I'm doing get_member_guild but it doesn't seem to be working as intended becuase despite me saying that it goes member, guild, 0 the db is adding joincount (the 0) as null even tho the db is set up so that the joincount column defaults to 0.py async def get_member_guild(self, member, guild): async with self.pool.acquire() as conn: res = await conn.fetchrow('SELECT * FROM membersguilds WHERE member=$1 and guild=$2', member, guild) if not res: res = await conn.fetchrow( "INSERT INTO membersguilds VALUES ($1, $2, $3, $4, $5, $6) RETURNING *", # $7, $8, $9, $10, $11 member, guild, 0, 0, False, None) return res
How does the table look like? Was the joincount really the third column when you created the table?
well this is a gui not cli

back in a few mins, gotta toilet the puppy
okay i'm back
it was a few days since I made the table but i'm confident joincount has always been the third column. should I delete the table and remake it to be sure?
Does the gui not have some sort of schema display where you can take a look?
Are you sure the entry in the db is coming from the insert code you showed? Maybe the entry was already there? Delete the row in the db and try again.
Hi, if someone uses and knows about sqlite3, please help me at Help banana
That's pgAdmin, and yes iirc it has
You can expand the table and after that see the columns
okay so what i have noticed is that it seems to be a issue related to the on_member_join event. I copied the db interaction into a command and it works flawlessly. It seems that upon further testing using the event it is all working strangely. It was definitely something to do with it setting the number type of joincount defaulting to null despite me telling it to be 0. I ran some sql statements in pgadmin which seems to have fixed my issues
When we do:
SELECT * FROM table_name_foo
in the above query * asterik stands for all?
So are we saying select all columns from table_name_foo
yes
ok thanks!
Hi
how do i get sqlite ping ?
i have a table with ids and points for that id. if i can get a list with a number of ids, how can i add and certain to the according points? pls ping on reply
You don't. It's either on your computer, or its the same as the ping with the host.
does anyone have any idea on sha256 for data Validation?
Can someone help here? ```py
await c.execute("UPDATE warn SET (?, ?) WHERE userid = ?", (member.id, user[0] + 1, member.id))
Error: ```py
Traceback (most recent call last):
File "/opt/virtualenvs/python3/lib/python3.8/site-packages/discord/ext/commands/bot.py", line 994, in invoke
await ctx.command.invoke(ctx)
File "/opt/virtualenvs/python3/lib/python3.8/site-packages/discord/ext/commands/core.py", line 894, in invoke
await injected(*ctx.args, **ctx.kwargs)
File "/opt/virtualenvs/python3/lib/python3.8/site-packages/discord/ext/commands/core.py", line 176, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: OperationalError: near "?": syntax error
That’s not a valid update statement syntax near the set. Usually something like
set my_field = ?
Sqlite3
i have a table with ids and points. i also have a list of ids thats from somewhere else. i want to use this list to change all the points according to these ids.
ex)
before:
table
id | point
1 | 19
2 | 78
3 | 76
list = [1, 2]
after:
table
id | point
1 | 20
2 | 79
3 | 76
UPDATE table SET point = point + 1 WHERE id IN $1
Where $1 is your list and table is the name of your table
?wgat
best database for discord.py?
someone help in #help-cake
try sqlite3 cuz its rlly simple to get going
if u wanna do smth more fancy? then pick mysql or postgresql
How can i search in sqlite3 with characters instead of numbers?
hello guys why i get this error? i'm trying to connect to sqlite3
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: OperationalError: no such column: lucbot
lucbot colum not exists
make sure you have create table and colum in your db file
but why i need table for my bot?? i dont need that
Am. Read how sqlite3 works (Setup, tutorial videos).
can anyone help me please? idk y but my bot calls the api 2 times at one command, whats wrong?

oh
im not in discord bots
sorry
i thought i was in #discord-bots
||mods dont kill me mods||
how to delete all records from DynamoDb tables in aws
is there anything i can do to check if a table is updated? or if any if the value changes? (in sqlite3)
You can create a trigger
Hey, does someone uses https://remotemysql.com/ ?
I been using it for a while but suddenly my discord bot can't connect to it anymore
I was hosting on heroku and suddenly the bot was unable to connect to the database, it used to work
Then I switched to a VPS, same thing happened. After a few days it wasn't able to connect anymore
Error: Error during connection 2003: Can't connect to MySQL server on 'remotemysql.com:3306' (10061 No connection could be made because the target machine actively refused it)
Or, Is there any other place in which I can host an SQL database for free?
hey guys, I made a drop down menu in js, how can I make it so that if anyone selects any option from the drop down list, it must stored in my mysql db
I believe Drop-down menu you are referring is in front... If that the case then you can use Api and send the request from Api to backend which will write into the db
how can i get data from .json file in reverse order? i want to get recently added data
You can reverse the dictionary using py dict(reversed(your_dictionary.items()))
json insertion order isn't deterministic even if dict insertion order is in python
i wouldn't rely on that
however if it's an array, obviously you can just slice elements off the array as needed
json isn't a "database", it's just a way to store data on disk in a file
Any suggestions for an async Mongodb odm?
Bad argument
Converting to "int" failed for parameter "pep_number".
!pep <pep_number>
Can also use: get_pep, p
Fetches information about a PEP and sends it to the channel.
!source database
Bad argument
Unable to convert 'database' to valid command, tag, or Cog.
!source [source_item]
Can also use: src
Display information and a GitHub link to the source code of a command, tag, or cog.
!src database
Bad argument
Unable to convert 'database' to valid command, tag, or Cog.
!source [source_item]
Can also use: src
Display information and a GitHub link to the source code of a command, tag, or cog.
Is there any way to decrypt google Cookies file?
!pypi motor

Non-blocking MongoDB driver for Tornado or asyncio
odmantic
Is anyone available to help troubleshoot a simple pandas script for an excel csv file?
!paste Post your question in #data-science-and-ml and someone might be able to help. Post your full code and a sample of the data. Use our paste site, do not post screenshots 👇
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
select t.table_name
from information_schema.tables t
inner join information_schema.columns c on c.table_name = t.table_name
and c.table_schema = t.table_schema
where c.column_name LIKE '%attachment_id%'
and t.table_schema not in ('information_schema', 'pg_catalog')
and t.table_type = 'BASE TABLE'
order by t.table_schema;
I'm trying to find column that has string 'attachment_id' in it and has a value of 561
With the above query I only get all the tables that have column with that string in it, then I have to manually look them up if any of them has that ID.
How can I only find thosee with id=561 and string "attachment_id" in it's name from all columns across all tables?
ping for reply
(note: discord has sql syntax highlighting, use ```sql)
i don't know if that kind of metaprogramming is possible in plain sql, would be interesting
is it posiible to use regular expression?
hm I fixed the problem in the meantime so no need to debug anymore, ty tho @harsh pulsar @lost vessel
Hii, im new to python discord chanel. I have facing issue to extract stocks data from bloomberg api. I installed blpapi. It works. But my goal is to fetch all stocks data from bloomberg api to database like mysql, postgresl. I cant work with excel because of shortage table row, column. If you have a ideas n solution. Please let me know thanx
Welcome. I'm not familiar with pdblp though according to the docs it uses pandas dataframes. The allows you to use the to_sql method. see https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_sql.html
Thanx.. my idea is to fetch all stock data from bloomberg to database like postgresql or mysel.
tickets = ['a', 'b',.....,'z']
blp.bdh( tickers=tickets flds=['Last_Price','EQY_FUND_CRNCY=CAD'], start_date='2020-12-31', end_date='2021-05-31', Per='M', )
Here is my code .. im not sure. I want to select all stocks.
you may need to find a list and iterate over them
Yeah but the list of stock name is too long .. its possible to put prefix alphabet order...
Amzn, appl, these stocks names start from A ..
Do you get a error when you list all stock tickers?
Yeah .. because the names are errors. I m thinking to solve this problem. I think this is wrong direction. Do you have any idea to solve this problem ?
First problem, how can i get all trickers name ?
Second problem, once i get all trickers name. How can i insert into database like mysql or postgresql? I think this is easier than first one.
I googled all stock ticker list and got a few stack overflow results
This one with the link in the UPDATE seems promising: https://quant.stackexchange.com/a/1862

Quantitative Finance Stack Exchange
I have a very basic data question: how to get a list of all common stocks traded on NYSE, NASDAQ and AMEX? I would need to be able to get the approximate list of common stocks as is available in
Only https://matthewgilbert.github.io/pdblp/api.html#pdblp.pdblp.BCon.bsrch is the only api function that doesn't take a ticker as a input
Im looking for python script to solve this problm
The issue is tickers parameters. If i solve this python lists.. then it will solve.. im not suree .
Thats why i initialized new python lists like ticker. I put alphabet order..
It will be possible to get a csv or file with all tickers.
