I'm a new user, someone more qualified could give a better answer for this, but it seems that Vae is the time when many calculations are being done, it seems that the model takes all the files from the SSD and at that moment throws everything into the RAM, so more RAM is better, you can see the peak on the graph at the moment where the Vae pass begins.
#✨|sdxl
1 messages · Page 150 of 1
there is an alternate vae that speed up the process
look for sdxl_vaefp16.safetensors
Thanks friend, I don't worry about Vae anymore, after the RAM upgrade I didn't have any more problems with it.
Does it work for dreamshaper too?
I hav 64GB of CPU RAM and 12 GB of GPU ram and it speeds up the last step a lot
I have 32gb ddr5 ram but ram cleanuper which can clean 5-6 GB of ram before a procedure
it works for every checkpoint that needs vae
Sometimes after closing many Firefox tabs my ram is still drained it cleans it up
Ddr5 is CPU ram right?
I also have 12gb vram on rtx4070
Although I have the dual version idk how much that matters
Can overheat easier
not for mine
You have 3 fans?
22
Gpu
2
Dual version too ?
5950x
AMD Ryzen?

😂 use sdxl base model! it's great for everything
where can i download it? im so confused with all of these models xd
scared to download the wrong one
Stable diffusion art website sdxl
Tutorial

They also have link
ty 🙂
download sdxl base, sdxl refiner, sdxl vae to start
how do these 3 differ
you use all of them together

for UI look this

Welcome to this exciting new video on AI insights! Today, we'll be diving into the topic of installing StableDiffusion on Windows with NVIDIA GPUs.
Instructions :
Workflow for Nvidia Cards
- Install Python (https://www.python.org/downloads/release/python-3106/). During installation make sure to Add Python to PATH.
- Try on cmd if Py...
i want to make people on a meeting table what kind of technics i should use ?
it's the same for 1.5 models and sdxl
a photo or a paint?
yeah im actually just watching this xD
ty
i target for photo realism
one person is easy but if people gathers it becomes weird results
wait is there a diffetence between sdxl base 1.0 or xl base 1.0
i think its the same?
yes+
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
thats the correct model right?

@cyan crown can we make realistic people faces with embedings are they for this kind of things
is this model restricted?
and does it let me use chatacters? dalle3 doesnt allow that
so u gotta have to trick it saying "an image of someone familiar to... "
dalle 3 is another thing......
not run locally. If you're running on a colab or something, the person hosting it may or may not
what you mean with restricted?
is there a sampling method considered as the "base one" for XL ?
ok, thanks 🙂
blood for example
or celebrities


Peeking in...

ah ok ty xD
whats the difference between the base to the base vae
there are 2 files of the base models except for that one of them has vae in their name
0.9 is the good one. 1.0 is borked
look at the picture i posted before
There a base model released now specifically with 0.9 baked in it
im confused
1.0 base model with 0.9 vae is good

oh this
oh so u need both of them
whats the "vae" for exactly? what does it do
decodes latent space to pixel space
decode
ah ok ty 🙂
starting with xl is find just dont use the refiner
whats the refiner?
mans is going to hit generate and wait 30 minutes for 1 image lol
start with 1.5
why though?
exaggerated
XL makes an image in like <10 seconds with the right settings
and 1.5 is <5 
impatience nowadays
why would you need an image every 2 seconds
XL produces substantially better quality
I understand if you're vram constrained and XL takes like 50x as long due to offloading but otherwise idk why you'd still use 1.5 outside of those animate tools
and qr monster 😄
people still doing qr stuff? lol
it shouldn't be hard to train a qr monster for XL im surprised it hasnt been done
there is one
everyone's too focused on waifus
you can use it to do otherstuff than just QR's
and it works fine
oh? is it good?
And the official qr monster team is working on an sdxl model
sometime

really? I thought the one released was bad
I feel like we're getting pretty far from QR codes lol
yeah, but its great
you still see the mona lisa but only from looking at the image from far away
pretty sure this is xl, i forget

yes that is the fun fact
where do you guys get your models from?
custom
civitai mostly
with SDXL you can have almost any style with base model
ah.. thank you ^^
löl

it's true. Base model is already very good. Custom models are not better in general, only for very limited styles
I would always try base model first before downloading custom models
I'm trying all the styles of base model
XL, no Loras

they are thousands
the base model is the skeleton that barley follows the prompt at all... civitai is a treasure trove of awesome ^^ thx
i wouldn't say treasure trove of awesome

uh.. nais
guys, I am following the tutorial to use (--medvram-sdxl) however I am not finding the file in my folder similar to the video file (webui-user) to open in notepad, does anyone know what I should do? Thanks

scroll down more?
lol
😄
I have it, but it's .sh, I can't edit it. 🥺

.bat
the .bat

you can edit a .sh if you just drag and drop it into notepad or another editor. regardless, you'll want the .bat because .sh is a linux shell script
god speed pickle rick

reminds me of that weird fiinal seaoson of american gods, well, i mean, they were all weird i guess
 thanks
thanks
Just missing Jormungandr unfortunately, otherwise this would have been perfect
cinematic photograph, space view of earth with jormungandr serpent slithering under the entire globes oceans, massive yggdrasil tree distant in space with nine realms connected to its branches
it keeps trying to make the branches made out of jormungandr
(jormungandr serpent:1) -> 1.4
Yeah testing weights currently
I just process batches of 5 to go through a full process and do work on the side while waiting for em to finish
~200 seconds for a full process including upscale
is there any way to use sdxl on my phone? like maybe somehow run it on some kind of server
like your server or from a host?
because if it's a host, you're going to be paying a lot
colab is free
for xl PC or pay
mm I dunno, never tried it with xl
then why say it's free?
things like runpod aren't that expensive are they?
for XL it will be, 1.5, whatever
since it's like a drug....yes
I've seen people using --listen 0.0.0.0 when they talk about using from a phone, but that's about all I know. No clue about the specifics.
you can use on your LAN without any trick
adding --listen to webui-user
I tried and it works fine
No Yggdrasil here, but still kinda neat

that requires your pc to be on the same network though right?
yes
or you can do port forwarding on your router and use something like duckdns to reach outside
port forwarding days on my own pc days are long over for me lol
well to reach your sd interface from outside your LAN you nned to do PF
on the router
What about share=true and using the gradio url?
people are too trusting, i just vpn or disconnect the internet altogether
yes VPN is the best solution
because you don't risk people using exploits of the interface
OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 2.00 GiB total capacity; 1.61 GiB already allocated; 0 bytes free; 1.65 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
hey i keep getting this error when trying to generate using the base sdxl model or just the 1.5
what can i do about it?
If in A1111, make sure you have optimization flags set in your webui-user.bat file
When I still used A1111, this was my settings.
TBH not sure if you still need the first two -- flags, but guessing you don't have a super beefy GPU, so at least keep the --medvram
set COMMANDLINE_ARGS= --opt-sdp-attention --no-half-vae --medvram
the alternative to the first opt-sdp-attention is --xformers
So that's another you can try also.
IF you want some light reading
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
oh ty
do i need to restart the entire program after adding a parameter?
yah
What size image are you trying?
What do you think is the best to use?


