#databases
1 messages · Page 52 of 1
But the thing is how to?
cause I did this code ages ago
and been asking everything how to fix it
No offense Hype but you should probably learn the basics of python before tackling bigger projects :/
Because you'll just keep running into issues like these
But there are no docs about making leaderboard commands
there are no docs on building amazon either
No but there are docs on how to use Python's basic data types/structures
programs are built up of components
and you need to figure how to stick those together out by yourself
and if you have other people do that for you, you won't really learn
it's gonna be like asking your friend to build a lego house for you
I do not want people to do it for me
How do you think I learned Python lol
reading books
but you're doing the equivalent of
"should I use this LEGO brick?"
"should I put this LEGO brick here?"
"should I use a red or green brick in this spot?"
we'd like you to succeed with your project, but you need to get to a place where you're more confident with the syntax and structures that you're using so we don't have to hold your hand through every step of the process
otherwise no one will get anything done, us or you
Yes but I wanted to challenge myself
not making simple Discord commands like cookie
and ping
and certainly not copying Ytubers
cause I have seen servers were people just wait for another viedo
video
and do not even know the basic stuff of discord.py
continued discussion along this vein probably belongs in an off-topic channel
Asking for every step is not challenging yourself
actually there is no point of you guys wasting my time on me
.
I am just asking for help.
there are 4 people in the database
I've been having issues on this: https://discordapp.com/channels/267624335836053506/342318764227821568/487911707931574303
Some people have answered me but I was already sleeping by then because they responded at 4 am in my timezone. Because of the time gap between that discussion and now, i'll be asking the question again
So over the past days, i've been working on fixing up the speed of my Discord Bot, and one of the big things that i've done was change the bot's way of saving data from separate per-server json documents in a folder to one big database which saves data. For whatever reason, the bot's response time has nearly doubled after I started using databases. I haven't changed anything else (including other asyncio events) - only json documents to databases, meaning there's something about databases slowing my bot down. Does anyone know what could be the issue here? I am using RethinkDB. (Those of you who've helped me on this already know what i'm talking about)
so you‘re just gonna ignore the answers because you‘ve been sleeping?
i acknowledged the answers
one of them said "why would you save a json document to a database tho? doesnt that kind of defeat the whole point of having a database if you just save the file?"
and to that i say that i've been updating my code to where it'd only save certain fields etc
but for some reason, dbs are still slower than what i've been using - json files
and we also explained why
there is no way a good database can be slower than reading and parsing a json file in python
oh, but, you're using rethink
wait
are you writing the json data to a db field?
@ionic pecan most people here will host the db on the same machine the bot is on
yes
and yes the db is hosted on the same server as the bot
network also shouldn't be a problem as the server has around 800mb upload/download speed
im gonna ask the same question the other guy asked
why are you saving entire json documents in a db
..
db.get(str(ctx.guild.id)).update({'apps':{appname:{'intro':newintro}}}).run(self.bot.conn)
that basically means data["apps"][appname]["intro"] = newintro
ORM?
i can read python
ok i was just saying in case u don't do rethink ook
ah, i see thanks
what's ORM?
object relational mapping
but rethink doesn't actually use an orm
i think rethink is your big issue here
you'd probably be better with a traditional sql database
but my data is formatted like a huge dict with more nested dicts and lists
there would be no way for me to use a traditional sql database unless i change literally everything
🤔 i dont know what data you have, but it may be worth the time to reformat it
i have a friend running a bot in like 8k servers that also uses rethinkdb on the same server
Usually, when looking for huge performance boosts. A rewrite is considered
with the information you told us, that's the only thing i can think of that would improve performance
but that's what i was confused about
json files and the nosql json db stored the exact same data, while for whatever reason json files was faster
because nosql database is just json files with a special way of accessing them
rethink is built for realtime (collaborative) access
would mongodb be good?
and also, then why would another bot which uses rethinkdb have a good response time?
but it does though
dunno lol
whtAwhtwEAFJIWJFOWIA
wdymmm
that's sucks ass broo
how does that even make sense
is there a way to have PyCharm auto start my local MongoDB server?
currently I have to start the server manually when I begin a "programming session"
meaning go to a folder and start mongod.exe
small inconvenience but can have broader implications? (doing stuff pre/post Python script execution?)
how do i manually unlock my database?
actually
@hollow tiger upload speed doesn‘t matter, latency does, you‘re always gonna have more latency with network I/O than reading files manually
so in the end, dbs are slower than json files?
@ionic pecan
or is there something i'm missing out on that's making dbs slower than they're supposed to?
you‘re misunderstanding terms here
speed != latency
queries over the network will be slower than direct file i/o
if you have something like 1,000,000 entries in your data, asking postgres to get you something with ID 74 will be instant, and with json you‘ll just have to go through the list and notably also load the entire doc into memory first
i have around 2.2k documents
ok
so i should've kept using json documents?
if you really want to use JSON i can‘t stop you. at the end of the day the only advantage of json i can think of compared to a solid database is latency, and there‘s 2000 disadvantages
man it's not that i don't want json
i want what's faster and more reliable
everyone's been telling me dbs are faster
i was really hesitant to change because it would take forever to learn dbs and change the code
it took me so long but after i changed, the bot's response time literally doubled
i was so hyped when i first ran the bot with dbs, but when i tested the ping, i was extremely disappointed
it took me a lot of time to learn how dbs work u know
And they would generally be better, I still feel like the way you structure your data is inefficient (Without knowing how rethink works, I'd assume having long method chains either builds a really long query, or queries a lot of values)
but that shouldn't be the problem here since it's remained constant from json to db
Which is probably why it's inefficient
what
What values do you have
well from the base it's not really a lot of info
{"apps":{},"members":{},'DM':True, 'blacklist':[], 'logs': None, 'archives': None, 'appeditroles': [], 'appreviewroles': []}
that's the base
if i explain what each thing does then it should be easier to understand
well for the most part, i'd be explaining "apps":{},"members":{}
my bot is a discord bot made for staff applications within disocrd
"apps"{} would be storing a dict full of apps, like this
Are you referencing a bunch of different things through the same structure then?
what do you mean by referencing a bunch of things?
What does a "slow" query look like thenb
just show me one of em
an app?
a query
of what?
anything that slow
but like
every command
/config --> 10s delay --> the message
not 10s more like 2s
again, databases aren‘t slow
my bot runs a select on every message and guess what, its blazingly fast
i am so bad
what
my db queries take around 20-50ms. i have no idea what you‘re doing that would take 2 seconds
i've been spending the last month trying to fix my bot's response time
messing with asyncio, json, and switching to dbs
asking for help, confusing helpers,
when in the end today i've just found out
sharding fixed everything
my ping has finally went down to around 150
sharding of?
So in other words, it was never a database issue.
apparently not
i'm still confused on why switching to dbs doubled the response time of the bot
maybe i happened to gain even more servers
we‘ve explained why using JSON might have lower latency than using databases to you like 3 times already
did you read that?
and what about it is still confusing?
idk man this whole problem i've been having has been pissing me off
it's 4:06 am and i can barely process anything anymore
hi, i previously has a SQLite database with all the items in my game, in one table, i decided to split items into different tables for ease etc
is there a way to search across all tables? previously i used
whats the best DB to start out with
SQL makes me want to kill myself
so preferably not SQL
sql is probably best for a bot
o
def item_by_owned(owned):
c.execute("SELECT * FROM items WHERE owned=:owned", {'owned': 1})
return c.fetchall()
@young scarab why on earth would you want to search across all tables?
just make a new table for each user
if i owned a weapon in weapons and an armopur peice in armour
there is only one user, the player
@visual flume I assumed you're making a bot. db choice depends on the project
idek what redis is lol
yeah and if owned and creating inventory dictionary from that
so i thought itd be better to do one query accross all tables rather than having to search them one by one
dont believe sqlite allows that
you could use flat files, but be careful with that
just make a new table for each user
that's. .. don't do that
@pseudo compass i mean right now im just using dictionaries and writing them to json files lol
anyone know why my rasbian cannot find my balance data in my db file and my windows can?
same file on both computers
something must be different
Hi guys, is there a best practice to do data migration? I have an existing database with data, but some rows are missing, no big deal, I've got all I need to create them, but how should I go for that? I have a Flask and SQLAlchemy back-end, using alembic for migrations, should I go for an alembic or python script?
I don‘t think you‘ll have much use of writing up a script to migrate data, if you need to do so again you probably can‘t reuse the old one
Instead, use your databases’ built-in tools to do it
E.g: pg_dump and pg_restore for postgres
Can anyone help me with this?
I have some code for my python project(though this is a SQLite question) where I'm using SQLite to keep all game items.
