#databases
1 messages · Page 62 of 1
okie what do I edit

wait theres nothing in the folder where it should be tf
use Windows search to find it
Is there anything else in C:\Program Files\PostgreSQL ?
nope
So if you go to the start menu and type PostgreSQL does something come up?
What's the difference between pool.fetch and pool.aquire.fetch?
speaking about asyncpg
They basically do the same thing
is asyncpg just for postgreSQL @river barn ?
Ye
ah
How would I setup a Postgres replication that only consists of specifc tables?
Hi, im supposed to remove referential integrity and indexes by using the ALTER TABLE command, and have been given these ALTER TABLE tablename DROP FOREIGN KEY keyname_FK2;
ALTER TABLE tablename DROP INDEX keyname_FK2;ALTER TABLE tablename DROP PRIMARY KEY; to use. I was able to drop the foreign keys and primary keys from my table, but i cant get the drop index part to work
I keep getting the error Error Code: 1091. Can't DROP 'CustomerName'; check that column/key exists, im on mysql btw
Are you running ALTER TABLE table_name DROP INDEX index_name;?
The return looks like you aren't providing the index keyword
no, im only using the ALTER TABLE tablename DROP INDEX keyname_FK2 provided @weary heart
indexes are the items in the first "fields" columns right ?
so can indexes be automatically created? such as when creating a primary/foreign key or something like that
What are the benefits of having a relational database with foreign keys as apposed to just querying multiple tables in the same query
I don't understand how multiple selects is a substitute for a foreign key
Can you elaborate on what such query would be?
Oh that is not what I had in mind when you said multiple tables in same query
I have not even tested what I'm asking, was just some debate between me and someone else as to why we should even use foreign keys
Well lets ignore foreign keys for a moment
It's still obviously useful to store some field of table B in table A
So you can associate it with a certain record in another table without just flat out merging things together or having redundancy
So, on top of that we just add the idea of a foreign key which is basically just for referential integrity
To me it seems like the argument is more "Why even bother referring to one record in another record?" rather than "Why bother ensuring the thing I'm referring to is actually valid and exists?"
Regarding the former I kind of touched on how other solutions would involve redundancy or requiring data to all remain in the same table.
Hope I understood you right
Either way I don't see how a select like that solves anything. How would you specify which rows to select?
Iirc all tables use a member id to indentify who it belongs to
Yeah
Like i have players
Whos ID is just their discord id
and they have an inventory and an adventure
but since i only want them to at all points only have 1 of each
i set those ids to the members id as well
Ok, I should have asked for this info sooner
I can see why a foreign key seems redundant
However it still enforces referential integrity
Otherwise your schema can't guarantee that all the tables for a given player will exist
Sure, you can point you your code and say "well this is the only part where these tables are made and you can see all 3 are created" but the point of constraints is that they are enforced at a "lower level" per-se than the code
hmm
without foreign keys I could go into the console, connect to the db
and type sql to just drop one of the records for 1 table for a player
and nothing would stop me
await cursor.execute("UPDATE clans SET clan-members = %s WHERE `clan-members` LIKE '%{}%'".format(ctx.message.author.id), (value,)) await conn.commit()
Command raised an exception: ValueError: width too big
Why i have this error?
Nvm
So I'm setting up a simple experience system for a bot project of mine, which involves the use of sqlite3. For some reason, my add_experience function does not seem to want to cooperate with me, and I cannot for the life of me figure out why. This is the only issue that I am having with my experience system, but as the function name suggests, it's quite a vital component.
async def add_experience(userdata, newtime):
c.execute("UPDATE experience SET UserExperience=:UserExperience AND LastMessage=:LastMessage WHERE UserID=:UserID",
{'UserExperience': (userdata[2] + random.randint(20,30)), 'LastMessage': newtime, 'UserID': userdata[0]})
conn.commit()
Context:
- The data stored in the
experiencetable of my file is in columns as follows:
a) UserID text
b) UserLevel integer
c) UserExperience integer
d) LastMessage real LastMessageis being stored as a float from the use ofdatetime, specifically (presuming onlyimport datetimeis at the top of the file)datetime.datetime.now().timestamp(). This is used to prevent spamming to quickly level up, as the bot checks the time stamp of each message and compares it to the value stored inLastMessagefor this user.connis my variable to establish the connection to my file, andcis my cursor.- Yes, I have used various print statements to check if the inputs each pass my conditionals, and it successfully reaches the point where this function is called. Additionally, I have an updated version being used to immediately return the data and print it to the console, for testing purposes. This is just another
c.execute("SELECT ...")call, thenprint(c.fetchone()). No update to any of the values.
Is anyone able to help me with this? I can provide more code or information about my file arrangements as necessary.
Please ping me if you believe you can provide an answer.
@kind fox (if you use async, use aiomysql)
what am I doing wrong?
@torn sphinx https://docs.python.org/3/library/sqlite3.html
@regal portal what is the difference between aiomysql and sqlite3?
aiomysql is better if you use async
@torn sphinx you aren't connecting it to a file or to memory
test.db?
conn = sqlite3.connect('file.db')
Oh
Hmm..
I didn't notice the second screenshot
..huh.
I mean sure it may be better but how is it better, that's what I would like to know
@Zork
But aiomysql is asynchrone
So can anybody help me?
@torn sphinx one of your files is named sqlite3 so python imports that instead of the standard library module. rename it
Yes?
oh
@kind fox why do you use async?
Is that a general question as to its purpose or are you asking my specific application?
Yeah
..that was an either/or question
I'm going to assume you were referring to the first option - async is used to tasks can be run simultaneously or out of order from where they're defined
You never commit
I told you to read this page, https://docs.python.org/3/library/sqlite3.html it has all the basic examples @torn sphinx
c = conn.cursor()
# Create table
c.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
# Insert a row of data
c.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY','RHAT',100,35.14)")
# Save (commit) the changes
conn.commit()
# We can also close the connection if we are done with it.
# Just be sure any changes have been committed or they will be lost.
conn.close()
--> # Save (commit) the changes conn.commit()
oh
sorry
why?
k
what does that do?
do I have to type that every time?
do I have to pip install it?
Also I cant find something like a documentation on the internet
I think I'll just stay with sqlite3
what you said makes 0 sense, dude
blocking code != slow code
running 2 + 2 in a command is blocking but it doesn't make the bot "extremely slow"
just stick with sqlite3 for now,
sqlite3 was kinda enough for work with one server
@quick hill dump operates on a file object:
with open('file.pickle', 'wb') as f:
pickle.dump(data, f)
i gave it a file
no
db is a dict, not a file
(or well, any picklable Python object)
ah yeah sorry did not read
pickle.dump(data, open("users.p", "wb")) the only place i dump is here
well, your file is still open in read mode, that might be an issue
in mysql, when creating a schema, i drop down to my tables --> indexes --> PRIMARY. Why is primary there? Its in all my other tables too. What does it mean?
How could I order by the largest int of all records/rows/transactions in sqlalchemy
I dont know sqlalchemy but i guess this has some answers 😄 https://stackoverflow.com/questions/4186062/sqlalchemy-order-by-descending

Stack Overflow
How can I use ORDER BY descending in a SQLAlchemy query like the following?
This query works, but returns them in ascending order:
query = (model.Session.query(model.Entry)
.join(model.
Nice
I looked at https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-iv-database but didn't userstand until that link :)
So.... barring the aiomysql vs sqlite3 issue, since that was discussed earlier... should I repost my question?
What was it?
I would like to have in my table a PrimaryKey as a ForeignKey.
Is a 1 to 1 relationship. I just want to avoid having a table with LOT of columns.
So how to do that ?
Let's say Master, is my master table.
And Slave, is my slave table.
What should i declare?
On my master, i said that i have a column which is a foreign key of my slave.
And on my slave, I put a column which is the primary key and also the foreignKey of the id of the master.
