#🔧|finetune
1 messages · Page 8 of 1
i see what you mean yeah
You could try it! might work well. I'm not sure
correct me if this is dumb but could i like shorten princess to prncs or something 😭
The longer the instance token the more you have to train
You could. But honestly, I think that's something you worry about later once you get the hang of it 
If you're training on Any3, I'd recommend "hta"
nah, that's fine
ok so
princess tutu is fine for now then?
this isnt serious or anything
i just like learning new stuff so its all just for fun
mmm, if you're learning you could try that, but the next time you try it, try it with "olis" or "sks" or "hta" and you might have better results


instance prompt:
[filewords] or princess tutu, [filewords]
just type [filewords]
no
alright done
now make sure you have selected the model you made
on the leftmost
section

it's better than mine, mine crashed the whole webui!
LMAOOO
WOOO
now u have to wait a bit
only a bit
3060 ti might have low vram
but that processor is mmmmmmmm
enough time to pray to the art gods!
it nom nom iterations
i heard peoples 4090s dying from stable diffusion
thanks to overheating
and having to RMA them
just be careful with the temperatures of your card if you don't already have a hand on it (not literally)
I think you can only db with 8gb by doing like 256x256 but I could be wrong
i have a very well cooled pc!
as long as it doesn't turn int o *has!
yall i think it failed

skill issue on NVIDIA's part
and then had :P
what
My 4090 never seems to go above 65deg. Is that because it only has 3/4 of the power cables plugged in?
yeah 4090 and 3090 have awful heating issues

LMFAOOO
What?
any ideas 💀
plug that 4th one, you arent using it full capacity...
Do i need full capacity? It seems to be like 95% the way there with 75% the power. Looks like good efficiency to me
u dont
dam
i gotta get rtx 4090
but how
am broke
just save for a A100 instead, not that much of a price difference!
Sell your ai pictures on patreon

yeah, didn't you need about 12 gig for training? or did they fix that?
LORA
Time to close every other app on the computer
Firefox uses gpu
fr
true
ok i closed like 5 tabs
i will try again
and it failed again
is it using LORA?
i feel like its not
this should work fine
if nothing else, then I'm sure there's people here who can help make the embedding if you ask them nicely! :D
yeah it does
true true
Embedding? I thought kole was training a model
this is a model
i dont really need a whole model thats just what got suggested to me
💀
What are you trying to train?
@split acorn Found the speed issue. I set the batch size to 1 and now I'm getting over 4it/sec
afaik, it is faster and higher quality
it would take like
2000/4 = 500 seconds to train
i just wanna be able to have SD make a certain character
yeah makes sense
I'd also recommend an embedding if it's just for one character, that way they might use it on all kinds of models :D
thats what i was thinking as well
You can definitely train a character using an embedding, it is somewhat lower quality
But at least you can do it with lower vram
yeah this doesnt seem to be going well
Have you had good luck there? I trained an embedding against the generic 1.5 model and then tried to use it with a custom model and the likeness no longer worked
and you might need to tweak the images, and settings if your results aren't to your liking so better start slow with something simple as an embedding! :)
do i need to start over to do an embedding?
Embeddings only generally work on the model used for training and on models which are 40+% merges. Other than that, the results can be very wrong
works extremely well for me, but as you said, changing the model which creates different stuff will change the likeness as well. Depends on it's too much or too little. And also how. But you can, if you use something like the webui increase the strength a little more with the use of ()
Yeah tried that. Unfortunately it doesn't help much on some of these more complex merges.
I accidentally used one of my anime embeddings in SD 1.5 and it gave me Japanese people with massive bug eyes
you don't need to start over, or rather, it depends on what you mean, but you got all the settings, and the images already so there's not much for you to do if you try again, etc
ok thats good at least LOL
No need for regularization with an embedding
yeah, merges are very finicky, results can be almost anything! But I myself mostly use merges AS the embedding as I'm after a style and not a character when merging. But we're all using it differently.
Thanks, i't a really good idea, but unfortunately, I can't put this kind of expression in automatic1111. I only able to fill the box with one number
ok so where would i go from here then to make an embedding?

I really just want to put a character into some of these really good models
I have no clue what that ui is. Embeddings are available on the train tab of the UI when extensions are disabled
depends on how well know the character is, how much detail and likeness you want. There's also a lot of small things you can try, like having the embedding prompt word later in the prompt sentence, or earlier, or twice, etc :)
LMAO OH YEAH
I'll do some more testing. Thanks!
sorry for being vague, but as I don't know what character you want and in what level of detail, it's the best I can give you :)

Not vague at all. You helped!
you can always play around and test what'll happen, if it works or not. But I fear the vram needs to be at a certain number to even be able to run :/
you must be hallucinating, I never help people. I mostly stumble over things until I either get kicked out, or someone gives me another drink... wait, this isn't the bar. W-Where am I?!
worth giving it a go! any settings i should change here?

(got this btw dw)

don't worry about the settings, try and get it to work first. You can always redo it if it turns out bad. And also ask people for more help. There's no limits... other than the electrical bill, but I never pay my bills so
LMAO
i turned 18 a couple weeks ago
and literally 3 days after i turned 18 my dad started making me pay rent 😭
These are the settings I used:
https://docs.google.com/spreadsheets/d/1rGy5Jb63LdFMfzqN_7Y-X6E5bnsYlqRt7zD61tCcGNs/edit?usp=sharing
ty!
The Prompt Template had a file that just said [filewords] I think?
just going to double check that
@split acorn finetuning on stable tuner doesnt work cause vram lul
guess back to lora
welcome to hell! having to pay your bills, why can't everything be free. And also owned by me? >:(
Im so glad i have amazing parents... Alhamdulillah.
just say you're going to ask your parents for help
what sort of parents...
western society ffs...
wdym?
@split acorn also i did a clever trick with .txt file prompts
yeah it sucks
for my 18th birthday my grandparents gave me $1000 to use for buying a car
and my dads already taken a quarter of it
for rent
...
Just joking that you can ask your parents for help, but as your dad is the one who you need to pay it'll turn around as a weird scene :P
man if i had money i would send over to you
oh yeah 😭
Right, there was a txt file with [name], [filewords] and a text file with just [filewords] that I tested (there might be a better way, but hey, it works)
hey its not too bad 
at least they agreed on not kicking me out
they havent decided what they'll do when i run out of money to pay them tho
so thats worrying 💀
yeah its definitely different
its weird being THIS cautious about spending money
bc im literally this close to being broke bc of my own parents
😭
the best part is, is both my mom and dad are very against "normal" jobs
and would literally shame me if i got a typical job
@stone garden The secret sauce was just to add the embedding name at the front of the prompt as well as around midway and even with the custom model it looks quite a bit like the source images
so this is literally gonna talk days right


if you have it save after X images, then you can always check the quality before continuing, I think. Not sure about that now that I think about it :O
its at 500 😭
ill just check on it tmr and we'll see how it goes
thank you all so much for the help!!
ima head to bed now
currently 2:48 am here

I have 300 carefully editing and captioned images, some are closeups of faces, some are single people, some are 2 people together. I'm training on a 1060 6gb, so it's slow.
Could someone tell me an ideal LR to not overtrain, but to maximize my time?
just put it at 10k, and stop anytime
let it train as much as possible
10k takes about 40 mins with a 3090 (and GA Steps of 1)
Yosh what Taken said
10k should be enough to give you good results
there is no ideal
its like shooting in the darkness
low lr might never find a solution not because it is slow, but because it will move in the wrong direction
too high might overshoot as well, so changing your lr is useless
you need to find the ideal lr to grad to batch -> this is literally throwing rocks and trying to hear if it hits something
takes time
yeppp
certain styles have a "standard" sort of in different models
in 2.1 anime is between 0.1 to 0.0005
realistic is ~ 0.05 to 0.001
has anyone had luck training on the new Waifu Diffusion 1.4 epoch 1? Results so far are really bad 
via dreambooth
I'll try going up to 1800 steps, 600 and 1200 were pretty yikers (nope 1800 is also yikes... will probably wait for the full release in 5 days and then fiddle around trying to make it work after)
Can anyone donate his favorite ti templetes?
oh, so I've been too low
gonna try this now; I'm training realistic... but 200 images takes forever, like, 10 steps on each image will take me hours

