#💀 Cortex Engine
1 messages · Page 2 of 1
btw, do you have an overview for me that outlines the features/controls of a channel like #cortex?
Cortex - moved to #cortex
i'll have to add the cortex role so people can sub to the /notify cortex
but i haven't done that bit yet
kk
btw, you are fine with unicode like "💀" in channel names?
I guess it fucks with autocompletion
i've been thinking about it and i think i've had this debate on the server in the past
channels can have icons
I have no clue and wouldnt know
but i think the weird thing is, when some channels have icons and others don't
we can iconify the frameworks obviously
but then things like #macros would look out of place
so its just a question of how do we make things fit in
(altough one problem is that, if the icons are at the start, you can't mention the channel)
i believe channel icons go in place of the #
Snippets
1) Moving objects
tags: ceramic, tutorial
A guide on how to move rendered images/visuals
2) haxeflixel pong
tags: flixel, game, tutorial
A tutorial on how to make a pong game in haxeflixel
3) 2D Platformer
tags: heaps, game, video, tutorial
A video tutorial series on making a 2d platformer in heaps
4) Shaders, HaxeFlixel, and ShaderToy
tags: flixel, shaders, tutorial
A guide on converting a shader from shadertoy to haxeflixel
5) HaxeFlixel - Shaders
tags: flixel, shaders, tutorial, video
A video tutorial series going over how to use shaders in haxeflixel
@grizzled laurel another feature you may not know about
Man i should really take a look at the cmd list loll
same!
the idea with that one was, whenever i saw someone post a game or some content. Just index and categorise the link
Also uh, daz, it seems like BGFX needs this flag. Adding <flag value="/Zc:preprocessor"/> to the build.xml of linc_bgfx fixed it.
Should I make a PR to add this?
You ask this in #cortex and I answer
Ahh
but anyone can do it
yes sir 🫡
i went through all the pins on the server when i added the command just added them to that thing
So its kindof like, used-made pins
because i found pins in general a little awkward to search through if you wanted to recommend a bunch to a user
*user-made
yeah
yeahh deff
a lot of discord "permissions", i think work better when more people have access to them
so now if someone wants to know all the heaps tutorials
Snippets
1) 2D Platformer
tags: heaps, game, video, tutorial
A video tutorial series on making a 2d platformer in heaps
I can just give them the list without saying "go search the pins"
but obviously the list needs to actually get populated x)
I would recommend pinning a message in every channel like
# User-Made Snippets
Please use ``/snippet search`` to search through user-made pins.
So your idea of how the command is used is a bit more obvious
the issue with this is that people don't really check pins much as it is
its hidden in discords ui
True
whereas with the command, the visibility is provided by the one who is helping
so the more people who use the command (eg find it productive/useful) the more the command is seen
the idea came about because i was searching through the discord api to see if i could open the pins popup on someone elses client via a discord command 😂
ah
also out of curiousity
do you use a library for the discord bot, or did you make one yourself?
discord.js externs
i had dts2hx generate them many years ago and just update the externs myself
as and when needed
I see
Man I remember when I used to developer discord bots
But imo it has gotten alot less fun
how come
Back in the day (4-5 years ago) the process was alot more involved
Bots usually were way more experimental
Then at some point came activities
Very few bots knew how to use them as they were hidden in the depths of the discord API
and then buttons and slash commands released
And the discord.js library has also gotten way more bloated
everything was more primitive back in the day
and that was quite fun
But now everything has gotten more, cluttered?
i think discord api has always been cluttered
i shouldn't really need "externs" for a http rest api
but sifting through that nonsense, NO THANKS
I mean it's partially due to discord.js
discord.js is horrible
like it feels overcomplicated
https://github.com/ClientCord/ClientCord quite a while ago i built this
very simple wrapper for discord's api
its easier than the standard discord api
(be warned, code is horrible, but it worked)
but now you already need a bunch of other stuff to make something simple work
the slash commands for example
i kinda hate em
but also like em
text commands work still as well
but slash commands are useful because i can document and provide useful things like autocompletion
ok, thank u!
💀 Cortex
teh skull is back
And we are back!
prolly for the better. dont wanna cause too much confusion
The moment I open the gates, people will be disappointed anyway, cause cortex will try to eat their soul when it comes to the project setup
its like, sure you may not accept any external "pressure" to release, but, there really doesn't need to be any external pressure to begin with
yeah. Im also seriously thinking about not making it opensource, but source-available
what's the difference?
Ownership and payback. I sorta like the model flaxengine is using https://flaxengine.com/licensing/

We Want You To Succeed! Use Flax for free, pay 4% when you release Flax Engine and all related tools, all features, all supported platforms, all Editor source code, all complete projects, and Flax Samples with regular updates can be used for free. GET STARTED NOW How it works? Use […]
ahh i see, i guess i always just thought "opensource" meant "you can read the source code"
small projects pay nothing, successfull projects give something back
things seem too granular these days 😂
since it limits what other licenses you can combine it with. something like LGPL is incompatible
i just thought of it as "opensource" means "you can read the source code" and "check what the license is to see what you can do with source code"
i never would have thought a license would change open source's implicit definition
but that's a bit off topic
i don't particularly think it matters what it is released under
its your project 😄
and the concept is pretty epic overall
We'll see
there's some major attention grabbing features here
yeah. I also see the traffic linc_bgfx is doing, there are some eyeballs
In the end I kinda hope I can get enough interest so people actually start building cool shit and contribute. That will be a super little percentage of folks checking it out. So I wanna prepare it well
probably worth tackling the project setup part 😂
i think this is a big turn off in general in haxe
it could be worse 😛
priority is getting the core + editor functional first. there is some architecture that is pretty brain-fucky
Obviously your project so you can do what you want with it, but I would keep it fully open source. I think the market for another proprietary-ish engine is quiet slim and you could always go for an open-core model for actual companies.
it ain't slim at all
if anything there's a massive gap for a good proprietary engine
everyone is very suck atm and cortex will offer some real heavy development advantages
right now, all the big dogs are bad and everyone is pretty unhappy with them. it's a real good time for small peeps to compete and steal some share from them with just some simple good practices and some good old fashioned hard work
Im open for discussion, so if you can share your reasoning why it should be opensource feel free to drop your feedback. My main motivation is simple: opensource doesnt work(money is made at some point but rarely trickles down into the supplychain, leaving maintainers to beg for support) and results in loose expectations from all kinds of directions. My project is also standing on shoulders of giants, but if I wanna help/support or even just let these these dependencies participate in any success, it's a lose-lose situation for me since I have to do that out of my own pocket & available time. Personally I hate that very much
I tend to agree
for growth resources are required
time has to be spent, which is a finite resource
so some return on it is fair for high quality of effort
uh-oh
daz
it seems to happen on my main pc now too after reinstalling the lib
submit a PR?
I'll try to replicate
Sorry for being kinda harsh in my initial message. My intentions with the Haxe community is to contribute back as much as possible. I release what I find would be useful for other people under the zlib license. I want new Haxe developers to have the opportunity to learn from my code (even when it is kinda shit) like I have done with many other projects. My choice of license allows them to do such a thing. All of the existing public engines are written in MIT and so they can be similarly researched while developing my project without worries of proprietary code leaking through.
"Open Source doesn't Work," implies that the only reason that you release your project is to make profit and not the improvement of the community that we all rely on. On GitHub, HaxeFlixel has around 170 different contributors throughout the years and has seen quite regular updates. FlaxEngine has seen under half of the contributors and had its last commit over two weeks ago. There are many pull requests left unmerged. I attribute this to some lack of motivation. They had hopes of profitability, but from what I can see no one is working full-time on the engine and there have been very few games made with it. Their second game jam only had 2 entries. HaxeFlixel has around a third of the Github stars, yet its contributions to HaxeJam were quite immense. I think the licensing model has scared away anyone who wants to make an actual game. Leaving only people who wish to poke around with Flax left.
Red Hat Enterprise Linux (RHEL) is Redhat's golden goose. Almost all of their other products (Quay, OpenShift, Ansible, etc) contribute to its success and vice versa. RHEL is built upon open source software and yet is a paid service. There are full bug-for-bug recreations out there like Rocky Linux, AlmaLinux, Oracle Linux, etc that are all free. These are as close to the original as legally possible, yet Red Hat is still a billion dollar company. They have employed thousands of people to work on creating resources for their clients, customer support teams, sales teams, marketing, legal work, etc which is the true product. Large companies want other trusted large companies to depend on and Red Hat provides that guarantee. Would you be able to do that with your project? Even if it was fully proprietary, why would a large company trust you enough to sacrifice part of their income. You would end up with only people who don't believe that they can make a game that makes $250,000.
Epic Games has its own golden goose (Fortnite), it has made the brand into one that companies can safely rely on. Even if Unreal Engine wasn't sold to the public, they would have their golden egg's to sustain on. Unreal Engine has quite a similar model to FlaxEngine and is what I assume it is based on. It asks for 5% of gross revenue above $1M. It specifies that only profits that can be directly attributable to the UE product counts. This is quite vague. I have seen many kids in public playing FNF on their devices, and sometimes weird knockoffs. FNF's success isn't about the game itself but the general aesthetic and characters. More than seeing people play the game, I have seen merchandise. T-Shirts, stuffed characters, belts. Do these count towards that revenue? The people who can give definitive answers (lawyers) are expensive. Now both you and aspiring developers have to have some form of legal backing to make sure the correct amount of money is getting sent to you. If you want to actually help people, you are now bombarded with extra tasks and financial requirements.
Raylib has seen a substantial amount of success as an open source project. The engine has allowed new developers to make simple games with ease. The developer left his job to work on Raylib full time. He does this by depending on donation and sales of his tools. He has constantly asked for ideas on how to make more money, but I am not sure if it is possible. Raylib has no successful commercial games to its name as it leans toward beginner programmers. It isn't seen as powerful enough for large games. And as I have stated before, UE's and FlaxEngine's source of financial success would limit you to this type of developer.
If you open source your engine and it gets a successful commercial game made with it, you can then consider different ways of monetization. Godot Engine is flawed, but it has positioned itself as a radical alternative to the big three engines. They have used this to raise a decent chunk of money from wannabe/current game developers. Individual developers of the project have figured out their own ways of profiting off of it, including commercial support and console porting. Consider those once/if Cortex gains success.
Jeremy has a message pinned in #ceramic that details his personal philosophy for how he treats development of the project. He only adds features that he needs and reminds himself that he doesn't owe anyone anything with it. His philosophy isn't selfish, it just keeps him sane, and he is able to share his work with the Haxe community. The community's value is in its willingness to collaborate and share. Most Haxe libraries were made for personal usage and were shared so others don't need to duplicate work. This is in contrast to other languages where people make useless libraries with the intention of personal success (looking at you JavaScript).
(I spent many hours on that, i need to get off the internet istg)
i should have probably proofread it, but that is a later project
bro is chatgpt
i wish 
i actually thought it was much shorter until i sent it