I use currently dpmpp_3m_sde_gpu/exponential for my main processing, and either ddim/ddim_uniform or dpm_adaptive/Karras for my facefix node
What gpu/how much vram?
how do i check that
Thanks budy

0.5GB/4
i mean im on a laptop rn though.. xd
didnt expect for the images to be generated quickly but didnt expect them to not generate at all too
is 4gb not enough?
Pretty low
for 1.5 is barely enough,for sdxl no, specially a laptop gpu
so 4....that's probably not gonna work in A1111 at least for SDXL.
Maybe you can squeeze em for 1.5 models in A1111.
Comfyui is more memory friendly, so perhaps you'd have better luck with it, but, it's more complex also
post the name of the gpu here
same screen I posted, top right name
idk the full name, its from intel though
if its intel iris its not good enough for ai
i see
ill try on my pc when i get back home
was curious how it would be on my laptop
ty
super slow if you set everything up perfectly lol
tiled processing, low vram flag, a bunch of dumped stuff to CPU processing...it would be slow.
probably possible, but not worth it likely
Where can I download dpmpp_3m_sde?


Has anyone found a way to use the GPT 4 idea2img in comfyui?
Im trying to batch process images in in Comfy, have a directory with images in name order, does anyone know of any custom node that has this feature?
I tried WAS suite, but it doesnt pull the images in name order.
https://github.com/ltdrdata/ComfyUI-Inspire-Pack
Should have that ability, I haven't used it, so you'd have to read through the github and see what it requires
GitHub
This repository offers various extension nodes for ComfyUI. Nodes here have different characteristics compared to those in the ComfyUI Impact Pack. The Impact Pack has become too large now... - Git...
It has it, but it just wont load in the name order
It has some random order, couldnt figure out what it is
I'm trying to batch prompt them at the same time so the order will matter
I've found a solution by changing the script with the help of chatgpt, what a time we live in lol
thanks @crisp owl , I changed the load order used in the WAS suite loader
Nice, yeah I've used it for some crafty code changes at times.
Helpful for some things for sure

ChatGPT is catching up to SD!

like for real LOL


I doubt I can decode that, no extended characters... but lol. I guess it thinks since I can supply images now it can make them some how
copy paste the data into an html file so your browser decodes it for you
looks like a valid png header so it might actually work

That would be my luck. Escaping an inferno in a suburu wagon
do you see it?

Frey's scalable ship


I've hid something here

that's more similar to how pixel diffusion works actually, it diffuses each pixel individually instead of diffusing the latents
I doubt it will make anything by writing PNG data, but it might be trying to color each pixel individually
very dumb approach to generating images though, but it'd be interesting to see an LLM being able to actually create a PNG
Terminator 2 villain?
nope, is it really too well hidden?

I can see it, but that's probably because I see the origin
I've hidden a word this time

it's really COOL that it's possible with SDXL now, but it's not quite as good as QR monster imo
Theirs is quite good, wonder how long until they release their sdxl version
the one I'm using is also somewhat decent, but it really struggles when the inputs have more complex shapes
it also deteriorates quality way more than QR monster used to

I'm assuming he's talking about quality deterioration? because that's the only flaw I see with the one I'm using (which isn't QRmonster)
No clue, I can't make assumptions on that
link to that post? I'd keep track of that


oh, that's actually a model I already released a week or so ago. I just use it as a base model in my workflows
i gotta figure out how to train i guess, 2 409024G cards and i'm rendering 1024x1024 jpgs....boring
too lazy to watch a 2 hour tutorial on youtube
I'll borrow one
will email it over to ya 😉
Sweet, looking forward to downloading it!
training isn't exactly what I did to make that. I calculated CLiP and UNET ratios to create a great (imo) model

I explained exactly what I did in that model's description
interesting

that works great tho if you play around with the cnet settings
huh, yeah, that's better than what I usually get with the available QR controlnet model.. what'd you do here?
this is what I'm currently working with. I was thinking the only thing limiting this from getting this better is the controlnet model?

how about white subject and black background, inverted image?
in controlnet it is definitely better.
the QR cnet is trained on barcodes and stickers, those have white background and black lines/whatever
I tried the other way, it wasn't as good
o.k.
but idk, I feel when you're trying to control SDXL too much it looses the ability to make stuff like this

again, a flaw caused by CLiP
CLiP never likes being controlled too much, it's just really good at the things it's intended to do. CLiP is SD's bottleneck imo, that's the only thing limiting complex multimodal inferences that won't cause quality degradation
Hi guys, has anyone noticed weird color issues with dynavisionXL after installing and enabling the TensorRT extension and switching to the dev branch of Automatic1111?

More than half of the images generated now have the issue in my case
In some cases to kind of extremes like this

Even more ridiculous 😅

just bumped cnet up to 1.2 and denoise on the first sampler to about 90


Though admittedly some images generated like this are cool like this skirt

Hi all, is there a way to check the list of artists' images that are included in the dataset and haven't opted out?
not quite, but you can find lots of resources of people who's done that and compiled together on their own sites
https://weirdwonderfulai.art/resources/stable-diffusion-xl-sdxl-artist-study/
interesting! thanks for sharing.
interestingly, it will always perform the same styles if you make up artist names
I used a made up name once, then did it again with an entirely different prompt that has the made up name; both images had a similar style
not sure if this is a good example:
"by jeff fuctional"

"bucket of water, by jeff fuctional"

similar color accents; but not as presistant with the made up style as I remember it being

I keep getting red spotting visuals on my texture generations using SDXL. I have tried using the 0.9 VAE and different schedulers but they all still seem to produce this type of distortion, any ideas?

There used to be tilled option which i believe can be found in quicksettings, are you using it?
This is using diffusers so I am manually applying the circular convolution for the Conv2D function. But the tiling is fine. It is the red artifcats that appear with SDXl in both tiled and untiled images
a better image

(watermark is also off)
i dont know. Probably try different SDXL model with baked in VAE
I get it using the default baked in VAE too. But I guess maybe trying some other models is a good idea
Have you got invisible-watermark in your enviroment, that looks a bit like the watermark.
nope, that is removed and deleted from all code

I'm loving the 2x faster generation speed with the TensorRT SD Unets.
But now I just find myself running Huen sampler at the same speed as I used to run DPM++ 2M Karras, just because I slightly prefer the output of Huen (but it is 2x slower than others).

Yes, the new Nvidia Extension.
The ComfyUI developers are planning it but with a low-priority
https://github.com/comfyanonymous/ComfyUI/discussions/1775
because of all its limitations.

