#databases
1 messages · Page 11 of 1
sure
you could also write an SQL query that does the string matching for you too
https://sqlite.org/lang_expr.html#like
im not sure if this will work

you only need to execute your select statement once

the select statement you execute once, but fetchone() you have to keep calling
e.g. py cursor = db.execute('...') row = cursor.fetchone() while row is not None: # append to your list, then retrieve the next row: row = cursor.fetchone()
This now works, thank you very much
can someone help me with this? when i try to add for example "La tierra pesa 9.8tons" it only adds "La", there is the code i use


seems like a discord.py-related issue you're having (more specifically your curiosidad parameter isnt capturing more than one word), but as a sidenote please dont use string-formatting to insert values like that
!sql-f-string
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
thank u bro
Hello, I’m new (also at programming ) so sorry if I ask in the wrong spot, I have a json dataset can someone help me here or is there a specific section ? I’m trying to convert it but I have some troubles, thank you!
Best to see #? and grab a channel and ask your question there as json isn't database related.
Thank you !
hi i'd like to ask something about foreign keys in mysql and why do i generate this error?
1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`studendiri_db`.`s_print`, CONSTRAINT `con_service_code_print` FOREIGN KEY (`service_code`) REFERENCES `services` (`service_code`) ON UPDATE CASCADE)
This is my code for executing and adding values
def add_service(service_name):
try:
cur = mysql.connection.cursor()
# Retrieve the maximum value of the service_code column
cur.execute("SELECT MAX(service_code) FROM services")
result = cur.fetchone()
max_service_code = result[0]
# Extract the number part from the maximum service code
# and increment it by 1
if max_service_code:
number_part = int(max_service_code.split("SCSD")[1]) + 1
else:
# If the services table is empty, start the service code from 1
number_part = 1
# Generate the new service code
service_code = "SCSD" + str(number_part).zfill(4)
# Generate the service_name
service_name = f"SF{service_name}"
cur.execute(f''' INSERT INTO `services`
(`service_code`, `service_name`)
VALUES ('{service_code}', '{service_name}')''')
mysql.connection.commit()
print("SERVICES ADDED")
return {
'code': 1,
'message': 'SERVICES Added' }
except Exception as e:
print(e)
return {
'code': -1,
'message': f'{e}'
}```can anyone help with mongodb please
- I have a mysql local instance running on my laptop A,
- I created a user accessible from any % host with full admin privileges,
- I tried to connect to a database in this server from another laptop B
mydb = mysql.connector.connect(host="laptop A ip4 address", user="username", passwd="password",
database="database name")```
* Laptop B returns error
```2003 (HYOOO): can't connect to MYSQL server on "laptop A ip4 address"```
Does anyone know what caused the error?
I tried adding a new firewall rule for the 3306 port but it doesn't work either
Thanks!In my collection i have three values. User1, User2, Love. I want to find the document and the amount of love from the first two values. Mongodb btw
How would i do that query
Well first of all that's not ideal for MongoDB as it seems to be relational data. I'm not sure why you separated it like that. Why not simply make two collections, Users and Love - and then make documents in Love like this?
{
"user1": "John",
"user2": "Mary",
"love": ".80"
}```Or you could even make it into a single collection with the users being like
{
"name": "John",
"love": {
"Mary": .8,
"Ann": .3
}
}
Yeah but this would need more entries or slower searching
Cuz then you cant find values for Mary. If you want to, you would need a separate entry for Mary and her values with other people
Which is redundant
You could write the same value to both documents, redundancy isn't as important as in SQL - searching for three collections would be worse. But yes, Mongo isn't great for data relationships https://www.mongodb.com/docs/manual/applications/data-models-relationships/

Hello everyone,
I'm starting a new internship in webscraping (I hope it's the right place to ask my question). My boss is asking for me to collect data from one website selling luxury goods for cats and dogs using Octoparse. For some reason, the software doesn't work for me and I'm using Beautiful Soup instead. The fact is, in the data he needs is the availability of the items but I won't be able to collect this information via the HTML which is what I'm doing to collect the other infos. Do you guys have a suggestion for me/ any advice?
Thanks
Not sure what you mean by "I won't be able to collect this information via the HTML" but if the data is not displayed in your browser or in the source code then it's not scrapable. If the problem is that the page is not getting fully loaded into BS4 due to scripting, you may need to use Selenium
So wait, if I use BS4, I can get more than the HTML content?
I finally managed to use Octoparse but I'm still interested
No, but if you're using a simple request on a page that requires Javascript to fully load, then you're not loading all the data that would normally be visible in a browser. Selenium emulates a normal web browser so you can (hopefully) access whatever is visible to a normal human user.
Amazing, thank you so much
I use postgresql (older version for now). I also have a way for students to enter data (name, address, etc...). One of the fields that the student has access to is the comment field. It has a data type of 'text'. Here is the issue - I ran into an issue when a student entered a emoji (a 'rocket ship') at the end of their comment. I normally use dbeaver or PgAdmin for my database manager. But either of the two displayed the 'rocket ship' when I reviewed the data that was contained in the comment field. So does anyone know how I might have found the 'rocket ship' - using some tool/s? It took a very long time for me to find the 'rocket ship'. But by chance I pasted the comment in a browser and then I saw the 'rocket ship'. It would be nice if the tool was written in python. Thanks
I'm not sure but if it's the unicode emoji it's just like any other character: ... where comment like '%🚀%'
Using a postgresql database configured to use windows 1592 (not sure if the codecs is the right number) which I believe is normal for windows. The 'rocket ship' appears as a 4 byte char. But neither pgadmin4 or dbeaver (latest version) were displaying the emoji when I made a query. So I'm looking for a tool that would display the emoji.
Sorry, I'm not using any of that. Can you switch to UTF-8? And doesn't pgAdmin run in a browser?
is there someone here that has used Prisma in python?
could someone be kind enough to tell me how can I delete all the rows where certain column has the number smaller than x?
so for example
value
row1 10
row2 20
row3 30
row4 5
so for example:
delete row's where value < 15
I'm doing this DELETE FROM BackTest WHERE net_profit < 0 but it seems like everything is being deleted
hey
Looks good to me. If everything was deleted than every net_profit was below zero.
is there a way for row of a table to be automatically be adjusted like this
suppose
1 abc
2 def
3 ghi
and we delete the second row, and the above table becomes
1 abc
2 ghi
the adjustment is made automatically, how can that be done?
Depending what kind of database, you can look at a trigger, but I wouldn't recommend it as this seems really messy, especially if that number is the index of the row. What are you actually trying to accomplish?
Depending what kind of database, you can look at a trigger
sqlite.
What are you actually trying to accomplish?
A grocery list where the indexes are automatically adjusted when an item is purchased.
Sqlite supports triggers: https://www.sqlitetutorial.net/sqlite-trigger/
But why would you want to keep messing with the indexes? Why is it a problem to just leave the gaps?

This tutorial discusses SQLite trigger, which is a database object that is fired implicitly when data in a table is changed.
Suppose the grocery list is
1) apples
2) bananas
3) orange
and the user brought bananas, then I think the grocery list is better represented as
1) apples
2) orange
than
1) apples
3) orange
any offers where to learn SQL?
That's not a problem. You can display the appropriate numbers at runtime, leave your database alone. Or if you really want to keep a separate sequence column in the database you can do that, and update it with your application logic, not with a DB trigger.
Hmm, that makes sense. Thanks!
To explain a little further "why", you don't want to mess with indexes because other tables may be referencing those indexes. It's normal practice to just let them have gaps when items are deleted.
There are endless options, I personally like interactive tutorials like DataCamp and DataQuest
hey yall, i have a mysql-python assignment to do, and im having trouble connecting the database using mysql.connector, is it ok if i ask questions pertaining to this issue?
Could help me to try and help you, as I am going down this path myself as well. Was able to get a query to execute. Feel free to reach out!
hay how to use cassandra.cqlengine.models
Would anyone know how to make this hack work for more than 1 level? I am trying to remove duplicates post-groupby on 3 levels, so something like this:
bbb 1
bb aaa 1
B aa aaa 1
1
bb bbb
c aa aaa
bb bbb 1```
https://stackoverflow.com/questions/64797580/pandas-groupby-remove-duplicates/64797686#64797686
Stack Overflow
input: (CSV file)
name subject internal_1_marks internal_2_marks final_marks
abc python 45 50 47
pqr java 45 46 ...
why does this render an error?

ah it should have been NULL instead of 'None'
Good evening/morning/afternoon, quick question:
Is it good practice to save datetime values in an aiosqlite database as text? Searching through Google told me that aiosqlite doesn't have a datetime or timestamp data type, so I'm thinking I'll just save it as text? I'm specifically using aiosqlite instead of sqlite3
and the previous response:
the sqlite3 module supports converters/adapters for custom types (and it seems aiosqlite provides the same functions) so you can just write your own to handle automatically parsing DATETIME/TIMESTAMP columns for you
https://docs.python.org/3.12/library/sqlite3.html#how-to-adapt-custom-python-types-to-sqlite-values
to clarify, sqlite is dynamically typed so you can write whatever you want as the column type, and python's module provides a way of automatically parsing those column types for you
What I'm understanding from this is I can save as text, and then when I pull the data I can then manipulate it/cast it/whatever into what I want?
yup
thats what the built-in converters for datetime do, but unfortunately they have a few annoying bugs with them
Awesome. That's the plan then. Thank you very much!
particularly with how timezones and microseconds are handled, which is why in the link if you scroll down you'll see a recipe for defining your own datetime converters
Why do i get a ''Station' object has no attribute 'id' when i try to bulk_create the objects? I know for sure i have one pk and weirdly, sometimes this works and sometimes it says this message
....
try:
obj = Station(
station_id=row['ID'], # This is set as the Station primary key
fid=row['\ufeffFID'],
name_eng=row['Name'],
address=row['Address'],
....
)
# If station is found in the db, skip to the next iteration
if Station.objects.filter(station_id=obj.station_id).exists():
print("Station already exists")
continue
# Add the object to the list
object_list.append(obj)
# Chunk create checks if there are 100 Journey-objects, if so, creates them and initializes the list
if upload_type == 'chunk_create':
if len(object_list) >= 100:
Journey.objects.bulk_create(object_list)
object_list = []
print("Station created!")
except ValueError as e:
print(f"Value error in row {i+1}! ", e)```context, i'm iterating a CSV file and creating objects from field data
i have no idea what you're using and a full traceback would be more helpful, but as an uneducated guess, perhaps the error is because your attribute is named station_id and not the id bulk_create() was expecting?
@left badger I saw y'alls coversation in #discord-bots and came here to offer my 2c:
If you're okay with a bit more of a crude approach but more simplicitly, you can simply use .strftime() to write it as a string to your database and .strptime() to read from it.
it's not really bad practice because programs like Prisma do this very same thing
yeah sorry i tried to keep it short .. but you mean 'bulk_create()' expects the objects within the list to call their primary key field 'id' instead of 'station_id' ? can i solve this problem somehow?
yeah, it seems you need both to agree on the same attribute/column name
ah... well that's annoying.. i guess i will have to just call the objects primary key 'id' so bulk_create understands i have a pk
thanks
I'm going to look into this too. Thanks!
hey folks, i'm tryna use flask_sqlalchemy, and i wanna use an array of objects to filter the queries, but i keep looking online and can't find anything, what can i do to achieve this?
for example:
my JSON would be ```
{
"brand":["one", "two"]
}
and i want to take the brand variable and filter for those results from the dbbut when i just put .filter_by(json["brand"]) it doesn't work
You should be able to use something like in_(json["brand"])see https://docs.sqlalchemy.org/en/14/core/sqlelement.html#sqlalchemy.sql.expression.ColumnOperators.in_
helped, thanks tons
can someone correct me if my understanding of this is incorrect?
I have a fully managed db and app communicating with each other. I have a ssl cert for my flask app and so does that mean the communication between my app and db is encrypted and I don't have to worry about anyone getting the data when travelling to the db or from?
since i have the ssl cert
No
you need to specify a separate encryption scheme for the database
your TLS certificate only affects http traffic between end users and your flask app
but in all likelyhood your db provider already has an encrypted connection
your https connections will be encrypted using your CA cert
I don't know exactly how your database is configured so I can't know for sure, but the connection that Python opens to your database is most likely already encrypted by other means
the https certificate and the database connection are completely unrelated
ah okay, thank you for the clarification
Hi all. I am setting up a daily import to a Postgres-database. I'm importing a txt-file into Pandas and then uploading it. My table has the following types: int, text, float, bool and date.
However, some dates are just YYYY, some are YYYYMM and others are the full YYYYMMDD. I also have boolean columns that appear as Y, N or "nan" (in Pandas). I have made converters for the latter, but conversion to datetime for the former is a hit or miss.
Pandas is just a "step on the way", I don't really need to work with it here.
I'm considering just saving the dates that will not be used for queries (like more than once a year) as ints.
Thoughts?
You could create a list of valid date formats and try parsing it 🤔
but if you're getting that data from your own system/app maybe fix it there instead?