ono
w00t! @green breach super interesting post, thanks for sharing. I'll jump on a couple of points and try to clarify
hopefully i don't need to write another essay lmao
concerning learning and sharing: Personally I grew up and learnt my skills almost exclusively from opensource projects and source available projects. Back in the day that meant dealing with (L)GPL every single time(ODE, Ogre3D, Panda, ...) or some heavily limited use(modding SDKs, unreal, quake, hl1). BSD or MIT was a luxury and the absolute exception. That meant I had access to all these great projects, learnt a lot, but I was always forced to roll my own implementations where possible when it came to anything remotely commercial. Custom or paid licenses where usually out of budget so you had to be creative and dilligent. Today I'd argue that this caused my skill to skyrocket and paved the way for cool career. I think making source available, even with a restrictive license, is awesome and helps people accomplish something.
What I mean by "open source doesnt work" is simple: Writing software is trading life-time for code, it's costing you something. This is not even about profit, cause I'd argue most of these licenses basically aim at covering some of that cost. I dont think any engine vendor is making back the investment they put into their releases
There is also the issue with switching licenses down the road: by that time the genie is out of the bottle and folks can just fork an older version of a software. It's true that this can be something good(see the whole hashicorp or redis mess), but it also means that you have basically given up control on what people do with what you created.
Actually there is nothing wrong with that, but people rarely take the ownership and run with it, instead there are cases where they try to get more investment from the original author for their individual cause
Now taking a look at all the libs / engines you mentioned
My previous message was kinda a stream of consciousness so I didn't really state my thesis. It should be that "Expecting reimbursement for a shared source project is poor for both the users and the developers." Just to get that out of the way. While I have my problems with the FSF, the (L)GPL licenses are intended to encourage that type of learning. At that point, BSD or MIT was a niche of course, but nowadays we have so many permissive licensed software that most would just learn from those instead. There is no reason for someone to use your engine at that point. I also don't mean learning to make another engine, I mean learning to use your engine and spread it. Very rarely can you copy code without understanding it. A codebase is a complicated web that you still have to detangle.
My previous message was kinda a stream of consciousness so I didn't really state my thesis. It should be that "Expecting reimbursement for a shared source project is poor for both the users and the developers."
Cool, why though? You pay for your internet service
Most of the pieces are accessible and in theory you can roll your own infrastructure, but you pay someone to take care of it for you
I think that's a totally valid approach that somehow gets questioned when it comes to source-code
That is what my first message was trying to prove. FlaxEngine has shown to not really be successful, and I can't find evidence of a project that has earned enough to contribute financially to FlaxEngine. My internet is through AT&T, they are descended through a company that is almost 150 years old. They obviously ran a telephone service for most of that time which built up confidence in the public. Similarly, Epic Games has made successful games that were used to bring success to Unreal Engine. I am not against people selling things or making money, I just don't think it is viable.
If you release an open source project and make money, that is good! If you make a project that you expect people to contribute to and give you money with no previous track record, then it is way more questionable.
If you want to see a decent way of making money from Open Source you can look at Armor Paint. They have open sourced their work under the permissive zlib license and sell precompiled versions on their website.
ok, one part is trust & track record. BUT: The moment you pay something you have already long received something.. it's not that you invest into the future but rather reward the past
Technically anyone can build it themselves and even redistribute it, but they have sold around 15,000 copies for around $19 according to their website.
Why would a developer who is expecting to make $250,000+ pick a software that limits their income and get limited support?
Epic Games can handle that
(gonna take a break, i'll be back)
If that software enables & facilitates your success you perceive this as a limit?!
One of my examples is Red Hat and how even though there is complete clones of it out there that do the same thing, companies pay them as it is trusted and they have an insane amount of resources for those paying customers.
A single person cannot do that
Technical advantages aren't very important for companies
And if the goal is to take a fair share of the revenue produced by large companies, I think that has failed
doesnt really make sense to me
You make money from companies by providing a service, not a product
companies choose the service by what they can get the best support from
mucho texto
just gonna say that some apps go with free-compilation/paid-updates or even free-download/paid-distribution (i mean that its originally free but you can buy through steam or itch to support the devs) scheme so maybe its acceptable this way
thats how aseprite and krita respectively do it
^ i am perfectly fine with that model especially since you are planning to have an editor
We'll see. There are some differences when it comes to the architecture that require sourcecode and a prebuilt binary might not even make sense (at least to a certain extend)
cppia is bytecode tightly interwoven with cpp code, so if you build new bytecode you need to compile vs. the engine lib and tell cppia which code is compiled into the host so it doesnt include&generate duplicated code. Sounds weird but that is actually what makes the setup so powerful. Im still discovering the workflows
Honestly it is probably way too early for this type of discussion. I am just passionate about this topic lol.
it is early, but still nice food for thought. much appreciated
large companies want other large companies
This is a very untrue statement. 'companies' don't particularly care who they go with, they just want someone or some entity to be able to do the job and is reliable.
Companies just so happen to conflate with that prospect as there's a track record associated with your work. Whether it is big or small
a simple example of this is Ian
It is 1 guy who has contracts with very very large organisations
from the UK's health care service to the French government
what matters most is not the company or the revenue, its how likely you are to be able to deliver a good product
Also what's with the focus on the 'big companies'
do you believe that there is only free or billions of dollars?
how about just sneaking yourself an extra 20k a year?
when someone uses something they like, it is in their best interest to fund said project
I truly do not understand this idea of working for nothing, it's like there's no value for life itself.
I'm not against opensource or anything. But I hate polarisation. There is room for everyone to do what they want to do
there is no 'absolute better way'
redhat's model works for them because they're redhat, go and try copying redhat's model for yourself and see how quickly it will take to start earning a billion dollars
^ message comes across a bit passionate lol, it isn't, just trying to be factual
its like we can't copy js model and superimpose it on haxe and assume we get the same outcome
the world isn't that simple
Reread what I said, that was actually one of my points. Red Hat works because they have tons of resources. I am saying that a single person isn't going to be able to do a shared source + payment model.
I compared Red Hat and Epic Games as they are both large companies that sucessfully profit off of a shared-source model. Flax Engine was an example of someone using the same model and not reaching success as they don't have the pre-existing resources.
Anyways, too early for any of this like I said.
yeah I'm saying this statement isn't accurate
a model doesn't imply that everything can use said model
businesses are extremely complex
especially large ones
ever baked a cake or something and forgot the baking soda? a small ingredient, whole cake is ruined
businesses are like that but on a much larger scale
these things don't work just because a model exists, they work because the people make it work
not every person or group of people can make it work, you're applying way too much value to the model
I think the convo is alright to put out there, dw about it. I'm also just a lil curious on this idea that 'open source is best'
because in my experience most opensource equivalent products never match the quality or care of financed or closed source ones in general
expectedly so, because there's no conversion for the life investment
Sheesh I've read all of this, quite the read.
I personally think that having source available at all is already quite cool (even if it's restrictive), at the end of the day if the goal is to make it a commercial success, there are many factors to said success: what license do you use, how good the product is, etc. At the end of the day if the complete package of your engine and/or framework is enticing, you may see commercial success. If your goal is to not have commercial success, it really doesn't matter what license you use.
Also the thing of "giving back to the community" is not a required one, it's an optional one (although it is very nice to give back to the community :D)
Making open-source projects can be quite exhausting, especially with certain expectations people may have.
I think a perfect example of this is the minecraft plugin "PlotSquared" where the developer changed his free plugin into a paid one (on websites like spigotmc where you can download a build), but the source code is still open source under the GNU license. Why? Well the developer felt people were acting too entitled to their support.
For this reason a source-available might be a nice option on a personal level, on a commercial level it may have it's benefits too, although that is outside of my knowledge to discuss about.
Also the thing of "giving back to the community" is not a required one, it's an optional one (although it is very nice to give back to the community :D)
important to bring up, bringing commercial success to the ecosystem is also giving back to the community
they are not mutually exclusive
That is very true, I didn't think of that yet.
Very big thing to "give back" actually.
That's bc guiding a vision is pretty time-consuming
it really is 😅
In any case, as all of this grows I will state the goal and expectation very clearly and hopefully deploy a model/process that caters both
There are some fundamental differences to other engines like godot or flax. E.g. these engines dont require you to compile code and you can build projects via scripting. With cortex you almost always want to build from code all the time in some way shape or form
Also, why everybody is talking about "commercial success"?? That implies someone is getting financially set. Which almost never happens without auxiliary services. Reality is that we should consider it "covering costs" ...
Is it possible to get an invite? I would like to play around with the HaxeUI backend.
sure. once the current pass is complete & I have updated all the samples I let you know
Hey! It seems like I am having some technical difficulties.
It seems like NanoVG is trying to free fonts I already freed when calling Nvg.destroy(vgPtr)



