#databases
1 messages · Page 55 of 1
so postgres is relational?
ooooo its making sense now that i think bout what i was dealing with in terms of users and account details
i still dont get when u would use a nosql db doe 🤔
generally when the data coming in doesn't really link together, time series data, or massive write count
i guess in stuff with large data etc
exactly
so stuff like splunk etc would work with is worthwhile
but it doesnt matter what databse type is i could still use something like sqlalchemy to interact with said db to run queries to get info etc from it?
yeah cause it has multiple connections config
Yep
cuz we use that with the postgres stuff
ooooooo
maybe if i read the docs id hav noticed which ones it can interact with haha
😉
its all good
what would be a good database that I can use through python, not something extra to download
sqlite3

host database on a separate server. problem solved 😉
but yeah, sqlite. it ships w/ python
Is there anyway for me to store a list of numbers in an SQLite Table within the same block?
Thought about turning it into a string and just appending it with a symbol and the new number to store but then I would have to do some funky stuff with regex and I honestly don't feel like doing that.
i think its 'more correct' to make another table and store each number as one row, and have a column that references what those numbers belong to
but you could just comma delimit text
split and join are pretty fast and easy in python
I am wanting to store ratings for staff teams (i implemented a reddit-like modmail system) where 2 of the 3-4 rows will be the same values - essentially creating an absolutely MASSIVE table after a while.
db.execute( '''CREATE TABLE Ratings(guildID TEXT, staffID TEXT PRIMARY KEY, ratings TEXT '''``` to give an exampleif its a rating like on shop websites you prob want to split them out and detail who gave the rating. there is no reason to store each rating individually unless you want to be able to remove them, which you cant really do unless you have meta data about each one
the alternative is look up how to keep track of an avg score with just like two values, which i think is possible
for that i believe you keep a SUM of all ratings and the COUNT of the total number of ratings
then recalc the average each time you look it up
smart ^^
Or keep a separate table with the avg rating, then update it by recalculating whenever a new review is made in that object. That's if your views grossly outweigh your reviews like Amazon's would.
Finally got scrolling working, thank you PostgreSQL and asyncpg+connection pools.
I'm surprised how hard it was to find an implementation (between connectors and databases) that can scroll on large amounts of data. It doesn't really seem like it would be a niche thing...
I even read on one website suggesting LIMIT and OFFSET as a means of doing it, but that's insanely slow.
i have this

discord.ext.commands.errors.CommandInvokeError: Command raised an exception: OperationalError: no such column: ahdb0001
And i get that error
and this is my db

Anyone can help?
Put {} into singular quotes.
no, don't do that
conn.execute('SELECT * FROM tickets WHERE channel_uid=?', (uid,))```depending on the database you might have to use %s instead of ?
And how to protect against them.
I've been getting this error when trying to create a table: ```css
Ignoring exception in ready
Traceback (most recent call last):
File "C:\Program Files (x86)\Python37-32\lib\site-packages\discord\client.py", line 225, in _run_event
await coro(*args, **kwargs)
File "C:\Users\DiscordBots\Desktop\DiscordSavant\cogs\modmail.py", line 46, in on_ready
self.db.execute( '''CREATE TABLE IF NOT EXISTS Modmail(GuildID TEXT, MemberID TEXT PRIMARY KEY, Case TEXT, Report TEXT)''' )
sqlite3.OperationalError: near "Case": syntax error
self.db.execute( '''CREATE TABLE IF NOT EXISTS Modmail(GuildID TEXT, MemberID TEXT PRIMARY KEY, Case TEXT, Report TEXT)''' )```thx
I'm not currently working on something but I was wondering what would be the best way to store a players inventory? Make a table with all the items that exist and give them codes then add a row on the players table with all the codes?
yes @quasi holly
Alright thank you!
Stupid question - im attempting to get some data out of influxdb, parse it, and re-insert it as a new record in a different measurement. however im not able to read the data.
oh that didnt paste right.
well either way, the error i get is that the retention policy isnt found, however that query works on infdb directly
sec_influx_host = 'test.testdomain.local'
my_database = 'telegraf'
use_ssl = False
verify_ssl = False
influx_client = InfluxDBClient(sec_influx_host, 8086, 'pytest', 'pytest', my_database, use_ssl, verify_ssl)
pcw_return = influx_client.query('select "wsrep_provider_options" from telegraf.mysql_variables limit 1')
pcw = pcw_return.get_points()
print(pcw)```there we go
this is pretty much the 3rd python script ive ever written so please excuse the green-ness of it all
I haven't heard of influx, why didn't u use psycopg2? I've had good experiences with it
How does ordering work in SQL? I have a dataset that seems like it will always be ordered the way I would like it to be. However, I figured that I might as well include an order statement in my query just to be sure. If data is added to the table over time, having to order the dataset before taking out new rows is going to become increasingly intensive, right?
The exact ordering mechanism depends on your DB of choice.
And indicies in place.
If you have an index respective to your query order by clause, there will be a small overhead in inserting data into the table due to the index, but queries getting ordered data (ordered according to that index) will not suffer from any performance issues.
Hmm. I wonder how much overhead that would be. Ex: If I have a dataset with a column that is essentially unique, sequential integers, and I'm basing the index off that, what happens when I add a small number of additional records?
I saw a comment on stack overflow that said, "Rebuilding an index drops and re-creates the index."
How many records approx do you have in the table, and how many queries per second do you expect it to handle?
Maybe 500,000-1,000,000 records in the table. It grows by maybe a 10-100 each second. I plan on splitting the table into maybe 100 different data frames in Python. I'd like to check the table maybe every second to scrape off the "new" records (records with the consecutive integer variable greater than the highest integer I read earlier).
So I'd check the table, see that there are 100 new records, and then maybe 5 go into data frame 1, 3 go into another, one here, none there, none there, that kind of thing
And then some analysis would be performed on each of the data frames. I'll probably end up throwing out old lines in the data frames though, so I don't think they'll get too clunky too fast
And a good portion of the time, many of the data frames (that correspond to a variable in the SQL table) will not need to be updated and then reanalyzed
So it will probably be more like 10-100 new records each second with a handful of dataframes of maybe 1,000-5,000 entries being updated and then analyzed each second
Does that sound reasonable?
Yes, pretty much.
Well in that case you do have to be careful with indicies and your queries.
I don't think that I can give a good response on this though.
If I was to do such task - I'd just make a similar table, populate it with random data and measure how fast does it do all the operations I need and how many queries can handle.
Then adjust indicies and repeat.
Alright, thanks for your input. I appreciate it
lads
i wanna have a very basic account system in my project
literally just a unique username and password you create, nothing else
will i require a database for this, or can i use a text file instead?
You can use the text file, but will have to implement some of the functionality DB provides out of the box by hand.
Such as enforcing uniqueness, for example.
Then by all means do use it. =]
can you join voice chat this is too long to type out
You can get away with sqlite for a start, it does not require server setup.
Nop, I can't right now, sorry.
ok its fine
i need to use sqlite if possible
to get marks on my coursework
so one database for usernames, primary key of userID
another table for hashed passwords and salts
i cannot host anything on a web-server, it must be done via files
Why not have usernames and passwords all in the same table?
So with indices, you don't really ever see them? You just make them and then if they help, the database software just uses them to speed up your queries?
lemme link the thing
sec
i need to be using these techniques
so i want the tables to be interlinked
I won't be able to help with your assignment, sorry. If there is a precise question about something not working - please do ask.
what
this isnt help with an assignment
this is me asking about whether or not i can do something in a certain way
Short answer - yes, you can do it with sqlite.
Well last paragraph of the right column literally says you'll have to use web server.
Or web service rather.
SQL does not directly relate to the web in any way.
SQL and web are different technologies that can be used independently. You con't have to build web server to use SQL and vice versa.
i know...
Then what's the question?
like i have said 3 times already, none of this project is hosted on a website
once again
can i have an account database, WITHOUT a web server, using FILES instead?
Yes, that's what sqlite is for.
ok thats all i needed, thank you
@night charm sorry, did not see your question.