Unfortunately I'm getting it from an external source - I've asked to clarify if they store bools as "Y" and "N", but I've not received an answer yet, so just working around the worst case scenario
I'd map that bool value too
I have a problem

all my syntax are correctly but it rises an error that cannot read the command to alter the table.
My guess would be that you never read the result from your sql statement in line 22.
Please learn to use markdown to format your code.
Your issue is very likely a missing ; from the statement before the error.
im getting this error:
py ERROR: there is no unique or exclusion constraint matching the ON CONFLICT specification CONTEXT: SQL statement "WITH current_week AS ( SELECT extract(week from current_timestamp) as week ) -- Pobierz sumę wartości dla nowego rekordu z tabeli "bank_history" -- w okresie obecnego tygodnia roku , balance_for_week AS ( SELECT sum(bh.value) as balance FROM bank_history bh WHERE bh.owner = NEW.owner AND extract(week from bh.date) = (SELECT week FROM current_week) ) -- Sprawdź, czy w tabeli "week_balance" istnieje już rekord dla danego tygodnia i właściciela , week_balance_exists AS ( SELECT 1 FROM week_balance wb WHERE wb.name = NEW.owner AND wb.week = (SELECT week FROM current_week) ) -- Jeśli rekord istnieje, aktualizuj go -- Jeśli nie istnieje, dodaj nowy rekord INSERT INTO week_balance (name, week, week_balance) SELECT NEW.owner, (SELECT week FROM current_week), (SELECT balance FROM balance_for_week) WHERE NOT EXISTS (SELECT 1 FROM week_balance_exists) ON CONFLICT (name, week) DO UPDATE SET week_balance = (SELECT balance FROM balance_for_week)" funkcja PL/pgSQL update_week_balance(), wiersz 4 w wyrażenie SQL SQL state: 42P10
if i make name and week unique i only get one record and future one are not updated
anyone know solution?
PostgreSQL
Hey I have a question regarding arrays, I've looked at the documentation for arrays but I don't understand how to implement it, maybe someone here can give me an example for Insert, Update and Select. :) (Python)
Does anyone know of a way to connect to a databse with ssh using asyncpg? I'm required to use ssh to connect to my remote database and don't think ssh is support with asyncpg
Certainly possible.. but are u sure u want it? Using ssh for this is greatest perversion
If u want to connect to database with restricted public access, appropriate way is using cloud provider private networks
Or at least your own VPN configured. Wireguard or something like this
Or if u don't need those security issues, just expose dB, and connect over TCP of 5432 port like a normal person to it
If i didn't have to i would, but since I am using pythonanywhere I'm required to by them to use it. I just cannot figure out how
I think i've got it figured out but just need to have the ssh connection closed properly
Port forwarding is a way to handle it... In the worst case. Just forward dB port to localhost and connect
Better just use some alternative solution though. With VPN or something
would a vpn be good for a discord bot?
Acceptable but in reality not really recommended.
Modern infrastructure I think should not be requiring needs in VPN for its functionality...
... Like... Why would we need it. Everything is resolved at VPC level 😐
(VPC as in private networks configured at the level of cloud provider)
Something is fishy if u need such hacks for your infra functionality
Usually we use SSH/VPNs purely for developer protected address to staging/production environment. That is the correct usage
I'm cautious of recommending as it was not ideal though I have used the sshtunnel for these purposes in the past.
import atexit
from sshtunnel import SSHTunnelForwarder
And had a class and a connect method ... All the caps variables are constants imported from environment variables.
self.server = SSHTunnelForwarder(
(SSH_TUNNEL_HOST, 22),
ssh_username=SSH_TUNNEL_USER,
ssh_pkey=SSH_TUNNEL_KEY,
remote_bind_address=(SFTP_HOSTNAME, 22),
local_bind_address=("0.0.0.0", 222222),
)
# add logger
ssh_tunnel_logger = self.server.logger
ssh_tunnel_logger.setLevel(logging.DEBUG)
logger.addHandler(ssh_tunnel_logger)
self.server.start()
Unfortunately to improve reliability had to
def close(self):
self.server.stop()
And the class in the __init__ would register the close to be called on as deconstructor of sorts.
atexit.register(self.close)
Hey guys since i found a reddit post that it is not recommended to store big blobs of data in database of mysql, is there any other recommended way to store huge data in database like extracting url of the data like in cloudinary? but cloudinary only supports limited file type even though it is formatted as raw file
Wtf?
<@&831776746206265384> ^^
What's a good way to add migrations to a containerized database? Should i have another container that does all the migrating?
You can store files just on local drive or any S3 compatible storage
If I want to have a user's account that has things, let's say a fantasy football app, a user has players. should the players have a field that references the user as the owner?
probably not I guess.. in the cas there are multiple leagues



Code
cursor.execute(f"SELECT user FROM liked WHERE id = {user1.id}")
result = cursor.fetchone()
if result is None:
sql = ("INSERT INTO liked(id, user) VALUES(?, ?)")
val = (user2.id, user2)
cursor.execute(sql, val)
db.commit()
elif result is not None:
query = ("DELETE from liked WHERE user = ?")
params = [user2.id]
cursor.execute(query, params)
db.commit()
Error
cursor.execute(sql, val)
sqlite3.InterfaceError: Error binding parameter 1 - probably unsupported type.```pls help idk what went wrong
Hey @sullen kraken!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Hey @sullen kraken!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Thanks for this. I figures something out like this as well with a close function as well and just subclassed it with asyncio
Hello, I have a problem, when I want to update the array, it adds all Ids (from the array) and the new one, does anyone know how I can fix this?
** EXECUTE METHODE **
@staticmethod
async def update_roles(guild_id: int, roles: [int]):
return await Database.execute(("UPDATE welcome_setup SET roles = roles || %s WHERE gid = %s", (roles, guild_id)))```mysql better?
Depends on what
What database engine are you using @real forum ?
PostgreSQL
result
So the issues is duplicates?
yes
If I were to run the method again, the 3 IDs would be added again + the new one :/
The array_append function works in PGAdmin but not when executing the method
I think you need array_cat and not array_append
as you are appending an array with an array.
Though the || is already doing that.
Yes, but he duplicates everything and then attaches the new ID
So, he doubles everything in the array and appends the new one (in case you didn't understand it that way)

sorry I don't understand a neat solution myself. I've found an example including updates though includes creating a new function.
Hire Developers, Free Coding Resources for the Developer
Coding example for the question How to remove values from an array that exist in another array?-postgresql
In Mongodb, I have a User collection and a UserInfo collection. Im wondering if there is a way to update both collections in a single request
Quick googling suggests existence of Transactions in MongoDB
https://www.mongodb.com/docs/manual/core/transactions/
My guess is: your roles variable includes all of them, not only the new one, so you append them yourself. If this is true you would only need to ... SET roles = %s ...
yes
Hello 👋
DISCLAIMER
- For this set of questions that I'm about to ask, having a local database is currently not an option.
- I'm looking for ideas/opinions/potential expertise/strategies, not necessarily precise & exact solutions
Problem
Has anyone had the chance to deal with database versioning for existing databases before ?
I'll try to make this as clear as possible, and you can hit me with questions if you want
Suppose we have 2 databases, one for production, and one for development.
We also have **n deployed web apps, each with its own domain. n-1 **use the same dev db, and the last one uses the production one ( so it's obviously the prod domain)
A big problem we have today is keeping these databases aligned, in terms of schema and data.
I'm trying to use flyway as a tool to do this, but I'm wondering how can we handle the same dev databases, when multiple teams could be working on features/sprints. This is a problem because ANY change should be done using that tool (according the the devs of Flyway), so we can't afford to fiddle around running our scripts & modifying the db manually.
Has anyone ever had the chance to do this, or something similar ?
interesting problem.
a few questions:
- could you elaborate on what does "keeping these databases aligned, in terms of schema and data." mean?
- if i understand correctly, you meant mirroring changes made to prod db into dev db? but then how can devs develop new features that require db migration?
- do you already have some sort of database snapshotting/backup capability? e.g. WAL logs for postgres
in my old job, we have a cron job somewhere that spins up a database using the latest snapshot of our prod database at midnight, and people can go wild on that dev db if they want, we could also spin up our local copy of it if we so desire
- could you elaborate on what does "keeping these databases aligned, in terms of schema and data." mean?
+ if i understand correctly, you meant mirroring changes made to prod db into dev db? but then how can devs develop new features that require db migration?
It means that every db should have the start from the same state that the prod one has, and when developing features/increasing db versions in those feature branches or whatever, they need to be reflected accordingly in the prod db, but also in the staging one or whatever
do you already have some sort of database snapshotting/backup capability? e.g. WAL logs for postgres
Not that I'm aware of unfortunately
Does that clarify/answer your questions ?
I have a few small python ETL's for redshift running in AWS Lambda.
Currently they all use SQLAlchemy & sqlalchemy-redshift (redshift_connector) to connect to the DB. All tasks are fairly complex so im not using the ORM rather generating SQL statements and running them in transactions.
My question is: What would be the optimal choice of library/connector for this workload?
- sqlalchemy?
- redshift_connector? redshift data api?
- pg8000?
- psycopg2-binary?
it does, somewhat.
however, i am still a little confused about what if there are two feature branches that require database migrations, but this is not a massive issue to figure out for your question i think.
my current idea is
- upon prod database migration, dump prod database states
- then load dumped prod database states into dev database (potentially from scratch)
- after the brief downtime when dev database is being provisioned/loaded, whoever was developing against the old dev database will need to run their own migrations again (if there are competing dev migrations, the devs will need to sort themselves out.)
my other ideas are mostly variation of this..
e.g. instead of blocking restoration of dev database, make it somewhat async, i.e. don't serve any traffic until the dev db is absolutely ready
e.g. instead of a resource intensive database dump, use WAL (or something similar)
For the parallel branches, that's another big issue that I need to figure out.
It somewhat becomes easier to solve using the features of paid licenses, but not sure they'll be willing to pay. Which is why this is an entire design space.
OK so I didn't think of a database dump, but are you talking about a data dump or what exactly?
We can't just copy prod data into dev db for multiple reasons.
Plus, it you want to do that and remain GDPR compliant, it's going to be a PITA to deal with.
On of the challenges is dealing with ad-hoc fixes as well
One*
ah! i actually assumed you weren't dealing with PII and GDPR doesn't apply. that complicates things a lot imo.
OK so I didn't think of a database dump, but are you talking about a data dump or what exactly?
erm i guess i am talking about a data dump, i was thinking about pgdump (https://www.postgresql.org/docs/current/app-pgdump.html) or mysqldump (https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html)
since you want to remain GDPR compliant, are you looking to just have the dev db follow the prod db's schema without the actual data?
or are you also looking to somehow scrub the PII from the underlying data to have something that really closely matches the prod db?
Scrubbing would be optimal, but I can do without it as well I presume.
I'm looking to make it work, then somehow make it better
hi, is psycopg3 beter than psycopg2 and why?
But I definitely need to be GDPR and PII compliant
dealing with scrubbing is also a something i would like to know how people solve as i don't have a good solution.
pgdump has a --schema-only flag, which should help you replicate the schema quite nicely. hopefully it also exists in the db you are using
I have actually managed to dump that into an sql script that contains the DDL of the database, along with the indexes, views, stored procedures etc
The tool needs it to use it as what it calls a '' baseline '' version for existing databases
Yes me too, I not experienced much with databases tbch
Has anyone had the chance to deal with database versioning for existing databases before Not really, but it should be pretty straightforward:
- Choose a migration tool (e.g. alembic)
- Replicate your current prod schema in alembic so running that migration makes identical schema
- Manage both databases using it 🤔
This SO question should help too: https://stackoverflow.com/questions/52121596/creating-zero-state-migration-for-existing-db-with-sqlalchemy-alembic-and-fak
Stack Overflow
I want to add alembic to an existing ,sqlalchemy using, project, with a working production db. I fail to find what's the standard way to do a "zero" migration == the migration setting up the db as ...
Not sure if '' Straightforward'' applies here, but I'll have a look at it
Thank you!
Do you have any functions or similar stuff that alembic can't detect? 🤔 Also what ORM (if any) you're using?
It's not even a Python project
And it's an sql server db
And the ORM is custom built
And it doesn't have any built-in/pluggable migrations?