I've been liking the [name], [filewords] template personally
i tried that with
filewords, name
name, filewords
name
filewords
this can copy style and the drawing style altogether
but... it doesn't produce high quality
just mid
i didn't try just name, filewords yet
Yeah, I could see that being mid quality
I'm confused
I train one model, then I train another model, but it seems to continue from the last step of the first model (the Lora Model). I don't understand what's going on there

you might have better luck with just [name], [filewords]
I've only done this for anime stuff though
what exactly does Lora Model mean here?
Not sure how well it works with non-anime stuff
Danbooru tags make training via filewords a breeze. Also Shuffle Tags works really well, imo 
yeah, sadly not for 2.1
danbooru tags + 2.1 for training? or
? curious on what comment that's in response to, because I've been struggling with 2.1
mind you, I haven't done too many models yet, but... the old settings that worked really well just... aren't

the danbooru tangs on 2.1 are useless
tags*
@split acorn
you either need to use clip 2.2
or do it by hand, clip 1 works semi well
danbooru like crap
This includes models like WD 1.4 epoch 1 (which was trained on 2.1)?
this is for example using clip 1

dunno, didn't touch wd 1.4 training
2.1 has horrible hands and eyes
look at this pic for example above -->> there are no hands, and the eyes are red
even though the entire embedding is B&W or yellow tint
yeahhhh, my Clip 1 results are horrible too
eyes in anime usually went above the 0.995 filter --> meaning that eyes are suxual and weren't included in the model
So I should be training using like Clip 2? and then change the settings to Clip 2 when using it?
for better results or
do 8 to 20 words, and use the

filter out bad words and such
its really easy, you can even filter in the entire dataset or replace words or certain tags
usefull as hell, i removed "a drawing of" and "a pencil drawing of" into nothing
basically erasing it all in 1 click
yeah clip 2 is better, but no versions can run locally yet
everyone gets errors
Run 2.1 models via Clip 2 without getting errors?
lots of people tried to make it work, but it just wont cooperate
you can use the collab for clip 2, but 30 secs per image
sometimes a full minute
it runs, just going to double check that it's doing something
wait what? did you manage to make clip 2 run locally?
ooo the results are better but still kinda poor
I probably overtrained it a lot
going to try a diff model
OHH
I think I know what's happening
Training dreambooth on 2.1 results in models with the same infistructure of 1.5, because it doesn't create a yaml?
oh it does make a yaml
mmm
will post example pictures in a sec
Really poor quality though
but like, it still works
I didn't train it via clip skip 2 though
Oh that's not the same seed
one sec, deleting and trying again
Clip Skip 1:

Clip Skip 2:

super poor quality but no error message
and a little bit of a difference
but huge though
clip skip 1 being better
I'm doing something wrong though. I think the settings definitely need to be different
Clip skip in 2.1 doesnt do anything
It did do something, but I'd agree that it looks broken
or at least it's not working as intended
Because it touches floats but it just means that the floats round up to a different close number
ahhh
So basically it doesnt do anything
that would explain the subtle difference
Say thqnks to sinister for explaining that

Dont ignore it, 2.1 gives off much higher quality results
I could try with the base 2.1 model 
2.1 base is gonna give you different results
That's what I'm looking for, different results, because the WD 1.4 epoch 1 results were super bad 
(2.1 would use different prompting and would need me to redo my filewords, so I'll save that for a future project)
Usually youd wait for 2k 1k steps on 1 grad or
10 grad for 100 steps on 2.1
Epoch 1 almost always will be useless, also you can accelerate your training by using good "Init words"
When you are creating the embedding
Good init is ~1 to 3 words
Hello! I have the same error
Don't do it in dreambooth
Do it in the training menu
Is there any instruction?
Im only training for my first time so I probably shouldn't give advice haha
OMG
it worked!
i was able to train on a 3060 ti!!
also, fyi it should be only "princess tutu, [filewords]"

yay
but hey im happy it worked
do you have to restart webui for it to load the new embeddings?
nah
just type the name of the embedding and it should auto activate. For the "-18000", "-17000" you'll need to click and drag them to your "embeddings" folder
Example:
E:\Programs\AI\Auto1111\stable-diffusion-webui\embeddings
now just type the name of the pt to test it out
for example "princess_tutu-18000"
or just "princess_tutu" for the default
how to use it?
mmm one sec, I'll give you an example
ive used embeddings before
im not sure why its not working
ive got it in the prompt and stuff

i tried a few prompts
and the name of the embedding in the embedding folder is "princess_tutu"?


can someone just give me an example how to?
do you have a screen shot of this area?


something for noobs
Oh so it's working, it's just working poorly / bad?
Also just use princess tutu, [filewords] next time for your instance prompt. The instance prompt you used is super wrong
https://youtu.be/HahKXY7AQ8c
It worked for me, but the interface has updated and I don't understand where to click now

Dreambooth local training has finally been implemented into Automatic 1111's Stable Diffusion repository, meaning that you can now use this amazing Google’s AI technology to train a stable diffusion model with your own images. You can train a character, an object, a style, or anything you want! There is also a new option that allows you to use D...
oh ok ty 😭
what is this?
downgrading?
idk
im not sure what youre asking
hi all!
I really need expert advice about few questions.
Trained casual artstyle for icons of in-game resources.
Used dreamboot from Thelastben and model 2.1 768
The dataset consisted of 100 images. Iterated the training several times. As a result, it turned out about 30k steps
The result is disappointing, with many images having severely distorted proportions. Also, the model practically stopped responding to the CFG scale values...
Who has already encountered training 2.1, what is the optimal UNet_Training_Steps and UNet_Learning_Rate for a dataset of 200 images?
What learning rates have you tried?
it was 2e-6 learning rate
Hi all. Happy new year!! May I ask whether there is some fine-tuning examples for stable diffusion, especially for inpainting model?
is there any other google colab for textual inversion training? I found only this: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb but I don't like it because you can't stop and change learning rate when you're training

Did anyone have any semblance of success training a Textual Inversion with Anything V3 through Automatic Web UI? Because so far it’s failing really badly for me.
I trained my own model, but it doesnt really follow prompts, seems to just churn out random images in the style of the instance images I used to train it
any idea what could be wrong?
Hello, I found a Ti colab for lower GPU user. But i dont know why I got error: RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu) The output can be seen in txt file and
The colab is here: https://colab.research.google.com/drive/11Z1k5rb_Rx-gHQBZA0A40je_tg00nsX8?usp=sharing
This one is for Textual Inversion
is there a useful guide somewhere to explain a little better how to decide how to configure ti/hypernetwork training? using automatic1111 there are a lot of options such as reversing images, deepbooru for anime tags vs BLIP interrogator (or both) for automatic image tagging, what prompt templates are recommended - the guides I've found have been very light on detail. Since training takes 8+ hours it takes a long time to conduct experiments.
Collected 9K images for my diffusion project
gotta collect 18K more
mmm


What do you train on?
What are your settings if ok to ask
I'm a newb I'm terrible person to ask for good advice. But webui embed in this case.
5950x/3090
In terms of introducing many unique subjects with few shared classifications, I've had much more success with dreambooth.
I am stuck between DB and finetuning so idk lol
some say its same but programs like StableTuner differentiates it
They only differentiate it to make life easier
DB for training on a token and Finetuning training on captions
They don't need the same settings, so it just disables the settings it doesn't need
whats the difference between tokens and captions
Have been having good luck with 2.1 training on TI and Hypernetworks but I think I'm doing something wrong with Dreambooth 2.1
Token is just the instance token. People use a rare token like "sks". Captions just means the filewords, the words that describe the picture
so you train on those words
is how I understand it
In 1.4, i used the same steps count and samples for embed vs. hypernetwork vs. dreambooth. For my scenario, embed and hypernetwork were similar, and dreambooth was exceptional. ~1000 artistically drawn pokemon with species and types. My measure of success generally was applying typing to different species. "dragontype eevee" for example. an attempt was made at "gmax style."

