
#✨|sdxl
1 messages · Page 122 of 1
/d@cyan crown








You mean you want to remove the image feed panel that collapses into img icon?
It comes with custom node called Custom Scripts

Leaving the randomizer I built to run last night was great. I did find a few things that needed to be removed as well as I've found it's a bit heavy on a few concepts...Superman, in particular, came up quite a lot. But here are some great examples of what it put out.










Spiderman Deer ❤️
If you're interested in seeing all the other images plus other things ones I've intentionally created, I've put them all up for viewing:
https://lychee.soulctcher.net/
Not sure I have that as I am currently in Linux so can't check but I will look when I switch over. I wonder why they never gave an option to remove that/disable that? I mean I will gladly remove their entire nodes just to get rid of that one thing.
you know, I am in Linux and it blows me away at how the same fucking EVERYTHING as in windows I go from 1.26s/it to 1.38it/s
for training a Dreambooth
almost half the time
was just looking at this on civi like 2 minutes ago, wierd
does it do well with bearded cats? lol

using shaun?
Just a prompt and a model.
Is it my Lora?
trying to get consistent grumpy bearded cats, pixel lora does ok but not great
Here's a few more with the same prompt and model, just different seeds.



extreme closeup headshot of a (((grumpy))) white (((old kitty cat character))) with whiskers and a ((massive beard)) (yelling at the camera:1.2) in the voxel art style voxel lora sucks for it
too many words,remove headshot ,old kitty cat character,yelling at the camera
This one?




Nope, that wasn't it. I do not have that node installed
it's not a Lora but is it sdxl standard model?
if i just installed Stable Diffusion A1111 via https://github.com/AUTOMATIC1111/stable-diffusion-webui.git is that sdxl? Where do I look to see what version
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.

I'm using the JuggernautXL model for those.


this guy looks devious af
seems to be more about the prompt then lol
short beard here

P:
texture, intricately detailed, theatrical lighting, amazing, highly detailed, sharp focus, trending, 8k, 35mm
(3D voxel style:1.2), pixel style, dynamic```
**N**:
```(worst quality, low quality, normal quality, lowres, bad, oversaturated, undersaturated, overexposed, underexposed, grayscale, bw:1.4), (watermark, autograph, trademark:1.2) (blur, blurry, grainy), morbid, collapsed, cropped, missing, deformed, imperfect, conjoined, deformed, ugly, imperfect, skewed, unnatural, error, mutated, out of frame, cut off, censored, jpeg artifacts, glitch, deformities```How about papercraft style instead?

How to prompt for these kinda images?

just dont put anything in prompts and u get that
that's an idea, haven't tried that
Blue_Jizz on Canvas
Anonymous, 2023
$3,050
🤣




kinda got what i'm after using your prompt idea

Nice...
appreciate ya





Does SDXL work with controlnet?
yes
aYE
Are their XL controtnet models to download?
Aye
Or can I use the 1.5 ones
1.5 not compatible

So I just put that in the same place as my other controlnet models?
Yup
https://huggingface.co/thibaud/controlnet-openpose-sdxl-1.0/tree/main
here's an openpose also

cool thank you
I am getting this error:
NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
Looks like you're in A1111, I know they recently got it working there, but I'm not using that as I've switched to Comfy.
So I cannot verify what works vs what doesn't in A1111 at the moment
darn
I'd pose the question again in a bit and specify it's for A1111, see if someone else can chime in regarding

I also am getting this error in text2img:
RuntimeError: The size of tensor a (64) must match the size of tensor b (96) at non-singleton dimension 3



No. This one with image feed.
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
GitHub
Enhancements & experiments for ComfyUI, mostly focusing on UI features - GitHub - pythongosssss/ComfyUI-Custom-Scripts: Enhancements & experiments for ComfyUI, mostly focusing on UI features
What models and vae are you using? That's a size mismatch of some kind
that error went away after I restarted auto1111
Ahh
That was one of the ones I had disabled too.

Still does it

Embosssed






why are they shrinkwrapped
Thiccc emboss







Try to uninstall it completely.
Do LoRas for 1.5 work for SDXL
no shouldnt

just added evening




they won't work?
yes. Afaik, so my answer is basicaly worthless. But i think i read it several times here in channels.
No, they will not work.
they wont work
for example at LORA with Geishin impact
technically you can send SD 1.5 fine-tunings to the CLIP_L encoder of SDXL, but you will not get the results you are looking for (at least most of time) since all the fine-tunings have been trained on a total different latent space
Btw how many images does one need to train a good Lora?
also can I ask what the number parameter does? lora:SDXL-Caricaturized-Lora:1
can it be anywhere from .1-1?