I have verified that my code frees the font once.
But when deleting the VG instance it tries doing it again
As soon as I don't manually free the font resources It doesn't crash
did some more investigations

it properly loads the 2 fonts
then frees the 2 fonts
but then, for some reason, nanovg thinks that one of the fonts are still loaded when i am about to shutdown the application
font0 (regular.ttf) gets freed correctly
font1 (bold.ttf) does not get freed correctly
the third log btw is me trying to find font "font2" which doesnt exists as a sanity check
Wait I think I figured it out
Does NanoVG change other fonts their ID's when freeing them?
Never mind, it just seems to be unable to free my second font?
Or it partially frees it but fails? Which causes other problems?
nvg.freeFont apparently returns false will check where that comes from
I think I've found the problem

So lets say font 1 gets created, nfonts should be 1
Then font 2 gets created, nfonts should be 2
font 1 gets unloaded, nfonts is now 1 again
But font 2 still resides on an index that fonsGetFontByName cannot reach, so it will be unable to free it.
And I think this could cause something else to hit the fan, causing the crash.
YES! That is the problem
If I unload the fonts in reversed order it works just fine (second font, first font instead of first font, second font)

So not only will it be unable to find font 2 once font 1 is unloaded, it also will be unable to free it because fonsFreeFontMem has a check idx >= stash->nfonts
It might be worth making a fork for NanoVG to fix this, although it's a very certain situation as this only happens if you have 2 or more fonts, which you unload in order.
wow, nice catch
nanovg is actually forked in linc_bgfx
you can create a pr for linc_bgfx
Should I also make an issue in the BGFX repo itself?
The NanoVG and fontstash repos seem pretty dead.
I added that code from an older version of a nanovg
official nanovg doesnt even have that one (you cannot release fonts)
its wonderful
I should go try actual fishing with this kind of luck LOL
xD
dude, the whole font handling + atlas stuff is weird
if you were to use fontFace instead of fontFaceId it would not be able to find the font you want
Yeahhhhh
NanoVG and fontstash are pretty outdated sadly :(
Yes
hmm, Im sure a few hours of review would yield some ported fixes, but in essence I think the fonts just need some tweaks and it would be fine as is
For now, I think if you checked if stash->fonts[idx] is a nullptr you should be able to remove the idx >= stash->nfonts check
while the findFont is still broken, it should be ok as you can still use fontFaceId (which doesnt use findFont)
my dayjob is sorta cooling down again, so im gonna invest some time in the coming days and see if we can clean up things a little
Alrighty!
let me try this out RQ, if it works I will make a PR 👍
awesome
I added this widget to my GH profile and now Im super pissed, I gotta write more haxe... 😄

HaxeFTW
well uhh, it seems like I still am a bit unfamiliar with how fontstash works
so uhh
I don't think I know how to fix it 😅
Just report your test-cases then
say if you cant come up with a PR, you can just file an issue for me with the details so i can take a look and try to fix it
Yes I can
Made an issue at https://github.com/dazKind/linc_bgfx/issues/3 as It seems like NanoVG isn't a submodule.
@dusk anchor Open Collective looks super interesting! Thx for bringing that up
im currently updating the included libs, this is a change inside bgfx that will require you to regenerate & rebuild your visualstudio solution
just pushed the fixes to linc_bgfx: https://github.com/dazKind/linc_bgfx/commit/336c98600a717af4fd99b2c853a2782e8dd70654

gah, fontstash is ugly
as a first step I updated nanovg and fontstash to the latest version
there are some new functions that take a font index
Awesome!
holy moly
I think I finally found an idea for the scene system and resources
It's ECS but you have a node system similiar to godot
There are soo many cases to think about though. Like you have a scene, you add a new component via cppia, add it to the node/entity and then you save, then you change the component & recompile .. it needs to detach all the components of that type and reload them
and Im not sure I wanna do that 😄
The cppia reload needs to annouce the changes to the engine so it can react to whatever
like we wanna retain as much state as possible
@grizzled laurel I understand the mess with attachments now

ayeeee
you should really write docs on these things though
or wait
does it still follow the normal, default, bgfx api?
ofc
the functions have some adapted names but this is straight from here https://github.com/bkaradzic/bgfx/blob/master/examples/21-deferred/deferred.cpp#L529
cortex abstracts that and you have a simple RenderTarget class you can create and it does all the setup for you
that is pretty nice
Heya! So I want to make a feature in one of my projects. But it requires a transparent framebuffer, is this possible in linc_bgfx. I figure I'd ask before I spend alot of time implementing the feature I want
sure
e.g. the included nanovg uses a transparent framebuffer to render to
Ah I see
awesome!
Is there a way to access NanoVG's framebuffer?
Basically, I want to attempt the capture idea that i had a while back
Now i did some more research
apparently download textures is asynchronous

