#tooldev-general
1 messages · Page 115 of 1
yeah, pass it as IReadOnlyDictionary
Immutable is ❤️
well, it's not immutable per-se, i know
In that case you can use ImmutableDictionary..
indeed. and more thread-safe iirc
my plan was to start with an empty dictionary of <int, Bundle> and whenever a thread needs to access a bundle for a file, then it would get the bundle from there or open it first, if it is not available.
Then Lazy is perfect
<int, Lazy<Bundle> in that case, right?
be aware that the stuff you access in the construction action needs to be thread safe as well
https://docs.microsoft.com/en-us/dotnet/api/system.collections.concurrent.concurrentdictionary-2.getoradd?view=netcore-3.1
Dict already has this build in
Adds a key/value pair to the ConcurrentDictionary if the key does not already exist. Returns the new value, or the existing value if the key already exists.
That is designed for a different purpose, though. But technically would work... well.. yeah test it
Yes. That's also an option. Just be aware that if multiple threads attempt to access the same bundle in that case you will construct it multiple times.
ah, that is bad then
Where with Lazy + 2nd argument you can lock in that case.
No, not for ConcurrentDictionary, rasmus
what's the magic second argument?
PC servers are restarting now.
A good implementation of call_once is icky.
Yes @thezensei? Multiple threads calling GetOrAdd will run the add action concurrently? Afaik there's no locking there
it should be atomic and block them, thus returning the added value to the second caller
I tend to go for spinning on an atomic.
at least that would be my assumption
spinning on an atomic is good way to lock the atomic 😦
Burns CPU for the waiters when you are blocked during initialization, but is "cheap" when not contended.
For modifications and write operations to the dictionary, ConcurrentDictionary<TKey,TValue> uses fine-grained locking to ensure thread safety. (Read operations on the dictionary are performed in a lock-free manner.) However, the valueFactory delegate is called outside the locks to avoid the problems that can arise from executing unknown code under a lock. Therefore, GetOrAdd is not atomic with regards to all other operations on the ConcurrentDictionary<TKey,TValue> class.
rasmus is right.
i am wrong.
well, but if all other threads also only use getoradd that should work, right?
Not sure if C# has mutexes with separate reader and writer locks, but that's more overhead for regular use.
because it says all other, but not itself
This is the 2nd argument https://docs.microsoft.com/en-us/dotnet/api/system.threading.lazythreadsafetymode?view=netcore-3.1#System_Threading_LazyThreadSafetyMode_PublicationOnly
Specifies how a Lazy instance synchronizes access among multiple threads.
There are a heap of different mutexes in C#
My eyes are now bleeding, I read stackoverflow answers.
lock, Semaphore, SemaphoreSlim, SpinWait and friends, and async/thread local variations
Like, if you want 1 StreamReader per thread, for an instance, you can use ThreadLocal<StreamReader> or AsyncLocal<StreamReader>
but that's extracurricural

😄
ah that would be a first good use case for the new org @mortal bone
have a repo with the tree json files for all releases?
Yeah, I have one
sure, would be great
Mine has the same updates lol
my bot repo has trees from 3.5-3.11 so far but i guess everyone has them

GitHub
An example project on how to use and render the Path of Exile skill tree data - EmmittJ/SkillTree_TypeScript
I have from 0.10.0 to now
@mortal bone yeah, but having it in one central place would be great, wouldn't it?
I added opts.json to most of them, but they don't need it
I can't chuck zips here can i?
Also, all of the images are good
never tried to upload zips here 🤔
Yeah, I have v2 in that repo
ahh ok
patch is up
@mortal bone depends on how many repos you want to have in that org. one monorepo? one per language? or split by content, e.g. one for just the json files?
nothing broke \o/ praise the machine god
5.7GB patch
I would think one for SkillTree Data Json isn't a terrible thing
Hah... my code exploded as I was trying to extract a bundle from the GGPK that was patching.
speaking of exploding. getOrAdd is not thread safe 😦
depends on how lovely your ISP is
@simple ravine you didn't get the memo to install before heist launch? 😄
@dull laurel I did. Then I downloaded the Heist preload torrent and put that in there.
Client decided to delete it and start over.
Great success.
northern internet unimpressed
I sit at like ~10MB/s
The format of stat description files changed. Before there was lang "English", now it is implicit and only present for other languages
we do have a poediscord orga btw, maybe @torpid mesa can merge that with the tooldev orga as its mostly unused atm
@simple ravine Mentions of this in #old-game-news, seems like you have to do the small patch first before you can cancel out and sub in the GGPK.
It outright deleted my ggpk and allocated new empty space immediately. Either way it's already done.
slowly getting forward.
for (int ii = 0; ii < bundleCount; ii++) {
openBundles.TryAdd(ii, new Lazy<Bundle>( () => {
int index = ii;
Console.WriteLine(index);
return new Bundle(Path.Combine(baseDirectory, referencedBundles[index].Name));
}, LazyThreadSafetyMode.PublicationOnly));
}
so i initialize the dict with all the lazy objects, but it seems, the index is always the maximum.
@fickle yew many thanks. progressing now. 🙂 On to the next problem: food.
Remember to eat thread safely.
no concurrency problem here. all mine
Mutual exclusion between food and air unless you know your implementation well.
I've often experienced a race condition between the two, leading to unpredictable behaviour where neither is consumed.
deadlocks with other words
the good thing is, the index works now so far when using multithreads for accessing bundles. now the bundles are the next problem, some blocks won't decompress 😦 I guess its the same problem
using the same stream object in all threads?
no, I don't think so. I instantiate a new one in each bundle constructor
well if things break when u start parallelize
it's a concurrency thread safety issue 100%
indeed. even if I set parallelism to 1 it breaks
I just feel that you shouldn't need parallelism for reading the index stuff
it's so small amount of data
ah no, it's for the decompression. I call index.GetFile(path) for each file I want to have.
and this then accesses a slice of the bundle which itself decompresses the bundles as needed
ah
seems to work now.
well, time decreases from nearly a minute to 8 seconds, while poe and twitch are open (for Data/**/*)
👍
extracting all files on the other hand was a bad idea. memory usage jumped to 16gb and full cpu usage. Guess I need to learn a little more
I haven't audited the ooz library for whether it is thread-safe, but I didn't see any static state outside of command line flags at first glance.
does pypoe's ooz code only work on windows for now?
lol
and how does one obtain the dll? "requiers zao's oozdll"
aaaa the macos client uses a v4 GGPK now
guess that answers my question about ucs32 filenames
Just for filenames and paths. I still don't know why they're doing it but at least it's identifiable now 🤷♂️
@chrome topaz Build https://github.com/zao/ooz from source or https://zao.se/~zao/poe/bun-x64-Release-g53c4c6d.zip
Guess you'd have to smell at some directory entry in the root otherwise to sniff out the format.
suddenly pack check started to work
The distribution story for the decompressor is not optimal yet, but builds on Linux at least.
I guess that's what
GGPK.Bump.exeis for 😄
ggpk.bump didin't work for me
it was in same direction as heist ggpk file
ha, the ooz lib has one comment ... referencing a paper for an implementation of a tree structure (https://db.in.tum.de/~leis/papers/ART.pdf) 😄
@worthy cape thanks
I can't even find the GGPK.Bump.exe. @fossil ermine where's it?
@split forum See news, download in tweet.
Also: GGPK.Bump.exe is only relevant if you downloaded the torrent
my bad, see it now
simply works as defrag
@worthy cape I might be blind, but where in that ooz code is the decompression function?
@dull laurel Middle of kraken.cpp, search Ooz_Decompress.
All it is is a thin wrapper exported with the same signature as the commercial one,
Made a small Implementations page on the wiki for people to list their implementations and tools regarding this: https://github.com/PoE-Tool-Dev/ggpk.discussion/wiki/Implementations
I think implementing just the decompression functions for kraken and the other ones used, shouldn't be too hard.
@worthy cape it's only kraken and leviathan, or more than those two? I mean: have you ever checked that?
Selkie and Mermaid also exist, not sure if GGG uses those
I think Selkie at some place
Should be "easy" to instrument if you're really curious".
depends on how much fun the league is
I tried a c# library that did have partial oodle support made for a fortnite replay thing
and it said "Sorry, Selkie not supported, only Mermaid"
as an exception when testing it
I wonder how much work it'd be to implement a DLL loader on linux or macos that's good enough to run the Oodle vendor DLLs.
they probably have versions for all OSes
@rapid pagoda Funny that you say that...
One old RAD trick is writing one DLL that has no dependencies and can be manually mapped and loaded on all OSes for the arch.
At least back in their Bink or UI days, I forget which one.
If you've already downloaded the Heist update, we've deployed another small patch with some shaders. If you're sitting in the queue, it's worth restarting your client to get these new shaders.
I wonder if it's the shadercache again.
🙀
mh, the kraken.cpp is all static stuff and such. I think I would put that all in the class
@worthy cape Hmm. I saw some imports when I glanced at the DLL but maybe those are for nonessential functionality. I'll have to take a closer look sometime
Yeah, it's the shadercaches again.
Oops.
Either the queues are moving or a whole ton of people just restarted. I just went from like 49k to 36k
it works, raizqt is already in coast
anyone know the new format of GrantedEffectsPerLevel .dat table regarding Quality Stats?
Dev version or Real?
1.4.170
looks like there is three new .dat tables for Quality stuff:
"Data/GrantedEffectQualityStats.dat",
"Data/GrantedEffectGroups.dat",```Oh. 1.4.170 is June. Explains it if the tree is 3.12
@velvet fog do you know the new layout?
I wonder why this code is written so complicated. Basically checks if the lower nibble is 0xC and the upper is 0x3. Couldn't it just check for 0x3C?
if ((b & 0xF) == 0xC)
{
if (((b >> 4) & 3) != 0)
return NULL;
The second test checks that the low two bits of the high nibble aren't set.
That is, it's either 0b0000, 0b0100, 0b1000, 0b1100.
(the topmost bit is restart_decoder, next is uncompressed)
oh, I see. tricky.
it is slowly progressing. got the enum for the decodertypes. :-D
just need to write tests later, probably with the data from poe to check if it works
@dull laurel I think it's a literal translation from assembly, and an awkward one
oh wow, someone really reverse engineered the code then? evil
lol, I think I found the corresponding code. from oo2core7_win64.dll:
1800a304f: 0f b6 c1 movzbl %cl,%eax
1800a3052: 24 0f and $0xf,%al
1800a3054: 3c 0c cmp $0xc,%al
1800a3056: 75 79 jne 0x1800a30d1
1800a3058: 0f b6 d1 movzbl %cl,%edx
1800a305b: 8b c2 mov %edx,%eax
1800a305d: c1 e8 04 shr $0x4,%eax
1800a3060: 83 e0 03 and $0x3,%eax
1800a3063: 83 c0 04 add $0x4,%eax
1800a3066: 41 89 00 mov %eax,(%r8)
1800a3069: 83 f8 04 cmp $0x4,%eax
1800a306c: 7e 08 jle 0x1800a3076
yep, exactly. the 0xf and 0xc stand out
@dull laurel Author is definitely in the RE crowd 🙂
Rad games tried a DMCA takedown.
https://github.com/github/dmca/blob/332f1896902c4f5780a249c0be5a22b75a4d784e/2016/2016-08-30-Oodle.md