And then load that into your database
And get the first N of those tickers to use in the api
And then that is done, get the next N
Is that what you want?
Thanx. You gave me some clues. The problem how to select all data from python side .. its very tricky
Been trying to use Tortoise ORM with aiosqlite and I'm running into an issue where I get sqlite3.OperationalError: unable to open database file, I've come to the conlucsion this an issue with my path, so I've been changing things around and researching and I figured that an absolute path is the best option, but it does not work and If anyone could tell me how to solve this It'd be much appreciated.
my current aiosqlite path - sqlite:///C:\\Path\\To\\Invites.sqlite
Is the file not next to the Python script you're running?
Does your Python script have permission to open the database?
Maybe you opened the file with open() or something?
Where can I host an SQL database for free?
Host it locally
But I need it to be online 24/7
And I can't do that on my pc
I will end up paying a host of course but for now I need a free option
Heroku has a free database service
How do i create a list in postgres SQL?
Is the sqlite:// part actually required? And are you sure you need the leading slash in front of C:?
@latent bone say what your intended working directory is and say where the sqlite file is
I think you have one slash to many: sqlite://C:\\Path\\To\\Invites.sqlite
The sqlite:// is for Tortoise ORM to define the db driver to use.
I tried that path already, // makes it relative, /// makes it absolute
?
Have you tried in linux form? sqlite:///C/Path/To/Invites.sqlite
That would work even If I'm on windows?
Can't say. It works for me in a bash, but never tried it.
I'll try it out when I get home
Ah, no, just tried it, didn't work.
But have you tried with only two slashes because in windows C:\\ makes it absolute anyway.

why is your query taking 30 seconds?
maybe increasing the timeout duration might help
that's not even a crazy query
uh what should i do..
idk, it randomly happens and after that it says to report the bug.. no commands besides maybe use works after that
iirc, that happens because 1) your internet is slow, or 2) the query takes too much memory
both false
:/
I'm creating a ticketing system and would like to archive a conversation. Would it be effective to pickle the conversation to save in a database?
..
That's up to you, I'd probably say no? But that depends on your ticket system. Personally we just generate dumps which are TXT files you can read.
and then where are the dumps saved?
Well we upload them to Discord in an archive channel so that it's easy for staff to download them as they wish or share them
ah I see
can any one give me a video for json pls
for adding data and edit data
and read data
You're looking for a video tutorial on how to use JSON in Python?
Is this with a Discord bot? You may be able to find tutorials were people use JSON.
You may be looking for an actual safe database, SQLite should get you started with that.
Or do you mostly want general advice with JSON?
No, I want to use json with the Discord library to add information to an external file and read or modify it, which is not important information, so I will not use Database
so u can help me ?
I've watched many of Corey Scheafer's other videos and they consistenrly put out good stuff, take a look at this
https://youtu.be/9N6a-VLBa2I
I can't help you if you're looking for a video in a native language other than English sorry

In this Python Programming Tutorial, we will be learning how to work with JSON data. We will learn how to load JSON into Python objects from strings and how to convert Python objects into JSON strings. We will also see how to load JSON from a file and save those Python objects back to files. Let's get started...
The code from this video can be ...
Thank you, I'm looking for any video in English
Why would this not work 
for x in range(len(result2)):
discid = str(result2[x][0])
percentage = round((int(result2[x][1])/totalpool))
payment = percentage*500
payment = round(float(result2[x][2])+payment,1)
async with bot.connection.acquire() as conn:
querystring = "UPDATE governance SET tokens=$1 WHERE uniquediscordid=$2"
await conn.execute(querystring, payment,str(discid))
No errors or anything but the tokens didnt get updated.
tokens are set as "double precision" in POSTGRES
What database library, asyncpg?
@grim vault I tried your suggestion, still got the same error
Hi did anyone have any idea about how to use sqlite3 with cpp
You've come to the wrong server, then.
Traceback (most recent call last):
File "bot.py", line 129, in <module>
bot = Logging(description=config.bot_description)
File "bot.py", line 53, in __init__
asyncio.get_event_loop().run_until_complete(self.init_tourtoise())
File "/usr/lib/python3.8/asyncio/base_events.py", line 616, in run_until_complete
return future.result()
File "bot.py", line 93, in init_tourtoise
await cache.create_cache(self)
File "/root/lograck/utils/cache.py", line 8, in create_cache
guild_data = await Guild.filter()
File "/usr/local/lib/python3.8/dist-packages/tortoise/queryset.py", line 890, in _execute
instance_list = await self._db.executor_class(
File "/usr/local/lib/python3.8/dist-packages/tortoise/backends/base/executor.py", line 132, in execute_select
instance: "Model" = self.model._init_from_db(
File "/usr/local/lib/python3.8/dist-packages/tortoise/models.py", line 725, in _init_from_db
setattr(self, model_field, field.to_python_value(kwargs[key]))
File "/root/lograck/model/functions.py", line 53, in to_python_value
return list(map(self.sub_field.to_python_value, value))
TypeError: 'NoneType' object is not iterable
Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x7fbdcd1e8730>
can anyone tell whats the issue?
return list(map(self.sub_field.to_python_value, value))```
Here value is None
it was working fine
i did not changed anything to my code
i just added 2 column on my db
how to create bigint list column in pgadmin?
ALTER TABLE guild_data ADD COLUMN ignored_snipe_channels ? NOT NULL default ?;
what do i put there?
I'm getting this error with MongoDB that I never seen before.
ConfigurationError: All nameservers failed to answer the query _mongodb._tcp.cluster0.rjefa.mongodb.net. IN SRV: Server 127.0.0.11 UDP port 53 answered ; Server 127.0.0.11 TCP port 53 answered REFUSED
I removed +srv in the URL but I still get it.
BIGINT[]
ALTER TABLE guild_data ADD COLUMN ignored_snipe_channels bigint NOT NULL default '{}';
ERROR: invalid input syntax for type bigint: "{}"
{} Is not an integer

PostgreSQL Documentation
8.15. Arrays 8.15.1. Declaration of Array Types 8.15.2. Array Value Input 8.15.3. Accessing Arrays 8.15.4. Modifying Arrays 8.15.5. Searching in Arrays …
i get a malformed disk image for my database when replit tab closes or crashes. if i close the database, would the database be fine even after replit crashing/closing?
Does anyone know why the files I make (for example .txt ones) are created as folders with the name .txt at the end? Probably not the right channel as it's a more general python question but I think it's better than a lot of the others.
How are you creating the files? Can you show the code?
Yep, gimmy just a second
def writeData(name, data, explorerDirectory):
datapDirectory = explorerDirectory + "/datap.txt"
if not os.path.exists(datapDirectory):
os.makedirs(datapDirectory)
f = open(datapDirectory, "a")
f.write(name + "\n" + data + "\n")
f.close()
writeData("name", "data", explorerDirectory)
I think I may already see an issue actually. It could be that I'm trying to create the .txt file with a os.makedirs....
can anyone explain to me what a Database actually is? Like how is it different from a normal file?
Yeah it was actually that. It works now 😄
i get a malformed disk image for my database when replit tab closes or crashes. if i close the database, would the database be fine even after replit crashing/closing?
Ping on reply pls.
A database usually provides some structure to the data, as well as a way to efficiently query/update it.
Normal files usually can only be overwritten. It's very difficult to modify most data formats "in place". A database is specifically designed to be able to:
- Perform partial updates and individual insertions without completely overwriting all the data
- Perform queries against the data, returning only specific subsets of it without having to load all of the data into memory; relational databases often use the SQL query language
- Handle concurrent reads and writes to the same data
You can think of the filesystem on your computer as a kind of database, where each filename is a lookup key and the file contents are the associated value. But without a proper database, the files themselves are often no better than "blobs" that must be read in their entirety in order to extract subsets of information, and must be overwritten in their entirety to modify/delete/insert information
And there are different kinds of databases for different purposes: relational databases, key-value databases, document databases, et alia
A database consists of a special file or collection of files, and special software that can interact with those files
Any expert in POSTGRESQL?
accidentally deleted all the rows in DB >.<
turned off the service 1-2min after
Just ask your question
well how can I recover it if possible, dont have backups
have 2 files in pg_wal
if it matters
It’s gone. Just learn your lesson so next time you do back it up or not delete it without backup.
I am not sure if you can reconstruct a database from those
This actually does seem to go through something like that @long dome https://www.enterprisedb.com/blog/postgresql-database-backup-recovery-what-works-wal-pitr

EDB
Which strategy works for PostgreSQL backup and recovery? Let's review WAL (Write Ahead Logs), PITR (Point in Time Recovery), Slave Database, Logical & Physical Backup solutions.
Turn off auto commit and re-think before commiting
are relational databases dead?
Not at all
ahh Thank You !
is there a way to select some raw in sql if 2 conditions are met and select less if the second isn't met ?
Can you explain more about this query and table-schema you have?
