#databases
1 messages · Page 115 of 1
But the users are already in the database?
But the users are already in the database?
@modern mulch sure, but I want to let this user register from another server
Is the user not in the other server in your database?
yea
Hmm I don't see anything wrong in your code here. Scroll up in your database program and maybe the record for the other server is there?
'server_id':751755633128243291
is not in database
any user
not register from this server in database
Oh wait
I think it's because .find always return a cursor, even if it doesn't find anything
I don't mind dms, but I'd say it's better to leave the discussion here so that more ppl can help you and I gotta go very soon
ok
query = """INSERT INTO tag_reference (is_alias,name, authorid, guildid, referenced_id)
true,SELECT $1, $4, tag_reference.guildid, tag_reference.referenced_id
FROM tag_reference
WHERE tag_reference.guildid=$3 AND tag_reference.name)=$2;"""
await ctx.bot.conn.execute(query, alias_name, original_tag, ctx.guild.id, ctx.author.id)```error:
PostgresSyntaxError: syntax error at or near "true"```how to fix this?
pls ping me when help
So I want to insert the value true for is_alias column
and for the rest four I want to insert values obtained from this query py SELECT $1, $4, tag_reference.guildid, tag_reference.referenced_id FROM tag_reference WHERE tag_reference.guildid=$3 AND tag_reference.name)=$2
@torn sphinx I got a chance to ask my database professor. She said in-memory databases are a fine way to unit test functionality that isn't directly tied to your ability to connect to the real database
As opposed to testing that you could actually connect to the real database in a production setting.
I'm sure you can find arguments against that online because programmers are highly opinionated, so do with that what you will.
Hi, for a firsty project in python i need to store some data, between 10 and 100 records of data sheets with each about 30 fields.
Currently i'm thinking about create yaml file for those data to avoid the need of a DB to install/manage.
And as it is text files, i can easely version them in the git repo with the code.
Any suggestion about this mothed or other thing to consider please ?
@rough hearth woah!! That is so thoughtful of you! Thank you so much!! I will look into that option now instead. Wish me luck :P
@midnight raven It's a fine thought, but if you did want to use a DB instead, sqlite is serverless and does not require install/management. Python has a standard library for it as well. Not that you should necessarily use it, but it's an option to consider.
for a little more details, i "only" need to store source data of creatures sheets for a RPG
and later i'll have some live data like user profile
hey guys
any database recommendation
im a flask developer
i dont rly want the "phpmyadmin thing"
how can i host a db natively in python wich then can connect to it using sqlalchemy
all i can find is how to connect not how to "host"
@naive umbra
Primarily you have two options:
First is SQLite, which requires no setup. You just initiate a connection from your script and if it doesn't find the db (which will happen the first time you run the script), it will create the db.
Second is to setup something like MySQL or PostgreSQL (I recommend PostgreSQL). This will require you to install the db and setup a username password before you can start using it.
The process of installing will depend on what OS you are using, but plenty of tutorials are easily available for both. Just search for how to install Postgres on <operating system>
Can anyone help me with this error message
Hey @quartz lynx!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
Lost connection to MySQL server at '127.0.0.1:3306', system error: Connection not available.
Nvm, I fixed it, embaressingly I spent half an hour on a typo 🙂
Help?
Can you show full traceback, and your code as well @boreal niche
I cant since
I can show code
Not traceback
Sonceim hosting it on my friends server
Since*
One sec
@client.command() async def buy(ctx, item: str): write_log("Buy command requested") #write_log("Sending GET request to Cosmos API...") try: SQL.execute('SELECT price FROM shop WHERE itemname = %s', item) price = SQL.fetchone() SQL.execute('SELECT balance FROM Accounts WHERE user_id = %s', ctx.message.author.id) SQL.execute('UPDATE Accounts SET balance = balance - %s WHERE user_id = %s', price, ctx.message.author.id) db.commit() await ctx.send(f"Successfully bought {item} for {price} Rollars.") except Exception as ex: write_log('ERROR') write_log(f'Errored whilst sending ctx(embed), (about): {ex}')
@proven arrow
Sorry I'm on mobile it's kinda hard to
Yknow
Ping ifu can hrlp
Ok well that is not readable at all
Ok, but looking at what you sent execute function takes the form execute(sql, params) where params is a tuple. However you are not doing that. Secondly, it looks like your using the same cursor for multiple queries, which I would not recommend to do so. Also it would help if you show how you define the connection as well as the SQL variable you have named. @boreal niche
@client.command()
async def buy(ctx, item: str):
write_log("Buy command requested") #write_log("Sending GET request to Cosmos API...") try:
SQL.execute('SELECT price FROM shop WHERE itemname = %s', item)
price = SQL.fetchone()
SQL.execute('SELECT balance FROM Accounts WHERE user_id = %s', ctx.message.author.id)
SQL.execute('UPDATE Accounts SET balance = balance - %s WHERE user_id = %s', price, ctx.message.author.id)
db.commit()
await ctx.send(f"Successfully bought {item} for {price} Rollars.")
except Exception as ex:
write_log('ERROR')
write_log(f'Errored whilst sending ctx(embed), (about): {ex}')
Shud look clearer
That is the same code you sent above, so my answer remains the same
Hello, any idea why looping through a table with a date (isoformat) is way way longer than the exact same table without the date column ?
So is there a way with sqlite3 to have custom row names instead of what defaults I think?
wait nvm I was browsing the structure and not the data, thats why it looked goofy to me
So is there a way with sqlite3 to have custom row names instead of what defaults I think?
@timber glade you can always create an id column
Hmm, tyvm!
id player_id otherfields updated_at
1 1213 ... 16848121
2 1213 ... 16848125
3 1548 ... 19848125
``` I want to select distinct player_id with the last updated_at including all fields in **mongodb**:
Result would be something like:
id player_id otherfields updated_at
2 1213 ... 16848125
3 1548 ... 19848125
How can I do it?I already have Postgres installed on my PC but I couldn't find pg_dump.
From where can I download it and install it?
Hey I need help
SELECT indexes.id,indexes.name,blueprints.bp FROM indexes,blueprints WHERE indexes.id = blueprints.id
how to put a condition for this query
i want to select the rows where id is ??
but when i added multiple where it gives error
thanks its working
im pretty new to setting up databases stuff, i know like relational dbs and some scalability (though im still a bit confused about this). but i wanted to know what would be best for my case. I need the database to store messages that were skipped and just normal messages from multiple streamers, nothing too complicated, though I'm not totally sure if thats going to be only it, so i want to make sure the db i choose will be sufficient enough in case it's used widely
ive heard a lot about postgres and mongo
hi, how can i set up a dashboard in grafana to show if a bot is alive or dead? say my condition is if any tickets has been closed over the last hour or so.
@client.command()
async def buy(ctx, item: str):
USER_ID = ctx.message.author.id
write_log("Buy command requested")
#write_log("Sending GET request to Cosmos API...")
try:
chk1 = "SELECT price FROM shop WHERE itemname = %s"
chk2 = item
SQL.execute(chk1, (chk2,))
price = SQL.fetchone()
chk3 = "SELECT balance FROM Accounts WHERE user_id = %s"
chk4 = USER_ID
SQL.execute(chk3, (chk4,))
chk5 = "UPDATE Accounts SET balance = balance - %s WHERE user_id = %s"
chk6 = price, USER_ID
SQL.execute(chk5, (chk6,))
db.commit()
await ctx.send(f"Successfully bought **{item}** for **{price} Rollars**.")
except Exception as ex:
write_log('ERROR')
write_log(f'Errored whilst sending ctx(embed), (about): {ex}')
``` @proven arrow Like this?bucuz i keep getting the smae error
i mean
a different one
python type tuple cannot be converted
and here is my db and cursor code
db = ''
host="127.0.0.1"
def tryConDB():
write_log('Attempting to connect to DB...')
try:
global db
db = mysql.connector.connect(
host=host,
user="root",
password="lol",
database="BankAccounts"
)
write_log(f'Connected to DB on {host}')
except:
write_log('ERROR')
write_log('Failed to connect to MySQL DB')
tryConDB()
if db == '':
tryConDB()
write_log('Setting SQL variable...')
try:
SQL = db.cursor(buffered=True)
except:
write_log('ERROR')
write_log("ERROR SETTING VAR: 'SQL'")
Show the full stack trace error you are getting
Also why are you getting the cursor outside your function and using the same one? You should get a cursor each time. And also your database is blocking your async code.