GitHub
Repository with text of DMCA takedown notices as received. GitHub does not endorse or adopt any assertion contained in the following notices. Users identified in the notices are presumed innocent u...
damn, thats serious
Hah. Wonder how it's still up then… 
I think GitHub decided it wasn't in violation
I should still separate my bun lib from the rest of the sources, is icky having it all together like that in production.
Only relation is that I was too lazy to do submodules 😄
Is there an out-of-the-box .dat visualiser? (similar to VisualGGPK?)
Patch 5 min ago.
Maybe they've fixed the trigger_on_kill_vs_frozen_enemy_% stat description still having an old %1% format placeholder (instead of the new {0} or {1})
@vapid pulsar I've skimmed the discussion thread, the DMCA was issued in the belief that the DLL was illegally obtained and block was reversed once it was sorted out.
@timber path I am working on one, but pypoe has a visualizer bundled with it
Ah, interesting
Is there repo of dat specifications, or a lib for reading the dat files that works currently? is https://github.com/MuxaJIbI4/libggpk up to date/recommended?
@lean spindle The universal reference for people tends to be stable.py from PyPoE.
Noted, thanks!
You can export it via an ordered dict to JSON to consume the spec in another language.
#!/usr/bin/env python
from PyPoE.poe.constants import VERSION
from PyPoE.poe.file import specification
import json
with open('stable.json', 'w') as f:
json.dump(specification.load(version = VERSION.STABLE).as_dict(), f, indent = 4)
Many thanks for the explanation o7
undeceided whether I should rework my viewer first or just mess with the changed dat files for now >.<
mess with the changes for now 🙂
I found it odd that kraken.cpp is just a single file, until I noticed that it deals with multiple formats, including kraken. I guess it should be called oodle.cpp to be correct, or something like it.
Learning a lot from that C++ code.
@timber path I am working on one, but pypoe has a visualizer bundled with it
@mortal bone i am aware, but i can't simply feed it a dat file... I have to feed it a content.ggpk, which isn't supporting the new file format yet... So not really and option? Unless i'm unaware of hidden features?
PoB updated with partial support for all the new gems and stuff
Took me a while to understand this one in Kraken. Initializes memory, either in 64bit blocks, if the source is at least 64bit, otherwise goes byte by byte.
if (offset >= 8)
{
for (; i + 8 <= length; i += 8)
*(uint64 *)(dst + i) = *(uint64 *)(src + i);
}
for (; i < length; i++)
dst[i] = src[i];
My code is not working yet, but if someone wants to follow and double check, I can check it in a testing branch --> https://github.com/totkeks/poe-tools/tree/noodle
Has anyone figured out how to finesse an ignite hexblast dps into PoB? I tried fiddling with Stormfire's mods and fiddling with resistances. but nothing seems to work
I'm prepared for the most janky-ass temporary solution
@dull laurel The function is rather subtle. It copies from earlier in a buffer to later in the buffer, and the range to copy could overlap while copying. If the distance between the locations is >= 8, it copies in eight byte chunks as far as it can go, and fills the tail 0-7 bytes one-by-one. If the distance is smaller, the eight-byte copy is unsafe as the source and destination overlaps.
Consider this example for a case where the length is larger than 8 but it still can't do large chunks:
byte buf[12] = { 'x', 'y', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
copy_match(buf + 2, 2, 10);
// ['x', 'y', 'x', 'y', 'x', 'y', 'x', 'y', 'x', 'y', 'x', 'y']
If you're reimplementing this, you need to ensure that copying don't assume that the range overlaps, this is essentially memmove.
odd, it was uised once in the code, memmove, but not for this piece.
QuestVendorRewards.dat removed?
They had a bug regarding quest vendor rewards that was hotfixed, so maybe its related.
@dull laurel Ah no, it's not equivalent to memmove. memmove ensures that the source range is accurately replicated in full into a possibly overlapped range. This code explicitly wants to consider the destination as part of the source left-to-right.
Guess I need to write some unit tests now for some test driven development
Yeah I think that's the only way to get through it
Every part of the code is there for a reason, and it's all subtle 😄
To be fair, subtle code doesn't necessarily make it good 🙂
Which is why I'm trying to make it as verbose as possible. Or at least as I like it
@timber path ah, no I don't think there is something that can view an exported dat file. That is a good idea though
Had some generic dat viewer in my hideout project but that is not conducive to getting at the data and needed the JSON flavor of spec which sucks to edit interactively. It also assumed the spec was correct.
I mean the oogle source code looks like it was at least partially sourced through something like hexrays, the code is more like full of traps, rather then 'subtitle'.
Explode things and use the exploration one someone here made recently?
I don’t know how far Omega got on pypoe but current trunk speaks bundles to some extent.
I am trying to figure out a way to display this haha
Currently I am reading in the index bin and building up a folder structure from that, but you also need the loose files that aren't in the bundle
Haven’t really looked at the loose files, thought it was mostly voices and videos?
I am thinking of a virtual/physical "directory"/"file"
Yeah, it is
There are some loose .bank and .day files
well, the good news is, my test doesn't trigger any exceptions in the parser. just the decoded data is missing for now 😄
@compact isle fyi the 'map region' search on the site is broken
Seems like the block headers in Kraken are at least somewhat designed like lzma, as it checks the same constraints in some places.
var upperNibble = (oneByte >> 4) & 0xF;
is equivelant to
https://github.com/kobolabs/liblzma/blob/87b7682ce4b1c849504e2b3641cebaad62aaef87/src/liblzma/lzma/lzma_decoder.c#L996
Eg something like this
struct BlockHdr {
unsigned char is_keyframe : 1;
unsigned char is_compressed : 1;
unsigned char unk0 : 1; //
unsigned char unk1 : 1; //
unsigned char reset: 2; // When 3 reset properties of the decoder?
unsigned char unk2 : 1; //
unsigned char unk3 : 1; //
unsigned char has_crc : 1;
unsigned char encoder_id : 7;
}

GitHub
Contribute to kobolabs/liblzma development by creating an account on GitHub.
Did anyone (start) work(ing) on the new Heist dat file definitions?
yesterday someone was talking about it
I'd reckon that chuan, the PoB crowd and maybe Omega would be most on it, I'm completely out of the loop.
@dull laurel fwiw, https://github.com/powzix/ooz/tree/master/testdata has a bunch of test files in each of the compression formats