I have 4 Table,
Image(image,someinfo...)
Tags(id,name)
LinkedTags(image,tag_id)
FavImages(image,user)
I want to make a query that can give me the infos about a specific image (with some join) and also see if a specific user is link to an image in FavImages if thats the case, then if its not just return the image info
For the latter, can't you also do an EXISTS()?
Let's do this, type out the query you're imagining for the first part and we can build from that
what i was doing was this. the issue is that if the user_id is not in the table then i dont get the image info
SELECT FavImages.image,Tags.is_over18 FROM FavImages
JOIN LinkedTags ON FavImages.image=LinkedTags.image
JOIN Tags on Tags.id=LinkedTags.tag_id
WHERE user_id=124910128582361092 and FavImages.image='0c6dd5f3cf18ec4' GROUP BY FavImages.image
Having Tags.is_over18=Max(Tags.is_over18)
but if i had to imagine the 1rst part without thinking about the second then
SELECT Images.file,Tags.is_over18 FROM FavImages
JOIN LinkedTags ON LinkedTags.image=Images.file
JOIN Tags on LinkedTags.tag_id=Tags.id
GROUP BY FavImages.image
Having Tags.is_over18=Max(Tags.is_over18)
"image info" in this case is the info from Tags?
return if Tags.is_over18
or not
in all case
You can't select directly from FavImages if the entry might not exist.
then can i select from Images and add aditional column with aditional condition?
SELECT Images.file, Tags.is_over18, FavImages.user_id
FROM Images
JOIN LinkedTags ON LinkedTags.image = Images.image
JOIN Tags ON Tags.id = LinkedTags.tag_id
LEFT OUTER JOIN FavImages ON FavImages.image = Images.image
WHERE Images.image = '0c6dd5f3cf18ec4'
AND FavImages.user_id = 124910128582361092
what's left outer?
FavImages.user_id will be null in the result set if there is no entry
thats exactly what i was looking for
i'll search what is left outer 🤔
An OUTER join will result in NULL if there is no entry which fulfills the join.
ah but
ahh
ok i think
i understand
nevermind
oohh
so
it means that
the WHERE doesnt affect the other column
idk howto explain properly
but i think i understood
thanks a lot
Berndulas and Bluenix
well
it doesnt set user_id to null it just doesnt return anything
so finally no
where restrict all the query
Ah, sorry about that but you can move the AND condition up to the join line, it should work there.
oh
you can
have condition like this in a join
ooh
i'm dumb
well
no finally
but it doesnt make sense
my bad
ok
it works
i understand
I just learn something, i thought you could only give the 'common thing' beetween 2 table in a join condition
thanks a lot
really
haha 😅
hello
does anyone here hv experience with creating a SQLite schema with JSON using sqlalchemy ORM?
hey, is it possible to order_by 2 functions with sqlalchemy? i want to order by asc and if there are multiple rows with the same number then i want to choose a random row
something like ORDER BY something, random()?
can anyone here tell can i link a msql database wit python??
not sure what you mean with link, but you can connect to one
in fact there are a multitude of libraries that help you with doing that
i think aiomysql works with mariadb https://aiomysql.readthedocs.io/en/latest/
aiomysql is for MySQL right?
it says it's based on pymysql which appears to support both mysql and mariadb
follow the instructions in the docs 🤷♂️
usually you need the database server url and a username/password
Forget aiopg I am switching back to asyncpg
how i can use dc in discord.py?
DC?
How can i start into the world of databases?
@austere zealot Do the "PostgreSQL for Everybody" specialization course on Coursera. A really nice introduction. Also, maybe read some books if that's your case or there are plenty of free yt video tutorials.
I wonder if sqlite database in memory could be visually seen
?
if so, how?
I installed a vscode extension for sqlite but I can't see anything...
Processes cannot share memory
is it a thing that if a row is added to a table in postgres you could make data from that row get added to a new row in another table
like as soon as the new row is added
Yes. it's called a trigger: https://www.postgresql.org/docs/current/sql-createtrigger.html
they can
but not in this case
@next sun You can't really inspect an in-memory database easily. I suppose that you could write a program to copy an in-memory database into a file.
Why do you want to do that?
I see. Well, I am running tests using the sqlite in memory as after the run, the database gets back to the initial state.
but still, it would be nice to see the tables and the database I create, and more importantly the fields
@next sun If you want to debug the tests, you can use some sort of switch to configure where the database is created.
e.g. if you're on linux, you could generate a file with a random name somewhere in /tmp/, which is still in RAM, but you can inspect it
(and then delete it, of course)
wow, that sounds brilliant
but let me see if I understand
...if you don't you will obviously have issues 🙂
I think I see what you mean. I could just go and change the database from in memory to a file which would live in tmp
check the database with an sqlite browser tool
and then delete the file once I am happy
right?
yep
I wonder if there is a nice extension as opposed to install an sqlite browser tool for it
well, it's only for local development. Plus, I am using linux
I tried some of them, but an external viewer like sqlitebrowser worked best
Question for anyone who's worked with MySQLdb: Any reason an update statement would work in pdb (within seconds of running the command), but will sit and do nothing until the server loses connection outside of it?
Odd thing is, I haven't touched/changed that part of the code and it has been running for months. Now it has just stopped working.
I'm looking for an elegant way to watch for changes and replicate them between different database engines (MSSQL -> Oracle), any ideas, or experience you had with this?
Maybe is it possible via triggers (can trigger run external command?  )
)
@commands.Cog.listener()
async def on_message(self, msg):
data = get_leveling_data()
await create_leveling_acc(user, guild)
xp = data[str(guild.id)][str(user.id)]["xp"]
lvl = data[str(guild.id)][str(user.id)]["lvl"]
to_the_next_lvl = data[str(guild.id)][str(user.id)]["to_the_next_lvl"]
xp += 1
print("test")
if xp > to_the_next_lvl or xp == to_the_next_lvl:
data[str(guild.id)][str(user.id)]["xp"] = xp - to_the_next_lvl
data[str(guild.id)][str(user.id)]["to_the_next_lvl"] = round(to_the_next_lvl ** 1.02)
data[str(guild.id)][str(user.id)]["lvl"] += 1
with open("leveling.json", "w") as f:
json.dump(data, f)```
does anyone know why isn't it adding xp to the member? it prints test and I have no erorrs.Hello everyone, hope you having a great day. I am tryna learn SQL, so I downloaded it from Oracle website. https://dev.mysql.com/downloads/mysql/
But I do not know how to start the application or something. There is no button or APP laucheer or stuff like that, I can click to starrt running SQL commans. I don;'t know what to do.
normally you run a database like this by invoking the program from the command line
the database is a "server" - it is meant to run in the background listening to requests
personally i recommend starting with postgresql instead. it has more useful features and fewer weird quirks, and pgAdmin is a good tool
How do I invoke it from the command line?
I tried searching for ways to know if SQL is installed online, my CMD gave me errors when I tried it out.
Can I download postgre?
Alright, THANKS. 👍🏿
pgAdmin - PostgreSQL Tools for Windows, Mac, Linux and the Web
Anyone know why a commit() would not function as is, but works in pdb.set_trace()?
with server_conn() as sc:
sc.c.execute("UPDATE tmp_table t1 INNER JOIN other_tmp_table t2 ON t1.Id = t2.Id AND t1.Date = t2.Date SET t1.DateMatches = 'Y'")
sc.db.commit()
Additional fun, the statement functions in MySQL Workbench as well.
based on my check, it appears to be getting stuck on the sc.c.execute() function
It's hanging? Or just not updating the db?
What library is this again?
Can you reproduce the problem in a standalone script outside your application? Do other queries cause the problem, or just this one?
Just this one statement.
Hanging...no error. If I use pdb.set_trace() and walk through the lines...it runs. I'm honestly perplexed.
I'm about to just extract that portion and run it separately as part of a script on its own. Far as I can tell, there's nothing wrong with the syntax (it runs in MySQL Workbench with no error or issue. 39K Updates in <1 sec.)
mySQLdb
I'm about to just extract that portion and run it separately as part of a script on its own.
this might actually help. i suspect that maybe there's something strange in your script causing this
I'll continue the spiral down the rabbit hole. Thanks for reading!
Having said that, any reason why it does work in pdb.set_trace() just walking it line by line?
no idea, i don't really know the intricacies of mysql. but maybe there's something happening with concurrency where the server is deadlocking
whereas stepping through with the debugger causes the concurrency issue to go away
That's good insight. I'll see what I can do
Separately running it runs fine. The search continues
definitely look for concurrency issues in your application then
is with actually an open/close context manager?
or does it start a transaction like in sqlite3?
the where statement blocks my returning i think
did i put something in the wrong place here?
insert into userdata (userid, dailytime, points) values ($1, $2, 0) on conflict (userid) do update set dailytime=$2, points=userdata.points+1 where $2-userdata.dailytime > 20 returning *, $2-userdata.dailytime as diff
basically i want it to actually do
if userid does not exists:
insert data
if userid exists:
if user claimed daily more than 20 seconds ago:
update data
return the row, and the time gap
Hey everyone, please let me know if I should take this to another help channel. This is a beginner question, but I'm trying to figure out an efficient way to operate on every row in a table with sqlalchemy. Currently my script is making a single query for each row. I want to just do a session.query.all() and then work with the results from that instead. I'm just not sure of the correct syntax.
