#🤝|tech-support
1 messages · Page 53 of 1
AM5, but I may start looking at power use anyways. Concerned about a faulty psu. Full build is below:
AMD 7950x CPU
Asus ROG STRIX B650E-I motherboard
2 x 48gig corsair 6000mhz, CL30
Nvidia 4090 FE 24gig
Corsair SF1000L psu
hmm
Only other thing i could think might be DRAM instability, but memtest showed no errors..
Yeah good idea. Will try that tonight.
Crashed my pc last night and basically had to take it apart and cycle through. Gpu fan was spinning up but unit was not lighting up. Blank screen. Not posting. Mobo indicator first showed red (cpu) until i took ddr5 out and reseated it. Then mobo showed yellow (dram) until i took 1 of the 2 ddr5 out. Then mobo showed white/green which is vga issues. So i tried flashing bios and finally got things to boot up fine. Rebuilt everything and system works again, but I keep getting gpu/vram maxing out.
It'll either stutter and white screen then crash the .bat or eventually crash entirely.
From process standpoint, it appears to be tied to repeated marigold depth estimation and that being used as a depth controlnet for 4 batch image generation.
Which really shouldn't be that intense, but vram seems to start stacking until it fills up and gpu maxes out even on basic generation.
Yes at the PC in 15mins maybe
cool cool
Yes you can move and image into the lora folder and rename the image to the Lora's name
i see. thanks.
You can also generate an image then click on the edit button on the lora and click "set preview"
It will use the generated image
can't seem to find this edit button on lora.
only these 3 buttons

The right one is the edit button
hello my friends i need help
would you like me to uninstall everything and start from scratch?
my friend is trying to install sd on his laptop
he has an intel cpu with integrated graphics and an rtx 3070
i already equipped the correct gpu in the user bat
updated graphics to new
so cuda is updated
but i still get "runtime error: torch not able to find gpu"
i reinstalled venv several times
i tried removing the test
nothing happens
git pull
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--precision full --no-half
set CUDA_VISIBLE_DEVICES=1
call webui.bat
GPU 1 is the 3070 and GPU 0 is the intel graphics
i also installed fast api into venv>Scripts
updated pip
We have been sitting here for 2 hours..... We are desperate and broken.... Our success is at your mercy oh great gods of Stable Diffusion🫂
You could try reinstall the HIP SDK and then download the zluda files again
Hey, remove --precision full and --no-half
Then instead add: --xformers --medvram-sdxl --no-half-vae
Then delete the venv folder.
Then open up a CMD and type
pip cache purge
Then hit enter and close the CMD.
Then launch the webui-user.bat
Try if you canoverwrite it

this is the correct one, right?

and everything look good here?


ill wipe the venv folder just in case.

:/

@ornate elk any idea?

Oh in Blender it works?


Then run pip cache purge in a CMD.
Then git clone the directml repo again
Make a new folder on C and clone it inside that


Thanks xd
hi CS1o
do u know what should I do in automate 1.1.1.1 if my goal is for the character to change clothes in random while im making 100 batches of a prompt
should i write
wear shirt, coat, jacket, full sleves t-shirt
or
wear shirt, wear coat, wear jacket, wear full sleves t-shirt
or
wear shirt or coat or jacket or full sleves t-shirt
Cfg is way too high
I'm sorta new to this so Idk why the image came out like this
What should it be instead?
1 to 2 max
Okay, I'll try it now thanks
The model page from civitai should give you good settings
Thanks! Have you tried this model before?
Yup

I changed the CFG

have you tried other models?
or is this your first one
I tried realism model before, this is a new model I'm trying today
is this specific one giving you issues?
I think so
I changed it to epicrealism model it came out the same 🤔

bump the cfg scale to 8ish
Oh I may have been thinking og lightning. Sorry. Did you check the model page on civitai though?
and sampling to 20
Okay, thanks
Lcm, turbo, lightning. They all run together in my memory at times. Sorry for the misleading
Oh


DreamShaper XL - Now Turbo! Also check out the 1.5 DreamShaper page Check the version description below (bottom right) for more info and add a ❤️ to...
Yeah, thanks for help Xd
im p sure it's not a technical issue
This is the one I downloaded I think
it didnt work sadly
maybe we did sth wrong
we will try again
Hi
Checkout my install guide in the pinned messages of this channel
do u know how to generate random clothes and stuff if your making a batch of 100 or so
in automatic 1111
. this
With Wildcard extension
wait
this one?

any idea...?
installed it. now what.