It increases the strength of the lora?
yes - 1.0 is the LoRA at 100%
Do I need to add the trigger word outside this part?
or does havinglora:SDXL-Caricaturized-Lora:1 do it
it depends on the LoRA

Trigger word Use " Caricaturized " in your prompts Refiner vs. Hi-Res fix Sometimes the refiner would yield a better result than the Hi-Res fixer. ...
read what it says under the LoRA title 🙂
so adding Caricaturized is the trigger word
correct
So I need to add Caricaturized and lora:SDXL-Caricaturized-Lora:1?
yes. it makes sense to use trigger words somewhere close to the beginning of your prompt
so like this?
Caricaturized donald trump in a suit and tie, full color, cartoon character, lora:SDXL-Caricaturized-Lora:1
or
lora:SDXL-Caricaturized-Lora:1 Caricaturized donald trump in a suit and tie, full color, cartoon character
yes, that's both fine. the placement of the <lora> tag is not important. it will be stripped before the rest of your prompt is being processed
you're welcome! what software do you use to create images? the <lora> syntax does work in automatic1111 but not natively in ComfyUI
I use auto
than have fun 🙂


new version 6.2 of my workflow - reduced required 3rd party nodes, cleanup, some smaller fixes and changes
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
https://i.imgur.com/XI4Adpw.jpg
GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.



That is my next attempt, but it does show it is a naughty node since it is not adhering to me saying disable. Hopefully it works BUT it is one of my most used nodes due to loras having an on/off that is not in the native lora node.
a lora node with an on off switch?
did you img2img @hardy cipher or what 😆
yeah, but is a drop down. I did see one with a real switch on it but not sure which one that was
I made lora nodes with switches
I don't make nodes it ain't my bag
comfyroll nodes have a few lora on/off nodes
yep
problem is that is the one that I am forced to remove
no way to turn off that queue thing
here's the deluxe version

That apparently comes from comfyroll
the one I normally use loads 3
10 is a bit much
I don't know. didn't find any that fit all the criteria. multiple loras in a single node, switches, and normal inputs/outputs

grinds my gears when I find a node that does most of what I want then has weird outputs that don't work with anything else


they look a bit soggy

she looks greasy
Always did
she
looksis greasy
FTFY



I just got done w/some workflow adjustments that allowed me to do something like this:



oh yeah, your automated system
Did you see the link I posted, @hardy cipher?





garlic teeth

don't think so
I made a new server to host all my diffusions. The site is here:
https://lychee.soulctcher.net/
If you click on Random Diffusions, that's the output from what ran last night.
ahh yes. that template is quite versatile
man, that's awesome
I plan on running more soon...just am working on stuff for the moment.
yes it is quite fun, always wanted to do cutaway style, mostly buildings

Isometric cutaway is a visual technique used in illustration and design to depict a three-dimensional object or space. It combines the isometric pr...
something like this https://youtu.be/d1RnYfFZK2k?si=S69hS0ozaZ-XNF6y

they're all quality outputs too. no fails in the bunch
I'm all about creating things like that. just haven't really put anything together yet
I found a couple, but they're not terrible and not quite obvious. But yeah, it really pumped out a nice batch. I did have to pull a few nsfw ones. Not that I don't like them, but I've got to keep it family friendly enough.
nice

well they can't all be 10s. sometimes you just get a seed that doesn't vibe with the input
Exactly. But considering what ran, it's like 99% good.
But there are some real gems in there... loved the computer monitor setup that displayed an anime wallpaper.
yes. I like these sorts of things.took a few iterations of things to get them where I wanted. started with regular blueprints.










Those remind me of the Metroid ones I did... very nice.
man, I had to keep some of them to myself. they had very phallic appendages, lol. was not going for that at all
and not normal ones either. weird stuff
Pretty funny what this stuff can do sometimes, that's for sure.
Hey...I'm going to create a new version of that ALBUMS picture above...give me 2 totally different styles...one for the background and one for the text itself.
I'm trying to see what sort of things I can mix with the ipadapter. some things definitely don't want to work together
hmm
8 bit background with calligraphy?
I don't know about these things

The font on the image is set...just need some other wild thing to fill it in with.
don't trust em. I know that much
I can do an 8-bit style for the background, though...
8 bit with ussr propaganda style fill
hmm. ever try pasting lyrics in? you should paste some dr. octagon lyrics in for the text fill
This is the latest one it just rendered. I'll go grab something from Dr. Octagon to kick off the next version.

blue flowers or something. it's nonsensical, but I've made cool things with that sort of approach
Can't wait to see how this ends up.
a bit too deep fried

That's wild.
Very cool, I''ve done some aliens myself today





some of these could be a bit more refined, but I do like the aesthetic.
Stuff like that works really well in tall aspect ratios, too. Like...rerun that, but set it to 768x1344.
that's a good idea, might do that in a couple minutes

cursed

that face in the bottom left
ha...yup
demon


Definitely went for that 8-bit propaganda look
but did you consult jesus?

Eggplant Man

need to unblurrify this one

alright, I'm going to reuse these. they're almost on point
details are just a bit goofed

Is there an inpaint model for sdxl?