Are you trying to use every row from a table as a parameter for a follow-up query or are you trying to query the data from said table?
As far as I've read, it's supposed to handle the connection opening/closure. Having said that, performing a db.connect(), query, and then a subsequent db.close() performs identically. There's just something wrong with this one query.
I'm trying to compare the table rows to a csv then either add, delete, or update rows based on the csv.
So I'm iterating over the rows in the csv, then modifying the db depending on what's in the csv row.
Any reason you can't pull the db and compare them as pandas DataFrames?
You might have better performance, at the least.
I'll have to look into that... Just having the table in memory instead of querying every row will fix the performance enough I'm guessing.
Or, if you have the ability, create a temp table (with the csv data) and then you can perform an Update Statement using a join condition
You could also use a subsequent Delete statement with the join conditions as you need.
Depending on the importance of said data, I'd be very careful to ensure you have a backup of it
Do you know the syntax I would need to get all rows from a table, and then return a single row from that list based on the value of a column?
If you're using sqlalchemy, assuming you have an eng with a connection string. I believe I'm using ORM, but I've got my custom classes set up so hopefully this gets you in the right direction:
conn_eng = create_engine(conn_str)
metadata = MetaData()
value = 'X'
my_tb = Table('TABLE_NAME', metadata, qutoload_with=conn_eng)
my_stmt = select(my_tb.c.Column1Name, my_tb.c.Column2Name).where(my_tb.c.Column1Name == value).execution_options(yield_per=1000)
with conn_eng.connect() as conn:
for x_row in conn.execute(my_stmt):
row_data = x_row._asdict().values()
SELECT * FROM table WHERE column = ??
sqlalchemy orm syntax
¯_(ツ)_/¯
np
Working on the edit above
See if the above gets you anywhere close.
do you have to explicitly name all the columns? can't just say give me everything?
I believe if you leave select as select() then you'll get everything

Stack Overflow
Is it possible to do SELECT * in SQLAlchemy?
Specifically, SELECT * WHERE foo=1?
That may get you where you need to go. Best of luck!
I use adminpg4 to edit databases, how can I made sure that something I do isn't instantly commit / unrecoverable?
Be careful 🙂
Also don't do your general database activity as the "super user"
Create a separate account with limited permissions
That way you literally won't be allowed to e.g. accidentally delete the database
Having backups also can't hurt
Hello everyone. I have a question.
Table 1 has a foreign key (fk) from Table 2.
I am inserting a row into Table 1.
The data in the row for the fk column doesn't exist in its table i.e Table 2.
How does this work ? I have to populate the Table 2 with actual data first and then do the insert on Table 1 right ?
A real example would be a creating a new account on some website. The system has to add the data in the tables which have their coluimns as foreign keys in others first and then insert into other tables right ?
yes
yes
in general
though there are techniques that let you defer foreign key checks "for a while"
I'm coding a discord bot with aiosqlite3 as database. (In: Replit.com). The problem is that every time the bot restart, it deletes the most of my data in the database. Please help.
you need to store your data remotely
on a dedicated database.
?
all data is stored somewhere.
if you want it not to disapppear
it has to be on a computer that won't delete it
e.g. a remote database server
which is the common solution
btw I have no idea which part you don't understand
electrons are cheap; feel free to ask for clarification in a more verbose manner.
replit has a database service
Hello all~ joined this discord forever ago and never really made us of it. I'm a noob working with BeautifulSoup, ElementTree and trying to write XML files based on input from a user. I can't find my error the XML file receives all of my variables, save one. When I have the program write a random string in the same spot, it works. Anyone available? I have screenshots and snippets.
hey so im trying to integrate mongodb to my discord bot, and im referring another bot's code to add a database. that bot is in sqlite3, and i need to write mine in mongodb. so how would this code be written in mongo?
c.execute(f"SELECT prefix FROM prefix WHERE guild_id = {message.guild.id}")```add three ` before and after
Thank you!
and on the first line, write py
?
if done_add_ingred == "no" or done_add_ingred == "n":
enter_ingredients()
else:
instructions = input("Please enter INSTRUCTIONS for the smoothie: ")
instructions = smoothie_info.append(instructions)
#WORKS
s_elem6.text = "PLEASE ADD INSTRUCTIONS HERE"
#DOESN'T WORK
s_elem6.text = instructions ```but his works... ```py for i in range(len(fields_to_fill)):
if fields_to_fill[i] == "Name: ":
ingred_entry = input("Enter a NAME: ")
smoothie_info.append(ingred_entry)
#Add ingred_entry to XML for name
#THIS WORKS
s_elem1.text = ingred_entry ```

!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
pls help
I'm just a noob, sorry. Super low level understanding.
omg i just found my error, of course after too long and then finally posting somewhere
sometimes it's like that, i suppose
@golden island btw your question would've better went somewhere else
This is for databases, you would've had better luck in a personal help channel #❓|how-to-get-help or like #web-development I think?
Any advice on what would be the best way to track new row inserts in a specific table on a local db (sqlite) to execute on? Been googling and there's some mentions of using triggers?
Context: Trying to make a kill feed for a game which logs events into a local db and need to continuously grab the latest event to check for new death events.
Right now I have it looping a select query but that's causing it to keep outputting the last row in the event table constantly.
Code: ```py
def select_events(conn):
conn.row_factory = sqlite3.Row
cur = conn.cursor()
# cur.execute("SELECT * from game_events WHERE eventType=103")
cur.execute("SELECT * from game_events WHERE eventType=103 ORDER BY ROWID DESC LIMIT 1")
rows = cur.fetchall()
for row in rows:
victim = row["ownerName"].encode("ascii", "ignore")
killer = row["causerName"].encode("ascii", "ignore")
victim = victim.decode()
killer = killer.decode()
ts = None
curr_coords = row["z"]
prev_coords = None
if curr_coords == prev_coords:
pass
else:
if row["causerName"] == '':
prev_row = row[0]
print(f"{victim} died.")
prev_coords = row["z"]
else:
prev_row = row[0]
ts = int(row["worldTime"])
debug_ts = datetime.utcfromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
print(f"{debug_ts}: {victim} was killed by {killer}")
prev_coords = row["z"]
```
Still a beginner so a little in over my ahead / overly ambitious 😄
So whenever something dies, you add it as an event to the database. Then you want to poll the database for the latest event and react to it?
Yeah, pretty much - game adds it as event to db. I need to poll latest and output
Why can't you just call the function to handle it directly?
You can just add the ROWID to the result and remeber it.
Spread over multiple processes? Do they not share memory?
@faint blade maybe i'm done but i thought xml was a database of some sort?
@faint blade i'm working on this as a side project for work....hope to be pulling data from their database and be able to manipulate it/save it outside
Xml is a file format
@faint blade i feel like i rolled a nat 1
Your problem was a programmatically one:
instructions = smoothie_info.append(instructions)
#DOESN'T WORK
s_elem6.text = instructions```
You reassigned the return value of the `append()` method of a list to `instructions` (which is `None`). So not a XML one ;)https://hastebin.cc/pumixawadu.py so I got this webhook, the first if statement is executed when a product is viewed by a customer on my website, the second one is executed once that product viewed by that specific customer also has been purchased.
So I got all products that customer has viewed before he made a purchase.
How can I now link this data (data = what products P has customer X viewed that he has not purchased?) to what he actually has purchased?
(I want to store that specific data in my db somehow and remove all entries of products the user actually has ordered on purchase)

Okay so I want to basically store all products viewed by customers in my db with: customer_product_view_id, image_url, product_id, ordered(Boolean)
When my code logic meets the 2nd condition (the product viewed was subsequently ordered), I would like to store: order_id, customer_id
When the 2nd condition is met, I also want the ordered column of the viewed products table to be updated from False to True
So that I in the end can query the db "Show me all products of customer X that have been bought" or "Show me all products that customer X has viewed"
You get the idea?
I'm using pscopg2 and when we do fetchone, does it always return a tuple?
@mortal light a row is always a tuple, yes
it will return None if there are no results to fetch
@mortal light You can also use psycopg2.extras.DictCursor (Docs: https://www.psycopg.org/docs/extras.html#dictionary-like-cursor) if you'd prefer the cursor to be more like a dict (although it's not a standard dict so be careful).
Thanks, salt rock and Shell!
I'll look at DictCrusor!