jus looked it up
is there an easier way to do that. like in the prompt itself.
does anyone know how to use .png bones/annotation file in openpose ?, or it just can't

Right, well it states "You can use the Turbo version (not Lightning) as a non-Turbo model with DPM++ 2M SDE Karras / Euler at cfg 6 and 20-40 steps." 😄
Nope everything looks correct
ill literally try anything
anything that comes to mind
@ornate elk

I tried following this... no dice.
Yea because to get that to work you need to run
Pip cache purge
In a CMD
And then delete the venv folder
Select None as preprocessor and openpose as model and it will work
it works thanks
that worked, but zluda does not... should i try sd.next?
Yes, that's a good idea
But I have a feeling it won't work too
But worth a try

It works 😮
ehhhhhh
Hello, I try to upload Deforum in a new SD that I have just installed today. But when I go to extension tab, then Available, then Load from, nothing appears. I can only read : URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)> If someone had an idea, thank you very much
i mean it looks better than on the directml
once in ui it doesn't use gpu
haha
im reinstalling it though
since i did fuck up my first time

whyyyyyyyy
if this is not ticked. I can't see most of my loras. but if I do click it. I can see most of them though still no point. cuz they aren't working for me. why are most of my loras incompatible and what can I do for them to be compatible.

oh it is not the 840000-ema-pruned, thx gonna check it out
aren't loras version based?
so like some are for xl, others are for 1.5...
what do u mean?
.

and loras are designed for them in specific. so only some loras can work with some models
ooh. how do I check which one I have
have you tried to delete the venv run pip cache purge and relaunch again?
yep
for sdnext
look at the lora page, it will say there
i wasted 2 hours installing RAM into my rig to find out it wont even boot, today
OOF
my evening is so wasted xD
but now i know, dont buy an additional dualkit of DDR5 6000MHz Ram because Mainboards cant even boot on 5400MHz with 2 dualkits
So back to only 1 dualkit


oh no. I know that
well... does it match!

In ComfyUI, I'm trying to use WD 14 tagger, However I'm running into this error
2024-04-08 18:06:56.8751234 [E:onnxruntime:Default, provider_bridge_ort.cc:1351 onnxruntime::TryGetProviderInfo_CUDA] D:\a\_work\1\s\onnxruntime\core\session\provider_bridge_ort.cc:1131 onnxruntime::ProviderLibrary::Get [ONNXRuntimeError] : 1 : FAIL : LoadLibrary failed with error 126 "" when trying to load "D:\AI\ComfyUI_windows_portable\python_embeded\Lib\site-packages\onnxruntime\capi\onnxruntime_providers_cuda.dll"
RuntimeError: D:\a\_work\1\s\onnxruntime\python\onnxruntime_pybind_state.cc:636 onnxruntime::python::CreateExecutionProviderInstance CUDA_PATH is set but CUDA wasn't able to be loaded. Please install the correct version of CUDA and cuDNN as mentioned in the GPU requirements page (https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements), make sure they're in the PATH, and that your GPU is supported.
here are the logs of me trying to install onnxruntime and test if my installation is correct (at the end of the log you can see there are no errors because python doesn't throw an assertation error, indicating python can find my cuda installation):
https://pastebin.com/dYbnf85b
These are the sources i was using:
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements
https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/gpu#checking-the-cuda-installation-is-successful
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.

Models that are 2-4gb are 1.5 based models.
6gb files are mostly sdxl models
The Lora's only show up when a compatible model is selected
its around 9.5 gb
What's the name of it?

Any idea why AUTO1111 forgets my settings in ui-config.json? 🤔
It keeps resetting my Sampling Method and Sampling Steps to DPM++ 2M and 20 even though I set them to Euler a and 30 respectively
did anyone had the issue when using the API that frequently the generated pictures will be 0kb? what is causing this?
oh. I see
Hi guys, I’m new to SD,I have installed automatic 1111 on my local but how can i check my version is sd1.5 or sdxl ?
Hi guys, can some1 point me to a simple LoRA guide for beginners. I installed LoRA Easy Training Scripts but I have no clue how to use it
Intro to LoRA’s by Laura 😝

In this video, we'll see what LoRA (Low-Rank Adaptation) Models are and why they're essential for anyone interested in low-size models and good-quality output. Next, we'll go through the process of finding and downloading the best LoRA Models available online. We'll finally see how to integrate these models into Stable Diffusion and how to use t...
can i training a checkpoint model base on models from civitai? are there any requirements for model file? like pured?
When I use SD Forge, after selecting the model in the controlnet, an error is displayed. Why?
Maybe I should ask another way: I installed SD1.8 and SD forge at the same time, but I don't know how to install forge's controlnet correctly and how to use preprocessor and preprocessor model correctly in forge?
Depends on what checkpoint you use, some checkpoints aka models are sd 1.5 and some are sdxl, search for sdxl and filter by checkpoint on civitai for sdxl models
Remember that text embeddings and control net models are different from sd 1.5 to sdxl
Idk about loras
When starting, the version will be displayed in the terminal.