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
def item_by_owned(owned):
c.execute("SELECT * FROM items WHERE owned=:owned", {'owned': 1})
return c.fetchall()
def print_inventory_names(inventory):
for i in inventory: #print out the name(index[0]) of each item in inventory
print(i[0])
inventory = item_by_owned(1)
i = 0
print_inventory_names(inventory)
This works great if i were to put every item into the one table, I'd like to split my DB up though as below:
Is there a way to search across multiple tables?
something like:
SELECT * FROM items,items2 WHERE owned=:owned
Does anyone know how I can get a unix timestamp for postgresql asyncpg?
huh
@young scarab why have a table for each item
it was to split items up weapons from armour and food etc as food would have a lot less fields than armour for instance
and i thought itd a more efficient way to just display food rather than search through it all everytime i just wanted to display food items or weapns etc
if i put it in one big table every food item would have loads of None feild entires as they dont have attack or defense stats etc
yeah for this one search
@upbeat rivet ???
to list all types of items with the field 'owned' being a 1
so this is an all items owned across all item types sorta search
Something like sql Select * from table1 UNION Select * from table2?
Itll remove duplicates, but you can use union all if you dont care about dupe. Not that you should have any?
sqlite is picky

Stack Overflow
I'm trying to query multiple tables at once. Say I have a table named PRESCHOOLERS and I have another one called FAVORITE_GOOEY_TREATS, with a foreign key column in the PRESCHOOLERS table referenci...

i was pervoiusly trying (as one of my test) select * from items Union items2 ...........
etc
so this should help me cut down wastefull queriying for most things, thanks very much
@pseudo compass like for sqlite I could do: strftime('%s', 'now', 'localtime')
but I switched to postgresql.. So I need that for postgresql
NOW()
?
Won't give me that
I want an unix
Since I want to convert it back to a formatI like
I convert it back like that: py timestamp = datetime.datetime.fromtimestamp(int(numer[5])) timestamp = timestamp.strftime('%d.%m.%Y | %H:%M:%S')
i mean
did you try searching for it yourself? 😛
bolt=# SELECT EXTRACT(EPOCH FROM NOW());
date_part
------------------
1536597692.17487
(1 row)
this seems to be what you want
In my database
EXTRACT(EPOCH FROM NOW())``` is a valid expression, you can put that in your tableLet me try
bolt=# CREATE TEMPORARY TABLE test (ts BIGINT);
CREATE TABLE
bolt=# INSERT INTO test VALUES (EXTRACT(EPOCH FROM NOW()));
INSERT 0 1
bolt=# SELECT * FROM test;
ts
------------
1536597865
(1 row)
Oh yeah I see nice I didn't know that. But that is what I am looking for
Will give me the local time?
yes now
It does
Thank you again. I actually found the same but didn't know I could use it in my case :D
👍
How you guys do it to close all connections if you stop the bot (For Postgresql)
make a quit command
I have something like that. a shut command which does: await self.client.close()
so I need to add there:
await self.client.c.close()
self.client? what are you doing?
Have the connection in my init
class SquanchyBot(commands.Bot):
def __init__(self, command_prefix, **kwargs):
super().__init__(command_prefix, **kwargs)
async def pool_init():
credentials = {"user": "admin", "password": "kkkk", "database": "database", "host": "kkkkk"}
self.c = await asyncpg.create_pool(**credentials)
self.loop.create_task(pool_init())```but self.client.c.close() wont work
await?
how do i prevent people from importing again?
like they register which imports, but i dont want it to import again
what do you mean @torn sphinx ?
so i have insert into
but once they insert they can do it again
i dont want that
im sql
so no importing. you are talking about inserting data into a database?
i might not be following your line of though.
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
Use their user id as a unique key
hi guys, I'm trying to create a polish conjugator. I'm having a problem about my characters on sqlit3. it actually is Jadę but at the table i see "JadÄ™" how can i fix this?
https://puu.sh/Btjha/421146058a.png

are you sure that's sqlite's issue and not whatever database inspector you're using?
I'm not sure, when i print at shell i see the correct character on python.
and I also using db browser for sqlite. is there any solution for me to fix this issue?
Its not an issue really, just seems to be the way db browser represents that character
i wrote a search motor for my database. so when i search my verb with polish characters i can not found any. but when i do use Jechać, it works. but it should work with polish characters.

I am making an data = await cur.execute("SELECT * FROM TABLE ORDER BY %s DESC;", (order))
But when I make
if 421296425981181952 in data:
print("Test")
I see nothing its printed, but when I check if 421296425981181952 is in my db manually, it appears as a normal value.
I am using MySQL
@hasty hinge what if you print data?
oh wait
is that psycopg2?
looks like the results would be in cur
try doing if ... in cur
although i guess data would have it too 
I am using AioMySQL
@torn sphinx And if I print data, the console will probably crash. Because it is a table with 4800+ rows
is your table name actually table
No, I changed it in that to make it easier to explain
you sure itd crash?
try it
execute returns int, number of rows that has been produced of affected
per the docs
try data = cur.fetchAll() after execute
That's what I am doing @torn sphinx
so
cur.execute(stmt)
data = cur.fetchAll()
cur.fetchAll()
But cur.fetchAll() its returning me a tuple of tuples, but when I check if its the ID what I posted in data with a print, the console doesn't returns me nothing.
yeah so fetchall is gonna return you all the rows
for row in data:
if <number> in row:
print("whatever")
I just tried that, nothing is printed @torn sphinx
no idea then, i would fiddle with the fetch more and find out what is being returned
ok so I was making a site with django and for some reason django didn't create the columns for one of the apps
I was able to create most of it manually and that fixed most of the issues
but I have no idea how to get it to properly make the DataTimeField work
I'm getting this error not sure what it is
'str' object has no attribute 'utcoffset'
this is my code
from django.db import models
# Create your models here.
class Blog(models.Model):
title = models.CharField(max_length = 255)
pub_date = models.DateTimeField()
body = models.TextField(max_length = 255)
image = models.ImageField(upload_to='images/')
Im able to create the date and everything in the blog post but when I try to view it again, I get that error
Im using pgAdmin 4
ok never mind this fixed, before it didn't work but I changed the datatype on the database and somehow now it worked (even tho I did that before and didn't work...)
from datetime import datetime
...
...
pub_date = models.DateTimeField(default=datetime.now)
lol sometimes talking about it helps XD, I need a rubber duck..
for relations (the diamond shape) in an er diagram, what is it actually?
lets say i put it between a many to many relationship
is the diamond shape a table?
another question

i have this er diagram and under match, player1ID and player2ID both references playerID in Players
idk if that is possible, taking out 2 different things from playerID and assigning them to player1ID and player2ID seperately
if not, what should i do instead?
nevermind, i solved all of those
last question, what NF are the tables in that ER diagram?
@severe bridge What are player1 and player2 for in the match table
Is there any way to limit rows processed by LIKE in mysql query. For example I was trying with subquery with LIMIT 10K but it turned out slower. The point is executing the LIKE query on 10K rows insteed of the full db.
@glossy ermine player1 and player2s username
How can I replace every "null" in my db with 0?
what have you tried already?
@ionic pecan I tried with SELECT IFNULL(Column, 0) FROM TABLE
But that is not changing the values
Wouldnt you want to update the values
@severe bridge Why do you need to store their username if you have a link back to the player table
@hasty hinge You would have to use UPDATE
UPDATE table SET column = 0 WHERE column IS NULL
idk but i removed it
i ended up moving everything besides player1 and 2score and tournamentid to registered, and removed player1/2
alright
Playing with Pony ORM. Everythin in the docs says while messing with the interavctive interpreter I dont need to worry about db_session(),. except I'm constanty getting errors that im not in an active session.
If I wrap everything with the context manager db_session everything is fine, but appearently im not supposed to have to do that.
Anyone else experiecne this? ideas on how to fix?
Is there a way to use SQLAlchemy's ORM with "dynamic" tables?
What I mean by dynamic: the idea of the program is that users can upload "tables" (CSVs or SQL dumps) and manipulate them. I'd like to use the ORM system,
but since there's no way to know how the tables will look before they're uploaded, I cannot declare the Mappings that are required by SQLAlchemy.
Is there a way to dynamically declare these mappings?
If possible, could I please get @'ed in responses? Cheers.
@left haven
- why would you want that...
- might could parse the input
It's part of the requirements, as in, it's the main requirement
Also, what do you mean by "parse the input"? Getting information about how the input is formed isn't the issue, the issue is getting the SQLAlchemy mapping working (which is represented by a Python class)
@left haven Build the class from the input
set the tablename and whatnot by parsing the input
How can I get something like .index() in SQL?
I did a select with a order and descendent because I want to make a top, but I don't know how to get the row number.