GitHub
NVIDIA just released the 545.84 drivers and they show a 2x speed improvement on image inference on this page: https://www.nvidia.com/en-us/geforce/news/game-ready-driver-dlss-3-naraka-vermintide-rt...
it working for SDXL for you as well?
Yes it works in SDXL.
i have this driver but i need as well github thing
https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
GitHub
TensorRT Extension for Stable Diffusion Web UI. Contribute to NVIDIA/Stable-Diffusion-WebUI-TensorRT development by creating an account on GitHub.
if you want to upsacle to 2k you need to generate an extra Unet (well for just about everything you need an extra unet)
yes but it doesnt work for me with SDXL
Did you generate the Unet with the SDXL model you want to use selected?
you need to do it for every model and lora you want to use.
I tried optimising a Lora and just got a load of errors, I think that is in Beta.
Does SDXL + Controlnets (IP-Adapter, depth etc) work when using TensorRT in A1111?
yes and it doesnt work
@mellow tendon yes
https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT#common-issueslimitations
@frozen terrace probably closest answer
GitHub
TensorRT Extension for Stable Diffusion Web UI. Contribute to NVIDIA/Stable-Diffusion-WebUI-TensorRT development by creating an account on GitHub.
Thanks, don't see a limitation there regarding my needs.
When you say it doesn't work, do you mean you don't see a speed-up when you have the Unet selected? Or you get an error?

Have you correctly installed the Extension so you see the TensorRT Tab?

does every resolution require compiling a new module? or is it similar to ai template where, say, a 2048 module can be used with 1536 resolution
or wait, more like, can I do 2048x1536 and 2048x2048 with the same module or would that requires 2 different ones
exporter seems kind of confusing
Using LLM (GPT-4V) to self refine the image. https://arxiv.org/pdf/2310.08541.pdf

Yeah, that looks crazy good, I cannot wait to get my hands on that if it ever releases publicly. (not sure if it needs to use GTP 4 in real time to work?)
Yeah I read that anything within the max resolution setting will work.
ah sounds good, thanks
That looks like an incredibly resource expensive way to generate a image.
hmm, using an LLM to refine the prompt to a level where you don't need to use Controlnet or Loras or Cherry pick from a large batch seems like it would save loads of resources to me.
Is it okay to generate images of my favourite kpop idol for personal use?
Oh but I suppose that is generating a load of image but that is happening in the cloud.
If I go through the flowchart it seems like it needs to generate N numbers of images to get to the point of generating the final output.
Unfortunately, the cloud is still using resources.
In my opinion, and I can only talk for myself. I think it's a bad idea 💡.
I still think if it can generate the image you want in one go (with a small batch of Drafts) it could be efficient, I just ran a bacth of 40 images and still didn't get quite what I was looking for.
I got some "happy accidents" along the way, with these learned dragons.


repo says you need to be on dev branch for sdxl
yes and one was there and it took him 3 mins to generate image, so it 9 times slower 🙂
i think i need be logged in nvidia and download that zip file probably. But SD is working o.k.
@qwerty_qwer sounds like you might have downloaded the wrong extension, that is what I did first. If you try and search for it in Automatic1111 it finds the Automatic1111 TensorRT extension with the same name as the Nvida TensorRT extension. Try deleting that and install from the nvida URL.
If there are tabs call Onnx or something you have the wrong one.
it says it should be installed from URL?
I have only tab TensorRT, but haven't tried advanced tab, supposing i have to have choose some converted model to appear? For SD models it is working, but still getting some errors starting A1111 about entry points. Probably i need download zip from nvidia which means signup and login?
It wasnt Qwerty_Qwer, it was @oblique swan i think
yeah, that's identical with speed to AITemplate except it's not as flexible.. if NVIDIA would have released this like a month or two ago this would be relevant to most of us
this would make sense if TensorRT is faster than AIT, but that's not really the case if both are done correctly
AIT is already working?
the next target for optimizing diffusion is pulling off something like exLLaMa for diffusion
for the longest time, it's been available on an old version of ComfyUI for ages; but it's now compatible with the latest ComfyUI
o.k.
the speed difference between pure PyTorch to AIT and TRT on a modern GPU is about 2-3 times the normal speed with no degradation when done correctly. HOWEVER; with language models- there's something called exLLaMa that does a WHOPPING times 8 boost by having actual optimized kernals. the day this happens to diffusion is the same day diffusion becomes an instant AI
Was kinda thinking about this before I joined. It doesn't really understand sentences right? I was reading the code and it seemed like it just sees keywords for the most part. Felt like it has to be doing something more than just that but thinking back on how the prompts turn out it really doesn't seem like it does.
unlike BLiP; CLiP just connects text to images, it won't have an understanding of language, and it's ONLY good at connecting text to images. however- more modern encoders such as BLiP are able to encode everything; making multimodal WAY easier and better
yeah so it just tells it what nodes to go to without any understanding of what a direct object is right? It just sees "Dog is node 52521 in model"
or even their relation to eachother
the only reason SDXL can have text in the images is because the UNET is a masterpiece, that's it. CLiP is a bottleneck
and CLiP is only good at doing that with just the text, this is why things like IPAdapter are required to make it able to blend/zeroshot images- and it will still loose plenty of quality
This video shows it well, "a plate without a bannana on it" cannot be done with just Clip right now https://youtu.be/TL2A8MYXsCE?si=MgROx4PW4kfHzocl&t=383

Get Magical AI for free and save 7 hours of busywork every week: https://getmagical.com/matt
▼ Link(s) From Today’s Video:
Research: https://idea2img.github.io/
ChatGPT: https://www.futurepedia.io/tool/chatgpt
► MattVidPro Discord: https://discord.gg/bQgcbjs2Sg
► Follow Me on Twitter: https://twitter.com/MattVidPro
------------------------...
the problem in my opinion is the limited training data for captions
initially, people used the ALT attribute in images to caption them
which means most image captions are rather uninformative
BLiP on the other hand, can encode both text and images just as easily; due to having an additional LLM component, it can have an excellent understanding of language. SDXL completely masters txt2img, but that's it. I can almost guarantee that if SDXL would have a more modern encoder, it would DESTROY other stuff completely
just think about an image of a battlefield with many soldiers and corpses, smoke and everything. The caption of such an image is not "battlefield, dead soldiers, corpses and blood on the ground, Napoleonic era", it's rather something like "Waterloo"
thus, CLIP was the best tool for this kind of data
it is trained to assign captions to images and embed them in the same space. This makes it extremely robust to bad captioned data
that's a very ugly excuse of an attempt to improve diffusion. gluing an LLM with diffusion is a horrible idea
I'm not sure if we are much better in this regards nowadays. My experiences with BLIP are rather... bad. Sometimes it's okay, but most time BLIP gives me totally wrong captions
when it comes to the QUALITY of the images, SDXL pretty much destroys everything else, but it won't be as creative as Dall-e 3 due to CLiP being a bottleneck.