Check the models page on civitai.
Usually models with 2-4gb are 1.5 based and models with 6gb are sdxl based
Python 3.11 is not supported. Also wrong installation method if this is auto1111
Man, sorry to bother you again, it's only that even if I use a sdxl model that support certain resolution, 1344x768 landscape in this case, I keep getting multiple characters even if I use a prompt like this; ((1girl:1.5)), sometimes even with vertical resolutions ;-; do you think my prompt is the problem ?
I used every negative word I could've imagined too
Hey, do you have an example?
Like what ? A image ? Im on mobile now sadly, ;-; but imagine a lot of the same character randomly put in the same image, sometimes the aí even divide them using black frames like a image grid
I'll send some images when I get home
Zero123 is adopted for MAC?

Yes, then we can take a look.
Normaly sdxl shouldn't create doublicates at that resolution
You need to download other checkpoints (models) from civitai.com
These models are trained on higher quality images and will give better results.
For example download dreamshaper v8 from here and put it into the models/stable-diffusion folder.
Then reload the checkpoints on the top right and select it there.
You will automatically get a better fox.
Here is the model:
https://civitai.com/models/4384/dreamshaper
Then work on your prompt. Add some negative tags like, blurry deformed, mutated, onto the negative prompt field.

DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...

Yea the 1.5 EMA pruned default is not a good model
is it this
This is the refresh/reload button


Can I download like multiple models and combine them all
or is that not a thing
also what are workflows used for
Yes you can merge multiple models into one. (it takes some skill to do correctly).
No you can't use multiple models at the same time.
Is there a tutorial for it, sounds fun, then again chaotic
probably better just using it individually
Gonna need a more precise questions to answer that.... Asking "what workflows" in A111 is like asking '"what workflows" in photoshop.
my bad
thank you
You can download multiple models and switch between them.
But Lora's can be used together with models
To get a specific style or character
Traceback (most recent call last):
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1431, in process_api
result = await self.call_function(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(args, **kwargs)
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\call_queue.py", line 95, in f
mem_stats = {k: -(v//-(10241024)) for k, v in shared.mem_mon.stop().items()}
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 92, in stop
return self.read()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 77, in read
free, total = self.cuda_mem_get_info()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 34, in cuda_mem_get_info
return torch.cuda.mem_get_info(index)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py", line 618, in mem_get_info
return torch.cuda.cudart().cudaMemGetInfo(device)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
do i put these 2 into the Model/Stable diffusion model at the same time

vae goes in your vae folder, full model (if it has pruned in username should include vae if not) put in stable diffuson model folder
Make sure your nvidia driver is updated
VAE quick guide :
1/ What is a VAE.
It's a part of the stable-diffusion pipeline that encode/decode information from tokens to latent space and from latent spaces to pixels. Aka it transforms math statistics in pictures
2/ Where do I put my VAE ?
- VAE with
.vae.pt,.vae.ckpt,.vae.safetensorsextensions go into the models\Stable-diffusion folder - VAE with
.pt,.ckpt,.safetensorsgo into models\VAE
3/ How do I use my VAE ? Three possibilities : - Either you name it similar to another one of your model (eg : Anything-V3.0.safetensors + Anything-V3.0.vae.pt), by doing that it should automatically load the VAE when you load the associated model.
- You manually load your VAE by going to Settings -> Stable-Diffusion -> sd_vae and selecting your VAE
- You add an easily accessible VAE dropdown at the top of your page to quickly switch back VAE by adding
sd_vaeto your Settings -> User Interface -> Quicksettings list
so tldr, yes get both
(the fact that the model is pruned does not mean it necessarily embed the correct VAE)
Hey, I just downloaded the 'rich' extension through pip for proper syntax highlighting / text color for python in the console, (Windows 11, zluda stable diffusion webui). I want to auto apply it for stable diffusion, so its easier to work around errors. Normally, you need to run something like "from rich import print" every time you start a new prompt or instance of python before it will apply... I want it to auto enable for all stable diffusion stuff, does anyone know if it would work to add the line to my webui-user.bat file? So it would look like this: if not, is there another way?
thank you
@ornate elk works rn