This is my select: SELECT * FROM USUARIOS ORDER BY XP DESC;
Yo get top x amount? @hasty hinge
To*
If youre using fetchall (or similar method) your can get their position by enumerating the list of rows. You can also limit for many rows your get in your query with
LIMIT # iirc (# being a number)
!t enumerate
enumerate
Ever find yourself in need of the current iteration number of your for loop? You should use enumerate! Using enumerate, you can turn code that looks like this:
index = 0
for item in my_list:
print(f"{index}: {item}")
index += 1
into beautiful, pythonic code:
for index, item in enumerate(my_list):
print(f"{index}: {item}")
For more information, check out the official docs, or PEP 279.
Or if you're using SQLite which it sounds like you are, you specify the query to include the rowid
SELECT rowid, * FROM USUARIOS ORDER BY XP DESC;
@hasty hinge
nvm im back to my old question
lets say i have a primary key called players, inside are the players player1 and player2
i have 2 foreign keys called player1id and player2id, how do i call 2 different players from players using the 2 foreign keys
how do i set a row of cells as the fields in excel so when i import them into db browser they're the field names?
So you have a table called players, with a primary key called player_id
You bring player_id into your second table, let's call your second table score. So your score table will have: score-id (primary key), player_id (foreign key)
Then you write your SQL statement to be select score-id, player_id where player_score is not null. So then as long as your players both have scores, you should be good :)
someone else helped me, they told me to change my table so now it looks like this
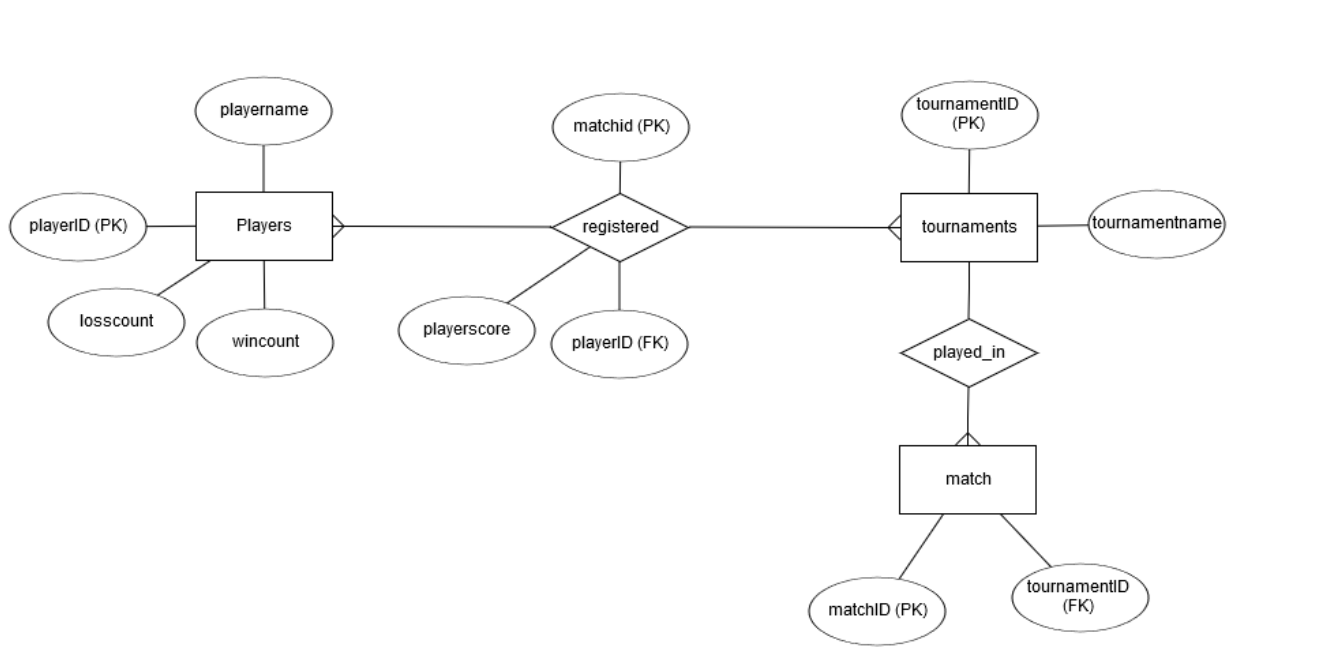
im skeptical though
will it work? because 2 players are supposed to match and then id update the loss/win count
but here i only have 1 player id
@wet sleet
matchid will be the connector between players, as the same match will have the same id, therefore you can query all players in that match
alright
i have another problem though
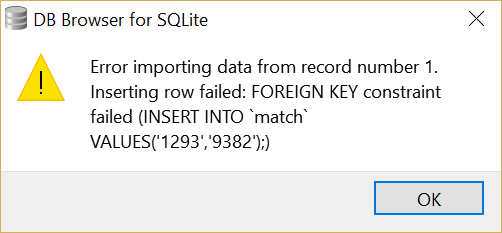
im getting this when trying to import csv data into match
CREATE TABLE tournaments (
tournamentname VARCHAR(64) NOT NULL,
tournamentID INT(4) NOT NULL PRIMARY KEY)
CREATE TABLE match (
tournamentID INT(4) NOT NULL,
matchID INT(4) NOT NULL PRIMARY KEY,
FOREIGN KEY (tournamentID) REFERENCES tournaments(tournamentID))
```these 2 are the only relevant tables
what did i do wrong
besides not using autoincrement
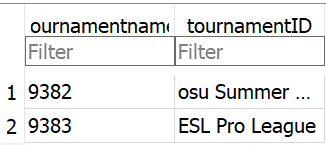
oh
now i see why i swapped tournamentname and tournamentid lmao
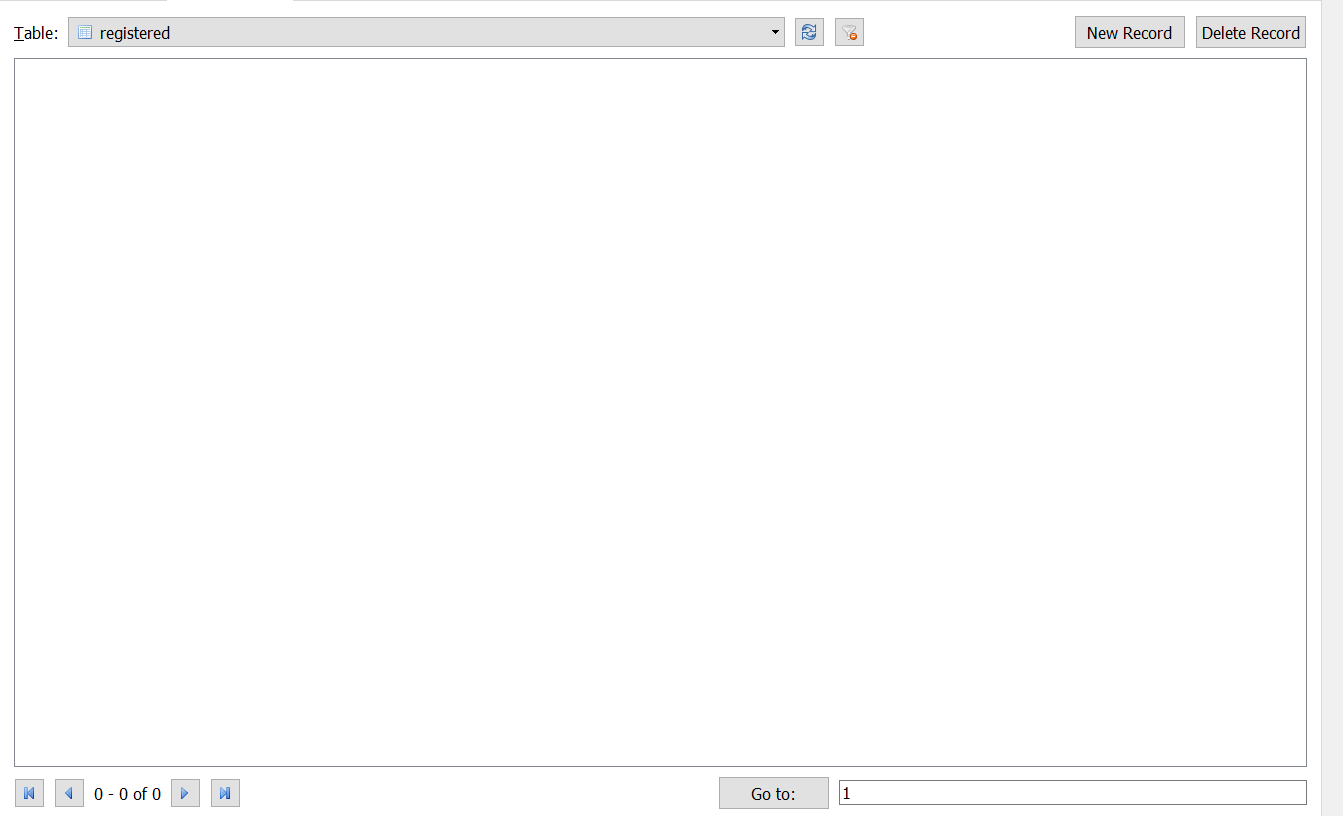
anyone know why theres nothing in here?...