Pretty much, yes. Indicies are internal structures that DB engine uses to speed up queries.
That's awesome. So since all I care about is getting the last few rows of the table sorted by Variable X, having Variable X as an index will basically solve the speed issue for me, right?
There might be a way to retrieve the raw index data if you really need it though.
@night charm sorted by field_x while having index over field_x - yes.
Great! 😃
Although that depends on DB engine, data type and particular implementation - generally yes.
Gotcha.
It will also slow down INSERT, UPDATE queries. Those that need those indexes updated.
So in essence - if you do a lot of INSERT/UPDATE and just occasional SELECT - it may be worth to think this through and not add any indexes.
If it's the other way around - a whole lot of SELECT and occasional INSERT/UPDATE - index(es) is(are) a must.
One other question: So I was planning on taking the big chunk of old data and any new data that comes up from MySQL into Python for analysis. I was planning on separating the data out based on one variable (which has maybe 60-100 levels) into as many data frames. I will probably clean out each data frame once it exceeds a certain number of rows (maybe 5,000 for example). Would it be better to try to do all this in MSSQL and just have Python send the commands to manipulate the tables there?
Or would Python be equally as capable?
@night charm I know I'm a bit late with the response, but generally DB engines are better at operating big amounts of data since it's their primary purpose, they are built around it.
And Python is a general purpose language, which can do everything (and is good at that), but will probably not overcome the performance of the DB engine while operating with big data chunks.
To have a better answer I'll need to understand what you are trying to achieve a bit better. What is data frame? A collection of rows? Do you intend to split a huge chunk of data into several smaller collection of rows based on some variable? How do you intend to store these split up chunks? Etc.
Yeah, I'm trying to split up a large table of 300,000-1,000,000 rows in MS SQL into maybe 60-100 Pandas data frames in Python.
Each row in the SQL table relates to maybe 1 of 60-100 entities, and each entity will have its own Pandas data frame.
When a new piece of data comes into the SQL table, it will need to be sent to the appropriate data frame.
I did not work with Pandas, so there is little I can advice there, sorry. Will need to check it out some time later as I see it being referenced to rather often.
Upon reception of the new bit of data in the data frame, I plan on running some basic analytics on the new data set.
When a new piece of data comes into the SQL table, it will need to be sent to the appropriate data frame.
Something will have to decide what data frame does it belong to. What's the nature of condition on which you decide it's destination?
There will be a variable in the SQL table that says which entity the data belongs to. Based on that, it will be sent to the appropriate data frame.
Over time, the data frames will be curated so as to not exceed a certain number of rows. But that number in itself may be something like 5,000.
So if I expect maybe 100 new records to enter the SQL table, maybe 10 data frames will end up receiving on average about 10 new rows.
So then I'm just worried that the analytics portion will take too long.
Hmm.
Because if 10 new data frames are changed, then new analytics has to be run on each of them. And that would involved computing statistics on potentially 5,000 rows * 10 data frames * however many different statistics need to be computed
Or something on that level of magnitude
I suppose realistically then the major burden for the program will just be the computation of the statistics, and that's more of a matter for me to figure out on my own, I think
It doesn't really seem like the actual movement of data from the SQL server to Python is that big of an issue, unless Pandas isn't really setup for that kind of thing. But you said that you haven't used Pandas, so I won't bother you with questions of what it can / cannot / should / shouldn't be used for.
Well what I can say is I don't see much benefits in splitting your data on the SQL side and then sending them into Python in small batches.
Unless there is some kind of business logic tied to them.
@torn sphinx what kind of database
question: i've got an sqlite database representing a bunch of files and folders. which one of these is a better schema?
create table folders (
path text primary key
)
create table files (
path text primary key
)
or
create table folders (
id integer primary key,
path text,
parent integer,
constraint unique_path unique (path),
foreign key (parent) references folders(id) on delete cascade
)
create table files (
id integer primary key,
path text,
parent integer,
constraint unique_path unique (path),
foreign key (parent) references folders(id) on delete cascade
)
in the first one the items in each folder will be found using where path like '{parent_path}%'
in the second one it'll be based on folder id (so an extra query to find the id of a folder as well)
i'll also be searching the entire database for keywords using where path like '%{keyword}%'. will either of these schemas provide improved performance for this?
In SQLite, does connection.commit() close connections or just save changes
@lofty quest .commit only applies changes
Hello, anyone using LibreOfiice spreadsheets?
saving a filesystem in the database seems conúnterintuitive to me, can't you use os.path on whatever system you're pulling the info from?
also generally sqlite doesn't care about your foreign keys unless you pragma it on
i need the speed boosts of storing the file paths inside a database, mainly for searching by keyword. traversing the tree (for populating nodes in a file tree ui widget as needed) is also faster using a db than accessing the disk directly.
it's roughly ~100k files and counting atm.
ah, i didnt know that about the foreign key pragma. thanks!
hey guys
got a csv was wondering how do i load all my date into a mysql db
the csv has the column names e.g. vehicle brand,id etc
??
something like
LOAD DATA INFILE 'c:/csv location' ?
can i import all that data and it will load up the table with the column headers as the table columns as well?
tried to run this LOAD DATA LOCAL INFILE 'C:\Users\Mohammed\Desktop\VehicleFinderFlask\Vehicles.csv' INTO TABLE vehicles FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' IGNORE 1 ROWS (id, Make, Short_Model, Long_Model, Trim, Derivative, Year_Introduced, Year_Discontinued, Currently_Available);
and keep getting the used command is not allowed :/
with this mysql version
nvm got it to work windows for development is a headache
any way i can do an sql query using the users input in flask
eg
cursor.execute("SELECT * from Vehicles WHERE make=(USER INPUT VALUE HERE)?
atm ive got a field where the user enters a make and pass that around in the flaskapp?
which sql module are you using?
they usually have some way of passing in parameters to queries that'll automatically sanitize them for you
currenlty using flaskmysql?
@app.route('/', methods=['POST'])
def index_post():
text = request.form['text']
brand = text.upper()
# result = search(brand)
conn = mysql.connect()
cursor = conn.cursor()
cursor.execute("SELECT * from Vehicles WHERE Make = %"+brand+"%")
data = cursor.fetchone()
return render_template('home.html', brand=data)
DONT Know if i could change that to a GET :S
so confused thats my home page and i dont know whether it should be a GET/POST as its getting info from the DB based on a id e.g. brand or a post cause its using the form on the page i.e. the search box to post :S
ok, looking at the source for flaskmysql shows that it uses pymysql underneath
looking at the docs for pymysql, you can pass parameters into a query using %s as a placeholder along with a tuple/list to specify their values https://pymysql.readthedocs.io/en/latest/modules/cursors.html#pymysql.cursors.Cursor.execute
as for whether this should be a GET or a POST, personally i think it should be a GET
iirc POST is really only useful for situations where you want requests that arent 'safe', in that the user shouldnt just be able to type them into the address bar
you'll probably get a better answer to that in #web-development
@dapper crescent
Hi - anyone here done any python with data manipulation from influxdb?
O yeah I wanted it to b a get too thanks il try that
having some issues getting the right data out into a list to parse through it
my influx skills are somewhat limites (as are my python :))
*limited
im writing a program that will go into influx, pull out a list of hostnames, iterate through them and search for specific data related to them, parse it, and reinsert it into a different table to be reported on later.
are you getting any particular errors when querying the database?
i havent used influxdb personally but if you post any errors/relevant code here someone who does might see and be able to help
Not specifically, looking for more of an approach on how to get the data out for a host. Im a SQL/cassandra dba so something along the lines of a select distinct(hostname) kind of thing
hosts = #Parsed list of hosts
for h in hosts:
string = influx_client.query('select wsrep_provider_options from "telegraf"."4_weeks"."mysql_variables" limit 1')
prim = "pc.weight = 1"
if prim in string:
print("Primary")
else:
print("DR")
thats the gist of what im looking to do
am i correct in assuming that once that host list is populated it would run that query for each host?
or, each item in the list
#influx connection
sec_influx_host = 'sec01u0inf01.npres.local' # Sec NonProd Influx server
my_database = 'telegraf'
my_retpol = '4_weeks'
use_ssl = False
verify_ssl = False
influx_client = InfluxDBClient(sec_influx_host, 8086, 'pytest', 'pytest', my_database, use_ssl, verify_ssl)
hosts = #Parsed list of hosts
for h in hosts:
string = influx_client.query('select wsrep_provider_options from "telegraf"."4_weeks"."mysql_variables" limit 1')
prim = "pc.weight = 1"
if prim in string:
print("Primary")
else:
print("DR")```im also having issues getting my_database and my_retpol to pipe correctly into the influx query line
it was just picking it up as "my_database" and not as the defined database name
This works:
c.execute( 'CREATE TABLE %s (%s)' % (table, ','.join(names)) )
But I would like to use this, and it doesn't:
c.execute( 'CREATE TABLE ? (?)', (table, ','.join(names)) )
I get:
sqlite3.OperationalError: near "?": syntax error
Any idea how to sanitize input here?