Need some help with Tortoise ORM right now, been getting
OperationalError: column "suggester_id" of relation "suggestions" does not exist , Things I have tried:
- check spelling
aerich migrateandaerich upgrade- rebuilding the database as a whole
in pymongo, is it possible to use collection.find() to get all documents that dont have a specific value for a key?
Hey, so im new to databases, and im looking at the code of an open source bot as an example, but its in sqlite, and im using pymongo. how would this line be written in pymongo?
c.execute(f"SELECT prefix FROM prefix WHERE guild_id = {message.guild.id}")```prefix = collection.find_one({"guild_id": message.guild.id})
collection.find({'someField': {'$ne': value}}) maybe? https://docs.mongodb.com/manual/reference/operator/query/ne/

ty
can i follow a tutorial that uses mongodb or sqlite3 if im using mysql?
not with mongo at all. with sqlite3, the basics will be the same, but there are enough differences that you should try to find something specific to mysql.
oh ok
i have setup redis broker for celery and i want to use redis db for recommendations as well, is there a configuration i need to do to prevent conficts?
Hello, I have a problem with Peewee. Why is this not setting the attribute Product to what comes from the Product table?
brochure_id = 68021524
query = (item_file_det.select(item_file_det, item_file, item, prod)
.join(item_file, on=(item_file.id == item_file_det.itemfileid), attr="ItemFile")
.join(item, on = (item_file.itemid == item.id), attr="Item")
.join(prod, on = (prod.id == item_file_det.productid), attr="Product")
.where(item.id == brochure_id)
)
for q in query:
q.Product
AttributeError: 'ItemFileDetail' object has no attribute 'Product'
but if I move join(prod) to first I can access it
I haven't used it, but I guess that you have to run the query after building it, so it fetches the objects from the database
I have a question too. What database would be the best to keep directed graphs in? The graphs are intended to be complex quizes. I guess a real graph database is overkill for that
And I'll have to validate the graphs so they aren't cycled and there is no stray nodes
Hello greatings everyone, I wanted ask if anyone has tried this: create two models in two different package and then setup a one to one relationship between them.
using sqlalchemy
This is leading to a circular import and I have tried some tricks like importing one of the models inside the class of the other, but the circular import still persist. Any ideas on this?
Hi,is there possibility that i make data base using python for my node.js app??
You want to make a backend server that uses a database?
Yeah kinda,i have discord bot and i want a db for it and i am asking if i can connect python database to node.js app
Is your Discord bot in Node.js?
Yes
Then why do you want to use a database with Python?
Postgres is the most painless SQL database (other than SQLite), which you can use with this module: https://node-postgres.com/
i kinda need it,it has some sort of checking for specific emojis and conent of messages and i want easy way to add more stuff messages and emojis to script
oh ty ❤️
will look into it
hello
I'm using firebase for my discord bot database but i got a mail from firebase that i need to set my rules otherwise they will denied all the services. can someone help me how to set rules on firebase?
Can you show the email you got?

do you need to download postgress to use it or can you install it with pip and use it
you need to install the postgres database itself, and then the python connector (psycopg2) to use it with python
thank you. no I have the values for FROM part of the database (item_file_det)
How do you generate that ER Diagram ? Is it automatic or you made that my yourself ?
made it myself
@torn sphinx Oh. I use Dbeaver to draw an ER diagram from my existing tables.
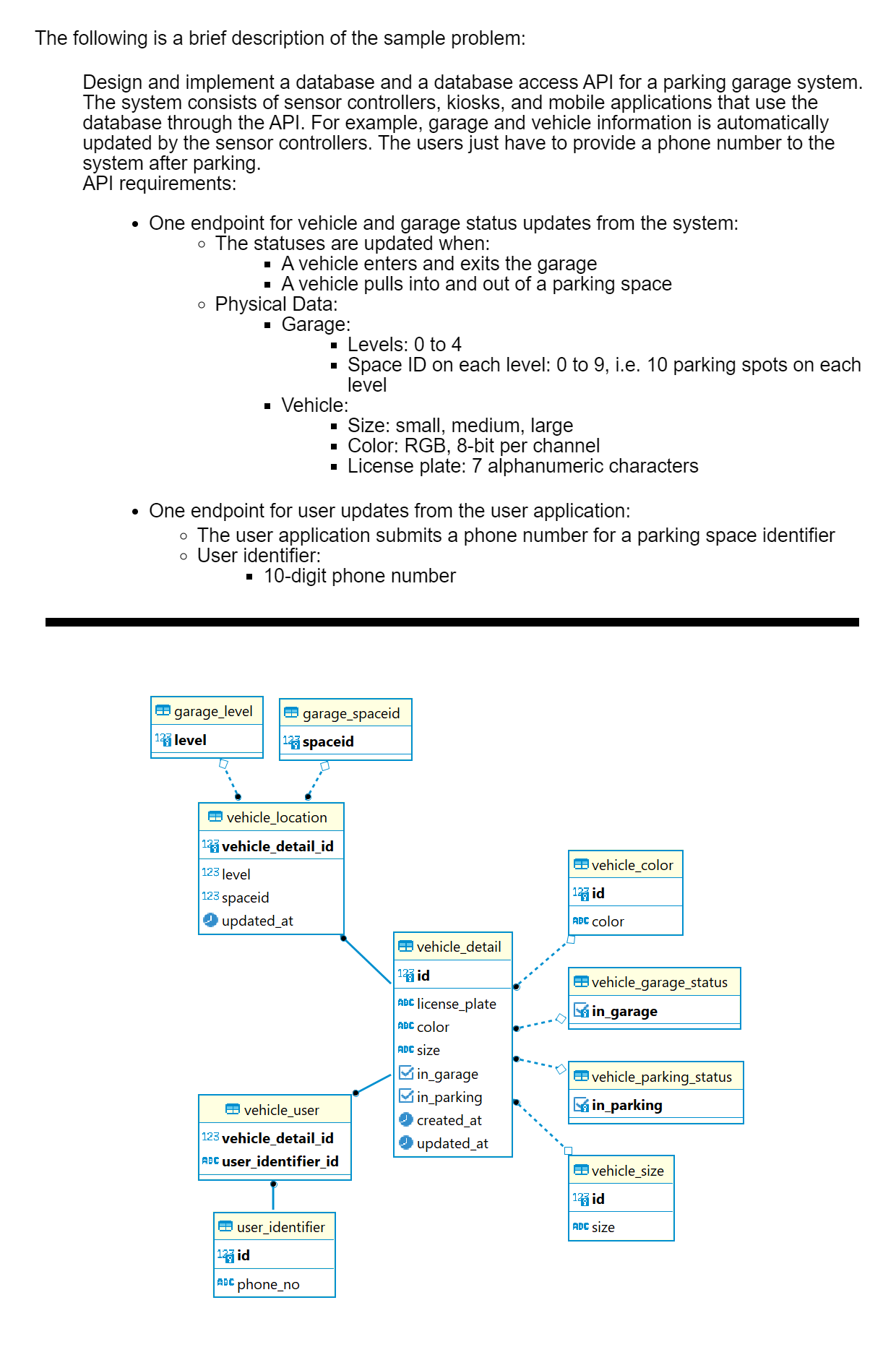
This is my requirements and my schema for it.
Any comments on this ?
https://i.ibb.co/vX9fw4G/image.png
I have two questions.
- Should a foreign key always refer to the
idcolumn of another table ? Why or why not ? Is there a standard rule for this ? - Is there a cost associated with using any other unique column other than
idcolumn for foreign key ? Performance / storage ? How significant ? Is it frowned in the industry ?
Stack Overflow
Should a foreign key always refer to the id column of another table ?
If yes, why ? If not, why not ?
Is there a standard rule for this ?
Example:
This is the schema for my sample problem.
In my s...
This is the question if anybody want to know
guys i'm trying to collect data from a online game, so i was thinking about how i can do a reverse engineering with python to collect data from a online game, someone know where i can start to learn about that?
Does python have an inbuilt database thing? or do i need a server or something to setup a database?
Basically I want to setup a database without needing the internet or something like xampp.
@warped turtle Python does have an inbuilt database
if there is a package you don't have
use the pip install command
Thanks for taking the time to respond. Is there any good getting started guides?
That is something I would like to avoid as it could interfere with the insert / delete / update statements and performance.
Check this https://stackoverflow.com/a/12975327
Stack Overflow
Hello and thank you for your time,
I have been searching everywhere online for an example, where a SQL trigger will run an external application, but I have had no luck. All I am seeing is that th...
Have you seen what the "Read the docs" and "Edit rules" buttons show?
This should help:
https://firebase.google.com/docs/firestore/security/insecure-rules
thanks for the link, but this is what I would like to avoid. Also, not all RDBMS have possibility to execute external applications. I am looking for some other way. The worst would be to query candidate table every x-seconds interval and then act on the new rows / modified rows.