Is it even legal to foreign key two tables between each other?
That's why I'm asking because something seems very bad
You can't have both table reference each other. Well, maybe you can technically but it'd be impossible to follow such constraints when inserting data
Only way is if you allowed one of the foreign keys to be null
I want Master to reference Slave.
and i want Slave ID to be same as Master ID.
and then later updated it after insertion
So you want their primary keys to be identical?
yep
Yeah that should be totally fine
They're in different tables so it doesn't matter
The keys will still be unique to their respective tables
yep
Does that answer your question then?
Mhh well. how can i do that?
So i have that situation
Master
Column n°1 : ID
Column n°2 : the reference to slave.
Slave :
Columns n°1 : ID as same as Master.
Maybe i don't need the id of slave to be same as master as I do reference
You would need to know the ID before the slave record is inserted
I create the slave, i get the ID, and i put as refernece to master
I'm searching something compilcated to something simple
Well yes, the ID can be anything you want as long as it's unique - they don't have to be the same ID
If it was the same, i wouldn"'t need a foreign key.... x)
You still would. Foreign keys enforce referential integrity
Yeah btw
But i mean my question was completely useless
because it the purpose of foreign key to make the link
I don't really care that my slave ID have the same as master ID
Right
It's very late here, god
Cause if you have the master Id you can get the slave ID by looking in the foreign key column
Reposting my original question in a screenshot because I'm lazy:
@kind fox why is that function declared async?
Also, define "does not want to cooperate"
It runs properly, i.e. no errors or anything and placeholder prints show up, except that it doesn't actually save the information in the database.
And as for your first question
I... don't actually remember. 
They're way they're used is no longer defined as async, though, if that makes you happy... same issue.
@kind fox how are you calling it? Show all involved code
Sure, just a sec.
I should note that this function is being defined in an external file, leveling_scripts, and is being imported within one of my bot's cogs, events, as ls
async def on_message(self, message):
if message.author.bot:
return
c.execute("SELECT * FROM experience WHERE UserID=:UserID", {'UserID': message.author.id})
member = c.fetchone()
time = datetime.now().timestamp()
if not member:
ls.new_user(message.author.id, time)
embed = discord.Embed(description = 'You hit level **1**!', color = 16755420)
embed.set_author(name = 'Level up!', icon_url = ctx.message.author.avatar_url)
await client.send_message(ctx.message.channel, embed=embed)
else:
if time - member[3] >= 60.0:
ls.add_experience(member, time)
leveled = ls.level_up(member)
if leveled:
embed = discord.Embed(description = 'You hit level **{}**!'.format(member[1]+1), color = 16755420)
embed.set_author(name = 'Level up!', icon_url = ctx.message.author.avatar_url)
await client.send_message(ctx.message.channel, embed=embed)
This is my on_message event within my events cog.
add a print statement to add_experience to check that it is properly called
hang on, I technically have one, it's just not in my original screenshot.
def add_experience(userdata, newtime):
print(userdata)
c.execute("UPDATE experience SET UserExperience=:UserExperience AND LastMessage=:LastMessage WHERE UserID=:UserID",
{'UserExperience': (userdata[2] + random.randint(20,30)), 'LastMessage': newtime, 'UserID': userdata[0]})
conn.commit()
c.execute("SELECT * from experience WHERE UserID=:UserID", {'UserID': userdata[0]})
print(c.fetchone())
The updated script, it'll show the old data and the new data.
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
The output does not change
between the first and the second
why should it? you are reading right after writing, you will obviously get the same value
put this
c.execute("SELECT * from experience WHERE UserID=:UserID", {'UserID': userdata[0]})
print(c.fetchone())
before print(userdata)
def add_experience(userdata, newtime):
c.execute("SELECT * from experience WHERE UserID=:UserID", {'UserID': userdata[0]})
print(c.fetchone())
print(userdata)
c.execute("UPDATE experience SET UserExperience=:UserExperience AND LastMessage=:LastMessage WHERE UserID=:UserID",
{'UserExperience': (userdata[2] + random.randint(20,30)), 'LastMessage': newtime, 'UserID': userdata[0]})
conn.commit()
c.execute("SELECT * from experience WHERE UserID=:UserID", {'UserID': userdata[0]})
print(c.fetchone())
Updated code...
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
"new" results.
well, it show that userdata is exactly the same as before
your function is working well, the issue comes from userdata
nah
Okay
pretty weird indeed 🤔
I should note that I've had print statements just with numbers to show the steps that the bot does take
is c defined from conn?
print your member and time in on_message
('267340999498399764', 1, 0, 1553303783.852234)
1553506209.112684
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
Never removed the old print statements.
print(newtime) in your function?
It will be on the line right after print(userdata)
member -> ('267340999498399764', 1, 0, 1553303783.852234)
time -> 1553506375.084608
fetchone()[1st] -> ('267340999498399764', 1, 0, 1553303783.852234)
userdata -> ('267340999498399764', 1, 0, 1553303783.852234)
newtime -> 1553506375.084608
fetchone()[2nd] -> ('267340999498399764', 1, 0, 1553303783.852234)
Just in case you lost track, I labeled them this time.
add assert c.connection is conn
oooh
wait a second
are you defining c and conn multiple times?
like, in different files?
Yes
okay, that is why
 well that's just brilliant lol
well that's just brilliant lol
you retrieve user data from a connection, and try to update it with another
you must use the same connection object
Where should I be establishing the connection? I would assume my bot.py file?
that's the equivalent of __main__ here
yeah, assigning it to your bot object might be a good idea
alright
define it somewhere and import it everywhere you need it
ooh.. good idea
Question
And this is more of a python question than a database specific one, but you seem smart lol

my files are split into a main folder and a subfolder, like so:
All highlighted files are where anything sqlite3 related is taking place
yeah
What directory would I place this file in to be able to define it properly
My main folder?
I assume it's a similar situation to my leveling_scripts
you can try to put that in bot.py in a first time
okay
Give me a sec to test.
Okay, so it doesn't work being defined only in bot.py
so it would have to be an imported file
you have to import it from bot.py in your other files
Pardon me if I'm misunderstanding, as it's getting late, but... how would I import only two specific lines from one file?
import their name
# foo.py
conn = sqlite3.connect('db.sqlite3')
cursor = conn.cursor()
# bar.py
from foo import conn, cursor
ahh... okay.
makes sense.
If I'm doing that, would I be importing sqlite3 in my other files?
i.e. the files where I'm importing conn and cursor?
no, just import conn and cursor
Python will take care of the nasty dependency trees
so just import sqlite3 in bot.py, and in my other files, import conn and cursor
let's see what happens, give me a few minutes.
yes
Well... things are working again, but not updating.
('267340999498399764', 1, 0, 1553303783.852234)
1553507205.219344
('267340999498399764', 1, 0, 1553303783.852234)
('267340999498399764', 1, 0, 1553303783.852234)
1553507205.219344
('267340999498399764', 1, 0, 1553303783.852234)
@kind fox did you import conn and cursor from bot.py to the files where on_message and you function are?
I imported it to leveling_scripts, leveling, and events
yes
If I hadn't, they would not be able to grab the data.
ah yeah, you must not import cursor and conn but you must assign them to an object accessible from your functions
like a Bot object if you have one
otherwise, you must define cursor and conn within your on_message callback, and pass it to your function so that they remain the same
could I technically make a cog for this?
I do have one for bot development and processes
i.e. stuff like making the bot go to sleep with a command, simple stuff
could I add it there?
no, that is not the point of a discord cog
client = commands.Bot(command_prefix = '.')
Are you referring to this line?
Sorry, I'm starting to get to the point where things aren't making as much sense for me anymore.
Both in a combination of "I'm not sure what you mean" and "I'm tired"
You are.
Sorry for that exhaustion, aha. Once I sleep a bit I'll test it.