GitHub
Open source Kraken / Mermaid / Selkie / Leviathan / LZNA / Bitknit decompressor - powzix/ooz
it lacks the decompressed values though for comparison?
it's a standard compression test suite, http://sun.aei.polsl.pl/~sdeor/index.php?page=silesia has the originals if you need them
oh thats great. thanks
is someone dev from poe overlay fork here? my app crashes when selecting standard
that would be @timber path
@pseudo ocean I recommend filing a bug on github.
whitefang has already helped and cleared the bug, should i still file it?
If it's fixed upstream already, nah.
@pseudo ocean it's a known issue that can't be resolved. There might be an open bug for it already. I think there's no need to file it. Thx for your patience though 🙂
@timber path we have the definitions for the new quality stats as that’s all that we needed. https://github.com/PathOfBuildingCommunity/PathOfBuilding/pull/1396/files
@velvet fog I'm curious how you get new uniques on your website so fast. Do you watch the river for them?
Also @velvet fog they removed the curse skill tag so a bunch of the tags now have a different reference number https://github.com/PathOfBuildingCommunity/PathOfBuilding/commit/fa2d00a27167e218ccdb2dd22f8df712dd931f9b. There’s a small mistake in the file where I put SteelSkill as 18 instead of 108 btw
I would assume he watches the river
@carmine merlin thx for the info and specs. I was more referring to the HeistJobs.dat etc... Maybe someone else has those specs and is willing to share. If not, then I'll dive into it myself and share my findings.
@golden bane yes, I'm watching the official site autocomplete file
@carmine merlin wow, thanks
The actual files vs those in the bundles are split out right now, but I can lazy-load files from the index.bin which is cool.
I don't have any of the .dat specifications stuff loaded up, but that has been done a few times already. It would be really nice to turn this into a complete file system and hide away a lot of how files are loaded which makes it easier to separate out the dat specification (and other file types) loading.
You could maybe just map it into the file system https://github.com/microsoft/ProjFS-Managed-API

GitHub
A managed-code API for the Windows Projected File System - microsoft/ProjFS-Managed-API
Don't even need interopp with other tools that way
@pseudo ocean I implemented that for old GGPKs to some extent. It's not quite optimal and has some strong opinions on file name comparisons.
I was thinking more of a literal file system implementation
Got to do some annoying things to get it to not do a lot of tombstoning and other writing/lazy stuff.
Something like this: https://github.com/System-IO-Abstractions/System.IO.Abstractions
My asset viewer tooling has a layered read-only VFS that mostly works.
Haven't gotten around lifting the new bundle stuff in there yet, as there's been more urgent things to do.
Yeah, I would basically do read-only. I don't need the option to write haha
Stole the low-level GGPK stuff to get Bun up and running.
(libpoe/format/ggpk.* in the ooz repo is from there)
Yeah I remember fron the demo code that the way the itterators and stuff where set up it made it kind of incompatible with the underlying database for my usecase
I thought it would have been maybe better with he managed api
I pushed my code here: https://github.com/EmmittJ/GgpkParser it isn't pretty, but it is there
GitHub
Contribute to EmmittJ/GgpkParser development by creating an account on GitHub.
@mortal bone you can also steal from my code 😉
Good job Emmitt. Your code is clean and reads like prose, as always
I can learn something from this about code structure and class structure. Really nice.
@compact isle There's a typo in Fated End: "inflcit" instead of "inflict"
would be cool if they changed the ctrl+c on items to copy the advanced tooltips. then you don't have to guess some things
I actually did use some stuff from white fang lol the ooz dll decompress wrapper and the fnv class.
I wonder what changed in 1758646762025641699, patch supposedly only touched the EXEs and the index.
Ah, I don't have any tools around diff checking haha I wouldn't know
It would be nice to have a tool for diff checking and mocking up the file specifications
is there a chat command btw do leave a party? or only /kick <mycharname>?
Iirc, you can kick your own character name, there isn't a way to /leave_party or anything
I had a poediff command back in my Rust project for v2 GGPKs, but that's not overly useful now.
Yeah, sadly you would need to decompress/export the entire tree
@mortal bone I'm thinking of hashing the file entries and dump out filepath -> hash to a reference JSON, which you could use to determine which files changed, so you don't necessarily have to keep both the old and new full datasets around.
You could technically have rename detection too, but that doesn't work well when there's duplicate payloads.
Anybody know if the guy ( Pboutin ) that devs POE Chaos Recipe Overlay hangs out in this discord?
Hey guys, I'm having issues with installed awakened poe trade. Any good alternative?
It says there's already an instance on my pc, when I prompt to reinstall the installer instantly crashes
@tiny wharf There's a github issue tracker if you want to file a bug against it and troubleshoot.
@worthy cape ah, that is true. I was thinking of diffing the files contents, but that wouldn't get you very much haha
I've hard-assumed that SHA256 doesn't collide in my deduplication project.
The likely hood of a collision in the file contents is so low haha
If you had any worry at all you can always switch to sha512
@compact isle "20% increased Elemental Resistances " on Replica Veil of the Night has trailing whitespace
"Lose 1 Fragile Regrowth each second " on Replica Fragile Bloom has trailing whitespace as well
if you get a sha256 collision we have much worse problems than your tool not working properly
Does api.pathofexile.com/leagues supposed not to show private leagues I participate in?
Hm that doesn't look right...
what should it actually show?
Woo, patch coming today https://twitter.com/pathofexile/status/1307803393566466049
does any1 know how to make a special rule on filterblade for corruption implciits?
i tried finding a filterblade discord. no luck @earnest radish
thanks
@chrome topaz is it normal for poe.trade searches to take 15+ seconds to load results?
also, Replica filter isn't working
https://poe.trade/search/asanirasimenob
Changing replica to "no" and searching always resets it back to "either"
Hi guys, I'm trying to run RePoE which uses PyPoE to extract some data from Content.ggpk, but PyPoE throws an error 'ooz' is not recognized as an internal or external command, what am i missing? Searched for it through the history of this channel but I'm not sure how to add that lib.
@deep girder It's a standalone program that can decompress the format used to compress blocks in the new bundle system.
hmm, I fould a link to a built version of it, an exe, and your repo, but other than that google returns some very weird results
@wind garden no it's not normal, what search URL takes 15 seconds?
You need either libozz.dll or ozz.exe, my precompiled x64 DLL can be found at https://zao.se/~zao/poe/bun-x64-Release-g53c4c6d.zip
but where do i put the dll? sorry for the noob questions, i know basically nothing about c/c++ development :))
Code seems to be looking at some absolute location on disk at first glance... https://zao.se/~zao/poe/ooz-g53c4c6d.zip for the EXE which should be found anywhere in path.
oh, that ooz.exe did the trick, it's doing stuff now
The EXE is a bit less efficient as it roundtrips via a temporary directory, but is functionally equivalent.
All this will probably be cleaner in the future when the dust settles 🙂
@wind garden and thanks for reporting the replica issue, I went ahead and fixed it now
@dull laurel a correct tooltip with mods would be nice 🙂
I derped with the fixed location. Should work now as long you drop the dll in the python dir
Does someone know all the occurances of the changed format string so I can test against them?
I've seen {n} and {n:+d} so far
hm well assuming my regex work it's just
{n} {n:d} and {n:+d}
[
"{}", '{:d}', '{:+d}',
"{0}", "{0:d}", '{0:+d}',
"{1}", "{1:d}", '{1:+d}',
"{2}", '{2:+d}',
"{3}", '{3:+d}',
"{4}",
"{5}", '{5:+d}',
"{6}", '{6:+d}',
'{7}',
]
@obtuse citrus you missed {}, {:d} and {:+d}
thanks
and {} may not alway 0
could be {} blah blah {} in ClientStrings.dat
and it should be translate as {0} blah blah {1}
can't you used the same library they use to make it easier?
I can't find a libfmt for php implement
Do stash ids get reused when the next league starts or something, it seems like most of my harvest data got superseeded
in stash api river, harvest will move to standard, read only, set not public and change id
Does it first move to standard/read-only and then change the id in a second update?
they may do it at the same time when harvest shutdown but no idea the sequence
Ah
I have some people(stash tabs) stuck in Harvest leagues still, i don't think i skipped an update id.
https://ladder.cld.moe/league/SSF Harvest HC/gamer/tommyrot
Time to play Hunt the Process https://i.imgur.com/Pxc93oX.png
huh
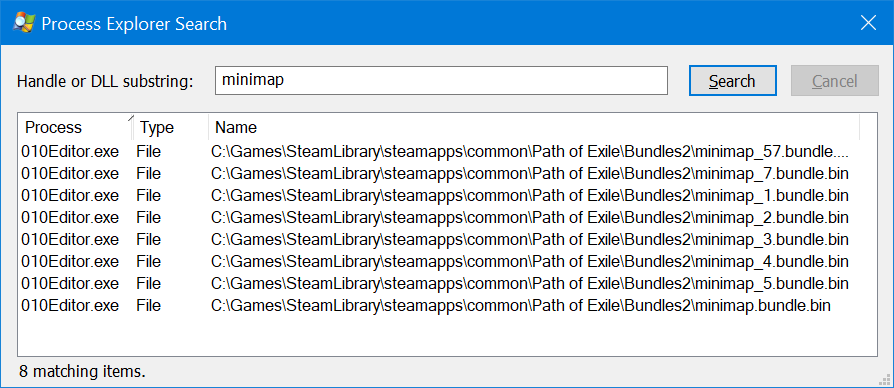
It looks like you have a few 010 editors open
I have no memory of ever opening these 😄
DepotDownloader feels faster now with the new structure of the Steam game, getting like 12-13 MiB/s instead of the past 3-4 MiB/s.
fewer requests, larger downloads
It should be the converse, in the past it was one big file that should streamline well.
I guess that there's some concurrency gains from multiple streams against a backend that doesn't get good single-stream perf.
Still need to figure out how to do delta compression on this new scheme.
Some WIP ggpk/bundle content viewer (based on @mortal bone 's ggpkviewer, hopefully he doesn't mind me using it as an inspiration). I want to add live-definition change watching , file name searching and file exporting to it.
nice man! I was going to start on that today haha
I don't mind at all. That is the point of putting it on github haha
@timber path Mine before the patch: https://i.imgur.com/YvO7PNS.png
There was a tool that someone made that used PoB (headless?) to determine the best mods to search for, based on a build. Anyone recall which tool that was? found it
@velvet fog I had a question today about the level of the curses applied by this mod, but couldn't find the corresponding information on poedb - https://pathofexile.gamepedia.com/Modifier:CurseOnHitConductivityWeaponInfluence1
level 10?
It's present on the wiki for the weapon mod and the ring mods (5), but I can't find the analogue on poedb.
How's the wiki coming along btw?
QuestRewards.dat removed?
Seems so.
The last time it was present was the two tech patches, there might be mention of it in channel history.
How's the wiki coming along btw?
Slowly I suppose
I haven't looked at any of the new stuff, mostly been busy fixing and updating everything :(
I'm trying to figure out how to make and publish artifacts from interim commits and tags on github.
As soon a I look at a YAML file my eyes defocus.
you mean a build pipeline using actions?
I can set up CI (with Actions) that builds stuff, but the workflow to get binaries published for download is not something I know how it's supposed to be done.
https://github.com/actions/upload-release-asset
something like this?
GitHub
An Action to upload a release asset via the GitHub Release API - actions/upload-release-asset
@dull laurel I've found all those fragments of a workflow, but I'm missing some top-level ideas on how a project typically does it
I only used azure devops ci/cd so far, but usually you hook that action to commits on master or a release branch and then always let it do its stuff, when you push/commit something there.
additionally police the branch to only allow PRs there, so you got some control over the releases
Data/*.dat filenames changes between 3.11.2.2 and current, btw - https://gist.github.com/zao/ac3cf45eb556799bb6c484c7bfeee9a4
I guess the client doesn't need a list of quest rewards but it was immensely useful
@obtuse citrus Does PyPoE currently support exporting dat files as json, or is that still being worked on? If the latter, is there any way I can help out? (What needs to be updated?)\
Am currently seeing that apparently everyone is working on their own little viewer lol
Mine's old and to visualize the stuff I need to load for the asset viewer.
Still working on bundle infra, but the league takes time.
Also have like a week of work that somehow got postponed 😛
@worthy cape I setup CI a lot at work. We mostly use Circle CI. And Have a workflow that builds and upload assets to Github tag if a commit is pushed to a branch that end with build
Do people have any plans of combining efforts in this area?
To avoid redundant applications and such
@velvet fog it should be pretty easy to add libfmt to PHP via an extension, do you build the PHP you run?
@lean spindle GGPK viewers are the new trade macro replacements. Not only in that they are the latest trend in new tool development, but also that while they share a great deal of common functionality, their scope, approach, and technology differ based on the needs and interests of their developers. So I don't think it's redundant to have many of them. It's not like they are carbon-copies of another. Just contribute to the one you like most, or even start your own as well.
I know I will rewrite PoB's exporter quite a bit over the next weeks as time permits
This is true enough. At the very least, perhaps we should create a list of the currently available tools on some pubic page, so that people can locate the tools that exist. (perhaps on a page belonging to the Poe Tool Dev org?) Thoughts?
@lean spindle There's already a list on the wiki: https://pathofexile.gamepedia.com/List_of_Path_of_Exile_related_applications
@compact isle could you paste me a link, I can't find it, thanks
ah I couldn't find one either but if there's interest I can probably set one up
we'll probably use it on the website anyway
@compact isle Under PHP8, ffi might be a viable option
oh, wait, not even 8, that's a 7.4 thing
I couldn't get it to build a shared library properly last time I tried
we're still on 7.2 for poe.com 😭
had troubles with fpms crashing randomly on 7.3 >.>
@golden bane a page on the org would be good. I like how vuejs is doing this. They add an "awesome-xyz" repo to the org and put all the links there: https://github.com/vuejs/awesome-vue
At least you're still in support! Barely. :X
yeah I've been waiting for us to switch to 64-bit before doing the upgrade, they changed a lot of dependencies and things
at least preg works fine for stat_descriptions and ClientStrings
if anyone found a libfmt php extension in public domain, please notify me 🙂
i guess you just need a parser for the format, not the same implementation
Oh. I see. libfmt is pretty heavily reliant on templates, so you'd probably have to write some kind of wrapper for the features you wanted to expose over FFI. And at that point you might as well just write a real extension
it seems quite easy if you limit the scope to PHP's type system
but I'd much rather just go the extension route since that's what I'm used to 😄
FFI seems like dark magic
@obtuse citrus do you know how support gem choose which stat_descriptions to use?
(Brief PHP tangent: Psalm is amazing, are you using it?)
(using php-stan but interested in psalm's pseudo generics)
Ah, cool. You can express some pretty detailed type behavior with Psalm templates, e.g. "calling this method with a class name gives you an generator that yields instances of that class" or whatnot. I've been using it for a side project to great effect
yep the difficulty is stuffing it into the build system somewhere for CI without pissing off a bunch of people when it fails
we're getting closer to the website being separated from all that but key people keep getting stolen for work on other features ._.
So, I've just started looking at the WorldAreas.dat file's actual binary data and am very confused by something I've observed.
For some reason, it seems that they are null-terminating after every character in a string
(As shown here)
utf16
Honestly, the reason why I am doing my own thing right now is for learning/practice. I haven't worked with files in a very long time, so this was a nice refresher. I think one of the problems is everyone has their preferred language, style and use-cases.
welcome to the real world 😉 I resisted to write the parser in typescript though 😄 performance would have been bad.
but for the same language it should be possible to agree on a style and for the use-cases to define a common api, so people can work with the libraries as a base for their own application
@dull laurel I think a wiki page on the org would be good, if it encompasses all PoE-related software. The wiki only lists end-user applications and some development resources, but no other deployed software like the discord bots here for example
Heh, that probably explains a lot of the tool implementations represented here 🙂 I think most of us have developed their own tools in their own preferred language, or in a new language to learn it better
sounds like it is a good time to change that. I would be interested, got some free time at the moment
The first useful repo lol https://github.com/poe-tool-dev/passive-skill-tree-json