I am working on an internal web application with a Flask backend for editing projects which data is stored in a database. For illustrative purposes, suppose that the database has the following two tables:
[projects]
project_id int PRIMARY KEY
name varchar(255)
[data]
data_id int PRIMARY KEY
data_attr float
project_id int FOREIGN KEY
Considering that the data of a project only takes up about 16 MB and the number of users is limited, when a project is opened, the data for that project is queried from the database and stored in memory as a pd.DataFrame on the backend until it is closed. To avoid edit conflicts, no other users may edit the project until it is closed by the first user. As the user navigates through the project, the frontend sends requests to the backend which queries the pd.DataFrame to display a subset of its data. Whenever the user adds, modifies or deletes any of the data on the frontend, a request is sent to update the pd.DataFrame accordingly. Note that in any case, the database is not updated until the project is saved (see below) - only the pd.DataFrame is modified.
To save a project, a request is sent to the backend, which overwrites all of the data for that project in the database with the contents of the pd.DataFrame. Currently, I am implementing this by running one SQL statement to delete all of the entries in the data table where project_id equal to the project's ID, then another SQL statement to insert all of the entries in the pd.DataFrame into that table.
Questions:
- Is there a way to combine these two statements such that it can be completed within a single transaction?
- Is this approach of saving a project efficient (in terms of speed)?
- Taking a step back, are there fundamental issues with this design?
How often, much, and important are these changes?
Is it kind of like settings where you're supposed to change a few things then save?
i need help
To be more concrete, a project represents a 3D video, where each frame contains some objects to render. The database stores the attributes of those objects (e.g. size and position). The user can go to any frame in the video and edit the objects within. I would expect the user to save at least once per frame edited.
Since each object can appear in multiple frames, changes in one frame can affect other frames, so for simplicity, the whole project is saved each time
i dont think that a relational database is that suited for the task
i mean you can do it but smt optimised for blob or object storage would probably be more easier to work with
that said there is an upsert query
which overwrites existing data or creates a new entry depending on the existance of a row with the primary key
I'm currently using a column-oriented DB for the task
 which one?
which one?{kind=link}
ClickHouse
ok so i dont know much about clickhouse, but from what it seems like that this doesnt seem like the intended usecase, but again i might be wrong
From what I've read, this database favours large but infrequent batch operations, which is perfect for this
fair enough
still i would've gone with smt like scylla or object storage, but your project your architecture
anyways enough of that, did the upsert query work?
yes, https://docs.python.org/3/library/sqlite3.html. here are the docs for the library, they give a cursory introduction
Doesn't seem like it's supported
thats unfortunate
What if they don't save? Will you do some auto-saving?
Because that was my concern
What if it crashes?
Yes, there is auto saving
I am thinking of saving the dataframe to a temp file periodically, that way the data could still be recovered if the backend crashes in the middle of executing the delete-insert statements
im getting an error for my mod logs system (discord bot) using sqlite3
the error is "parameters are unsupported type"
@snow nicheyou want do something with unsupported type like
insert function parameter only accept tuple
try:
conn = self.conn
cursor = conn.cursor()
cursor.execute(f'SELECT channel_id FROM mod_logs WHERE guild_id=?', (ctx.guild.id))
channel = cursor.fetchone()
ch = self.bot.get_channel(channel)
em = discord.Embed(
title = 'Member Kicked',
timestamp=ctx.message.created_at
)
em.add_field(name='Moderator', value=ctx.author, inline=False)
em.add_field(name='Member', value=member, inline=False)
em.add_field(name='Reason', value=reason, inline=False)
await ch.send(embed=em)
except Exception as e:
print(e)
``` this is what i have rn, how can i make this work?change (ctx.guild.id) to (ctx.guild.id,)
will that work?
ok
'NoneType' object has no attribute 'send'
can i get support here for mysql??
yep ofc
Well, sorry, you could not find the answer. I hope you will find the answer
maybe the channel it returned is None
but im storing it right?
use print to show whether it is a channel or None value
print ch ?
yes and channel too
hey i want to change a column parameter ( i mean when i created that table i enter create table new(name int not null default 0) but now i want to change it to (name bigint not null default 0) so what will i use
oh XD I forgot that
lol
share the ddl command
ddl?
The command u used to make the table
class Mod(commands.Cog):
""":moderation: Moderation Commands"""
def __init__(self,bot):
self.bot = bot
self.conn = sqlite3.connect("db's/moderation.db")
self.c = self.conn.cursor()
self.c.execute("""CREATE TABLE IF NOT EXISTS warns_data
(guild_id int, admin_id int, user_id int, reason text)""")
self.c.execute("""CREATE TABLE IF NOT EXISTS mod_logs
(channel_id int, guild_id int)""")
the warn commands all work.. that is the warn_data
change the datatype from int to bigint
ok
channel_id and guild_id?
.
yes
😔
bruh
ALTER TABLE
ch is None if the channel cannot be found in cache
so this returns channel id?
channel = cursor.fetchone()
idk im confused now
trying from months... then gave up
eventually i have to do this
How can i set the limit int of a column is infinity?? ( i tried bigint but it limited )
mysql*
That's impossible
When do you need numbers bigger than like quintillions (rough guess of BIGINT size)?
so im making a command for my bot which allows users to set custom prefixes in their servers. im using mongodb, but the tutorial im following uses postgreSQL. im trying to convert the code and follow, but im stuck in this part:
db = cluster["discord"]
collection = db["prefixes"]
if not message.guild:
return commands.when_mentioned_or(DEFAULT_PREFIX)(client, message)
prefix = await collection.find_one({"guild_id": message.guild.id})
if len(prefix) == 0:
await collection.insert_one({"guild_id": })
The video im using is:
https://www.youtube.com/watch?v=fnsN1HZLyrk&t=0s
i have defined the DEFAULT_PREFIX variable, its just outside the function
the timestamp im at is at the 6 minute mark
well ig we dont need to work on custom prefix bcz of discord's update
slash cmds only
yea
damn
thats why danny quit as maintainer of dpy
can some1 help pls
channel = cursor.fetchone()
if it does find an entry channel will be a tuple, you'll need channel[0] for the id.
...
cursor.execute('SELECT channel_id FROM mod_logs WHERE guild_id=?', (ctx.guild.id,))
channel = cursor.fetchone()
if channel is None:
print("no channel_id found")
return
ch = self.bot.get_channel(channel[0])
...```I did that, but returned another error
'NoneType' object is not subscriptable
channel is None
So it's actually not storing?
psycopg2 - I used execute in a for loop, but it was slow and came across execute_values:
https://stackoverflow.com/a/30985541
https://www.psycopg.org/docs/extras.html#psycopg2.extras.execute_values
I have used context manager with other database methods, so I wanted to keep it consistent.
Is below the proper use of context manager and insertion of data to postgres?
with self._connection.cursor() as cursor:
psycopg2.extras.execute_values(cursor, query_with_table, list_of_value_tuples, template=None, page_size=100)
Does page_size mean how many tuples will get processed at a time? so in this case 100 at a time.
Most up voted way didnt seem safe because it concatenates the query and values which could lead to sql injection. Any thoughts on that also?

This is what my method looks like:
def _db_insert_many(self, ebay_info_instances:List[EbayInfo]) -> None:
"""
Method inserts a list to the database
"""
# {} denoates table name
# %s denoates values being inserted
list_of_value_tuples = []
for each in ebay_info_instances:
current_tuple = (each.store_name, each.item_id, each.manufacturer_part_number, each.date_ebay_api_request_made_in_epoch_seconds)
list_of_value_tuples.append(current_tuple)
query = """
INSERT INTO {}
(ebay_store_name, ebay_item_id, ebay_manufacturer_part_number, date_ebay_api_request_made_in_epoch_seconds)
VALUES %s
"""
query_with_table = sql.SQL(query).format(sql.Identifier(self._table_name))
print("Inserting data. This can take a moment...")
with self._connection.cursor() as cursor:
psycopg2.extras.execute_values(cursor, query_with_table, list_of_value_tuples, template=None, page_size=100)
Hello, I have a trouble with this command
cursor.execute("""UPDATE member SET Pseudo = speedy WHERE id = 8823482957107364""")
why I get this:
sqlite3.OperationalError: no such column: speedeux
the column name is Pseudo
is it supposed to be ID all uppercase?