"dugtrio GMAX"

Too much pictures, the ai just goes haywire, better split them into styles
For example: bi pedal, quad pedal, wtf this isn't legs pedal etc...
@little hollow Wait, so more pictures aren't always good? I am probably going to train a sci fi diffusion soon, with a dataset im collecting which has over 26K images
Well, sci fi is a really broad topic so i think its fine?
I think the issue @little hollow is pointing out is with the singular uniqueness of the samples and names.
For my case, I separate them into "styles" by identifying the types (firetype, poisontype), so the result is a dozen or so styles with 60-90 samples respectfully.
i see
i first write a script so it makes a textfile with the filename and the filename written in it, then i append the clip interrogation prompt to the txt file
or vice versa
BLIP + manual species/type data works well for me. "a cartoon character holding a stuffed animal in its arms and smiling at the camera with a smile on its face, Slowbro, WaterType, PsychicType"

yeah for 10 images manual is ok for 30k it isnt lul
well, let me rephrase -- I have a spreadsheet of numbered subjects and attributes (style, type, gender, region, etc) that I use to script into a string. I append that string to the BLIP. By "manual" I mean not BLIP.
You could use all sorts of things for training pokemon, like dex entries, or the dex species name, or maybe even base stats and abilities
ikik
Then you can submit the results to the CAP project
that's what i do; sticking with based attributes such as type right now.
Hello,
How are people doing Textual Inversion on Apple Silicon since it appears to not be working on latest version of InvokeAi?
I have tried several google colabs including the official hugginface one, and can't get it to work?
results for 2d have been really positive. able to merge species and cross-type species. ok maybe "really positive" isn't the right word, but it's .. within expectations.

results for 3d ... well,

If you give the dataset pictures with nothing in common to make something
It will take the only thing it has in common between them
In this case, white background and a basic shape


what is the CAP project?

Create-A-Pokemon run by smogon
I got it to be consistently 5 fingers, except its literal nightmare fuel

even the off fingers look decent
@white current
Try to place them by a certain category, the more round ones
The more square ones or something
Anything you can think off, and if something has nothing in common with the rest - to the bin with you
any clue what caused this nightmare fuel with my training? I used a dataset of 11k hands
1e-6, 14,000 steps
-mixed_precision=fp16
--train_batch_size=1
--resolution=512
--gradient_accumulation_steps=1
--use_8bit_adam
--train_text_encoder
I did this twice
@white current #1045349359044280360 message
Look at this example of how learning works for embeddings at least, the chat between me and sinister, he gave out a long explanation, it lasted ~1 hours so ~ 60 70 chat logs down
Some visual explanation from his as well, it really helped me to understand on how to filter
From 400 pics i went to 30, and those 30 gave out 10x as much effect than the 400 could
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 93: invalid continuation byte
Argh. Turns out I was converting the txt files to utf-16 during processing.
Headsup. They need to stay utf-8 apparently. heh
how does the text encoder learn new ideas?
if I give it an image with something it's never seen before, and a description, how does it understand what in the image the new thing is?
Are you asking at a technical level or a procedural one? There are a lot of resources for the procedures, while the technical is mathematical voodoo for me.
I want to understand theoretically how it thinks, so I can make the right decisions when I curate / edit training data
https://github.com/chavinlo/distributed-diffusion Idk is this what I am hoping for? Training SD over peers like Stable Horde?

GitHub
Train a Stable Diffusion model over the internet with Hivemind - GitHub - chavinlo/distributed-diffusion: Train a Stable Diffusion model over the internet with Hivemind
I wouldn't use that, unless you want your name on some list
How many epochs would you recommend for a 60k image dataset on everydream?
Hi all!
I have read several guides on training a model in a dreambooth. Everywhere it is written that file names must have a unique identifier. However, the examples in such cases are usually about learning based on one subject.
I am having trouble figuring out the correct approach to naming image files in a dataset if I need to train a model on an artstyle rather than a specific subject.
I am asking for help with the file naming approach if I am training a model based on different subjects that are similar in style.
- Should I give descriptive names to the image files in the dataset?
- Should I give the files a unique text identifier and include a description of the image in a separate text file?
PS: When training a model based on approach 1.5, I gave the file names a descriptive name by separating the words with spaces. The results were good. However, on version 2, the results deteriorated sharply
Anyone know if adding mirrored images to the data set help with training? If so, do i need to add to the description that the image is mirrored, or should i just name the file as SubjectA Mirror (#).ext ?
if the point of your embedding is the subject like a person - then no its a bad idea, but for a pose and such, concept why not
so those guides that have mirrored data sets for their photos of a person were not good? generally they tend to say have x amount of images then mirror it for x2 images in the data.
imagine someones face with a freckles on the left side, only the left side(from the perspective of someone looking at the person)
and the person having one arm only, lets say his right
you flip the pictures, now what do you have? - sometimes a person with freckles on the left, sometimes on the right, a hand on the right, sometimes on the left
ahh ok, so it must be a person with sometimes L/R freckles, and sometimes L/R hand
4 different variants arise
or worse -it might make the face fully symetrical
what im saying is correct for 2.1 yeah?, not so sure about 1.4/5
should be quite simmilar
oh i see, my thoughts are if you specify that it is mirrored then the AI might take that into account.
just take 4 pics and put a mirror
i think that 20 epochs are enough?
then try to see how well it performs
right, in order for me to test that was why i opened the original question. If i am to specify it is mirrored, would it be done in the text description or the file name?
filename
alright, cool.
the templete might give the regular one the word mirrored sometimes
yo, if anyone thinks im wrong tell me, id be glad to learn something new
i'll give it a shot after i set up the data. the main reason is indeed because the data has asymmetrical aspects and i sometimes notice the AI doesn't see it as asymmetrical.
Hey is anyone using runpod for stable diffusion 2-1? I can't seem to get dreambooth working on it
There should be some tutorials on that
I've watched the tutorials I've found, the dreambooth tab just doesn't show up for me. The tutorials for the Joe Penna notebook don't work for 2-1
Hm weird
For sample descriptions (filewords/captions), is it problematic to have superfluous language and punctuation? For example:
a squat, quadrupedal amphibian with bumpy, blue-green skin. It has small, circular red eyes and a short, blunt snout. Its mouth is wide with two pointed teeth in the upper jaw and four in the lower jaw. On top of its head are small, pointed ears with reddish pink insides. It has three clawed toes on each foot.
Not because I like to write verbose descriptions, but because there are some well-written descriptive language that I can reference, and ideally programmatically.
It is currently not working
Even if you get those juicy yaml files, the training sucks as of now
It just doesnt train well on that model, there may be a way to do it, but I have yet to see someone do it successfully

I'm assuming you're all using dreambooth
this runs all the way but the final model is the exact same as the initial
The only weird thing is how it's "only" using 9gb of ram
I don't think it's training at all
i can change the learning rate to 1 and nothing changes
where does that come from?
dreambooth notebook
If i try on colab, same exact settings
it does work
decently well actually

it's the default dog whatever
if i try it locally however it doesnt work
im on a 3080
is there a different way of doing it?
i think the problem might be xformers
mmm, you might have better luck with this one:
https://github.com/d8ahazard/sd_dreambooth_extension
or using the colab
There's also this, which is pretty easy, as well:
https://github.com/devilismyfriend/StableTuner
lovely thanks
Hi there! I know how to train for faces and I know how to train for styles... but how would I do that for specific body parts like a hair-style? 🤔
what kind of model you working with?
I stick more with the v1.4 and 1.5 Versions 🙂
so from my understanding after trying to train a character with a specific hair style, you would need samples of the data set that has many people with the same hair style. you can probably make this yourself using img2img and inpainting.
after you have enough data for it just set it up with the right descriptions and it should be able to train it.
Ok, I try with inpainting, thank you 🙈
good luck. lol i spent the last few days stuck with my training only to find out the build i was using was bugged.
I am about to xform so hard
I'm trying to train a textual inversion embedding for sd 2.1, but I keep getting the error Sizes of tensors must match except in dimension 0. Expected size 1024 but got size 768 for tensor number 1 in the list. Does anyone know what I'm doing wrong based on that error?

Just the settings I use on StableTuner to train on a 12GB 3060 card. I also set sampling to more than the total number of steps to avoid any samples, I do sample epochs and save the epoch though.

