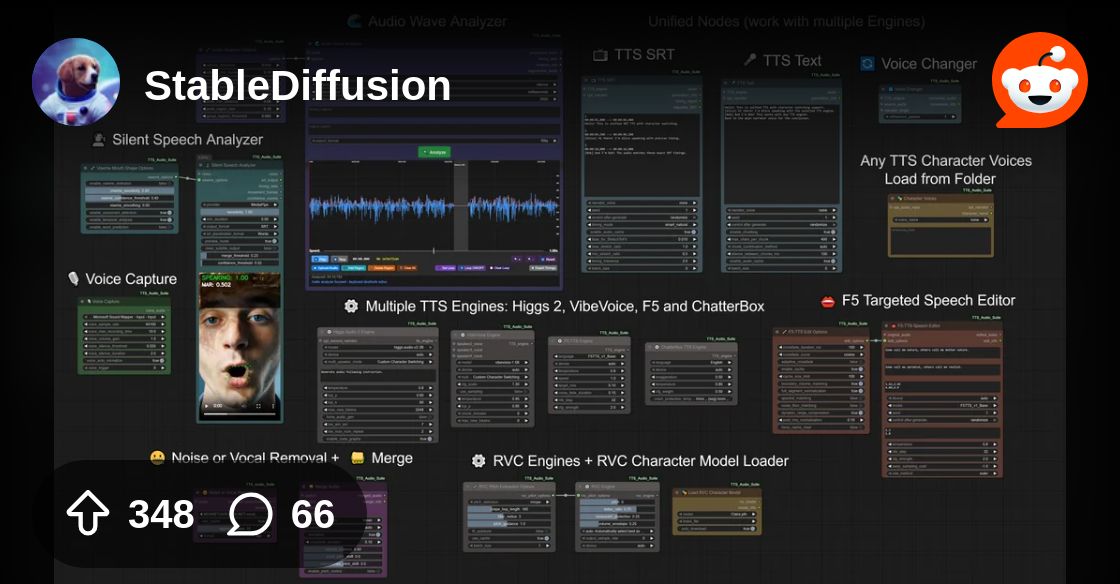
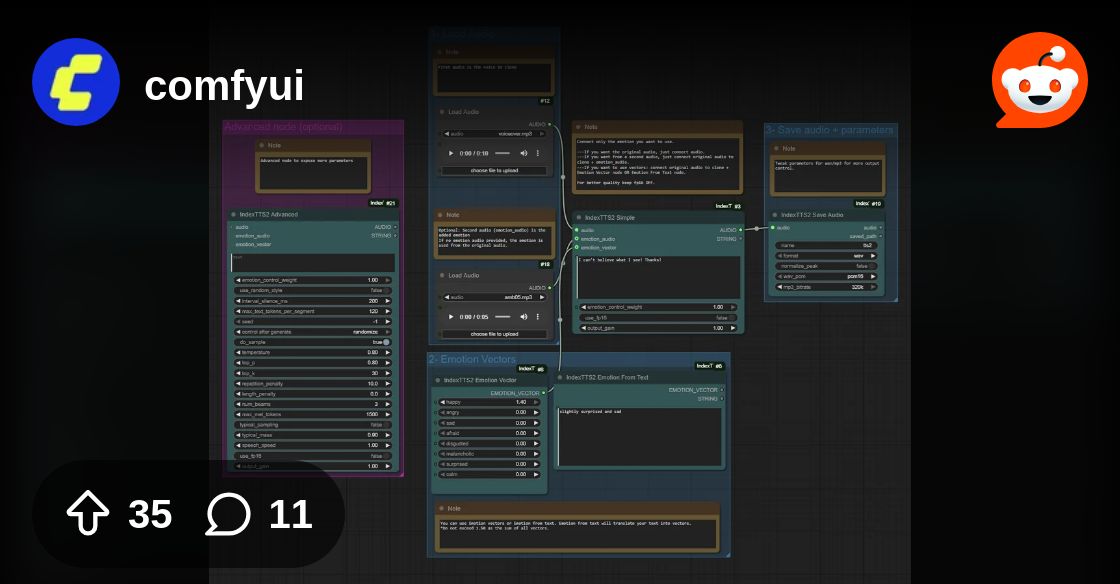
Example of using all together
- name: threshold
description: Adjusts the strength of the edge detection
type: string
required: false
choices: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
steps:
- if_group:
- if:
value1: "{result}"
operator: <
value2: 0.2
steps:
- send_content: "You Selected 0.1"
- elif:
value1: "{result}"
operator: ==
value2: 0.3
steps:
- send_content: "You Selected 0.3"
- else:
- send_content: "You Selected value greater than 0.3"