Thanks so much for your help.
I shoved the database functions into an extension and load it wherever I need it. But I did set up the db connection in the main bot file
Has anyone had issues doing inserts into a MySQL DB using mysql.connector?
is this the best place to ask for help, or should I use a different channel?
I am using python 3.7.2 on a free-tier Amazon EC2 instance
connecting to a MySQL instance on free-tier RDS
The database is definitely up and running:
- I can log into it from my desktop
- I can see that another process is updating and inserting another table
My code does not throw an error, which is weird
the relevant part is:
print(insert_page_title_qry)
print(key)
print(url)
print(value)
insert_result = cursor.execute(insert_page_title_qry, (key, url , value))
print(insert_result)
conn.commit
and this produces this output:
insert into finder.pages_found (url, site_crawl, title)
values ( %s , %s , %s )
http://blueflame.co.za/contact-us.html
http://blueflame.co.za/
Contact Blue Flame
None
Blue Flame - Contact Details.
Blue Flame is a 100% black owned, multi-disciplinary, strategic communications agency based in Sandton, South Africa.
So I think I this is correct:
- the unbound query looks right, and I can compare it to the table structure
- there's no error or exception thrown that I can see
- the values all look correct
Is there some way of getting MySQL to tell me what it tried to execure?
Hey guys I have a MySQL related question.
When I create my cursor with the prepared=True argument, all the information I get back is raw (it's as if I'd use the raw=True statement with it) is there any way to fix this?
@static kindle is your table using the InnoDB engine or similar? If so, then you need to call the commit() method, otherwise it will not actually insert anything (InnoDB is a transactional engine, which requires that inserts, updates and deletes be "committed" after running the query)
Also, if you are using MySQL connector (from oracle's site), I recommend using the pyformat method for arguments and passing a dictionary for the args themselves (see below example), rather than using %s and a tuple of arguments.
query = "INSERT INTO `some_table` (col1,col2,col3) VALUES (%(col1_val)s, %(col2_val)s, $(col3_val)s)"
data = {"col1_val": your_variable_value_here, "col2_val": your_variable_value_here, "col3_val": your_variable_value_here}
cursor.execute(query, data)```
pyformat is a lot easier to use, and in my own experience, I found that doing this helped with escaping things (as i didn't need to do it myself, the lib did it on my behalf and reduced code complexity)@onyx seal Thanks for the reply :-)
Yes, the tables are InnoDB, and there is a commit there already. Have to go out for a while, but will create a more readable copy of the code and output, then look at the pyformat option.
👍
cursor = conn.cursor()
...
cursor.execute(clear_page_titles_qry, (url, ))
print('Delete page titles done')
for key, value in page_titles.items():
print(insert_page_title_qry)
print(key)oops
cursor = conn.cursor()
insert_page_title_qry = """insert into finder.pages_found (`url`, `site_crawl`, `title`)
values ( %s , %s , %s )"""
....
for key, value in page_titles.items():
print(insert_page_title_qry)
print(key) print(url)
print(value)
print('Inserting...')
#subs_text = ("insert into finder.pages_found (`url`, `site_crawl`, `title`) "
# "values ('" + key + "', '" + url + "', '" + value + "')")
#print(subs_text)
cursor.execute(insert_page_title_qry, (key, url , value))
#cursor.execute(subs_text)
print('Inserted ...')
....
conn.commit
Is that any more readable?
Anyway, this outputs all of the values that end up in the tuple, and executes the print statements before and after the cursor.execute and conn.commit statements
So I am confused!
Also, it's not in a try: block
is it possible that the cursor is not ready somehow?
do I need a different kind of cursor for an insert than for a select?
anyone know nay SQL discord group ?
Anybody on with experience in flask and sqlalchemy?
I'm trying to create essentially a search function with sqlite3 I have done this so far:
search = input('Search: ')
cursor.execute('SELECT * FROM users WHICH =?', (search,))
print(cursor.fetchall)
Currently not worried with how it's displayed however my problem is that I'm trying to have it look through all the columns and show me results where the user input is mentioned
Would anyone be able to help me?
does anyone know a way to check if something exists in a database?
@feral glen json, some form of sql?
json, pymongo
Can anyone recommend a good tutorial for using flask-sqlalchemy without the whole setting up a flask web-server. I only need it for my desktop app to communicate with a mssql server. I'm plenty confident with MSSQL (been using it for years at job) and confident enough with python. But all these ORM terms keep getting thrown about with no explanation in the tutorials I've tried and it's all going over my head at the minute 😦
@opaque palm if you don’t need to run a flask server then you don’t need to use flask-sqlalchemy at all. Just sqlalchemy. And if you already know sql well then the quickest, easiest thing to do would be to just use sqlalchemy-core, which skips the ORM entirely
Ah, I got recommended on here to go the flask-sqlalchemy route since ORM's are meant to be the better way to go about it
And there’s also reflection capability so in just a few lines of python you can set up sqlalchemy and have it do auto detect the tables
Not always true. Depends.
First off, if you aren’t doing the web server you don’t need flask
Flask is the web framework
Sqlalchemy is the orm
No need for flask-sqlalchemy unless you are building a web app
I was under the impression that the flash-sqlalchemy adds on features that arent in the standalone
Yes, features to make it easier to use the ORM from a web app you’re building haha
ah fair enough
flask-sqlalchemy is just a bridge between flask and sqlalchemy
Some will say orm is better than core, others the opposite, depends on your needs but if you already know sql well then the fastest way to get you going would be core
Unless you want to define the database as classes using python
If the db already exists and you just want to talk to it from Python, then that’s easily doable with core and maybe 10 lines of code
Sounds exactly like what I need then 😃
Then yeah the orm and flask stuff would’ve had you writing hundreds of lines of code defining each table and field and stuff
I've been using AHK for the front end for years and I want to port it all over to python , so all the complicated SQL views/statements are there already
oh god, that sounds tedious
Core just let’s you query a sql database using python functions that look similar to their sql equivalents
So some people hate that if they don’t know sql and definitely ORMs make some things much nicer to work with
But your use case is very different
I've used the sqlite3 module before for talking to a sqlite databse. With that I could just set a sql query to a string, and supply a dictionary with the values.
Will this be similar?
I can show you a quick example in a couple min that’ll get you started, walking into my office
That would be much appreciated
You can also do that if you want but I’d recommend using the python functions, they are the same syntax as the sql queries so you will recognize them, but just nicer than doing everything with strings
ah ok
I'll try out the python functions for it for sure
There are better tools entirely like records
I'll try sqlalchemy first since it seems it works with multiple db types and seems more of a transferable skill if i manage to learn it
Yeah just a second
find = self.bot.partners.find_one({'user' : str(member)}) if find == 'None': print('he was not a partner') else: print(find) self.bot.partners.delete_one({'user': str(member)}) print('partner removed')
find always prints as 'None'
yet it always tries to remove the partner
partner being the doc in the collection
this is pymongo
Would anyone be able to help me with a sqlite3 problem?
What problem are you having?
I'm trying to create essentially a search function with sqlite3 I have done this so far:
search = input('Search: ')
cursor.execute('SELECT * FROM users WHICH =?', (search,))
print(cursor.fetchall)
Currently not worried with how it's displayed however my problem is that I'm trying to have it look through all the columns and show me results where the user input is mentioned
Like a WHERE colmn_name = value
Yeah but WHERE all columns = value if that makes sense
You can chain those predicates togheter with AND or OR depding on wether one of them or all of them need to be matched.
WHERE column1 = value1 AND column2 = value2```Is there any way to streamline this as I have quite a bit of columns?