but ill try with a more extending prompt
if it bricks gg
(advanced prompt)
60 s/it OO wtf, what s your gpu ?
i might need an upgrade XD
maybe... depends what gpu your toaster is equiped with
2060... (at the time my toaster was considered a good pc) :*(
ok those are NOT 2060 number
something is wrong with your install
is 60s/it bad XD
yeah....
im tryna get into animation
for stable cause im working on a yt video
and tryna test some stuff out
good luck
and temporal kit + ebsynth
is too hard
😦 my prompts always = blurry
might just be skill issue
is animatediff not the way to go?
there are many workflows for video. I m not an expert on that subject, animatediff is a good point of entry.
It s just that generating animations/movies is way more taxing than creating still pictures

no
but

big file is a stable diffusion model so it goes in models/stable-diffusion
yes but it s not a VAE
OH
only the small file is a VAE
Hey, I still have the issue with NetControll not saying ticked when hitting apply, which then prevents me from selecting model in openpose. On recommendation of someone here, I excluded site from AdBlock but it didn't helped

Hello! I have a small question about VAE.
For some reason, when generating during the entire process, ''Livepreview'' appears normal, but after completion to 100%, the final file comes out like on the screenshot.
This only happens when using VAE 840000 and PonyV6 checkpoint, but after searching in CIVITAI many people have used Pony with VAE840000 and for some reason they don't have a similar problem and I don't understand what could be wrong in my case. Has anyone encountered something like this?
p.s. There is a ''built-in'' VAE in PonyV6, but it seems that on CIVITAI, if I'm not mistaken, they used 840000 instead of it.

84000 VAE is an 1.5 VAE and won't work for sdxl based models
You need an sdxl based vae
Whats the maximum resolution I can process without crashing
got it.
Are there any good similar VAE like 840000 but for SDXL?
Where to get new Lora configuration file?
depends of your config and settings. In theory stupidly high if you know what you re doing
Infinite in theory
Hello, how do I properly uninstall an extension that has been installed from github?
you delete its folder in the extensions folder.
there's nothing to delete in the extension tab?
Yes the official sdxl VAE and the sdxl VAE fp16
so if im using batch count to generate 100 pics the quality of those pics will not deteriorate afaik though the downside is I can only get 100 pics at a time. so my question is if I use batch size along with batch count to get more than 100 pics. or will the quality worsen then?
The quality won't be affected.
Batch count = the amount of images generated one by one
Batch Size = the amount of images generated at the same time (requires more vram)
can u elaborate on what u mean by at the same time
cuz I was hoping that batch size works in a a way so that as soon as the first 100 batch count is generated. will move to the second batch count of 100 and so on, that is if the batch size is set to 2 and batch count to 100
so I'll be getting 200 images total.
whats making me confused is what u mean by at the same time. cuz how is quality not getting compromised if ur getting pics at the same time.
Stable diffusion loads the model into the vram and creates an image by denoising random noise.
This is a vram heavy task but doesn't have anything to do with the quality.
If you have enough GPU vram you can set the batch size to a higher value.
What affects the quality is:
The model
The Prompt
The resolution
The right amount of steps
A good cfg value
The sampler
Upscaling
Extensions
Lora's
Embeddings
oh. so its not like gpu vram will be divied b/w 100 pics or something
xd
cuz thats what batch size sounded like until now
i have a 3080ti
and 32 gigs ddr5 ram
about time I check how many its im getting
nope
No the vram will just get filled up more
ur supped to see them through the command window thing right?
hoping its somewhere along 6-7 atleast
i'll try batch count 100 and batch size 2 and lets see


Hello, I have installed Deforum in SD. SD does work. But when I try to generate videos with Deforum, I always have this error message : URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)> . I also have exactly the same message when I go to extension tab, then Available, then Load from. If someone had an idea, thank you very much
Is using Pinokio impossible if there’s spaces in my user file name and I can’t change it ?
thanks!
what country are you from ?
I think i maxed out something but I forgot
Oh i maxed out upscale
I'm from France. I did use Deforum without trouble since some months.
no vpn ?
no vpn ? @quiet swift
I do not know what is a VPN. I'm on Mac by the way
ok, can we get a full log ?
(copy paste everything from the console into a file and drop said file here)
do you speak to me ? 🙂
yes
ok, thank you but I do not know what is a "full log" and what do you intend by "from the console". I can give you the settings of my video if this is what you ask ?
ok 🙂 I give you a captur of my screen Terminal when I launch webui. thank you if you can help 🙂

ok but one including the error
and please copy paste the text into a file and drop the file in here it will make both your and my life easier when the log gets big