GitHub
This repository contains passive skill tree json data for Path of Exile - poe-tool-dev/passive-skill-tree-json
@dull laurel pushed me a bit to upload them 😛
We should probably come up with a nice way to de-dup a lot of those images
pretty sure the only ones that have ever changed are the skills/group images lol
Can anyone key me in on the format for the dat file headers?
PyPoe's fields.py says:
The header of the file contains the number of rows and the size of the rows,
so we can determine with certainty how large it would be.
but I'm struggling to extract these sizes in any meaningful way.
Any help would be greatly appreciated. I feel like this should be quite simple, but I am honestly quite lost in this binary world :P
Number of rows is always present at the head of the file. The size of the rows is inferred by searching for the end-of-rows marker (BB BB BB BB BB BB BB BB) and dividing its offset by the number of rows
Aha! I understand, many thanks!
Or you calculate the row size based on what you already know about the file structure. The separator-searching trick is a way to start analysis without knowing the row size
Yes, that would be ideal, but I'm currently attempting to update a file spec, which is why I'm in this mess to begin with lol
If you're working on a data file that changed, another trick that may be worth trying is comparing it against the same file from an earlier release.
@mortal bone i would have thought git does this with its magic compare, but I guess that is for changes to a single file only. but maybe github does this. are you worried about the size of the repo?
git will dedup identical images, and the json files are trivially small
Well, maybe not trivial. But still only like 1-2 MB each before compression, which isn't much as far as git is concerned
Yeah, the images will hash to the same values, but there isn't really a reason to have them in each folder if they are duplicated anyway
https://git-scm.com/docs/git-sparse-checkout may be useful if working tree size is a concern
or put the assets in a separate repo
I don't really see a reason to move them out tbh
https://github.com/Novynn/libfmt-php good enough for me @velvet fog ¯_(ツ)_/¯