where outpaint tho
the future

not yet afaik

I did some inpainting with the SD XL models, it kind of work for changing some details
bro boarded the wrong plane
Steven doesn't have much chance or

I'm just going to run them back through ipadapter


that aint DW opepose thats just openpose v2🤓 🤓
There we go

I guess I'm missing context of what DW is 😆
extra deep friend orange man
a more accurate preprocessor than "openpose_full"
aah gotcha




Man, how does someone figure out what epoch is the best one?
well you can save state after each epoch right?
there are all sorts of ways to gauge their progress as far as data is concerned
but ultimately I think it's just a judgement call


beautiful
he looks squeaky clean

¯_(ツ)_/¯


shiny nipples 🤣


What are criteria or recipe to generate excellent images?
Let me guess...
1.Checkpoint
2.Vae
3.Lora (optional)
4.Image Resolution
5.Prompts
Am I right?

no, prompt is always first if your prompt game sucks your image will suck
Prompt #1 for sure.
Why is that surprising in a text2image product?
Checkpoint is like the beginning of everything yes?

steven seagal vs godzilla?
yes
Checkpoint I use at stylizing mostly. But just because I use a specific checkpoint does NOT mean my images are going to look amazing

Are there checkpoint even past SD version focus on generate anything?
instead of specific thing
huh?

yes but specific style checkpoints are better than all in ones
Oh, yeah, what he said.
I wanna try all in one cuz I want to reserve my storage drive lel
I mean really, SDXL is pretty damn great at holding it's weight in a ton of different subjects without needing to change checkpoints much
Storage is cheap in the grand scheme of things.
But i get it, money spent is money spent.

taylor doesnt understand what sensei is talkin 🙏
Hahahaha






he got them shiny nipples again 🤣

They all just look like overbaked images to me.
get new eyes, a better screen, or get off that mobile dinky screen
I can't help blindness
If I was blind, I wouldn't be able to say with confidence that this is an image of Monica Lewinski.

But seriously, all that effect does besides make all those images look terrible is maybe make them look like they've been vacuum bagged.
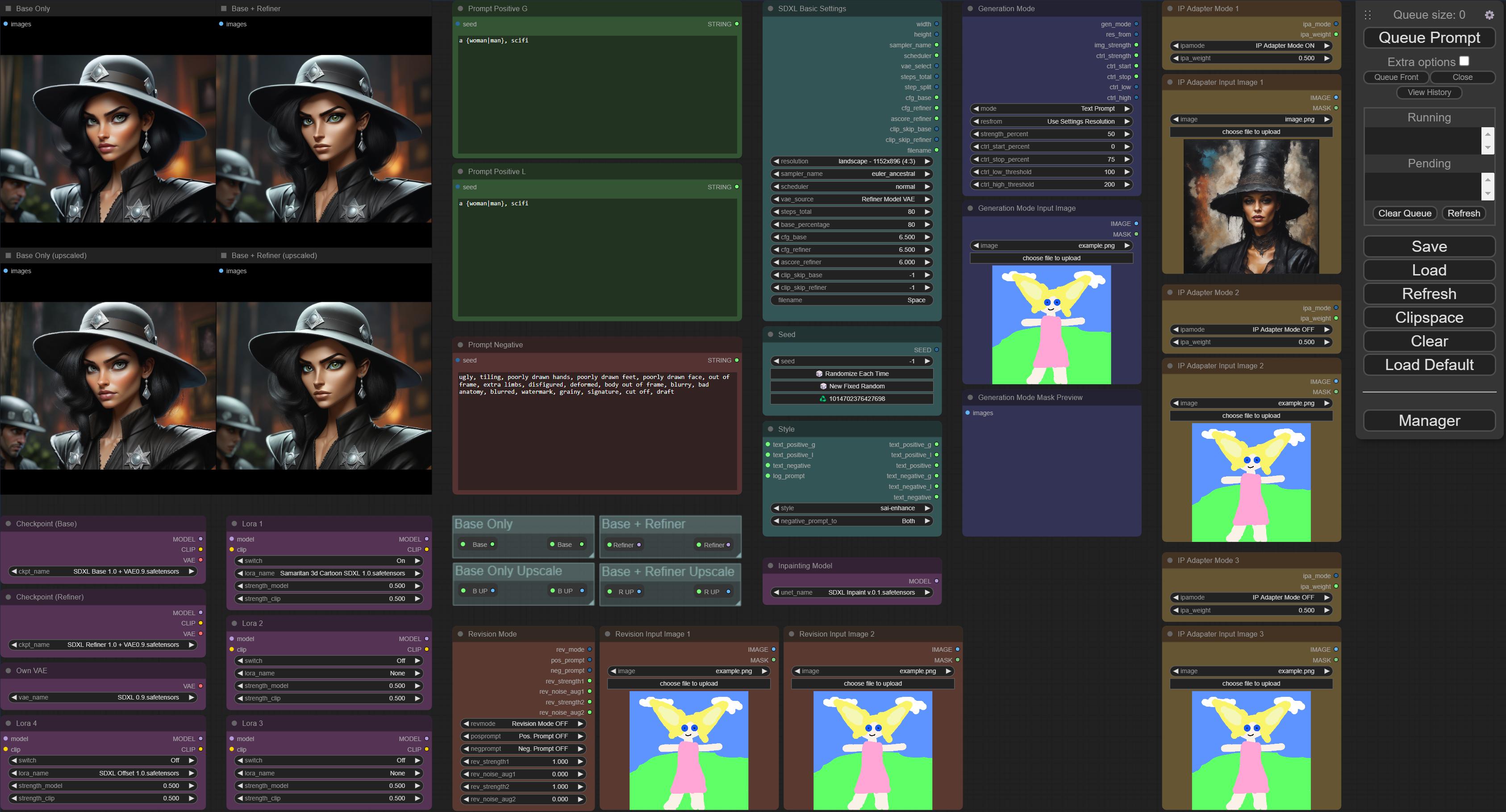
Finally put together completely my main workflow. Control switches operate Controlnet/Revision/Ipadapter/etc, and combinations of them together.