ok, sorry. Here is a file with the Terminal Text with the error, which is always the same. It is also the same error message when I go in SD to "extension" tab, then "Available", then "Load from"
What webui did you installed?
It doesn't look like the normal automatic1111
can someone tell me how to utilize clip skip in stable diffusion
I can't even seem to find it.
Settings, User Interface, Quicksettings,
there add Clip stop at last layer
Then apply and reload
thanks. worked like a charm.
I checked this error on Google, but there is no solution for this error.
Can you link me from where you got it?
wait a minute
Because the basic webui doesn't have Aki-v4 in its name
夸克网盘是夸克推出的一款云服务产品,功能包括云存储、高清看剧、文件在线解压、PDF一键转换等。通过夸克网盘可随时随地管理和使用照片、文档、手机资料,目前支持Android、iOS、PC、iPad。
here
I come from CHN
This is the stable diffusion starter modified by our Chinese people.

yes
This version often causes various problems
This fork no python
Only this interface is also the launcher
Moreover, our network often has problems, even if the VPN is disconnected, the problem persists.
does the preferred weight in lora metadata has any importance? should I leave it be to 0? or change it to something?

Ah okay is it based on the latest version of automatic1111?
The text2video extension might be outdated
LET ME SEE
HERE

OH,LET ME CHECK
Is my error report the same as theirs?

its his error

yes its the same
OK I try
are these speeds good for a 3080ti?


its probably the modelscope inside the venv folder
do you have a venv folder?
NO

@karmic crown you ve seen something like that before ?
and then?
@quiet swift your macbook is updated ? its hour/time is set correctly ? internet connetion is stable ?
i thought maybe there is a second modelscope folder inthere
but you should check the whole webui folder for them
why is there such a difference in speeds?

assuming you re using hires.fix / upscale then the resolution
first pass is low res, second pass is high res
OK
yes my macbook is updated and hours and time are correct. And no problem with Internet.

try to open a console in stable-diffusion-webui folder and run venv\scripts\pip install --upgrade certifi
ok. thank you. To be sure that I understand, I write what you say ("venv/scripts...") in my Terminal after having launch again SD in terminal ?
first you navigate to your stable-diffusion-master folder then you run the command
ok. but how do I know the generating power in general thats being utilized
all of it
like i have a 3080ti. I wanna benchmark that with other gpus like 4090. lets say
it always use as much resources as possible
to see how slow mine is
Use a 1.5 2gb Model.
Resolution 512x512
30 steps.
And for the prompt only
Cat in positive and
Blurry in the negative prompt
Without upscaling or anything
then you get it/s to compare with others, when they use the same settings
Just pick a prompt and its settings, stick to it and compare its results ? do a simple "cat" promp test at 512x512, 30 steps, Euler A, no upscale and voila
sorry but I don't understand where I must write your command. I have tried to write it in Terminal (which is the application where you launch SD on mac) but nothing happens.
idk which one to rename
open a terminal,
cd /Users/arnaudbigeard/stable-diffusion-webui
./venv/scripts/pip install --upgrade certifi
ok, thanks. I did write your command. Terminal reply is : "zsh: no such file or directory: ./venv/scripts/pip
arnaudbigeard@MacBook-Pro-2 stable-diffusion-webui % "
commuting back home I ll check once I get there
ok, thanks
does it make a difference if I use prompt with or without gap
i.e cat, mouse, dog
i.e cat,mouse,dog
notice one has gap after comma. other doesn't.
@ornate elk sry for tag. can u tell me this one last thing.
is there a universal weight I need to set for lora. or should I jus apply lora and let it remain 0