If you don't train the text encoder you can set the batch size higher, I've used 4 successfully but I've heard people using higher numbers.
Train epochs can be set to as high as you want.
As each epoch is the total number of images seen once (each step=one image) it can take quite a while on a 3060 card, I usually set it to 5-20 epochs, but depending on your needs you might want to set it higher. I've got some pretty good results with 10 epochs and more.
That guy on yt was supposed to share a notebook for Linux users.. i couldn't find any.. do u have hold of it to run on runpod or colab ?
no idea why i cant run this on 8GB

are there any settings or something i messed up?
keep getting this

That’s only half the error
anyone get dreamartist to work for training? i can't seem to get it to work and would like to experiment with it a little to see how it stacks up with other tuning methods.
I run it natively on windows, can't help you with Linux.
Oh no prob bro.. cheers
Any tips for textual inversion with a photograph style?
There’s a lot of discussion about it on the extension github page, with different people getting different results. I’d also be happy to learn the right way to do it, so lmk if you figure it out
https://github.com/7eu7d7/DreamArtist-sd-webui-extension/issues/18

GitHub
Hey guys, I am just wondering if anyone has successfully replicated the 1 image embedding and recreated similar results from 7eu7d7? Right now I have no luck testing it myself. Training time for th...
you get a notebook when you do a cloud export
@prisma nacelle I'm wondering how can we train a new model with faces? What repository or guide can I use to extend the base SD model? Any quick ideas will be helpful
Oh, I thought this is for faces. If I want to train a new model using 100s of hand images so that SD can generate good pictures of people with good fingers/hands, is dreambooth useful in that case? or any other ways we can approach this?
Dreambooth and Textual Inversion should both work for this 🙂
Great, is there any other training methods generally available to extend the SD model?
just trying to learn all these tech behind the fine-tuning and training
I also know this thing: https://github.com/victorchall/EveryDream
And aesthetic embedding, but the last one seems more to be for style.

GitHub
Advanced fine tuning tools for vision models. Contribute to victorchall/EveryDream development by creating an account on GitHub.
oh yeah, I've heard about it. I thought it was using a dreambooth way. But looks like it's a different one. It's helpful.
I'm planning to start with dreambooth first, in that case
Regularization images: `a photo of hand` - generated with inference
Class: `hand`
Instance token: sks_hand
After training, the prompt can be like → a photo of man saying hi, sks_hand
Is my approach is right? any feedback?
Seems rights to me, Feedback: the sks thing is a random example term, you can use something own if you like^^
for sure, thank you so much for your answers 👍 🙏
It's really helpful and I'll also explore Everydream
for shiro dreambooth, the instance token is the instance_data_dir right ?
i mean it rely on the directory name ?

thanks, so for the shivaro db the only triggers is from the directory name or the whole instance prompt ?
what the folder name is doesn't matter, its just the path to where you want to store your training images
yeah, i just want to know what is the instance "trigger" on shivaro db x)
since there is no specific field for it
the prompts decide that
i see thanks
Hello, anybody knows of a tutorial or document going through all the settings in Dreambooth A1111 webui?

DreamBooth for Automatic 1111 is very easy to install with this guide. With DreamBooth for Automatic 1111 you can train yourself or any other subject. Use your own trained Model to create images in your styles or of yourself. The DreamBooth training in for Automatic 1111 takes only around 30-40 minutes with a good GPU.
LINKS From Video ##...
There is some information missing, but it's a really good start!
For best results, generally your dataset should be with different backgrounds, clothing, lighting, expression and different camera distance/angles. In the video they used an unideal dataset, but the rest is pretty good!
Thank you Alicat! I have followed it, its pretty good. Having issues training an object (a car), I did it once and it came out pretty good, now Im trying it again with a variation and not working so well. Not sure what went wrong...
just had a little disucssion in #🌶|off-topic where someone asked "how many images do you need for finetuning" .. answers varied from 10-1000s ("2.1 can't be tuned on 10 with good results" "not dreambooth"...) whats the situation , i'd basically heard "fine tuning is possible with a few dozen", but aparently more can also help increase accuracy for a model narrowed for a more specific domain?
I don't think there's an answer to that. It all depends on what you're trying to do and what you have available
How many images for training can vary from 1 to 1000s yeah
(haven't started on finetuning myself , I need a new PSU for a bigger GPU first.. but basically I'm interseted in generating game art - textures, background wraps - and I have some hacks in mind to try and project onto scenery from keypoints - anyway a fine-tune on sci-fi film stills could help out I guess.. I wouldn't want it to replicate specific copyrighted things but just be better at making 'generic futuristic buildings' etc)
Here's a good guide for styles:
https://github.com/nitrosocke/dreambooth-training-guide
GitHub
Contribute to nitrosocke/dreambooth-training-guide development by creating an account on GitHub.
a bit outdated, but the information is still relevant
Thank you, this is quite helpful 👍🏻
is there a way to resume a textual inversion with this google colab notebook? https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
Hi, im pretty new to this, but have been playing around with embeddings. I want to copy the style of art from the rules book of the RPG my group is playing. So I trained it on 50 character images like the one on the left for 100,000 steps and its produces... the right. Any idea how I train it to understand what this art style is like, or even just what a human face is? Using the embedding leads to all pictures turning into monstrosities like the one on the right. *Not sure if this is the right place as this is an embedding not a model, but I didn't see an embedding fine tune channel. *

I'm in pretty much the same boat as @prime perch, I've trained 8 different embeddings trying to generate images with my likeness, but I get results like this (second). This is trained with 18 images similar to the first image, trained with the colab notebook that @honest nexus posted a few messages ago. Any thoughts? Image gen info: 22 steps Euler a on protogenDragon. I've tried with the default SD1.5 model, but the results are even less coherent. (at least it gets my hair right though, ha)


try another model, sd is pretty bad for textual inversion. I suggest you elldreth vivid mix
Ok will do! Is there a convenient way to find that model? Google leads me to a reddit post with this model
https://civitai.com/models/1259/elldreths-og-4060-mix

This mixed model is a combination of my all-time favorites. A genuine simple mix of a very popular anime model and the powerful and Zeipher's fantastic f222.What's it good at?Realistic portraitsStylized charactersLandscapesFantasySci-FiAnimeHorrorIt's an all-around easy-to-prompt general purpose semi-realistic to realistic model that cranks out ...
Just search for Elldreth on that site. its there. Not getting much better results from it myself sadly.
Anyone used dreambooth to make a LORA? wondering how to use the .pt file it generates in models/LORA in A111, the additional networks extension won't load those
i'm working with elldreth vivid mix and works pretty fine with textual inversion
I still think the best way to train textual inversion is from automatic1111, lowering the learning rate every 300 steps
oi, ACCELERATE implemented into a1111?
i saw a few results from training using it, they were freaking top notch
even replicating everything that he did gave me about idk a third of his quality?
how to activate this accelerate
its in one of the diffusors, im not quite sure what it is
or how it works, i know that it does work in DB or was it HN?
i trained myself with 20 images in SD 2.1 and turned out very good, the most important thing is the dataset
Can we train SD on 32x32 and 7x1 images for example?
thanks for the info, thats encouraging
Is there a good low vram (sub 10gb) version of dreambooth out there currently?
new au1111 has Gradient Clipping --modes: norm/value
default is 0.1 - any ideas what it is and what it does? seems like a cool new option but figuring it out is gonna take way too long alone
Currently using this, preliminary results are looking good at 850 steps at LR .005:300,.001:500,.0005
do you use google colab notebook or automatic1111?
Auto1111, I couldn't quickly figure out how to get the model into the colab notebook you sent so I just went local
Here are the results at about 1050 steps, still takes some coaxing to get right. Might be some trouble with my dataset with multiple people, but this is pretty good!
First is generated, second is reference


add some negatives
and this will be awesome
pos is: photo_of_benclements_mod6_man_close_up_alone_sharp_focus
maybe negative is: lowres, low_resolution, bad_light, bad_shadows
Thanks! I appreciate the help!
I'm away from my computer right now 🥲 I will keep the channel updated though. Also fwiw, this is on a 6gb card, so this embedding stuff can be accessible to more people than training a whole dreambooth model!
i've tried to train with my 1060 but cuda goes out of memory
Interesting. I believe that's the same card I have. Have you tried smaller image sizes? --medvram? --xformers? I'm using those args and I'm able to train on 512x512 images
yep, 512x512 and xformers, but never tried --medvram
I'm not sure if it helps in training, but it certainly allows larger image generation for me
@honest nexus I also used the modifications in this reddit post. Give it a shot and see if you can get it to work
https://www.reddit.com/r/StableDiffusion/comments/yibx9b/successful_hypernetwork_training_on_a_6gb_vcard/?utm_source=share&utm_medium=android_app&utm_name=androidcss&utm_term=1&utm_content=share_button

reddit
51 votes and 44 comments so far on Reddit
Can anyone point me in the right direction? I'm trying to follow Aitrepreneur's instructions to create a textual inversion embedding in runpod using the Auto1111 UI and keep on getting a {} error when trying to preprocess images.
https://www.youtube.com/watch?v=4E459tlwquU&t=659s