Nope, unfortunately not
Any once active here
please help me
https://discord.com/channels/267624335836053506/1062076543607779398
this was my question
Hey 🙂
Does anyone know how to merge to sqlite databases? They have the same columns I just want to have 1 DB instead of two, so I'd like to merge them
Backup both
Make SQL dump of second
Erase from from dump table/indexes and etc creation, leave only record insertion
Apply resulting dump to first db
And get errors of already existing primary keys 
Alright. Then querying in bulk from first to second and inserting in bulk, table by table
Or, u can actually complete first path
With simple regex, u should be able to delete all conflicting unnecessary columns
Or actually u can just prepare second dB for copying, by in advance deleting not necessary columns... Wait u can't
If some records have ID conflicting with first dB, u can't delete them
Because other table foreign keys can be depended on those keys
Therefore data integrity will be broken
All right, then the only left choice is to write complex queries in order to copy one dB to another, unless u will find some short way around it it for to copy depended on each other tables with preserved data integrity but changed ID keys in order to avoid conflicts
Any moderators help me
Now, 1st of all i am still not clear that if the table is being created or not,
i think it gets created automatically, like other databases
The table is created when you call create_a_table(). I suggest you modify the SQL to be CREATE TABLE IF NOT EXISTS rather than CREATE TABLE so that you don't get an error after the first time the script runs.
but if it is being created then where its getiing stored i am not sure
The table is stored in the database file SQL Book.db
and last, I am not getting the values, while giving the as command in other words
get_all_books()is not responding
You need to uncomment the call to promt_get_all_books() in your while loop. Then it will work.
Hey folks, my Postgres table is partitioned using table inheritance strategy. Should i also create indexes in the parent & child tables using the partition column for better query performance?
eg.:
cols [ 'received_at_date', 'device_id', 'body', 'source']
partition col: received_at_date
the 2 most frequent queries use the following sets of filters:
1 - ('received_at_date')
2 - ('received_at_date', 'device_id')
indexes:
1 - btree('received_at_date')
2 - btree('received_at_date', 'device_id')
I don't think I have anything commented
Any moderators please activate my chat again
And any helper please help me
Run query with EXPLAIN ANALYZE and read if u need it.
Also Betterc having monitoring system running to gather metrics about query time completions
If you guys use mongodb, can someone enlighten me on something: Can you use any database as an auth point, and any database user table can be used to define access to any other database?
Like I'm very confused, I can define a user in the admin as having access to mydb, but also a user in mydb as having access to admin ?
And if that's the case, where am I supposed to define my users? in admin? In a the related database (if there is one and only one) ?
You are supposed to define only one user to Auth and get access to your database
Users should exist purely as table in database, having fields name and password_hash (which stores them through Bcrypt algorithm for example)
Application, should run Bcrypt and match hash in order to consider your app users authenticated. Attach to them some JWT cookie for confirmation of successful Auth
I'm talking specifically about mongodb users, why would I only define one user though?
Isn't the entire purpose of role and context separation to access a database more safely?
Also, never use Mongo as main database. Use Sqlite or Postgresql for fully fledged one
Why is that?
Mongo is having poor data integrity enforcement, very poor relational query capabilities and lack of data migration mechanisms.
It will lead to very code and data dirty state of your application and database.
Imagine writing code only in in one function, never splitting to different ones, never using classes, and etc. Never writing unit tests, same essentially bad stuff will happen
You will face those problems especially if going to write new application version after initial release
I think those roles... Usage is kind of outdated essentially. They were mostly needed from time when one database was used as central point to multiple applications.
This role management ensured minimal access for different apps in the past
As of today, code best practices found in a hard way it is bad idea to share database access One microservice should own dB fully
Oh okay gotcha, I'm surprised mongodb's own service isn't better than any microservice I'd roll out myself
I'm mostly dealing with logs, or time-seriesish data, I don't have any complicated relational query needs (if any, really), but I'll keep that in mind
Fellas I've got a question to ask... what does it mean to "know" a database? When you check job offers online some of them would ask you, for example, if you know how to use PostgreSQL. Now, if for example I made a django project using PostgreSQL to store data, can I say that I know how to use it?
I know that it might sound rather silly and stupid, but like I am wondering if "knowing to use a database" involves MORE than just knowing how to implement it and use it
I would interpret what they mean based on the rest of the job listing. Do you know enough to do what they will be asking for you to do, and are you prepared to answer relevant interview questions?
Ah okay thanks
Don't ask to ask, just ask. There are many different kinds of NoSQL databases so what exactly are you looking for help with?
https://discord.com/channels/267624335836053506/1062076543607779398
Any one please reopen this one
Moderators
for future reference: just open another one.
We do not re-open closed threads - users should just create another one instead
like the bot's message says,
If your question wasn't answered yet, you can create a new post in python-help. Consider rephrasing the question to maximize your chance of getting a good answer. If you're not sure how, have a look through our guide for asking a good question.
Please go through my question once
I have tried to make it best from my side
But still I don't any response
BTW the waiting period must be atleast a few hours I thinks 30 min is a bit low
I am using sqlite3 as a very tiny database for a small program and in my python script its not returning the correct results of a join query while the same command works fine within the sqlite terminal. Would there be any simple issue I am overlooking?
show your code
apparently it was because I set row_factory to the builtin sqlite3.Row class. It doesnt work with joins
!e You sure?
import sqlite3
conn = sqlite3.connect(":memory:")
conn.row_factory = sqlite3.Row
conn.execute("create table foo(foo_id int primary key, foo_txt text)")
conn.execute("create table bar(bar_id int primary key, bar_txt text)")
conn.execute("insert into foo values (1, 'foo'), (2, 'bar')")
conn.execute("insert into bar values (1, 'bar'), (2, 'foo')")
for row in conn.execute("select * from foo join bar on bar.bar_id = foo.foo_id"):
print(dict(row))
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | {'foo_id': 1, 'foo_txt': 'foo', 'bar_id': 1, 'bar_txt': 'bar'}
002 | {'foo_id': 2, 'foo_txt': 'bar', 'bar_id': 2, 'bar_txt': 'foo'}
The column names are the same and I am joining by id. A simple change would probably break the above code
!e
import sqlite3
conn = sqlite3.connect(":memory:")
conn.row_factory = sqlite3.Row
conn.execute("create table foo(foo_id int primary key, foo_txt text)")
conn.execute("create table bar(foo_id int primary key, bar_txt text)")
conn.execute("insert into foo values (1, 'foo'), (2, 'bar')")
conn.execute("insert into bar values (1, 'bar'), (2, 'foo')")
for row in conn.execute("select * from foo join bar on bar.foo_id = foo.foo_id"):
print(dict(row))
@formal latch :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | {'foo_id': 1, 'foo_txt': 'foo', 'bar_txt': 'bar'}
002 | {'foo_id': 2, 'foo_txt': 'bar', 'bar_txt': 'foo'}
so a change to my table is needed but that includes having colum names which are over verbose
Well as bar.foo_id = foo.foo_id you only need it once.
how else am I to join the related entries in the two tables
I am dealing with foreign references
Yeah, I can see how that could become a problem. But dictionaries can only have unique keys.
ah yeah I can just create column aliases
anyone here
Hey can someone review schema for me?
https://hastebin.com/vayafeticu.sql
Im working with a lot of data (10k rows everyday) and dont know what else can be improved, please @mention me if you want to help
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
Hey, working on an ML project and looking to create an host a database that contains training, validation and model data in a way thats safe from accidental user tampering and very scalable. looking at postgres, mysql and sql server. any suggestions? only db experience is with mongo (which is fully not the right tool for the job)
Using SQLAlchemy 2 with async, I found how to load relationships within the object (with options and selectinload etc...)
but can we get the relationship AFTER get the main object
like :
main = await session.get(Main, 1)
main.second # relationship with second, will raise an error because of lazyload
await main.load_relation(Main.second) # load the relation into the current object
because I have a function that get my main object (and create it if not exist)
so I use it everytime I need the main object, but I don't always need to have relations loaded too
I could maybe add an option argument to my function if I need to join relations, but maybe there is a way to get it by after
Maybe just use session directly? 🤔
Afaik there's really no way to load relationship into object with async, but maybe there's something new in 2.0
SELECT user_id, total FROM points ORDER BY timestamp
I have an almost postgres query... what would be the way to go down this list and take the first user ID-total pair (the one with the newest timestamp), return that, and ignore any further of that user ID
any chance anyone can give advice?
SELECT
DISTINCT ON (user_id) user_id, total
FROM
points
ORDER BY
user_id, timestamp DESC
i think this is what you want?
documented here: https://www.postgresql.org/docs/current/sql-select.html#:~:text=is the default.-,SELECT DISTINCT ON,-( expression [%2C ...] )
won't that order by the user id first?
Wait, that doesn't really matter
yes it would. just use CTE or subquery if you want to re-sort by timestamp
you must sort by user_id first if you use DISTINCT ON
I just need the value of total with the most recent value of timestamp for each value of user_id
does that make sense
then what i have typed above is correct
Meaning this, or the sql query
this, and you don't need to resort (if you don't want to)
Okay cool
Thank you very much, i had gotten to distinct on by googling but didn't understand why i had to use user_id in order by or how i would have done that.
you can try removing the order by user_id, iirc postgres will just scream at you
it will
and this is quite a niche functionality that is only supported by postgres dialect as far as i know.
most people replicate this behaviour with a row number window function and then filter for row number = 1 if DISTINCT ON is not implemented
(also some dialect might support FIRST(total PARTITION BY user_id ORDER BY timestamp DESC), which also makes sense)
Kinda new to SQL but i'm wondering if its possible to do multiple executions since I keep getting sqlite3.OperationalError: database is locked?
Yes atm I load them separately
But it would be cool if there was a quick way to do this
session.execute(select(Second).where(Second.main_id == main.id)) is « long »
Using Django DB., so SQL Do you add lists of items to a single database item? or do you create a new model for each item and set up a one-many relationship? For example, In my app, a user creates a project and can add URLs to that project. The URLs are bulk added in an excess of 50+. I save the URLs as a JSON and add the JSON to a JSONField. When the user needs access to those URLs Later in the project, I JSON.loads the URLs and the user can add to or delete from the URL list. Once they are done, the data is JSON.dumps, and then the new URL list is saved into the project under the single cell.
I could also do this ig
await session.run_sync(lambda _: main.second)
can someone could tell me the error :
username_email = 'vicentedouardle'
query = ('''CREATE TABLE %(Username)s (Emails LONGTEXT, SKeys LONGTEXT)''')
data = {'Username' : username_email}
cur.execute(query, data)
cnx.commit()
what database/library and what error message are you seeing?
I am using mysql.connector and this is the error :
mysql.connector.errors.ProgrammingError: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''vicentedouardle' (Emails LONGTEXT, SKeys LONGTEXT)' at line 1
You can't use binding parameters for SQL identifiers, only data is allowed.
so there is no way to bind identifiers ?
Well, you can use f-strings and be very careful what you allow. And using a email as tablename doesn't sound good.
i ll try this. Yes this is why I just get the username without the @ to not generate errors
It's more like, the table should be named user and the email is one column of it. You normally don't make a table per user.
yes maybe i didn't organize myself well
thanks !
Who can help ? My bot does not respond to messages and does not give out the participant's level for them and does not write about it in the chat. Just please don't throw me a link to the documentation for this module
Hey guys, if I have a tree that has subcategories and articles, and each subcategory can have articles and other nested subcategories, like the image below, how should I go about storing that data so I can access all the child nodes from a parent category?

sql question, which attributes here has full functional dependence here

it seems like none to me
Not sure but I think we're missing information... this is a homework question?
its a question in an old test
Between which columns there can be a complete functional dependency based on content i
the table below?
is the full question
there is no more context
me too, test could be wrong
guys I have to write lots of data into a DB, will do so with a for loop, do I have to commit everytime I write data into it, or I can commit once I'm done writing all the data?
Thanks
The values of B and C seems to always match.
a -> x, b -> y, c -> z, d -> y
It depends on what u need.
If data u write should be written only when all queries passed successfully, and if not then all of them should be cancelled in case of error in any of them, then use commit once.
If data u write is allowed to save intermediate queries and failing with rollback only on last failed, then commit every time or stop using transactions(sessions?)
(p.s. or write already context manager with automated commit on its end, as universal solution removing need in commits)
In relational db you could have parent column that would reference PK field of parent node
I was thinking of storing all the Parent-category and the title in a regular database
And then to create a hashmap-like table for storing all the nested subcategories, so I can get all the subcategories of a given category
With my method you can just SELECT * FROM table WHERE parent = ..., I don't think the additional table is really needed
And using a reference to PK allows you to delete all subnodes on deletion of a category with a single query
It depends on how much data there is, as long running transactions would negatively impact whole DB
But you can commit once at the end, it should be fine, but again - depends on how long it takes
Well lets say that the root node is "History" and I want to select all the elements under "Roman Empire" category (which also has multiple subcategories) how can I do that?
If I understand you correctly, I can only get the node right after the category "Roman Empire", but not all the desendents
First you will need to fetch all subcategories recursively, then select elements for each category
I don't know what db you use
I was wondering about fetching the data, if there is a way to do it without recursion?
I currently I'm just brainstorming, I could use whichever works best
You typically operate with tree with recursion
The issue is that if multiple subcategories (in the same level) are present in different functions, than I cant use multithreading to get the children at the same time. (to get the children I need to do a web-request which is pretty slow)
@queen rose in postgres you can do this https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-recursive-query/
In this tutorial, you will learn about the PostgreSQL recursive query using the recursive common table expressions or recursive CTEs.