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@dull scarab sorry for pinging, but its urgent since my project is due in like 2 hours
I don't know I'm afraid. My skills in sql are limited to most base usecases
But I'd guess you have to put in the references yourself between players and matches
That it's not an automatic thing, but that's just my guess
ok
Hey, I need a little help with Redis.
self.bot.r.set(
f"{game}-players", dumps(
loads(
self.bot.r.get(
f"{game}-players"
)
).append(
ctx.author.discriminator
)
)
)
This somehow wipes the key.
(r is an instance of StrictRedis from the redis module)
.append is generally an in-place operation, isn't it?
self.bot.r.set(f"{game}-players", dumps([]), nx=True)
This is how the key gets initialized (if doesn't exist).
Yes.
Oh... Shit, kinda used to in-place ops usually also returning the new version from a particular language that shall not be named.
QQ: Why couldn't this be answered on #help-coconut? I mean, this issue didn't even actually involve the DB (or any of the DB calls).
@vestal apex
because I hadn't looked at it very closely and I wanted to give you a place to be that wasn't being immediately interrupted by someone else
Well, in that case, 👍 😄
def create_table_Previous_Violations():
c.execute('CREATE TABLE IF NOT EXISTS Previous_Violations(name TEXT, address TEXT, zip TEXT, city TEXT)')
def data_entry():
values = ("SELECT facName, facAdd, facZip, facCity FROM excelDataIns INNER JOIN excelDataVio on excelDataVio.serialNo = excelDataIns.serialNo WHERE vioStat = 'OUT OF COMPLIANCE'")
c.executemany("INSERT INTO Previous_Violations(name, address, zip, city) VALUES (?,?,?,?)", values)
conn.commit()
c.close()
conn.close()
I'm trying to select some data from a table on the data base and insert it in a new table but im getting a "ProgrammingError: Incorrect number of bindings supplied. The current statement uses 4, and there are 1 supplied" anyone know why is this?
You're passing one named tuple (Im guessing that is what values is) as one parameter to a prepared statement which requires 4
You probably wanna unpack values
Can anyone tell me how to dereference a DBRef using MongoEngine, or Mongo in general for that matter?
I have a my_documents = ListField(ReferenceField(MyDocument) in my MyUser document, but when I try to access the field all I get is something like [DBRef('mydocument', ObjectId('5b9ce67d69dff700136f0829'))]
do I have to manually go fetch those?
Hi. i want to get the names of these packages and insert them into the database which is located on a server. what is the fastest way to do that? because i tried to fetch the package names with html parser and put them in local sql db and it took like 10 seconds(i tested with local db but want to make it online actually). https://pypi.org/simple/
and for this purpose, it's better to use mysql db or mondoDB?
You can get package information on PyPI from Google's BigQuery
I don't know much about it though other than using the pypinfo package
Probably PostgreSQL or MySQL
Can / does sqlite raise a specific exception if an insertion fails based on duplication, so i dont have to check my database for a matching entry before inserting / denying
user = db.fetch("SELECT username FROM users WHERE username=?", (username,))
if not user:
db.execute("INSERT into users ...)
... ```to avoid this
I'm fairly certain it ought to, so long as the column is marked UNIQUE
data = changeset_details(id=id,
created_node=created_node,created_way=created_way,created_relation=created_relation,
modified_node=modified_node,modified_way=modified_way,modified_relation=modified_relation,
deleted_node=deleted_node,deleted_way=deleted_way,deleted_relation=deleted_relation)
db.session.add(data)
db.session.commit()
sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such table:
I'm sure I have the table because I created it in pgadmin. and the rest of my connections to the database work, post and get for querying data, but for inserting data it doesn't see the table. Any hints?
@dull scarab
>>> cur.execute("CREATE TABLE test (x UNIQUE)")
<sqlite3.Cursor object at 0x1022d4ab0>
>>> c.commit()
>>> cur.execute("INSERT INTO test VALUES (?)", (1,))
<sqlite3.Cursor object at 0x1022d4ab0>
>>> cur.execute("INSERT INTO test VALUES (?)", (1,))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
sqlite3.IntegrityError: UNIQUE constraint failed: test.x
thinking about schema design for my discord bot that tracks results of games and shows leaderboards. right now it only supports games with two equal sides. trying to figure out a schema that would make sense to allow more formats (1v2, 1v1v1, 2v2v2, etc)
i have a database with tables students and lessons. Each lesson has multiple students. But each student has multiple lessons. Is that many to many?
ok ty
I would say each lesson belongs to many students
It’s different than each lesson have many students to me
How would you handle a student with 2 lessons then? If you're referring to lessons from users
🤔
any chance someone has an idea on what I might be doing wrong, pasted my issue yesterday a few scrolls up , if you need me to give you more information let me know, thanks
Try creating the table programmatically to see if its the db connection or login? ( I dont know anything about sql alchemy just trouble shooting )
The thing is that the table is already created- I created it manually from pgadmin, and if I rewrite the code in order to query my table, it return the values
I just can't seem to figure out how to insert data into the table, even the interpreted query is ok :
[SQL: 'INSERT INTO changeset_details (id, created_node, created_way, created_relation, modified_node, modified_way, modified_relation, deleted_node, deleted_way, deleted_relation) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)'] [parameters: (62449687, 5, 1, 0, 0, 4, 0, 0, 0, 0)]
app = Flask(__name__)
app.secret_key = 'SHH!'
engine = create_engine("postgres://user:password@ip/osm-changesets")
session_factory = sessionmaker(bind=engine)
session = flask_scoped_session(session_factory, app)
db = SQLAlchemy(app)
Base = declarative_base()
class changeset_detailss(Base):
__tablename__ = 'changeset_details'
id = db.Column(db.Integer, primary_key=True)
created_node =db.Column(db.Integer)
created_way = db.Column(db.Integer)
created_relation = db.Column(db.Integer)
modified_node = db.Column(db.Integer)
modified_way = db.Column(db.Integer)
modified_relation = db.Column(db.Integer)
deleted_node = db.Column(db.Integer)
deleted_way = db.Column(db.Integer)
deleted_relation = db.Column(db.Integer)
if __name__ == '__main__':
db.create_all()
app.run(debug=True)
It seems to want to use sqlite, which may be why?
The engine is defined as postgres, I don't know why the error throws (sqlite3.OperationalError)
@dull scarab I managed to figure it out, you lead me in the right direction, thanks a lot
I had a warning that I kept ignoring UserWarning: SQLALCHEMY_DATABASE_URI not set. Defaulting to "sqlite:///:memory:".
and since I don't fully understand what and how you define connections with flask, and sqlachemy I commented one of the lines that was setting the database uri
app = Flask(__name__)
app.secret_key = 'SHH!'
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgres://user:pass@ip/database'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
engine = create_engine('postgres://postgres://user:pass@ip/database')
session = scoped_session(scoped_session(sessionmaker(autocommit=False,autoflush=False, bind=engine)), app)
db = SQLAlchemy(app)
Base = declarative_base()
i'm still not sure if this is the right way to do it, but it works
glad it worked out at least ¯_(ツ)_/¯
I have a follow-up question. I have a table that I'm getting values from, and gonna use those values later on in a for loop and process them , results will be sent to a new table.
but the table I am getting the values from gets updated every 5 minutes. Question: how would I go about creating a mechanism so that my loop is never ending and checks for new values in the table
Get the values when you process them instead
and once i process all values from my table - the for loop exists, but in the meantime i have updates in my table and get new values, how do i make sure my loop starts again
also make sure the isolation level of your database is read repeated or higher
Since read commited or lower could lead to phantom reads
a url shortening app
which kind of db will be preferable sql or no-sql?
app supports analytics as well
sql probably
because?
what would you need a nosql db for?
you've got a code, a target link, and visitor data
easy schema
sql generally ensures faster operation and data safety
hmm.. ok
visitor data can be concise or detailed based on what all is intended to collect
in that case it wlll be feasible to store such info in separate table
and relate data with parent url
basically a one to many relation between url and visit data, where each row will define a click
will it not be slower when such rows count to thousands or million perhaps..
?
on the contrary
if such data is stored under url in nosql
we need not bother about bulky joins or associativity between tables
what is your viewpoint on this?
uhhh
thousands or millions isnt a big deal to a good sql database
how would nosql be faster
I have a question regarding #announcements where the site is being ported from RethinkDB to PostgreSQL. Is this just a matter of preference because one is document based?