For your error, your passing a tuple inside a tuple.
chk6 = price, USER_ID # is a tuple
SQL.execute(chk5, (chk6,)) # the second parameter here becomes ((price, USER_ID),)
You can unpack the tuple by adding a * before the argument like so: execute(chk5, (*chk6,)) or just pass directly chk6 as the argument like execute(chk5, chk6) @boreal niche
could someone have a look at #help-cherries pls 🙂
helpers._check_command_response(
File "C:\Users\DELL\AppData\Local\Programs\Python\Python38\lib\site-packages\pymongo\helpers.py", line 167, in _check_command_response
raise OperationFailure(msg % errmsg, code, response,
pymongo.errors.OperationFailure: bad auth : Authentication failed., full error: {'ok': 0, 'errmsg': 'bad auth : Authentication failed.', 'code': 8000, 'codeName': 'AtlasError'}```I am using MongoDB
what does this mean ? some connection problem or i did some mistake
import json
import pymongo
from pymongo import MongoClient
with open('config.json', 'r') as f:
data = json.load(f)
url = data['url']
client = pymongo.MongoClient(url)
DB = client['test']
collection = DB['test']
post = {'_id': 0, 'Name': 'Naman', 'class': 1, 'Roll No': 10, 'friends': [
'Ankit', 'Ashwin', 'Harry'], 'marks': {'maths': 80, 'english': 81, 'hindi': 78}}
print('connected')
collection.insert_one(post)```Show the full stack trace error you are getting
@proven arrow how can I get 2 cursors and I cant show full traceback since my friend isn't online hence the write_log function.
I posted the answer to your error below that
Not all parameters were used in the SQL statement
@proven arrow yup now im getting this
do i have to use the param=()
or something?
How come I don't have pg_dump even if I have already installed Postgres 12?
@ me please.
@boreal niche Then you passed more parameters than the database was expecting for that query.
How come I don't have
pg_dumpeven if I have already installedPostgres 12?
@ me please.
@lime echo Can you be a bit more specific in terms of what you tried and what response you got?
@tepid cradle ok. Normally, I would find pg_dump inside my Postgres/12/bin folder but I don't.
Do you know how can I fix this issue?
Ubuntu?
@proven arrow i made a few changes but keep getting this error:
Traceback (most recent call last):
File "Bot.py", line 322, in buy
SQL.execute(chk5, chk6, chk4)
File "/home/vihanga/lib/python3.8/site-packages/mysql/connector/cursor_cext.py", line 248, in execute
prepared = self._cnx.prepare_for_mysql(params)
File "/home/vihanga/lib/python3.8/site-packages/mysql/connector/connection_cext.py", line 626, in prepare_for_mysql
result = self._cmysql.convert_to_mysql(*params)
_mysql_connector.MySQLInterfaceError: Python type tuple cannot be converted
code:
@client.command()
async def buy(ctx, item: str):
USER_ID = ctx.message.author.id
write_log("Buy command requested")
#write_log("Sending GET request to Cosmos API...")
try:
chk1 = "SELECT price FROM shop WHERE itemname = %s"
chk2 = (item,)
SQL.execute(chk1, chk2)
price = SQL.fetchone()
chk3 = "SELECT balance FROM Accounts WHERE user_id = %s"
chk4 = (USER_ID,)
SQL.execute(chk3, chk4)
chk5 = "UPDATE Accounts SET balance = balance - %s WHERE user_id = %s"
chk6 = (price,)
SQL.execute(chk5, chk6, chk4)
db.commit()
await ctx.send(f"Successfully bought **{item}** for **{price} Rollars**.")
except Exception as ex:
write_log('ERROR')
full_traceback = traceback.format_exc()
write_log(f'Errored whilst sending ctx(embed), (about): {ex} {full_traceback}')
@tepid cradle I have finally fixed it by downloading the binaries and pasting pg_dump in my /bin folder.
I just dumped my database and I have no clue where it is now, and this is my current issue XD
await conn.execute(
f'UPDATE config SET r_data = {row} WHERE id = {id}'
)```
What is the proper way to use f-strings for Postgres queries? This gives a 'syntax error at or near {'easy, you dont use f strings
ookay how do I get a variable in there? concatenation?
you should look at sql placeholders
that is part of the query right? I'd still have to get a python variable into the query 🤔
no...
this is not what you meant? https://www.techonthenet.com/postgresql/declare_vars.php
thanks
Trying to understand where I went wrong here (though it's not too hard to fix at least). This query I was expecting to update only on a certain streamer_id, however it seems to have ignored this and just updated every value for every streamer_id
UPDATE
viewer_data
SET
user_type = full_data.base_type
FROM
(SELECT
base_data.streamer_id as streamer_id,
base_data.viewer_id as base_id,
base_data.viewer_name as base_name,
base_data.user_type as base_type,
secondary_data.viewer_id as second_id,
secondary_data.user_type as second_type
FROM
(SELECT
streamer_id,
viewer_id,
viewer_name,
user_type
FROM
viewer_data
WHERE
(user_type='BadBot' or user_type='GoodBot')) as base_data
JOIN
(SELECT
streamer_id,
viewer_id,
user_type
FROM
viewer_data
WHERE
user_type='PotentialBot') as secondary_data
ON
base_data.viewer_id = secondary_data.viewer_id) as full_data
WHERE
full_data.second_type = 'PotentialBot' AND
(full_data.base_type = 'BadBot' OR full_data.base_type = 'GoodBot') AND
full_data.base_id = full_data.second_id AND
full_data.streamer_id=41659699```Can I have 2 tables in one database?
I'm assuming I can
But I just wanted to ask before potentially messing the data up in my current database
yes considering its a SQL database
Bit of a curious issue i have with postgre rn.
After deploying it on a docker container (It decided it didnt want to run normally 🤷♂️) im getting 600ms+ latency when doing any query
which doesnt make much sense unless something is going very wrong
avg remote latency is ~100ms and the mongo db running on the same server is at 120ms response time so its not my connection or the server's network
which is what confuses the crap out of me where this 600ms is coming from
update: we got it working on a standard system and its still 600ms ish which is a yikes
more debugging:
[{'Plan': {'Node Type': 'Seq Scan', 'Parallel Aware': False, 'Relation Name': 'anime_details_legacy', 'Schema': 'public', 'Alias': 'anime_details_legacy', 'Startup Cost': 0.0, 'Total Cost': 11.2, 'Plan Rows': 120, 'Plan Width': 32, 'Actual Startup Time': 0.004, 'Actual Total Time': 0.004, 'Actual Rows': 0, 'Actual Loops': 1, 'Output': ['ROW(title, desc_short, desc_long, reviews, thumb_img)']}, 'Planning Time': 0.487, 'Triggers': [], 'Execution Time': 0.035}]
latency 624.876ms
INFO: 127.0.0.1:64433 - "GET /api/anime/details?terms=hello+world HTTP/1.1" 200 OK
[{'Plan': {'Node Type': 'Seq Scan', 'Parallel Aware': False, 'Relation Name': 'anime_details_legacy', 'Schema': 'public', 'Alias': 'anime_details_legacy', 'Startup Cost': 0.0, 'Total Cost': 11.2, 'Plan Rows': 120, 'Plan Width': 32, 'Actual Startup Time': 0.006, 'Actual Total Time': 0.006, 'Actual Rows': 0, 'Actual Loops': 1, 'Output': ['ROW(title, desc_short, desc_long, reviews, thumb_img)']}, 'Planning Time': 0.079, 'Triggers': [], 'Execution Time': 0.035}]
latency 636.2943000000004ms
INFO: 127.0.0.1:64433 - "GET /api/anime/details?terms=hello+world HTTP/1.1" 200 OK
I've already posted this code, I changed it, but it's still doesn't work. I have another error: NotImplementedError
from aiohttp import web
import asyncio
import aiopg
import routes
async def main():
dsn = 'dbname=test user=user1 password=123 host=127.0.0.1'
async with aiopg.create_pool(dsn) as pool:
app = web.Application()
app["db_pool"] = pool
routes.setup_routes(app)
web.run_app(app, port=80, host='127.0.0.1')
asyncio.run(main())
Idk where to ask, but is there any way to re-assign ids (SERIAL PK) in postgres database? I deleted the first row, and i want my rows, to start with 1,2.. again (instead of 2,3...)