Organized by groups to allow for group bypassing to save on unnecessary models/nodes loading in taking up VRAM.
https://civitai.com/models/142535?modelVersionId=158068

This workflow is mostly created for my own purposes. However, it is highly adaptive given the ability to combine nearly every aspect of it. There a...



thats a cannon
mall cop seagal has some serious forearm girth though. he can handle it
getting weird




Is it possible to prompt a watermark for prevent stealing?

Shrink Wrap V1. Use various weights with this one.
You yourself, not really.
There is a treering watermark tech that can be implemented (to my understanding) by hosting sites for proprietary models
there's a way to watermark the images. but I believe that's only to say that it's created with stable diffusion or ai. but don't think it's customizable for the individual
Is it possible to use more than 1 img during img2img?
probably more of an IPAdapter thing
https://civitai.com/models/138381?modelVersionId=152897 Try this it works really well

A version of the AIT workflow, but this one does img+img, instead of text2img. [REQUIRED NODES/MODELS]: - https://github.com/FizzleDorf/AIT - https...

chonker hands

playing with the conditioning pooled output on the last image gave me this

he looks devious 🤣
he really does
looking intense now

that tuft of chest hair really pulls it together
it's a crazy balance of numbers though. change anything and it breaks, lol
he looks like an 80s sexy macho badass
Finally got the RGB and Alpha Channels all sorted out.
Tomorrow I will work on brush softness and opacity.

pushing the limits with latent Seagal

curious to see if it even works with other seed numbers. 0-1 so far
lol

that image in the back really brings it together
this is the only other one that even rendered. rare Steven

I don't even know if it looks like him anymore
Anyone know a way to randomize the seed client side without having to do a gen in ComfyUI?
hmm? you mean to cycle through them?

monster hippo seagal looks like he took some front tooth damage
hippo looks like he had a mask with eye cutouts 🤣
Seed changes after the generation, it's annoying if you are disabling parts of your flow for speed. You then have to check the metadata of the generated image you like to use that same seed and run the full workflow. If there was a way to change it before the gen or a button that randomizes the seed client side would fix it.
this guy

what are you using?
hmm they don't allow us to tag a moderator, that's a mistake
you know, the internet has plenty of porn. don't really need to see it here
pretty sweet, dude
Must live an exciting life
Using what? Comfy?
there were some ppl talking to ping them

Report and block
@smoky patrol
There seem to be more than me that would like some options controlling the seed randomization. https://github.com/comfyanonymous/ComfyUI/issues/1084

GitHub
The current behavior is randomized AFTER generation but that causes confusion when you are looking at a NEW random value, but not the value that was used for generation. Please update with an optio...

oh, that wouldn't be too hard to implement

Never fiddled with the javascripts in Comfy but yeah, should be doable if you know what you are doing. 😄
well I believe it's python, but close enough. easiest way would probably be to create an external seed randomizer and have it keep a log or something. or create an image loader node that displays the seed number
or I guess you could modify the sampler
wouldn't be that hard to add it to a sampler, but then it'd just be in that one sampler
how to denoise an existing image?
i thought i got magic prompt for architecture, but when removing black magic part, it is even better 😄

I think it's somewhere else than in the sampler. I'd have a look and see where it's done now.
how do you mean?
@ionic dragon denoise like in photoshop? Or some latent you mean?
the seed number? it's right there in the sampler unless you manually changed it
for example, i have this image, i want to denoise(0.3) this image and generate a new image

seed generation in the code
latent
Sampler just takes seed as a argument to the function so it's generated somewhere else
Which CN model do you use for tile upscale? The preprocessor is showing up but I dont see a tile model

def common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent, denoise=1.0, disable_noise=False, start_step=None, last_step=None, force_full_denoise=False):
@clever verge can we do something like this?
you just set denoise to 0.3 and do it
in img2img
just run the image through a vae encoder
@smoky patrol he is posting NSFW stuff, and using abusive words
too bad discord still doesn't do blocking of people properly
@worldly temple
I don't need to see the mentally ill's constant '1 blocked message Show message'
indeed
Could be in widgets.js:
`function seedWidget(node, inputName, inputData, app) {
const seed = ComfyWidgets.INT(node, inputName, inputData, app);
const seedControl = addValueControlWidget(node, seed.widget, "randomize");
seed.widget.linkedWidgets = [seedControl];
return seed;
}`
they should also freeze their account for a while if they get several reports and blocks onb one person
well why you need to mess with all that?