DALL-E, Imagegen and DeepFloyd are models that use LLMs trained on text-data only. So this models don't have the disadvantage that they are only trained on bad captions, they are trained on the whole internet text corpus. HOWEVER, they are NOT trained on images and, thus, have no idea about visual components
they have a better text understanding, but probably a worse "style" understanding, as they don't have any knowledge about visuals.
I'm pretty sure the reason SDXL is using CLIP is because it turned out to be better than the alternatives
BLiP2 has knowledge about visuals
if you look into the SDXL source code you will see that they tried different text encoders, too, such as Flan T5
yes, but is BLIP better than CLIP? I'm not so sure about that. as said, for me BLIP often gave me really bad results
did you try BLiP2? it's really insane, I asked it about the expressions of the characters in an image and it even started making up their thoughts
in theory BLIP should have a better text understanding as it is instruction trained. But I wouldn't say this is guaranteed. As said, it always depends on the quality of your training data
yeah, most time it cannot even distinguish males from females
also, BLIP2 is a really large model. You cannot have both, a model that fits into consumer hardware and a model that is state of the art
for me it even distinguished the styles and expressions. you must've not inferred it correctly then
sometimes it does, sometimes it's really stupid
SDXL is pretty much state of the art when it comes to the quality, but it won't be as creative as other things due to CLiP. HOWEVER; if your prompt is rich enough, it will make insane stuff
maybe if SAI came up with a new text/image encoder..

SDXL base image
Just trying the Iterative self-refined Idea2Img prompt from https://arxiv.org/pdf/2310.08541.pdf
again, I wasn't complaining about the quality, it's just that CLiP is definately a bottleneck, look at IPAdapter for instance; that's the only thing that ACTUALLY enables it to get image input
if the text encoder itself would have image input capabilities IPAdapter won't be necessary and there won't be any degradation when doing image input
The paper explored how good the model (SDXL 1.0 base) could be with "good" prompt.
with current text encoder
that was kinda my point..
the text encoder itself is fine, it just won't have a good understanding feeding off of small prompts and it won't get image input
Yeah if you roll the right seed and hit the right nodes in just the right way it does a good job.
It could be a huge improvement by using new techs which just came out within a few months.
i'd say even the best job, it's just that CLiP is what's holding it back from pulling it off at a higher rate and having more capabilities
the solution to this seems to be SAI making a new text encoder that is best at all worlds
that has nothing to do with the text encoder oO
SDXL is trained on CLIP text tokens. In principal you can include images, as CLIP embeds images and text into the same space, but then your image would be only a single token which does not make much sense
image input? of course it does, SDXL can't blend/zeroshot images without the assistance of IPAdapter
you can condition SDXL on images, too, like ControlNets are doing.
because they haven't trained SDXL on image conditioning
that has nothing to do with the text encoder
you can train SDXL with image input if you want. It's just a decision
Dall.e 3's prompt following/understanding is simply amazing when compared to SDXL, when your output isn't being block by the filters...
Controlnets are doing that. IPAdapter is doing something similar. They encode an image into "text-like tokens" like CLIP and train an conditioning on that
are you telling me that it's theoretically possible to make a version of something like SDXL that can get multiple image inputs and blend them?
@mellow tendon and do you know minimal requirements for it? I am happy sai is keeping to make it real for say 4GB gpu cards or even lower.
And day by day more tags on black list.
yeah, why not. The unet is getting an conditioning as input. SDXL is trained on text conditioning, but you could use any kind of conditioning. ControlNets are a variant/finetune of SDXL that are using images as conditioning
I'm pretty sure you could even train a controlnet to blend multiple images
the most natural way of blending images, though, is just using their CLIP embedding
one flaw with controlnet is it almost always causes the model's quality to degrade the more you try to force it to do something
this is also the case with text input
as more your conditioning moves away from the training data, as more difficult is it to get good results
not really, I've been making 300 word prompts and the images come out incredible
it has nothing to do with the number of text tokens
probably token normilization, isn't it?
SDXL is always using at least 75 tokens
if you give a short caption it just fills it with blank tokens
what I mean is if you force SDXL to follow a strange prompt then it will degrate image quality. Long texts give good results because they often give SDXL much freedom
if you make an image from a song lyrics there is no "correct outcome" you enforce. You are happy with any nice looking result
anyways, whenever SD3.0 comes out, I'm assuming it'll have image conditioning like @rustic garnet mentioned is possible, that'll probably be a huge step
or even possibly the next focus is mastering other components of the model? it seems like SDXL mastered the UNET, but idk about all the other stuff
Sorry I don't understand what you are asking??? I have 24GB of Vram so not sure about 4GB....
SDXL IS the unet 😅
all other components (vae, text encoder) are independent of sdxl
the VAE is also SDXL, SAI has a repo that contains just the VAE of SDXL for some reason
yes, but it's trained independently from sdxl and can be used independently
true, VAE is just pixel to latent and the other way around
but I think conditioning is dependent..? if you use another model's conditioning on a UNET with a different architecture the Ksampler will fail
yes, the unet depends on the vae and the text encoder input. Use a different conditioning and you have to retrain the unet
I just say the unet is the main component that is trained - all other components were trained too, but independently from it (and sometimes by different labs and on different data). If you look into the source code of SDXL you will see that many different conditionings were implemented. They haven't chosen CLIP for no reason. I guess it was the best trade-off between hardware requirements and visual appealing
if you compare SDXL with DeepFloyd IF, which is using an LLM trained on pure text, you will see that DeepFloyd IF has a MUCH better text understanding than SDXL. However, I don't find the images from DeepFloyd IF visualy appealing... maybe it's because they still haven't published the highres model. But I think it might also have something to do with the text encoder is not good with styles and aesthetics
The model need to be run on consumer level hardware is a limitation. They could do better without this.
Well, Dalle-3 has shown you can have both aesthetics (NOT really detailed styles) and careful prompt following; some times. But overall styles/aesthetics is defiantly SDXL's strength. Especially organic and fine details (a jungle) SDXL manages to create much, much better. At first i was impressed by Dalle-3's prompt following, i still am, but even there, i start to notice it also has a tendency to fail once scenes get really out there. At the same time, it's awesome that it works for simple things where sdxl has a tendency to flat out ignore aspectgs of a prompt, it and won't do things at worst or needs carefully formulated prompts at best. On 1, 2 and 3 of my wishlist for SD-next is better prompt-following., especially for coarse "details" (fine details like color of eyes are solvable like https://rich-text-to-image.github.io/) but i've yet to find a good solution for coarser ones affecting (composition of) whole scene.
Maybe one model won't need to do all, just create the basic scene in a model that does the prompt, then enhance in sdxl. Kinda like sketch to image but the sketch is a different model
Dalle3 is better with writings and understanding prompt. SDXL is better with quality
So one good idea could be creating base image with DE3 and then use it with Controlnet in SDXL for example

This is great! I will review the Community Submissions on your GitHub to add the missing artist names.