GitHub
Bringing libfmt to PHP. Contribute to Novynn/libfmt-php development by creating an account on GitHub.
@compact isle You are a hero
I hope you're not running windows
are all ggg devs on macs? 😉
yeah using linux
Hmm. I'm using PyPoE extract a few files, and WorldAreas.dat in particular is giving me a SpecificationError
"WorldAreas.dat": Specification row size 480 vs real size 476
So I set out to update the file spec, as one does. Only problem is: my calculated "real size" is 480. Its safe to say I'm thoroughly confused. Any ideas as to what could be happening?
(I've successfully extracted and parsed other files, likeAtlasNode.dat)
So what's your method for computing this?
take the uint32 for number of entries from the header of the file
that means they removed a column (most likely)
Removed harvest chance, maybe?
But when I check the row size myself, it matches the PyPoe spec size
That's why I'm so confused
I expected something to be removed, but it looked like it matched the spec
Harvest chance is probably near (if not at) the end of the row
Welp, yep, it was harvest chance removed. Edit: Don't quote me on this!
Now I just want to know how I messed up that calculation..
O.o
Are there any other implementations of a dat file parser beside pypoe?
At least one: https://github.com/oriath-net/pogo/tree/main/dat

I've got half-arsed ones in Rust and C++, don't remember if I published them.
I'm trying to build one with nom in rust, I think where I'm getting hung up is that it appears that the files aren't self-describing
If you're using Rust, I recommend not bothering with trying to do DAT with macros.
I had a build-time parse of the JSON exported schema from PyPoE which generated typed specs and parsers for them.
oh, that sounds rough
Unless you want to learn how procmacros work, then it's a fun and frustrating project.
My C++ one right now uses nlohmann::ordered_json as the output type for rows 😄
oh proc macros are fun, I'm just trying to use nom because I like the idea of fitting the grammar into a parser combinator
It might not be coincidence that the approach I took is "fun and frustrating" in its own way. The schema is described using Go syntax which is parsed at runtime and converted back into a type through reflection
clever, you're effectively working around static typing by being more general and using the types you create?
Partially that, but mostly I didn't want to have to statically compile all the type definitions into the executable
My current solution is a build.rs that loads the JSON and emits a spec.rs via a bajillion of print!.
Including parsers that use friendly helpers like fn read_ref_list_ref_string(r: &mut DatReader) -> Option<Vec<String>>
I guess if it works it works. I think I'll try defining individual types and functions for table rows and passing those into a more general parse function that just calls those on each row
Yeah, went a bit pragmatic after a couple of iterations of Good Ideas.
actually I can probably make that cleaner by making a parse trait, but it's still a bit tricky since I don't understand the static row / variable row relationship yet
What bit about it is vague?
I should write up a DAT primer on the wiki, thought I had done it for the poe-doc thing already.
I just haven't really read much into it yet since I'm still working on the overall parser
Some column values are offsets+counts into the data section.
The variable row section is used for values which aren't fixed-size: strings and arrays
good to know
Strings are stored as an offset, arrays are stored as an offset and element count
That's super helpful, thanks. I think that'll help a bunch on getting started
All of the variable data in a dat file is usually stored in the same order that it's mentioned in the fixed section, although I've seen some situations where that rule gets broken
Offsets are relative to the start of the separator, not the end of it, btw.
Are the fmt strings for the "explicitMods" that appear on items in the river somewhere? Like the trade api just gives you the values as strings
good to know, I'll probably store the separator in the variable data then
@pseudo ocean Yes, they're in the /Metadata/StatDescriptions/ files
But if you mean you want to turn the river back into stats... that's tougher 🙁
Ye that's the idea
and if you want to turn that into mods, that's an outright guessing game
I mean, first step is to turn it into a modifier id, second step is maybe doing something like pob where you parse the description into what stats it modifies
@rapid pagoda I've got a nice omelet here, could you please tell me how many eggs there are in it? 🙂
The hen produces eggs of rather varying sizes in a bimodal distribution.
If I eat the omelet to make the answer "none", does that count? 🙂
It's a solution.
I mean, I feel like most of the permutations of the mods are non destructive.
I guess like combining mods is a problem huh
Hybrid mods tend to throw quite some wrenches in the soup.
Yeah doesn't the official trade site show mods with tiers and shit though?
IIRC it sources the data in a slightly less baked form.
That would be nice to have
They probably dont even need to parse a tb of json a week to keep up with the api
thats not much data
I tried doing that briefly, turned out it's expensive to host that much data processing in the cloud
as a "regular person" you probably don't need the service and reliability and all that. as a company it is really convenient
Ye, a friend of mine asked why I dint use dynamodb, they charge like 1500$ for a tb of writes
Which seems insane
If you need it, it's worth it.
you wouldn't want to store all the json, only the relevant bits and pieces.
But this is virtually the worst application imaginable for Dynamo. It's a key/value store, not a search index
If one were implementing Path of Exile as an AWS-native application, though, it might make sense to store player data in Dynamo, since it rarely needs to be looked up by anything other than its ID.
Update on my weird WorldAreas.dat spec row size issue.
(There is a reason I edited to say don't quote me!)
I was being silly. I have PoE installed both via standalone launcher and via steam. I've been doing most of my dev work recently with steam, but PyPoE was using the default launcher's install, which was using the last harvest-league patch. The spec was correct, and the missing 4 bytes were for the new uint32, HeistChance.
oh certainly - I was playing around with the stash tab api and the kafka cluster gathered about $150 in charges in a couple weeks. Not having to manage kafka was great and the speeds were great too, just very expensive. I can see why cloud is very enterprise-y still
streaming the data through azure functions?
Just buy a cluster of rpis and hide them in zenseis basement
At least that's what I would do 
wasn't there one guy here with 1 gbit line to his home? that should work
Iirc it was him
Maybe zao (too)
The real heist is connecting a rpi cluster to your fellow northerner tooldevs while they know nothing
@dull laurel thezensei - I have "just" 300/100.
Back when I cared about pulling the river and it was bursty with delays between requests, the river sustained around 5 MiB/s.
Not azure functions
wow, that will be quite costly
That could just have been the speed at which one would catch up and it may be lower if you're riding the wave.
"Riding the wave" means what?
I mean, being current with the river data.
if you have a service running 24/7 that should be no problem. just wondering about the cost
I'd also guess that the rate varies based on where in the league you are.
I forget who, but some of the people doing this competently have stat dashboards.
I finally setup visual studio, even the new preview with .net core 5. But it is just so overwhelming compared to visual studio code.
Use the tool that makes you happy.
I really tried it with C# and VS Code, but managing projects and solution dependencies is so much easier in the big brother
nah. it was a confluent-managed kafka cluster in GCP, the expensive part was that I was piping over 5 MBPS into/from it constantly, which would have been 13 TB of data a month
you just want to parse and then store the data that is coming in via the stream, right? the "river", is that a websocket or what technology is behind it?
@dull laurel You poll a HTTP endpoint with a change ID, and get a set of full stash tab contents back as JSON, with the next change ID at the start.
So even if someone reprices or moves an item, it'll eventually cause a full republish of everything in that stash tab.
Rate limited at 2/s or something.
yea the stream is definitely very chatty - even at 2 calls per second the stash tab stream produced 200-400kBps at the end of harvest, which I expect about half to be from bots based on the patterns I saw
The common optimization strategy is to look at the raw bytes of the response as you start streaming it in to get the next ID so you can get started on the next request while parsing the JSON payload.
basically. I was trying to build something that would emit an event every time an item changed meaningfully or was removed, so I would have a topic full of "current state of league economies" and a close approximation of the actual economic activity, since I wouldn't be able to tell if removed items are always sales, if they're using currency from a public tab, or taking it off market for some reason
@worthy cape I was looking into this... I recommended the same before. However, the bulk of the IO is TTFB. The actual transmission is fairly fast.
I guess that may vary as well, but at some point, you may choke on that pattern
you still save like 200ms if you start the second request before the first one is fully transfered
I wonder if I should force-push to clean up the history of my ozz fork when moving out bun, or if it should be there for hysterical raisins.