Is there a way to make a "trigger" sort of thing so if there is more then 2 people in the queue then it will create that channel?
For context im making a queue basically once there is more then 2 people in it will add them into a channel
@vapid flax Hi Unbound-, the only way I know of to reset an identity column is to truncate the table with the "restart identity" clause. See https://www.postgresql.org/docs/9.5/sql-truncate.html
Ive read it aswell, but i couldn't figure out how to keep the data, since everything gets deleted
Perhaps select the data into another table, truncate the original and then reinsert the data from the new table, then drop the new table
Heroku is asking me for a HTTP-accessible URL to my database but I don't know how to make one. It suggested Amazon S3 but I don't want to use it since it's asking me for my card info and stuff.
Do you guys have an alternative to it?
This makes so much sense !! I totally forgot that you can create temp tables, since i didn't really get to use it yet. Im going to get rid of my ugly original solution of "set id= where id=" and alter_seq.Thank you very much!
@grand vector
is it bad to connect and close a lot to the db ?
like I have lots of function and in each of them I create a connection and close it
I need to do it this since its asynchronous
@torn sphinx This link ought to help you: https://dev.mysql.com/doc/mysql-getting-started/en/#mysql-getting-started-basic-ops
Anyone used MongoDB before?
trying to convert my BSON data into my cluster by doing mongorestore
but keep having this error when its related to my atlas link
please ping me if you have a solution

Me and this error message been at it
@torn sphinx I'm not a MongoDB guy but the ReplicaSetNoPrimary stood out to me. Maybe the replica config ought to be checked? https://docs.atlas.mongodb.com/reference/alert-conditions/#Replica-set-has-no-primary

i got a new error
2020-10-18T17:15:33.672+0200 error connecting to host: could not connect to server: connection() : auth error: sasl conversation error: unable to authenticate using mechanism "SCRAM-SHA-1": (AtlasError) bad auth : Authentication failed.
PS C:\Users\Administrator\Desktop\mongodb-database-tools-windows-x86_64-100.2.0\bin>```apparently
MongoDB 3.2 – server returned error on SASL authentication step: Authentication failed. This issue will happen to all MongoDB tools (mongo, mongodump, mongotop, mongostat). However, I encount…
im supposed to single quote the atlas link or password
isntead of quotation marks
''
""
imma try and see
Nope
didn't work.
2020-10-18T17:22:42.350+0200 error connecting to host: could not connect to server: connection() : auth error: sasl conversation error: unable to authenticate using mechanism "SCRAM-SHA-1": (AtlasError) bad auth : Authentication failed.
PS C:\Users\Administrator\Desktop\mongodb-database-tools-windows-x86_64-100.2.0\bin>```Error Status: [Fixed]
reason: Wrong password, should be using password you assigned with your ACCOUNT```
Have more of a best practice question ...I can provide more context as well
For joining and building reporting off various data sources (from database tables, spreadsheets, etc.) do you see 1) loading those datasets into Dataframes directly or 2) Ingesting those datasets into normalized tables and then leveraging SQL as a more "preferred" approach?
can someone help me
im making a discord bot and am looking for a hoster that can also store a couple tens of gbs of databases
i've never used a premium host before
Three are several options. Paying for a virtual machine, container hosting, or managed db instances.
The first option requires the most work on your part.
You have to set up everything yourself but you have full control of the machine
I'm not sure what the pricing is like for Docker container hosting. It may be meant for shorter lived containers rather than something like a db
Managed db takes care of most of the setup for you.
Most if not all of the big names provide these options
Gcp, aws, Oracle, digital ocean, azure, linode, scaleway, etc
If youre looking to host both the program and db then a VM may end up being the cheapest option, since one machine will likely have enough resources to accommodate both
@fleet haven
Basically yes
can someone help me with aiosqlite
any projects related to data management with python-mysql user input
???
including some examples???
guys
pls help
can i close a cursor in mysql?

Stack Overflow
I don't really understand how tuples work. But what i do know is that they look something like this.
(1, variable)
But I keep getting the error:
Python type tuple cannot be converted
Can someone
Can anyone help me use pyodbc for ms SQL server that's used it before? Pls@ me!
Getting an an 08001 error, but im 90% sure the connection string is ok, using odbc driver 11 for SQL server
I guess I should reconfirm what to store in server port... I can query the db if anyone knows what I should query
@boreal niche The fetchone() function returns you the result as a tuple. So when you use fetchone the value stored in the price variable is a tuple like the following: (100,).
Then when you execute your update query, you are passing this entire tuple as you received it inside another tuple. If for example, the price value was returned as 100, then below is what your passing into the execute function.
SQL.execute("UPDATE ..... ", ((100,), USER_ID))
So the first element of your arguments is a tuple instead of a value, and you get that error because the database is thinking there is some value there that it can use, however since it finds a tuple instead as the first element you get that error.
What you should be doing is simply passing a single integer value as the price parameter so it looks something like: SQL.execute("UPDATE ..... ", (100, USER_ID))
To do this, you can either unpack the tuple by putting a * in front of it, or get the first value from it like price[0].
I got my connection string working
Who did work with aiopg and aiohttp ?
What you should be doing is simply passing a single integer value as the price parameter so it looks something like:
SQL.execute("UPDATE ..... ", (100, USER_ID))
To do this, you can either unpack the tuple by putting a*in front of it, or get the first value from it likeprice[0].
@proven arrow OMG thx
so, what is your guys' favorite database programming language?
so, what is your guys' favorite database programming language?
@ornate hemlock MySQL
what makes you say that?
thats not a programming lanuage
- Thats a DB server
- SQL is a Query language not a programming language
Is it best practice to roll back a connection no matter what? Ie encode everything in a try else finally block
How is db optimisation done for the most part? Java? C#?
Hey there, here is a good one: How do you properly insert pandas NaT datetime values to a postgresql table without getting errors?
I've replaced NaT values to NULL or none, neither work.
im using SQLalchemy / psycopg2
@nocturne basin what's the error you get from those? and what datatype is it on the pg-side?
pg_restore: error, did not find magic string in file header
I always get this when trying to use heroku pg:backups:restore. How do I fix this?
SELECT studentName FROM student RIGHT JOIN enroll ON student.sid=enroll.sid WHERE deptName='Computer Science'; -- I need to get the row with the highest value in the gpa column. SELECT TOP doesn't seem to fit the bill.
SELECT studentName FROM student RIGHT JOIN enroll ON student.sid=enroll.sid WHERE deptName='Computer Science';-- I need to get the row with the highest value in the gpa column.SELECT TOPdoesn't seem to fit the bill.
@rough hearthORDER BY student.gpa DESC LIMIT 1?
I have never heard of SELECT TOP, and it appears to be nonstandard and do the same thing as LIMIT
TIL
@brazen charm bro can you help me?
I thought top vs limit was the same concept just with a different syntax across rdbms
I thought top vs limit was the same concept just with a different syntax across rdbms
@pure cypress apparently there's one difference
LIMIT allows offsets
how to create a superuser account for postgres? I'm on windows btw
and also does anyone has a good instructions of how to get started using postgres for django? it can be a link
Select top is ms SQL, limit is mysql iirc, and Rowlim is Oracle
limit also works in postgres and sqlite
which one would be more efficient ?
sending a query which opens a new connection every time whenever required or querying every data that would be needed with one connection at the very beginning?
how much expensive is establishing a psql connection btw?