@ornate elk hi, I was trying to re install Zluda so I took a look at the pinned message. If I remember correctly, we had to copy a couple files in the Zluda folder, rename them and paste them in specific folders, do we no longer need to do that?
I'm new to using python to load models. I'm trying to load both stabilityai/stable-diffusion-xl-base-1.0 and the stable diffusion 1.5, but they seem to be too big for my 6gb of vram.
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", low_cpu_mem_usage=True, use_safetensors=True,
)
pipe = pipe.to("cuda")
Is there anything I can do to make it load (partially?). or should I use some smaller model? How do ComfyUI and Automatic11111 do this (they work for me)?
pipe = pipe.to("cuda")
^^^^^^^^^^^^^^^
...
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 5.77 GiB of which 42.31 MiB is free
hey, thats no longer needed
as this step is automaticly done by the webui
every lora is different, the prefered start value should be 1
so change all of these to 1 instead of 0 and see what happens. right?
ok
also this
normaly dont change anything if its not the default value
lora weights have to be changed in the prompt
every lora Ive installed had this value to 0 by default.
i see
you have to try a lora and play around with the weight, and if it needs a specific weight then you can edit the slider
every lora starts with 1 and the strenght goes from -2 to 2
alright. I get it now. makes sense
and can u tell about this? @ornate elk
some prompts have gaps. others don't
i normaly make spaces after a ,
thats how it was since the beginning
Hi, can you give me some advice ? In "My Machines", my machine is marked FAILED, and I am unable to start it. Was Ok yesterday.
I am new to this, so any help is appreciated. Thanks.
open a terminal,
cd /Users/arnaudbigeard/stable-diffusion-webui
./venv/Scripts/pip install --upgrade certifi
we have NO IDEA what you're talking about.
what is "My machines" ?
"unable to start it", what is "it" ?
@ornate elk hi, so I finally fixed the crashing problem. I was messing around with the arguments and I realized I get no crashes when I remove --medvram-sdxl . I still get the same exact speed of generation only now I don't get any crashes. If anyone else has a similar problem they could try this perhaps.
okay thats interesting, thx for letting me know
Sorry, perhaps I am not in the right place. I have a problem starting a machine in Think Diffusion. I can start a new machine, but cannot start the one I created yesterday.
Not necessarily the wrong place but you have to give the full details when askin for help. And at the same time you'll probably get better chances asking in their discord. There's probably few people here using thinkdiffusion, we mostly run SD locally.
ok thanks
hey can someone help me? ive used loras before and now i wanted to try SDXL Loras. so i installed forge webui (similar to A1111) and SDXL. I think the SDXL seems to work now, i use the model from civitai and the refiner. But now i cant get the lora i want to use to work. (this one: https://civitai.com/models/129556/ps1-graphics-sdxl) The image seems unchanged in style. is it because of the refiner? Do I need to use comfyUI for this?

PlayStation 1 (Mid to Late 90s) Nostalgia Game Graphics LoRA (Inspired by Silent Hill PlayStation1 childhood nightmares) Must include trigger word ...
pickles imports detected how is dangerous?
what?

@ornate elk Hey man. here are the examples you asked for




and both of my prompts

sometimes i get good ones, one in fifth lol (grid image to show how many are the bad ones)



Model; Animagine SDXL
Sampling; DDIM - 35 steps
No hi res fix at 1344x768 at both vertical and horizontal
i noticed that tiny dupes were caused by the word "doll", but the big ones i have no idea, idk even if this is a prompt problem ... i dont wanna change the model tho, i really liked the good results i got
ok, ill try
also i would lower the lora doll joints maybe
ok. good idea

for w/e reason my art coems otu a bit crystalzied
any idea why?

loosk about fien when loadign but then when tis done its all like that

What settings did you used?

is that wym or
Set the upscaler to Resrgan4x+ Anime6b and Denois to 0.5
And hires steps to 10

Try DPM++ 2M Karas as sampler
Should be using easynegativev2 with that model as well, to help with outputs
whats that
Read the model page:
https://civitai.com/models/4468/counterfeit-v30

high quality anime style model. Support☕ https://ko-fi.com/sfa837348 more info. https://huggingface.co/gsdf/Counterfeit-V2.0 Verson2.5 https://hugg...
When you download models, you need to read. Often-times, there is important information to help with output.

the pt since you're using A1111
But as was also suggested, you should adjust your sampler to match what is in the examples, too.
YEAH BUT THATS NOT THE PROBLEM
oops capslock
it isnt the problem too
cuz that was just a random test
Samplers matter.
every imagie seems to come out that way

Better.

Pickle files can contain runnable code , that executes when the model is loaded, they should really be avoided at all cost IMO unless you totally trust the source.
It could be safe or you could load it and runs a background task to delete your files, or install a backdoor.
its audio model
not recomended use it?
@ornate elk well we tried your pinned guide
my guy
it fucking worked like a charm
my guy, you helped me out a lot several times
love u bro 🫂
Does anyone know how to change stable diffusion relying on cpu?
I have an installation problem saying that torch cannont use gpu
prolly the wrong version of torch
Anyone else find that forge uses really high amounts of ram, or is it something wrong with my setup?
how could i fix this
does it say what version you're running in the console
how can i check for the version for torch

it just says this
K so it's not the CPU version then
Looks like you either don't have a GPU, it has failed/died, or it's not detecting it
Hey, what's your GPU?
so, i let it overnight and sadly same results, 1 in 50 is a good solo girl, the rest are multiple portraits or somethin


new prompt, i added a lot of negative words and some sd xl negative embbedings to it