The problem with using controlnet to blend images is that you still need training images for that, but if you have it then it is quite doable.
@finite thunder it is not my github 🙂 but there were owner presented. Mmnt
it is @cursive warren i think


SDXL Version

Images you can hear.
😂
I once again screwed SDXL by training a Lora on mostly 80x112px images of Faces. Getting some glorious output here at the extreme resolution of 88x120px 😅


At least i get 11.51it/s 🤷♂️
cool i guess

i bet he really nose how to party
Oh yeah, he can sense them from miles away.
dont be so picky
these are insanely good
something smells fishy


I keep getting these dot mess on my white images I create. Is ist something to do with trying to create white images?

I am using sdxl + refiner
That looks like the noise that having the bugged 1.0 model+vae causes.
@native knot I am using the base 1.0 model but then swapping the VAE with this code

but also, on the stability ai huggingface card they reinstated the 0.9 VAE so i am left confused https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
im kinda stumped since I "think" I am applying all the various fixes
Yeah so there's the base_1.0_0.9.safetensor model which has the proper working vae baked in. the 1.0.safetensor is the wonky one.
The standalone vae files, normal and fp16 are these
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main/vae
hmm i still get the weird colous though when swapping out the vae with the fixed version (my code above)
Hi everione, I'm wondering if there is a command to update the "run_nvidia_gpu.bat" file. I've never update it, so I don't know if its necessary.

Are you generating outside of standard size ratio's? Adding any other models/controlnets/lora's/etc?
no res is 1024x1024, no other controlnets or loras. Just base for 30 steps output as latent then into refiner for 15.
ComfyUI_windows_portable\update
then run the update_comfyui.bat file
Thanks solesbeedude
don't run the python_dependencies file
you don't need to unless you know what you're doing.
That's odd...
I'd still lean to a vae issue just given what it looks like in your shared screenshot.
I've personally never run into that issue ever though
Can I update smoothly using the update_comfyui.bat file?
Yup, you can run that file whenever, the update will only apply when you restart your entire instance
thanks buddy




Just waiting for things to get better in South Africa...

You from there? Where at?







There we go, had to download the app to replicate the sun. Even sets in the same direction lol

i trained on a buddies custom car 🤔







hmmmm.....well, I'd giess somewhere close to 1024
but I haven't used ultimate upscale for SDXL
can always test and see if the outcome is wonky though

felt like it doenst make a big difference, the image at all look a lil different, but not the quality imo
Nice, probably if your pc can handle it, any speed increase between 1024 tiles vs 512 tiles?
i felt like it doesnt make a big difference
bec i have doubled tiles with 512x512
with 1024x1024 i have bigger tiles
having less tiles is definetely an advantage anyway
im running a gtx 1070, still happy with it 🙂
best gpu purchase of my life so far
I notice with my vae tiled nodes in ComfyUI, if I keep the tiles at 512 vs changing to 1024, I lose about 30 seconds, and I haven't noticed a difference in quality.
I'm running a 2060S, this thing has been a trooper lol




i just dont get why sdxl is so sensitive to prompts , i often have completely oversaturated, overexposed results
I've mostly seen that with specific checkpoints.
I had protovision really disliking some prompts, but if I change to a different checkpoint, be completely perfect
I finally managed to train a LoRA model with my 8 GB of Vram, in 512x512, but I was looking for speed (2h40). The results are very impressive, despite the small number of images and steps.
(model : Leah Dizon)








Colored latents are fun





And don't ever talk to my son again!



maybe future SD versions will have a pre-sampling to just create vague shapes than have a modern UNET like SDXL decode them?
I feel like that would make it even harder to blend images, this means that both modelA and modelB will need to have image conditioning to enhance the capabilities beyond what current SD can do
though I know Kadinsky2.2 can blend images without needing something like IPAdapter; but I'm unsure if that's because of the different encoder, or because it is pixel diffusion

also idk about SDXL having NO understanding of language; I just wrote here- "a polite and friendly octopus drinking tea"

it figured out the tophat on its own, so unless polite means wearing as tophat, it did get creative here


nice.. got the Intel A770 doing 1920x1080 SDXL

dude.. this might be my new wallpaper

what's the speed you get on that?
doing 1920x1080 is like 5-6 seconds per iteration... smaller SD1.5 stuff was under 1.3S/it
so an image like that above just a straight, un upscaled 1920x1080 takes like 9-10 minutes
probably 4-5 if I wasn't using an insanely high number of steps
10 minutes for this.. I'll use the same prompt and do it for 50


3 minutes, 54 seconds, 1920x1080, 50 steps

foam also gonna be cool, but you know 🙂
people gonna people 
Looking for a SDXL specialist to create a dreambooth Model for me Photorealism (no more cameras 🙂 or photography studio ). Can anyone help me create this?


Curious to ask, can AI generate characters or animations like this?

there's some 1.5 tunes/loras meant for making spritesheets
you'll have to either inpaint or doctor them to make them consistent though
mermaid skeleton found by researchers in the abyssal zone

mermaid skeleton found by researchers in the abyssal zone
that's not the prompt lol
One image explains Dalle3

grainy submarine footage of a skeletal mermaid in the deep abyssal ocean was what i used, but you probably wont be able to re-create it in the bot because it uses a black input latent

sounds like they hired them for their general torch knowledge
not just SHARK
some of this black latent shit's kinda nightmare fuel lmao

she has the omae wa mou eyes

black latent?
yea
never heard of it
instead of feeding the ksampler torch.zeros() I feed it a latent with the approximate VAE values of black
its a custom node I wrote

Oh, nice. Yeah, I barely touched latent

Has to be
it picks up on keywords like "dark, black, bright, white" etc and changes the input latent color
instead of just neutral grey like SD does by default
dynamic latent iow?
iow?
in other words
ah
yea
so I made a little node that creates colored latents in the 6 main colors + black/white
at any strength
it works super well
yeah, MJ has always been about the tricks behind the curtains
if you want just a night time scene you can use not-quite-black
I have zero knowledge of node crating
this one needs that