.
Generally when you try to dynamically select table you might wanna rethink your data structure. Nonetheless there are no ways to use prepared statements for table names, but there are probably a few libraries that handle sanitation
database junkies. i'm having an issue i can't quite figure out. probably something incredibly simple. i'm getting this error
"Not all parameters were used in the SQL statement" on the following code.
csv_reader = csv.reader(csv_file)
next(csv_reader)
for line in csv_reader:
sql = (f"INSERT INTO `jobs`(`id`, `date`, `time`, `first_name`, `last_name`, `email`, `address`, `city`, `state`, `postal_code`, `phone`, `service_total`, `extra_total`, `sales_tax`, `final_amount`, `frequency`, `discount`, `teams_assigned`, `teams_assigned_no_id`, `team_earnings`, `date_created`, `created_by`, `services`, `staff_notes`, `customer_notes`, `bookin_id`, `customer_id`, `date_cancelled`, `cancelled_by`) VALUES ('',{line[0]},{line[1]},{line[2]},{line[3]},{line[4]},{line[5]},{line[6]},{line[7]},{line[8]},{line[9]},{line[10]},{line[11]},{line[12]},{line[13]},{line[14]},{line[15]},{line[16]},{line[17]},{line[18]},{line[19]},{line[20]},{line[21]},{line[22]},{line[23]},{line[24]},{line[25]},{line[26]},{line[27]}")
print(line)
mycursor.executemany(sql,line)
mydb.commit()
mydb.close() ```you are trying to insert 28 values into 29 columns
first value is ' '
ah true
its an auto_inc primary key
wait but shoudnt it be execute instead?
executemany if I;m not mistaken is for the prepared statements
it will make a prepared statement, and then iterate over your sequance and execute the statement for every element of your sequence
so in your case you should either use execute or executemany(sql,[line])
towards the bottom i have mycursor.executemany(sql,line)
so change that to [line]?
same error
Oh, that's probably why the %s needed because it inserts the values there... Maybe I've helped you make your code worse in the help-channel
lol
😄
ah shit just realised you had an f-string there, well it would probably work without any params then
like a pure execute(sql) would have worked
but using f-strings to inject values that are coming from unknown is not a way, you are opening your system for the sql injections
just switched back to %s
yes, that is one way
I would say it's about personal preferences
alternative is something like execute('insert into my table ('id', 'name') VALUES (:id, :name)', id=123, name='foobar')
but i'm not sure if every DB API has those named params, that is specified by python standart, but I don't think that everyone cares about standarts
and i could do id=line[0]?
yeah
let me give it a try. that makes more sense to me
than %s
well at least im getting different errors. so thats a nice change.
out of curiosity
i kept with %s
print(mycursor.rowcount, "record inserted.")``` returns "-1 record inserted"the insert did not go thru, but also what would trigger a negative count to be returned?
can't get ``` exec("INSERT INTO jobs(id, date, time) VALUES ('',:id, :date, :time)), id=' ', date=line[1], time=line[2]")
As required by the Python DB API Spec, the rowcount attribute “is -1 in case no executeXX() has been performed on the cursor or the rowcount of the last operation is not determinable by the interface”.```are you getting an exception?
the use of ` seems off
i can remove and see
nvm
thats sop sql
you are correct. one sec. let me fix.
same error.
exec("INSERT INTO jobs(id, date, time) VALUES ('', :date, :time), id=' ', date=line[1], time=line[2]")
cur.execute("select * from people where name_last=:who and age=:age", {"who": who, "age": age})
in the docs the example has a dict with the variables
let me give that a try
you also don't need the id when you have it empty instead of a named placeholder
https://docs.python.org/3.7/library/sqlite3.html#sqlite3.Cursor.execute
this is geared towards sqlite3 but the api is the same across most db's
would it also work for mysql.connector?
is it still erroring?
mycursor.execute("insert into jobs values (%s,%s,%s)", ('',line[0],line[1]))```try putting NULL for the id
it was actually a db config that i fixed.
so that works
hallelujah
thanks
much simpler than i was making it out to be.
hmm it looks like discord doesnt really have much info on pandas - I'm not the best at python but I'm trying to use functions to append new data rows in a csv using pandas, and so far I have the db working correctly and open, but i'm unable to append new data with an user's discord id and steam id, and i relied on using google to see if they would work similar to what i had, sadly doesn't (aka it would return a type error) and i'm not sure what to do
oh, I see, I should be using to_csv, since append would not work for adding to the csv file?
anyone who works with pandas here? i'd like to ask few questions in dms
same problem here apparently @Alright#2304
cant believe how frustrating pandas can be when it comes to setting up new DataFrame from scratch rather than working with existing one
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
I am so lost rn... Any help would be much appreciative :)
My Function: ```python
def get_case(param: str):
results = {}
search = Storage.cursor.execute( '''SELECT Report FROM Modmail WHERE Docket LIKE '%?%' ''', (param) )
for report in search:
results[report] = cursor.execute( '''SELECT Docket FROM Modmail WHERE Report = ?''', (report) )
return results
The Error: python C:\Users\clapp>C:\Users\clapp\Desktop\Lightning\cogs\data.py Traceback (most recent call last): File "C:\Users\clapp\Desktop\Lightning\cogs\data.py", line 41, in <module> Storage.get_case("35434") File "C:\Users\clapp\Desktop\Lightning\cogs\data.py", line 36, in get_case search = Storage.cursor.execute( '''SELECT Report FROM Modmail WHERE Docket LIKE '%?%' ''', (param) ) sqlite3.ProgrammingError: Incorrect number of bindings supplied. The current statement uses 0, and there are 5 supplied.
I am sort of new to SQL and still learning the language
in this case, Storage is the name of the class with the cursor and connection objects that connect to my DB.
it might be important to note that they are in the same class as this function ^^
Although the intended purpose of this function is to be able to call it from a cog in my rewrite bot.
hell, here's the whole darn code if you'd like: https://pastebin.com/3mwJtXrU

(param) is just param, it's not a tuple
fixed, but I still get the exact same error
you have this error in a few different places
remember, (x) is not a tuple, you need a , after x (ie (x, ))
doesn't surprise me
but i fixed the tuple issue for this specifc occurance and i am still getting the same exact errror in the same exact place for the same exact statement
your statement doesn't take any arguments because ? is inside a string, so it's being interpreted literally as inside a string, as opposed to a placeholder
no, change your statement to do something like SELECT ... WHERE ... LIKE ? and put the '%' around your param
something like execute('SELECT ... LIKE ?', (f'%{param}%', )) (obviously not literally execute or that query but you get the idea)
could you help me with this as well? @slate spire
File "C:\Users\clapp\Desktop\Lightning\cogs\data.py", line 31, in new_case
Storage.cursor.execute( ''' INSERT INTO Modmail(Docket, Report) VALUES (?, ?) ''', (case, text) )
sqlite3.IntegrityError: UNIQUE constraint failed: Modmail.Docket```i... have no idea, somehow case isn't unique
Base64?
If I use sqlite for prototyping and testing, what should I use in the ready product?
🛫 🛬
depends on your needs, you pick DB based on the usecase.