Not that I know of.
when i am printing specific fields in a doc using find it prints as {'_id': ObjectId('5c9a653f7c923609a87701d2'), 'partners': 0}
is there a way to get it to just print as 0
which is the value of the field
this is in pymongo
@opaque palm hey sorry i walked into work and noticed catastrophic issues with something i launched yesterday so had to just dive into that for a bit but can still show you what you want to be doing if you didnt already get it going in the last couple hours haha
for id in memberid:
print(id)
async with aiosqlite.connect('database.db') as db:
cursor = await db.execute('SELECT * FROM users WHERE id', {'id': id})
data = await cursor.fetchone()
await cursor.close()
print(data)```
As you see I also print (id) in the loop and it pritn outs all ids from the memberid variable one by one. But so some reason when I want to fetch data from the database it only give me data for 1 id multiple times. Itsl ike the id doesnt change therei think you are missing the part where you tell sql what you are matching to id. eg ... WHERE id=?', (id,) ) is the form i usually use
looks like with a dict you need cur.execute("select * from people where name_last=:who and age=:age", {"who": who, "age": age})
niec
Can you help me with something?
I have a table called Clans and an other one named Users. In Users table I save user data (crystals, wins ,loses crates etc) and in clans I save Clan data (members, slots etc) I want to create a leaderboard based on wins But idk how to do that. Since wins/loses are saved on Users table and Clan name/tag is saved on Clans table.
Have you used JOINs before?
In what way are you storing your users in clan @torn sphinx
No I havent used join
async def clan_create(self, clanid, id, owner, name, tag, member, memberid, membercount, clanslots, desc, created, rank, logo):
async with aiosqlite.connect('database.db') as db:
cursor = await db.execute("INSERT INTO clans VALUES (:clanid, :id, :owner, :name, :tag, :member, :memberid, :membercount, :clanslots, :desc, :created, :rank, :logo)", {'clanid': clanid, 'id': id, 'owner': owner, 'name': name, 'tag': tag, 'member': member, 'memberid': memberid, 'membercount' :membercount, 'clanslots' :clanslots, 'desc': desc, 'created': created, 'rank': rank, 'logo': logo})
await db.commit()
await cursor.close()
return```This is when a new clan is created
async def clan_invite(self, clanid, id, owner, name, tag, member, memberid, membercount, clanslots, desc, created, rank, logo):
async with aiosqlite.connect('database.db') as db:
cursor = await db.execute("INSERT INTO clans VALUES (:clanid, :id, :owner, :name, :tag, :member, :memberid, :membercount, :clanslots, :desc, :created, :rank, :logo)", {'clanid': clanid, 'id': id, 'owner': owner, 'name': name, 'tag': tag, 'member': member, 'memberid': memberid, 'membercount' :membercount, 'clanslots' :clanslots, 'desc': desc, 'created': created, 'rank': rank, 'logo': logo})
await db.commit()
await cursor.close()
return``` This is when a user joins a clanyeah sounds like youll need to select the clans, join in all the users for a particular clan and then sum the wins of the people in that clan
i dont know sql well enough to be able to explain exactly how to do all that though
Are you making a new record in Clans for every User that is in it?
async with aiosqlite.connect('database.db') as db:
cursor = await db.execute('SELECT * FROM clans')
clans = await cursor.fetchall()
await cursor.close()```Thats how I select all clans
Now I dont know how to merge a clan with a user.
learn sql joins on codecademy
Grote yes
then you will know
oh yeah i think you need to separate your tables out a bit more
one table for clans
one table for users
one table for what clans a user is in
assuming they can be in more than one
A USER_CLAN table that has the clan id and the user id.
if they cant be, then you can give each user a clan
Both being foreign keys to their respective table.
yeah
With the primary key being the combination of the two.
yeah you shouldnt make multiple entries for the same clan
thats duplicate data that youll have to keep in sync
separate that data out, either make it so a User has one clan they can be in and keep it in the User table
How should have I done it :/
or make a new table like Grote has suggested
Yeah, no, your way is better.
My way is for many to many relationships, which this isn't.
Instead of saving the user in the Clan table, keep the clan in the User table like riffautae suggested.
So I will have to reset clans?
or I can move them to user table?
because i cant move them one by one XD
yeah tbh your clans table is really bogged down with a lot of repeat and junk data
You only put the clan ID there.
you want a single entry for each clan that describes the clan itself
So you won't have duplicate data.
So I need to put Clanid into Users table
like check out your member count column
its different for every row even in the same clan
yea
But then it will still be seperated. Cuz I will need Clan Name/Tag to be shown in the leaderboard
You also have a clan with a negative amount of members.
yeah but that makes it way easier to select both clans and the details of who is in a clan
JOIN is the magic here
I shouldnt have created a an other table for clans. Same for crates I created a diffrent table to store items lol
idk why I did it again
no you do need a table for clans
clans are not the same as users
they have different data
you just need to establish a relationship between the two tables
In clans table I store memberid and clan id. But in users table I dont save clan id
clans
-----------------------
|clan id | clan data|
-----------------------
users
----------------------
| user id| clan id|
-----------------------```have both
for it to work in an sql database you have to build tables in this fashion
well they cant have memberid in the clan table
Likely thers only 40 users now that are in my clan table since I added clan tihng rcenlty
youll have to migrate your data
Ah, I see, saving both the id and the name isn't neccesary.
Since you would get the Name from the User table using the user id
Now I cant delete any of them because it will mes up everything.
the core of a relational db is stuff like these relationships
each row in a table can have a unique number that you can easily use to reference that data in sql statements, but that is not dependant on the data in the db
A process called normalizing is used to achieve a design like that.
https://www.w3schools.com/sql/sql_join.asp has some examples
OrderID CustomerID OrderDate
10308 2 1996-09-18
10309 37 1996-09-19
10310 77 1996-09-20```
CustomerID CustomerName ContactName Country
1 Alfreds Futterkiste Maria Anders Germany
2 Ana Trujillo Emparedados y helados Ana Trujillo Mexico
3 Antonio Moreno Taquería Antonio Moreno Mexico
discord messed up the formatting a bit :C
the second table is a list of customers
you can have a ton of customers and they each take up a single row
then you have a table of orders
each order takes up one row
but they reference a customer
that lets customers have an infinite number of orders
Give me a sec to create a new column and add clan id to users that are in clan
they are just 40
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
would produce
OrderID CustomerName OrderDate
10308 Ana Trujillo Emparedados y helados 9/18/1996
10365 Antonio Moreno Taquería 11/27/1996
10383 Around the Horn 12/16/1996
10355 Around the Horn 11/15/1996
10278 Berglunds snabbköp 8/12/1996
here it generates a new combined list of results, that has pulled in the customer name and lists it next to each of their orders
In a relational database, if you have to change data you should only have to change it in one location.
yeah you also dont need to list stuff like 'member count' since you can just check the number of Users that have that clanid
well if you dont, things will end up much more complicated and messy
this is the standard way of doing things because it turns out that long term its way simpler
Can someone help though? To set it up properly? Only if you want though.
Looking at the member counts of clans you can already see that having it duplicated can lead to problems.
think of each table like you would a class in python
class User:
def __init__(self, name, clan=None):
self.name = name
self.clan = clan
class Clan:
def __init__(self, name):
self.name = name
cool_guys = Clan("Cool guys")
leader = User("Jim", cool_guys)
except that these classes cant directly contain a list or other container
is it ok if I but in with a question too?
I have a question about how I best organize my data.
I have Discordserver with around 600 users.
Most users belong to around 20 different teams.
Some users belong to more than one team
Some users don't belong to any team.
I thought about the following structure:
Table "Users" with all userrelated information (userID, userName, ingame rank, ingame roles, ...)
Table "Teams" with all team specific information (TeamName, TeamShort, TeamColor, ...)
Tables "team_teamshort" for each team the members of this team are lists.
I feel like that is a stupid set up though. I would have to create a new table every time a new team is formed but I don't know how else to do it bc a member can be in more than one teams... Any advice on how to structure that propperly? I don't have a lot of exp with databases.
you can make a table that connects users and teams
have it contain userid and teamid
then any user can be in any number of teams
Can a user be in multipe teams and can teams have multipe users?