Seems similar to what you're trying to achieve
btw Im trying to extract items from the tree (the picture I sent earlier) and I have a function that does that recursively and I reached the "maximum recursion depth"
because the tree is so large
You need to use that recursive query from a tutorial I sent
It is more effecient
And won't get recursion error
Im talking about extracing the data from the web (with web requests)
You can collapse the tree into array
What do you mean?
can someone help me here?
https://pastebin.com/AvtMr5Yh
pycord and sqlite3
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
The thing in example doesn't provide tree-like structure, it provides an array, so you just have to iterate over its elements
Or do some other stuff with array
Do not use sync sqlite3 lib in async apps, use aiosqlite
Very likely that your issues are because of that
!pypi aiosqlite

asyncio bridge to the standard sqlite3 module
how do i do that?
Not for you
oh
Everything after reply is for you
but my other currency commands all work- is it possible to fix this inventory command?
You need to change to aiosqlite no matter what
When you do a query nothing else works
💀
Try getting 10 users to use a command at the same time, bot will freeze
it doesnt matter.. how to fix it?
I suspect that you already have table with that name, try dropping it
Hi does anyone have experience with sqlalchemy python?
I want to fetch videos from the database (postgres) and display them in my web page using html.
I work with it daily, what's the problem?
My project is about fight detection. And once the model detects a fight it will automatically record the live stream. We’ve successfully stored the recordings in the database but our problem now is how to display those recordings in the website (html). We have this page called recordings where we will display recordings so the user can view past fights and so on.
We’ve tried putting the video in a html video tag but it does not display
Is there a way to display the videos from database into our website using sqlalchemy?
You don't store actual videos in db, do you?
correctly optimized sqlite queries can achieve sub-millisecond performance, so a threaded worker isn't always a necessity
Should I concentrate on mongodb or redis? Any advice to ameliorate my skill set?
As far as I know we have it stored yeah
Full videos? You shouldn't do that
Store it on filesystem/s3/cdn/whatever, not in the db
@noble glen Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
more relevant to sql but i still need this
i have this sort of query:
Select table1.*,
(select sum("data") from tmp where tmp.column1 = table1.column1) as "TOTAL"
FROM (select [...] from tablex [...]) table1
What i need is to change the output order so the column total would not be shown as the last column
is there any way to visualize my db? i keep getting this error even tho i JUST created the table

oh my god the if statementw as wrong
HAHA
i am attempting to make my mongodb database async for a discord bot, i replaced pymongo with motor in the imports and connection creation but now i get this error when trying to search
TypeError: 'AsyncIOMotorCursor' object is not iterable```printing type(self.default.find()) returns <class 'motor.motor_asyncio.AsyncIOMotorCursor'>
async for ...
so i'm trying to decouple db code & discord bot code
sometimes i have to take a list/json, whatever, modify it, & put it back
should i have a get_asdf and set_asdf function? i'm new to dbs, so idk any conventions or whatnot
@pale escarp Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
You could name the functions get_asdf() and set_asdf(data) or get_data() and set_data(data) depending on your preference or naming conventions in your project
a
after doing a school project in postgres
i take this back sql isn't too bad
though i still think it's harder than mongodb
it depends what you're doing.... throwing heaps of data at MongoDB is a breeze, but good luck building an app that can use that mess of unstructured data
I wanna create a Pastebin website were u can save text that get saved in a database and can be accessd by a custom url. Whats the best database system to use.
Postgresql is a best default choice 🙂
SQL for the win
k thanks. Should i sage the text as a blob or plain as text in the db
Use Text. It is meant for this.
Don't try to optimize
Postgres with hacks... I tried heavily to break its optimisation mechanisms once... They are very powerful as it is.
Nice to tune for more performance at some point though, if u know what u a doing and having enough data size
and i take it i'd need different get_[insert field] & set_[insert field] functions for all needed fields in my db?
You can probably use for loops to move the 2nd to last column to the end instead, and I believe you could just apply this for each column you want to move

can anyone help me on a flask app. I am having problem with creating database with sqlalchemy
https://www.sqlite.org/lang_altertable.html#making_other_kinds_of_table_schema_changes
The only schema altering commands directly supported by SQLite are the "rename table", "rename column", "add column", "drop column" commands ...
Changing column constraints is not supported (easily).
You can rebuild the database with the changes you want.
sqlitestudio uses a temporary table to store existing data before dropping and re-creating the table
not sure if this is a good question
say i have a user
and they have a bunch of different attributes, and these attributes can be separated pretty cleanly
say they have some attrs related to their email & some related to their, idk bank acc (hypothetical example)
should i put all of them in 1 table, or separate the attrs into 2 tables?
import sqlite3
conn = sqlite3.connect('bank.db')
cursor = conn.cursor()
cursor.execute("""CREATE TABLE clients (
id INTEGER PRIMARY KEY,
name TEXT,
account_number INTEGER,
code INTEGER,
token TEXT
)""")
conn.commit()
cursor.execute("INSERT INTO clients (id, name, account_number, code) VALUES (1, 'John Smith', 123456, 1111)")
cursor.execute("INSERT INTO clients (id, name, account_number, code) VALUES (2, 'Jane Doe', 654321, 2222)")
cursor.execute("INSERT INTO clients (id, name, account_number, code) VALUES (3, 'Bob Johnson', 111111, 3333)")
conn.commit()
import uuid
import time
account_number = input("Enter account number: ")
code = input("Enter code: ")
cursor.execute("SELECT * FROM clients WHERE account_number=? AND code=?", (account_number, code))
client = cursor.fetchone()
if client is None:
print("Error: client not found.")
else:
token = str(uuid.uuid4())
cursor.execute("UPDATE clients SET token=? WHERE account_number=?", (token, account_number))
conn.commit()
print("Access granted. Token: ", token)
time.sleep(45)
cursor.execute("UPDATE clients SET token=? WHERE account_number=?", (None, account_number))
conn.commit()
----I made this code for assigment in my school-----
Task
Using the sqlite3 module, it is necessary to create a client database in the bank. The client has id as primary key, first and last name (as one data-string), account number and code as attributes. It is also necessary to define the attribute token in which the token of the user accessing the account will be stored. It is necessary to insert three arbitrary users into the database.
It is necessary to create a program so that it requires the account number and client code as input. If the client does not exist in the database, the program must return an error. Otherwise, the program needs to create a token that will be valid for the next 45 seconds and write the same token for the specific user in the column intended for that (use the sql UPDATE method). It is also necessary for the program to display a message about the success of the access and return the token to the user.
-----This what i needed to do--------
Can some1 check it and see it is good?
@worldly spoke Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
Anyone have a good resource or tutorial that they really like for connecting to Microsoft SQL Server from python and pulling data?
Something that you feel actually demonstrates best practices in a production environment for automation?
I feel like a lot of tutorials I come across are watered down for the sake of learning or take short cuts that might not be best in a work environment.
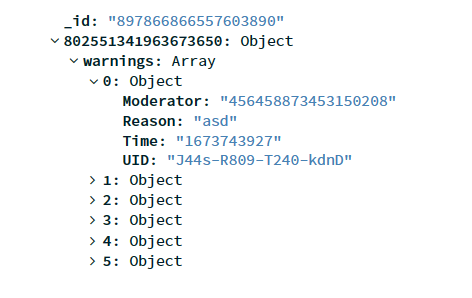
Hello, I've been trying since a certain time (30-40min) to access the "UID" fields in MongoDB. I can't figure it out, and I would say I tried almost everything that could possibly work. I need to iterate over every existing UID throughout the whole document in order to check if the UID already exists. I would appreciate any help
https://i.imgur.com/sfKGLnf.png
Hi! I'm trying to understand databases a bit backwards. I have a piece of code that I didn't write myself and am trying to understand the pieces of that and the info given in the error at the same time.
I'm using SQLalchemy with PostgreSQL. This is the error:
Can't attach instance at <Season at 0x7f68ede99b80>; another instance with key (<class 'db.season.Season'>, (2,), None) is already present in this session.
My two questions:
Is <Season at 0x7f68ede99b80> an instance, a table, or what exactly?
What's a key in general? I know how to use primary and foreign keys, but I'm not sure what just key is.
Hi I am trying to get a table such that it has maximum of sum_of_rr in each rating category and I want to know in which rental duration it is....so in the second image I want get rental_duration column also but I am getting this error Error Code: 1140. In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'y.rating'; this is incompatible with sql_mode=only_full_group_by i wanna know is there any work around it


I am trying to do something like this
await pool.fetchval("SELECT thing FROM things WHERE created_at = $1", date)```
Where date is the instance of pendulum.Date. This simply does not fetch anything, although there is record meeting these conditions (I did manual SQL query and it worked). How can I make it correctly convert pendulum.Date?You have a mistake in your statement and I believe indeed you still can alter columns
not sure if this is a good question
say i have a user
and they have a bunch of different attributes, and these attributes can be separated pretty cleanly
say they have some attrs related to their email & some related to their, idk bank acc (hypothetical example)
should i put all of them in 1 table, or separate the attrs into 2 tables?
Honestly, if it relates to the table im editing I just stick the bank account information into one table, however if it was for businesses or jobs, I wouldn't put jobs that people have in a business and rather make a 2nd table for jobs, hope this helps 🙂
that's kind of... complicated question opening some wormhole of problems
-
Firstly you can dump everything into one table. Advantage: everything remains in one user, simple to query: Disadvantage: A hell of overbloated user it becomes, and your mind can stop easily tracking this information after 8th added column
-
You can split data into other tables while leaving foreign keys linked to main one: Advantage: data is less bloating, in general nice, Disadvantage: Your SQL queries will become more complicates 😦
-
And now third path trying to join good things out of both first two ways: At the code level as Python/Golang whatever programming language, you can make beautiful arragement... Which in terms of python it would be Dataclasses or better Pydantic Models. User Pydantic models has sub models of Pydantic model which are grouping in sub groups relevant data. Same you do at the level of ORM if u are using it. Through inheritence / composition, you organized your SQL models in the way they are splitted. Yet during SQL table creation, all those subgroups will appear as one table, thus remaining simple to SQL query, yet remaining clean readable for human eye at the terms of Python/Programming language reading. So all advantages... as Disadvantage... it nicely works only if u have ORM i think, without ORM it would be a bit more complicated to do it nicely :/
my current project team chose path 1
I am choosing path 3, as i think it has most of advantages and no disadvantages...

ORM is a special library to work with some database engine at the level of programming language mapped OOP objects (Classes).
For example Django ORM or SQLalchemy in python can work with MySQL engine (also with Sqlite, Postgtesql, MariaDB...)
ORM is translated as Object Relational Mapper
There are different multiple other approaches abstracting away regular SQL in programming languages
So, shortly saying you googled, is a knife a potato? Answer is no. But they can be used together to make a soup

With and without orm joining tables is just that - a join, it's pretty easy
Depending on your requirement it might not be suitable to put everything into one table
e.g. user may not have a card, they can have multiple cards
or bank account info, but still
so i have this set of relations to do:
i've users & cards
user -> cards is one to many
each user can also have 6 decks, each deck containing at most 12 of their cards
a card can be in multiple decks
```how would i go about doing it?6 tables, one for each of the 6 deck slots?
i think just two tables, one user to many decks and one many decks to many cards would be more convenient and flexible, e.g. ```sql
user user_card
- user_id PK - card_id PK
- user_id FK
deck deck_card - deck_id PK - deck_id PK FK
- user_id FK - card_id PK FK
an example of querying the decks that each of a user's cards belong to:sql
SELECT deck_id, card_id FROM deck NATURAL JOIN deck_card WHERE user_id = ?``` and your constraints can be enforced with BEFORE INSERT triggers
I would personally prefer to implement that logic (deck amount, size) in app layer since I usually don't touch triggers/functions on DB level
It's easier to handle errors, test and change requirements, but you potentially can end up with inconsistent state
hello, im trying to add a new column in my database. i want to add the column "age". it checks the "year" column, does some maths to figure out the vehicle age then add that number to the row. if i use
pd.read_sql_query("SELECT strftime('%Y','now')-1900-year AS vehicle_age FROM results ", conn)
i see the column, created exactly like i want it. but if i
SELECT * FROM results
i dont see the new column
You're selecting a column in the first snippet, not creating it
You could look into adding new column into your tables with "alter"
the column does not exist in the database or the table
ive been bashing my head against the not so beginner friendly docs
i was able to create an empty column with 0 as place holder, even tho it spit out a giant error
tyring to update the table with SET created an sqlite-journal file .. this is a mess
yeah thats what ive been doing for 2 hours
thats why i asked here
maybe theres something obvious that im not seeing
SQLite doesn't support alter
It supports a limited subset, you can add new columns then
You can show how you tried to do that and what the error was
so how is python is it good
like im trynna learn python
im also trynna learn java ]
what do u guys think
This channel is about databases. So you are in the wrong place?
You may want to ask in #python-discussion
srry thats my bad i must of hit ctrl + k
hello, using sqlite3 how i can get a records of 2 or more tables?
np
You're probably looking for join
Stack Overflow
How can I make a copy values from one column to another?