I'm looking for good gens with less of my workflow enabled (upscaling and other stuff muted) to find a good gen that I then want to upscale and do other fixes on.
What I have to do now is to set seed to fixed and look for the seed in the generated image and paste that back into comfy and enable the full workflow.
@hardy cipher like this?

okay, but the seed number is used by the sampler, so no matter what the sampler knows the seed number. and it could easily be modified to log them all if you wanted to
looks right to me. it'll tell you if something is wrong when you run it
Like this

oh, well you have an atypical setup there.
but it brings us back to the things I proposed originally. an external random number/seed generator that logged previous seeds
or an image loader that showed you the corresponding seed, or even had it as an output
Nah, just want to be able to hit a button that updates the seed client side. Like automatic1111.
well good luck with that
Or if the seed is updated just after you hit generate could probably work too.

@hardy cipher whats wrong in this?
the input image and the ouput images are the same

increase denoising
ok

no this is a different base image, this is the base image used

should I also decrease the cfg?
if you want to I guess. see what happens
ok
show me an output image

If you wait a few minutes, I'll be uploading a quick update to it. Just tidied up some things.
https://civitai.com/models/123048
you have denoise set at 0.2. increase it if you want to see more change
Think it's working.

oh, a random seed generator?
@uncut steeple
I changed it to 0.4, and got minimal change
well then change it more
you can try 0.6 what was default somewhere, or even 0,75

you got that spicy cfg as well
13 is a bit hard to manage without some other things going on
also, you have an entire huge workflow right above yours

just pushed the updated version
yeah, just muted thatt
might have to give it direction or something. and that cfg should be lowered unless you really want your image cooked
cool tq
Civit flagged this for review

🤣
one other thing. you probably want to cut down that image size
speaking of first picture id like to see a fetus lora for some horror experiments but looks like theres none

Vintage Dr. Pepper commercial circa 1979 featuring David Naughton ("Makin' It") & Popeye The Sailor.
Wonder if they'd allow it?
prob not 😔
so they can have the most degenerate sexual depravity imaginable and that's all fine. but a shiny skull crosses the line
hahah ikr

because sd isnt good at 2048x2048?
damn, what are your settings
well because if you don't use 1024x1024 it won't render correctly. well it just has to be 1 megapixel

if you want to use any of my settings just load any of these images
I just added a couple things to your workflow

using some models you might not have, but you could download almost everything from the manager
That's a ui error, what'd you do?
is there any node, which downscales the res?
i didnt get you
Usually errors like that are because of a backend issue
I added it


ig its not fetchng
we can get a cool animation
Your Comfy updated?
i last updated it around 15days back
that's a while...

Threw that image into my flow haha


GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.
pretty sure that's this
yah it is
got an error damn
missing upscaler model?

@visual glade Do you have any idea how to best implement this without breaking other stuff? I've modified stuff in widgets.js now.

It's just your Efficiency nodes install bonked. Remove it and reinstall.
Use the manager if that's easier

My img2img flow I made the easiest way possible, there is a single node to change, the denoise.
Everythign else is done for you
i used manager to install
lol
Then delete the folder and install via the git

yea doing that
manager gets wonky with some things
ywa
this image doesnt contain the workflow

same error
Hmm.... I'll have to check efficiency pack later then, but I know I recently updated it and it's fine for me.
In the meantime, bedtime for me
gn
interesting armor

@hardy cipher can you please share your settings?
are you even running them through refiner
you can literally look at the settings if you drg that image into your workspace
the image doesnt have the metadata, i dragged it, but not happened
i think you copied the image and pasted it here
I dont think you can,discord strips the meta data
if you attach it, you'll have the metadata
discord doesn't strip anything
oh yeah, well I might have done that with the last one actually





now it works, tq

Are you using Windows or Linux?
me?
yeah
windows, but I sometimes run things in linux
@hardy cipher do both load images be the same?