For some of the tasks sqlite may work just fine.
For others it won't cut it even for development due to some specific requirements regarding queries.
postgresql is usually considered the best allrounder sql database
Hello,
I have a variable with approximately 290k objects in it. Whenever I try and insert into MySQL database it takes about 45-60min and then errors saying pymysql.err.DataError: (1264, "Out of range value for column 'location_id' at row 1")
after inserting about 190k rows.
All of the objects are formatted the same so I don't understand this error after so many successful entries.
So I have two questions/issues. How do I try and trouble shoot this error? and how can I speed up the insert, because 1 hour seems like a very long time for a simple insert?
It means whatever value you were trying to store exceeds that maximum allowed value for the data type for the location_id ID column.
Presumably it's an integer?
If so, have a look here for the valid ranges for data types https://dev.mysql.com/doc/refman/8.0/en/integer-types.html
You could alter the table to change the data type to something that supports larger values
Ok, would that be the reason the insert is taking so long? it hits that point and freezes until it spits out an error?
I want to say doubtful, but then again I am not knowledgeable enough on such matter to suggest what else could be the problem.
I am only confident in my suggestion for the error, not the slow insertion
Ok, thanks. I have it as INT, I will try BIGINT and see if that fixes the error.
You could also make it unsigned if you don't need negative numbers.
That'll double the max value
Ok ill see if i can get that to work
you could also use negative ints as IDs, of course it's better to have only positive ones, but making thing unsigned does not extend number of possible rows, it just makes is more human-friendly
Depends how you look at it. Total possible number of rows is unchanged. But if the IDs in your data were only ever positive then effectively half of the range is unused
Technically not doubled, but effectively yes.
you can change the counter back to the minimum negative:)

Hacker Noon
It’s a story no one wants to encounter: Your primary key column runs out of values and your database starts exploding. Alarms go off as…
here an article where guys faced that
Again, not saying that this is way to go. Just mentioning it in sake of learning something new about IDs of postgres
Hi, does anyone here work with hive?
what's a good way to store huge amounts of data
should i just use mysql?
A database should work fine, but what is huge amounts?
Postgressql can handle a few hundred million rows of data hourly or so, mysql is probably not as suited for large datasets like that. Else I've heard good things abou "SQL server 2016" but never used it. I'm not super experienced with this, so take it with a pinch of salt
@torn sphinx ^
@dull scarab any way you could link sql server 2016
also i kind of dont want to be dependant of setting up a localhost
postgresql is usually considered the best allrounder sql database
mysql is considered a text file on drugs by my coworkers which I tend to agree with
actually as far as i'm aware mysql can be faster than postgresql because mysql tends to not give a damn about quite some stuff
sqlite is also pretty fast as far as i'm aware
but in general, as with python, postgresql is fast enough
no idea what "setting up a localhost" means. do you know what localhost is?
no as in
i dont wanna set up an actual server using uh
xampp
i just want it to be local storage without anything else
no hassle
are you gonna access the data from more than one application at once
nay
do you plan to export it or replicate it to other servers
self.c.execute("SELECT prefix FROM guilds WHERE id = ?", (server_id,))
prefix = self.c.fetchone()
return self.config.default_prefix if not prefix else prefix[0][0]
Error:
sqlite3.InterfaceError: Error binding parameter 0 - probably unsupported type.
whats server_id
is that a question?
How do you create the table
@dull scarab
def create_database(self):
self.c.execute("CREATE TABLE guilds(prefix TEXT, id INTEGER)")
self.db.commit()
Is the id a discord id?
What do you mean?
What are you storing
prefix and guild id
So discord related guild id
Cause those get way larger than a normal int can handle
Not sure how sqlite handles its casting, but try recreating the table with id being a BIGINT
Did you delete the table as well to allow it to be recreated?
yes
Ehm, what's the full traceback
Traceback (most recent call last):
File "C:\Users\Matteo's PC\AppData\Local\Programs\Python\Python37\lib\site-packages\discord\ext\commands\core.py", line 62, in wrapped
ret = await coro(*args, **kwargs)
File "C:\Users\Matteo's PC\OneDrive\Desktop\Matteo's PC\Programming\Athomos v2\modules\help.py", line 34, in _help
pages.add_field(name="» MusicBot 🎧", value="`{0}play` | `{0}pause` | `{0}resume` | `{0}volume` | `{0}np` | `{0}skip` | `{0}queue`\n `{0}shuffle` | `{0}remove` | `{0}clearqueue` | `{0}stop` | `{0}summon`".format(self.db.current_prefix(ctx.message.guild)), inline=False)
File "C:\Users\Matteo's PC\OneDrive\Desktop\Matteo's PC\Programming\Athomos v2\utils\db.py", line 32, in current_prefix
self.c.execute("SELECT prefix FROM guilds WHERE id = ?", (server_id,))
sqlite3.InterfaceError: Error binding parameter 0 - probably unsupported type.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\Matteo's PC\AppData\Local\Programs\Python\Python37\lib\site-packages\discord\ext\commands\bot.py", line 898, in invoke
await ctx.command.invoke(ctx)
File "C:\Users\Matteo's PC\AppData\Local\Programs\Python\Python37\lib\site-packages\discord\ext\commands\core.py", line 615, in invoke
await injected(*ctx.args, **ctx.kwargs)
File "C:\Users\Matteo's PC\AppData\Local\Programs\Python\Python37\lib\site-packages\discord\ext\commands\core.py", line 71, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: InterfaceError: Error binding parameter 0 - probably unsupported type.
ok what is server_id if you print it before the execute
FIXED
What was the issue, if i may ask?
Because where i call the function, the argument was ctx.message.guild instead of ctx.message.guild.id
It happens ¯_(ツ)_/¯
lol
I'm using MS SQL. I have a table with Column_1 and Column_2. Column_1 contains strings. Column_2 contains unique integers. How can I sort by Column_2, take the top 10 of this sort, and then take then take the distinct values of Column_1 from the top 10 of the sort?
Should I be using a subquery for this?
I've tried: SELECT DISTINCT Column_1 FROM (SELECT TOP 10 * FROM Table ORDER BY Column_2)
But this doesn't work.
Could you get the top 10 with select * from table order by column 2 limit 10?
No, that does not seem to work, @dull scarab .
"SELECT TOP 10 * FROM Table ORDER BY Column_2" does return the top 10.
But I'm not sure how to get from those top 10 rows to the distinct values of one of the columns.
Im afraid im not knowledgeable enough about ms sql then, sorry
That's fine. Thanks anyways.
SELECT DISTINCT Column_1 FROM MY_TABLE where Column_2 in (SELECT TOP 10 Column_2 FROM Table ORDER BY Column_2)
@pure scroll That works! Thanks so much.
Do you an idea where I was going wrong?
Or where it seems like my biggest misunderstanding was?
so you where trying to select from the subquery, which is only returning 10 results
what you need is to run a subquery to find COL_2 values
and then select every value of your table that contains it
Alright, thanks (for both the explanation and for your solution). 😃
but you was quite close
repost
alright so I'm having an issue in relation to a database entry expiring.
I want to have posts expire at a certain date depending on what the user wants, 5 minutes from post time, 10 minutes, etc.
I'm not sure how to implement the expiration though.
I could have a cron job that runs every 5 minutes and deletes posts where the current date is >= expiration date, but if that job has 3 minutes until it runs, and someone submits a post that expires in 5 minutes, then 2 minutes later, the job runs and then it has to wait another 5 minutes to run again.
so, what is supposed to expire in 5 minutes instead expires in 7 minutes.
does anyone have any ideas of a better approach to this?
is there no library for sqlite encryption?
hi guys, im kind of new to databases
I have a fair understanding of SQL
so im curious how i should go about making a database with python
Mongl? SQLAlchemy?
could i get some reccs?
postgres
oooo ok
i mean, you can use SQLite for a large one too, depends what you are doing with it
wouldnt hurt to use postgres just to be safe though
Postrgres & asyncpg @fringe seal
I tried SQLite at first but I switched to Postgres, never looked back
ahh ok ty
that depends on what large is
postgres has a vertical scaling, so you might face a problem there if you have really lots of data
you might consider horizontal scaling DBs for the big data
@clever lava I have a solution, will post when I get time
@clever lava are you using asyncio?