I have:
Database name: list
number | test
123456 | somedata
123486 | somedata1
232344 | 34
I want to
UPDATE `players` SET test = (SELECT thing from temp3)


can someone tell me what's going wrong here?
SELECT thing from temp3 returns more than one row, and if you return more than one row, the update wouldn't work because presumably it couldn't figure out which thing from which row to use
i want to set the entire column test to the entire column thing?
how hard could it be?
you need to consider it from the software point of view, which row from players should be updated by which row of temp3?
you aren't specifying that at the moment, and it won't work
well i'll give more context i guess
i have a column, all are strings of true or false
i wanna convert this to a column of booleans
i got a new column of booleans like so:
(SELECT IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null) FROM (SELECT * FROM players) xxx);
now i have no clue how to put it back in
okay
UPDATE players
SET test = IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null)
is this not what you wanted?
how.... does it work now...
hmm? do you mean it doesn't work? or you want me to explain why it works?
UPDATE players
SET show_map = (SELECT IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null) FROM (SELECT * FROM players) xxx);
i previously tried this
and it didn't work
so how come your code works and mine doesn't
right i see.
UPDATE players
SET show_map = (SELECT IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null) FROM (SELECT * FROM players) xxx);
is quite different.
think of this as
- update players
- for eact show_map, set it to something
- something here is defined as
SELECT IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null) FROM (SELECT * FROM players) xxx
BUT in 3. the something is a long list of booleans, this just doesn't work, you can't put a list of booleans into a box that can only contain boolean / nulls
as opposed to your code, which...
UPDATE players
SET test = IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null)
on the other hand is
- update players
- for each show_map, set it to something
- something here is defined as
IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null)
in 3. the something is just a boolean/null, which is great, because we want to put it in a box that holds boolean
it's a bit hand-wavy, hope that explanation makes sense.
IF(show_map IS NOT NULL , IF(show_map = 'true' , TRUE , FALSE) , null)
shouldn't this also be a list though?
no, that's evaluated per record within table players
as opposed to your, which is evaluated against the entire table players
ha yes it does get some getting used to. i think it's pretty natural 🤷♂️
Heyoo
i hope its the right channel for that.
Im trying to use mysql to make a database for my discord bot. Problem is: i installed "mysql-connector-python" via pip. Terminal said its installed. when i try to import mysql.connector to my code but it does not exist.
mysql is a package i can import but mysql.connector is not there...
im confused 😅
Maybe someone can help me out because i have no idea what i can do anymore
i have a problem regarding ssh and i'd really appreciate if i get some insight. so i'm trying to host a python application on a shared hosting (namecheap.com), connecting to mysql directly is disabled so you have to use a ssh tunnel. and i cannot use sshtunnel library because i cant install paramiko, paramiko needs libffi which i can't install because i dont have sudo permission on the shared hosting. is there any other way i could connect to mysql database through ssh without using paramiko or sshtunnel library?
perhaps it's connector instead of mysql.connector
import connector
should i install "connector" then?
Because the only thin i can import is "_mysql_connector"...
and thank you for helping ^^
does anyone have an idea how resource intense creating new SQLalchemy sessions is? 🤔
Does SQLalchemy support cursor pagination. I am currently using slice for **offset/limit **pagination but offset pagination is not efficient for large records.
Make sure you choose the interpreter that you are installing packages to :)
yeah i did xD
Like 6 times already xD
So other packages that you are installing are being found?
(I'm asking because I installed the same package and can import it as mysql.connector)
To give some context to my problem the business I work for is doing an IP swap and we need to build a list to track whether an IP range has been broken down into smaller ranges. In the database there's a parent_id column that has the ID of the subnet it was broken down from (1.1.1.0/23 has ID 12 so ParentID of 1.1.1.1/24 would be 12) and my plan was to have a recursive function that checks if the ID passed to it is in the parentID column, if it is then get the IDs of the ranges with that ID in the ParentID field and repeats but my road block is how do I keep track of the relationships. I wanted to build a json file that would have keys be the IDs of the subnets with children and the values be an array of child subnet IDs but I'm not 100% if this work or how to go about implementing it. Any input on whether this idea will work and what it should look like or if there's a better way would be appreciated.
i dont know... i guess not. But i already reinstalled it
sorry for the late response
I'm unsure if you're still having the issue, but have you tried python -m pip install rather than pip install?
i tried both…
i will try using a new interpretor (is that spelled correctly?) tomorrow.
hi guys, i would really like to store images in some database but i know its advised to not make them into blobs because it takes up a large amount of space
any ideas on where to do this?
Use a blob store for the content and a DB for the metadata
hi! how can i fix this error? here is the code


sorry for offtop, but great status

Hi, if I have an excel which I import into a database and there is a cell which contains sql code can this lead to sql injection? Do I need to check for sql code in the excel file before importing? How would I do this? Check for sql keywords like select, delete, etc? Or escaping and encoding?
where to ask help?
Well there are a few things:
- what database
- How is it being imported? Is it native to the DB? Or is this being done with a script?
the database is Exasol
the excel is imported via a python script using the pyexasol library
what methods r u using with the pyexasol lib?
import_from_pandas
Mmm looking at their docs my assumption is that it treats strings as random strings rather than SQL statements
the easiest way to confirm though is to just put some SQL in your sheets and testing if it gets executed or now
it does look though that the import methods do not process SQL only the export / query layer does
so you should be safe
ok, thank you, i will test it by putting some sql in my sheets just to be sure
anyone is experienced with sqlite here?

Hi
what have you tried so far? here's some ideas: https://stackoverflow.com/questions/54722251/cant-connect-to-mysql-db-withh-python-bad-handshake
Stack Overflow
I am trying to connect to a mysql database (hosted on media temple) with my python script (ran locally) but I am receiving an error when I run it.
The error is:
Traceback (most recent call last...
probably a lot of people are... I would encourage you to ask your question
thanks g
is there a big names and genders genders dataframe?
can someone help me here? what is wrong?


You could generate a sql file from https://www.mockaroo.com/ and then just use pandas to generate a df from the sql file. Or csv, or whatever format you prefer
A free test data generator and API mocking tool - Mockaroo lets you create custom CSV, JSON, SQL, and Excel datasets to test and demo your software.
db = connect('database.sqlite3')
db.execute('CREATE TABLE test(text TEXT)')
why does this work? why doont i need a cursor
I'm just guessing, but it seems like you're trying to execute something from a closed connection since you closed the connection in this line

Then tries to do something with the closed connection in these lines

!d sqlite3.Connection.execute
execute(sql, parameters=(), /)```
Create a new [`Cursor`](https://docs.python.org/3/library/sqlite3.html#sqlite3.Cursor "sqlite3.Cursor") object and call [`execute()`](https://docs.python.org/3/library/sqlite3.html#sqlite3.Cursor.execute "sqlite3.Cursor.execute") on it with the given *sql* and *parameters*. Return the new cursor object.if we have a MongoDB collection with a collection and we have a status field and I have 2 options to use an enum with string value status = { starting: "starting", running: "running", stopped: "stopped" } or the numeric value status = { stopped: 0, starting: 1, running: 2 } which one is better? I think using numeric values will be better because it will use less space and the index size will be also low.
Does motor provides a context manager (like aiosqlite) does?
fwiw i didnt find any existence of a context manager for the client itself, just stuff related to "client sessions" and transactions, but i dont use the library so maybe i wasnt looking for the right thing
What if I use async with AsyncIOMotorClient() as client:?
Hello everyone
are there any links for a beginner (me) to make databases and tables in MSSMS then connect them to my bot?
i also want my bot to create and populate the databases and tables.
hmm
so im doing the whole thing incorrectly from the beginning
this looks like something useful
wait... how do i make my own server? i wanna run everything locally.
anyone here
Hi guys. I'm setting up a daily import of a table to a postgres-db with approx. 140k rows identified by a unique number. It gets updated each morning (new csv). How can I effectively insert any new rows and update any existing rows with sqlalchemy?
The file I receive has 203 fields, and I add two fields (date added, and date updated). I have tried generating an INSERT ON CONFLICT with a generated set-clause using the excluded tables, but it always gives me a "syntax" error on "ON CONFLICT". I'm afraid I've dug too far and I've missed something obvious.
Can you share your current code? 🤔
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Why did you mention sqlalchemy if you use raw sql? 🤔
You plan on using it?
I don't think copy supports on conflict
insert does though
Oh shit wrong code sorry 🥴 yeah learned that the hard way. This was with psycopg2
I'll get back with the new code
That should of course be Insert into but the same set clause and column names.
I'd like to use sqlalchemy but I assume I'd then have to insert line by line? Or is there a bulk / batch insert feature I've overlooked?
There's bulk insert with sqlalchemy core, sqlalchemy orm has "native" support for bulk inserts since 2.0
You had to use bulk_insert function before iirc, now if session has multiple objects it should bulk insert them
Does it handle conflicts like postgresql "upsert"?
Orm doesn't provide on conflict functionality
You have to either use core or manually fetch these entities
When you say core, are we back to generating sql statements then?
Kind of, but not manually
Sqlalchemy has core and orm, core features a query builder that you can use
And you can use orm in other places that don't need to use core-specific features like on conflict
So the second answer here: https://stackoverflow.com/questions/43300886/what-is-the-difference-between-sqlalchemy-core-and-orm
Is an example of core? You still have to build the query "manually", but the connection object had methods to execute it differently?
Stack Overflow
What is the difference of purpose between SQLAlchemy Core and SQLAlchemy ORM?
So no select(Table).where(etc)?
Ehm, no, they're just executing textual sql
I'd read official documentation
hey is there any free postgressql hosting site? i got one planetscale but it's using mysql
{
jutsu:["",""]
}```
Also , I want to make `jutsu` column which holds multiple value like described in json. is there any way to do in `postgressql` or `mysql`I think this will solve my issue.

Hey what is the best way to speed up search results from websites aka. making db-queries? Ive been indexing a few fields but the performance is not where i want it to be.. my db has like hundreds of thousands of entries and i have many search query parameters....
i read up on ElasticSearch but it seems tricky to set up in Django
Hi! there is a way that the database give me the data in a list and not a tuple?
Depends on the database module you are using, for sqlite: https://docs.python.org/3/library/sqlite3.html#how-to-create-and-use-row-factories
How can i make that fetchall returns me a list in pymysql?
hi Im quite new to sqlite3, i have like no experience in it and im trying to make a basic little program that just creates a table and adds a row to it but im getting a syntax error
conn.execute('''CREATE TABLE ACHIEVEMENTSMAINLIST
(ID INT PRIMARY KEY NOT NULL
ACHIEVEMENT_ID INT NOT NULL
GOAL INT NOT NULL)''')
conn.execute("INSERT INTO ACHIEVEMENTSMAINLIST (ACHIEVEMENT_ID, GOAL) "
"VALUES (1,1000)")
conn.commit()
cursor = conn.execute("SELECT id, achievement_id, goal from ACHIEVEMENTSMAINLIST")
for row in cursor:
print(f"ID = {row[0]}")
print(f"ACHIEVEMENTID = {row[1]}")
print(f"Goal = {row[2]}")
conn.close()
it says the syntax error is near "ACHIEVEMENT_ID"
oh it requires commas my bad
hey guys, I have a data analyst interview with a focus on SQL experience, any tips and advice for the live technical interview? It'll be about an hour long.
Good idea I guess to refresh SQL knowledge 😊
Otherwise I recommend as most important just to prepare most comfortable development environment in advance for yourself
And checking that your microphone and web camera works for the chosen way to connect. Plus that u have backup instruments in case first ones fail 😅
have never done in live interview, so very nervous on if they'll ask SQL concepts or just queries can't tell
Well, they can ask about what are transactions
Or write some queries (simple ones with Joins or more)
And etc
@wise goblet any help?
why doesn't cur.execute immediately return results
why do i have to call cur.fetch or something of the sort
localhost 🙂
Aren't you connected to the internet?
savage reply🫡
Yep, I doubt you'll find something good for free
bro so please tell me the second question
yes it's good
{
jutsu:["",""]
}```
I want to make `jutsu` column which holds multiple value like described in json. is there any way to do in `postgressql` or `mysql`What kind of values?
strings
For what? 🤔
Most common way of storing multiple values per entity is using one-to-many relationships, postgres has support for arrays and json, but in most cases you need a relationship
{
"character":[
{"image":"https://user-images.githubusercontent.com/68345524 /212600493-b83bb071-54d2-483a-b6d4-43cb10e0e43e.png",
"name":"naruto uzumaki",
"nature":["wind"],
"clan":"uzumaki",
"father":"minato namikaze",
"mother":"kushina uzumaki",
"jutsu":["rasengan"],
"id":"72ba4633-c8cf-4a48-8a6d-e442bfae96f3"
},
{
"image":"https://user-images.githubusercontent.com/68345524/212600605-ee521f06-4c4f-4b1f-84a0-9cc365562ba0.png",
"name":"sasuke uchiha",
"nature":["lighting","fire"],
"clan":"uchiha",
"father":"fugaku uchiha",
"mother":"mikoto uchiha",
"jutsu":["amaterasu"],
"id":"c7a15929-fc05-4324-8b36-827116f3db1a"
}
],
``` here's my json?You need a relationship
any why to hold multiple values?
so you want me to make nature table and link it with character?