XL_CONSTS = {
"black" : [-21.675981521606445, 3.864609956741333, 2.4103028774261475, 2.579195261001587],
"white" : [18.043685913085938, 1.7262177467346191, 9.310612678527832, -8.135881423950195],
"red" : [-19.665550231933594, -19.79644012451172, 10.68371868133545, -12.427474021911621],
"green" : [-3.530947685241699, 14.075841903686523, 26.489261627197266, 8.67661190032959],
"blue" : [0.45569008588790894, 16.3455867767334, -17.67197036743164, 4.145791053771973],
"cyan" : [12.434264183044434, 26.013031005859375, 4.298962593078613, 7.954266548156738],
"magenta" : [-0.9616246223449707, -5.109368801116943, -12.062283515930176, -9.02152156829834],
"yellow" : [-6.609264373779297, -10.563915252685547, 32.47910690307617, -8.209832191467285],
}
class BSZColoredLatentImageXL:
@classmethod
def INPUT_TYPES(s):
return {"required": {
"color": (list(XL_CONSTS.keys()),),
"strength": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1.0, "step": 0.1}),
"width": ("INT", {"default": 1024, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 8}),
"height": ("INT", {"default": 1024, "min": 16, "max": nodes.MAX_RESOLUTION, "step": 8}),
"batch_size": ("INT", {"default": 1, "min": 1, "max": 4096}),
}}
RETURN_TYPES = ("LATENT",)
FUNCTION = "generate"
CATEGORY = "latent"
def generate(self, color: str, strength: float, width: int, height: int, batch_size: int):
samples = torch.empty([batch_size, 4, height // 8, width // 8])
cols = XL_CONSTS[color]
for batch in samples:
batch[0].fill_(cols[0] * strength)
batch[1].fill_(cols[1] * strength)
batch[2].fill_(cols[2] * strength)
batch[3].fill_(cols[3] * strength)
return ({"samples":samples},)
entire code for it.
darker?

yea that's the node. 0 strenght is an empty latent like you're used to. 1.0 strength is pure black
or pure white/blue/red/etc
only works on XL
0.5 is the mid grey?
No 0.5 would be like 25% lightness approx
SD is mid grey by default.
so 50% black is 25% lightness if that makes sense
cause 0% black is gray
it works like that because I cant blend latent colors, only multiply
I already feed into latent and this has no pass though 😦
if you have my whole pack, the Offset node has a -1.0 -> 1.0 node that just adjusts your existing latent
so 0.0 is gray, -1.0 is black, 1.0 is white

might be more your style
use it before the noise is added
cause it's multiplicative
def offset(self, latent, offset: float):
samples = latent['samples'].clone();
if offset > 0:
cols = XL_CONSTS['white']
elif offset < 0:
cols = XL_CONSTS['black']
offset = abs(offset)
for batch in samples:
if offset != 0:
batch.mul_(1 - offset)
batch[0].add_(cols[0] * offset)
batch[1].add_(cols[1] * offset)
batch[2].add_(cols[2] * offset)
batch[3].add_(cols[3] * offset)
return (latent | {'samples': samples},)
basically it adds offset% white or black and multiplies the latent by the inverse to compensate
0.5 and 0. 0 is like it was without


yea the node does nothing at 0
-1.0

except consume a few MB of memory by caching the latent I guess
yea 1.0 is usually a bit too strong unless you're literally making a black background with a single thing on it
sometimes -1.0 looks good though

the -1.0 is perfect
for positive values +1.0 will basically turn it into a digital doodle on a pure white photoshop canvas lol
so +0.5 is usually the limit unless it's like an angel in white robes in a blizzard
if you ever use 2.1 or 1.5 the RGBA node can do something similar since it has arbitrary colors.
for img2img or other non-empty latent scenarios you'd have to merger it though
comfy has nodes for latent blending/merging too btw
built in
they might be in _for_testing still
yes, I think that is where I saw them
I needed this last night as I was fighting with way too dark

yea hypothetically you could use that to mix my colored_latent_image node with an existing one instead of just using the offset
but idk that's a lot of effort hence why I just made the offset

but yea I'm playing with -1.0 black to make some sketchy research footage and its great

I need to remake this now as I will use it to colour the latent instead of the image back into latent
if you're blending then leave the colored latent at 1.0 strength and just change the blend
should work similarly maybe
life pro tip if you clamp the values in addition to the black latent you can straight up make pure black values

also the refiner does indeed still work with colored latents without totally breaking down but I'd say its even less useful tbh
I wonder if post processing I removed for my look if I can do them in latent? gonna try
see, I prefer to get rid of post and work entirely in latent if possible
yeah, I can.
with pure black its not really necessary but with other values it's still allergic to black/white pixels
it'll limit itself to like 10% 90% lightness
lol
also some other values are fun for specific looks.
Yellow does good for golden hour sunlight
cyan for underwater coral reef stuff
etc
cyan can also be used for images that have a lot of sky
then white if it's a bright image and SDXL starts darkening things to compensate
it sure did mix them as red + white is pink

no, it was a nice accident
sometimes it makes the ocean stuff have black bars. must source movie stills?

This one's fun. Has that effect I was going for of a research submarine finding some eldritch shit


also seems like the black significantly reduces the overtuning effect of "mermaid" to just make hot women with nylon fish tails. must force it to approach the image totally differently

like a like a black/yellow mix?
also one thing I do if I'm really in the colored weeds is to connect the latent to an ImagePreview node before it samples so you get a little preview of the color you're feeding the sampler each time you run it

white?
I accidently went from 0.3 white to 1.0 on the above image


can I move this file anywhere and it will still work the same? ComfyUI_windows_portable
ah I could probably change the steps to be 0.05 instead of 0.1
I didnt think it'd make a big difference tbh
or does it have to be at the top of a drive?
should I update the nodes to step at 0.05 or does it not really matter do you think?
unless you're talking about the comfyui node which I cant change
I'm getting a error with the qrcode system that I cant fix
Error occurred when executing ControlNetLoader:
module 'comfy.sd' has no attribute 'ModelPatcher'
Well, look how HUGE of a difference 0.3 and 0.4 were.
yea slight color changes affect the composition a lot
I pushed to git it should step at 0.05 now
I'm not gonna do 0.01 lol
should be able to just update it with the manager
well, for testing I would like to see if .01 matters. I think it might
you can change it yourself in the file it's just the "step": 0.1 value on the node input thingy
Hi guys, I hate to interrupt and not sure if this is the correct channel, but I used Realistic Vision and ChilloutMix model, all works fine, but as soon as I switch to SDXL, eerything becomes like this. Any help is appreciated!!!! :)))))