I wouldn't use in on my local computer unless you trust the user, perhaps contact the author a see if they can update thre code and convert the moel to safetensors.
Its about time the AI world got serious about security.
I think you can you try to remove
"Great composition" and
for sure remove "concept art" as this could trigger it for multiple poses of a person in one image
Hey guys. Does anyone know how to use Demofusion in webui? I tried but the output looks missing a big piece and blurry compared to normal output.


is it something wrong because of settings? I kept them default

yeah lol, why did i put concept art xD bro, thank you for sharing some brain lol

dont understand hhow to download
whats the difference

you did something wrong
maybe you messed up a path
or simply your computer needs a restart
Hey everyone,
I could really use some assistance with something. I'm trying to figure out how to create a new artistic style by combining influences from multiple artists using stable diffusion prompts. I've experimented with various examples, like Artist Name 1 and Artist Name 2, as well as trying to emulate the styles of individual artists like Artist Name 1 and Artist Name 2. However, despite my efforts, I'm not achieving the results I hoped for. Any suggestions or guidance would be greatly appreciated!
Also, does anyone know of any straightforward stable diffusion prompts that I could use to test and experiment with different artist styles?
Thanks in advance for your help!
bot
I'm using mov2mov from Stable Diffusion web ui,
The video is not generated even after more than an hour.
What settings do I need to make to generate videos?
The mov2mov items are still displayed on the screen.
■Environment
Stable Diffusion web ui ver.1.8.0
■How to install
Use the installation URL from github (https://github.com/Scholar01/sd-webui-mov2mov.git) and install from the URL on Extensions on Stable Diffusion.
■Checked "Allow other script to control this extension" in ControlNet
■Things used for operation confirmation
・Sample video of about 10 seconds
・Resize mode: "Crop and resize"
Video output size
Width:
512
Height:512
・Movie FPS:10
■Other concerns
The following message is displayed in red in the Movie Editor item.
[This feature is in veta version!!
It lnly supports Windows!!!
Make sure you have installed the ControlNet and IP-Adapter models.]
The PC I am using is Windows,
ControlNet is installed,
I have already installed IP-Adahttps://huggingface.co/lllyasviel/sd_control_collection/tree/mainpter from the following site, but the error message does not disappear.
・ip-adapter_sd15.pth
・ip-adapter_sd15_plus.pth
・ip-adapter_xl.pth

GitHub
This is the Mov2mov plugin for Automatic1111/stable-diffusion-webui. - Scholar01/sd-webui-mov2mov
I don't know, I never had to download an lfs file from github, only from hugginface and they have a convenient download button for the items.
What Github repo is this.
You could clone the repo, but that will be slow and could download several times the amout of data than just downloading the model.
its safe downolad safetensors version this pickles file?
user made safetensor version
whats a pickle file?

Mov2mov is broken and needs a manual fix.
Here is a link to the fix:
https://github.com/Scholar01/sd-webui-mov2mov/issues/140#issuecomment-2017033461

GitHub
"After installing mov2mov, it can't generate anything. My computer runs on Windows 10, Python version is 3.10.6, and Stable Diffusion version is v1.8.0. I've reinstalled several times,...
what
so never to download pickletensors even if the creator is trusted?
maybe you can
wym?
you can if you trust and people not said is bad
i see
but i dont like any risk trust or not
Thank you!!
I will try to fix it in my own environment.
From python's own documentation
https://docs.python.org/3/library/pickle.html#