optional

well that's ipadapter
you want to use "pytorch_model.bin" for sdxl
for clipvision
all those models should be in the manager
you should use the manager to find these things if you aren't sure about them


cant find them in models tab

hmm. well they're certainly all on hugging face. weird they're not in the manager list
i got it
srry for the ping someone was spammin porn gifs but wyzborrero banned him already 🙏

I like how they were like "yeah, but I'm trolling the server" when I expressed my displeasure with their actions
yes, you'll want to use the IP-adapter models specifically
ok
also, there's most certainly a cleaner implementation of ip-adapter out there if you have trouble with this one
is there a tile-upscale for sdxl? I have the new CNs and it has the tile preprocessor but not a tile model
i am here
what did i miss
nothing
kaj did a backflip
@hardy cipher added refiner, and getting this error


your conditioning inputs are using clip data from the other model
need to give the sampler refiner clip data

oh ok
@hardy cipher i am using this, but I cant find denoise in ksampadv

I just saw there's a PR for this behavior that seems to still need some work. https://github.com/comfyanonymous/ComfyUI/pull/93

GitHub
This PR adds the ability to generate a random seed before the workflow is queued.
Converts the random value widget from a toggle to a combo with the following values:
after generation
before gene...
I am new here . Can anyone help me with SDXL on comfyUI. :V
what is this crop_w crop_h do?

if you are new I'd recommend just not using comfy but using webui or one of the even easier UIs, comfy is a mess to work with
Super Furry

but crop w and crop h seem pretty self-explanatory - crops width and height
it doesn't seem to affect my output at all..
crop_w: 400 crop_h:0

crop_w:0 crop_h:400

crop_w:400 crop_h:400

crop_w: 800 crop_h:0

crop_w:1023 crop_h:0

Yeah, shame about that, guys. Thanks for the ping, though I was dead to the world.
C a t s
crop_w:0 crop_h:0

no problem 🙂
The crop conditioning doesn't work very well.
trying to quit smoking. It is difficult.

Crop conditioning is a new feature introduced in SDXL 1.0 that allows the model to take cropping coordinates as conditional input during image generation.
Specifically, crop conditioning provides the cropping coordinates (x1, y1, x2, y2) that were used to crop the original training image. This information is fed as additional conditional input to the model alongside the text prompt.
By providing cropping coordinates, the model is able to generate images that better match the original aspect ratio and framing of the training data. This leads to outputs that are more precisely cropped and framed according to the text prompt.
Some key points about crop conditioning in SDXL 1.0:
-
It provides cropping coordinates as additional conditional input to guide image generation.
-
The coordinates correspond to the crop applied to the original training image.
-
This allows the model to adapt and generate images matching the framing and aspect ratio of the training data.
-
Results in outputs that are cropped and framed more precisely according to the textual description.
-
Represents an enhancement over previous SD models that did not leverage crop conditioning.
In summary, crop conditioning gives SDXL 1.0 more contextual information to produce outputs tailored to the desired framing and composition indicated by the text prompt. This allows for finer control over the cropping and leads to higher quality results.

OK, so FollowFox's w/flow is more useful (to me) than I thought! Great to hear.
It has this crop conditioning setup

Followfox.ai is an AI venture studio focused on small AI models running locally or on the edge. We are fully open-source, and in this blog, we share about our exploratory journey, providing useful and helpful details on our progress. Click to read followfox.ai’s Newsletter, a Substack publication.
The logo is perfect





She BEEG. She Queen.
She have army.

The Randomizer run last night gave us this fine image.

bro 🔥
When you and your homies all max out the same armor and raid together.

Definitely would shop here.

tested A1111 it has nice results, but still slower, on other hand made huge leap in performance.



500 more images, including this fine image of Kirby, from last night's randomizer run added to my gallery: https://lychee.soulctcher.net/


Yeah, i think have reached peak LoRa Training performance. Made a LoRa that makes every picture look kinda uncanny, unsharp, flat and with a paper texture. Nice 🤣








analog camera??
No, my lora that makes things look worse





@noble shoal old newspapers lora 🙂







And that's exactly what it was trained on

can i have it?





I might upload it later today. Will keep you updated
just made in image input multimodel workflow LOL

Oooh, these are cool.
Mobile so can't check if there's Metadata attached, lora effect, or prompted?



Second lora in row i guessed right! 🙂

man, IPA is damn magic

simple prompt.. protovisionxl

McSpider+destroying cyberpunk city= this monstrosity LOL





pcb king
1 sec.




modern pcb

sure.. wounded modern pcb solider

Thaevil TM

sorry my english is too weak. I need easy english 😄
if i offended somebody it wasn't my intention. I hope we all are o.k. 🙂
Wow I love that one really nice gen

GN ALL





does anyone know how to inpaint / outpaint with SDXL? will this require a different model or something similar to 1.5?
LOL

using this lora in the negative will do wonders
?

Nice, like the outcome 👌


It is very cool, unfortunately for me, 2 IPAdapters can sometimes use more than 10GB VRAM, so it slows the generations down.
Have you tried the new version that's out? It uses Vit-h instead of Vit-g. I gave it a go but found it to not be as good at doing what I wanted.
the node? idk about that or are you talking about a new ipa.bin file?