No
It was supposed to be uppercase but it still sending the same error message
Are you grabbing pseudo column from the right table(which in your case is member)?
yes
it the only table I have for now
I use it in:
def member_edit_name(member_id, new_name): print(member_id) print(new_name) cursor.execute("""UPDATE member SET Pseudo = {} WHERE ID = {}""".format(new_name, member_id)) database.commit()
Which print:
8823482957107364
speedeux
the table look like:
""" CREATE TABLE IF NOT EXISTS member ( ID int PRIMARY KEY UNIQUE, Pseudo text, Balance int DEFAULT 1000, Earned int DEFAULT 0, Lost int DEFAULT 0, Post text DEFAULT 'Stagiaire', Experience int DEFAULT 0, Salary int DEFAULT 0, Composition text DEFAULT '', ContributePoint int DEFAULT 0, Contribution text DEFAULT '', ActyToday int DEFAULT 0, ActyWeek int DEFAULT 0, ActyMonth int DEFAULT 0, Here int DEFAULT 1 )"""
You are trying to update the column name from Pseudo to speedeux, where ID is 8823482957107364?
yes
There's a lot that I dont know about databases, so I'm just baffled we can do that... o.O'?
I try to update in column named Pseudo of the member with the ID 8823482957107364 to speedeux
don't worrie, someone else have an idea ?
When we use context manager to fetch data, does it matter if the return is inside the context manager or outside?
def db_fetch_all(self) -> List[tuple(int, str, str, str, int)]:
query = """
SELECT * FROM {}
"""
query_with_table = sql.SQL(query).format(sql.Identifier(self._table_name))
with self._connection.cursor() as cursor:
cursor.execute(query_with_table)
result = cursor.fetchall()
return(result)
or
def db_fetch_all(self) -> List[tuple(int, str, str, str, int)]:
query = """
SELECT * FROM {}
"""
query_with_table = sql.SQL(query).format(sql.Identifier(self._table_name))
with self._connection.cursor() as cursor:
cursor.execute(query_with_table)
result = cursor.fetchall()
return(result)
Actually I guess I would have to put return inside the context manager, in case there's a failure in fetching data. So leaving return inside the context manager would act as a try.
https://stackoverflow.com/questions/9885217/in-python-if-i-return-inside-a-with-block-will-the-file-still-close
Yoo guys
https://cdn.discordapp.com/attachments/704067023939960985/888179252455936020/unknown.png
Cause I have made so many rows but then deleted it manually from my database after my code for some reason remembers the ID for before even though after me deleting the rows it should start at 1
but its starting at 114 then 115 etc
{kind=link}
print("Account has been Registered!")
mycursor.execute("INSERT INTO login_details(username, password) VALUES (%s,%s)", (entered_user, entered_pass))
db.commit()
Not sure if this is to do with it

you can return inside
Yeah thanks!
You have the id set to auto-increment? That's normal
Yeah I wanna reset it to 1 though
how can I do that?
I don't believe you can do that easily, and in general you can't rely on them being consecutive
What database is this?
mysql
I wouldn't worry about it, IDs are meant to be "internal" anyway
Stack Overflow
How can I reset the AUTO_INCREMENT of a field?
I want it to start counting from 1 again.
thank you
@harsh pulsar where do I put ALTER TABLE tablename AUTO_INCREMENT = 1
in mysql?
any one know where to find some good datasets
im doing an econometrics research project
and am looking for a topic
kaggle? https://www.kaggle.com/datasets
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
thanks king
For econometrics research you might want something more "economic" in nature. For example the FRED data or stuff from various other US agencies like the Census, BLS, etc.
yea that's a good point. This is for my first paper in my introductory econometrics course so I am a bit ignorant. As long as I prove casualty between two variables I will be fine, doesn't have to be purely financial.
Causality? I assume they mean Granger causality
Wondering if someone can tell me what they think of this method insert many please. And if context manager is used properly.
How can i set the limit int of a column is infinity?? ( i tried bigint but it limited ) in mysql
does python directly support SQL operations?
SQLite is a database that's stored in a file format, delete the whole file. You should have a .db or .sqlite file.
Thank you. I figured it out a while ago on my own. Should've said something I know. But thanks anyway for taking the time to reply ^-^
Using the "lang" method, the correct sql command to delete from a database is:
(delete from <table> where id=? and other=?), (id,other)
cur.execute('DELECT FROM table WHERE id=? AND other=?', (id, other))
```?Yes that looks correct in terms of removing rows
That said, it's usually risky and often never done. You really don't want to forget data.
That's why many instead of deleting rows, somehow mark them for removal. Every now and then they do an audit and look at how many rows have been marked, then delete them.
Depends on what data it is you're removing, thought I'd mention it though.
@faint blade I'm creating a 'tempmute' function for a discordbot and i don't see a reason to keep the users information in the database once they've been unmuted
Why not? Wouldn't you want to look back on the history?
I could move the data elsewhere I guess. 🤔 but with the way I got it setup, it wouldnt work to keep the data there
While I agree with you that hoarding data is best. coz i too like to hoard data. In this instance I don't want to keep this particular entry in the database
@faint blade If you want, you can review my code and maybe you can offer me advice on how to improve it.
;D
This isn't about hoarding data to have fun with statistics..
Wouldn't you want to know if you have muted someone 5 times before?
Of course. But for now. I just want to get the basics down. Later on I'll expand it.
I've only just started learning to do database stuff with python
it's surprisingly very similar to the PDO method used in PHP
I think you should add a column to the table called "active" that's a boolean, you can then set it to False when the mute expires
i honestly have no idea why that never occured to me
i'm here like 'it cant be done. no. it'll ruin EVERYTHING.' and you're like 'just do this.' ;-;
So quick question @faint blade - How is a database better than a json file? both create a file on my computer.
So why would I want a database over a json file? 🤔
Coz parts of my code before getting this database stuff going is saving to a json file.
its not easy to query data in json files
adding data to json files might mean rewriting the whole file
reading numbers is expensive due to expensive parsiung
Databases are designed to store huge amounts of data efficiently.
The only way to work with JSON is if you parse the whole file into memory.
SQL can efficiently find data according to different ways you decide to filter it. Try finding all mutes that have expired, you would loop through each mute and check if it is expired.. SQL databases can create indexes and do this as efficiently as possible according to all knowledge known in computer science.
The possibility of corruption is incredibly low, databases are designed to do everything else but corrupt the data.
You have smart transactions and ways to make sure everything success or nothing does.
How can i prevent SQL injection attacks? My program requires a user to authenticate with an id and password and i'd like the transaction between the main file and the database to be secure, even if the only user here is me
sqlite3.OperationalError: database is locked how to unlock it tho?
Either the database is locked to edits (Read only) or some unfinished process still has the database open
some unfinished process still has the database open
how to kill it?
Either the database is locked to edits (Read only)
and how to make it editable
How to kill whatever process is using it? Its kinda hard considering you dont know what process has the database open
How to make it editable, right click the database in File Explorer, hit Properties and ensure Read Only is unticked
its unticked already actually
Good, strange that it wont let you edit it though
Its kinda hard considering you dont know what process has the database open
I only do regular sql expression (select, insert into)
That... means nothing. The queries you give it dont affect access
If the database has no connections active, the first process to connect to it gets controlling interest for the database
- and delete from
guys how do i update my database instead to replicate the row when i already have a the primary key?
Hey guys what database you suggest for python?
sqlite, postgresql
I think you are referring to Upsert. Look it up along with the db server you are using and the should be some examples. I’m only familiar with upsert in Postgres.
Use UPDATE query, which DB are you using?
mysql
INSERT INTO talent (Users, Localization, WorkFor, Website, Twitter) VALUES ('None', 'None', 'None', 'None', 'None') ON DUPLICATE KEY UPDATE VALUES Localization='None', WorkFor='Pera', Website='None', Twitter='None';
UPDATE talent SET Twitter = 'twitter' WHERE Website == 'website'
but in this way i only able to update if i know the where (in which case),
the database will receive the data automatic so i should be able to update based
on if the primary key already exist
in this case is my Users
You need to know some informations when you want to update certain row (I like to have auto increment id column)
yeah, i wanna do that
if i use this query how i would be able to update for each case that already has a key on mydatabase, instead to write manually?
You have ON DUPLICATE KEY UPDATE in your INSERT query so it should update automatically when detects duplication
mysql> INSERT INTO talent (Users, Localization, WorkFor, Website, Twitter) VALUES ('None', 'None', 'None', 'None', 'None') ON DUPLICATE KEY UPDATE VALUES Localization='None', WorkFor='Pera', Website='None', Twitter='None';```Can you show me columns declaration?
mycursor.execute('CREATE DATABASE IF NOT EXISTS github')
mycursor.execute('USE github')
mycursor.execute('''CREATE TABLE IF NOT EXISTS talent (
Users VARCHAR(50) NOT NULL,
Localization VARCHAR(50) NOT NULL,
WorkFor VARCHAR(50) NOT NULL,
Website VARCHAR(50) NOT NULL,
Twitter VARCHAR(255) NOT NULL)
''')
wow
I see that i dont have a primary key ...
uhm...