@grave wren I don't quite like to have traces of my source in a GPL repository, mostly that.
🏄♂️
Oh, looks like nagios
All the RRDs.
does it have to be gpl
oetker grafs. they all look the same
I mean if your http library doesn't accept compression then its like 8x the size.
Using brotli
Can't wait for the river to speak Oodle 😛
i doubt http will add non-public compression formats to their protocol
@worthy cape don't give them ideas lol
@dull laurel you could compress it however you want, though.
You don't need http to add a compression format. You can add a custom compression type as long as you state that in the Content-Encoding header. You can always add the Accept-Encoding to your request to change the compression type (if allowed)
Just cross-compile Oodle into WASM ^_^
wasm will be the end of javascript 😉
wasm will be the end of your RAM
is it less efficient than javascript?
For number-crunchy things it's king, even if it's a weird VM.
I mean WASM memory in current spec is not shrinkable
time to buy that 64GB upgrade then 🤔
It's a 32-bit thing, isn't it?
atm, but 64 is planned
That's neat, but also scary.
DEC64 all the things.
got a parser done for a simple .dat file, next step will be something using the variable storage - https://github.com/jlmcmchl/poe-dat-rs

GitHub
Contribute to jlmcmchl/poe-dat-rs development by creating an account on GitHub.
rust looks very interesting, code wise
@wintry surge There's some recursion in the kind of things to parse, like you could have both ref|string where the offset is in the fixed section, and ref|list|ref|string where the list offset+count are in the fixed section and the string offset is in the variable section.
Behold all the hardcoded combinations of byteorder-powered parsers: https://gitlab.com/zao/poe-rs/-/blob/master/poe-dat/src/types.rs
gotcha. At least the types are consistent and not some list[int or string]. I'm hoping that recursion can be expressed cleanly in how I process the variable section
I ran into some expressivity and deduction problems when templating things like one would in C++ for nested parsing functions.
Used to have special wrapper types in my specs like literally RefList<String> and Ref<Ref<u64>> and whatnot, and try to Do The Right Thing with traits on them, but it never quite worked out.
I'm sure I'll come across the same, but I think my goal is for something like ref|list|ref|string to be fully resolved to Vec<String> or Vec<&str>, but probably the former
This is what I ended up with when going from procmacros to just printing a Rust file from build.rs: https://gitlab.com/zao/poe-rs/-/blob/master/poe-dat/build/genspec.rs
Results not too far from yours: https://gist.github.com/zao/ba705ff29ba1b89b4ce1f0a358ecbddd
If you dare look at the other file formats, I'm using pretty much every variant of hand-rolled parser and nom in wild mixes.
sheesh that's a lot of file specs, I see why you generated them at build time
When I started Nom was using the old macro-based combinators btw, so I bounced off it rather hard. v5 is supposedly way nicer.
Big endian, in case you ever have to do an port to an ibm main frame
yea I initially tried using the macro combinators for this one but you get way more type / failure info with the functional combinators
@pseudo ocean Not too foreign on ARM or Power either.
Ye but they can switch or something right
It's just nice to have binary parsing code deal with endianess correctly now instead of in the future where it might matter more.
(that being said, libbun is completely ignorant of endians for bundles)
why is it making network calls?
uh? evil code? or some dotnet weirdness?
yeah not sure
@worthy cape ARM is little-endian for all intents and purposes, fwiw. technically some cores can support big-endian mode but nobody uses them that way
python run_parser.py all
File "run_parser.py", line 58, in <module>
main()
File "run_parser.py", line 50, in main
ggpk=ggpk, data_path=data_path, relational_reader=rr, translation_file_cache=tfc, ot_file_cache=otfc
File "e:\programming\python\repoe\RePoE\parser\modules\base_items.py", line 191, in write
inherited_tags = list(ot_file_cache[item["InheritsFrom"] + ".ot"]["Base"]["tag"])
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\cache.py", line 184, in __getitem__
return self.get_file(item)
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\cache.py", line 298, in get_file
f = self._create_instance(file_name=file_name)
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\cache.py", line 276, in _create_instance
f.read(**self._get_read_args(file_name=file_name, *args, **kwargs))
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\__init__.py", line 192, in read
return self.get_read_buffer(file_path_or_raw, self._read, *args, **kwargs)
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\__init__.py", line 153, in get_read_buffer
return function(*args, buffer=BytesIO(file_path_or_raw), **kwargs)
File "e:\programming\python\pypoe\PyPoE\poe\file\shared\keyvalues.py", line 369, in _read
extend + self.EXTENSION].record.extract()
File "e:\programming\python\pypoe\PyPoE\poe\file\ggpk.py", line 580, in __getitem__
self.get_path(), item
FileNotFoundError: /Metadata/Items/Currency/AbstractCurrency.ot not found```
is repoe not yet in a good place?I think you're looking at the answer
The file is present in the index.
zao@mim:/media/stuff/depots/downloading$ bun_extract_file list-files 3341589452991106600 | grep AbstractCurrency
Metadata/Items/Currency/AbstractCurrency.ot
Metadata/Items/Currency/AbstractCurrency.otc
well, i needed ooz, which wasn't mentioned in the readme.md, so I figured i'd check if there was something else that might need to be in place
I wonder if there's a problem with the leading slash.
Heh, there's quite a lot of warning spam above that, including some about invalid tags.
@inland kestrel PyPoE seems to be looking in the root directory of the GGPK and not via the bundles contained therein.
interesting
(it's failing at Metadata already)
@inland kestrel You would probably be best off by maybe checking with @obtuse citrus , seems like ggpk[] and ot.py doesn't care about bundles at all, while RelationalReader does.
I've done my best at trying to trace through this but Python in an unusual IDE is a nightmare 😄
which IDE do you normally use?
For Python, none as I'm typically headless and haven't figured out remote debugging. Here, PyCharm.
All the debug stepping buttons are weird compared to MSVC.
ggpk file only checks paths within the ggpk and not with the bundle
I haven't touched ot yet so probably the inheritence might not work
Ah 🙂
@worthy cape yeah, i don't have a great python debugging environment 😒 i'm a .net boi
Do you use Visual Studio? It has first-class Python support
Last I touched Python there in like 2010 you had to use IronPython, back when F# was hyped.
back when F# was hyped

but yeah, python is nice in VS now
if VS got erlang/elixir support, i would probably learn it, because i hate all other IDEs
I think you can do R, Python, Node and the regular C, C++ and .NET stuff now. Missed anything?
vscode would like to have a word 😉 (and I still think it looks much nicer, for some reason the font rendering in VS is ugly)
Yes, you missed Java 😉
haha.. yeah, no 😛
the font, look at how smooth it is!
ha, reminds me that I'm stupid.
this is of course a different font 😕
So, I work in IntelliJ, and I will say I miss Visual Studio lol
also fuck Java
IntelliJ Idea*
I accidentally searched for something like __getitem__ in the whole codebase and PyCharm went "lol, out of memory" and started churning.
lol
Caps to like 1125 MiB heap by default.
yep
The machine has 64 GiB... please spread your wings a bit.
also, I have a problem right now where we have a vendor product in a proprietary language/compiler and I can't turn off the compiler warnings. I want to die
~1k warnings really slows down intellij
Sounds like heist spectres might be in the patch in 20 minutes.
@velvet fog I guess there might be a dat update needed for poedb for that?
where u see the patch going in 20 minutes?
Bex's messages in #ggg-tracker
Hotfix live, I guess Bex replied blindly to an unintended message.
Since there are some C# people here, is there a nice way to write headerWord & 0x3FFFF? Something without runtime overhead, but more readable, e.g. headerWord.Bits(18)?
Can you extension-method integers or is that too fancy?
Don't know about anything language-specific, but one way to emphasize the fact that it's 18 bits is & (1<<18 - 1)
@worthy cape looking for that right nao
You can.
int size = headerWord.SelectBits(18); much nicer now 🙂 though I still don't get what happens after...
uint32 size = v & 0x3FFFF;
if (size != 0x3ffff)
{
I thought it means if size != 256kb, but that's 0x40000
The size seems to be biased.
If it's less than 0x3FFFF it's compressed and the compressed size is that + 1. If it's exactly 0x3FFFF the thing is verbatim and will be used later either as a verbatim block or (for other algos) Kraken_CopyWholeMatch.
server side patch and no client changes
Yeah, Bex's post must've been to the wrong thread.
@dull laurel Are you trying to rewrite ooz in C#? Let me warn you in advance about LznaReadNibble.
i am actually trying. what is the warning about?
The implementation in ooz is built out of x86 vector intrinsics. You will need a sound understanding of SSE to adapt it
You know that because you already tried the same?
I'm trying to get it to compile as C under gcc so that I can link to it from cgo.
yea i completely gave up on it
font rendering in notepad++ is the best imo 😉
Dotnet has support for sse intrinsics
https://docs.microsoft.com/en-us/dotnet/api/system.runtime.intrinsics.x86.sse?view=netcore-3.1
This class provides access to Intel SSE hardware instructions via intrinsics.
@vapid pulsar that doesn't make them easier to understand 😄
Does someone have up to date type information for the public tab api? Found this https://pathofexile.gamepedia.com/Public_stash_tab_API but it's quite out of date