Read the terminal
Nothing's happening in the terminal when I create the embedding and try to preprocess the images...

hi, so i dreambooth trained using the colab for 2k steps, is it possible to go for more steps without having to start over?
results feel a little undertrained
you can start with your previous created diffuser model
instead of starting from 1.5 or whatever your base is
anyone know why the TI templates have so many lines in them? like... painting of [name], rendering of [name], etc... what's the point of all this
im not sure how these templates are even used I guess
are they using them to create... potential images of your [name] while training... but then how does the algorithm determine if the resulting image is "good" or not... like... what's driving the loss function of the optimizatino routine
with each step of the training process... how does SD figure out if it's going in the right direction or not...
I had thought that it was using back propagation on your set of training images... using the captions that you write for each one as input and the actual photo as the correct answer
but in that case, what's the point of the TI templates
are they just there so that you produce a variety of different images for like... qualitative evaluation while the thing is running? but they serve no purpose in the actual training process ?
Is it possible to train embeddings using the google colab notebook?
Yes, but for high quality results of a person's likeness you will need to use a model other than SD 1.5, I posted a result a couple messages back with my results from that colab notebook and the results were subpar. I haven't done much looking into it but you need to figure out how to import a model other than SD 1.5. another user recommended me eldreths vivid model, and it's worked really well in my local installation, so I would recommend that.
You can upload the custom model to your google drive and just copy and paste the path “ckpt path” or just insert the huggingface ckpt link.
But this is for training models. For some reason I can’t train embeddings using google colab. I’ve tried several times. I can’t find any resources on that either
Can you link the colab notebook you're using? This is the one I used
https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
I tried it a week or two back on this one
I would go into the gradio app link and to the train tab but when I started the preprocessing it would keep giving me errors
Oh wow. I had no idea there was a separate notebook for training embeddings. Thankyou so much bro. I’m gonna try this today. Really appreciate all the help
Yes, ok, so there is a difference between that and textual inversion embeddings. What you linked is for training a dreambooth model, which as you stated, creates a whole new 2GB .ckpt model on whoever you provide it pictures of. This works really well, but ckpt files are large and you can only use one at a time, but TI embeddings are harder to train it seems, but you can use them on top of nearly any model, so long as the version matches
No prob! I only found that a day or so thanks to another user. Again, you'll likely have to figure out how to import a different model into that notebook bc the default 1.5 model is not that great at it.
Ohh. I will definitely let you know if I figure that out
Please do! That notebook is in theory 4x faster than my PC, so viable results with that would be huge!
@tidal cliff
The templates are used to give the embedding some 'context' to what you're training. The template file provided probably isn't suitable for plug and play into most trainings. I created a custom template file named 'custom_subject.txt' that only contains "a photo of [name], [filewords]". This is sufficient for training on a likeness of a person, in fact, for my own likeness, I created a template file that only contained "a photo of [name], a close up photo of a young man" to some pretty good results. The [filewords] is a caption that describes the image. This is useful because without it, the embedding will pick up on things in your training images. Say for example you have a lot of pictures of you in a black shirt with trees in the background, then the generations of your trained embedding will favor you in a black shirt and trees in the background, so by letting the network know what is NOT you in the image, the embedding becomes more versatile. I hope that makes sense?
https://www.reddit.com/r/StableDiffusion/comments/zqlhwn/is_it_possible_to_train_an_embedding_using/
I also just found out this link as I was asking you. Might want to give this a try as well
reddit
2 votes and 3 comments so far on Reddit
I've seen this error before actually. You have to find the line
logvar_t = self.logvar[t].to(self.device)
and change it to
logvar_t = self.logvar[t.cpu()].to(self.device)
Oh. Thankyou so much for all the help. I’m going to try this all. Hopefully I can start making the embeddings I want to 🤞
No prob! I never thought I really knew much about this stuff but we close to the frontier here, so experiment away!
Since LORA's been around for a bit, is there a general opinion on its usefulness? I know it's a smaller file, so ignoring that, does it have any particular weaknesses/strengths? I assume it's somewhere between TI and Hypernetwork?
it's like dreambooth lite
can train with less VRAM and the added bonus of smaller file sizes
there's also a convenient webui extension that lets you try it out with various models and lets you adjust the strength too
With first impressions, I prefer TI and Dreambooth to LoRA, but I'm still pretty new to it
Uhh. What’s inversion training?
Anyone want to test (for free) a dreambooth service focused on video game characters? I mostly am looking for feedback on whether you like the results. Link is https://polymorf.me/ . Send me a DM and I'll send you a custom test link. We use a combination of diffusers + dreambooth + some Textual inversion + some img2img depending on character
my lora test run