The primary is a composite of the userid and the teamid
Both being foreign keys to their tables
how do I do that?
What database are you using?
MySQL
Stack Overflow
Here is a gross oversimplification of an intense setup I am working with. table_1 and table_2 both have auto-increment surrogate primary keys as the ID. info is a table that contains information ab...
this?
Yes
where t1ID and t2ID are both primary keys right?
No, they are foreign keys.
yeah that's what I meant
t1ID + t2ID is the primary key
primarys in their respective tables
it should end up something like this
CREATE TABLE Users (
UserID int NOT NULL,
PRIMARY KEY (UserID),
);
CREATE TABLE Teams (
TeamID int NOT NULL,
PRIMARY KEY (TeamID),
);
CREATE TABLE TeamMapping (
UserID int,
TeamID int,
FOREIGN KEY (UserID) REFERENCES Users(UserID),
FOREIGN KEY (TeamID) REFERENCES Teams(TeamID)
);
oh users might be a reserved table name
Yeah they are the primary key of the ohter tables.
Nah it's not, it's fine
WHy do you have the id in there?
habit for all tables took it out
and a PRIMARY KEY (UserID, TeamID)
ok one more question
What happenes if I delete the user #394
IIRC if you have foreign key you can't just delete the entry you have to delete the other ones first right?
You can use ON DELETE CASCADE and it will delete itself from other tables automatically, but not 100% sure on that one.
ok I will just test it out and play around with it
Hey thank you two @nova hawk and @wind pelican that was very helpful!
yw :>
What does this error mean?
asyncpg.exceptions.DatatypeMismatchError: column "inventory" is of type character varying[] but expression is of type text
HINT: You will need to rewrite or cast the expression.
So your inventory column has been set to type Varying[] but ur trying to input type text
@ornate isle no problem, I'm in the opposite timezone and had just finished work and was out all evening. Just got up now so going to have a play around with it. if i don't manage to get anywhere in a few hours, i might @ you again if thats alright
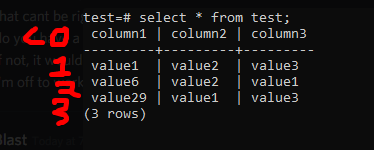
lets say i have a table like this:
+---------+---------+---------+
| column1 | column2 | column3 |
+---------+---------+---------+
| value1 | value2 | value3 |
+---------+---------+---------+
| value6 | value2 | value1 |
+---------+---------+---------+
| value29 | value1 | value3 |
+---------+---------+---------+
how can i search all rows which contain value1 and value2 in any column? (and being able to add optional values to search too)
are you after the raw sql for it or some way of doing it with a specific library?
raw sql, im working with it on python but i use raw queries
yeah there's a unique index on column1 column2 column3 (i think i found an issue with how im doing that, but i can fix this later)
that cant be right, you have "value2" twice in column 2
do you have a column where no value is repeated twice?
if not, it would be useful in this case to have one
I'm off to work now, but ill be on in just under an hour. happy to help more then
sorry i meant multi column index
but i think i did something wrong on my side
There @opaque palm from when you're back later, take your time. im just practicing and trying out stuff for learning lol
@opaque palm haha, which side of the world do you consider "opposite"? i'm still awake for a short bit
@ornate isle Not quite the opposite, but I'm guessing your US, I'm UK, So I've just arrived at work lol
@ionic zenith Ideally you'd have a column like this: https://i.imgur.com/AxQRvCD.png where each row has a unique number in it
{kind=link}
{kind=link}
{kind=link}
actually scrap that
just go "SELECT * FROM test WHERE column1 = 'value1' OR column2 = 'value1' OR column3 = 'value1'
bonus points if you set value 1 as a variable first rather than typing it out for every column
@opaque palm yeah i'm in los angeles. you get core going? or db reflection or any of that
Just starting to have a look now 👍
@opaque palm So I'd need to do multiple OR (3 per column) if I want to search for multiple values? I do remember reading about something regarding array overlaping to query multiple colums based off a value or multiple ones but sadly i cant find it right now
@ornate isle I've been looking through here (which still looks great for how to to translate my sql queries to sqlalchemy core):
https://docs.sqlalchemy.org/en/latest/core/tutorial.html
But it makes no mention of connecting to an existing database. Do you know what page that shows up on?
Though I think that wouldn't use the current index i have in case of a large table
@ionic zenith maybe, but generally, if you need to search multiple columns for 1 item, you're not storing the data correctly to begin with.
you could do with unions
Hmm I see
One more question, before I head off to bed lol I'll take a look at that a bit later
errm, i suppose you could use "IN" . like SELECT * FROM test where 'value1' IN(column1,column2,column3)
cuts it down a bit
Well, now its working but before I populated a database like this with 5 million rows and created that same index (column1, column2, column3) however when querying and doing a where only on column1 would do a bitmap heap scan and then a bitmap index scan (still new to these terms, but was around ~100ms), but if i did the where with conditions on column1 and column2 it would do the index only scan (~2ms) not sure why
will try to add more data and see if it happens since im only doing 1 million rows
weird, I would't be to sure on that then
maybe i was setting up the index wrong, since i can either query only for column1, or for column1 and column2 or so
@opaque palm setting it up is easiest! you just give it the db url
just playing with that now. i found the page to work out what to supply it with 👍
Cant replicate it but before it was
for first query plan execution time around 170ms using bitmap heap scan and then bitmap index scan)
second and third query plan took around ~1ms using index only scan (second also had two conditions on where, and third query had 3 conditions on where, just like in the picture. The difference is that on my tests earlier it used index only for 2nd and 3rd query and bitmap heap scan for first query)
im not sure why
maybe im setting up indexes wrongly? as i can have from 1 to 3 conditions
no idea there sorry 😦
this thing is going to drive me crazy heh
well maybe 100ms isn't much for 10 million rows, i dont know to be honest
but comparing it to the other queries which return in less than a ms...
@opaque palm heres a snippet: https://gitlab.com/snippets/1839407
that's all it takes to start querying in an existing db
@dense jungle https://asciinema.org/a/gUPJuNX2mKUWejRJalXPW5oA3

just me showing it in action
forgive the fact that ive slept 10 hours in 3 nights and i can barely remember how to launch the repl 😃
@opaque palm oh yea, i was testing the where in but it does a parallel seq scan and on 10 million rows on this pc it takes 12 seconds vs where column1 = 'value1' and it's 0.136ms;
Let's say I have 5 identical tables that I want to union where all the column names are the same, the only thing differing is the table name. In raw SQL is there a way to do a loop of some kind to union them all instead of having to copy paste the same query?
I've tried researching it but I feel like I am searching using the wrong terminology
@opaque palm yeah just a quick example, which i just wanted you to see because it took, what, 10 lines of code, whereas i remember yesterday you were about to embark on something much much too complex and overkill, which i see all the time because tutorials suck and the tools have changed and improved quickly
@ornate isle Yeah, I followed your vid and am now communicating happily with our* DB. I'm just following through their tutorial to use all the inbuilt commands . thank a bunch !
@opaque palm this might be helpful: https://www.pythonsheets.com/notes/python-sqlalchemy.html
theres both ORM and Core thrown in there so be careful
the sqla docs are certainly thorough but ive never found them intuitive or enjoyable
at least not quickly
yeah that looks handy. I was following https://docs.sqlalchemy.org/en/latest/core/tutorial.html
Hi all,
In Sqlalchemy, how do i reference a column name that has a space in it. For example, I'm using "users.c.fullname" currently. but what if the collumn name was "full name" instead ?
in my 15 years working with sql i have never even known you could do that
have spaces in columns.