Path of Exile Wiki
Public stash tab API is a basic JSON interface to obtain information relevant for general trade using Premium Stash Tabs for PC clients.
Basically the interface serves global update information (considerable as an update-"stream") on any public stash tabs recognized by the gam...
which part is out of date?
The sum of that page and all the per-league forum posts by Novynn tends to be good.
forum posts by Novynn tends to be good
damn dope, didn't know they make these api changelog posts
zao, if you want to guess a little with me, look at this funny function LZNA_ParseWholeMatchInfo
Sweet success -- I now have Go bindings for ooz. (gooz?)
@dull laurel Looks interesting function indeed. Seems like the result is used as an offset.
I think is some fancy bit packing of the offset into either 16 bits or 8 bits
Hmmm or 32 bits too
I think it's using the 8th bit and the 16th bit to determine the packing size
and it stores the result in the bits 31 - 16, though sets bit 16 to 1 first.
GitHub
Go bindings to ooz, a Kraken / Mermaid / Selkie / Leviathan / LZNA / Bitknit decompressor - oriath-net/gooz
I have so many questions about the design of the bundle index.
GitHub
Go bindings to ooz, a Kraken / Mermaid / Selkie / Leviathan / LZNA / Bitknit decompressor - oriath-net/gooz
Isn't this just memcpy
Probably. Ask powzix, not me 🙂
Actually, I'm not sure it is precisely. There's some weird behavior for copies at non-multiple-of-4 distances I think?
There are a lot of function like those that at first lace just seem like inlined memcpys
Not sure if that's intentional or just a case that doesn't get hit.
It's not memcpy
Consider the dist == 1 case. A memcpy would try to slide data around cleverly to avoid overwriting, but that isn't desired here -- it's a bytewise splat
And I think this is one of the places where the "going over the end of the output buffer" behavior shows up. It explicitly doesn't care about anything beyond the end of the destination, because that's guaranteed to be uninitialized
If anything, it intentionally behaves like a really dumb memcpy (or a very trusting memmove) that isn't aware of overlapping buffers.
I mean if the distance between 2 pointers is 1, the memset just becomes a single op
The length can be greater than the distance
consider memcpy(&buf[100], &buf[99], 10) vs. this thing
Yep. That's deliberate. Means you can represent patterns like "the last three bytes are repeated 200 times" as a single copy (distance=3, length=600).
This pattern is pretty common in LZ family compressors.
holy balls, awakend poe trade is amazing
idk if the dev is in here, but kudos to them
ah you are, nice job 🙂
is this all javascript?
looks like angular + electron
I just checked the github page for it and it seems that it is a vue app inside electron
pretty snappy for that good job
i'm always a bit curious about those overlays using electron, since it is basically a wrapper around chromium and comes with a memory overhead. on the other hand making an UI with html/JS is much easier
In general I would prefer more native overlays like Sidekick etc
Maybe someone can come up with a feature list and then work on one goal together instead of a dozen different tools
Ha, really happy that C# has some x86 BitOperations builtin - makes the ooz port easier a lit.
Hrm, does anyone know how the results of the guild stash audit log endpoint looks? Hard to tell as a member currently 🙂
I guess it’s paginated on some ID?
@earnest radish https://app.swaggerhub.com/apis-docs/Chuanhsing/poe/1.0.0#/default/get_api_guild__guildid__stash_history
Join thousands of developers who use SwaggerHub to build and design great APIs. Signup or login today.
There seems to be filtering of a base timestamp and a "fromid", which I assume paginates from the last item of the previous page.
@earnest radish Trying to figure out how you'd take the endpoint and get a decent CSV or JSON to jam into a Google sheet or something, and if that can be automated.
Had someone complain that the listing on the website is full of noise due to people "organizing" the stash while trying to look for offenders and I was dumb enough to look.
Shouldn't that be a numerical id like 711977315?
@dull laurel also look into Span<T> and Unsafe in System.Runtime.CompilerServices
is there a way to get the guild id from profile somehow?
i can only seem to find the guild name in the api for a profile
Click into the guild and it's in the URL.
No clue.
I'll wait for my mates to get online and play with what I've got, I guess.
Not sure how to deploy whatever I write to a non-technical person tho.
Still would require their POESESSID in an online thing, which is ick.
Better to have something auditable that runs locally.
Maybe C#, easier to deploy that @#$#@ Python.
@grave wren Not sure if I stated the context - I've got a guild-leader/officer that wants to look at the audit log grabbed via the API, and I don't have any guild rights.
Whatever it is would need to auth as them against the API with session ID, so either run locally on their machine or as a bot/site that took their session ID.
yeah but either way they need to input the session id
or do we have the oauth available for everyone
Two different kinds of weird trust, either jamming it into a black hole or jamming it into a compiled binary that might have some loosely correlated source to audit.
Neither is awesome.
i mean third solution is just using the feed on the official page which requires 0 trust
a normal desktop app doesnt offer much more usability
Initial complaint was excessive pagination with no filtering.
Sounds like a great way to be flagged by AV 😄
I tried it. Nemas problemas.

It has to run in the user's context though, because it uses the user context's encryption key
More GGPK mysteries: even though the Mac GGPK uses a different format from Windows (UTF32 path names), the only difference in the contents is the absence of the ShaderCacheD3D11.packed directory
Sneaky.
I'm a bit bummed that I can't make it download/patch on my 10.13.
Got to reinstall the VM again some day.
ponders a "Windows <-> Mac GGPK" utility.
@rapid pagoda which makes sense, since there is no directX on mac
@simple ravine thanks. I tried to come by without using unsafe and basically falling back into C++ territory. but I use Span<T> and Memory<T> extensively
Heist spectres coming for 3.12.2, either end of the work week or early next week, according to preview patch notes.
my GDB0-Y spectre build can hardly wait 🐶
We did it bois
Snazzy
the reference strings gave me a headache haha
I didn't really setup to account for recursive type parsing...
It ended up looking like this: https://github.com/EmmittJ/GgpkParser/blob/master/GgpkParser/DataTypes/Specifications/DatSpecification.cs#L78
tencent china client is very special on this tech patch
@mortal bone is that a runtime view on the bundle/index.bin files before extraction?
@velvet fog Ooh, anything fun?
they don't use the bundle tech, instead they still use a patch.ggpk to patch content.ggpk
Heh, how does one of those work? I've heard it vaguely in the past but never found out how.
Is it a pack of files that are injected into the main GGPK, how about deletes?
@dull laurel yeah, when you open a file it decompresses the bundle and parsers the file out. The view is also "seamless" between files that are actually in the ggpk and those listed in the index
wow, that is pretty cool
http://poedb.tw/dls/patch_.ggpk an old patch.ggpk (32mb)
I never got around doing the hybrid stuff between loose files and bundle ones.
ggpk will vanish, won't it?
It isn't too bad to support. The file name is either a record or it is in a bundle. If it is a record we can just parse that immediately, and if it is in a bundle decompress, get the file contents and treat it like a record
@dull laurel I assume it will be there forever for world Standalone, as for Tencent heaven knows.
@mortal bone It's more annoying on Steam as it's loose disk files there.
Not sure why, but actual r/w filesystems scare me with their volatility and permanence of mistakes 😄
aren't all filesystems r/w?
Oh, yeah. I think I would have to make some minor modifications. I think all the code would work accept the record piece. It would just be much slower to read each bundle
VFSes like GGPK tend to be stable and boring.
No-one messing with case sensitivity, networks, etc.
Yeah, loose files means people can delete random shit lol
Or antivirus just deciding that you're not worthy of perf.
Saw someone delete all the shader caches from the Steam install the other day, being surprised that they had to patch up 1.2 GiB 😄
...some people
Heads-up btw: https://forum.gitlab.com/t/upgrade-to-gitlab-13-4-0-b0481767fe4-killed-all-repositories/43038

GitLab Forum
yum update automatically upgraded gitlab-ci to 13.4 after upgrade finished no repo is available any more I can see projects listed on the web, but clicking on any of them show “repository does not exist / create empty repository” /var/opt/gitlab/git-data/repositories here ...
Colleague responded The following packages will be upgraded: gitlab-ce (12.10.10-ce.0 => 13.4.0-ce.0) and went "not today then".

Why are people still using GitLab?
The product in general or the self-hosted one?
there is no free self-host github @simple ravine
Solid CI workflows, it's not GitHub, community edition is community edition.
Hmm, true that
I was more thinking of the cloud version
And then spoke too early without thinking
and yeah, I recently noticed how troublesome it is, that GitHub for example is located in the USA. As long as we in Europe are friendly its okay, but it was quite odd to see that accounts were deleted because they are from export-banlisted countries.
dunno selfhost gitlab is pretty solid in my experience
ci has some weak points but it's working fine
I don't want to think about dystopian futures like out-of-spite-banlists of european countries.
When that happens, we have bigger problems to think about than our git repositories
we're not too far off - look how many websites ban europeans
we invented those great cookie banners 🙄
I think this is a bit too close to a political discussion, so I'll just leave it at that
main rant about gitlab ci is that you can define blocks to only run when something in a region changes but you cant get a list of filechanges reliably from the pipeline, very annoying lack of feature
Interesting, never thought of that need before.
I'm a fan of GitLab ever since the incident where they broke production and livestreamed the recovery process on YouTube 😄
i selectively test stuff where changes occur
or rather let it test stuff
no need to run all tests if you only change a specific part
if you would run all tests, it would take an inconvenient long time?
because i can see some issues with not testing all things
regression problems etc
it's just very broad regions
e.g. backend, frontend1, 2, 3
if nothing changes in the backend you only run all the tests for the frontend you worked on during development
saves a bit of resources and costs 2 lines in the ci config
the feature rant was needed for a small tool i wanted to add that is able to notify in chat about file changes - it'd detect changes in a specific folder, parse the modified or added files and post previews to specific channels so you can monitor changes in there. Would've been used to track changes in architecture decision records inside of the project and globally company wide.
that sounds pretty cool. but aren't you tracking those already via pull requests to those files? or is it rather to inform everyone (and not just the reviewers) about the changes?
I prefer to keep those in separate repositories.
A project in Azure DevOps can have multiple repositories, which is quite nice. You can then track the product's process (scrum, kanban whatever) together, but keep different services, frontends etc separate based on how they are deployed etc
yes you can get them via git diff easily but its just a bit of a pain compared to just having the files available as gitlab already needs it for the feature
i'd do that to but its not my call, legacy project and all
not a fan of one repo for everything
not the people who develop CI/CD tools either 🙂
having 3 frontends and the backend in one project isnt blazing fast in intellij until it starts up
if you ever have to reindex the thing you better be ready to drink multiple coffees
also saw a bit about JIB and it's pretty nifty: https://github.com/GoogleContainerTools/jib