So I'd like to try and use that to my advantage to be able to record video at high framerates
They aren't yet?
I only added externs for the functions above
Ah
should be easy to add
Out of curiousity, was there a reason for that? (aka something was broken?)
nah, just didnt think we would need them yet
Since we are on the topic anyway, do you think this would work out?
The idea is to get the pixel data and throw it straight at ffmpeg
package util;
import bgfx.ViewId;
import bgfx.FrameBufferHandle;
import nanovg.Nvg.NvgContextPtr;
@:structAccess
@:unreflective
@:native("NVGLUframebuffer")
@:include("nanovg_bgfx.h")
extern class NVGLUframebuffer {
public function new();
public var ctx: NvgContextPtr;
public var handle: FrameBufferHandle;
public var image: Int;
public var viewId: ViewId;
}
@:include("nanovg_bgfx.h")
extern class NvgFramebufferHelper {
@:native("nvgluCreateFramebuffer")
public static function createFramebuffer(ctx: NvgContextPtr, width: cpp.Int32, height: cpp.Int32, imageFlags: cpp.Int32, viewId: ViewId): cpp.Pointer<NVGLUframebuffer>;
@:native("nvgluBindFramebuffer")
public static function bindFramebuffer(framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
@:native("nvgluDeleteFramebuffer")
public static function deleteFramebuffer(framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
@:native("nvgluSetViewFramebuffer")
public static function setViewFramebuffer(viewId: ViewId, framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
public static inline function resetBindFramebuffer(): Void {
untyped __cpp__("nvgluBindFramebuffer(NULL)");
}
}
this doesnt support cppia yet, but posting it here for anyone who needs it.
could work
thx! I can make that compatible
I already have done that :D
package kawaii.rendering;
import bgfx.ViewId;
import bgfx.FrameBufferHandle;
import nanovg.Nvg.NvgContextPtr;
@:structAccess
@:unreflective
@:native("NVGLUframebuffer")
@:include("nanovg_bgfx.h")
extern class Native_NVGLUframebuffer {
public function new();
public var ctx: NvgContextPtr;
public var handle: FrameBufferHandle;
public var image: Int;
public var viewId: ViewId;
}
#if (scriptable || cppia)
@:build(linc.LincCppia.wrapStructExtern('Native_NvgTextRow'))
class NVGLUframebuffer {}
#else
typedef NVGLUframebuffer = Native_NVGLUframebuffer;
#end
@:include("nanovg_bgfx.h")
extern class Native_NvgFramebufferHelper {
@:native("nvgluCreateFramebuffer")
public static function createFramebuffer(ctx: NvgContextPtr, width: cpp.Int32, height: cpp.Int32, imageFlags: cpp.Int32): cpp.Pointer<NVGLUframebuffer>;
@:native("nvgluBindFramebuffer")
public static function bindFramebuffer(framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
@:native("nvgluDeleteFramebuffer")
public static function deleteFramebuffer(framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
@:native("nvgluSetViewFramebuffer")
public static function setViewFramebuffer(viewId: ViewId, framebuffer: cpp.Pointer<NVGLUframebuffer>): Void;
public static inline function resetBindFramebuffer(): Void {
untyped __cpp__("nvgluBindFramebuffer(NULL)");
}
}
#if (scriptable || cppia)
@:build(linc.LincCppia.wrapStaticExtern('Native_NvgFramebufferHelper'))
class NvgFramebufferHelper {}
#else
typedef NvgFramebufferHelper = Native_NvgFramebufferHelper;
#end
very nice system you made for cppia
really easy to support
also a note, i didnt support the various overloads of nvgluCreateFramebuffer yet
then ig i will try
I think I've found a problem

It seems like C99 and C++ types are mixed?
bgfx::FrameBufferHandle and bgfx_frame_buffer_handle_t
the original extern generator worked on the c99 header
ahhh
would need to review, you are just calling that func?
#if (scriptable || cppia)
@:build(linc.LincCppia.wrapStructExtern('Native_NvgTextRow')) <--- wrong clsss name
class NVGLUframebuffer {}
#else
also what for fix do you suggest
i can prolly hack my way to success by using untyped __cpp__
but if you have other ideas let me know
since it's only a struct with idx
I just need a simple example how you use it
public function getPixelData() {
var tex = Bgfx.getTexture(handle.value.handle, 0);
trace(tex);
}
handle.value is of type NVGLUframebuffer
.handle of it is of type FrameBufferHandle
getTexture requires one of those
but due to the c99 and c++ mismatch it doesnt want to work (currently)
FrameBufferHandle internally is just a struct with idx (integer)
ah ok. the binding in general uses c99 types and the nanovg extension uses cpp types
ah
altough bgfx.FrameBufferHandle is from bgfx, not nanovg
and getTexture is also from BGFX
but you use NVGLUframebuffer and that contains the type bgfx::FrameBufferHandle, not bgfx_frame_buffer_handle_t
But FrameBufferHandle is from bgfx, so you would expect its c99, but its not
we have the same problem with bimg and debugdraw. I think I need to redo the types to use cpp types everywhere
Yeah would probably be a good change
I guess we just need a cast there

seems like this will work
it looks jank (and it probably is)
but it should work
availableAt seems to return a valid frame number
I just need to implement the callbacks and I should be done
Daz, by any chance, are you aware of any limitiations on readTexture?



I seem to get RNG crashes
for some reason "src" is null
sometimes it has no problems
sometimes it has problems
sounds like a threading issue
I mean I run Bgfx.renderFrame(-1) at the start
so it shouldn't do multithreaded rendering
Wait that does get me to a different point
the NanoVG FBO doesn't support readback by default probably
GitHub
For implementing something like AVI logging, it would be nice to be able to read the contents of the backbuffer, or even a render target, back via the CPU. It appears that bgfx::readTexture can acc...
well the thing is
I probably cannot use BGFX_RESET_CAPTURE
you want a framebuffer
Because, I want to render faster than realtime
maybe this help to establish some context: https://github.com/bkaradzic/bgfx/issues/802
just call bgfx::frame twice after bgfx::readTexture and return the result
😄
well i got most of it working
I got a "queue" working
because I don't want to block for 2 frames till its complete
block 2 frames? just call it twice in your current loop
Won't that block the cpu?
Because it has to wait for it to read back the pixels from the GPU
It'd prob be better if it did its thing in the background
My goal is to achieve a program which "renders" video, ideally as fast as possible
I have literally no idea. I have too little experience with bgfx internals atm
Im currently working through the last renderer bits and once that is working I will expand it. atm only the material system needs some more love and then we got all the pieces finally
I hired 5 awesome developers in the last 2 months so Im bound to regain some much-needed freetime soon
yeah, it works like 90% of the time, there is still some occasional manual tweaking necessary
but happy that it works 🙂
:O
That's epic
What kind of edge-cases are there?
things like the attachments and some pointer stuff related to bx::Memory can be problematic
I see
you know
I think its my pointer stuff that messes up readback
because if i check where it fails in memcpy itself
it is after a part with ; store ... bytes to destination
which makes me think that is what is messed up
OK I think I fixed it

will post this here for whoever wants to do the same thing
nvm that didnt fix it
Ok so i've learned a few things
So basically, the crash is because of the Blit and it trying to blit nothing in the first frame
But then, DX11 just gives me a whole bunch of 0's
VK and OpenGL do work?
So I guess I'll wait till callbacks are supported
Since capture should probably work
😉

reached the point where things come together on the ECS level
:O
starting to update again, stealthily 😄
Today I learnt that in a heavily multithreaded app you might run into gc locks when you overdo starting and reading back long-running processes
specifically if you use Inputs to read stdout/stderr
good part, it wont break anything, but threads will start to wait on eachother. That one was a real bitch to nail down
@ionic badger I think I forgot how showcase crossposting worked, once again 😄
nah i think you've done it correct
but for some reason there's some "delay" in the transfer, i'm not sure where that delay has come from though
ah ok! Good to know
i tried looking into it a lil while back but couldn't figure out any issue on my end
i'll check to see if there's any errors in the mean time tho

errr, maybe it is my fault
yeah message seems to be stuck, nevermind
could you repaste the exact same message
sure, lemme clean it up
okay, yeah, fault is defo on my end. No idea why someone else used it the other fine
i'll look into it
np, thx
third time lucky?
[showcase] Finally got around to do some major work on cortex:
The first iteration of the new 3D renderer, new assetpipeline, gltf/glb support, scenes, meshes, materials, shaders, haxeui, hmecs + other stuff and everything hot-reloading, ofc. 😍
Watch it in action here: https://www.youtube.com/watch?v=EjqdzZzXSs8