@opaque palm so im not sure, but if you use the reflection thing i sent you, you can look at the reflected table
it will list its fields
it will probably show you if it's mapped it to an underscore or something, or if not you can just query it with strings otherwise i imagine
@ornate isle I'll take a look at that then, Thanks.
Yeah, I'm connecting to an external DB, and the developer will only allow access to certain views. Which for all other purposes can be treated like tables in sql when doing select statements... except he's aliased them all with damn spaces
i didnt know that was even valid and never thought about it because ive never encountered that
nor did i until yesterday
but yeah yo udont have to query using table.c
you can also do it with strings and a couple ways
ah , strings would make it much easier since I already know the column names
would it just be table['column'] then?
Anyone with knowledge of the sqlalchemy join able to look at this? I'm trying to use with_entities to limit the number of columns returned in a query and the table has two relationship fields to other tables which I'm trying to join the data from the three tables together. https://quickpaste.net/09712681e7a026fe1b425a2459b5298c
I don't know how to form the query so that it pulls the Character data and the relationship data to be accessed as well.
I'm creating a django web app and converting a pre-existing database for use in my django database. In my old database, I used lots of foreign keys linking to surrogate keys because I was adding values from excel and people were using MS access. With my new web app, the only way to create data is to go through the web interface. Data will be accessed via a REST api from DRF and I'll be using a Vue.js frontend.
Are there any best practices around foreign key columns when using a web app? I'm wondering if I could use the foreign key linking to a natural key (value field, a string) instead of the id (int) field.
you don't ave to have an id field at all, technically
if I reference the string value instead of the id, that would make viewing the data easier.
just make the natural key the primary key too
if you're converting a pre-existing database that might be complicated, but at least create a unique index
by default django uses the id field but I'm pretty sure I saw how to link to the natural key
or I could just remove the id field.
ah well i'm not sure about django, i just meant for database design in general, if you have a natural key you can just make it the primary key and not bother with an id key
yeah, I'm just wondering what would make my life easiest in the long run and what problems I might run into with django/vue if I used natural keys.
I think I'll jsut switch to natural keys and insert values from dropdown lists, etc.
what is the best tool to use to host a databse server on a headless ubuntu virtualmachine
easy setup. i have experience with windows sql server but for my project i want it to run on ubuntu without gui
I'd go with mongo
I can't install Postgresql on Win7. It shows me the error 1 when I launch the installer. Found a way around this error by launching the installer with --install_runtimes 0 parameter, but it leads to error 2. I tried to search for solution, but kinda failed
I tried 10.7 and 9.6 installers, and I run them as administrator
Maybe it doesn't work because I try to install it on my work PC, but hey, I managed to install sqlite and other stuff here
http://s3.micp.ru/4z9Eq.png
http://s1.micp.ru/Ncyr8.png
{kind=link}
{kind=link}


@harsh pelican MariaDB is okay. If that is for a local tool also consider SQLite
how can i make a database with python and MySQL?
Choose a library and search for examples
Hi,
this isn't specifically a python question, but it is a DB question and I don't know where else to ask.
When I first run a query, it takes 20 seconds to run, but if i run it again after a few seconds, it runs near instantly.
What could be the cause of this?
Many thanks in advance
@opaque palm probably the data is in cache after your first query
without knowing more about what db engine, what kind of query, etc, impossible to say more
After having a play around with it some more, I think you may be right @patent glen Thanks.
shame though, I'd love that speed every time I queried it
@opaque palm depending on what kind of query it is, adding an index may be helpful
20 seconds is a long time
@patent glen It's our accounting database so I can't go adding indexes sadly, and they never bothered to set up indexes on anything useful. 15+ years later and here we are lol. 20s is a short time for some of the queries I run 😦
ah
@reef musk
cursor = await db.execute("UPDATE garage SET :item = 1 WHERE id = :id", {'item': item[:-3].lower(), 'id': ctx.message.author.id})```
I cant format columns?
`sqlite3.OperationalError: near ":item": syntax error
Command raised an exception: OperationalError: near ":item": syntax error`no, you can't
Ughhh So I need to add if statements for 14 turrets and 7 hulls lmao
if item == "wasp":
lmao rips
@torn sphinx - you can use f-strings --> cursor = await db.execute(f"UPDATE garage SET {item[:-3].lower()} = 1 WHERE id = {ctx.message.author.id}")
Command raised an exception: TypeError: '>' not supported between instances of 'NoneType' and 'str'
@reef musk
The column I am trying to update is set Null
I think the error is from somewhere else. Hold on
Ah yeah
if wasp > item[-1:]:
Wasp is set to Null
How to fix that?
I want to keep it null
async with aiosqlite.connect('database.db') as db:
cursor = await db.execute('SELECT * FROM garage WHERE id=:id', {'id': ctx.message.author.id})
data = await cursor.fetchone()
await cursor.close()
print(data)```It will just print values.
How can I get the colum name too?
@torn sphinx --> https://docs.python.org/3/library/sqlite3.html#sqlite3.Row
I tried that
but i get error
Wait let me do it agian to show you the error
It says something like aiosqlite does not have attribute Row
Something like taht
Also thats sqlite3
I need aio sqiite
@torn sphinx - the reason I shared the sqlite3 documentation is that aiosqlite3 is supposed to be an async implementation of same API, so usage is probably very similar ... looking at the source for aiosqlite it does look like it has row_factory and that the Cursor class uses sqlite3.Row, but I can't find documentation on usage specifically for aiosqlite. ... https://github.com/jreese/aiosqlite/blob/66a7b51d873eacffdbe9508ac1ef27846e5604d0/aiosqlite/core.py

GitHub
asyncio bridge to the standard sqlite3 module. Contribute to jreese/aiosqlite development by creating an account on GitHub.
what happens if you do print(data.keys())?
if it prints off the column names (like I suspect it will), then you could get both by iterating through for key, value in data.items(): ...
I'm trying to insert a large amount of csv data into a local postgres database. I'm just testing it with a single CSV file which is 3.1MBs in size and 21200 lines. I'm using sqlalchemy with the psycopg2 driver. My code creates an instance of my model with the data from a row, then adds it to a session. This process takes 2 seconds for all rows in the file. Then, at the end of the file, I commit the session. This takes 19 seconds. I figured I would be able to get much better speeds than that for commiting, since it's a local postgres instance. Does anything immediatly stand out with why this could be taking so long?
Edit: The program, data, and database are all on the same SSD, so IO speeds shouldn't be an issue
DataError: (1264, "Out of range value for column 'messageid' at row 1")
I use aiomysql
is that a question?
I already solved the problem
alright
so uh, I want to retrieve data from a table (MySQL) which has only multiple columns and one row, when I get all the data it outputs them as (273788132170792961,) for example so I tried putting them in a list one by one and this happened [(197054540015599616,), (142398345153871872,), (236187750301302785,), (238039035711324161,), (273788132170792961,)]
btw I am using pymysql
I'm not sure how to prevent it from putting (number,) and just put number,
also I'm using cursor.fetchone() with a for loop, if I made it cursor.fetchall() it will look more like....
((197054540015599616,), (142398345153871872,), (236187750301302785,), (238039035711324161,), (273788132170792961,)) [((197054540015599616,), (142398345153871872,), (236187750301302785,), (238039035711324161,), (273788132170792961,))]
Also the goal is to make a list like this:
[197054540015599616, 142398345153871872, 236187750301302785, 238039035711324161, 273788132170792961]
I'm not sure how you would use cursor.fetchone with a for loop but you can do unpacking like,
(number,) = cursor.fetchone()
mylist = [number for (number,) in cursor.fetchall()]```or just access by index py number = cursor.fetchone()[0] mylist = [row[0] for row in cursor.fetchall()]
@wind zinc
Oh thanks, I'll try that tomorrow. 👍
Hi
I've been studying 'Python Algorithm', 'Python data structure', 'Tensorflow' and Neural Network.