Rethink dB is shutting down
oh wow
yo - this line of code works
c.execute("SELECT * FROM students WHERE username=:username",{"username":username})
but this one doesnt
c.execute("SELECT * FROM :table WHERE username=:username",{"table":table,"username":username}) where table = "students"
anyone know a fix? The error is Traceback (most recent call last): File "D:\School Database\sql stuff.py", line 91, in <module> createuser() File "D:\School Database\sql stuff.py", line 78, in createuser c.execute("SELECT * FROM :table WHERE username=:username",{"table":table,"username":username}) sqlite3.OperationalError: near ":table": syntax error
iirc you can't use preparedstatements to insert tables (or columns for that matter)
aight so any idea what to do?
~shudders~ string formatting it
But ideally your structure shouldnt need to have dynamic tables
floppy if your free could you help out in #help-coconut ?
If you have a small set of tables, just make one statement per table.
And if the username is identical across tables, maybe consider using joins.
sqlite = small db
postgres = big db
how small is small and how big is big?
re. using with discord bot
There's a many factors to play in tbh
quick, dirty and simple to setup would be sqlite
sqlite can get really big, sort of
But it is limited when it comes to multithreading
And performance, of course.
yup, using sqlite atm but just using sqlite package and having blocking troubles. so while im gonna be changing code to something async-sqlite (aiosqlite?) wondering if worth it to go postgres
Which is why it works for smaller amount of guilds
And you should be using aiosqlite with d.py
i think i worked that out the hard way
If you you have a lot of db traffic from events / commands, like 1000+ members etc i'd make the jump to postgres before the transfer becomes too much work
not rly that scale, so might just stick with sqlite/move to aiosqlite 👌
For sure make the jump to aiosqlite
thanks!
@analog spruce take that spam somewhere else
Any idea why PyCharm will tell me access denied when trying to connect to a local sqlite database? I can view it in SQLStudio and connect to it like normal, but not in PyCharm
nvm adding it and deleting it a 4th time working for some reason
I have this string 2018-06-02T22:51:28.209Z as a timestamp.
How can I format it to match a SQL datetime format ?
hi
@brave grotto you can make a datetime.datetime object using datetime.strptime(...). relevant documentation:
https://docs.python.org/3/library/datetime.html#datetime.datetime.strptime
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
strftime.org too
thx 😃
Hey, is it okay to duplicate question from "Python Help" channel here?
is the question is relevant then yes I think
if you asked it earlier with no response then yes, you may.
just don't post it in more than one channel at once, of course.
I have a dataframe, in which one columns consists of scipy objects. My goal is to evaluate this object (spline) at corresponding 'splice' value.
My function looks like this:
def EvaluateSplineDistance(h):
b = h['splice']
a = h[0]
q =a(b)
return q
result2 = result.apply(EvaluateSplineDistance)
i get this error instead:
TypeError: 'InterpolatedUnivariateSpline' object is not subscriptable
this is how it looks
Here is a screenshot of my database
here is a look at my sql query
and here is the error i'm getting
Send help plz
Abolah no comprendo the problem
does it work if you directly execute the sql on the db
In a SQLite dB of 2 columns - one an int and the other a list that’s been str()d. What’s the most efficient way to select all rows a that has an element i in its list
@dusky owl a simple select a where b = i?
@brave grotto i can only see the first part in your screenshot
@dusky owl make sure you have an index on b if you need to do that often
cursor.execute( 'INSERT INTO CMC_COINS values (id_coin, coin_name, ticker, cmc_rank, btc_price, btc_volume, btc_percent_change_1h, btc_percent_change_24h, btc_percent_change_7d, usd_price, usd_volume, usd_percent_change_1h, usd_percent_change_24h, usd_percent_change_7d, eur_price, eur_volume, eur_percent_change_1h, eur_percent_change_24h, eur_percent_change_7d, last_updated)', (id, name, ticker, cmc_rank, btc_price, btc_volume, btc_percent_change_1h, btc_percent_change_24h, btc_percent_change_7d, usd_price, usd_volume, usd_percent_change_1h, usd_percent_change_24h, usd_percent_change_7d, eur_price, eur_volume, eur_percent_change_1h, eur_percent_change_24h, eur_percent_change_7d, updated))
Grote that won’t work because b is like [1,2,3,4,5] and id only be passing it like select a from table where b contains 5
Or something like that
they are not in the same table?
I need to known more about what your db looks like
yeah that was to clay 😛
oh sorry
@brave grotto did you select the right db when connecting?
yep
Can you try and select * from the table
I have only one DB
let me try this
The query is executed properly
when doing the SELECT *
Row A: Row B:
1 [3,4,6, 9, 14, 19]
2 [43,221,442,5523,32]
3 [1,2,3,453,23432412,3642565]
4 [534,234234,2432316756,3242]
looking for like select Row_A from Table where B contains X
but i'd only be passing in like 4 to return row 1 because it has 4 in it, or if i passed in 3 i'd get 1 and 3 back
id_coin is UNIQUE and NOT NULL
I'm not passing a list in, just a single element that may or may not be in each rows list
SELECT a where x in b
oh word i didn't realize in was a SQL keyword
eventually gonna move this to Neo4J but was just scraping everything first
i read that the wrong way around :/
that lets you check if a value in the database is one of multiple values
what data type is B
a JSON'd list
In the code where you connect with python, do you select the right db, use the right password and username?
is it for me ?
if yes. I do select the right file named database.db and there is no username/password
the proof is that the SELECT * from CMC_COINS query works
@dusky owl the proper way to do this would be one row per list element
depending on the contents, of course
so its a string
and I just needed it to store everything one time to move to neo
Oh so id have like
1 3
1 4
1 6
1 9
1 14
etc?
what sql version do you use
yeah
sqlite has an instr function
you could just write up a script to change it to that format 😄
I guess that'd probably take just as long as selecting everything the first time though
since I was just using sqlite as a temp place to move to neo
how much data is it?
you can't index a instr though
should be fast enough
@brave grotto since the query works when you do it directly i suspect the error lies elsewhere
i dont think string searching is reliable
What if you search for 5 and have 15 in the list?
best would be to transform the db to the format volcyy suggested
great, what was it?
I have no fucking clue
but instead of specifying the column names
I put ?
and it worked
@nova hawk
How do I store the output of a Select query in a var ?
I want to store a row from the db above in a var
the type does not matter
You use an sql query and it will return a tuple of the values
Is there a way to link a set of questions and answers to a database e.g SqlAlchemy
Yes
I have a flaks app connected to a postgresql db.
I'm quering a table that returns values that need to be processed with the GetChangeset()
The table I'm getting my values from gets updated every 5 minutes. What I would like to do is keep processing those values as they are being added.
I thought of putting it in an infite loop so it would try to fetch the new results every 5 minutes ( i realize this is quite some bad code), but with this approach my app doesn't even start because it never gets out of that while.
What other solutions should i search for ?
while True:
GetChangeset()
time.sleep(300)
if __name__ == '__main__':
db.create_all()
app.run(host= '10.230.2.56',port=5010)
You could use an ORM solution that automatically syncs
To use the loop approach you'd need to use multi threading to create a worker that runs said loop. And also knows how to terminate when the program quits. It's a good exercise to learn threading. But if you just want a canned solution, try something like apscheduler https://github.com/agronholm/apscheduler

GitHub
Task scheduling library for Python. Contribute to agronholm/apscheduler development by creating an account on GitHub.
@wispy fable is there any resources that i can read up on that show how to do this or talk about it?
Have you read the docs yet?
As far as I know, there are multiple ways to accomplish what you asked for.
If you're unsure or you've never worked with databases or any other type of data storage (json, csv, xml, etc.), then I would recommend testing your solution with json, then use sqlalchemy once you're certain thet you know what you want.
Also, if you have zero experience with SLQ and this is a personal project, then I would recommend using sqlite3, as it is more simple to use (and included with the current standard library)
How can I get something like .index() in SQL?
I am trying to make a top by an ORDER
@hasty hinge what‘s your use case?
I have a basic knowledge of sql and databases and I need some guidance
if my discord bot is going to run across thousands of servers, and each server is supposed to have its own server-specific settings, economy, and leveling system that is server-specific, not global, how will i organize all of the data?
i guess the server settings could be stored by just making a row with the guild id with multiple columns for the settings, but what about the lvling system? should i make a json file for each guild id and its member list and exp values or is that inefficient to be opening thousands of json files every second?