which sampler, scheduler and model?
in general SD 1.5 is 512 x 512 SDXL is 1024 x 1024 @slow yoke
hypothetically you could also allow the min/max to be greater than they are too but that's actually insane
like how do you have 150% black?
sampler is Euler a, model is sd_xl_base_1.0
thank you, will try
that's a VAE thing
class BSZLatentOffsetXL:
# {{{
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"latent": ("LATENT",),
"offset": ("FLOAT", {
"default": 0.0,
"min": -1.0,
"max": 1.0,
"step": 0.01,
}),
}
}
idk what UI you're using but make sure you're using automatic or the XL vae
negative black doesnt work I dont think. makes like brown?
hm, weird, it looks like it is not fully denoised. But yeah, you definitely should use a resolution of at least 1024x1024, otherwise the image will look very ugly
see here for a list of resolutions that work well with SDXL: https://www.reddit.com/r/StableDiffusion/comments/15c3rf6/sdxl_resolution_cheat_sheet/
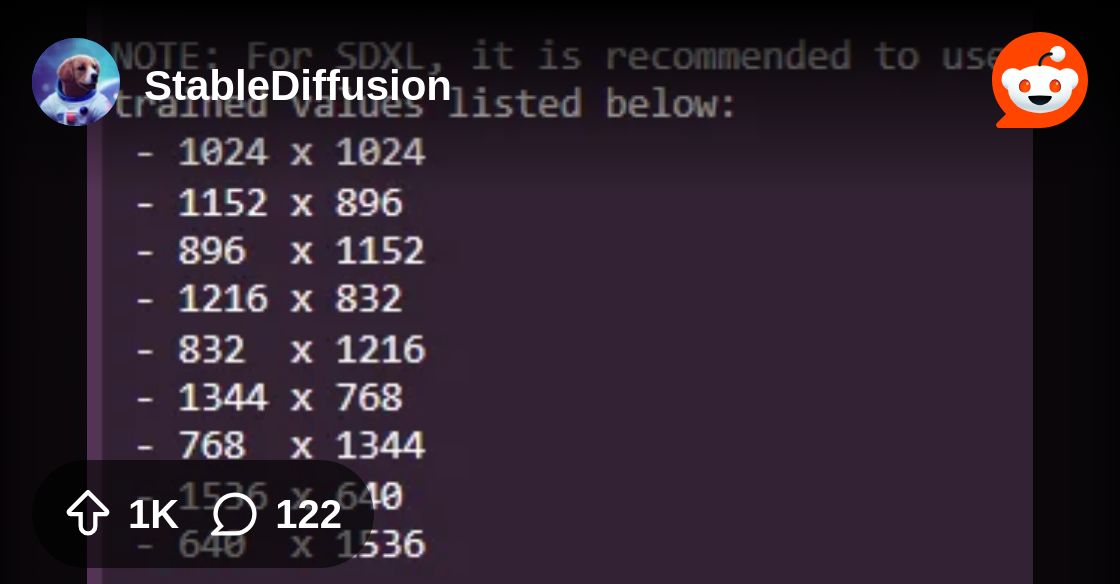
Reddit
Explore this post and more from the StableDiffusion community
I'm 99% sure it's the 1.5 vae on an XL latent
which is why it works fine with ChilloutMix
somewhere in the UI the VAE is manually set to sd-ft-mse or something
for sampler I wouldn't use Euler A. If you want a non-deterministic sampler use some of the Karras DPM SDE samplers. Or simply use DDIM or UniPIC for deterministic.
wow, I wouldn't have expected that this is even possible lol
I mean, technically, yes, but I would have expected you get pure noise back then
they're both 8x latent space so they technically work
just XL was trained from the ground up so it's totally different

LMAO when you see your neighborhood abyssal demon on your way to work 👋

refresh the browser too sometimes it gets stuck
i think the comfyui web app caches what the nodes' value sliders are
yeah
so if you already restarted the server gotta F5 as well
Thank you guys for all the help, let me give it a try
It worked, changing to Automtic erase the problem completely, thank you 🙂
OUCH, 2011
not mine
despite the stuff looking complicated my nodes are probably the most mundane of all the node packs. just slightly altered existing comfyui nodes for the most part


that's mostly gonna be seed variance at that point
actual colors are the same
don't care it made a good change because the latent color changes content as we know
I meant latent color is also a seed of its own
its like a variance seed
yeah. I will stick with .01 changes as I like this the best.
so the tiniest of changes will affect an image even if the actual color is the same
One thing i give XL credit for is most of my "mermaid" things dont have legs. in 1.5 you had to blacklist like feet legs knees etc and it'd still most likely fuck up. XL i dont have to blacklist anything

2.0/2.1 had legs too
never used it runs like shit
2 is slower than XL
if you autocast 2 it just NaNs instantly.
and fp32 is like 1/5th the speed of fp16
sometimes it makes them red 🤔

I was trying sand castles you all got any good ones
on this channel?

I hate how I am forced to to use fp32 for the vae
on XL?
yes
yeah, I use that on comfy now but still the same amount of vram being sucked up
damn really
on automatic1111 we have to use the fp32 for vae
yes, so I wonder why use it? I think speed as bf16 is faster than fp32? I dunno
yea bf16 should be speed comparable to fp16 I think
thought it was supposed to use less mem though
I despise vlad with a passion. I mean pure hatred the kind you probably do not know. in other words, no thanks.
interesting.
trust me, I have a legitimate reason for it so I don't go anywhere near him, or his work.
I've only spoken to Auto in pull requests and never to vlad so im not sure what the whole deal is
I have no idea Auto isn't really in control his rag tag band of devs are all over the place.
sd.next has a HF diffusers backend so its pretty nice. UI is a little jank sometimes though
idk anything else that supports arbitrary Diffusers models
I guess i could write my own CLI script it wouldnt be too hard
I can't even find any trainers that use diffusers BUT one from hugging face. Really janky but damn the quality of diffusers directly I like it
but making a full UI with live previews and everything is pain
simpletuner?
unless you mean loras
??
OneTrainer really took its place
I used to be on the ST discord then they said it was dead and I just left it
this one? https://github.com/bghira/SimpleTuner
gets updated all the time lol. I might try to get it working with Lora later once ROCm isnt having a crisis
Don't know now as it was a while back. They were being asked for someone to take it over but honestly it just never was my thing. for DB I used Shiv's. FT no way in hell am I going to hand curate 3k+ images and captions.
This was before XL was even being talked about
ST can use DeepSpeed now for 24gig cards so if you're doing full checkpoints it might be spicy.
DeepSpeed is very similar to AITemplate
DeepSpeed spanked me on WIndows. Being Microsoft I was shocked but I didn't like being spanked by it. I decided it won, I lost, and moved on.
it's not compatible with windows, microsoft are stupid, didn't you know?
i got rocm's deepspeed fork to actually work but it miscompiles if you use stage 2 cpu offloading
I do now.
this accident has lotr level bloom

accidents are always fun
it's just a shitty version of AITemplate except it's only for LLMs, best optimization for LLMs is exLLaMa; which is x8 speed