Yeah they released a new bin file that's trained on vit-h instead of vit-g
oh, yeah, I see. is it really better?
as far as I know, ViT-G is bigger, so IDK if it's a downgrade lol
heh, it doesn't even work in ComfyUI lol
bruh

I'll just stick to what I used before, this doesn't even work


is this supposed to be usual time taken even with xformers used?

DUDE

Vit-g is bigger, but apparently vit-h gives similar results. But seems like it'd have to be a zeroed out conditioning thing because it can't deal with the clip-g input from the text prompt. I got the same errors when I tried to use it. Need to mess with it more though
You're probably exceeding what your gpu/vram can handle which vastly increases render time. Even then that's still a ridiculous amount of time
It does, you need to use their SD1.5 clip vision file.
You also can't mix conditioning from the IPAdapters with the SDXL text encoder

SDXL>1.5, I'm probably not going to use that










https://aituts.com/comfyui/ I can't get it to work

ComfyUI is the node based interface for Stable Diffusion. Since the release of SDXL, it's popularity has exploded. Here's how to get started.

Ask a better question then.
Jesus
@mack gief some SD love.
I'm taking a shit right now. sowy.
Again ok.
second time today.

Anyone here have a good comfy upscaling workflow I can see/use/adapt?
I know how to do basic upscaling...looking for something with better results.
Upscaling you should never do to in a workflow.
Imo, here I only upsacle if I get something good and use chainer instead.
Why wouldn't I simply be able to have all of the upscaling steps in a group that can be turned on when I need it?
Imo you should only upscale the wicked output, my 2 cent.
Because not every image is wroth a upscale.
Thats why imo, my 2 cent again.
Hence the "can be turned on when I need it".
Same idea as the other parts of my workflow.
I just turn the group off when I'm not using them.


upload one of your upscaled image
Ok.
Is the upscaling adding any detail or just smoothing out whatever you're upscaling?
depends on what kind of upscaling workflow you are using
I'm asking Thaevil1, specifically.
1 file sent via WeTransfer, the simplest way to send your files around the world
I'm trying to get a good workflow that increases fidelity/detail.
1 file sent via WeTransfer, the simplest way to send your files around the world
still downloading lmao..
That chromatic aberration on the lips, tho.
Got more if u like.
I think that's the effect from that bad VAE.
Fucking disc wont allow file size. 😦
lul

too much artifacts..
Im pretty happy with it.
I'd like to take something like this and make it a bit larger, more detailed. It's great, but it could be a bit more.

Like said I only upscale those I think I are good
Using a upscale in the end of a workflow is ass to me.
Why? You will not know what the image will become. So do it after hand. 🙂
And also why? I do not need nothing from the un-upscale imaget to do it.
If you're in Comfy and you change nothing prior to a step, then enable that step, it will pick up from there. I can just keep that group bypassed until I want to upscale something.
i do 10 to 20 batches .. only upscale the ones i like.. I only upscale upto 4k res.. not more ... i never do just general upscale always latent upscale..
does comfy remember your pending queue if you close it?
I need to stop generating but I have a bunch queued up still
I always upscale later.
All my images posted are non upscale unlesss told so.
🙂
But it is what float ur boat, what may float for me might not flow for others. 🙂
@stone fossil

Drop one of ur upscales then? 🙂


Hey hoping to get some help ? How the heck to I solve this issue I can't seem to be able to get these nodes working


is not healer. is rococo
A raccoon?
rococo 🙂 an actual thing
😄
Comfy can i have question, suggestion? That if AITemplate detected in workflow, it when fixed seed, do not generate just only one image, as each image using AITemplate is original? I mean each image generated with AITemplate is similar but different. And allow this, it can be interesting doing those small differences animation.
I wish comfy would allow for cuda select per node.
who is duping whom?
And second thing make default disable in AITemplate keep in memory 🙂
like?
SHow me one imgs have been deleted.
what are you saying?! I am having hard time understanding you.. 😅
Then lets keep it that way. 😄
sure.. why not.. 😕
Lets burn some VRAM.

It still looks good .. it's just putting a analog filter on..
That might have been cherrypicked. Wait until you see faces

@noble shoalHave you shared your Loras and whatever else you have on CivitAI?
Not now. But i will release this soon. Just picking the best....or might i say worst rigth now
Do you have an account I can check up on?
Oh, that will be my first release. I will post it here when i have uploaded it. I might need a name for this abomination.
I mean a CitvitAI account that I can check up every once in a while.
Should be aimingfail on CivitAi.
wicked

teeth in shape of tooth 😄

reminds me starry night

Hey - were you able to get the new vit-h model for ip-adapter working? I get dict size mismatch errors


i tried negative prompt as the prompt, and the fingers are perfect

Yeah, but they've moved the files around on their hugging face, so let me make sure the information I'm going to give you is correct.




is revision better than reference only?
How do you find them compared to the vit-g ones?