@clever lava Okay, here you go. The idea was to use a non-blocking queue of jobs. Then I just had to find something that implemented that. And I found something. If you're not using asyncio, the following works. If you are using asyncio, or something similar, with a slight modification, the code will work.
@tacit horizon I ended up doing this
@classmethod
def delete_expired_pastes(cls):
current_time = datetime.utcnow()
expired_pastes = cls.query.filter(current_time >= cls.expiration_date)
if expired_pastes is not None:
expired_pastes.delete()
db.session.commit()
...
@crython.job(hour='*/1')
def expire_pastes():
with app.app_context():
Paste.delete_expired_pastes()
if __name__ == '__main__':
crython.start()
app.run(host='localhost', use_reloader=False)
When someone requests a paste that technically has expired, but the paste still exists as the job hasn't run yet, I simply just return a 404 for it
Yeah, that works
Your method works, but I do think the way I'm thinking is more elegant. Having a new job automatically be created each time there is an insert into that table and having that new job automatically running 5 minutes from when it was created.
But, hey, if it works - it works.
oops, that pastebin should say from apscheduler
Hello, so I'm attempting to move over from Sqlite3 to MySQL
I'm getting an error with my Flask app when attempting to insert values into the Database.
Any help is greatly appreciated.
Post the error
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''Keys' ('Key', 'Email', 'CustomerID', 'SubscriberID','Used', 'End Date') Values ' at line 1")
Like I know it says syntax error but I can't find any differences between SQlite3 vs. MySQL Syntax and I
have created the tables
Might need to see the SQLs to figure it out.
I'm not sure what you mean, can you be a little more specific?
I'm just trying to run that atm to figure out my issue
can you capture the actual sql from that?
I'm so dumb
unmoneto
c.execute("Insert Into Keys (Key, Email, CustomerID, SubscriberID, Used, 'End Date') Values ('1', '1', '1', '1', '0', '1')")
conn.commit()```you mean 'uno memento' ❓
why does End Date have quotes?
I just did, same result
All good 👍
Ok I solved that issue, but it seems for whatever reason when I attempt to query newly added information it doesn't find it.
quick sqlite3 question, should I be preforming a SELECT when i want to check if an entry already exists, or is there an exception that get fired when this happens?
name = svardas.get()
print(name)
c.execute("DELETE FROM main WHERE name = 'lukas'")
how do i make 'Lukas'
into a name variable
i do get the the right name from user entry but do not understand what's the syntax for making it into a variable
c.execute("DELETE FROM main WHERE name =?", (user_var,))
or you could do named
c.execute("DELETE FROM main WHERE name=:name", {'name': user_var})
im assuming this is sqlite?
yes
sqlite DB browser
c.execute("DELETE FROM main WHERE name =?", (user_var,))
this one workes
so the things is now i want to delete the row when and only when the name and the last name are the same as i enter
so i simply add ?
c.execute("DELETE FROM main WHERE name =?, WHERE lastname =?", (user_var,lastname_var,))
c.execute("DELETE FROM main WHERE name =? AND lastname =?", (user_var,lastname_var))
oh okay
you would use AND and dont need the other comma in the tuple
tuples are weird in that if there is only one index, it needs to have a comma after it
once there is more than one it will be normal
ouch, good luck
also

do you happen to know how to remove that .0 ?
on python it's 700 on DB it's 700.0
or i shouldn't worry about such thing
what did you specify the fields to be?
when creating fields in pyther, o used TEXT, INT, CHAR, REAL, etc. it all adds a number (.0) at the end no matter the data type
or this wasn't what you askes ?
i'm really new to the programming so it's kinda hard for me to understand all the terms you guys would be referring to
It is probably just what you're viewing the table with. I wouldn't worry about it
@dull scarab
Do you know about my error? It seems simple, but I do not know how to solve it.
sorry for marcation
:/
I have no idea based on that. Unless you meant language instead of linguage
Can't say I do. Did you try this? https://stackoverflow.com/a/27168062
Should I run these lines on my terminal?
You should read what it says, to manually create the dir and paste the files from the link he provided
The lines are for a linux based, system and probably tailored towards the SO question. I don't know more about it than that.
word = keyword.get()
c.execute('SELECT * FROM pagrindinis WHERE alga=?', (word,))
for row in c.fetchall():
print(row)
it's a silly question, but. How to print out "Nothing Found" if this statement is false
what statement?
result = c.execute('SELECT * FROM pagrindinis WHERE alga=?', (word,))
result = result.fetchall()
if not result:
print("Nothing Found")
i would do something like this
since if there is nothing to select fetchall() returns an empty list
can you also explain how to check all columns with one value
like i'm here just cheching one of 6 the 'alga'


like i type one variable and it would check through all columns, if found any matching values print it
your SQL statement should return all rows where the 'alga' is equal to what is entered
but then.. it wouldn't work for other columns ?
sorry im not sure what you are asking
alga is the name of your column, if you want to check other columns you need another SQL statement
or create a variable to change the columns in the SQL statment
c.execute("SELECT * FROM pagrindinis WHERE vardas =?, pavarde =?, pareigos =?, telefonas =?, darbo_stazas_me?, alga =?", (word,word,word,word,word,word))
you need to use AND between columns, and that will only return the row that matches ALL of those columns
Let me try
okay so, i wanted to print if any of those were true not all, so used OR
word = keyword.get()
c.execute("SELECT * FROM pagrindinis WHERE vardas =? OR pavarde =? OR pareigos =? OR telefonas =? OR darbo_stazas_men=? OR alga =?", (word,word,word,word,word,word))
for row in c.fetchall():
print(row)
conn.commit()
did that work?
yea
@vernal ocean i have created a new table and now i want it to inherit 3 columns from the main table and one new one
what's the best way to do that, do you know ?
no sorry i dont know
Hi
I need help, when i try to insert data on a column and that data contains a ', SQL throws an error
How can i prevent that?
Could you provide an example
yes
Trying to add CyberLife is the world's leading android designer, manufacturer and retailer of androids. gives an error
@dull scarab
sql_query = f'INSERT INTO encyclopedia (name, alias, content, owner, created_at) VALUES ("{tag_name}", "{tag_raw}", "{cont}", "{str(message.author.id)}", "{str(datetime.now(timezone.utc))}");'
await crsr.execute(sql_query)```What database are you using?
InnoDB i believe
mysql?
yes
Try using prepared statements instead, as they handle most of these cases (to prevent SQL injections). You should be using them nontheless to prevent sql injections
query = "INSERT INTO table (x, y, z) VALUES (%s, %s, %s);"
execute(query, (1, 2, 3))```oh i see
where %s is a placeholder, and you provide the values for all placeholders as the 2nd parameter for execute
in the form of a tuple
works the same with strings?
it should
query = "INSERT INTO table (x, y, z) VALUES ('%s', '%s', '%s');"
execute(query, ('1', '2', '3'))```?You wouldn't need the quotes in the query
since it's not modifying the string, it is applying the values to the query for you
still, works when the string contains a '?
It should as it should escape them to prevent the variables from escaping the query
let me try
So I'm trying to switch my bot from sqlite to mysql but it won't connect to the host
import aiomysql
loop = asyncio.get_event_loop()
@asyncio.coroutine
def test_example():
conn = yield from aiomysql.connect(host='HOST', port=3306,
user='user', password='password', db='database',
loop=loop)
cur = yield from conn.cursor()
yield from cur.execute("SELECT Host,User FROM user")
print(cur.description)
r = yield from cur.fetchall()
print(r)
yield from cur.close()
conn.close()
loop.run_until_complete(test_example())``` File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 488, in _connect
await self._request_authentication()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 770, in _request_authentication
auth_packet = await self._read_packet()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 578, in _read_packet
packet.check_error()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pymysql\protocol.py", line 220, in check_error
err.raise_mysql_exception(self._data)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pymysql\err.py", line 109, in raise_mysql_exception
raise errorclass(errno, errval)
pymysql.err.OperationalError: (1044, "Access denied for user 'u400_UDCldfr76J'@'%' to database 'database'")
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "bot.py", line 34, in <module>
loop.run_until_complete(test_example())
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\asyncio\base_events.py", line 568, in run_until_complete
return future.result()
File "bot.py", line 24, in test_example
loop=loop)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 77, in _connect
await conn._connect()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 508, in _connect
self._host) from e
pymysql.err.OperationalError: (2003, "Can't connect to MySQL server on 'HOST'")```I get that error ^
I don't want to local host it though I have a database I want to connect it to
use its address then?