@simple berry what you should do is make a connection once and work with transactions
@little pumice i would assume if you log in with the psql terminal you could make a new account and add it as a sudo
otherwise you can make it from the pgadmin4 if you click the top right > users and make sure to set the slider superuse to true
jayz a connection doesn't take too long, but it's an easily avoidable delay and unnecessary trafic really, so it's best to avoid it and use transactions
jayz a connection doesn't take too long, but it's an easily avoidable delay and unnecessary trafic really, so it's best to avoid it and use transactions
@wintry stream Transactions are nothing to do with the connection
@torn sphinx the reason i suggested it is because he was asking for something that sounded like splitting up the load
transaction is as name says, allows you perform actions as a whole or not at all
hence why i suggested transactions
they can use connection pool for this then instead
but you are correct that it will cause unneccessary delay because it has to do quite few things for each connection
@little pumice i would assume if you log in with the psql terminal you could make a new account and add it as a sudo
@wintry stream I’m on windows so I can’t use sudo
also sudo is a regular program, not a valid psql command
is it possible to store python dictionaries as dictionaries in Postgres? I assume that's what the json data type is for but I've only managed to store it as a string so far
MongoDb is good enough. Lots of resources available for it on account of it being quite popular. @torn sphinx
Scylla or Cassandra are the more 'performant' noSQL dbs
mongo webscale™️™️™️ is just a meme now with how overused it is
@keen shuttle you can use the json module... json.dumps will convert the python object to a json string, json.loads will convert the json string to a python object
that's what i'm doing now, but i could just store the string in a db column with the 'string' data type. i was kinda wondering what json was for
I'm not sure but according to stack overflow the json gets validated
a column with type json or jsonb should be able to store a Python dict that only contains string keys and valid values
the exact way to store depends on your database driver or ORM
ahh string keys; that's probably why i couldn't get it to work. mine were ints. Thanks 
Anybody on here?
Psql with json or mongoDB which one is preferred
👀 Why would you even use a SQL db if you're just gonna treat it like Mongo
cause i have seen article stating psql is 15x faster than mongo
yeah speed is the major reason i would use SQL database like a json db
however that doesnt mean anything when you're storing everything in a single row
if you want the DB for performance then you actually have to use it how its designed and postgres is very much not designed to be treated like MongoDB
the major thing is i have a bit of irr-rational data , so json would be a better option
what sort of data
if you want the DB for performance then you actually have to use it how its designed and postgres is very much not designed to be treated like MongoDB
@brazen charm 100% agree with you , but the main question was psql with json or mongoDB
👏 for 👏 what 👏 data 👏 though 👏
don’t trust an article saying «X is better than Y» unconditionally
if you're just gonna use postgre with a single column with JSON in it then you might aswell deal with mongo and accept the penalties that go with it
All universal statements are false
Oh there we go
if you have relational data and some irregular json
if you already know and operate postgresql
if you are using an ORM that works with postgresql
if you want extensions like ranges geographic operations etc
then you may have a good reason to use a json column in postgresql
if you're just gonna use postgre with a single column with JSON in it then you might aswell deal with mongo and accept the penalties that go with it
Definitely not like that , i meant that i could structure the data in a semi-rational data then use json inside psql
ehh you can do that ig
(and yes it is very good and generally fast, but that depends a lot on your schema, the kind and volume of data and your queries)
Postgre Overall is probably the more useful Database with what it can do but equally the JSON format is more of a 'hacky' system
and it will not give you performance
I'll just leave my question into the queue
How do you make a working Composite entity
all it essentially does is dump the data and then lets the driver load it again when its fetched
Oh shit if i compromise performance then i m loosing the point
how is it hacky? postgresql has interesting custom types and you can make your own
jsonb helps for performance, and there are operators for deep querying in the json data (so it’s not just a string)
and there are even indices possible!
its hacky because it dumps it then loads it again like you would sqlite dumping to a string and loading it again
its a sort of work around for supporting the type
if you want performance Indexes and Fixed size datatypes are your friends
I disagree, see my edited message above
at that point you're just recreating what mongo does
Mong does but fast
if that was a persuasive argument, there would never be a tool similar to another tool 🙂
mongodb does not come free of operation and maintenance cost
its really depends on your data which you still havent told us
if your app or site already uses postgresql for 90% of its needs, having hstore/json/jsonb column types is great
if you have like 100 million rows of data then suddenly postgres becomes considerably better
Yes i m writing it up
if its Async system then postgres comes on top
if its pure dynamic data then Mongo will probably do it better and easier
a user can upload 20 reviews about thier day ,
And I didn't want to create my table as
user_id
review_text
timestamp
rating
Cause with the flow of more user it will cause to flood the table with many rows making it slow
not as slow as sticking it all in a json every time
my idea for using json for this format was
Postgres can easily handle 1 Million rows a second on a single client
but equally is this a Sync or Async system?
user_id
day_1
day_2
day_3
.....so on till 10 day
day_x holding the json value
For 20 reviews
that would be a very inefficient method
but equally is this a Sync or Async system?
I'll prolly be using db foractix-webso it would be async
And I didn't want to create my table as
but that is a clean and proper schema
Cause with the flow of more user it will cause to flood the table with many rows making it slow
you will be fine for tens of millions of rows. creating new rows should not be slower; querying data also does not have to be slow if you define the right primary key and/or indices
oh you're using this with rust?
yeah actix-web
@lament basin yeah but then selcting the last 30 day review by a user on average he is posting like 20 reviews a day so wouldn't it make a bit more on slower
well if you're worried about lots of users then mongo is probably gonna be rules out
@grim lotus and no
no for ? 
20 posts a day from a single user is nothing in reality
a 'bigish' sql db can easily go to the billions of rows
oh no for the making it slower*
if you want things like average score or other data aggregated from rows, the DB can do the work easily
if you want to fetch the full 30x20 records, then that’s still a small number
Suppose my application is at 100k user , sorry for bruteforcing
Then 20×100k reviews = 2000k rows a day
By the end of the month
thats nothing
Wouldn't it be...
do you really need to get all reviews from all users for a whole month
pagination is a thing!
one of my db queries about 15,000 Rows a second with less than 5ms latency
lots of rows are relational DB's bread and butter
how many total rows yu have btw ?
6 Billion ish i think in this one
do you really need to get all reviews from all users for a whole month
Yeah toh prevent api spam for each day
6 billion rows ? 
And 15k row fetching takes 5ms?
per query on average
if you are comfortable in sharing , is it a db hosted on high powered computer
obviously the server infa is there to support that number, you wouldnt get that from a rpi
not to interrupt, when you have a chance:
so can someone explain to me the difference between the db uri
and the connect object? does one supersede the other?
Yeah toh prevent api spam for each day
@grim lotus so you want the count of rows, not the full data
Okay
I havent worked with the mysql driver im afraid
i imagine the uri is the direct connect url
@lament basin no i want full data I'll consume all the column when dispatching the data from my api after Fetching it from db
do you have a link to what you call connect object?
that would be helpful ^
pymysql.connect
@glass gorge ok so db_uri is typically a string that encodes information to connect to the database (host, port, username, password, database, options), and you pass it to the connect function to establish a connection
if you want to cut down of queries then use a cache db like redis to essentially buffer them
in what database
depends on the DB and driver or ORM
In any database, in a database you make on paper,
oh okay
@glass gorge the uri is the direct url that has all the info needed to establish a connection
what that Connect class does is produce the uri internally
The book says that I'll need to put two foreign keys together and the merge them as a primary key
where as alchemy takes it direct in the above link's example
but I don't know how that would work
so i dont actually need both
shouldnt do
Anyways CF8 , merwork you guys were absolutely helpful
To sum up
user_id
review_text
timestamp
rating``` this schema shouldn't be a big problem as such if i would even have 100k user on my app
psql database shouldn't be a big problem until i have like billionish rows thanks!if you want to increase speed of the DB if it ever becomes slower make a Index on the column you index at
and also for extra speed give it more ram
i think by default postgres is only allowed something like 128MB of ram for buffering
if you want to increase speed of the DB if it ever becomes slower make a Index on the column you index at
well i think how can i index my column only primary key i could set for my schema is
primary key (user_id , timestamp)since a user cant enter a review entry at the same time
@glass gorge I don’t understand your problem
what that Connect class does is produce the uri internally
@brazen charm can you elaborate a bit on this, what do you mean internally. Do you mean within the function that is called.
define «need»?
there is a string parameter with info and a function that needs it
your app configuration will have the db_uri string, and your code will get the config and call connect
define «need»?