GitHub
🏗 Build container images for your Java applications. - GoogleContainerTools/jib
it can work, but you need the tooling around it and that is currently not really available. or to specific. for javascript you got lerna to handle multiple packages in one repo, but that's just javascript
I am still waiting for Java to burn to the ground
🤷
I never understood the idea of the mono repo. It doesn't make anything any easier
You just seem to shift problems right/left
its alright if you need to adapt front and backend at once cos fulltext works
but its a slight benefit for huge negatives
At my last company, they started to do a redesign of the whole system which involved pulling out all the sub components into pakcgaes, but the problem is when one of you base components change it is a lot of effort to update the sstack
that was pretty easy when we did it for a component
It was nice after everything was done haha
the wat moment came when someone said we need to put it back
we had that in our frontend as well, each team being independent in their own repo. but updating the master was tedious, especially if you wanted to sync changes from multiple teams.
Now they can just create a branch together and do their stuff.
Today in tech - zao tries to get a hecking rate limiter working for the API.
(spoiler alert - it doesn't go well)
today in tech faust learns that the api the customer bought has a quota of 3k calls per day since a few weeks
:>
But it was cheap!
put your rate limits in the header!
lul wut is header
@dull laurel Parsing all the X-Rate-Limit-* headers, keeping track of the last N requests, sleeping accordingly, still not quite there and the Nth request is a wee bit too eager.
aren't there some libraries that do that for you @worthy cape?
seems like a common use case
For the PoE kind of scheme? Not really, and authors in the Rust space seems to care mostly about maybe handling 429 Retry-After when you've already been booped.
Am I completely barking up the wrong tree if I keep track of my oldest request and if at the cap, wait until it should be out of the window?
No that seems fine.
Only time u dont want to do that is if you're doing serverless and share IP between nodes, then u obviously need to pace it instead
That's probably the problem actually, my process runs a few requests and then exits, so if there's a re-run within the period, it's not finding the oldest it has and just goes on.
@velvet fog Hey I've found some bugs with replica uniques: https://poedb.tw/us/Replica_Atziris_Foible lists its normal base implicit and https://poedb.tw/us/Replica_Prismweave has the wrong mods (added damage to attacks instead of spells).
okay
Maybe I should just smash into the limit and honor the retry-after, should be mostly fine.
looks like there was a tool banwave according to reddit, thats why i mentioned it here
Any chance anyone could give any pointers on what files I should look into for adding more info to the tooltips in PoB?
Nevermind, I think I found it.
Patch in 1h \o/
anyone can give me a c# advice. is it okay to use existing exception types e.g. from system or write them all myself?
If a generic base exception works fine, I'd use it. Using an exception from a specific unrelated library/module would be surprising.
Like you'd throw an ArgumentException if you don't have anything more meaningful to communicate to your callers, I reckon.
Okay, thanks. Was trying to make the code more readable
also on exceptions, this is the best article
Writing good error handling code is hard in any language, whether you have exception handling or not. When I’m thinking about what exception handling I need to implement in a given program, I…
In this patch 3.12.2 we lost Data/ItemTradeData.dat.
that all just gets piped into /api/trade/data/static anyway
@velvet fog Spectre time \o/
Ah, already in - of course it is 😄
@rapid pagoda Enjoy the goodest of bois.
I didn't notice this, but since 3.12 they are calling the hotfixes by their name rather than letter haha
@simple ravine the article is pretty nice, however i can't fully agree with what he says about boneheaded exceptions. Clearly nobody does them on purpose, and clearly there will always be such bugs that make it through to production. Happens all the time, regardless of how careful you are. If you place them into exception boundaries where applicable you can make it affect only certain (maybe even irrelevant to the user) parts of the application and fix them when they get reported, maybe via a popup or a automated reporting system
I agree with him.
I also trust his word, knowing Eric Lippert is smarter than most of us 🙂
So, I tried my hand at multithreading for the first time... On a 24 thread machine, running the job using 20 threads results in the entire process taking roughly 4x as long as it did when on a single core. I think I have some reading to do... O_O
This was in attempting to simply construct a tree describing the files contained w/in the bundles (from the index.bin) I feel like this is a decent case to split the compute load between cores. Am I wrong?
or locked objects
hello, sorry if question was asked 100 times already, but is there a way to get from API item base type (dagger, body armor) by typeLine field ? (f.e. "typeLine": "Golden Plate")
o that could be great idea - thanks
are there any user-config options for ggg-tracker? (wasn't sure where to ask (sorry))
It appears to be that Mods.dat length changed from 306 to 338 bytes since 1.12.2
https://github.com/powzix/ooz/blob/master/kraken.cpp#L1075
Another code find in the ooz code. if (1) with a big an complicated else that will never be reached 😄
that's one way of "stashing code for later"
Inb4 it randomly breaks If you remove it
The massive file made me a bit uncomfortable too ngl
trying to convert that to C# currently. It's "fun" 🙂
Lol I have seen that a lot although, typically, not an explicit if true
those work best with goto, because that's how you jump over them
It just happens that the conditions are never false
Maybe let static analysis run ahead and remove all the bloat afterwards
Reminds me of the talk I listened to yesterday where they migrated away from old COBOL code and noticed only ~33% of the code base was used in the last 1.5yrs
As in functions called from existing functions
Makes sense a lot of the time that stuff is written before it is needed or has been replaced but nobody wants to remove it
"maybe we need that code later", even if you use a VCS
Yep
Hundreds of lines of useless commented code
never touch a running system. and that is how spaghetti code is created
Because we all know how good shit is tested
True but what are you going to do when you have more pressing stuff to fix
Gotta prioritize
There are solutions to this. A colleague told me that at Bosch they do regular "cleanup" sprints (they have some fun abbreviation for it), where they focus on technical debt.
And to be honest, it is kind of measurable, if you look at how long the most basic tasks take to be completed.
Yes and now try it on a huge project you maintain as a small team
it seems the problem is already with those two words "huge project" and "small team" 😉

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Better hope you're not paid by signed LoC.
Then the inevitable moment comes where the shitty cheap solution cost more in the end
Time and material contract
those are great money makers for the consulting company
but yeah cleaned up lots of code thankfully when we were more in the project
or simplified shit another previous colleague overengineered in
We have been doing an upgrade, and I have been forcing time to do all the cleanup. For instance, over 150 files were copied between three applications, so we are now using subtrees lol
git submodules? or what is a subtree?
A git subtree. Basically, you can mask out a piece of your repo and push all the commits that happened in that subtree
It is more of an opt-in way of applying changes, although, submodules mean less PRs
You think 150 files across 3 apps is bad? ... How about 1K+ files across 5 apps (forks) with the majority being changed in minor obscure positions over the course of 6 years? 😄

Lol I don't think it is that bad. It is just annoying that they designed this system for 5 years and they couldn't figure out how to share code
That's 1K+ c# files I'm talking about 🙄
The only difference was a namespace lol
Still have fond memories of my master thesis which had 3-4 libpng and 9 zlib vendored in tree.
Also a set of patches on top of a very specific Boost version to introduce proposed and rejected Boost libraries.
There is also more shared code between 2 of them, but I haven't got around to doing that
Agree Emmitt... But it just happens... Like a small team starts out, doesn't know much about how to properly code, or use git... They make a project, which then gets forked 5 times over the course of 5~6 years... So it just grows over time
By my count, the unreal engine source tree only has 3 full copies of boost inside it. In my opinion, any real engine should easily have 4 or 5 copies of boost to really deliver on quality.
Likes
429
They went balls deep in this one. It wasn't a small team. It was over a hundred people between on site and off shore lol
Also, no forking in this one it is 3 completely separate applications that have shared custom code. It is a vendor product that you can customize
It is a proprietary language so that isn't super supported
It supports all java packages and what not, but we aren't a java shop
So no one did any of that lol
Lol to be honest, I don't want to have to explain it to the team haha
had some "fun" to make a php package once tho
their weird naming scheme haunts me to this day
I think azure supports generic packages now, so I might mess with that a bit
I haven't touched php in years outside of wordpress
7+ is actually usable with type hints and stuff, still hope to never touch it again for long