I'd like to study so-called 'Big data'
What is the very first thing I should do?
learn sql.. i.e language of data..
Ive studied MySQL already
ok.. try BigQuery..
really depends what aspects of big data you intend to tackle.. if you've learned TF, do you intend to go the ML or analytics route?
or the Data engineering route
I majored in Math
and Im looking for a job
I already graduated
Mhm to build my career?
or just gain some power
BigQuery is a database.. columnar data storage that supports repeated fields and is a major big data tool..
it works on sql, with some minor differences
ok but big data is quite vast..
really depends which area you want to gain expertise/skills/experience in
Oh thanks.
That's what my friends said haha your very thanks!
What about
Big data + ML?
It also depends on what Im trying to do
asdfkljasld;kjasld;kj
it sure is.
right.. so for ML most of the time, it's data cleaning like say 90%.. that includes moving it some place, making it available in the right format.. 5% ml and 5% making your code performant..
to apply the 5% ml part, you need to understand concepts and where to apply them.. case studies help.. learning what is in place helps.. CNNs for example have been traditionally used for images.. if you keep up with recent trends, you'll know they're also now being applied to images..
things like that.. just giving context
What do you mean by 'Case studies' and 'learning what is in place'?
and you mean that 5% Big data i.e. ML is applied to images?
I've heard about ResNet AlexNet or something 😹
no..
like job wise.. most of your time, if you worked on ml that's solution oriented and not part of research, will be preparing the data to be used for ml
tools like bigquery help with that
Oh I see
BigQuery, Google Cloud Storage.. for storage and quick querying..
I could go on about tools.. but really everything is domain specific
lol "most of my time will be preparing the data to be used for ml" lmao
ml itself.. you need to specialize.. like audio, image or text.. or business use cases like Marketing analytics, forecasting, finance
Yes it is!!!!!!!!!!!!!!!!! That's sad
yes.. it's not all about fitting some model.. people think that's sexy.. it's not.. about the models.. It's about solving problems..
just like engineering is..
doesn't matter how much you know, it's about how much you can apply for the task at hand.. to get results
I see. specializing audio, image or text. What a big help. Thanks!
wait.. I only mentioned a couple of fields.. it's quite vast.. more vast than that :v
do your research..
Oh okay!!!! But still big help! Thanks a million
hi guys, never used SQL before and trying to implement into my python code - I'm confused understanding how I defined a column as UNSIGNED INTEGER - I see I can do INTEGER. google says ZEROFILL INTEGER but where would I put this?
sql_command = """
CREATE TABLE employee (
staff_number INTEGER ZEROFILL
PRIMARY KEY,
fname VARCHAR(20),
lname VARCHAR(30),
gender CHAR(1),
joining DATE,
birth_date DATE);"""```would this work?
how can i compare two differant tables and see who a cell changed and see the differans between the 1 table and the 2 Table ?
(if the 1 table is a copie from the 2 Table)
@inner pecan what database are you using
sqllite
zerofill is separate from unsigned, and sqlite doesn't really do either of them
the only integer type in sqlite is signed 64-bit
if you need to store larger positive values, store them as strings
ok
also am I doing something wrong here
addColumn = "ALTER TABLE Capture1 ADD COLUMN ColumnName=%s ColumnType=%s,"(Name,Type)```because I get error TypeError: 'str' object is not callable
Name, Type are strings
i want them to replace the %s
isn't it "string with %s" % (things to fill in)?
i mean your expression of the formatting is incorrect
you dont place a tuple after
you use the above python
i dont think sql likes empty tables or empty parentheses
oh.. yeah I was hoping i'd be able to make it empty
and then fill it in with a loop
because I didn't know how to make it with the columns right away in a loop
try filling in the column name and type like normal
CREATE TABLE table (thing INT, thing2 TEXT);
@inner pecan oh shit ;
now its saying my table exists already
if I ran the code - it makes my table
so if i run it again and it makes the table, it already exists?
Ok so now i need to remove that from my code
you know to drop a table?
is it DROP table
DROP TABLE fufu;
yes,
addColumn = "ALTER TABLE Capture1 ADD COLUMN ColumnName= %s ColumnType= %s," % (Name,Type)
This is still incorrect?
sqlite3.OperationalError: near "=": syntax error
nw
😄
@inner pecan that's not the right sql syntax for that anyway
addColumn = f'ALTER TABLE Capture1 ADD COLUMN {Name} {Type}'```
with %s it would be ```py
addColumn = 'ALTER TABLE Capture1 ADD COLUMN %s %s' % (Name, Type)```
(I normally wouldn't recommend f-strings or %-formatting of anything for sql statements, but column names etc are different. Though this does suggest you should rethink your database design, if you're adding arbitrary columns at runtimewhat is the f?
!f-strings
f-strings
In Python, there are several ways to do string interpolation, including using %s's and by using the + operator to concatenate strings together. However, because some of these methods offer poor readability and require typecasting to prevent errors, you should for the most part be using a feature called format strings.
In Python 3.6 or later, we can use f-strings like this:
snake = "Pythons"
print(f"{snake} are some of the largest snakes in the world")
In earlier versions of Python or in projects where backwards compatibility is very important, use str.format() like this:
snake = "Pythons"
# With str.format() you can either use indexes
print("{0} are some of the largest snakes in the world".format(snake))
# Or keyword arguments
print("{family} are some of the largest snakes in the world".format(family=snake))
thanks
Sorry hopefully my last question:
(('SymbolName', None, None, None, None, None, None),)```Why does it shhow the None and not just.. nothing?
for my columns
using
cursor.description))
historical reasons
sure but if its saying I don't have 6 columns
I mean why is it saying I dont hasve 6, and not 7.. or 9
those aren't columns
they're additional data fields about that column that the sqlite driver does not populate
Oh
Ok
Shouldn't it tell me the data type there?
I told it it was VARCHAR(255) ?
so should that be instead of one of those Nones?
it doesn't do that because sqlite3 data types are just suggestions
if you want the original data types, you can use pragma table_info(foo)
how can i compare two differant tables and see who a cell changed and see the differans between the 1 table and the 2 Table ?
(if the 1 table is a copie from the 2 Table)
that's not really something sql is designed for
i mean you could write an algorithm to do it yourself, but this isn't something that there's going to be a built-in function for because it's not how tables are designed to be used
Oh
what's your actual goal here
ok what
as discord is poorly done i can not know by whom the person joined a waiter then i have to watch which invite to change
deleting from a column doesn't really make sense either
cursor.execute("""CREATE TABLE Capture1(SymbolName VARCHAR(255);""")```
What is wrong with my syntax here - I'm dumb and don't get it - is it the ; ?@inner pecan you're missing a )
And are 3 "'s always needed?
no
so this would work with just " and "?
yeah
Why do examples all use """ or '''
triple quotes are mainly useful for when the string may go to multiple lines, or have both types of single quotes in it
ok thanks it was the bracket.. my bad
so you can do py execute("""CREATE TABLE tablename( column1 type, column2 type, column3 type, column4 type, column5 type, column6 type)""") with triple quotes
it's not needed
Ok thanks
side note - is it normal for it to take 14.616921424865723 to add 1368 columns
....yes.
and, you really should rethink your database design
it's unusual to be adding any columns at runtime, let alone over a thousand of them
i havent even added the rows yet.
What do you mean by that? Doing it at runtime.
I should make this outside of the program?
why does your table have 1368 columns
no, the point is
whatever you're doing seems very strange
it's not normal to have a function for adding a column, or to add 1368 columns
that's not how sql is meant to be used
oh..
It's possible I don't need all 1368 columns
but I don't know how to make the table without adding my columns like htis
ok what is your data actually representing
it's hard to talk about this without concrete examples\
- I made a mistake I don't need 1368 columns I'll find out how many I actually need in a moment and then I'll give you examples
is 39 more reasonable?