😅
Uhm 😛
whats wrong with this
MongoDB question - how can I update the document, then roll back the update in the DB if the send_payment function didn't complete in x seconds after the update (in this example the server that ran the function explodes so it will never complete)?
def send_payment():
print("Updating bob's status...")
collection.update_one(
filter={"user": "bob", "paid": False},
update={"$set": {"paid": True}},
)
print("Updated bob's paid status to True")
print("Sending payment to bob...")
input() # Boom server exploded, the script doesn't go further and the paid status update needs to be rolled back to False
send_payment_to_user(user="bob", value=100) # Nope not gonna happen
print("Payment sent to bob") # Nope
print("Everything went smoothly, no need to roll back the update") # Nope we exploded
I've looked into transactions (https://pymongo.readthedocs.io/en/stable/api/pymongo/client_session.html) but not sure how to handle a rollback, as in commit the update, but revert it if the transaction didn't finish in some time (instead of only committing at the end of the function, that'd be pointless in this scenario as the payment could've been sent but the status never got updated because the script never got to the commit point)
I've tried this:
def send_payment():
with mongo_client.start_session() as session:
with session.start_transaction():
print("Updating bob's status...")
collection.update_one(
filter={"user": "bob", "paid": False},
update={"$set": {"paid": True}},
session=session
)
print("Updated bob's paid status to True")
print("Sending payment to bob...")
input() # Boom server exploded, the paid status update needs to be rolled back to False
send_payment_to_user(user="bob", value=100) # Nope not gonna happen
print("Payment sent to bob") # Nope
print("Everything went smoothly, no need to roll back the update") # Nope we exploded
But paid doesn't get updated when the update function runs, only if the function finished properly (which it won't)
i think normally in a transaction you have to perform the rollback while the transaction is still open
frankly i'm not sure you need a transaction in this case.. you could do it entirely "in software"
But how do I roll back from a script that is already dead?
Oh, can you elaborate?
don't update alice's status until you're sure that the payment was sent successfully to bob
although in that case you could end up with the opposite problem - bob gets money but alice never loses money
Yes that's my issue
fwiw i don't think this is mongo's strong suit
Hence why I wanted to update first, but then roll back if the function didn't complete in x seconds or within the session or something
That said, this might answer your question
Upon normal completion of with
session.start_transaction()block, the transaction automatically callsClientSession.commit_transaction(). If the block exits with an exception, the transaction automatically callsClientSession.abort_transaction().
Yeah there is no exception
There is just boom
That's what my issue is with this scenario
well if the python process explodes so badly that it can't even run try/except then you might be in doodoo
or maybe the server does the right thing and rolls back?
it's a good question... let me see if i can find it in the docs
the other option is to update both records in the DB simultaneously, if such a thing is possible
In my example the DB is obviously not running on the server that runs this function and explodes, so I want to rollback on the DB's end
https://docs.mongodb.com/manual/core/transactions/#transactions-and-sessions
If a session ends and it has an open transaction, the transaction aborts.
I was looking for something like how a message queue handles such things
so it seems like mongodb does the right thing, but the rest of the doc suggests that you need some fairly specific settings to actually make transactions work in mongo
I figured out the commit/abort part, but the issue is that you cannot abort after you've committed already
this is pretty heady stuff, i wouldn't feel comfortable configuring mongo for this task without taking a course on it
well right, but you haven't committed yet in this case
Yes but if I haven't committed the document doesn't update either
as per your code, your client catches fire and melts while the transaction is still open
I want it to update, and then revert
so the transaction will roll back because the client session will eventually time out after the computer melts, and the server will end it
Yes but I want to update the status first, then it explodes, and then the DB server rolls it back because it never finished
Oh
yes that seems to be what will already happen in your code
however you should test it
But that ain't the case unfortunately, the document doesn't change
what do you mean?
The paid status isn't updated by the time it reaches the input()
It's only updated if I comment out the rest and simulate a successful run
Let me try again just to make sure but I've tested it like 20x
Yeah if I just sit at the input() then paid just stays False
It should be True by that point
And then I simulate the boom, it should be rolled back to False
But I'm not really understand why it's not updated and then rolled back instead of not updated at all unless it finishes properly
well that's because the transaction isn't committed
try it with sqlite, that's how it works by design
But then the whole purpose of this is pointless?
In this case then it's the same as if I just moved the update function to the end of the function
i'm not sure what you mean by that
it wouldn't be "atomic" if it was like that
and im curious, why would you even want it?
Do nothing - wait for successful payment - update document
Update the document - wait for successful payment (never happens) - roll back because successful payment didn't happen
imagine alice seeing that the payment was accepted and closing her browser, then 30 seconds later she gets an email saying it was rejected after all?
No it's not like that, it's for a payout system
If I send the payment, then mark it as sent, but the server died before it marked as sent...
It will send it again the next time it runs
but sure, you might want to move the update to the end anyway
Don't you see the issue?
why would it? it's inside a transaction, the server explodes, you never even get as far as sending the payment, so the transaction rolls back and no harm is done
right, that's what you currently have, and it's the right thing to do
That's the catch
what do you mean?
Bruh lol
it will be updated when the transaction completes
...
How does the DB update if the server exploded before it could update the DB... but already sent the payment?
Send, explode, update DB
That doesn't work
is this what you're worried about?
- update local db
- send payment
- server explodes
- transaction is committed (you never get this far)
There is no local DB
"local" meaning your mongo db
i assume sending money means sending it to some other system?
In your example step 1 never happens because it would only happen at step 4
It never updates, it would only update when step 4 is reached
But that is useless in this case
Am I missing something?
that isn't the code snippet you showed me
This is what I've got recommended
i think they were recommending what you already have
Yes
so what's the issue?
But what I have doesn't work the way they said it should work, it was just my spin on it
i'm not following
def send_payment():
with mongo_client.start_session() as session:
with session.start_transaction():
print("Updating bob's status...")
collection.update_one(
filter={"user": "bob", "paid": False},
update={"$set": {"paid": True}},
session=session
)
print("Updated bob's paid status to True")
print("Sending payment to bob...")
input() # Boom server exploded, the paid status update needs to be rolled back to False
send_payment_to_user(user="bob", value=100) # Nope not gonna happen
print("Payment sent to bob") # Nope
print("Everything went smoothly, no need to roll back the update") # Nope we exploded
My original question
i'm talking about this
How is something like this handled in production?
def send_payments():
unpaid_users = [i for i in users.find(filter={"paid": False})] # Create a list of unpaid users from the DB
for user in unpaid_users: # Current user: bob
send_payment_to_user(user=user["user"], amount=user["amount"]) # Send payment to bob
users.update_one(filter={"user": user}, update={"paid": True}) # Update bob's paid status to True in the DB
Let's say the server that runs the script explodes just after it finished send_payment_to_user() but before it started users.update_one(), so it sent the payment but it didn't have time to update the user's paid status to True in the DB, which means if this script starts again, bob's payment will be sent again. What's the solution for handling such issues?
Yes I know
The one you copied doesn't do what I want it to do
it sounds like you're asking two different things
The one I just copied is the original issue
The one you copied was my solution
... my broken solution
i see that, and it looks like you solved it more or less the right way
i still don't understand what's broken about it
The document NEVER gets updated to paid: True
I want it to update to True, but revert if the function didn't finish
def send_payment():
with mongo_client.start_session() as session:
with session.start_transaction():
withdraw_from_user(user="alice", value=100)
server_explodes()
send_payment_to_user(user="bob", value=100)
That ain't how it works
is that not more or less what was in the code snippet you posted above?
oh, i see
(probably should've said that earlier)
yes, i think there were a lot of details missing here
Yeah sorry let me try to make a less confusing example
with mongo_client.start_session() as session:
with session.start_transaction():
mark_paid(session, user="bob")
server_explodes()
paypal.send_payment(user="bob", value=100)
so this is what you have now?
Yes, but it never gets marked as paid as it would only get committed if server didn't explode
but the server explodes before the payment is sent to paypal!
with mongo_client.start_session() as session:
with session.start_transaction():
mark_paid(session, user="bob")
paypal.send_payment(user="bob", value=100)
server_explodes()
this is what you're worried about, it seems?
I'm worried about it exploding before it sends, because then the payment never happened
I think...
I'm just as lost as you are at this point lol
Basically my concern is
I don't want to send payment twice
So if I send, then mark paid
There is a chance that it never gets marked as paid
But it has been paid
Right?
if the server explodes before the payment sends, the payment never gets sent and bob is not marked as paid
Send, explode, mark paid (-$100 but not marked as paid, so will try to send again)
Oh
Right
if the server explodes after the payment sends but before the tx is committed, then yes bob gets paid twice
My example is messed up
so there is a small window in which explosion results in bob not being marked as paid even though the payment has been sent
but that is after sending payment and before the tx is committed
this:
with mongo_client.start_session() as session:
with session.start_transaction():
mark_paid(session, user="bob")
paypal.send_payment(user="bob", value=100)
server_explodes()
in which case... yeah, i understand the use case. no idea if there's a way to do that in mongo.
And even if it's the other way around