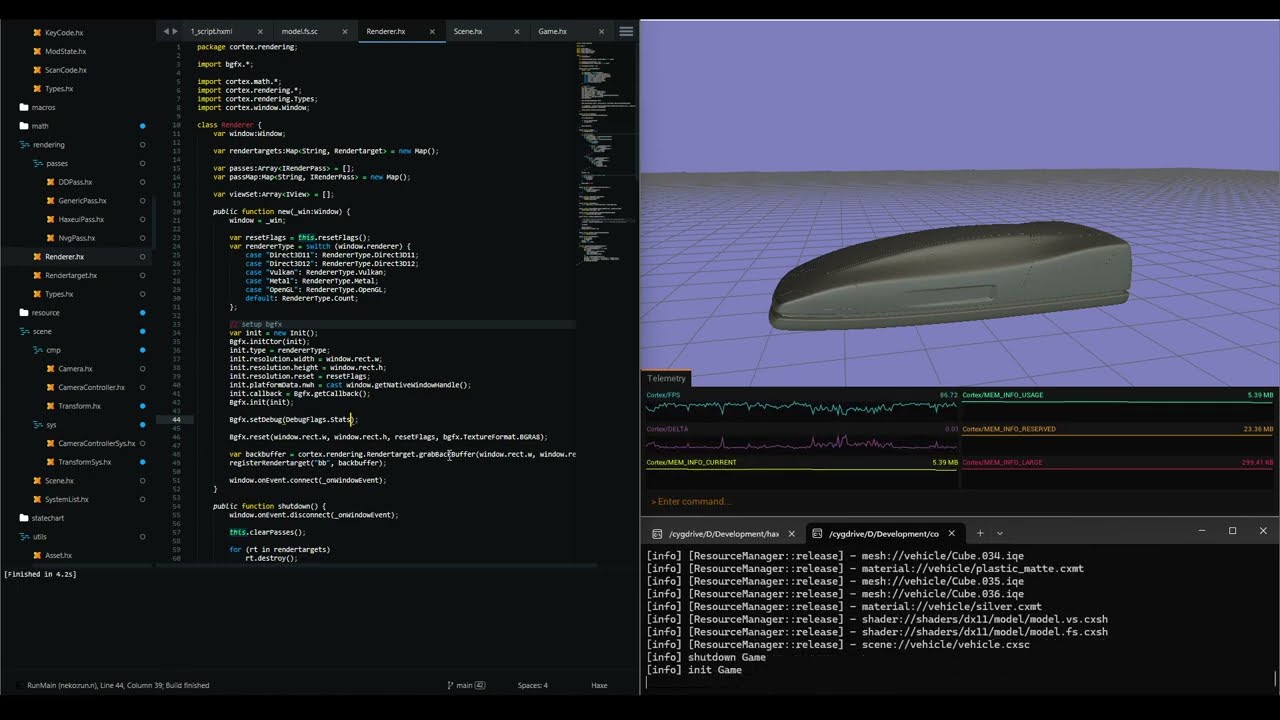
hell yeah
win 😄
refining the gltf importer and materialsystem some more. got feature selection for shaders done, now need to add textures and samplers


yay, uniforms and samplers + textures are working

Hey, how far did you come along with this? Wondering for a friend 😛
Well, I decided to make #1268509269104525352 so that the code im writing can be re-used in the future. That means that for now JoltHx is on hold, but will be continued in the near future
ah ok. What did you use to generate the initial externs? The docs?
Yess
I got stuck on the fact you needed to overwrite extern class methods
so i figured if i needed to do all kinds of stuff to get it to work, that i might as well just make said code re-usable
From experience, any auto generation will only get you so far. There are certain patterns where you need to manually fix things
Could be, but the further i can get the happier i will be
sloowly getting there

shadowmapping? Nah, that's just a port of my old IBL + pbr shaders



uniforms are behaving wonky. looks like I cannot rely on the compiled shader binaries to contain all the valid bindings, which is kinda stupid
other than that, things are looking fine. testing more and more things
Sick!
Altho how can it be that a shader does not have all valid bindings?
You would expect it to have that
It's due to shader-compilation and bgfx having to support all kinds of apis. I appraoched it like my old renderer + foo3D, being super specific about everything. Newer APIs are less strict compared to old OpenGL and its attributes(https://github.com/dazKind/foo3d/blob/experimental/foo3d/impl/OpenGLRenderDevice.hx#L273)
GitHub
Crossplatform lowlevel 3D rendering API in Haxe. Contribute to dazKind/foo3d development by creating an account on GitHub.
also had to patch shaderc since it reports samplers both as samplers and image resources when you query the uniform-infos under dx11/12. All looking good so far
some more fixes and cleanup for uniforms and samplers. finally all backends behave the same ❤️ 🙂


GG
automatic splitting of meshes per material is a little issue in my gltf / iqe importer, but for the moment it's not a showstopper
gah, turns out the mesh splitting was actually an index error when converting gltf to iqe
you gotta love file formats and translating them
totally
need to refactor my resource system for the 3rd time in 2weeks
have to introduce proper resource dependencies to allow huge resource-trees to resolve and load in order
small scenes work nicely but once they increase in complexity with a lot of subresources I get a couple of nasty race-conditions
esp when scenes are cooked and hot-reloaded
What kind of race condition?
Or more specifically, how did the race condition happen


Resources have hard and soft dependencies and form trees. it can happen, that a change happens while you are already loading, then you need to recover and update the hardlinks
just spent 2 hours battling the file system
while working on the resources I had a little idea: What if I use a statechart to decouple the behavior from the business logic? Turns out it was a good call since the following kicked in and I have found several issues that were hidden before!

A benefit of using statecharts is that it is easier to identify more states than otherwise. Especially error states are highlighted, as are shorter in-between states.
looks like I got it

FUCK YES
no more issues, works even better than before. hot reloading even complex scenes just flies along nicely using 15 Threads
Ignore the shading of the materials, I still need to set all formats and shit correctly. Here is the beauty: https://www.youtube.com/watch?v=4GtWX40Irl4

What a beauty
Out of curiousity, does it allow for any way to check the progress of the current reload?
might be useful for a notification or something alike
sure, you can check the state of all resources via the resource manager. Though there is no such global concept of "we are reloading now". It works things as they happen. individual progress of resources is not included since it needs to be added to the resource-loaders for every file-type, didnt bother
wooohooo, we are getting close to 10k 😄

can i ask 10K of what 🙂
lines of haxe code 😄
ok ^^
@ionic badger hey, I saw you using hxscout, did you use the download or build it from code? For me the download is running super unstable
Im currently thinking of forking and reworking it
just used the precompiled one
2 secs there are some flags you want
- HXCPP_DEBUG_LINK
- HXCPP_STACK_TRACE
- HXCPP_TELEMETRY
I got them
it is a bit glitchy but it seemed to work for alright for me
holy shit, how many github accounts does jcward have
ah looked in the wrong place
This seems to be the actual app: https://github.com/mpoint4u/hxScout

GitHub
A Haxe Scout Alternative. Contribute to mpoint4u/hxScout development by creating an account on GitHub.
if you do fork scout tho lemme know, i'll be happy to use it
seems like a limitation x)
i'm browsing through the source and it seems like a lot of work
but i guess a lot of this is actually just "inefficient" ui creation
most of it is the ui drawing / styles
i just looked at the 1.5k Main.hx and was like... oh mainly UI...
like wtf, this function: https://github.com/mpoint4u/hxScout/blob/master/src/client/src/Main.hx#L1070
lol i was just looking at that
in some ways, this looks like hell to write
but in other ways, it shows the dedication
😂
I dont get how it works. This is an enter_frame handler, and it modifies the displaylist with new objects every frame. I can only assume it renders on input events
i think as long as you can prove getting the telemetry data out of a running process, the rest should be pretty simple tbh
the treeview is basically built/render immediate mode style
maybe because it can be really big?
can isolate that pretty easily
the ui in scout is glitchy anyway
ok, so suggestions for the stack? cortex font rendering is not ready yet. So I might wanna give nme a shot. You boys in?
im listening
well, i just mean if we have a lib that gets telemetry data to "an app", and that app is haxeui, then we can use any backend
haxeui-nme sounds like a nice start, but we can also use haxeui-openfl, haxeui-raylib, haxeui-ceramic, etc...
been meaing to give haxeui-nme the "once over" so this seems like a good excuse
(canvas i think should be good enough for the graphs - i doubt we need anything "crazy")
coolio. I will isolate the server part into a lib
I'm gonna be biased with haxeui ceramic
my point is it doesnt really matter - we can run them concurently, i do it all the time
lol this is true

thats my "goto testbench" app
so its just a different hxml file really, you can use haxeui-ceramic, i can use haxeui-nme, daz can use haxeui-cortex, etc (as long as we dont use framework stuff ofc - which i dont really see why we would need to)
I think question is more to do with 'what is the release binary' gonna be in for the most part
the one that performs / looks the best... ?
yeah
it should be the most chill, rock-solid backend with good font rendering
we'll have a profiler to profile the profiler 😄
yeah, i betcha it'll find haxeui leaks 🙂
I haven't even ran a profiler on my haxeui backend yet
I'm sure there's gonna be stuff lurking around
(i just did, haxeui is a hoooog) :DDDDD
wdym? 😮
2 secs
I'm still curious tho because I've implemented some specific lil tricks here and there so it would be cool to see if they actually do anything