@lament basin need as in, I don't need to define the uri in a config file, and then redefine it again in a connection object
@brazen charm can you elaborate a bit on this, what do you mean internally. Do you mean within the function that is called.
@glass gorge Basically within that function it will take the hostname, password etc... and produce that connect uri which it'll use to connect
that's what I thought you meant ^
Thanks guys for helping out !! 
maybe your question is: why not directly write the conneciton info in the code?
the separation of code from settings is explained here: https://12factor.net/config
in my codebase im currently defining both an app.config which contains some connection information for the db
basic idea is that an app should contain code that can be used in multiple places, so if you separate settings from the code, you don’t need to change the code to change the configuration
and also
im using a connection object, which in pymysql requires you to define those same parameters, which were already defined, in the app.config file
are you using the ORM or?
well define use
its there
but im just using it for queries
actually... I think I am... nvm
but im not using it to create new tables or anything
basically what im getting at is do you use both the ORM and the standalone pymysql module or just the ORM
do you understand my messages @glass gorge ?
basically what im getting at is do you use both the ORM and the standalone pymysql module or just the ORM
@brazen charm both currently
if you have a config file with parameters, don’t copy the params to your connect call, get them from the config file and pass them
don’t write them in two places
you can use the ORM to execute raw queries but it kinda defeats the purpose
so i wanted some clarity as to what is happening in my code
why do you need to connect to two seperate dbs
i saw some info on binds
well because i have a db for just user information
basically...
one db is for thigns related to users
and one db is related for information to be shared on the website
i think it would make sense to keep them separate?
why not use a table?
i mean
i could
but why not?
seems logical to have it stored in a different bucket
general management and organisational issues
because there wont be any, i forgot what its called, relationships between the two types of data
your 'bucket' would be a diffrent table
you can use two databases to keep them seperate but that doesnt make much sense in my mind
database has two meanings:
- different servers
- different namespaces in one server
especially considering the nature of MySQL
namespaces in one server
How are you doing that with MySQL 🤔
well
to be fair
i have no idea what im doing
😄
but.
basically i just created another db on my mysql server
https://flask-sqlalchemy.palletsprojects.com/en/2.x/binds/
@lament basin yeah i saw that
use that
but before you get to that, I had to figure out how to establisht he connection to another server, and to do that I had to ask in ehre the difference between the uri and the pymsqyl connect object
since i have both
as you can see i am learning as i go, and patching code together
i dont always have the opportunity to ask people, and people sometimes have different best practices 🙂
How are you doing that with MySQL 🤔
@brazen charm i created another db on the server usingcreate database
because by default when i created the server it came witha f ew extra tables
like information_schema and performance_schema
but that's stuff for the server i believe
not db specific tables
yeaaaaa idk
UserWarning: Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. Defaulting SQLALCHEMY_DATABASE_URI to "sqlite:///:memory:"
Postgres is saying database already exists but when i try to use it it says it doesnt?
show the traceback
that means no tables are found, but you are inside a database
🙂
check your query
show your uri
i know for mysql you have to specify which table you are using in the uri
nvm i fix that
but now why does it say that the user owner is postgres and not me?
i created role and granted all privs
It can say that, however what issue are you actually facing?
Are you getting any error when trying to read/write?
yes
ERROR: permission denied for relation dossiers
this is name of my table called dossier
I ran
cur.execute("UPDATE guild_settings"
"SET {}={}"
"WHERE guild_id={}".format(key, value, guild))
And got ```Command raised an exception: SyntaxError: syntax error at or near "="
LINE 1: UPDATE guild_settingsSET lottery=FalseWHERE guild_id=6783599...
^
the arrow is still in the correct space
like %s?
Do not:
cursor.execute("SELECT * FROM table_name WHERE value = {}".format('peepeepoopoo'))
Do:
cursor.execute("SELECT * FROM table_name WHERE value = ?", ('peepeepoopoo',))
Consider: if a command accepts user input, and they input True; DROP TABLE table_name- The resultant query with format is:
SELECT * FROM table_name WHERE value = True; DROP TABLE table_name which has obvious results.
Utilizing your SQL library's sanitization methods prepares the statement and exclusively inserts the values, without editing the query.
Note postgresql uses $1, $2, ... for value substitution, mysql, %s, so make sure you know your DB!
https://xkcd.com/327
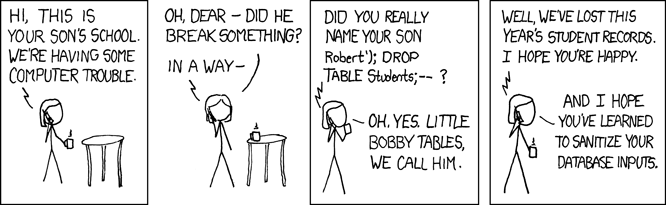
Ahh, SQL injections, my favorite
very rare that you really use dataframes with ML
@torn sphinx
Make sure you connect to the right database. To do so \c database_name
Then try if it works.
If not then try the below:
Login as a superuser like the postgres account you had. Then enter the following: GRANT ALL PRIVILEGES ON TABLE dossier TO your_user;
What is the difference between a data frame and a data base?
alot
very rare that you really use dataframes with ML
@brazen charm we're learning ML and Dataframes in school
yeah
alot
@brazen charm how?
but dont get mixed / linked to being the same thing
I thought I could use a dataframe to store the information for the ML bot
Do I use a database?
Or a data set?
Dataframes are generally designed for analytics and are not designed for large long term storage
databases are designed to store data quickly and efficiently
wait let me try
Do I use a database for the ML?
well that depends on the ML
I wanna build a simple ml bot
I would advise actually getting the hang of ML tools like Numpy and Tensorflow before jumping into what thing to use to make ai when data storage is a tiny problem compared to everything else

Osman bey is in the chat boys
I would advise actually getting the hang of ML tools like Numpy and Tensorflow before jumping into what thing to use to make ai when data storage is a tiny problem compared to everything else
@brazen charm ok
Bey meeting in 15 mins
Can I build a machine learning bot that can tell the difference between a male voice and female voice?
Ok i think to stop now off topic
@torn sphinx yep
If you have good data to train then yes
Maybe there is like public dataset available or otherwise collect your own
audio based ML is incredibly complex
maybe if you read some paper of research they may have published dataset
you would need literally Millions of data points to make it even remotely accurate
I have a user input code that prints out groups that you choose of the periodic table. How can I put this code and ML together?
I want an epic ml bot
But linked to the periodic table in some way
Any idea?
again....
I would advise actually getting the hang of ML tools like Numpy and Tensorflow before jumping into what thing to use to make ai when data storage is a tiny problem compared to everything else
@brazen charm
maybe ask in #data-science-and-ml
Oh ok
ok now i have
cur.execute("UPDATE guild_settings"
"SET %s=%s"
"WHERE guild_id=%s", (key, value, guild))
but am getting
LINE 1: UPDATE guild_settingsSET 'lottery'='False'WHERE guild_id=678...
^```
idk why they are in quotesand where
you cant use table name like that
its concatenating the string it aswell
("UPDATE guild_settings"
"SET %s=%s"
"WHERE guild_id=%s")```is equal to
UPDATE guild_settingsSET %s=%sWHERE guild_id=%s
yeah
you cant no
So how come his error is outputting lottery?
so how could i fix this?
well it takes it as a string litteral
you cant have a column as a placeholder
cuz it'll escape it
and database will reject the string lateral?