(very small part of a 2k image tank dataset)
Can someone explain me something
can i actually train stable diffusion on 1024x1024 images by selecting resolution = 1024?
or if i do that does it just downsample my input to 512x anyways?
you can in theory, but if you dont have 80gb vram or sth, you cant
can anyone offer advice on why a hypernetwork seems to have no effect?
I got good results during training but it doesn't seem to affect the image gen
So I've been succesfully training Embeds with my 3070ti 8gb, but when I increase the batch size over 1, I get a CUDA out of memory error - I've seen people succesfully train on 8gb with batch sizes of 4-6 before, any ideas why this is happening? I'm launching with --xformers --opt-split-attention --medvram
I've never had much success with hyper networks, but if you're in auto1111, have you made sure it's mounted in your settings? Much like you have to select an SD model, you need to select a hyper network. I trained one once and it did change image generation for sure, but not in an effective way
thanks for your help, I did have to figure out that stuff but I think I did get it working
I think in easy sd the setting takes time to turn on and off, in automatic1111 it does seem to work when you enable and reset the ui
doing smash bros it's not easy
I'm having some success, need to do a lot more description and having more reference images will make it better but I'm already 500 img in smh
went from the machine having no idea who mr game and watch is to having a pretty good idea, 8 hour training tho rip
most people just trying to put in one face I wish it was that easy for me
Rip yeah. Local training is slow for me as well, I got embed training working on my 6gig card, but takes time. Can hyper networks do multiple subjects like that? I didn't know that was possible, if so, cool!
yes
like I said most tutorials or examples is 1 face
so I wasn't sure if it would be ok with 89 subjects + their sidekicks and cohords
cohorts
and with some settings it does reach what I call the singularity where all the characters are mashed up but
my last training went like this
oh I can't post pic
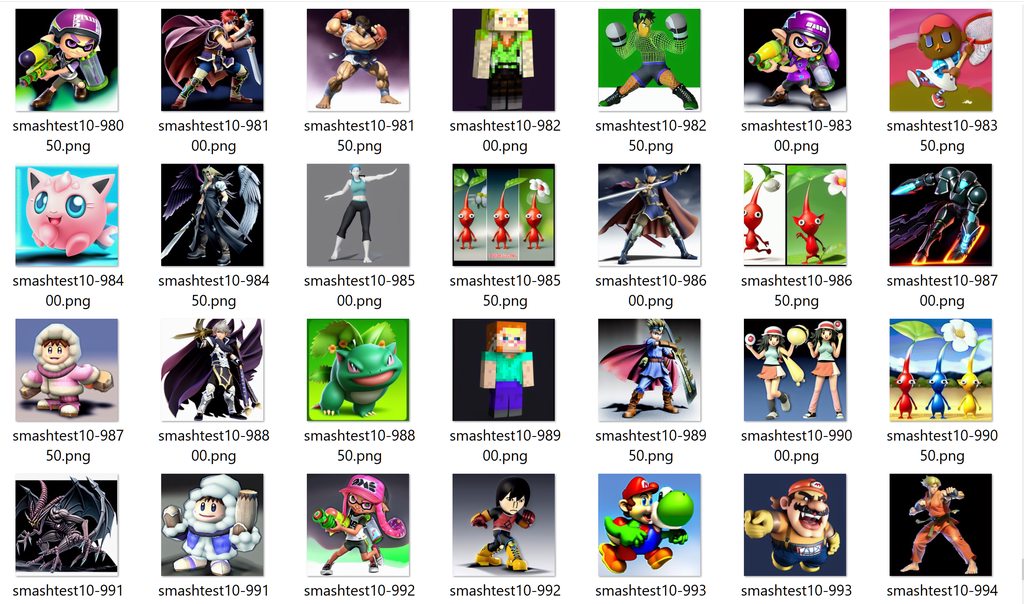
imo
smarter than some of the irl people I've tried to explain smash bros to
it def has a hard time looking at 2 subjects in 1 pic that it doesn't know
so I'm having to break down like banjo and kazooie etc
the koopalings are a nightmare for it but I am helping
Interesting! I'd like to see how you make out with this!
the training in most of the models for mario series subjects is just wack af and is hindering the process but we'll get there
if nintendo doesn't find out
don't tell em
Safe with me 🤐
I had to do it cause it's like 98% anime girls and I'm like yo show me yoshi
and it's like some japanese guy
I cannot stand for this
I'm concerned about weights
like, for example the pikmin people there's 2 dudes and 5 pikmin and so I have multiple shots of the pikmin cause there's 5 colors of each and 3 stages of growth
it's rough being me
so like, is olimar and the pikmin gonna weigh more than say cloud who the machine already knows or mr game and watch who it's clueless about
we'll find out I guess
So long as they're labelled correctly in your dataset though that shouldn't be too huge right? Also with such a large and varied dataset I would set the LR really low
uh
I'm new
what's lr
oh I got another question too
so
can I use this .pt in conjunction with deepdanbooru so I can stop labeling the shit at some point?
like can I feed my smash dataset another dataset of smash images and have it point out who's in the img once it knows
learning rate, by default it's set to .005, in my recent experience with embeddings, .005 becomes too fast around 800 steps or so, so I went down to .001 and then .0005
I'm running .0000001
But it might be something you play with. If you end up with generations that look beyond screwed up then your LR is too high
I'm not overly familiar with LR for hyper networks, so I don't know if that's lower high but that's definitely one of the knobs to turn as you start to refine your process
tbh around 30 or 40k it has it mostly figured
but like subjects that are really similar it doesn't have it figured by 100k
duck hunt is hard cause of the name
there's 2 roys
it's rough stuff
I think it's a worthy endevour I hope at least, but I'm worried when I release it nintendo gonna shut the whole sd project down haha
thanks for your reply re: the template file. How many vector per token have you used to get good results on a person trained on photos? Also, how many epochs did you let it run at 0.001 and 0.0005? I find it's hard to get a sense if the model learning too fast or too slowly
8:00 to 10:00 seems to be good for getting someone's likeness. As far as learning rate, you know it's gone too fast when you generate something with it and it looks otherworldly and not even close to sensible. When an embedding is undertrained The output images will look reasonable and you can tell it's starting to get the idea of what your subject is, but it's not quite there yet. The case of a learning rate that is too high is worse than too low. A good schedule that I found is this: .005:700,.001:1000,.0005:2000,.0001
This is for batch size 1 and grediant accumulation 1. That schedule would change if those values were to increase, but I can't increase them because of VRAM
I haven't verified this, but I hypothesize that if you're training a style instead of a person, you can set the learning rate a bit higher and train for less steps
Hey bro thankyou for all your help. I’ve been able to make the embedding successfully. Also, in the link I shared you can add any model you want to by pasting the hugging face download link in. The embedding will be trained through that model
No problem!! Can you post results? If love to see what that notebook made
Yes ofcourse. I’m in the middle of training another embedding right now. As soon as I’m done with it I’ll post the results
Hey, can anyone give me some sugestions at finetuning since i'm a newbie?, I have about 350 images instance images and 550 concept images, all images are high quality and 1024x1024, but it seems like I'm getting A LOT of failed ckpts, any advice? (im trying to fine tune on dreambooth colab)
Folks, What's the difference between diffusers and ckpt model types? I'm getting good results when dreambooth training using joepenna repo with ckpt file compare to the diffuser repo.
when using dreambooth less is more, i havent trained a style but 350 images seem too much
alright, thanks a lot for the advice, I'm currently trying again with 100 images, all captioned and for about 1000 steps (10x the number of instance images), what about concept images, any advice? does the rule of less is more also apply? thank you
Has anyone here trained LORA? According to this guide, you can train many concepts at once, but you're not supposed to use the character name or series name, so that it would "become implicit to other tags". This is really confusing to me, because I want to add a cartoon series that has various characters in it. How would it know the difference between the style and a character? How am I to differentiate between characters?
For instance, for X-Men, on a given image, I want to be able to make Gambit hang out with Jubilee, or Storm with Wolverine, or Gambit with Storm. Maybe I just one one of the characters to hold a cat. If I can't use any character names, how would it implicitly know which setup I want when generating images?

/hdg/ Logo Imgur (3 Sizes)
Written by StyleAnon with some help from a few others and the Thread!
Links to other Collaboration Edition Guides/Resources
PromptAssist | LoRA Repo
LoRA Training Guide
What is a LoRA?
For Using
For Training
Diffing two models
Captions
Saving and resuming training
Instr...
Because you're training on an instance token
The instance token is the replacement for the "character name" or "series" basically
Got it. You are still giving each concept a name, but not the original one
yeah, using a rare token to help it with the learning process
You can do it another way though
I'll find the video
ohh thank you.
I'll find the time stamp
but basically they trained on something the original model already knew how to make
Which is another valid way to do it
though, I'm not sure if it's better or worse

I fooled my friends and family with photorealistic images I created using StableDiffusion and then posted to all my social media. I go into how I made these photoreal pictures and also my descent into madness.
Wanna see for yourself?
instagram.com/kylevorbach
twitter.com/kylevorbach
I'll be sharing my AI pictures that didn't make the cut and ...
Ah I watched several videos, but not this one. Thank you. I'll investigate.
regarding what you were saying before, each character has to be a pre-existing token, right? I can't just do "xmenGambit" "xmenStorm", etc..?
I've seen models use phrases like that before.
But maybe not LORA tunings...
mmm
Generate images with those tokens and if they look good, then it should work (to some extent)
mmm let me reword it
if it doesn't exist, then you're better off using a rare token
So if "Xmen Gambit" doesn't consistently produce good quality Gambit pictures, then you're better off with like "olis" or another rare token
"Gambit" gives a gentle unsure whiff of the original character. So that would be a good candidate to train?
I honestly don't know, but my gut feeling is no.
Rare tokens, so it's completely random.
Or well known tokens, so you have high quality token you can train off of
I'm not aware of anyone doing anything different though, it'd be cool to see
ah, all or nothing. Hmm
Thank you very much. I mainly wanted to know if LORA worked best with a fundamentally different approach (and it sounds like it doesn't). I'll experiment and figure something out.
anybody else getting error when loading 2.x model with automatic1111? I''ve tried to get it working 4 times now and I kinda dono what to do anymore.
the yaml is in there renamed and auto1111 is updated
it just gets killed without an error and sais error in the ui
someone have an example of captionned image for scenes please ?
Any clue what might be causing problems with lora dreambooth, whilst training the 512 version of SD 2.1?
768 seems to be developing normally, but 512 immidietly turns into an abstract mess.
I've had poor luck with it too, not sure why
It's so weird, I swear
Yeah ti seemed to work fine for me as well
Dreambooth becomes literal black magic to the 512 base. Tried almost everything at this point. Nonema, 8bit, text encoder, non standard resolutions, preservation, learning rates. Nada.
Simply won't budge.
Meanwhile even 512 training on the 768 looks better 🤡
I honestly wouldn't be surprised 
At least I can vaguely recognize the shapes

Think I only haven't tried turning off xformers and fp16 in parameters.
Then again, the 512 base would output blank, brown images without using xformers, so what gives.
for the caption image names and text encoder, does every tokens counts as their own or a whole ?
like "An ARAV74 plane", does the whole sentence will be trained word per word and quite destroy "plane" token ?
or it will create a new entry in the model for the entire sentence only ?
or should I name the concept image file "ARAV74" only and specify after at prompting "An ARAV74 plane"
hmm i may be confused between concept and caption aswell
i still don't even know where the text encoder is reading from : the filename or the instance prompt ? both ?
Anyone knows how to train stable diffusion inpainting?
I can only find [img2img inference] [img2img fine tune] [inpainting inference] sample code.
But I want to do [inpainting fine tune]
Bit of a noob question here. If a model is trained using a specific sampler, does that mean the same sampler will deliver the best results when creating images. Or doesn't it necessarily work out like that?
which one is the best sampler that can produce optimal image with CFG Scale more than 10?
It doesn't necessarily work that way. DDIM does work well for both though when training realistic
Anime trained on DDIM can still look better using something like Euler A
Although my Euler A models turned out well so 
Thanks for the info 👍
Did anyone finetune inpainting model to generate backgrounds for transparent images?
there are so many options to train right now, I wonder, what would be the best way to train something on a consistent style?
ddim if it's still the case
I'd say textual inversion is usually enough, since style is more of an adjustment in tone, rather than a totally foreign concept.
Dreambooth is kinda overkill for the most part, unless we're dealing with styles, which focus on subjects completly unknown to the base model.
With ti for style, your best shot would prolly be with a [name], [filewords] template, having manually described content of each training image in their filename. Just avoid using adjectives, which are inherent to a given style.
thanks a lot!, how many images should I use? also, any good colab sugestion?
3-5 is usually enough, but you can't go wrong using more, unless you just feed it bad examples.