BUUT to be fair, this is debug & scriptable, haxeui fully in cppia, rendering graphs
and I reduced it already, since I was clearing componentsGraphics for no reason
dude, this is useful when it works! 😄
for sure there will be bottleneck though, i have profiled it a little and done a few passes for memory etc... but no doubt there could be improvements (another reason to have an hxscout clone!)

well i just ran a quick test
button demo xml^
however booting up haxeui-ceramic seems like there may be too much that needs polishing for it to be used for an app
actual backend wise that is*
wdym?
bugs here and there and things aren't looking as close to the og haxeui
was trying to measure the canvas as icons demo yesterday and it just crashes on native as well lol
performance wise I recon it will be really good
just the backend still needs that polish
well, mebbe an hxscout clone will be better for everyone... find some core bugs / leaks, find some ceramic bugs / inconstencies, etc

yeah, looks nice... but again, choosing which backed we want to use is kinda irrelevant ... we can use any one / all (potentially)... its kinda the whole point of haxeui... is that you arent backed into a framework (unless you want to be by using framework specific features)
yeah was just browsing around and checking state as i've been apart from it for a while
😆
an updated hxscout would be very nice, it's in dire need of it
I made an attempt a few years ago but from a different angle, i.e. take the telemetry packets and write it into a file format that can be read by an existing tool
but I didn't get very far with it as the hxtelemetry format is based on an old flash format, so carrys a lot of baggage which makes it a pain to use
I also wanted to add more telemetry as what you get at the moment is quite basic. Even when I used hxscout I never found is particually useful, especially compared to similar tools in other ecosystems
i think this is a really nice idea... make it "tool agnostic"... so the front end is just a thing that reads a file and puts it in a UI
does it matter though? Cant we just ignore the bits we dont need? Or do you think its worth totally revamping the format itself?
(i dont even know what hxcpp spits out with the correct flags, or where, or how)
from what I remember of the hxtelemetry protocol there's an initial handshake in AMF which is some old flash serialisation format
it then switches over to a json format
right, hxtelemetry is built ontop of data that hxcpp spits out, is that accurate?
I think so, but I also believe the hxcpp telemetry stuff was added specifically for hxscout / hxtelemetry. so its not a case of that telemetry already existed in hxcpp and they were working around that
ah, gotcha - i thought it existed already and hxtelemtry was just taking advantage of it
at the time I didn't want to change it much as I also didn't want to break compatibility with hxscout, but if thats not a concern then its probably fine to change / extend the format
i dunno, i mean, i know nothing about the format, or what it spits out - you sound more clued up - and if you say its somewhat bloated and we dont care about compatibility then... ... ... ...
yep, it's based on amf
this is an issue I opened back in 2018 about the format, might be useful https://github.com/jcward/hxtelemetry/issues/62

GitHub
Hello, I've recently been working on some stuff which requires reading haxe telemetry data, while I've got the general gist of the format down and can successfully read telemetry data from ...
but, regardless, i defo like the idea of something sitting there dumping out json files (or whatever) that the [any] app can read at will...
I'll prep the lib over the next few days and then we can fiddle with the direction i guess
hxscout isn't open source so how you interpret the data hxtelemetry spits out to make nice graphs was a complete mystery to me as its in an odd format. Jeff posted some of the code that hxscout uses to generate the graph data
in essence, hxscout is dumping the files already and then reparses them
I found the code
jesus, that code block 😮
not sure if its the latest version(looks like it) but it's here : https://github.com/mpoint4u/hxScout
GitHub
A Haxe Scout Alternative. Contribute to mpoint4u/hxScout development by creating an account on GitHub.
so what does hxcpp spit out? I mean, like, is it using this protocol also?? in files? pipes? sockets?
hmmm, alright
you need to include the lib for the socket & connection, hxcpp + telemetry just tags things you can pick up and send with the lib
client_socket = s.accept();
reader = new Amf3Reader(client_socket.input);
ouch so it looks like hxcpp is spitting out AMF format ... ... ?
hxcpp doesn't directly output anything over a socket, hxtelemetry calls into hxcpp telemetry data and then wrangles that out a socket
you can see the lovely untyped code here https://github.com/jcward/hxtelemetry/blob/master/hxtelemetry/CppHxTelemetry.hx
GitHub
Haxe Telemetry Generator for hxScout. Contribute to jcward/hxtelemetry development by creating an account on GitHub.
and the hxcpp side here https://github.com/HaxeFoundation/hxcpp/blob/master/src/hx/Telemetry.cpp
GitHub
Runtime files for c++ backend for haxe. Contribute to HaxeFoundation/hxcpp development by creating an account on GitHub.
ok, so if im following / understanding, hxcpp has a feature where you can "plugin" some code that it will use to store its telemetry diagnostics:
return untyped __global__.__hxcpp_hxt_start_telemetry(hxt._config.profiler,
hxt._config.allocations);
That can be pretty much anything, but hxtelemetry takes this data, turns it into an AMF format and transmits that over a socket to the client - that about right?
public static function compile_fails_without_this_function_definition():Void
{
// DCE? seems to need this for the cpp code above...
var b:Bytes = Bytes.alloc(4);
// Tried various forms of:
// @:cppFileCode('#include <haxe/io/Bytes.h>')
// With no luck
}
🙂
yeah, pretty much, hxtelemetry also has writers for neko and hl which takes their telemetry structures and writes it out into a common format for hxscout
that entire string function code block is mad
then it feels like a good time to dump hxtelemetry also, and come up with an alternative (better) format... especially with all that untyped, amf and the fact no one really knows whats going on
i think the hxcpp side seems solid, its a nice arch... supply some data holders, or callbacks or however it works, and start receiving raw data... then we can just process that and do what we want... sockets, files, whatever...
feels like it would be alot easier to interpet and display that data than trying to work with two weird mismashed formats (FLM, HXT - all over AMF or something)
alright, ive gone though a fair amount of the code, just browsing and im fairly convinced, if we want to do this, we should just plugin to hxcpp directly... not only are there layers we dont really understand, but said layers seem pretty mental... whaddya reckon?
I think that pretty sensible if compatibility with hxscout / hxtelemetry isn't of interest, also allows adding more telemetry functions to hxcpp without needing to fit it into hxtelemetry and not break existing hxtelemetry based stuff
hxscout / hxtelemetry isn't of interest
yeah, i mean, its a valid point - my personal opinion is "clean break" - forcing ourselves to handle some legacy, unmaintained protocol seems like tying a hand behind our back and going swimming
adding more telemetry functions to hxcpp without needing to fit it into hxtelemetry
yeah, very true...
over to you @void condor - probably while we've been talking about it, Daz has written the hxcpp plugins, come up with a new format and protocol, and written half a client 😄
well if we look at the latest hxscout version that daz linked, it's still 9 years old
i don't think there can be a cleaner break 😂
true, but i think the original idea (maybe im wrong) was to use hxtelemetry, but looking at that lib, and somewhat understanding how flexible hxcpp is with this, it seems like the alternative ("start again") is better
one limitation of hxcpps telemetry stuff is threading, the reason why each thread is a different session in hxscout is because each haxe thread has its own telemetry tracking due to the frame based approach of hxscout.
I've always found the frame based nature of it quite odd, guessing this is just a hold over from adobe scout? Makes non game based applications really difficult to use with hxscout as well as heavily threaded applications.
I've always preferred the "capture memory dump" approach you find in most other memory debuggers. they allow giving you that "whole program" view / analysis.
Giving information on object retention paths, heap fragmentation, generation capacity, etc, isn't really do-able with the frame based approach and thats the sort of information I was wanting to add ages ago.
lol, i wish. currently at work cto'ing. im fine with whatever
fact is we need a profiler/tracker beyond the target tools
as a start i would prolly learn from the exisiting setup and then iterate/replace it
there is, "tracy" is what I was planning on targeting but never got around to, its basically a generic abobe / haxe scout https://github.com/wolfpld/tracy

GitHub
Frame profiler. Contribute to wolfpld/tracy development by creating an account on GitHub.
like hxscout its memory profiling is pretty basic though, its focused more on cpu & gpu profiling
could be super useful / cool if we could pass hxcpp data to that in the right format
what what I remember there's a c++ api you integrate with, so theoretically you could use standard hxcpp externs to get cpu profiling
think you'd need tighter integration with hxcpp to track memory allocations and the like though, been a while since I looked at it though
it should already be compatible with hashlink as well, it can import chrome profiler dumps which I believe is what hashlinks profiler generates
lots of options... though for simple stuff, i do prefer the "cut down" UI of hxscout
the ui is similar to VS iirc, where you can drag around and dock different windows to your liking
but, yeah, the screenshots don't make it look simple
you can play with it here: https://tracy.nereid.pl/
niiiiiiiiiiice
well well well