@minor venture You will have to use string concatenation
But because they can be unsafe you will have to maybe check the input first
so i have to change set %s=%s to set lottery=%s?
yeah just hardcode it
im not understand much of what is said :/
what if i have multiple columns that i want to be in that line?
i have about 10 columns that all use this code to set there values
you mean lottery can be different value?
yes
You can then use string concatenation
But you have to make sure you validate input before you pass the value
otherwise you get problem like the person told you before, with injection
better way is to do like have a list of valid column names. Then check if the input is from that list
the input is hard coded into my code its not a user input so it will be fine
even your other parameters?
anyways just do it, you get practice
alright i go slepe now
i have something like this
if this:
column=lottery
else:
column=poll
yes my other parameters. this is for a function
thanks for the help
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'db_name',
'USER': 'postgres',
'PASSWORD': 'my_password',
'HOST': 'localhost',
'PORT': '3000'
}
}
got an error after setting the database configuration to this in django ^^
error:
Is the server running on host "localhost" (::1) and accepting
TCP/IP connections on port 3000?
i put the superuser password for the PASSWORD field btw, the one I created during installation
and also I selected to have a remote server instead of one set up on my pc
@app.before_request
def before_request():
database.connect()
@app.after_request
def after_request(response):
database.close()
return response
By default, all your application needs to do is ensure that connections are closed when you are finished with them, and they will be returned to the pool. For web applications, this typically means that at the beginning of a request, you will open a connection, and when you return a response, you will close the connection.
I got this from peewee's documentation. Isn't it a bad idea to recycle a single connection per request? What if you're doing a lot of async stuff? Wouldn't it be better to pull a new connection from the connection pool everytime you do a query. Immediately after you're done you would close the connection so it goes back into the pool
WIth the above solution, each request will have a single connection to play with. The bad side about this is if you have a number of async db calls, all but one is going to be blocked
@little pumice try checking to see if postgres is running. It seems like postgres isn't running on your localhost
how do i connect to it?
let me look it up. I don't really use postgres all that much. If i had to guess it would probably be postgres -u test -p
postgres doesnt appear to be a recognized command even if i added it to path ;-;
and you're certain you installed postgres?
did you install it with a gui?
what os
if it's a mac there is a pretty simple dmg that's a one click setup 🙂
windows
i think windows may have the same
i installed it from their site
and you did it through the installer?
there is a very good chance your path isn't setup correctly if it can't find the cmd tool 😦
go to the path you specified and make sure that executable is there
yea it asked me create a password and did
go to the path you specified and make sure that executable is there
@prime tulip kk
i mean i have postgres running but my machine is different :(.
did you find it in your path?
well try to find the psql executable in your file system
and then copy and paste that path to it into your PATH env var
kk
if you don't remember where you installed it you can probably find the default installation location through a quick search 🙂
I do have a SQL Shell (psql) .exe
nice 🙂
lemme try adding it to sys var
oh it's called DIR on windows
well print the location where you found the exec
and show me what you put in the your path var
it should've added it by default to your PATH 🙂
idk man maybe i messed something up
sometimes there maybe a checkbox to add it
yea
but let's say it's located in C:\postgres\bin\psq.exe then you would add PATH: <other_stuff>;C:\postgres\bin
wait it's saying make sure the psAdmin is shut down
TablePlus
In this post, we are going to figure out how to start, stop, and restart a PostgreSQL server on macOS, Linux, and Windows.
oh wait you don't have pg_ctl in your path do you 😦
you can probably just kill the process directly in task manager
is it a service?
does it show up when you do a net start
or you can just visit your list of services running on your machine (there is a gui for viewing services). See if it's in that list
if it is, just right click and hit stop
if you still can't find it maybe we can just get your env working 🙂
i can't tell if i'm using peewee wrong or if the API is just unique'
like why am i having to associate my models with a db connection
❤️ SqlAlchemy doesn't do it this way
But i've already written so much code with peewee. damnit
How do you make a composite entity and its primary key
How do you make a composite entity and its primary key
@torn sphinx can you elaborate
@torn sphinx can you elaborate
@shell ocean Let's say we have an M:N relationship and we want to build an intermediary table for it
by that you mean many-to-many, right?
From the research that I've done it seems that this intermediary table (Composite Entity) should only contain the foreign keys of the two tables that it acts as an intermediary table for.
Yes
And that the two foreign keys make the primary key of the intermediary table itself
not necessarily
each row can have its own primary key
so you have 3 columns: primary key and one foreign key for each related table
I see
So we just make a unique primary key for the intermediary table?
How do we use this unique primary key in the two parent tables?
How do we use this unique primary key in the two parent tables?
@torn sphinx you don't
and it can work fine
without a separate primary key
Like let's say we have an enroll intermediary table, that contains the foreign keys Student_ID and Class_ID
it's just a convenience if you're using an ORM or something that doesn't do well with composite primary keys
Yes but my question is, even if you do make a composite Key, how do you use it in the two parent tables
Yes but my question is, even if you do make a composite Key, how do you use it in the two parent tables
@torn sphinx what do you mean "how do you use it"?
like in the sense that you want to get the set of related objects?
Yeah
No, I'm just doing some conceptual work
I'm trying to understand the logic behind this, for some reason I can't wrap my head around it
I'm trying to understand the logic behind this, for some reason I can't wrap my head around it
@torn sphinx okay, so
let's say your tables are student and class
and the name of the junction table is enrolment
you have a set of students
and therefore their IDs
Okay
right?
you want to get all the classes that all of the students are in
therefore, conceptually, you go to the enrolment table and retrieve the rows where student_id is in the set of student IDs you got earlier
then you extract the class_id column from those rows
and lastly you go to the class table and get all the rows whose IDs belong in that set of class IDs
make sense?
how fix that
@hasty juniper did you port forward the server machine?
and is the database started?
And if I wanted to get all of the students that are enrolled in a particular class I just find all the rows that contain the Class_ID of that class and get the corresponding student_ids right?
@wintry stream i wont to create db
And if I wanted to get all of the students that are enrolled in a particular class I just find all the rows that contain the Class_ID of that class and get the corresponding student_ids right?
@torn sphinx indeed
well if you install pg, you get a pg server
that error appears if the pg server is not started or not port forwarded ocrrectly
in the server after it has been started you can create a db, but first you need to start the server

yw
can someone tell me what's wrong here?
Stack Overflow
This is what I have written for hwid authentication:
try:
current_machine_id = subprocess.check_output('wmic csproduct get uuid').decode().split('\n')
[1].strip()
r = requests.get('htt...
can anyone help me with this ?
this has nothing to do with databases
dict(i.split("=") for i in r.text.strip().split("\n")) or something similar
TypeError: can only concatenate str (not "dict") to str
i cant commit one kind of object in a flask_sqlalchemy project, should i ask about it here or over at help?
can someone tell me what's wrong here?
@pulsar kestrel what is the type of the email column?
@pulsar kestrel show your code. You are not passing the parameters correctly.
As a general rule, always post your code along with the error message. It's mostly not possible to tell what the exact problem is without looking at the code.
hello, anyone who could help me with an connection issue with python script in docker container and influxdb also in docker container
Which library?
mariadb
library. Mariadb is the database
Oh, sorry. I was not aware that the name of the library is also Mariadb
how do i connect MYSQL to python (i have a db already and ready to go)
@tepid cradle yeah
@pulsar kestrel I don't think this library supports named parameters. Can't find it in the documentation.
You can use Python MySQL connector: https://pypi.org/project/mysql-connector-python/
Since Mariadb is a fork of MySQL, this works as well
@torn sphinx this library works for you as well.

thank you
ohh
this server is more helpfull then discord.py server for bots XD
hi
hiiiii
so like basically, I got this postgres thing installed (it's a different problem today). I tried to run the psql command in terminal, error says it's not recognized, so I added C:\Program Files\PostgreSQL\12\bin (where it's installed) into my system variable, but still fails.