i mean it seems to train diffusion models fine
I haven't heard a word, for the last month, about the new xformers being released. Supposedly it is done but was waiting on torch.
more mem efficent and faster
yea it's based on Flash Attention 2 now
problem is needs tensor cores of ampere and ada cards only
maybe, idk. WE. NEEDS. exDiffusion
well, I want it for training
exllamav2 uses Flash Attention 2 natively but I haven't been able to successfully compile it on rocm yet
there's a PR to merge the Flash Attention 2 changes into pytorch 2.2 as well
so scaled dot product will get the same speedup eventually too
hypothetically you could directly use the flash attention lib on stable diffusion instead of through xformers/sdp
maybe they could make something like exLLaMa for training?
that would rock
exllama is hyperoptimized for inference specifically isnt it
I feel like it is the Commodore64 days again and every single byte counts.
it compiles a microkernel for the model/context shape/gpu
so similar to AIT i guess
the x8 speed boost comes from optimized kernals; this is why I first thought it will be easy to make something similar for diffusion
but exLLaMa for diffusion seems far for now.
i mean you already have something like that with AIT. it just doesnt seamlessly compile the kernels for you and just work™️
it does just work depending on your system..
exllama works always. not depending on your system
if you have a 3000 series card and above it will work right away
true, and the speed up is even higher
exllama hot-compiles a kernel if your gpu isnt included in the pre-shipped ones
so it works on AMD and everything too
the first gen takes +30 seconds while it compiles then it's gucci
AITemplate compiles engines, exLLaMa compiles kernals right?
idfk
I have no idea what the difference is
they call it a kernel in the readme so
they are different, optimized kernals are more flexible than optimized engines
and faster in this case
I do not get it. I trained YET again and still blurry but non of my data was blurry

SHARK does the compiled kernel thing for diffusion models too
but it's pretty fiddly I've found.
if I switch from base the blurry goes away but base is what I trained on
blacklist "blurry"
by how much is it faster than pure PyTorch? because exLLaMa is about 8x as fast in my experience
comparing exllama to transformers is apples oranges
exllama runs on quantized models
I can't release this like this having people type blurry in the neg
you cant quantize SD afaik so it'll not be 8x

and if you're talking about exllama 1, that's a 4bit quant which is substantially smaller than a fully fp16 PyTorch model
so it's going to be a lot faster
exllama2 can use mixed precision quants, and 8bit cuts the speed in like half compared to the default 4bit
idk, I feel like if we'll have something like exLLaMa for diffusion we could get close to instant image generation

i mean it might be possible to do an exllama2 approach mixed-precision quant by brute-forcing all the layers to find which can be tuned down without spitting NaNs
so you could have like 9.82bit SDXL
or whatever
13b 5q is very slow in comparison with 7b
Only optional, otherwise 50% users cant use it.
yes should i install xformers?
i get the same problem. fixed when i switched to prodigy
for what?
i got it as option in gradio for oob*ga
I get 8T/s with GPTQ and 62T/s with exLLaMa... I would love to see the day this will happen to diffusion models
yea that's a pretty spicy gain.
Is that something ADAfactor does?
try exllama 2 with flash attention if you can
should be even faster
if it's a 4bit gptq model you dont need to convert it to exl2
I tried that on Linux. it was a pain to do but it got to over 80T/s
no its an alternative to it. like adamw
yea, just know that not all backends will use it.
like exllama 2 doesnt use xformers
No, I know what it is just wondering if this blurry is an issue with adafactor?
oh idk i only used adam before prodigy
o.k. i am now using gguf models. lama.cpp
adafactor is adam it is a variant that tries to find the right LR as it goes.
ada short for adam
lol the adam mixed-cpu kernel is exactly what miscompiled in DeepSpeed for me
could be rank or lr doing that to you as well. or an optimization like mem effn attn
so ideally; exLLaMa is 8x as fast as GPTQ, so if you have something identical to exLLaMa for diffusion- your it/s should also be x8 as fast
prodigy is so mem hungry I can barely get BS2-4 (forgot now)
if you can somehow quant a diffusion model down to 4bits without fucking it up then maybe
well, that is straight up Dreambooth
that's what we get with AITemplate
I finally got it to train and it blurs like that :/
yeah im using bs1 but its working great for styles
then I'm not sure it'll matter unless you can develop a way to quantize diffusion models without producing NaNs
exllama's black magic is in it's handling of the quantization
exLLaMa also has its own attention? I tried it with and without Xformers and it was a little faster without Xformers
no diea
idea
exllama 2 uses flash attention 2
I've never used the original exllama
it uses flash attention or something else as a fallback. not sure what the fallback is
For prodigy what are you using for its Optimizer extra arguments?
I think exLLaMa 1 just has a built in version of Xformers
decouple=True weight_decay=0.35 d_coef=2 use_bias_correction=True
even if we'll be able to quantize SDXL in the future, I'm not sure if AITemplate can make engines for 4bit models
i dont think so, which is why GPTQ and exllama became a thing
so we'll need something like an SDQ first then after an ExSD can be made
hope this happens one day
I guess it's kinda bound to happen eventually, but the question is when
wow, 0.35 for the decay?
constant for the scedulere or cosine? annealing is too much mem
I am stumped as to which one?

this is what im playing with rn
Thank you
Those are 500 step difference checkpoints
sometimes I wonder if I should've gotten the 16 core...
Next year I get zen 5 and 16c/32t is what I am after but for python stuff it will not help but does if I do anything else along with it
i have zen 4 12c and it compiles pretty fast
tbh not often i can peg all 24 threads like that
I went from 1600 to 5600 a few months ago and glad I did but I already have issues with just 6
most of the time it only uses 24 for a few seconds then decreases as jobs complete
6 cores 12t not enough
so unless you're compiling the linux kernel or pytorch it'll fall off after 12c
interesting

kill it, kill it real good
okay it's not faster but exllama didn't bitch about Flash Attention not being installed
anything to enable using only gguf models @nimble heart ?

no idea I don't use gguf
o.k. what model i can afford and you can suggest having 16GB RAM and 8 VRAM?
do you mean like compiled with visual studio, cuda, and the whole circus installed or did they add like windows wheels or something to pip
i mean with ROCm on Linux
oh that's a whole another can of worms I guess
should work just fine on nvidia
I know my next pc will have 64, or 128gb of rams right off, all slots filled.
anyways the exllama "you dont have flash attention" warning went away but it's functionally identical. Same vram usage, perf, etc. So I'm guessing it fails and falls back later or the rocm flash attention is just all stubbed functions to pass tests currently.
will try sdp_attention and see if any difference
you can check by importing attn from exllamav2
like uhh
python -c "from exllamav2 import attn; print(attn.has_flash_attn)"
False
@soft bone your "T_max=25" is out of whack.
sheiße

yeah then it's just failing silently
ah it gates it to Flash 2.2.1 and my fork is 2.0.4
let me bypass it real quick
what's the worst that could happen
yeah my bad it was 25 epochs before i changed it
Well, I am still a bit wonky about t_max as the net says epochs and steps but never says this is EXACTLY what it is.
amd fucking card gated it

this is where i got that

I'm hoping that changes once the 7900 cards are "officially" supported because they should have the architecture to do that
they have the WMMAs that their flash attention fns use
SDXL from Distillery@Discord (free in Alpha Test)