Now - as for the data..
I have a dictionary which has ~1300 key:value pairs inside. The keys inside are NAMES for a stock symbol and the value for that stock symbol is a nested dictionary, which has {Field Name : Value } pairs
in the test data I'm using, there are 39 Fields
So I want a database with Symbol name as a column, then these 39 fields as the others
with the values as rows
and the symbol names as rows on the symbol name column too.
Make sense?
I then want another Table with this info, and I want to do a Join on which values are different across both tables.
(both tables SHOULD be the same but in some cases have different values by mistake)
ok so
i would say you should probably just have one column for the symbol, one for key, one column for the value,
and have a row for each pair
no
(each symbol has 39 fields with values)
like i said, you'd have a column for the symbol too
ok
so each combination of symbol+key gets a row
So I would have ( SymbolName, Field, Value) columns? and then multiple entries for each symbol on the symbol name column?
if thats not it then im confused
right
your rows would be symbol1 key1 value1 symbol1 key2 value2 symbol1 key3 value3 ... symbol2 key1 value1 symbol2 key2 value2 ...etc
there's a way to make the primary key consist of two columns
CREATE TABLE mytable (
symbol,
keyname,
value,
PRIMARY KEY (symbol, keyname))```ok
i will try this
but yes then I think what I'd want to do is I have two of those tables
and I want to check if each primary key across both is equal
if that makes sense..
and if not show which ones arent
in a SELECT FROM statement I guess
Data-base. {always-being-viewed}
How can i reset a column?
@torn sphinx no, delete all values on the column
Set it to 0 🤷
How?
what exactly do you mean by "delete all values" that setting it to null doesn't accomplish
ok that's not a column that's a whole table
"delete all values from the column" sounds like you want count to be blank but the links still there
Drop table 😂 👌
delete from table
no it's just delete from table
you can do delete from table where ... to delete only some rows, or by itself to delete all rows
okay and thank you ^^
yeah sorry for the confusion, talking about deleting from a column made me think something weird was going on
this is amazing
I managed to get the Database code running, tho, if I restart the code it says the mysql database timed out, 30 mins later it works fine but again, if I restarted the code it says it timed out, anyone knows a solution?
To be specific it says OperationalError: Database Timed out
How can I prevent RuntimeError: readexactly() called while another coroutine is already waiting for incoming data? Is it there a module that supports caching?
Hi 😃
I have a table which is "COmpetition"
And i would like to add a table of format
Like, the rules of the competition, the mode, etc
Buf each game have is own format
Can we have a foreign key that reference to a table in function of the value of a column
Or what should be the architecture here
Shoudl format not a data in a table but an array of string and its the application that manage it?
Did the first 5 get deleted?
Well it's an increment. It goes up, thats what it's made for.
How can I reset the auto increment?
remake it
How do databases work with k8s?
Do you have like one seperate from k8s that they all connect to?
If you can use managed database instances, use them. It will save you a lot of time.
E.g. on amazon it's possible to create isolated from k8s cluster database instance.
If you want to maintain your own database instance inside k8s cluster use stateful sets.
Or even better, make/find k8s operator for this database.
For zero downtime/high availability you'll have to use several replicas.
Note that you have to choose underlying volume type thoroughly, it must support all the required capabilities for the database to guarantee durability, like fsync.
Is delete from table the same as truncate table ?
I have 2 postgres tables: users and messages
users (
id BIGINT
)
messages (
user_id: BIGINT,
content: TEXT
}``` How can I select message so it can be easily exported into the following json: ```python
{
# instead of
# "user_id": 123
"user": {
"id": 123
},
"content": "abc"
}```I'd also want to automate it so each time I select message somehow I get internal user object fetched by user_id
I came up with something like this: sql SELECT messages.user_id AS user_id, messages.content FROM messages LEFT OUTER JOIN users ON (b.content = 'abc' AND messages.user_id = users.id); user_id | content ---------+--------- 0 | abc (1 row) Problems:
- Table relation isn't automatic, I'll have to use this code in all my queries for messages (with minior changes)
- In case I would want to change some fields, I'd need to update all my queries because all parameters are hardcoded
I already asked but didn't get an answer. With asyncpg what is the difference between executing queries with just the Pool object or with pool.acquire() ?
My app crashes and the error says it's an db error(in image). here is the code: https://bpaste.net/show/4e69fbde0540
@tacit dagger it looks like esperanto is an unexpected type
also, why is there a comma in (esperanto,) ?
ah my mistake. i cleared the comma, still the same app crash no difference.
the comma is correct
@steel slate sql requires a tuple or list for parameters, which means an extra common for a tuple of one element
@tacit dagger what does print(repr(esperanto)) show
So basically I'm trying to convert my double dict json files into a database file, but I'm having trouble understanding what the best way to do that is. The thing is, in the long run Im not sure of the exact length of the dictionary (its for a discord bot and I need rows for each guild and columns for each index). The other problem I'm having is that sometimes I need to use a list in one of the spots, like for command prefixes they could have a list. This was all very easy with a json file, but that is very bad practice so can someone please help me
I just don't know where to start. I don't need some link to a learn sql website
I'm using mysql.connector
What does this error mean?
ConnectionRefusedError: [WinError 10061] No connection could be made because the target machine actively refused it
What do you think it means...?
Does that mean it's at the database end or my end?
@patent glen print(repr(esperanto)) shows nothing. 😐
where did you put the print statement? before the sql call
i put it after results = self.cur.execute("SELECT English FROM Words WHERE Esperanto = ?", (esperanto,))
before this line it shows: <PyQt5.QtCore.QModelIndex object at 0x0000000002C24BA8>
yeah you need to figure out how to get the actual string from that
i don't know enough qt to help, sorry
👍 thanks for your help
@tacit dagger try currentItem instead of currentIndex?
that gets a QListWidgetItem, you might be able to get the text from that more easily
with currentItem also app crashes. and repr shows <PyQt5.QtWidgets.QListWidgetItem object at 0x0000000002C46EE8>
How do you make a table a variable length / is there an easy way to check the current columns and add any that do not appear in a list
@subtle flax as for "Table relation isn't automatic", you want to look into views for that
This looks like what I need, thanks!
@tacit dagger I said you could get the text from it, not that it'd be the text itself. try currentItem().text()
I figured you would search for how to get the text instead of giving up, i found documentation at https://doc.qt.io/Qt-5/qlistwidgetitem.html
I did not give up. i'm trying. i found that index = self.listWidget.currentRow() gives me the index numbers, but not the text itself, and .text() can't be put at the end of it. i've changed it to this below but itemFromIndex() won't work even with index parameter.
index = self.listWidget.currentRow()
esperanto = self.listWidget.itemFromIndex()
results = self.cur.execute("SELECT English FROM Words WHERE Esperanto = ?", (esperanto,))
for row in results:
self.textEdit.clear()
self.textEdit.insertPlainText(row)```ok have you tried .text() with that then?
yes, but doesn't work.
if I'm doing something like an inventory system, is there anything bad with PySide2 + psycopg2?
For that, you'd use the various fetch methods that Python has. You'll execute() your various commands but in order to retrieve and use them, you'll need to fetch them from the cursor
But i mean a view similar to a spreadsheet or something
Oh sure yeah
One sec
That's covered in the "Loading Data" part of this tutorial. I think it's well worth reading over https://stackabuse.com/a-sqlite-tutorial-with-python/

Stack Abuse
Introduction This tutorial will cover using SQLite in combination with Python's sqlite3 interface. SQLite is a single file relational database bundled with most standard Python installs. SQLite is often the technology of choice for small applications, particularly those of em...
And if you just want to see what a particular table has and aren't looking to filter anything out, then a simple SELECT * FROM my_table will get you where you need to go
Okay and so like should I write items to an items_table and then read from that?