I am that's what HOST is
use the IP of host instead of it's name.
I am?
is u400_UDCldfr76J really the user name?
might want to double check their permissions
"Access denied for user can be host name, user name, password or specific permissions
Yes it is
Use the IP that's in there!
database name is wrong
I am
yeah
you sent database
oh
unless he changed it for the copy into here
he wouldnt get access denied if he used the wrong ip unless he happened to hit another db server by chance
he might if he uses the hostname and the permissions require the ip or the other way around
i thought that, but the error said it was caused by the second error.
thats not a typical issue on servers provided b a company
File "bot.py", line 34, in <module>
loop.run_until_complete(test_example())
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\asyncio\base_events.py", line 568, in run_until_complete
return future.result()
File "bot.py", line 27, in test_example
yield from cur.execute("SELECT Host,User FROM user")
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\cursors.py", line 237, in execute
await self._query(query)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\cursors.py", line 455, in _query
await conn.query(q)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 420, in query
await self._read_query_result(unbuffered=unbuffered)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 607, in _read_query_result
await result.read()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 1089, in read
first_packet = await self.connection._read_packet()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\aiomysql\connection.py", line 578, in _read_packet
packet.check_error()
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pymysql\protocol.py", line 220, in check_error
err.raise_mysql_exception(self._data)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\pymysql\err.py", line 109, in raise_mysql_exception
raise errorclass(errno, errval)
pymysql.err.ProgrammingError: (1146, "Table 's400_database.user' doesn't exist")```did you create the user table yet?
I believe so I'll double check
if this is the first time you connected then its likely that you have not unless you used the web interface
Yea I use the web interface must have not go through it wasn't created
Okay yea it connected now
I just forgot to save when I created the table
Okay so I'm trying to update a command i have from sqlite to mysql and well here is the code and error i get https://hastebin.com/uwidikucas.coffeescript could anyone help
Hello, I'm having an issue with MySQL 5.7.23. When I request the Database for information the first time it won't find it. But if I request a second time it will. I'd obviously like it to work on the first attempt rather than the second.
Any help on the matter is greatly appreciated!
it's likely a timeout issue
anyone wanan trade discord nitro
if you timeout and quit listening then the query still goes, and it gets cached so that the second query hits cache
How do I prevent the connection from timing out?
I haven't closed the connection anywhere
Just realised, my question in #help-coconut is more of a sql question then python so I should have posted it here maybe. But instead of posting it again could someone take a quick peek at it?
Going off of what I previously said, I don't think the connection is timing out. I just think that the query for whatever reason isn't able to search through the most recently updated rows. Instead it's going off a cached version of the Database.
I cannot find anything how to fix this issue or prevent it, if anyone can help that would be greatly appreciated.
Question:
im using postgreSQL through flask
Do I have to use SQLAlechemy?
from the tutorials im reading, it seems like i do
it seems like i have to make a SQL object or something like that?
hello i need help
ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'tag, picture, records, type) VALUES ('293555442670370817', 'Connor', 'Connor', '' at line 1")
What's the query
sql_query = 'INSERT INTO identification (id, name, title, direction, code, height, date, model, serial, owner tag, picture, records, type) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);'
await crsr.execute(sql_query, (id, name, title, dir, code, height, dat, model, serial, own, gamertag, picture, records, typ))```the values are
293555442670370817 Connor Connor CyberLife Tower, Belle Isle 48207 6' e RK800 yes CyberLife e https://vignette.wikia.nocookie.net/p__/images/6/67/ConnorANDROID.detroitbecomehuman4K.jpg/revision/latest?cb=20180602033431&path-prefix=protagonist None 1
is owner tag one column?
oh
Nonetheless you have 13 columns, and 14 values
How would I do like if name not in result[1]: result is what it's getting from the sqlite file and by doing [1] it should select only the column I specify
But I get this
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\discord\ext\commands\core.py", line 62, in wrapped
ret = await coro(*args, **kwargs)
File "C:\Users\galyajar0\Desktop\Bots\Garbage 3.1\cogs\tag.py", line 38, in create
if name not in result[1]:
TypeError: 'NoneType' object is not subscriptable
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\discord\ext\commands\bot.py", line 898, in invoke
await ctx.command.invoke(ctx)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\discord\ext\commands\core.py", line 1025, in invoke
await ctx.invoked_subcommand.invoke(ctx)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\discord\ext\commands\core.py", line 615, in invoke
await injected(*ctx.args, **ctx.kwargs)
File "C:\Users\galyajar0\AppData\Local\Programs\Python\Python37-32\lib\site-packages\discord\ext\commands\core.py", line 71, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: TypeError: 'NoneType' object is not subscriptable
@commands.group(invoke_without_command=True)
async def tag(self, ctx, *, name):
main = sqlite3.connect('main.sqlite')
cursor = main.cursor()
# Get the prefix from the database, using the guild id to search
cursor.execute("SELECT name, content FROM tags WHERE guild_id = '{}'".format(ctx.message.guild.id))
result = cursor.fetchone()
if name not in result[1]:
await ctx.send('That tag does not exist.')
elif name in result[1]:
await ctx.send(f'{result[1]}')
main.commit()
cursor.close()
main.close()
``` Here is my code for itI'm trying to do like ?tag <tag_name> and it would check if a tag with that name was created by checking the name in the sqlite file and if it's a thing it would send the content
Ping me when someone can help 😄
If there's no results matching the query it will return none, which you can't index
You can probably check for a result with result.get("name") as (per assumption) will return a named tuple when you use fetchone
Okay I got it to work sort of
But when I add a message that is more than like 15 or so characters the bot doesn't seem to get it
It adds it into the sqlite file
but won't let me have the bot grab and send it
If the message is more than like 15 characters
Any ideas?
nvm seems it isn't adding it to the file it just told me it did...
Is there a character limit on things you can put in a table?
There shouldn't be a limit at that low level
I can't seem to find why it won't add those ones to the table then it works with small messages
And I get no errors
String limit is like around 1,000,000,000 bytes or something
Unless I read that wrong
Yea so I can't figure out what's wrong with it there
How are you inserting it
@tag.command(aliases=['add'])
async def create(self, ctx, name, *, content):
main = sqlite3.connect('main.sqlite')
cursor = main.cursor()
# Get the prefix from the database, using the guild id to search
cursor.execute("SELECT name, content FROM tags WHERE guild_id = '{}'".format(ctx.message.guild.id))
result = cursor.fetchone()
if result is None:
sql = ("INSERT INTO tags(name, content, guild_id) VALUES(?,?,?)")
val = (name, content, str(ctx.guild.id))
await ctx.send('Tag added!')
elif name not in result[1]:
sql = ("INSERT INTO tags(name, content, guild_id) VALUES(?,?,?)")
val = (name, content, str(ctx.guild.id))
await ctx.send(f'Tag {name} added!')
elif name in result[1]:
await ctx.send(f'The tag `{name}` already exists.')
cursor.execute(sql, val)
main.commit()
cursor.close()
main.close()
``` And it works with smaller msgsIf I do
?tag create test testing test
it would create the tag test
so if I do ?tag test it would say testing test
What does the table look like
cursor.execute('''
CREATE TABLE IF NOT EXISTS tags(
id INTEGER PRIMARY KEY,
name TEXT,
content TEXT,
guild_id TEXT
)
''')
going to get some lunch I'll be back
I can't really tell. Try printing a few of the variables here and there and see that everything makes sense in that regard
Okay a quick update it's not the length @dull scarab It's not working at all now. It tells me it did but then it does not work
This is the full thing if that would help anyone help me figure out why it's doing this https://hastebin.com/wuvonufaba.py
Hey guys I’m having an issue with my function not grabbing the latest rows from the Database. It will work on the second request but not the first and I’m trying to ensure it always works on the first attempt
Any insight you can give would be great.
are those rows you want to find inserted within the same request?