@hardy cipher @eternal fog
Old version working:
sdxl_models/ip-adapter_sdxl.bin is working with sdxl_models/image_encoder/(model.safetensors or pytorch_model.bin)
New version error:
sdxl_models/ip-adapter_sdxl_hit-h.bin not working with either sdxl_models/image_encoder
Yeah they've not explained you need to use the SD1.5 Image_encoder
fr?

Yeah because it's using vit-h which is the SD1.5 Text Encoder
So this needs to go into your clip vision loader - https://huggingface.co/h94/IP-Adapter/blob/main/models/image_encoder/model.safetensors
sweet, will try thanks
And if you are putting the IPAdapter through an unCLIPConditioning that is coming from an SDXL Text Encode node, you need to remove that.
doesn't that mean it's a sdxl/sd1.5 hybrid?

No it just means that it's only using the vit-h text encoder and not the vit-g
SDXL uses both, or it can use both
oh got it

I wonder if they finetuned the image encoder that SDXL or SD1.5 used or made it from scratch
I had more of a play with it last night and I have to modify my workflow to make it work, but this is the difference I see from 1 image.
This is with the newer vit-h only

And this is the older vit-g

And this was the input

what setup did you use? this is what I put together. pretty barebones


key is you can't send vit-g clip data through it so not sure you can even use the ipadapter node most people seem to be using. the all in one thing
You can use that node, as I'm using it.
You just can't control conditioning through it
you might be able to concatenate the two
My Original Workflow I had like this

You can't I tried
At least not with the stock concatenate node. Because the sizes of both the conditionings are different.

But I've just had to remove that unClip conditioning for it to work. Because I'm still using both vit-g and vit-h text encoders in my conditioning
ahh. I wonder if my conditioning normalizing node would fix that
Although let me try a text prompt and see if it breaks it
@wet nacelle https://civitai.com/models/142931

Are you done with ultra clean images coming out of SDXL? Then wait no longer and get the crappy newspaper photo style . Trained with a whooping 34 ...
I should add those nodes to my github. I just didn't want to put anything up until I knew it was working as it should
at first I goofed and had it modifying cached conditioning, lol
that goes awry quickly with the multiplier node

Ok you can still use vit-g conditioning with it, you just can't sent the IPAdapter into an unclip that has vit-g conditioning going through it, which makes sense I guess.
But you could just send that same image into Revision and it would basically do the same thing alongside it.
I don't even know what these terms mean tbh
revision, etc
I know what the nodes do, and the models
Revision is the thing where you can provide an image for the conditioning
Wicked. Thanks man.
So I have a workaround for my previous workflow, I just have to decide how I'm going to fit it in. And it's a bit annoying because I have to load both Clip Vision G and H models, which starts to max out my VRAM.
ahh, just never really spend much time looking at the example workflows. maybe I should


@hardy cipher Have you seen a benefit to using the vit-h one at all?
To me it seems to be a little bit worse for a few things, but similar for most. However the thing they mentioned about potentially using less memory doesn't see to happen for me, it uses the same amount of memory as when I use the Clip Vision G ones.

h on the left, g on the right. identical parameters otherwise


Yeah sometimes they are similar, which is fine. Other times, with the model I'm using and with people it seems to go a bit funny sometimes.
But without anything else effecting it, like no lower memory usage, I might just stick to the Vit-G one.


yeah. not sure what the advantage for H is exactly. but I like messing with new things
@eternal fog what does the unCLIP you mentioned do?

It's what's used for Revision. You feed an image into it and it takes that image concepts and uses it for conditioning.
Is that the control net revision that SAI released?
gvd waar is mn vuurtje.

It seems like the vit-h and vit-g ones both go towards different things sometimes.
In this example the input is an image of tracer. vit-g creates a real person and vit-h creates a more 3d model type look (you can get both to do it at different strengths, but this is at the same strength)


Yeah

is there a smaller file for the revision control net? my kaggle breaks above 13 gb ram
Don't believe so


oh yeah what weights and cfg do you recomend for the ip-adapter

Spanks @floral island
Play with the weights, their recommendations were if you are just trying to make something that looks similar to the target image, then use a weight of 1.
If you are trying to make something slightly different and your adding prompts in then use a weight below 0.5.
Weights of 1 sometimes go a bit nutty, so if it looks weird turn it down


I have buid a prompt that improve our prompts âne get Best image that you can use with gpt and bard



@eternal fog using their example:

If your need to express your image it shit.
My 2 cent.
Yeah, I see no overall benefit between the 2, so I might stick with the old one as it works with my workflow better.

Sue me.
do you have a preferred control net
diffusers/sai/other?




Just did some stress test with random images. Not sure i can run it all night.











Noice slmots.




I've not been using it a lot, the T2I Adapters are nice because they don't slow down generation time.



Random question... Do you(Or anybody) happen to have a copy of of Hlkys repo with the 0.3.33 changes referenced here.... https://github.com/FizzleDorf/AIT/commit/33ad2d7b7227338593c95489ac593b04853deff9

{kind=link}







Free.