Does anyone know the problem?
I also tried C:\Program Files\PostgreSQL\12\lib and C:\Program Files\PostgreSQL\12
and even C:\Program Files\PostgreSQL\12\bin\psql
users.pop(message.guild.id)("values")```
this doesn'T work how do i let delete "values" out of the json?did you spawn a new cmd.exe window after adding to PATH @little pumice
yea
i spawned a new git bash tab in the windows terminal
i also tried using different terminals but still same thing
windows power shell, git bash, and cmd
im having trouble with a relationship in sqlalchemy
the addtodo function fails when it tries to append a todo to a user ( line 92)
weirdly enough, adding todos to a category does seem to work
oh and also how do I create a new postgres user role on the pgAdmin 4 page ?
hey does anyone know how i can fix this? https://media.discordapp.net/attachments/343944376055103488/768520085496660028/unknown.png
{kind=link}

@azure herald there's no error
there was something wrong but i figured it out
Where does pgAdmin store Postgres backups?
i just started using pymysql, how do I escape values before inserting them to prevent sql injection?
@mild haven You would use a parameterised query. This is where for the query you would provide a placeholder such as %s instead of the actual value. You would then pass the value as a list/tuple of parameters.
So the execute function would take the format cursor.execute(sql, parameters).
The docs provide example, https://pymysql.readthedocs.io/en/latest/user/examples.html
execute functions: https://pymysql.readthedocs.io/en/latest/modules/cursors.html#pymysql.cursors.Cursor.execute
Im getting TypeError: not all arguments converted during string formatting When using the %s placeholder in my sql. is there a different way to do this?
ping me please
Your placeholders and parameters probably dont match. You would need equal amounts. @minor venture
@little pumice you need to respawn the windows terminal itself
all apps on windows have their environment variables set once when they start
yeah i had the wrong syntax for my parameters
, %s);', guild) changed to -> , %s);', (guild,))
hey guys, somehow i can't install psycopg2 in my venv on vscode for django. It shows me a really weird error-code with
ERROR: Command errored out with exit status 1:
whats the rest of the traceback
that error message tells us literally nothing except "there is an error"
@noble oak
@pseudo cove can i dm you?
put it her
it's in help-magnesium
I'm trying to find if I have any rows in my table with a particular column value and currently I am doing:
cursor.execute("""SELECT ORDER_ID FROM ORDERS WHERE ORDER_ID='VALUE'""")
if not list(cursor.fetchall()):
#do the thing
Does that seem reasonable?
You could make it better by using a limit of 1
Since you don't care about the actual values; you just need to know if there's at least 1 item
Therefore limiting the query to 1 item will be more efficient
Ah yeah. Ta.
Wasn't sure if this vs SELECT COUNT(*) ... WHERE ... would be better tbh
I'm not sure either. I think it's marginal
You need a condition to check the count anyway in Python, whether its 0 or 1, so that's not any better than just checking the length of the results like you are currently
An exception being if the column you use contains very large data, but in most cases you have a small PK so it's no problem to use that as the column
I realised I can actually just do if cursor.fetchone()
Which should at least be more efficient from a python perspective than using fetchall
also fetchall returns a list anyway so not sure why I wrapped it there... 🤦♂️
Don't code before coffee
I don't know if fetchone actually limits the query or if it fetches everything and just truncates the rest.
Well it doesn't truncate the query. But you aren't pulling the entire result into python as I understand it
I think it's more efficient
Got me curious
I dug into the sqlite3 code a bit but don't have the will to try to understand it at the moment
Should note that fetchone actually works kind of like next() does for iterators
So you can call it over and over until it exhausts all rows in the results
Yup
I think the reality is the important part of it is really which DB implementation you are using tbh.
I think that in cases where your python is running on a different server to the sql DB fetchone can help reduce time transferring across network?
I don't know about the nitty gritty details, but I'm curious
It's hard to follow the source cause it's C and nothing is documented
Was just looking for any indication of the the execute() doing some sort of operation on all results, even if it doesn't necessarily load it all into memory
I thought execute just ran the query on the SQL server side
And nothing is returned to python in terms of a result
Hence why you even have to call fetch* in the first place
I found some docs on this. For SQLite, its API lets Python request one row at a time from a prepared statement (i.e. SQL)
SQLITE_DONE means that the statement has finished executing successfully. sqlite3_step() should not be called again on this virtual machine without first calling sqlite3_reset() to reset the virtual machine back to its initial state.
If the SQL statement being executed returns any data, then SQLITE_ROW is returned each time a new row of data is ready for processing by the caller. The values may be accessed using the column access functions. sqlite3_step() is called again to retrieve the next row of data.
That being said, there could be some more optimisations around specifying a limit. I don't know, but I am satisfied with this answer
@meager vine could you try doing a count query vs a limit query and time them? I think a count query should be faster to execute
I mean probably. Apparently the SQL Server equivalent of TOP is often slower than just fetching everything because the query optimizer gets befuddled
You can't use count with limit, can you? I didn't even consider that at first
I suppose that would be pointless anyway cause you can just do SELECT 1 or something if even your PK is large
Anyone using peewee for orm?
sigh now i have to write my own migration tool. why didn't i just use sql alchemy
anyone know of a large production application using peewee
can i do
conn.execute(f"CREATE TABLE {name}(ID INTEGER PRIMARY KEY AUTOINCREMENT,NAME TEXT, MESSAGE TEXT, TIMESTAMP TEXT)")
as long as i check for sql injection?
why not just use a parameterized query
it's a bad idea to attempt to check for this stuff yourself. you will mess up
if there is no way client input can dictate {name} then it's fine, but otherwise always used parameterized queries
the number of applications i use with sql injections issue is basically everything on the net except companies that are known for engineering
well i plan on letting people build chatrooms. so it could potentially be sql injected... but im trying to think of another way to do it
look at the post i sent you
that's the appropriate way of doing it
also why are you creating different tables for each chatroom?
you could technically have it all in one table and you can avoid this altogether
if your concern is speed then proper indexing will make this a non issue 🙂
but if you really wanna go down this route use parameterized queries as shown in the article above 🙂
chatroom is db name > topic table name. lets me reuse the code already built. but the table name will have to be a variable to be able to do it this way
i'm not certain how it changes things really, but yes if that's the approach you can definitely use the example above 🙂
i know salesforce does the same thing
multiple ways of doing a multi-tenant system 🙂
I have a problem with installing mysqlclient, I can't figure out the error
SOLVED
@remote vessel don't create tables dynamically
just add a chatroom id field to a single main table
and tag every message with the right id on insert
that's the sql way to do it
also if you're making this with user input you're going to get pwned
badly
unless you use parametrized queries using non dynamiclly created tables
def buildDB(c_name="CompSci", t_name="Homework"):
timestamp = buildTS()
param_dict = {
"name": "SYSTEM",
"msg": "Welcome to the chat!",
"timestamp": timestamp,
"table": t_name
}
path = getPath(c_name)
print("building database")
conn = sqlite3.connect(path)
sql_placeholder = "CREATE TABLE " + param_dict["table"] + "(ID INTEGER PRIMARY KEY AUTOINCREMENT,NAME TEXT, MESSAGE TEXT, TIMESTAMP TEXT)"
conn.execute(sql_placeholder, param_dict)
sql_placeholder = "INSERT INTO " + param_dict["table"] + "(NAME,MESSAGE,TIMESTAMP) VALUES (?, ?, ?)"
conn.execute(sql_placeholder, (param_dict["name"], param_dict["msg"], param_dict["timestamp"]))
conn.commit()
conn.close()
is the code im using. its been "cleaned" i thought, cant get the %()s to work, so i changed it to this
@pseudo cove
let me repeat this again
but i understand what your saying. just means ill have to change the sql code and rebuild the display for the whole rest of the chat
idgaf
your method isn't secure
nor is it anywhere near clean sql
you should never be modifying db structure dynamically
never
especially based on fucking user input
do you care about security
even if its stored and approved by admin?