I'd say 2 tables, one for guild stuff like configs etc
and one for members with their id+guildid as a toupled primary key to have multiple entries for each user pr guild their in @tired sigil
Then, if you need more detailed stuff create new tables which each guild or member row references
@tired sigil
users, servers, users_to_servers, economy_data, users_to_economy_data, servers_to_economy_data
Main point is at least to plan ahead, if your bot is going to get other features later down the line, plan ahead so all your tables make sense for such
you can structure it so that users are linked to specific data for specic servers, and you can calculate the economies per server
or go the relational path like Clueless is referencing
Personally just keep my tables simple when i do d.py bots, probably out of habit
combining id and guildid for primary key is a good idea i was probably gonna do something dumb like make 3 columns
whily I'm aware of some basic theory around SQL databases, i'm not experienced in implementing them yet, so my suggestion should carry little weight
organization is always key though I think
but yeah, userid-guildid pairs is my go to for different rows pr guild
for each user
so i have one more basic question, if certain settings are optional, like a leveling system, do i really have to query during every message event
to check if that server has say leveling enabled or not
maybe its not a big deal idk but it seems like a lot of constant queries for repeated checks
Keep it cached, load it when you start the bot and update cache + db as needed
for some reason import rethinkdb as r bot.conn = r.connect(db="appbot") the r.connect() keeps raising this error: ```py
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 359, in recvall
chunk = self._socket.recv(length - len(res))
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "appbotdev.py", line 31, in <module>
bot.conn = r.connect(db="appbot").repl()
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 661, in connect
return conn.reconnect(timeout=timeout)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 572, in reconnect
return self._instance.connect(timeout)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 430, in connect
self._socket = SocketWrapper(self, timeout)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 318, in init
char = self.recvall(1, deadline)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rethinkdb/net.py", line 365, in recvall
raise ReqlTimeoutError(self.host, self.port)
rethinkdb.errors.ReqlTimeoutError: Could not connect to localhost:28015, operation timed out.
what's happening here?
It's timing out
how do i solve this issue?
is rethink running?
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rethinkdb 6285 Joshua 44u IPv4 0xf9e1a0f9174d6d07 0t0 TCP localhost:28015 (LISTEN)
rethinkdb 6285 Joshua 45u IPv6 0xf9e1a0f910196a87 0t0 TCP localhost:28015 (LISTEN)
yes
haven't found anything online that helps
do your rethink logs reveal anything useful?
how do i check that?
You have to specify the IP
what
hmm, i've never needed that
but i'll try
nope same error
damnit dude i can never get things done because stupid errors like these just randomly appear
What's a good place for an experience python programmer to learn about SQL databasing?
I've started playing with ORMs like sqlalchemy, but I'm not sure how to make proper relatioships.
You should probably start by learning the underlying concepts and raw SQL if you're not already comfortable with it
SoloLearn as a decent but short course on SQL that will help with some of the basics and syntax
@hollow tiger what happens if you run telnet localhost:28015
what is best way to connect to postgres with python?
connecting to PostgresSQL localhost 127.0.0.1:5432 via terminal is the following supposed to work? psql -U username --password password
Hello! I am building a product categorization system using Flask + SQLAlchemy.
I need to download every few days a large JSON file from an external server, that has over 150.000 categories information, and sync it to my DB.
The script tat does it is very simple but it takes a long time to complete the operation. It starts fast but later it becomes too slow for some reason.
It takes over an hour to update everything, so I was wondering if there's a better way to bulk insert/merge a large dataset into the database.
I don't have many experience with databases so what I'm doing is probably a bad idea.
For now I download the JSON file, loads it to a dictionary and iterate through the items. Each iteration I'm merging and committing it to the database.
Any ideas?
@west lark store/cache a value that tells when the database was last downloaded
last_download_successful = datetime 3 days ago
last_download_failed = datetime 1 hour ago
every hour
if last_download_successful > 1 day and last_download_failed > 1 hour:
download()
Can I fetch (asyncpg) without client?
client = SquanchyBot(command_prefix=commands.when_mentioned_or(prefix))
client.remove_command('help')
data = await client.c.fetch("SELECT * From config")
async def prefix(client, message):
try:
if data[message.guild.id]["prefix"] is None:
return "!"
else:
return data[message.guild.id]["prefix"]
except KeyError:
return "!"```
Because it doesn't work like that..@uncut laurel That isn't my problem - if I understood you correctly. I don't need to automate it. What I would like to know if there is a better way to insert into the database a large data set, other than looping through it.
Each category is a flask model
Hi guys, i'm currently using Google sheets to keep a track of my current PC hardware, i have motherboard, cpu e.t.c on seperate sheets but i'm trying to find a way how to have a main hub so i can just enter data into that and it'll input it into the sheet. is there anyway i can do that? i know it can be done on excel but idk about this - please tag
„is there anyway i can do that“, yes, computers can do anything if you work at it hard enough
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
you gotta be more specific
Well idek what else to say? All I want to do is have a main sheet which I can enter any data In and it redirect into that specific sheet
why do you use multiple sheets instead of a table where each row corresponds to a system?
you can use openpyxl, you can use the .active to change current sheet
for sheet_index in range(0, len(wb.sheetnames)):
wb._active_sheet_index = sheet_index
ws = wb.active
for x in ws.iter_cols():
if x[1].value is not None:
heads.append(str(x[1].value))```a small sample but you can tweek it as you like
but you'll have to work around a custom appliction for it
maybe use tkinter
I am doing my first Django project, I need to select a database engine. It needs to be relational database, size is going to be around 500 tables and a couple of million entries. Im thinking about PostgreSQL. I have limited experience with postgresql and mongodb, I have used MySQL some and have mainly worked with MSSQL.
any thoughts on what is best practice?
It might be more a Django question then database question.
If you want to use a relational, SQL database I'd definitely recommend Postgres, if not only because it's free with no restrictive licensing
may i know whats wrong
how can i fix this sir
allow access to the database file
but i dont know how this is new for me
i dont know either
do some research on your tool. see if you can figure out how to open a database
working on it
you don't have permissions to create that file there in the os?
If I have this data:
https://b1nzy-banned.me/lfuK2.png
Is there any way with rethinkdb to sort it by total_xp but also be able to access the id?
{kind=link}

!t ask Hello, I am doing a project here I am saving the IPs of the visitors and their time offset in a table called "date". I am trying to a query in flask, passing it to SQLite3 . This is the code I am using:
Idb.execute("INSERT INTO time (ip, offset) VALUES (:clientIP, :offset) ON CONFLICT(ip) DO UPDATE SET offset = :offset ;", clientIP = clientIP, offset = offset).
The resulting query is: INSERT INTO time (ip, offset) VALUES ('10.240.0.222', '180') ON CONFLICT(ip) DO UPDATE SET offset = '180' ;
However, it is failing... I have tried different versions and looked for information. In this query I am following the official documentation: https://www.sqlite.org/lang_UPSERT.html
Can anyone give me a tip? 😄
Hello, I am doing a data analysis assignment using python. I need help analyzing a hurricane dataset, if anyone can help me with the last two problems that would be great. This is my first course using Python and I am kind of new to this language. Thank you
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
@torn sphinx
I cannot stress enough how much better suited #data-science-and-ml and the people that browse it would be to this question
Oh sorry, I didn't realize I posted it in this channel again.
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
Well I have a database of timeseries data associated with values. The timeseries data captures samples every few minutes or so and I want to produce, some kind of chart of sliding window average, minimum, and maximum but using the SQL engine .
So I'm looking to learn to do a basic SQL query which can meaningfully group that data, since it has been so long since I did SQL 😦 Nearly a year.
So a result might be.
Max Min Avg FiveMinIntervals
10 1 6.90 1995-01-01 00:05:00
10 2 7.15 1995-01-01 00:10:00
10 4 8.25 1995-01-01 00:15:00
I recognise there could be a problem of lossy data too
But before I take it any further ala https://popsql.io/learn-sql/postgresql/how-to-use-generate-series-to-avoid-gaps-in-data-in-postgresql/

PopSQL
If you’re grouping by time and you don’t want any gaps in your data, PostgreSQL’s generate_series can help. The function wants three arguments: start, stop, and interval:
select generate_series( date_trunc('hour', now()) - '1 day'::interval, -- start at one day ago, rou...
I'd rather get the basics right
something like sql SELECT Max, Min, Avg FROM table WHERE daterange('1995-01-01 0:0', '1995-01-01 0:20'); maybe?