They are seperate
@pure scroll
One is executed by a flask app, the other by a discord bot
probably you don't commit the change as fast as the another one tried to read
could anyone here help me out with a minor thing about asyncpg?
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
using asyncpg, is there a way to connect to the database outside of a function?
db = asyncpg.connect(**credentials)
async def bot_db_check():
await db.execute("CREATE TABLE IF NOT EXISTS assignable_roles (Role_ID integer unique, Name)")
await db.execute("CREATE TABLE IF NOT EXISTS assignable_roles (Role_ID integer unique, Name)")
AttributeError: 'coroutine' object has no attribute 'execute'```Any reason you need to do that?
basically I have a script that handles all database stuff
and I don't want to create one more class inside it
so, an async function to connect?
I mean, you kinda have to since asyncpg.connect is a coroutine you need to await
I see, thanks
(btw, I know IF NOT EXISTS is not a thing in postgresql. I'm migrating from sqlite)
Just ask for the db, store it where you're calling it and pass it to the db_check when it needs a db
it is a thing though?
its only a thing for DROP
No?
I've made some researches about it and as far as I've seen, thats the case
That looks perfectly viable for postgres
oh wait, my bad.
I use it myself ¯_(ツ)_/¯
await self.bot.db.execute("""
CREATE TABLE IF NOT EXISTS blacklist(
guild_id bigint NOT NULL,
channel_id bigint NOT NULL,
set_by bigint,
date_set timestamp,
primary key(guild_id, channel_id));"""
)```I mixed it up with CREATE DATABASE
That may be so
Finally got my relationship working in sqlite3 😄 Time to celebrate with ice cream and Game of Thrones
This is how I needed to set up my tables for it to work.
http://www.hatebin.com/qvvedujwqu
I'm super stumped on this issue: When I insert into into my table and I then want to select that info in a different statement it returns None.
Any help is greatly appreciated, I cannot find this issue anywhere. 😃
@sinful stratus i use a pool
@vale mulch share code for inserting and selecting + your queries. We cant magically know why this happens
alright thanks
@dull scarab how did you define db to your bot?
like, you're able to use it with self.bot.db.execute()
I want to do such thing, but even in __init__ of bot, it wants me to create the pool inside an async function
async def connect():
credentials = {"user": "postgres", "password": "paswd", "database": "db", "host": "127.0.0.1"}
return await asyncpg.create_pool(**credentials)
async def bot_db_check():
db = await connect()
await db.execute("""
CREATE TABLE IF NOT EXISTS assignable_roles(
Role_ID bigint PRIMARY KEY,
Name text);""")
when I use it like this, it creates a new connection each time
which is inefficient
idk what to do
you could either store connection into the variable and make your connect function return it if
e.g
connection = None
async def get_connection():
global connection
if connection is None:
connection = await asyncpg.create_pool(..)
return connection
or you could define a class that hold the connection and behaves that way
by defining the __call__ method for it
could you show an example of such class too?
class Connection:
def __init__(self, credentials):
self._credentials = credentials
self._connection = None
async def __call__(self):
if self._connection is None:
self._connection = await asyncpg...
return self._connection
connection = Connection()
def my_func():
db = await connection()
or just explicit get_connection method
whatever there are lots of ways
but the idea stays the same
I see. thanks a lot! I truly appreciate your assistance.
you just make it lazy, so it is called for the first time the connection gets created
any consequent call would return already created connection
I see
I sometimes assign it to my bot
Sometimes keep all db related things in a seperate file / cog
when I run the bot, database sessions increase by 10 like this https://gtaodiscord.com/u/a0be5e16d9bc.png

but it stays the same. is it normal?
Probably
As pool allows for multiple transactions, so its probably just creating more sessions
Without saying im 100% sure that is it
I see. btw do you also assign the db to the bot with __call__ ?
You can also create a task to connect in your init, connect before you start the bot, or connect in on_ready
No
am I able to make __init__ async?
No, but you can create tasks for the eventloop to handle
Bot.loop.create_task(coroutine())
hmm
Not going to state its the best way to do it, but this is how I opened a connection in an init https://github.com/tagptroll1/Streamio/blob/master/cogs/database.py

GitHub
Contribute to tagptroll1/Streamio development by creating an account on GitHub.
hmm, I see.
conn.ping()
cur = conn.cursor()
cur.execute("INSERT INTO License VALUES('{}', '{}', '{}', '{}', '0', '{}')".format(cusKey, email, customerID, subscriberID, end))
conn.commit()
cur.close()``` conn.ping()
cur = conn.cursor()
cur.execute("SELECT * FROM `License` WHERE License_Key = '{}' AND Used = 0".format(key))
keyInfo = cur.fetchone()
cur.close()```@dull scarab Those are my insert and select statements.
To reiterate the issue I had, when the first statement is executed I have full reason to believe it's commit because I can physically see it in the Database using MySQL Workbench. When I execute the 2nd SELECT Statement the key value is not found within the Database and it obviously returns None.
Don't use .format() you make yourself vulnerable to sql injection.
Anyway, have you tried running this query directly on the DB rather than through python?
I have not, I can right now give me a second.
And can you show the structure for this License table?
Table: License
Columns:
License_Key text
Email text
CustomerID text
SubscriberID text
Used text
End Date text
Table: Subscribers
Columns:
License_Key text
Email text
CustomerID text
SubscriberID text
DiscordID text
End Date text
Expired text
UUID text
Canceled text
Also @pure cypress Just tested it directly with the Db and it returns all results properly
If it helps narrow the issue down I'm using JawsDb with Heroku
Are you sure your query string is correct?
after formatting
like the key looks like its inserted correctly etc
Yes because if I restart the discord bot in which I'm making the query through it will work.
so it only works when you restart?
Yeah
I have a file called database.py which all the queries are made through
and import it into the flask app/discord bot I'm using
which package are you using for interacting with the db?
that's the official one right
Yeah
I don't see anything wrong with it (besides using string formatting, but that's not relevant for this)
Not sure why it behaves like that
Yeah I can only assume it's the Database itself but other people have been fine using JawsDb
maybe you need to explicitly commit?
What do you mean exactly?
That would be great, thank you!
Interesting that it says it does not commit by default
Yet you see your table updating when examining it manually
Well I have auto commit enabled in mysql workbench
Is that just some tool to examine the db?
So how have you been testing? Run the Python code then you see in the workbench the table was updated?
Or you've just been testing inputting the query yourself into workbench?
I execute a test payment through stripe, the webhook is sent through the flask app
Sorry, not just the query but the table update too of course
the flask app takes information generates a license key and commits to the table
Just try committing it in python and see if that works.
? so issue fixed?
You're saying you tested with explicitly doing cnx.commit()?
well cnx.commit() is the same as my conn.commit()
right
They are just using cnx.commit() because cnx is what they assigned to their connection to the Database
Yeah, all good thanks for the help, this issue is super confusing
The only reason I can think it wouldn't be working is because I'm using two separate "apps".
I'm going to try splitting it into two separate files
What means sqlite3OperationalError: database is locked?
presumably that the database is locked

Stack Overflow
sqlite> DELETE FROM mails WHERE (id = 71);
SQL error: database is locked
How do I unlock the database so this will work?
weird - it seems that that error means that the database is locked to that specific connection
for instance
@teal rampart Close your database viewing program
and then relaunch the script
are you accessing the database from multiple threads? @teal rampart
or processes?
hmm
that looks fine to me so far
do you get the locked error at specific points or is it random?