I think that would apply to all fields - nature, clan, father, mother, jutsu
father and mother wil too comes under character
why null one empy null row inserting with current

we are unlikely to be able to answer without seeing the query you used and also any triggers you may have defined 🤔
question incomplete
if i have a class which is accessed from different threads and has a sqlalchemy model as its attribute, should i only save the id of the object and define a property which returns the object from a query or what is the smartest and cheapest way?
how do i retreive data ...im using sqlite
@client.command()
async def adduser(ctx, member: discord.Member = None):
async with aiosqlite.connect("main.db") as db:
async with db.cursor() as cursor:
a.append(ctx.guild.id)
data = await cursor.fetchone()
if data:
a.append(ctx.guild.id)
await ctx.send('Added to list')
else:
a.append(ctx.guild.id)
await cursor.execute('INSERT INTO users (id, guild) VALUES (?, ?)', (member.id, ctx.guild.id,))
await ctx.send('Added to list')
await db.commit()
for e in a:
await cursor.execute('SELECT id FROM users WHERE guild = ?', (e))
this is the code i use to add user to db
idk how to get the data
here pass three rows but getting 4 rows with without sr_fulfilment value which 'NO' and see last row which first value inserted without quantity.

hi! please post the query you used, this new screenshot you posted isn't exactly helping us in debugging why you are seeing what you are seeing.
?
Anyone got psycopg3 working with SQLAlchemy 2.0?
can someone help me out on how to export to an excel file what my python console prints out?
There are a few libraries like this but I've never bothered with them: https://www.geeksforgeeks.org/writing-excel-sheet-using-python/
Unless you really need to go direct from Python to XLS, I would use CSV instead (which also opens in Excel)
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
how do i use csv?
the csv library
how
raise ValueError("If using all scalar values, you must pass an index")
ValueError: If using all scalar values, you must pass an index
i get this error when i try csv
!paste your code
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
soup = BeautifulSoup(response.text, "lxml")
name_tag = soup.select_one("h1#HEADING")
if not name_tag:
print('hotel has no name')
continue
data['name'] = name_tag.text
script_tag = soup.select_one('script:-soup-contains("window.WEB_CONTEXT={pageManifest:")')
script_text = script_tag.text.replace('\', '')
email_split = script_text.split('"emergencyEmail":"')
email_address = None
if len(email_split) == 2:
email_address = email_split[-1]
email_address = email_address.split('","')[0]
data['email_address'] = email_address
print(data)
if not email_address:
print('Hotel has no email address')
time.sleep(5)
time.sleep(5)
Hi! In pymysql, how can i get data on a list instead a tuple with fetchall?
I think you can just use list(result)
did anyone here uses peewee? is there a way to db.init(pool)?
I try it, but idk why it doesnt work
Gimme one min, i'll explain
i mean, it transform the tuple on a list, but when i try to found a value in that list, it doesnt get it
How did you try to find it?
how i write code here? xd
thanks
lista = list(result)
if acker in lista:
print("u already register!")
else:
all the code to insert into database the user
like that
But even if acker is in the list, it does the else code
can you print out result?
you can hide fetched results, but i think you'll understand what i mean
fetchall() returns you list of tuples as i remember, so you need to specify which tuple you want to use
and also as i remember, each tuple = row
so ```py
for row in result:
if acker in row:
do_smth()
You don't even need to convert it to list, you can search for values in tuple

so only what's left is to check how fetchall() output looks in your case
can i add you? for dm but tomorrow, i gotta sleep
I think my answer is exhaustive, you can ask again when you encounter problems here :) There's many of smart people that can help you

Hello, curious if anyone has any experience with Python to MySQL integration - specifically, using TKinter to use a button to return data from a data frame? Hope I'm in the right spot. Thanks for the time!
hi hi, how can i do to check if the user is already in the table? i try it this way but it doesnt work, also this is how fetchall give me the data

Hey, in you code how did you retrieve the data from db?

is there any reason you are querying all rows in db and looping through it to find user?
you can just add condition WHERE user=member
right now, you are getting all users and then looping through it, so on every else case it will insert new row in db for that user
also you prob want to use discord unique user id instead of their name#discrim
ohh thanks
there is my database

searching for ammount of days i gather date

i wanna get the avg per day

but the code count wrong idk why

select julianday('2023-01-19') - julianday('2023-01-05') -> 14.0
925 / 14 = 66,07...
The min and max date is for main_category = salary in this case, the first one was over the whole table.
Hello , i need urgent help with Databases / Sql / Oracle, please dm me. Thank you
Hi!
It's better, faster and easier for everyone to ask their questions here or in the help threads
thanks
How bad is this?

It's not bad, but I think you don't need a BaseRepo class 🤔
And you don't need a try_commiteither
And you don't instantiate your repositories anywhere
Using this template, but want to make simple "rollback" on errors
https://github.com/Tishka17/tgbot_template/blob/master/src/tgbot/services/repository.py
GitHub
Contribute to Tishka17/tgbot_template development by creating an account on GitHub.
How can i use session.add or session.add_all then in other functions?
As i understand, repository used for db queries, don't instantiate means that i must use something like
repo.add_user(<parameters>) and nothing more in handlers?
Where to tell database to commit then..
Sqlalchmy should automatically rollback if you don't commit your transaction
You could commit your transaction in a middleware or manually at the end of your handler
like this?

from sqlalchemy.orm import Session
class UserRepository:
def __init__(self, session: Session) -> None:
self.session = session
def create_user(self, id_: int, username: str, first_name: str) -> User:
user = User(id=id_, username=username, first_name=first_name)
self.session.add(user)
self.session.flush()
return user
def main():
with sessionmaker.begin() as session:
repository = UserRepository(session=session)
user = repository.create_user(...)
sessionmaker.begin should automatically commit transaction
Can i ask for which purpose you return user from repo if it adds user to session inside create_user function?
from sqlalchemy.orm import Session
class UserRepository:
def __init__(self, session: Session) -> None:
self.session = session
def create_user(self, id_: int, username: str, first_name: str) -> User:
user = User(id=id_, username=username, first_name=first_name)
self.session.flush()
return user
def main():
with sessionmaker.begin() as session:
repository = UserRepository(session=session)
user = repository.create_user(...)
session.add(user)
So you can actually use it? 🤔
Why would you add user into session outside of repository?
O.o i just need to add new user to database, if i need to change something i think it's better to use model.. wait, i need to learn more about this
I just don't understand how i can use returned user 😅
What do you mean by "how"?
@lunar pier
You can just use it, 🤔 Also about adding user to the session - your modified code won't work since user is added to a session after it's flushed (objects sent to db), so you have to first add it, then flush the session.
And if you want to use repository pattern underlying storage implementation shouldn't leak out of your repository, in your case you use repository.create_user and immediately use the session
The reason is why i don't understand is because i don't understand what create_user returns to me :)
I'll read more of sqlalchemy docs and then come back to this question
I can't even imagine rn how repository pattern can leak my storage implementation 😅
Like, user typed /start, handler catches it, inside handler function i can just use context manager to call create_user and after this i don't need session anymore, i can just return one indent back... If i need to change smth, i'll just open another context
idk, i thought sqlalchemy gives enough security out of the box, for "private" bot with registration i think no problems will appear :)
It would return a sqlalchemy model to you 🤔
def main():
with sessionmaker.begin() as session:
for i in range(100):
repository = UserRepository(session=session)
user = repository.create_user(...)
print(f"here i have only last user inside {user}")
let's imagine i create 100 users in a loop, what can i do with this returned value?
I can't find anything in docs about that
About what exactly?
about this returned user 😅
User would be a sqlalchemy model that you define, you can use it in other parts of your program that need that model
like... i imported my model on top, why should i need returned user from here?

You don't, but since we create user model in create_user method we can return it if you want to use it after it was created
as i understand, user was written in this variable just to use it with session.add()
oh wait
waitwait
but i imported this, can't i just use this class?

Let's imagine following situation: When you create a user you want to execute some extra logic, for example create some related model, you could do it this way:
user = user_repository.create_user(...)
some_related_thing = some_repository.create_something(..., user=user)
sorry for my stupidness, can you point me in doc where i can find info about this please, i think my questions won't end...
What do you mean by using it?
i started learning ORM like few days ago 😅
It's fine, different orms use different approaches when it comes to saving and querying your objects
Are you familiar with REST APIs? It would be a bit easier to explain it that way
maybe i can use returned user variable to search for it in database?
user = user_repository.create_user(...)
stmt = select(User).where(user)
No sorry, didn't get to REST rn, don't need it in my smol projects :)
No, just wait 😅
You're making a bot, right?
Well, let's imagine you want to create a ticket, you'd have two repositories - UserRepository and TicketRepository:
class UserRepository:
def __init__(self, session: Session) -> None:
self.session = session
def get_user_by_telegram_id(telegram_id: int) -> User | None:
stmt = select(User).where(User.telegram_id == telegram_id)
return self.session.scalar(stmt)
class TicketRepository:
def __init__(self, session: Session) -> None:
self.session = session
def create_ticket(title: str, user: User) -> Ticket:
ticket = Ticket(title=title, user=user)
self.session.add(ticket)
self.session.flush()
return ticket
You can use these two repositories to abstract how you create your objects, so your business layer doesn't have to deal with underlying implementation
async def create_ticket():
with sessionmaker.begin() as session:
user_repository = UserRepository(session)
ticket_repository = TicketRepository(session)
user = user_repository.get_user_by_telegram_id(some_user_id)
ticket = ticket_repository.create_ticket(title=some_title, user=user)
This code won't work since we don't get user id and ticket title from anywhere, but I think you should get the idea 🤔
We get user by his telegram id, then create a ticket for that user
Then you can use created ticket model to send a message with it's title, id, etc
Whatever behavior you want to implement
Oh, i can use it with code above py def main(): with sessionmaker.begin() as session: repository = UserRepository(session=session) user = user_repository.create_user(...) ticket = ticket_repository.create_ticket(title=smthng, user=user)
Yeah, if you want to create a user and immediately create a ticket too
So, i think i understand.
when i INSERT something, sqlalchemy returns this inserted row to me, if i use add_all, i get list of rows back.. or something like that, so i can use this specific row to modify it or find relations or whatever i want to do with this specific row
so i don't get entire model back, i get specific user back...
I don't think session.add returns anything
It doesn't even touch the db, it just adds object to a session
sorry, not that
interaction with model user = User(id=id_, username=username, first_name=first_name)
That just creates a User model, it doesn't do anything on itself either
i think i understand model a bit different, for me model it's columns in table, and this line above using predefined model to insert some data(row) into table
that's how i see it from newbie view :)
Yeah, model is mapping of a row in a table to a python object
Honestly sqlalchemy has a great tutorial but documentation is hard to read 😅
^ this... yes! I can't even thank you enough for this help
It's not hard, but it's complicated, it has tooo much of .. everything
You can jump straight to orm, or read it top to bottom https://docs.sqlalchemy.org/en/14/tutorial/orm_data_manipulation.html
There was a tutorial...
i moved to sqlalchemy from peewee like .. yesterday, and started with peewee around 3 days ago, honestly i used pure sql with sqlite before, now i make some docker compose for postgres and wanted to do everything properly this time :)
If you already used sql maybe it would be better to start with sqlalchemy core and move to orm later 🤔
i'm using my projects to learn and orm is what i wanted to learn when i was getting headaches with pure sql
sqlalchemy orm uses core under the hood, so you could learn both 😉
my brain will turn into pumpkin if i try to learn them both
im using sqlmodel / sqlalchemy, and im wondering if there's any reason why a primary key select statement might fail to return data, yet when i try to commit new data right after, it will error with that key already in the DB
Can you share a reproducible example?
its not very reproducible, least not that i know how to, but the code part that is erroring is the await db.commit():
async def fetch_user(db, user_id: str | int) -> dbmap.User:
try:
data = (await db.exec(select(dbmap.User).where(dbmap.User.id == str(user_id)))).one()
if data:
return data
except NoResultFound:
pass
data = dbmap.User(id=str(user_id))
db.add(data)
await db.commit()
await db.refresh(data)
return data
my guess would be race condition / another "thread" creating after the first one failed to select
do you know of a way to add "on conflict do nothing" to the commit? or should i do a try block?
What DB are you using?
postgresql
Hmm, I don't think that should be a thing in postgres 🤔
I mean the behavior you're seeing
(sqlalchemy.dialects.postgresql.asyncpg.IntegrityError) <class 'asyncpg.exceptions.UniqueViolationError'>: duplicate key value violates unique constraint "botsettings_user_pkey"
DETAIL: Key (id)=(596359299236626453) already exists.