Well the data is recorded in minute or even second intervals
but i'll be able to try it
once the data comes out of the boiling pot
extend the time part with ms as well, shouldnt break anything
Stack overflow has all these massive SQL queries
Quite surprised how succient that is
I'll investigate the daterange func too
Completely depends on what you need, stackoverflow will most likely provide a bunch of alternatives with pros and cons
Mmm I guess. I really need to improve my SQL so its better than basic
There was a time
Although I only ever used MySQL
actually, my example might not work 😅
SELECT Min, Max, Avg
FROM table
WHERE FiveMinIntervals >= '1995-01-01 0:0:0'
AND FiveMinIntervals < '1995-01-01 0:20:0'``` would be the more static way of doing itFive min intervals is only an example column
the data actually exists on a column timeseries
which is like
Huge
but yeah i understand that much
it's somehow getting it to aggregate and provide me results per aggregation which i find confusing to sort of think around
I haven't used daterange my self so can't really provide a working example of it 
mmm i'll try and make a fiddle
but non the less basic time < "yyyy-MM-dd HH:mm:ss" should suffice

So lets say I have something like this and I want to min/max/avg 30m intervals
That's probably clearer
CREATE TABLE conditions (
time timestamptz,
var float
);
INSERT INTO conditions VALUES ('2017-10-03 10:10:54+01', 43.4);
INSERT INTO conditions VALUES ('2017-10-03 10:13:54+01', 43.4);
INSERT INTO conditions VALUES ('2017-10-03 10:30:54+01', 43.4);
INSERT INTO conditions VALUES ('2017-10-03 10:40:54+01', 13.4);
INSERT INTO conditions VALUES ('2017-10-03 10:45:54+01', 33.4);
INSERT INTO conditions VALUES ('2017-10-03 10:56:54+01', 76.4);
INSERT INTO conditions VALUES ('2017-10-03 10:28:54+01', 43.4);
INSERT INTO conditions VALUES ('2017-10-03 11:30:54+01', 35.4);
INSERT INTO conditions VALUES ('2017-10-03 11:40:54+01', 63.4);
INSERT INTO conditions VALUES ('2017-10-03 11:45:54+01', 13.4);
INSERT INTO conditions VALUES ('2017-10-03 11:56:54+01', 33.4);
INSERT INTO conditions VALUES ('2017-10-03 11:28:54+01', 23.4);
INSERT INTO conditions VALUES ('2017-10-03 12:45:54+01', 13.4);
INSERT INTO conditions VALUES ('2017-10-03 12:56:54+01', 33.4);
INSERT INTO conditions VALUES ('2017-10-03 12:28:54+01', 23.4);
INSERT INTO conditions VALUES ('2017-10-03 12:45:54+01', 13.4);
INSERT INTO conditions VALUES ('2017-10-03 12:56:54+01', 33.4);
INSERT INTO conditions VALUES ('2017-10-03 12:28:54+01', 23.4);
incase the fiddle doesn't work
@woven crest Looks like you may benefit from InfluxDB. It's a time-series db built for realtime data manipulation and everything is based around timestamps
You would probably have to do the averages here yourself
I don't have that choice unfortunately 😦
Not my system.
I kind of want to do something like this but for every 3 hours http://sqlfiddle.com/#!17/3ccec/2
Hey guys. Can i have you opinion on something? At work we have a database administrated with alembic and we have a use case when we must have some data inserted in the database before making it available in production. The thing is my boss wanted to use alembic migration scripts to insert thoses data. And he wanted to make a revision for the table itself and an other for the data. I strongly belive that making one revision to create the table and the other to create the table's data is storngly wrong. What do you think about that ?
Is there a recommended lib for working with couchDB in Python?
Seems like no-one played with couchDB 😃
The only time i’ve ever seen couchDB is when I was looking through a comparison of databases to find one for my use case
Outside of that single instance never even heard of it 😂
hey there
well, the db is already here, I'm not the one who installed it, but maybe I can help
okay
so i installed from binaries
also installed with pip
and copied this form docs
couch = couchdb.Server()
db = couch.create('test')
doc = {'foo': 'bar'}
db.save(doc)
i'm getting an error
ConnectionRefusedError: [WinError 10061] No connection could be made because the target machine actively refused it
http://localhost:5984/_utils doesn't open either
so i installed fauxton with npm
and run it fauxton
now localhost:8000 opens but all pages are blank
and http://localhost:5984/_utils still doesn't work
any idea what i'm missing?
Maybe a firewall ? What does netstat tell you ?
no connection with ...:5984
you installed the library but is the server running?
and that does what?
seems like i got no error
but ...:5984 still won't open
@ionic pecan
`
Running "copy:dist" (copy) task
Running "copy:couchdb" (copy) task
Created 4 directories, copied 22 files
Done.
doesnt sound like its starting a server to me
how should i do that?
the official docs can probably explain that better than me -> http://docs.couchdb.org/en/stable/index.html
@ionic pecan there's no curl for windows...
oof
@rigid fable https://curl.haxx.se/windows/ is this what youre looking for?
@gilded narwhal i guess so thx
i get this
C:\Users\user>curl -v 127.0.0.1:5984
* Rebuilt URL to: 127.0.0.1:5984/
* Trying 127.0.0.1...
* TCP_NODELAY set
* connect to 127.0.0.1 port 5984 failed: Connection refused
* Failed to connect to 127.0.0.1 port 5984: Connection refused
* Closing connection 0
curl: (7) Failed to connect to 127.0.0.1 port 5984: Connection refused
do you access to its settings? you can probably configure it to allow that specific port
do you have*
anyone can help-me?
!t ask
ask
Asking good questions will yield a much higher chance of a quick response:
• Don't ask to ask your question, just go ahead and tell us your problem.
• Try to solve the problem on your own first, we're not going to write code for you.
• Show us the code you've tried and any errors or unexpected results it's giving
• Keep your patience while we're helping you.
You can find a much more detailed explanation on our website.
@gilded narwhal i added port 5984 to inbound and outbound rules but still getting the same error
then i have no idea im afraid
ok..
@waxen tartan pyinstaller
hello everyone. does anyone know of a place to lean about database creation. Such best practices, things you need to know to create a good long term database.
Use parameterized queries if you’re accepting direct input from a user in any way (NEVER trust the user), in general try to use the smallest datatype possible (so if you’re using single digit numbers, use TINYINT not INT), and look up primary and unique keys (but don’t use them unless you absolutely have to, cuz it slightly slows down inserts)
I don’t know of an actual place to learn stuff, other than just ask questions and look online :/
@full geyser Thanks this will help a lot.
np - also look into the different kinds of databases - like my bot uses MySQL for the SQL database, and then Redis as an in memory NoSQL database (but like REDIS is single threaded, so if you wanna use a NoSQL database, you might want to look into different options)
Fetchall from MYSQL DB. Getting a list with a tuple inside and then data in that.
What about it?
How can I grab it in a JSON format? @full geyser
Uhh don’t think u can? Unless you have a primary key or a unique key as one of the columns?
And even then I don’t think that’s something that MySQL does natively
It does have a json datatype tho (never used it tho)
Perhaps a more important question is, if you want it in a json format, perhaps a nosql database would be better suited to your needs? U seem to want a key value storage system rather than a relational database
(I’m pretty sure what i’ve said is correct but I don’t have much experience with databases outside of my bot)
Carrying over from other channel.
MySQL is wrong. PostgreSQL is right.
SQLite is right for small things.
Mongo
How is postgresql better than MySQL?
(Assuming you’re not a commercial business so u don’t need to buy a license from oracle)
- Its not MySQL
Es Que El or Sequel
Uber did a tech. post back in 2016 (https://eng.uber.com/mysql-migration/) about their migration to MySQL.

Uber Engineering Blog
Uber Engineering explains the technical reasoning behind its switch in database technologies, from Postgres to MySQL.
Also idk if other comparisons are like this, but I just read the top comparison on google - it tried to make out that postgres was way better, but basically said that MySQL can do all the stuff postgres can apart from nosql with the latest version on default settings
Also idk about postgres so can’t compare, but I found MySQL documentation to be REALLY good
mariadb
previously, a business I was involved with left mysql because they started legal actions that worried liability
I cannot speak on pros vs cons, they both seemed to work fine honestly
that's where mariadb comes in
(I side not including legal stuff regarding commercial licenses, although it is a fair point)
Speaking of nosql... this might need a detailed response, but I was looking into aerospike nosql
How is it that their service performs just as well on ssd as it does on ram? (According to their website)
Hey so I've got a SQL question for you guys. I'm using Python and PostgreSQL in a MUD game (multiplayer text game) that I'm developing and I'm new to the DB schema business. Right now everything is in memory and I'm converting the code to use a DB.
Let's take this code that returns a row with the player's username from the "players" table.:
cur.execute(SELECT player_id, name, inventory FROM players WHERE "name"="name"")
value = cur.fetchone()
Now how do I take that row that I've found, and return player_id, or name, or both, or any number of specific values from this row and use those values in my game? Let's say I have a function that checks if the inventory is None or not. Now that I have the row, how would I return that value back to the function that requested it?
Cur.execute returns a record which can be indexed like a dictionary (for most db I'm familiar with at least)
Wait no, that's fetchone.
Value[0] is player_id, 1 is name and 2 is inventory
In general print() stuff (or dir() stuff if it’s a class)
Easy way to find out what to do
AKCHUALLY everything is an object, so you can dir everything
Yeah but like str(“hi”) yay now ik I can use .upper and .lower like big whoop 😂
*dir(“hi”)
huh?
Doing dir() on non class stuff, or stuff like str (which is a class) doesn’t really teach u much lol
Nvm lol
dir(if) ha! not everything!!1
Doc:
docs Lookup documentation for Python symbols.
Information:
server Returns an embed full of
user Returns info about a user.
Reddit:
reddit View the top posts from various subreddits.
Site:
site Commands for getting info about our website.