@obtuse burrow this is easier than I thought. We can just include it in hxcpp, hidden behind some defines, litter the whole hxcpp code + macros with scopes/markers and supply a lean cpp.* extern for using these in user-apps
so thats telemetry from hxcpp inside cortex and then imported to tracy?
oh, ok, so they supply like an api/some code or something that sits in hxcpp?
yep. Just included the source-files of that client in hxcpp, wired it up and the magic happens. gimme a sec, wanna try something

Easy!
now we can measure haxeui in nanosecounds! 😂
10M calls to get screen bounds? 😮
oh, 2 nanos...
or is that picos? actually not sure what MTPC means
I really dig how it deals with the threads:

nice! wonder if there's an api to map frames / source to another language
currently looking the Stackframe macros, I think we can just forward these
would be good to have the ability to toggle between c++ and haxe, so you can hide the _hx_run and other mostly irrelevant gubbins
hmm, it's a bit tricky, since we depend on compiletime constants
we would have to modify code-generation a little
Is it the FrameMarkNamed macro for stack frames?
could you modify the constructor of hx::StackFrame to call that macro with the name from the provided StackPosition?
jo what
that is mad quick
this was proposed at 16:11
20:49 and it works
that is crazy
really just a 20min hack
what's even crazier: I found a super shitty multithreading bug this way... 😄
my resource manager wasnt using it's threadpool correctly, so some resources where loaded in the mainthread even though we had idling workers. This is a bug that has been in the code for the last 7 years
looking at it
the magic of profilers
"DazSpeed"... somewhere between the speed of sound and the speed of light 😄
Nahhh the man exceeds the speed of light lol
E=MDaz^2.... 😄
Haxe: "Oh yeah we are stuck with pretty old tooling for profiling"
Daz: "nahhh just a 20 minute hack mate"
xD
@pearl slate @ionic badger @obtuse burrow In case you wanna try it, I just pushed the tracy prototype branch on my fork here:
https://github.com/cortex-engine/hxcpp/tree/feature/tracy
Basic instructions are here: https://github.com/cortex-engine/hxcpp/tree/feature/tracy/src/hx/tracy
GitHub
Runtime files for c++ backend for haxe. Contribute to cortex-engine/hxcpp development by creating an account on GitHub.
oh, now i need to figure out if i can switch hxcpp in ceramic
i recall issues with that in the past
You can use haxelib dev for it and then do haxelib run hxcpp cache clear
should give you a clean slate
ceramic uses dev files for its things
can't recall what the issue was in the past, will have to mess around and see
hmm ok
should just work if i overwrite the source files
but keep teh 4.3.2 version name on the folder lol
ceramic "forces" 4.3.2 in haxelib
interesting, I just used 4.3.4 with latest hxcpp

lol
here you go: https://github.com/wolfpld/tracy
GitHub
Frame profiler. Contribute to wolfpld/tracy development by creating an account on GitHub.
i love the idea of typing "tracy" into google an not expecting anything back except "tracy's" 😄
yes i was really surprised to see people in the results
Error: Project.cpp
./src/Project.cpp(67): error C2065: 'FrameMark': undeclared identifierFailed to compile C++
i downloaded the tracy branch zip
hmm

defo got it
oh... i know what's happened here
dw @void condor
i've got 2 config files
i put the defines in the wrong one
ah! ❤️
I pulled the changes into my hxcpp and it seems to work fine
made some changes to get haxe names in the stack calls as well

oh that's super cool

mine is compiling now as well
awesome!
not really a "frame based" program, which I'm guessing is why my tracy looks all odd
or I just don't know how to use it yet
it defo looks complicated
the tracy docs have some directions for that
the docs are very nice
I put FrameMarkStart(position->fullName) in the constructor of hx::StackFrame and FrameMarkEnd(position->fullName) in the destructor instead of the ZoneScoped changes to HX_STACKFRAME to get the haxe names

that also explains your screenshot
but now i just have no idea what i'm looking at x)
also this seems to lag the build quite a bit - is that unexpected?
click on one of these blocks 😄
you can also use all the tracy macros in your code and enable more and more tracing, eg. custom plots etc
it does a lot of reflection stuff setup during the build/compile
or you mean runtime?
ah, well it's sending a LOT more data
here i'm getting stuttering, whereas hxscout is smooth
for me I dont notice it, but I have a powerful machine
nice to see only ceramic things in the stats panel x)
run your haxeui-app with it 😄
but there are some things in here that i didn't catch from hxscout
compiling a haxeui test project now
i'm curious
seems like my haxeui keeps wanting to crash :/
nvm again, i didn't change something
😄

here's what i got
testing against this

ran for some more time
wdym? Problem with haxeui?

nah, just more stuff in the stacks 😄
"revisit haxeui-ceramic backend" is defo gonna be back on the list at some point
no idea why but there seems to be bugs everywhere now
happy to get some more confirmation that chart stuff is doing very good tho
yeah, was getting mixed up in terminology, I was assuming frame referred to stack frame
seems like you have to dip down in to the c api to specify zones with custom names if you don't want to use the RAII macros
I'm getting somewhere, the haxe program deadlocks almost immediately though... need to read through this pdf more

nice 🙂
I think we could customize the tracy macros here and write one that works on a stack position directly: https://github.com/cortex-engine/hxcpp/blob/681d9d7e4bf2acce73708a6525c504ca5081f24b/src/hx/tracy/tracy/Tracy.hpp#L145
what I've got at the moment is two new fields in hx::StackFrame
___tracy_source_location_data tracyData;
TracyCZoneCtx tctx;
and the following added to the constructor after the frame is pushed into the context
tracyData.file = position->fileName;
tracyData.function = position->functionName;
tracyData.name = position->className;
tracyData.line = lineNumber;
tctx = ___tracy_emit_zone_begin_callstack(&tracyData, ctx->getDepth(), true);
and a ___tracy_emit_zone_end in the destructor, basically what some of the macros do under the hood
smart 😄
here is how user-text looks like when hacking the string in there

not sure I like it
but then, this is already super useful
if your hack works then it's even better
I think there are string lifetime issues at the moment, as the client worker thread crashes with the SendString function, guessing the stack strings have gone out of scope hence the memory error

the macros declare static ___tracy_source_location_data structs to avoid this
hmm yes, read about this in the docs, there are some macros that have string + size for making an internal copy I think
this is the best threading overview I've had in a long while
will be interesting if we can also expose the memory stats
the ___tracy_alloc_srcloc function creates that location structure and takes in strings + lengths, but doesn't actually seem to internally copy them...
still end up with the same SendString crash
ah ok
no, never mind, I'm an idiot
you need to use the ___tracy_emit_zone_begin_alloc function with ___tracy_alloc_srcloc
lovely jubbly

this is so damn cool
suuuper nice. Send me a PR 🙈
here's a patch for StackContext.h, you'll probably want to do a bit of clean up / guarding around tracy defines. I just quickly bodged it together
only other change needed is to include the tracy c header somewhere
looooooovely

added it to the branch
@obtuse burrow ❤️
lets see if I can catch the GC
I started playing around with that using the plotting macros

can't use the dedicated alloc / free macros for GC allocs sinec they're not symetrical, so I peppered plotting macros around a few GC allocation functions to show the large object and immix allocs
not perfect, but a start
hmm, actually I think objects on the LOH could use the standard alloc / free macros as they exist outside of the thread local allocations and are never compacted
yep, just did this as well on the app level querying the GC-counters:

all that's left is really just a slim extern class for all the macros
looks super tasty... i assume this will make its way into actual hxcpp (seems insane not to)
i will need to look up how to use an actual profiler outside of the normal "time looks big"
I mean this even supports screenshots and can also hook into Vulkan, OGL etc
I bet you if a PR was made it would most deff be considered
But I wouldn't be surprised if it would be rejected for some random reason either
but my god is this stuff cool
aidan and daz i think have merge rights to hxcpp lol
lmfao wat
NotBilly the hxcpp developer
maybe not daz, but i think aidan does at least
I'll offer a PR, I think I just shoehorn tracy in there, lets see 😄
new title for NotBilly
all the talk of alternate formats, etc seems very superfluous. Its clear the information is there and, with the right hooks, is accessible. If you wanted, you could write your own client, but seeing as capable and developed as tracy seems, it seems like wasted effort (imo)
nono i've done nothing except use memory
I agree with that
i could defo be wrong here
But you never know if they do or do not include it
It's basically gambling
but a PR
probably, but the thought of a new haxeui profiler did seem nice
but then i think about the work/effort aaaand its no longer nice x)
Every developer has their own stance on what should be the direction for haxe, and PR's including third-party tools
i think a -D telemetry_tracy (or whatever seems like a great thing to add)
that is for sure
nope, most gencpp or hxcpp changes I make usually get waved through though
(atleast, from my, you and quite alot of other people's perspective)
i dont think they are mutally exclusive, though i must admit, my interest in a home grown solution has dropped to zero after reading this thread
i contemplated mocking up a ui of scout on playground earlier today and then when i saw daz running tracy i just completely let go of that idea 🤣
why waste the effort to duplicate something that is worse - thats how i feel
eexxacttly
i worked on my project, which i'll likely be using the new profiler with anyway
true. The tracy docs alone are pure gold and you can tell that this has been battlehardened already
same, i was thinking about "things" with this new hxscout then saw that its already doable with tracy, and almost certainly better / more refined and thought... well, whats the point? (in a good way)
But im seeing some issues at the moment, in debug performance is ok, but anything release comes to a crawling halt. I think we generate too much data too quickly
could it be because we have to put that untyped thing in the mainloop
how does hxscout do it without that addition?
well you could at least test the theory by locally throttling the untyped calls
or i guess cap fps
but having too much data is a nice thought to have
not often the case in haxeland x)
no, we are leaking the string data
mapped the large object heap to the memory viewer, can now see all large allocations and their stack traces

shame we can't do something like this for non large allocations
what does "non large" mean in this context?
hxcpps GC splits objects into two types "large" (>= 4000 bytes) and "not large"
large objects are treated separately, its essentially a list of mallocs the GC holds and tracks
also, this isnt an actual line number... ... right? right?!?! right?????

non large go through all the fancy GC allocation, compating, etc
hmm, good spot, no, GCInternal.cpp doesn't even exist!
interesting... 4k is large... i guess that makes sense, kinda like the generational GC in java... wonder what the median object size is
.net sets its large object size threshold to 85k! I assume there must be some rhyme or reason to how they came to these values...
no idea what the bucket sizes are in java... now-a-days, it wouldnt surprise me if they are similar
the JRockit differentiates between large and small objects during allocation. The limit for when an object is considered large depends on the JVM version, the heap size, the garbage collection strategy and the platform used. (italics mine - DL.) It is usually somewhere between 2 and 128 KB. Large objects are allocated outside thread local area in in case of a generational heap directly in the old generation. This makes a lot of sense when you start thinking about it. The young generation uses a copy ccollection. At some point copying an object becomes more expensive than traversing it in ever garbage collection
2-128 depending...
starting to think darts boards were involved in deriving these thresholds
almost certainly: pick a number between 0 and 1M that can be divided by 2... ... ... ... .net: 85!

lmao
@obtuse burrow I found the free for your alloc.... https://github.com/cortex-engine/hxcpp/blob/215de81b91d2cff3996b0aa41f73bb2d3a7c6819/src/hx/tracy/client/TracyProfiler.cpp#L4230
not sure how this is supposed to be handled
yeah, I was unsure about if I'm supposed to free that allocation or tracy takes ownership of it after its passed into the zone function
I had a search around github and most usage is just people allocating and then passing that pointer into the function, no one was doing manual clean up of it
actually, it's haxeui...
lol, without it i can profile everything nicely

this shows the startup with multithreaded resource loading
im actually losing a lot of frametime due to Sys.println...
yeah that happens

ok, here is a moneyshot. I will work a little more on this and prep a PR for hxcpp

is this pushed to the branch?
yep
but you need to use the tracy macros, im currently writing a simple extern for it
ahh okay
no rush, was just looking to prep my cpp before shutting down for the day :3
want to do some more things but trying to find a thing to do that is "small enough" to consider lol
ok so now when is the haxeui rewrite of tracy /s
be sure to send me a patch 😄
will do, still having a play around with things
removing the gc::new stack traces makes the window much more useful, can see the last bit of haxe code which made the allocation instead of gc internals

also added a dedicated "GC Collection" zone so you can quickly see all GC runs, their time, the stack that caused them, etc

18ms GC collection!
very cool!
there must be some reasonable way to have all allocations (not just large) go through tracys memory tracking
best idea I've come up with so far is to keep a list of all allocations and then hook into the GCs marking. Something like extend hx::MarkContext to keep a list of all pointers its marked as alive which we can then compare to the allocations made to find objects which have not been marked and therefore are dead
could then issue the symmetrical alloc / free tracy macros without issues (I think...)
sounds feasible. Interesting to see if you can make it work
Here are some simple cppia compatible externs. Keeping it as a gist tille we figure out where to take it: https://gist.github.com/dazKind/b36475c0846491aefdfb12c5f831daba
@waxen valley saw your message on X. Tracy hacking happens here 😄
scroll up to find the fork/branch
@pearl slate Just realized that the crazy amount of stack traces i see from haxeui might just be cortex' backend working it wrong and I can use Tracy now to compare it to the other targets very comfortably
might also help you streamline the other hxcpp based backends
defo - will be a huge help - no doubt. Will probably uncover some issues in core, which would be ideal since then all backends benefit
Preparing the PR for the branch in the master
for some reason the MacOS builds are failing in the mysql code: https://github.com/cortex-engine/hxcpp/actions/runs/10755109056/job/29826439385?pr=1
looks like there is a conflict around PSOCK
merged the branch on my fork. will prep the PR for upstream now
Draft PR is here: https://github.com/HaxeFoundation/hxcpp/pull/1153
GitHub
Problem Statement
As a Haxe developer I want to be able to reliably profile the performance of my engine & hxcpp apps in a ergonomic, lightweight and battletested manner.
I have looked at H...
Hey! I want to try out the PR
I'm getting this problem
The steps I've done are:
haxelib remove hxcpp
haxelib git hxcpp <git repo link>
cd <hxcpp dir>
cd tools/hxcpp
haxe compile.hxml
then compile my project as usual
you need to compile in debug mode or with the HXCPP_STACK_LINE define
Ah that fixed it
https://github.com/HaxeFoundation/hxcpp/pull/1153
@void condor I suggest adding that here :D

best fix might be to set the line number in that tracy object to 0 if the define is not enabled
not sure if that would break / cause confusion though
I'd rather have HXCPP_STACK_TRACE & HXCPP_STACK_LINE toggle on when HXCPP_TRACY is defined
Well tracy already spotted a major problem in my task system: (span of 4 seconds 😅)

but that could cause issues as well
ok, https://github.com/HaxeFoundation/hxcpp/pull/1153/commits/1426a88c1cf80cc2d14de523076b779e59062eab seems to fix the macOS builds and tests on GH. That means we need someone with Mac have a closer look. At least tracy shouldnt interfere with normal builds anymore
I can give it a go at some point over the next few days, assuming I can will myself to turn on and use my mac for any amount of time
same here. my mac mini is soo old that I always worry
yeah, I've got an ancient mac mini as well, think its on old dual core i5 one from god knows when
yay!
@obtuse burrow awesome feedback on the PR
applying some changes now. Moving the code to third party & moved the tracy code in haxe-target.xml into its own section
@obtuse burrow Invited you to my fork, if you accept you can push directly
I love old mac minis, mine is from 2010
mine is 2016 I think
I've shifted all the telemetry stuff into a dedicated TelemetryTracy.cpp file, all seems to work nicely with the exception that tracy doesn't connect...
probably doesn't help that I'm testing with very small, short lived programs now. All my main hxcpp projects are using asys which needs a branch in my fork
I can push it anyway if you want to try it out and see if you can spot what I've missed
sure, lemme try it
just pushed, with that commit you need HXCPP_TELEMETRY defined along side HXCPP_TRACY
seems like I cocked up my git branches since I have two remotes in my hxcpp clone now, I pushed it to a new branch called cortex-master instead...
😆
I've pushed that commit to the right branch now, and cleaned up my mess
I will add some __hxcpp_tracy_* functions to Telemetry.h
then things will stay self contained
and people can use untyped __global__.__hxcpp_tracy_framemark() etc
ok, I have some small fixes.
The cppia stackframes seem to missing the context, thus it will crash when you try to get the depth.
is the line frame->ctx = ctx; fine here? https://github.com/HaxeFoundation/hxcpp/pull/1153/commits/b7227245cae0b7774b054e05d4d4b5b435db3a2f
This the current version. Connection etc seems to be in order