Specific
which ones
is this the entire function?
yes
hmm. the only thing that comes to my mind is that maybe since you're not using the async sqlite wrapper there's some funky interaction going on somewhere
either that or some hung process is keeping the db locked
can i send an error i get? but im not sure if its related to databases or not. its related to the subproess tho
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
Alright so hypothetically if I have two connections to my Database in MySQL and Connection 1 inserts information into a new row, and I want to select that information from Connection 2, is that possible and if so are there any preferences I have to change or adapt my code in anyway? I’ll send my Insert and select statements here shortly.
You can do that with 2 different connections, sure.
But the insert statement has to be committed before your select statement fires.
Otherwise you will not see the changes.
@buoyant breach That's my dilemma. I trigger the select statement manually
After I know the insert statement is commited
but the select statement doesn't find the newly inserted information until I reconnect to the Database
cur = conn.cursor()
sqlQuery = "INSERT INTO License VALUES(%s, %s, %s, %s, 0, %s)"
cur.execute(sqlQuery, (cusKey, email, customerID, subscriberID, end))
conn.commit()
cur.close()``` cur = conn.cursor()
sqlQuery = "SELECT * FROM License WHERE License_Key = %s AND Used = 0"
cur.execute(sqlQuery, (key))
keyInfo = cur.fetchone()
cur.close()```All solved now.
Obviously it was a simple issue. But quick question regarding I guess efficiently
Is it ok to make a connection every time a query needs to occur? Obviously the connection is closed after it's done.
what solved it? im curious
@vale mulch it's kinda ok as long as queries are sparse. Connection process itself takes time and resources.
@buoyant breach Gotcha, yeah they should be spaced out enough to not warrant any issues.
Also @vernal ocean I have 2 Connections 1 for my Discord Bot one for my flask app. So when I was inserting information from the Flask app connection it wasn't being received on the Discord bot's connection, so to solve this I just have the connection be created for each query
So that each query always has the latest information possible.
Each query should have the latest info possible even with persistent connections.
If you do not get it - it may have to do something with transactions not being committed for some reason.
@buoyant breach
Hi, nice to meet you
so ive got a table that has columns that are text and some that are binary BLOBs, if there a way to check if they are blobs, or am i okay to just except FileNotFoundError for when the column isnt a blob?
sql_q = "SELECT content FROM {}_tags WHERE tag=?".format(table_name)
result = await self.db.query(sql_q, (tag,))
result = result.fetchall()[0]
print(result['content'])
try:
file = result['content']
file = discord.File(file, "tag.png")
await ctx.send(file=file)
except FileNotFoundError:
await ctx.send(result['content'])
this does what i want, but i want to know if there is a better way
looks like ```python
isinstance(result['content'], bytes)
I'm trying to use aiosqlite but I don't understand how it works. Can anyone help me?
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
OperationalError Traceback (most recent call last)
<ipython-input-1-50e3e5810ac2> in <module>
13 AGE INT NOT NULL,
14 UNIQUE(FIRST_NAME,LAST_NAME)
---> 15 ):''')
16
17 print('Database Created')
OperationalError: unrecognized token: ":"
idk if i put the ''' correctly
is there a way i can query using django a 2-word string that may contain double spaces?
because when you query 'a string' and the real value is a string it won't show up because of the double spaces
@buoyant breach Yeah exactly what I figured but I know the transactions are committed because they can be viewed from MySQL workbench
Which just made it easy to do this work around since it solves my issues flawlessly
Well as long as it works fine for you - it's ok. =]
Yeah it works, but I also did upgrade my JawsDb to 8.0
Idk if that made any difference
@median ocean if you mean querying via django ORM - I don't think there is an easy way to do it. You can try https://docs.djangoproject.com/en/dev/ref/models/querysets/#regex though.
@buoyant breach ya, thank you, i'll dive into it
in python
i have this bit of code
when run, i get the following traceback
can someone help plz?
clients is a list of strings
a comma is needed to separate the query string from the parameters
furthermore, I believe the parameters must be tuples, right? If that's the case you need (i,) to create a tuple with a single value
yes
🤔
I think columns needs to be singular column
Oh it's cause table and column names cannot be parameterised
🤔
this is where i got the main block of code
so i hav to add in the name into the line itself?
But they explicitly write the column name rather than taking it from a variable
You could do it with string concatenation but be wary of sql injection when doing that
i need a variable, since the commit is meant to be in a loop
@pure cypress
according to w3, its from a web page input
so, what did u mean be wary?
Make sure you don't allow it to happen in your code
If you just have a constant list of column names then you should be fine
but if they come from user input or some sort of generation then it's a risk
cursor.execute("SELECT * FROM user WHERE name = " + name)```
or also
```py
cursor.execute("SELECT * FROM user WHERE name = {}".format(name))```Hey I was wondering If you guys can help me out on the basic structure of a database for a shopping cart
Is the following structure safe , and correct ?
- users table
- products table
- order table with order id and a relation to the user
- product order table with product order id and a relation to the order table, this table lists the ordered products individually
can django ORM handle/store positive big ints?
i guess I can just use MinValueValidator
don't want users to submit negative big ints
BigIntegerField may be what you are looking for.
@buoyant breach it allows negative values, so i just used validators=[MinValueValidator(0)]
Yes, for positive only you either make a type of your own or validators.
this question has probably been asked a lot already, but nonetheless, pandas or sql? I got the good hang of pandas, and know a thing or two about sql, but im way more comfortable with pandas. Which to choose?
well you'll receive the answer that's probably been given a lot, 'depends on your usage'

we can't really tell you more than the error already does
show us the code
what is col.find_one supposed to return?
corresponding to which python type?
so a dictionary I guess
not sure how that is supposed to have worked before. blind ugess would be serverdata.update_one would need to be col.update_one
not sure how "update one" is supposed to work - does it update the first thing it finds that matches some criteria?
try python help(serverdata) see if you can actually use update_one
so it's a dict object it has no attribute, unless you want to use the method update_one which I'm not sure where is it coming from, so I assume your issue is with update_one
try adding col. before update_one
nah that wont' work
it's a direct result of col lol
well then you're trying to update the collection why not just use col.update_one(), or is it a must that you instantiate it
hm
try find_one_and_replace()
replace find_one with find_one_and_replace
or you can merge both lines using find_one_and_update()
@set.command()
async def testing(self, ctx):
client = mcl("mongodb://Savage:nonononono@ds117423.mlab.com:17423/rapterdb")
db = client.get_default_database()
col = db["serverdata"]
col.find_one_and_update({"auth":True},{"$set": {str(ctx.guild.id):{"goodbye message":"Not Set", "welcome message":"Not Set"}})
await ctx.send(f"Current server data is here: \n \n{serverdata}\n")
you got it? nice!
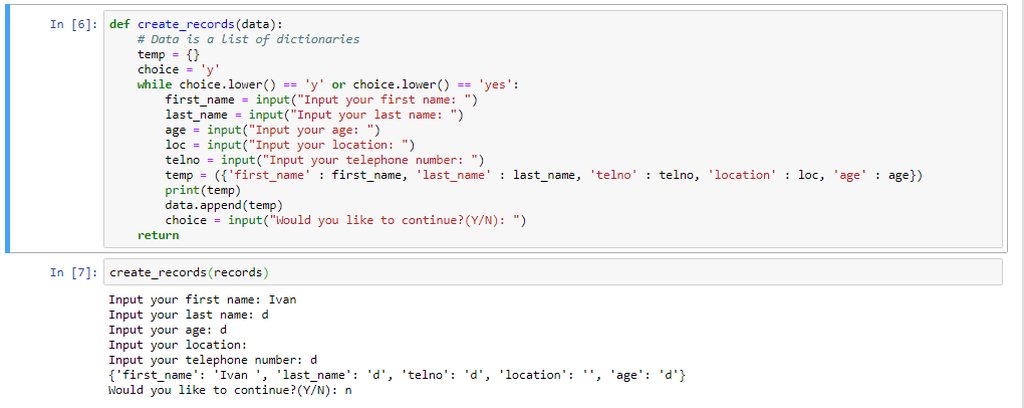
{kind=link}
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
instead of storing and retrieving the values in a list of
dictionaries, how to store and retrieve from the table created
?
are you creating a table?