Snakes:
snakes Commands from our first code jam.
Utils:
pep Fetches information about a PEP and sends it to the channel.
No Category:
help Shows this message.
Type !help command for more info on a command.
You can also type !help category for more info on a category.
![pep|get_pep|p] <pep_number>
Fetches information about a PEP and sends it to the channel.
Anyone know how to get the value of something in line?
say i have this table and i want to get all rows greater than the value of e
Something like nested queries. I havent done much of them myself but in general you query for the value of e, and use the result in a higher query looking for anything above it
@rustic yarrow
Yeah thanks I know how to do that the main problem is my query is 15 lines and I was hoping to not have to duplicate it.
Could probably generalise the query with placeholders, maybe?
I think there was a procedure option and alternatively dump it into a temporary DB
Problem is that procedures are not supported on SQLite that I am trying to use.
I'm looking for a free driver for ODBC to Active Directory, any ideas? Also, perhaps there's a sub-reddit that I could post to?
does anyone know how to calculate the difference in years between a time and the current time(now)? in sqlite
e.g. the years between 2001-04-18 00:00:00 and DATETIME('now')
class Product(Model):
id = Column(Integer, primary_key=True)
price = relationship('Price', uselist=False, back_populates='Product')
class Price(Model):
id = Column(Integer, primary_key=True)
price_history = Column(Json)
value = Column(Integer())
product_id = Column(Integer, ForeignKey('product.id')
product = db.relationship('Product', back_populates='price')
with app.app_context():
for _ in range(2):
id = 1
product = Product.query.get(id)
if product is None:
product = Product()
session.add(product)
session.flush()
Price = Price()
price.id = 2
price.value = 100.0
price.price_history = [{'date': utcnow(), 'price': 100.0}]
price.product_id = product.id
session.add(price)
session.commit()
else:
price = product.price
price.value = 200
print(price.price_history)
# output:
# [{'date': utcnow(), 'price': 100.0}]
price.price_history.append({'date': utcnow(), 'price': 200.0})
print(price.price_history)
# output:
# [{'date': '04-10-18', 'price': 100.0}, {'date': '5-10-18', 'price': 200.0}]
session.commit()
price = Price.query.get(2)
print(price.price_history)
# output:
# [{'date': utcnow(), 'price': 100.0}]
print(price.value)
# output:
# 200.0
# Changes not being commited to the price_history but being commited to price.value for some reason
oops.. SORRY!
I was trying to send it formatted, but just realized its gigantic..
Anyway. Its already here. Can someone explain why the price.value is being changed but not the appended parameter? I tried everything, merge/add to the session. Changing list to str and loading afterward. But nothing works. Only the value. SORRY AGAIN FOR THE SPAM
and btw, how can I send code formatted ?
Ok nvm, found a fix if anyone is wondering. Have to import "from sqlalchemy.orm.attributes import flag_modified" and use flag_modified(price, "price_history"). Sorry for the disturbance
Anyone on who is good with SQL database structures who I can DM? Python/sqlite3, but mostly about the sql side of things
Dont ask to ask. Just tell us your problem and whoever knows the answer will get back to you, also
!t no-dm
no-dm
Can I send you a private message?
No. We do not provide one-on-one tutoring - you can hire someone locally if you really need that. We also prefer that questions are answered in a public channel as it means that everyone else present is able to learn from them. If you're working with code that you are unable to disclose for any reason, you should try to make your question more general and write a separate, small piece of code to illustrate your problem.
Alright - I have a simple many-to-many relationship table that I'm trying to figure out how to optimize. Using one of the standard examples, I am trying to relate a student table to a classes table. From what I've read, these many to many tables generally rely on a unique entry, usually the rowID, and a third bridge/intermediate table to cross reference everything.
The trouble I'm having is that in my particular case, I need to search students by a text field (student_name), and classes by a text field (class_name). I've tried inserting each relationship (i.e. just creating the bridge table) and then indexing columns as needed, which seems space inefficient as the relationship table is now text-based (student_name:class_name). I can make the bridge table using rowIDs, but that seems to recommend INTEGER PRIMARY KEY as a constraint, which means that the text fields aren't indexed. I can index the text fields, but then I end up with student_name being in a table, and then its index is sort of duplicating those entries.
Anyway, I'm not sure what the best way to proceed is. I have ~10 billion entries for student_names and 5 billion are unique, so I am trying to be careful with space and time efficiency
From what I can tell, space-wise the best relationship would be: Student_Table:[Student_Name:student_id, ordered by student name for the B tree and student_ids generated somehow, rather than ordered by rowID], Classes_table:[class_name:classID, same constraint as student_table], and then students_classes[student_id:class_id] but I'm not sure how to get there since I need SQL to assign the IDs but index/order by the text
I'm not very knowledgeable about SQL, but how do you have 5 billion unique student names?
You would need some unique key in both. Class name+year for classes maybe, and studentid for students
Ok got an issue - I have a dynamic prefix (for bot) with a new list of prefixes for each server. What is the best way to store these prefixes - I'm using sqlite and tried that but quickly realised you cant put in and return a list (of prefixes). Is there a way to do this with sqlite or need I look elsewhere (json)? The amount of prefixes is not set either so having 4 dif cols isnt an option really
nvm im so dump just do select * and then delete guildid col from results
Have it be a prefix pr row
Guildid. | prefix
X. Y
X. Z
And just query all with that id, and build your list from that
legend. thanks!
@versed coyote because it's just an analogy, student_names are really DNA fragments
Context often makes quite a difference in how others can provide help
Hey what naming convention you guys use when dealing with SQLalchemy models? Is it best practice to use python naming convention or sql naming convention?
or should i use both? like student_id = Column("StudentId")
or tablename = 'Student' instead of the default 'student'
I'd follow the conventions of the database itself to name tables and fields
But inside python, with the ORM, of course I'd follow the standards and have snake_case for fields and TitleCase for model names
@rancid pier Thanks!
tl;dr depends on your backend but when in python, stay python 😊
@versed coyote it's probably not the names that are unique.
and honestly, on that scale, would you make relational names?
why store a guy's name 1000 times, wne you can just store an int
But what size of int :^)
well, I'd expect it to be like, 64 bit, 8 bytes
8bytes is better than whatever overhead per string you mght have for a name.
I need to kick my ass to learn sql relationships already
After using mongodb and elasticsearch for a long time, I don't want, ever, to use SQL again :p
Thats silly
why ?
Because they have different use cases
Its like saying you would write everything in one programming language
You can do relations with MongoDB too using references, so you can have a SQL-like hierarchical model (which can be useful sometimes if you reference a huge document which you don't want to be copied in every index referencing it), with the power of document-based NoSQL.
"power of nosql"
Why bother with NoSQL if you're just gonna emulate a sql database lmao
Certain operations are faster and others are slower
Indeed
Depends on the application, but in my case, I'd rather have a NoSQL database emulating some SQL-like relations (but really, I don't use them much, I usually just replicate the data) when it's absolutely needed and be able to perform very fast text-based search than having a SQL with dozens of pivot tables, performing slow searches and requiring 10-line queries. The sharding is also built-in, so I can span my database over different clusters, and I don't fear to lose my data if a server crashes
Yeah, the price for that is that migrations involving updating of entries is entirely up to the developer, but as far as I'm concerned, that's 100% worth it
But well, when I have to work with purely relational data, I use Postgres 😉
Best way to split up an imported mysql database into variables?
^ please elaborate
some examples would be nice, yeah.
@torn sphinx
be able to perform very fast text-based search than having a SQL with dozens of pivot tables, performing slow searches and requiring 10-line queries
suggests you really struggle with db table design and organization
and if you can't get away from that kind of structure, ehh
nosql has its place, so do rdbms
but have to say, when someone talks about replicating sql functionality in nosql because its the new hotness, that's giving the impression that someone doesn't know what they're talking about
Or maybe it means you never worked application large enough to face this kind of problem. About the "new hotness" of nosql, it's hot only for those who read tech news and barely work with SQL in general, as far as I'm concerned I started nosql with mumps, 20 years ago : nothing new, nothing hot.
And I'm not replacing SQL functionalities in NoSQL, I just said that sometimes and in very specific cases (because it's slow), I'll reference an object instead of embedding it because it's really too large. Passing by reference instead of value, that's not "replicating SQL"
Hey guys, new with database and would require some assistance. I am querying the created table for certain key...however if the key is not found no response is returned.
Sqlite3
How can this check be done
for row in cursor.execute('SELECT * FROM table WHERE id = ?', user_id):```if user_id is in the database it returns data just fine
however nothing is returned if no such user_id registered
what are you trying to do @pallid zinc ?
I'm making a login with python and it is getting the data from the MySQL database. What is the best way of searching the username and password columns for the values? There will be no GUI.
I'll attach a screenshot of the database now
you check if the user is in the database and that the password is identical
do not share passwords
They're made up passwords.