here's an example from the people behind it
so when you make a template, go for something like [filewords] in style of [name]
[name] will automatically get replaced by name of the embedding/textual inversion, and [filewords] will be replaced with whatever you wrote in filename of each image
as for colab, can't help, since I'm only familiar with local 😅
@split acorn Did you use Lora, when you tried to dreambooth SD 2.X in 512?
No, just dreambooth
Oh
I think maybe
Well I tried WD 1.4 as one of them
and that's based largely on 512 2.1
so yes! at least a model based on it
so, if I wanted to train a pose for example, [pose] (image names) in the style of (my textual inversion) right?
come to think of it, maybe I'm misleading you, since I'm not sure if colabs support the method I mentioned
in the case of fastDB, does text encoder training consist of blip auto-captioning? or does it just train the token name?
didn't find yet
i hope to do some serious tests on caption / text encoder soon
also, if I understood you correctly, the pose would be a new, separate embed/textual inversion
You can use multiple embeds in one generation. Only requirement being, that they were trained on the same model.
one embed is basically one concept, be it person, shape, style, pose, composition, action, whatever
How is Embedding and Textural Inversion different from using Dreambooth? I'm still new to this so I'm kinda clueless
I'm also seeing LoRA being thrown around
Let's say I wish to create a consistent output that shows a set of poses, a bunch of clothing from different eras in the style of Bloodborne
Basically I want to generate Lady Maria doing an A pose, T pose, and Flossing in various historical clothing, how would I best achieve this? Then would it be possible to change it to Queen Elizabeth II
Sorry for the cursed example, Im not trying to mock the British royal family, just trying to learn how they’re different from each other
Im doing
[Filewords], [name]
[Name], [filewords]
Works great
Same here. Just phrased it that way, since the example is easier to understand I hope.
Sometimes adding
X, bad art, horrible art, bad painting, horrible painting, bad darwing, horrible drawing
Might eliminate the need to use negs(works like 20 40% of the time? Idk)
Oh? That's interesting. Never considered training in negatives per se'
What you caption is to be eliminated from the embedding
What is left is what makes the embedding
That's why it works at all
Makes sense, I guess that's why some of the default templates would use phrasing like "the weird X" or "dirty X"
Yep
Just sounds counter intuitive to me, purposefuly training it on qualities that would supposedly make a worse generation.
No, what happens is that it lets you render all of the words of the org picture
What cannot be generated using those prompts is given to the embedding to regenerate it
Hopefully this clears it up a bit
And btw, id put the embedding somewhere close to the beginning of the caption, as it put more attention to the ones at the start
Too late and it might regen the entire original picture using only the prompts(caption) you given it
Lets say a dog in a forest, and you want only the dog
You caption
A forest, green, branches, leafes, sky etc...
But leave out the dog out without being captioned
It will regenerate everything beside the dog
And here comes the embedding trying to regen the dog with random words
Once it gets better at making the doggo come back, the loss drops
At 0 loss, you get q replica of the dog
But, if there was a stop sign you didn't caption - it might try to regen it as well
This might interfere and slow down the training
And give you stop signs
Usually shuffle my tags, since I tend to train more abstract or generalised concepts. Something akin to generalised style guidelines, rather than a certain character/subject.
Not sure if it was for the better, but seemed to make sense to me, since it resembled training a checkpoint designed for a certain type of art.
Interesting. Someone basically had the opposite problem.
Just can't wrap my head around what might be causing this behaviour..

is there any colab that I can use to train an embending?
Not sure, but could this be it?
yes it works, but not good as automatic1111 train
It needs an update definetely
that's a shame, apparently I can't train it on auto1111 with my gpu :/
same to me, i'm trying to tweak that colab to get some decent results
I am having difficulties with embeddings getting to the result I want
they always seem low res or out of scale
Its taking about 12gigs of GPU memory to train an embedding

its either blurry or checkerboard sometimes like this
When I fine tune a model in dream booth, should I be using the model name in the prompt?
I think it's either your instance token, if you use filewords, or whatever unique word you used in the instance prompt.
Also looks like someone's been trying to embed space marines
Anybody had luck with StableTuner on 12G card?
Shouldn't be that big.. My guess would be either:
-training with too big a batch size
-training in wrong resolution
-training with images that weren't resized and cropped to your models resolution
Other than that, if you are using autos, look into settings under the training tab.
You should probably check "cross attention optimizations while training" and "Move VAE and CLIP to RAM when training if possible"
Is it possible to use checkpoint merger to allow one to use danbooru tags with another model?
My line of thinking is that the LAION tags are pretty awful especially when compared to the danbooru tags of waifudiffusion. It would be interesting if you are able to merge WD with another checkpoint to allow using danbooru tags.
Technically speaking yes, it's just that they'll have lesser or greater impact, depending on weights of the mix.
Merging is quick and easy, so just give it a go, see for yourself. Try out different proportions, and note how the different tag systems interact.
Has anyone found the ideal class images for training faces? with portraits being the intended outputs
Yeah, the merging didn't seem to work terrifically. Tough luck for me
That should work just a matter of finding the right merge combination 



Has "cross attention optimization while training" been updated recently? There was an open issue on it claiming it was negatively affecting training if enabled, wasn't sure if it's been updated (or if it ever even was an issue to begin with)
Hello everyone, fairly new in training with stable diffusion. Hope this is not a noob question.
I trained a style with 30 images with hypernetwork. I tried different layer structures, using the preprocessed captions without further editing, and different learning rates down to 5e-8, 20000 steps.
The problem i have got is that, i was able to img2img and got a similar trained style, but the results were very messy. The lines were not straight, shading was not consistent, especially the eyes, it was totally messed up.
I wanted to find out which part had gone wrong.
Was it my data sample not large enough? or was it the learning rate or steps that was not set to the right scale? Or is it the model is already well trained but I need to fine tuning the settings in img2img instead.
Not looking for an exact answer, discussion is also welcome, really need some new ideas on what to do next. Thank you guys.
having messed with hypernetwork training myself, and still struggling to get the ideal results i'm constantly trying to update the training data with anything that might be "slightly" off.
I've also used dreambooth models and tried TI embeds. Overall dreambooth works well in fast learning but it also pretty much makes the model it is trained on not usable for anything else.
the hypernetwork issue you experienced is the same as mine, sometimes it just doesn't work at all and other times it works on img2img. Recent hypernetworks I've trained have been better, but there is still those problems such as uneven outputs, inconsistent lines etc.
recently trying to see if TI embeds can do any better, but that seems to be taking longer to train and hard to see if it is any better than hypernetwork.
what exactly are you training the hypernetwork to generate?
Hey shihiko, thanks for the time in replying
For the TI embeds method u mentioned, was it "embedding"? sorry if this is a stupid question, not very familiar with the terms yet.
I was training a set of chibi characters with a painting style that is similar to fire emblem heroes's chibi characters.
I have trained both embedding and hypernetwork with the same set of images, and what i have experienced are:
-
Embedding could generate a much closer style when i use txt2img, but one problem is that there is a hint of my original images' pose in all generated images, and when i ask to generate some poses that never existed in my dataset, the results are broken. Not sure if that was because of my prompts not accurate enough or some other issues, couldn't figure out yet.
-
After several tries with embedding, the same poses made me give up in the hope of using prompts only to generate sth in different compositing, so i then thought of using img2img, hoping for with a simple draft, i could get a stylized result. So I switched to train with hypernetwork. (after reading articles saying HN is better in training style) Failed several times but in the end, i tried with a setting of layer: 1,3, 0.75, 0.75, 0.75, 3, 1, LR: 5e-8:20000. Took one of the “alright” pt and was able generated sth that I think is around 50% looking alike my expected style.
-
So in order to improve the result, I tried to add the trained embedding model in (1.) in the prompt when doing img2img together with the HN model (2.) But no matter how i tried differently with changing CFG scale, steps, denoising, sampling method, I could never get back to the 50% in (2.)
Thoughts in mind now:
- Should I continue training with embedding but in a much slower rate? However, i know my GPU is not having enough RAM to train.
- If stick with HN, what other settings should I try?
- Couldn't try with dreambooth, simply couldn't run the thing with my current GPU
omg, my message is so long, really sorry about that
yeah so TI is referring to Textual Inversion embedding.
I also experience alot of "pose biases"
I think the issue here is just not having enough training data to give the AI more examples to learn from. When it keeps learning from the small data set, it improves in detail but also becomes more biased towards what the data set contains.
If you are able to get the style you want to come from the img2img it might be a good idea to get the AI some more data from generated images that are closer to what you want. Which is what I am doing, it takes a long time and trial and error, but I feel it is the best way to go when trying to be specific with what you want.
thank you shihiko, will feed the AI with more images
lets hope the trial time end soon for both of us
good luck with ur training as well !