Perhaps you have other data pending in your session?
Is that a primary key of user table or of another one?
Can't tell for sure by the name
class User(SQLModel, table=True):
__tablename__ = "botsettings_user"
id: Optional[str] = Field(default=None, primary_key=True)
Maybe there's a problem with your select then
If it's a discord bot you can use begint instead of strings
For user id
it is, its just a very old db, that i didnt make, that im putting sqlalchemy onto
Could you try
async def fetch_user(db, user_id: str | int) -> dbmap.User:
data = await db.scalar(select(dbmap.User).where(dbmap.User.id == str(user_id))
if data is not None:
return data
data = dbmap.User(id=str(user_id))
db.add(data)
await db.commit()
await db.refresh(data)
return data
Also I'd recommend only calling commit once at the end of your command/operation
You might want to use flush here instead
looking at my friend's code which is trying to decouple a db from a discord bot we're doing
is it normal to have upwards of 50 functions, most of them < 5 lines
doing extremely similar things?

I'd say you should fetch whole user and update all fields at once too
You should map your row to an object, for example to a dataclass
It would be easier to work with it compared to setting and getting multiple properties from your db one by one
wouldn't that have performance impacts?
how would a dataclass update correspond to a row update?
- You wouldn't notice
- They most likely already doing multiple db queries where only one could be made
You'd have to manually call a function (e.g. update_user) with that dataclass
oh
i'm using mysql lol
And? 🤔
What is the datatype and collation of your MySQL fields?
Not quite sure if this works because I often have similar problems myself that I spend time in fixing but I suggest you try something like that https://stackoverflow.com/questions/41922029/load-data-infile-invalid-ut8mb4-character-string
Stack Overflow
I'm using LOAD DATA INFILE to import some big tables (iTunes EPF).
However, the import fails with this error:
string(52) "Invalid utf8mb4 character string: 'אל נא תלך'"
The table is created like...
I am using aiosqlite to connect to a database hosted on another server machine. I need help connecting to said database. This is what I have to connect to the database
conn = await aiosqlite.connect(host="", user="", password="", database="manager")
c = await conn.cursor()
if val is None:
await c.execute(cmd)
else:
await c.execute(cmd, val)
await conn.commit()
await conn.close()```[2023-01-23 16:24:03] [INFO ] discord.gateway: Shard ID None has connected to Gateway (Session ID: 192e57138a4769e8f773f0412a936e15).
[2023-01-23 16:24:05] [ERROR ] discord.client: Ignoring exception in on_ready
Traceback (most recent call last):
File "/home/container/.local/lib/python3.10/site-packages/discord/client.py", line 409, in _run_event
await coro(*args, **kwargs)
File "/home/container/main.py", line 79, in on_ready
await cmd_team_database(
File "/home/container/main.py", line 129, in cmd_team_database
conn = await aiosqlite.connect(host="panel.practicalhosting.co:3306", user="", password="", database="manager")
File "/home/container/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 137, in _connect
self._connection = await future
File "/home/container/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 102, in run
result = function()
File "/home/container/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 397, in connector
return sqlite3.connect(loc, **kwargs)
TypeError: 'host' is an invalid keyword argument for this function```
Error. I have the user and pass in I just took it outsqlite.connect() (and aiosqlite similarly) takes a file path to the database to open, which is described here: https://docs.python.org/3/library/sqlite3.html#sqlite3.connect
but neverminding the incorrect parameters, SQLite is a file-based database so you would need to setup a network drive to do such a thing, but SQLite isnt designed to be accessed over network: https://sqlite.org/useovernet.html
Generally, if your data is separated from the application by a network, you want to use a client/server database [like PostgreSQL]. This is due to the fact that the database engine acts as a bandwidth-reducing filter on the database traffic.
The database is setup and everything correctly in the drive and everything
I went into the SSH and checked
oh so the database and python script are on the same system? nevermind the network part then, the part you need to fix is your arguments to connect() because it doesnt take any host/port/password parameters (as described by my first link)
What should I use? Its not a local file database
oh you just confused me
right the sqlite docs i linked suggested postgresql because that database is intended to be used over network
you know pterodactyl panels correct?
Im using the database system on that
As Im running a rust server off of the same panel and im connecting the database to the server to make a plugin for the server im working on.
it looks like they use MySQL given what i saw on their front page
!pypi aiomysql is probably what you should be using then
MySQL driver for asyncio.
could I just swap it into this?
conn = await aiosqlite.connect(host="panel.practicalhosting.co:3306", user="", password="", database="manager")
c = await conn.cursor()
if val is None:
await c.execute(cmd)
else:
await c.execute(cmd, val)
await conn.commit()
await conn.close()```Im looking @ it. Yes I can nvm
Thank you for helping me! ❤️
hey can someone help? Im using Postgres in Django, when i try to insert a lot of data at once to the db (reading from a csv file) Somehow at 200 inserts it stops adding data to the database. If i stop the task and try to add data again, it adds another 200 and stops.
Whats wrong?
This structure looks right?

alright, how can i do this code work?

if i try with
if id in result
it tolds me that result is not iterable
if i try with
if id in result```
it doesnt work, help me it getting me stressed
if I recall correctly:
fetchone() should return either None or a tuple like (user, )
fetchall() should return a list, either empty of a list like [(user, ), (user, ), (user, ), ...]
one way or the other, I recommend checking the documentation for those functions
if what I said is correctly, just use fetchone() + if result is None
thank u, im gonna try
if i replace /migrate a ms access to postgres what's a good interface for over 10 people
Do you mean a client, like DBeaver / pgAdmin?
i think so yeah
both the ones I mentioned are free (there is a paid version of DBeaver but I have no idea what extra features you get with that)
those might be great for admin purposes, i'm also thinking of using something like this for non-admin folks: https://www.youtube.com/watch?v=yjPwi3RGvTI

If you want a more direct equivelent to MS Access there is https://www.libreoffice.org/discover/base/ but MS Access itself also supports Postgres via ODBC
Base, database, database frontend, LibreOffice, ODF, Open Standards, SQL, ODBC
thanks for sharing some thoughts
Whats a recommended way to decouple a database from a piece of code.
[1] Create multiple read/write functions for every single variable?
[2] or create a function that processes reads/writes for multiple variables at once?
First is straightforward, second makes data fetching easier to look at.
Thanks!
this is an example of [1]

@fading meteor ^
ooh ok, wait so in what scenarios would [1] be more preferable than [2]?
when the databases have low variable count maybe?
In my opinion - almost newer, If you want a "generic" toolkit to work with sql databases - maybe try using an orm
Otherwise I would write separate queries for functionality you need, without "covering" every column with get/set function
Orms like sqlalchemy can optimize updates, e.g. if you only update one field on your python object it would only update that field in db
does orm stands for Object-relational Mapper Software ?
I see, thanks!
Just without software, ORMs, plural
There are several ORMs written in python
But most popular ones are probably Django ORM and Sqlalchemy
ahh I see I see, tysm 🙏
Bro thank u so much it finally worked
Hi. Anyone used timescaledb here?
I want to use it for my personal project, is it free to use? Or is it paid?

{kind=link}
maybe
def get_user_data( field: str, uid: int):
cur.execute( f"SELECT {field} FROM temp2 WHERE userid = {uid}")
return cur.fetchall()[ 0][ 0]
if(butVal.equals("add")){
rs=stmt1.executeQuery("select * from spendInital where prod_id='"+sgpId+"' and pgId='"+pgId+"' and empId='"+empId+"'");
if(rs.next()){
stmt.executeUpdate("update spendInital set quantity='"+qty+"',remarks ='"+remarks+"',sr_fulfilment='"+fulfil+"' where prod_id='"+sgpId+"' and pgId='"+pgId+"' and empId='"+empId+"'");
}else{
stmt.executeUpdate("insert into spendInital (group_id,prod_id,quantity,remarks,pgId,subgroup_id,empId,sr_fulfilment) values('"+grp_id+"','"+sgpId+"','"+qty+"','"+remarks+"','"+pgId+"','0','"+empId+"','"+fulfil+"')");
}
}
@hollow oar see above
I have a take assignment that says I should show the schema for my postgress database. I'm using SQL alchemy as my orm. What does it mean to show the schema and how can I do it? Thanks
Schema probably refers to a collection of tables/design of your database
Hello everyone. I'm currently working on a project and I want to save data on multiple support. I explain. I made a crawler which yield item as dict, a want to be able to save this items to multiple support. Principally SQLite table, postgresql table, CSV and JSON. Does anyone know a module which allow to save a dict on multiple support effortless? Thanks in advance.
Effortless? I don't think so
Different db engines could be abstracted using ORM though
So the code for the tables?
Like
class Recipe(Base): # 1
id = Column(Integer, primary_key=True, index=True) # 2
label = Column(String(256), nullable=False)
url = Column(String(256), index=True, nullable=True)
source = Column(String(256), nullable=True)
submitter_id = Column(String(10), ForeignKey("user.id"), nullable=True) # 3
submitter = relationship("User", back_populates="recipes")
Basically models right?
Yep, in sqlalchemy models represent tables
Thanks
To be clear: Model class is a table, model instance would be a row
Could someone please Help me with a problem in create a db SQLite in flask
Please 🙏😔
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(name)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///blog.db'
SQLALCHEMY_TRACK_MODIFICATIONS = False
db = SQLAlchemy(app)
But still keeping appears track_modifications erro and doesn't create the db
@commands.command(aliases=['wk', 'toplisteners'])
async def whoknows(self, ctx: Context, artist: str = None):
async with ctx.channel.typing():
username = await self.bot.db.fetchval("SELECT username FROM lastfm WHERE user_id = $1", ctx.author.id)
if not username:
return await ctx.warn(value="You have not set your **username**.")
if not artist:
async with self.bot.session.get(f"http://ws.audioscrobbler.com/2.0/?method=user.getRecentTracks&user={username}&api_key=43693facbb24d1ac893a7d33846b15cc&format=json&limit=1") as response:
artist = (await response.json())["recenttracks"]["track"][0]["artist"]["#text"]
tuples = []
rows = []
async for user_id, username in await self.bot.db.fetchrow("SELECT user_id, username FROM lastfm"):
try:
if_user = ctx.guild.get_member(user_id)
if not if_user:
continue
username = username
z = await self.get_artist_playcount(username, artist.replace(" ", "+"))
tuples.append((username, z))
except:
continue
number = 0
for x in sorted(tuples, key=lambda n: n[1])[::-1][:10]:
if x[1] != 0:
num += 1
rows.append(f"`{num}` **{x[0]}** -- {x[1]}")
embed = discord.Embed(color=self.bot.color, title = f"Top Listeners for {artist}", description = "\n".join(rows))
await ctx.send(embed=embed)```
Using asyncpg and PostgresSQL to try and fetch every row in the database, but getting `TypeError: cannot unpack non-iterable int object`Don't use await in an async for loop.
Also, I think you need to use .fetch(...) not .fetchrow(...)
Command raised an exception: TypeError: 'async for' requires an object with aiter method, got coroutine 🤔
You might need a cursor? Sorry, I have no experience with asyncpg, maybe like:
async for user_id, username in self.bot.db.cursor("SELECT user_id, username FROM lastfm"):
should i store audio files in a database? 🤔 i'm making a clone of spotify and i'm not sure if it is the way
i'm using postgresql for reference
no, an object storage or CDN is more suited
Hi, i am trying to do a liltle project in my class. In this project we use pandas and i would like to know if someone know how to make this work

like, i would like to keep only the data in tab['Location'] that respect the regex ^.({salle}[^b].|{salle})$
idk even know if it's possible but i would reallly like it
PS : i'm using re for the regex
did you try googling pandas regex before asking?
see: https://pandas.pydata.org/docs/reference/api/pandas.Series.str.contains.html
You don't need async for here, just for
Using AsyncPG, how would I return the value of customembedcode = await self.bot.db.fetchrow('SELECT code FROM lastfm_embed WHERE user_id = $1', user.id) in a string form, not <Record Code "value"> or whatever it returns
customembedcode["code"] would likely be the most suitable
Hi all, i'd like to iterate the json2lab function trough all the .json files in the folder, creating a .lab file for each file with the same name. This is the code
import json
def process_parts(data, beatz = None):
if 'parts' in data.keys():
for part in data['parts']:
process_parts(part, beatz)
else:
if beatz is not None:
beatz.extend(data['beats'])
def json2lab(infile, outfile):
with open(infile, 'r') as data_file:
data = json.load(data_file)
duration = float(data['duration'])
all_beats = []
process_parts(data, all_beats)
with open(outfile, 'w') as content_file:
for s in all_beats:
content_file.write(str(s) + '\n')
any suggestion?
I have these requirements and I'm using them to create a table. Can someone please verify if what I've thought of is correct?
Q ......
Create an order endpoint (with unique order reference codes) View a customer's Orders endpoint (get by phone number) Update products and quantities in an order (update total amount payable) Send email to the customer when the order has been created.