bruh
it's still shitty sql
even if you "claim" there's not going to be a security vuln
there is literally no problem
to which dynamically creating tables/columns/dbs is the right solution
so my chat program, pulls based on the id thats auto incremented. only runs if the id has changed. if you add in a topic_id column, you also must create a topic_id_id column as well to keep with the same idea?
wut
why do you need an id for the id
you don't?
you're only going to be selecting where topic_id = 1337 or something
maybe add a join or something
correct, but the program is keep a running total in cache of the chats. and updates if the running total != id. otherwise it skips and waits for the next count. putting them in the same database changes the id, but wouldn't necessarily change the chat. how do you cache the running total of multiple chats in one table?
my timestamp was put that for ease of posting in chat. just building for ease first then changing later once its fully built
but i like your idea. can cache the datetime of the last topic_id = and only modify if its changed
Ignoring exception in on_member_join
Traceback (most recent call last):
File "/home/pi/.local/lib/python3.8/site-packages/discord/client.py", line 312, in _run_event
await coro(*args, **kwargs)
File "/home/pi/Desktop/TelBot/cogs/Welcome.py", line 21, in on_member_join
db = await aiosqlite.connect('TelBot.sqlite')
File "/usr/local/lib/python3.8/site-packages/aiosqlite/core.py", line 124, in __await__
self.start()
File "/usr/local/lib/python3.8/threading.py", line 852, in start
_start_new_thread(self._bootstrap, ())
RuntimeError: can't start new thread
How can I list tables with asyncpg? Can't run await connection.execute("\dt") without getting syntax error at or near "\"
Or I shouldn't bother and just CREATE TABLE IF NOT EXISTS on each launch?
You can select the tables from information_schema.tables where the table schema is public @torn sphinx
I'll try that, thank you
How can I fix this mysql.connector.errors.NotSupportedError: Authentication plugin 'caching_sha2_password' is not supported (I am new in coding)
(My code:
host="192.168.1.251",
user="Minecraft_server_database_user",
password="Minecraft_server_database_password",
database="Minecraft_server_database_table"
#I fill the things good in
)```)How so?
Postgres support modern applications feature like JSON, XML etc. while MySQL only supports JSON. Postgres is much faster. PostgreSQL is complete ACID compliant while MySQL is only ACID compliant when used with InnoDB and NDB.
postgres optimizes complex queries very well
when mysql is having trouble doing this
mysql is a thing of the past
The data you see in there is the data you entered
Which means you will have entered null value into it somewhere
You can set a NOT NULL constraint to those columns if you dont want to enter null values, which would raise an error when trying to do so.
so while creating a table i have to do NOT NULL for each lines?
async def antithreaderror(time=1hour):
await db.close
await asyncio.sleep(1)
(what is the command to start the database)
@pulsar kestrel You can yes, however as I said that will only prevent NULL values from being entered as a query to the DB. It seems your issue is you are passing NULL to the query, which you may need to troubleshoot as well.
thanks a lot
@shy viper What are you trying to do? Why close the DB and sleep and reopen?
Ignoring exception in on_member_join
Traceback (most recent call last):
File "/home/pi/.local/lib/python3.8/site-packages/discord/client.py", line 312, in _run_event
await coro(*args, **kwargs)
File "/home/pi/Desktop/TelBot/cogs/Welcome.py", line 21, in on_member_join
db = await aiosqlite.connect('TelBot.sqlite')
File "/usr/local/lib/python3.8/site-packages/aiosqlite/core.py", line 124, in __await__
self.start()
File "/usr/local/lib/python3.8/threading.py", line 852, in start
_start_new_thread(self._bootstrap, ())
RuntimeError: can't start new thread
@shy viper What are you trying to do? Why close the DB and sleep and reopen?
@proven arrow i can make a singolur connect for fix?
I guess that error is because you have used all available threads?
the bot then works after 10 hours you have to restart the bash otherwise it gives me that error
when I stay it he doesn't give me any more error
after 10 hours he gives it back
hii
Instead of closing the database like how you said previously, you can try closing it after you are done using it. Well at least thats how the documentation for sqlite shows this.
but my bot needs to be used 24/7 for 1 full year
db = await aiosqlite.connect(...)
cursor = await db.execute('SELECT * FROM some_table')
row = await cursor.fetchone()
rows = await cursor.fetchall()
await cursor.close()
await db.close()
Or with a context manager:
async with aiosqlite.connect(...) as db:
await db.execute("INSERT INTO some_table ...")
await db.commit()
See the examples above. The first example, you close the DB by executing await db.close(), and in the second example it is closed automatically for you.
@proven arrow now i am getting empty datas
but my bot needs to be used 24/7 for 1 full year
@shy viper In that case you may want to consider upgrading to a database that can handle more powerful database.
@pulsar kestrel Are you even inputting any values to your query? Inspect the parameters you pass to the query
I think you mean upgrading to a actual server type database
secondly i dont think his error is the db
its the fact he connects to the DB on every member join
I think its opening too many threads
which even if his bot is in like 20 servers still has the potential to be alot of connects a second
I assumed it opens one thread per db open
it does
Which they never close
hes just opening hundreds of connections
Yeah i mentioned to close the db
db = await aiosqlite.connect(...) cursor = await db.execute('SELECT * FROM some_table') row = await cursor.fetchone() rows = await cursor.fetchall() await cursor.close() await db.close()Or with a context manager:
async with aiosqlite.connect(...) as db: await db.execute("INSERT INTO some_table ...") await db.commit()
@proven arrow should I put it at the end of the commands?
thats generally a really bad idea
First understand the problem you are having and why.
db = await aiosqlite.connect(...) cursor = await db.execute('SELECT * FROM some_table') row = await cursor.fetchone() rows = await cursor.fetchall() await cursor.close() await db.close()Or with a context manager:
async with aiosqlite.connect(...) as db: await db.execute("INSERT INTO some_table ...") await db.commit()
@proven arrow should I put it at the end of the commands?
how does mysql handle selectfield values?
@proven arrow yes i am typing something to my input fields and then click on submit and then i check my table and it's still empty
No i meant, the parameters being passed to your query. @pulsar kestrel
no i want that those datas get dynamically to my table
every user fill it then it automatically fill the database with datas
It doesnt matter what the user fills in. Its what values you pass to the database. If your table shows an empty value for an inserted row, then that is the value you passed it.
how to remove some string for the json
@torn sphinx huh?
i have something that puts a message in the json sent by a user
hi i have question. How to backup pgadmin database?
but it only stores the first message and i want it to delete the previous message and store the new one
you can overwrite it or use dict.pop()
json is dict in pythob
async def open_msg(user, content):
with open("msg.json","r") as f:
users = json.load(f)
if str(user.id) in users:
return False
else:
users[str(user.id)] = {}
users[str(user.id)]["msg"] = str(content)
with open("msg.json","w") as f:
json```aaaaah
dict.pop
aight i will try
scary code
also json is not a data base
you know
yeah
hi i have question. How to backup pgadmin database?
@torn sphinx Is that your question or you're quoting someone else?
@tepid cradle hello
this is my question
because i did the pg dump but file disappear somewhere
so im confused
i can do also from the command line if that is easier
OK. Then first of all, it's not a pgadmin database. It's a PostgreSQL database.
pgadmin is just a software which connects to the database and allows you to run queries on it
coming to the second part, I don't use pgadmin, so I can't say where it dumps the backup. But when you are using the command line to export, you can specify a location where you want to save the backup
Are you using Linux or Windows?
windows gang here
Oh
but i think the commands are the same or should be right?
I'm also Windows gang member, but sadly my Db runs on a Linux machine
oh lol
This is what I use for backup
sudo -u postgres pg_dump db_name | gzip > \home\myusername\backups\db_backup.gzip
So for windows, this should work pg_dump db_name > c:\path\to\backup\folder\db_backup
yeah let me try