yeah about to train another hypernet, the embedding didn't work too well and it was like 6 hours of training lol... sometimes it isn't easy to know if the training went wrong too. the last training i did was the right character showing up but the colours were wrong and stayed wrong for the 5000 steps afterwards.
wow, 6 hours! how big was ur dataset
No clue, but I've been running just fine with it, doing even like 8/9 batches in textual inverson with a 8vram laptop gpu
What does finetuning with 8-bit adam look like?
Is it noticeably worse?
also, weird question but if i wanted to finetune on about 10000 images
what learning rate would be most appropriate?
Is 3-4 images truly enough to train a subject in dreambooth?
Additionally, for dreambooth, should one provide mostly closeup portraits, full body, or a mixture of the two?
So I got a decent embedding but its struggling on the faces/helmets
can I add additional reference images to my dataset that focuses just on those details and then it will improve the embedding or will it get confused if you have images that are only a "part" of the whole?

I made a space marines embedding and it works pretty well for their armor but the helmets are wrong
and it doesn't understand if I say I want one without a helmet
30ish for that one. didn't work well so back to drawing board.
Dont trust your preview settings for how your embedding performs
always switch to a custom model and try generating using some of the similar keywords from your captions
and if hypernetwork is like embeddings copy them all over so you can try myembedding-1000, myembedding-1500 etc
its also better to train using a generic model like the SD 1.5 one or WD
how is the results of a hypernetwork different from textual inversion?
How much VRAM does EveryDream need to train a 768px SD 2.x model?
has anyone tried training a person with LoRa and got decent results?
i tried on myself and it was a failure
Anyone have a recommendation for a number of epochs using 30k+ images?
what's the visual difference between over/underfitted text encoder vs unet?
every time a model fails i have to experiment in both directions with both unet and text because no one seems to know the visual difference between under and overfitting of the text encoder vs. under or overfitting of the unet.
will try it, thank you
file size is the least of my worries, i already have like 50gb worth of sd models
Hi all, i'm using dreambooth to train files. I need to hold a lot of fine tuned models but storage is an issue considering the cpkt files are 4gigs
I saw a video that converted a tar file to a cpkt really fast. I downloaded a similar tar file and saw it's also 4 gigs so doesn't solve the problem.
https://www.youtube.com/watch?v=-6CA18MS0pY
Is there any way to just hold the weights in some smaller file format then convert them to cpkt easily. Goal again is to massively reduce storage size of the customization.

In this video, I am explaining how to run Stable Diffusion models that not provided in .ckpt file format. Moreover, I am step by step explaining how to convert these .bin training weight / model files into a .ckpt file to use in Automatic1111 Web UI and other interfaces. Furthermore, I am explaining how to use generated ckpt file to teach your f...
what's the best collab for making those insanely amazing videos that i keep seeing on instagram? I know a few but would like to get input from others as this field is ever changing.
i have used camenduru's colab model to run it works great but can't work with models larger than 7gb i also use nocrypt model it still needs to choose to be able to install 7gb but it's not very stable when 2 or more images, it can't be output compared to camenduru, can output more than 2 images without any problem so is there any easy-to-use model like camenduru and can load 7gb ckpt model file
Where can I find instructions?
If I have images that aren't 1:1, does keeping center crop **unchecked ** automatically force the images to be squished to 1:1?
I'm looking to squish images that are 512x512+ or 512+x512 when training
It shouldn't if you're using the dreambooth webui extension version. They added aspect ratio bucketing about 2 weeks ago.
I've been working on a new embedding that I'm working on anythingV3. But then.
RuntimeError: CUDA out of memory. Tried to allocate 1.25 GiB (GPU 0; 4.00 GiB total capacity; 2.13 GiB already allocated; 180.00 MiB free; 2.24 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
anyone good with photoshop scripts?
trying to load image, remove background, add a solid color black layer, move the layer done, flatten image, save as png
yes you ran out of ram
training in particular is very ram intensive

try checking this box if you havent
Is there way's to get more ram?
like... RTX 3090?
anything Nvidia with more ram
Like... Which one?
Depends on your budget
like more then one RTX 3090?
I don't know card stats I just went from a 1080 to a 4080
and there are still things I can crash on with 16gigs of ram
Damn. I was about to get ready to make some custom models...

and embeddings
also preparing the images before training is very important I am finding
my first attempt I just dumped images into a folder and it didnt go well

I tried to make a space marines one and it still wont get the helmets right and you won't be able to get specific poses or chapter colors etc
and I've trained it through different settings and sets of images a few times
I was trying to mix Anythingv3 with some of that f222 along with some sd.1.4.

thats just merging models

you can do that on the merge tab in automatic1111
checkpoint merger you mean?
yes
I already did that.
thats exactly what that does mix's checkpoints together
But it doesn't have that realistic feel that I'm currently making...
well you are using an anime checkpoint?

This is one I have been working a long time on, and I think it's finally ready for release. A do (almost) anything model.Beautiful lighting, paintings, portraits, multiple photography styles, photorealism, anime and animated styles, alien creatures, armor, clothing, massive dreamy landscapes, abstract retro art, horror, space, nsfw, extremely de...
try this one
I ve had a lot of success with it
AnythingV3 yeah that one.
I'll go check that out then...
I also honestly want to make my own textual inversion.
a 4080 which has 16gigs of ram
the 12gigs of VRAM i mean
but I just upgraded from a 1080 which I think had 8
let me guess, a GeForce RTX 4080 Graphics Card?
What about the
NVIDIA GeForce RTX 4090?
also $1,309.99??
Rtx 4090 £1,599.00?
Jesus...
I had not bought a new card since 2016 but I already wish I had more VRAM
Looks like the road for me to make textual inversions has already ended in a matter of a few minutes...

use google colab, i always use it to train my models
I'm not very good at codes cause I'm a bit of a moron...
you have to like rent server time or something for that?
@novel pond Im using my first collab and im literally just clicking play buttons
the code is already written
use thelastben collab, it also has automatic1111 as an option
yes its literally clicking buttons and adding whats missing
oh if its a collab that runs automatic1111 then its practically the same
Fine, is there link for on automatic1111?
towards google colab cause I was usally on webui.
does anyone knows how the text encoder is set on the shivan collab ? I mean which values are used ?
Hope to see the improvement!

I mean they do mostly look like miata's
but in my experience you have to back through the embedding and check the every X iterations models and try using some different checkpoints
you want to train on the base checkpoint like 1.5 but switch when checking it out
By the way does anyone know DPM++ 2M Karras Simpler? Cause I've seen others prompts using that one. But I've seen anything like on my webui.


Here's mine ^
fwiw I wouldn't worry about missing a sampler
hmm.

see how largely similar they are for a given seed

even changing steps as well doesn't usually make a big difference
you are more likely to find what you want by tweaking your prompt, just generating lots to choose from and then going into img2img
the biggest advantage for AI art is being able to take hundreds of shots at it

all of the karras's were similar and the first seed was the same with all samplers
I doubt mine could reach to 150 steps with the low memory I got. But there's only few changes around the prompts.