What I thought up.....
`Table - orders
What columns table has - unique order reference codes, user phone number (foreign key on user table),
products and quantities
Table - user
What columns table has - user id, user phone number, customer order (foreign key which shows product and quantities)`
yo guys
if i want to implement a whitelist/blacklist feature into multiple services using the same database should i create an extra table for the diffrent ips and just reference to them or save all hosts inside the column of a service?
Hello
Using sqlite3, I want to add data to columns 4 and 5 without adding data to the first 3 columns. How can I do it
You just specify the column names with the insert:
cursor.execute("INSERT INTO tablename(colname4, colname5) VALUES(?, ?)", (value4, value5))
This will insert a row with only values for colname4 and colname5 all other columns will get their default value (or NULL).
Thank you so much
I'm making a spotify clone and idk how to design the tables that would connect playlists and tracks
i'm assuming there's two ways to do it
- make a table that would store all the connections between playlists and tracks. so the primary key would be playlist_id + track_id
2)make a table with playlist_id as the primary key, that would store an array of track_id's
are both ways to do it valid or should i strongly choose one over another?
i guess that is "one to many" kind of situation
Sounds like a Many to Many cardinality, since 1 playlist can have many tracks and 1 track can be in many playlists
So yeah, a relation for Playlists, a relation for Tracks and then a relation to join them would make sense
one track can be in many but i don't really think i need to know that
i think i'm misunderstanding one to many vs many to many 😅
this would be 1 to many

where one playlist is related to many unique tracks
if this was the case, you would be able to add a playlist_id FK to your Track table and it would be fine
however a track can appear in many playlists, so that won't work
Gotcha, thanks 
the actual thing would look like

I guess i'll need a table like this one
CREATE TABLE playlist_to_track(
playlist_id int references playlists
, track_id int references tracks
, primary key(playlist_id, track_id)
);
yep, sounds right
hi! somebody knows how to sum a value to a row in mysql?
for example, i wanna sum +10 to the row coins if the user wins a minigame

an increment can be done with an UPDATE query; ```sql
UPDATE TABLE SET coins = coins + 10
WHERE user = ...
thank u so much bro
i was working with sqlite
and in cursor.execute function i want to pass an f string
like where there is the name of database i want a string variable there
i tried the format method and f strings but i am getting this error ValueError: parameters are of unsupported type
it works fine when i dont use f string
but i dont know how to do it without f strinfs
cursor.execute(f"INSERT INTO {guild} (member) VALUES(?)", user)
Bro don't create separate table for each guild
Make user_id and guild_id column that's it
And you can't insert a user object into database
Use its ID
^^^^
Why does this remind me of neural network 🥶
just one table with all users of all server?
ofc with separate guild ids
yep i am using IDs for both
guild and user
The what is INSERT INTO {guild}
it was id of the guild
and the TEXT type can take int data type too?
In this case you are inserting into a table named str(guild) whatever guild is
yep yep
but when i use that it dont work
but yeah i changed the method
i am not gonna make it separate for each guild
class add(commands.Cog):
def __init__(self, callisto):
self.bot = callisto
@commands.command()
async def add(self, ctx, member:nextcord.Member):
async with aiosqlite.connect("callisto.db") as db:
async with db.cursor() as cursor:
await cursor.execute("SELECT id FROM users WHERE guild = ?", (ctx.guild.id,))
data = await cursor.fetchone()
if data:
await cursor.execute("UPDATE users id = ? WHERE guild = ?", (member.id, ctx.guild.id,))
else:
await cursor.execute("INSERT INTO users (user_name, id, guild) VALUES (?, ?, ?)", (f"{member.name}#{member.discriminator}", member.id, ctx.guild.id,))
await db.commit()
def setup(callisto):
callisto.add_cog(add(callisto))```my code but when I run it in main py and execute the cmd c+add (user) it doesn't add them to the db
not returning any tracebacks
did some reading on database sharding, more specifically about hash based sharding and got to thinking, does hash functions follow benford's law, or do they generally end up with uniform distributions? I assume it's uniform as it's commonly used, but just wanna be sure. Couldn't find any info on it real quick
This:
await cursor.execute("SELECT id FROM users WHERE guild = ?", (ctx.guild.id,))
will select ALL users of the guild. So as soon as one exists you will not insert another one.
This:
await cursor.execute("UPDATE users id = ? WHERE guild = ?", (member.id, ctx.guild.id,))
is a Syntax error (be happy) and would set ALL ids of the guild to the current user. You don't need this at all.
The correct syntax would be "UPDATE users SET id = ? WHERE guild = ?" but don't do this!
This should do:
@commands.command()
async def add(self, ctx, member:nextcord.Member):
async with aiosqlite.connect("callisto.db") as db:
async with db.cursor() as cursor:
await cursor.execute("SELECT id FROM users WHERE guild = ? AND id = ?", (ctx.guild.id, member.id))
data = await cursor.fetchone()
if data is None:
await cursor.execute("INSERT INTO users (user_name, id, guild) VALUES (?, ?, ?)", (str(member), member.id, ctx.guild.id))
await db.commit()
And I think str(member) will do the same as f"{member.name}#{member.discriminator}"
^^
thank you sm!
is there anyone using async SQLAlchemy? I'm trying to get ORM object from db query, but struggling to understand how it can be done..
Using sync queries like this:
user = session.query(User).where(User.telegram_id == 1).one()```
returns db model inherited from declarative_base()
`<class 'app.models.user.User'>`
but using async `session.execute()` returns `row` objects
```py
result = await self.session.execute(select(User).where(User.telegram_id == telegram_id))```
Where should i look in docs... can't find any info about converting `row`The answer is to use scalars(), nwm then...
I have some tables in SQL Server and need to transfer them to Oracle.
I use SQL Alchemy to be able to use <inspect> on SQL Server database, iterate through tables, get their column name and types.
I use this function to convert data types from SQL Server to Oracle:
`def sql_to_alchemy(sql_col_type_dict):
mapping = {
BIT : INTEGER,
DATETIME2 : DATE,
DATETIMEOFFSET : DATE,
VARBINARY : NVARCHAR,
UNIQUEIDENTIFIER : NVARCHAR,
TIME : DATETIME
}
converted_dict = {}
for col, coltype in sql_col_type_dict.items():
if type(coltype) in mapping.keys():
converted_dict[col] = mapping[type(coltype)]
else:
converted_dict[col] = str(coltype).split()[0]
return converted_dict`
but I receive "ORA-00907: missing right paranthesis" error. Why would that be? and how can I work around this error?
NOTE: I used .split()[0] to only get the type, without additions like COLLATE, etc..
helo
sooo I have a 2 columns in my sqlite3 file and want one column have strs and other integers what should I do so python calculates all the total of integer column and print it?
have you tried sum(integer_column) ?
or maybe try to cast it to the pandas.DataFrame(), then you can try
total_sum = df[integer_column].sum()
thanks
retrive int column import sqlite3
Connect to the database
conn = sqlite3.connect('your_database.db')
Create a cursor object
cursor = conn.cursor()
Execute the query to retrieve the sum of the integers in the column
cursor.execute("SELECT SUM(integer_column) FROM table_name")
Fetch the result
result = cursor.fetchone()
Print the result
print(result[0])
Close the cursor and connection
cursor.close()
conn.close()
Hi can anyone help?
When i using this
getinvite = "Select * from invites"
cursor.execute(getinvite)
global invite
invite = cursor.fetchone()
On empty database it crashing hole script
how i can handle it ?
I have the following Table:
ID | Date | Flag 1 | Flag 2
11 | 01/01/20 | 0 | 0
11 | 02/01/20 | 0 | 1
22 | 01/01/20 | 0 | 0
22 | 02/01/20 | 0 | 0
22 | 04/01/20 | 1 | 0
33 | 02/01/20 | 0 | 0
33 | 03/01/20 | 1 | 0
33 | 04/01/20 | 1 | 1
How do I calculate the lag time between flag 1 OR flag 2 changing from 0-> 1
So for example, ID 22 would have a lag time of (04/01/20 - 01/01/20) and ID 33 would be (03/01/20 - 02/01/20).
In SQL
SELECT *,
(
(SELECT MIN(BB.Date) FROM table BB WHERE BB.ID = AA.ID AND (BB.Flag1 = 1 OR BB.Flag2 = 1))
- (SELECT MIN(CC.Date) FROM table CC WHERE CC.ID = AA.ID)
) AS LagTime
FROM table AA
ORDER BY ID
;```note that the actual date subtraction kinda depends on your database and column type
i.e. maybe TIMESTAMPDIFF for mysql
there is definitely a way to convert those two subqueries into joins (by joining on a record that has no prior record and by joining on a record that has no succeeding record with 1-flags) but I'm too lazy to think about that right now
Uh, so Tables BB, CC are just duplicates of AA? If I'm reading that right?
They are new references to the same table
If you want to query the same table multiple times in one query, then you need to give the table multiple names
otherwise if you just do table.xyz then the database engine has no idea which copy of the table you're talking about
I'm not understanding the new references to the table. Is that INTO statement? Could you give an example of giving the table multiple names?
Let me give a slightly different example with separate tables, just to get you familiar with aliasing
Lets say that we are bad at naming tables, and we used a long names like employees_at_our_company and employee_wages_at_our_company. Instead of writing every query like this:
SELECT employees_at_our_company.name,
employee_wages_at_our_company.yearly_salary
FROM employees_at_our_company
JOIN employee_wages_at_our_company
ON employee_wages_at_our_company.employee_id = employees_at_our_company.id
;
``` We can alias the tables, so that the query can become a whole lot easier to read ```sql
SELECT employees.name,
wages.yearly_salary
FROM employees_at_our_company AS employees
JOIN employee_wages_at_our_company AS wages
ON wages.employee_id = employees.id
;```See how aliasing works? You just give the table a new name that you can reference in the query rather than typing out the full table name
(I will explain the table copying mechanism after this)
No, I understand using AS. So, somewhere above there's
With AA as Select * FROM table original as AA, BB as SELECT * from table original as BB
no you don't need with
imagine you are writing a query on an employees table, where you want to select an employee and the person who was hired immediately after them
You would need to join the table on itself
SELECT employees.id,
hired_immediately_after_them.id,
FROM employees
JOIN employees AS hired_immediately_after_them
ON hired_immediately_after_them.id = employees.id + 1
;
this query would be impossible without aliasing the JOIN, since you wouldn't be able to differentiate between the two tables
So, basically left join on itself, but shifting by one.
yeah
typically people just always use AA, BB, CC, etc. and skip trying to give it a sensible name
so sql SELECT AA.id, BB.id FROM employees AA JOIN employees BB ON BB.id = AA.id + 1
if you get rid of the alias then everything falls apart sql SELECT id, (SELECT id FROM employees WHERE id = id + 1) FROM employees this query makes zero sense and the database engine has no idea what "id" references (WHERE id = id + 1???)
Yea, ok. From the previous to this step was what I wasn't understanding.
Jesus, that sentence. My* english man lol
Yea, I think that make more sense. I'm going to test on a small scale and work through it.
Thanks
np
How generally are the digital whiteboards content/data modelled, as they are highly unstructured handwriting and free form of data?
I have 100 sensors that source data every 5 minute. The data include: date, time, measurement value and latitude/longitude for each sensor. How could I structure my tables?
what do you have so far?
100 sensors and a csv file containing data.

I don't think this is a viable approach..
I would make the second table Datetime | DeviceID | Value
And for this kind of data I guess you might want a time-series database but I have no experience with that.
Hi guys I trying to connect to my redis cluster container but can't. My script is always stuck and never responds to anything every time I execute it. Here is my python script :
r = redis.RedisCluster(
host='127.0.0.1',
port=36379
)
r.set('foo', 'bar')
value = r.get('foo')
print(value)```And here is docker compose for my redis cluster :
services:
redis:
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
ports:
- 36379:6379
redis-node-1:
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
redis-node-2:
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
redis-node-3:
# <<: *redis-common
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
redis-node-4:
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
redis-node-5:
image: docker.io/bitnami/redis-cluster:7.0
environment:
- 'ALLOW_EMPTY_PASSWORD=yes'
- 'REDIS_NODES=redis redis-node-1 redis-node-2 redis-node-3 redis-node-4 redis-node-5'
- 'REDIS_CLUSTER_REPLICAS=1'
- 'REDIS_CLUSTER_CREATOR=yes'
depends_on:
- redis
- redis-node-1
- redis-node-2
- redis-node-3
- redis-node-4```Does anyone here know why? any advice and input is greatly appreciated
are the containers all running? do the logs show any errors?
hello, I want to make a function in which I add a date in my sqlite3 database and when that date comes I want the program to print something, like a trial period where a person takes a free trial period and when it expires he recieves a pop-up
Just add a field with the date and everyday you check each date
To avoid the program of checking all dates on days that doesnt have one, I'd save somewhere the days that are in the database
Like if there arent dates in the DB that correspond with the current date, the program wont check the dates
And with the user id on the table it will get the user on the DB