Python documentation
Source code: Lib/pickle.py The pickle module implements binary protocols for serializing and de-serializing a Python object structure. “Pickling” is the process whereby a Python object hierarchy is...
safetensors is a format for tensors that does not execute arbitary code so at the moment safetensors are considered a secure format.
Hello, I open a terminal and wrote your command. Terminal reply is : zsh: no such file or directory: ./venv/Scripts/pip
arnaudbigeard@MacBook-Pro-2 stable-diffusion-webui %
ok what's in the /Users/arnaudbigeard/stable-diffusion-webui/venv/Scripts/ folder ?
inside the stable-diffusion webui/venv/ I don't have a "scrpit" folder. Inside venv folder, I have 4 folder = bin - include - lib -share. And I have 3 files =dev.txt - pyvenv.cfg - x.txt
inside bin ?
Inside bin, there is 52 elements.
is there pip ?
there is pip pip3 and pip3.10
ok then
cd /Users/arnaudbigeard/stable-diffusion-webui
./venv/bin/pip install --upgrade certifi
Terminal did reply : Requirement already satisfied: certifi in ./venv/lib/python3.10/site-packages (2024.2.2)
[notice] A new release of pip available: 22.3.1 -> 24.0
[notice] To update, run: python3.10 -m pip install --upgrade pip
arnaudbigeard@MacBook-Pro-2 stable-diffusion-webui %
Is there a "Install Certificates.command" file in your /Applications/Python 3.10 folder ?
yes, there is this file in Application/Python 3.10 folder
run it
when I double click on it (is it "run it"?) there is a window that open in which is written : Last login: Wed Apr 10 10:19:43 on ttys000
/Applications/Python\ 3.10/Install\ Certificates.command ; exit;
arnaudbigeard@MacBook-Pro-2 ~ % /Applications/Python\ 3.10/Install\ Certificates.command ; exit;
-- pip install --upgrade certifi
Collecting certifi
Using cached certifi-2024.2.2-py3-none-any.whl (163 kB)
Installing collected packages: certifi
Successfully installed certifi-2024.2.2
[notice] A new release of pip available: 22.3.1 -> 24.0
[notice] To update, run: pip3 install --upgrade pip
-- removing any existing file or link
-- creating symlink to certifi certificate bundle
-- setting permissions
-- update complete
Saving session...
...copying shared history...
...saving history...truncating history files...
...completed.
[Opération terminée]
try again to run the stuff that gave you error yesterday
It does work !! :)) Thank you very much. After having generated a video, I went in "extension" tab, then Available, then Load from, just in order to see if the same error message appeared. And the list appears, there is no more error message. Thank you !!! :))
where can I save this
this morning I tried to reinstall my environment but I got this error

wtf r u typing
How do i make it more vibrant

Im trying to make it look like this - from https://civitai.com/images/55758

how do i force my Webui to like use the VAE given


First go into settings, User interface, quicksettings, there add sd_vae
Then hit apply and reload ui
Then download a VAE and drop it into the models/VAE folder
Then you can select it in the dropdown
what is "this" ?
Will this still work if the VAE is already in the folder?
pruned <=> trimmed off, it's lighter model. They removed part that of it that are useless 99% of the time. Making it way lighter.
anyone knows how long it takes for a credit purchase to become active? I've bought credits 5 minutes ago but I still get an error about insufficient funds if I try to generate an image via API


works now
I have an issue with 1it/s no matter what in forge and sdxl models on a 4090. I have installed cuda with cudnn update, pytorch, latest gpu drivers etc etc. On win 11. Anyone encountered something similar?
Googled all day and tried whatever fixes I found, no change.
I get the error:
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
anyone know any fixes?
hey, whats in your webui-user.bat?
whats your gpu?
gtx 1080 ti
can someone tell me how do I use embeddings?

you can find youtube tutorials
it's not hard to look for
stick them in embeddings folder and then just call them like a lora in a1111
am I supposed to put them in adetails folder
alright. thanks
my bad not ti it's just gtx 1080
hello?
not properly installed? start over https://stable-diffusion-art.com/install-windows/

We will go through how to download and install the popular Stable Diffusion software AUTOMATIC1111 on Windows step-by-step.
the default https://pastebin.com/VZ8vsLyV Ive tried with --xformers, but apparently it's not needed for forge
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
okay, make sure you have the latest nvidia driver
yea, we should focus first on getting auto1111 to work, then forge will work too
so whats in your auto1111 webui-user.bat?
I do
started over like 10 times
I don't have it installed right now, hold on.
this here is the recommended install guide for auto1111 on nvidia:
#🤝|tech-support message
check if you have done these steps
I have
okay, can you share a screenshot of the whole cmd after launching it?
Sure
follow my install guide from here:
#🤝|tech-support message

ewall - try deleting your VENV folder
Like I said I reinstalled it 10 times
okay, open up a cmd and run
pip cache purge
then delete the venv folder and relaunch the webui-user.bat
even starting from scratch
also do you have an intel cpu ?
yes
check in the taskmanager under the performance tab if their is GPU0 and GPU1 or only GPU0
okay so only the nvidia gpu is listed, that would be good
so what does that mean exactly?
that does mean it didnt used the intel igpu
Installed and ran a very simple prompt at 1024x1024 in a1111, it's at 9it/s, so that's promising. Opening forge again and its installing a bunch of stuff
inside the a1111 .bat:
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --xformers --no-half-vae
call webui.bat
looks good, also 9it/s is good if you used an sdxl model (6gb), on 1.5 models it should be much faster on 512x512
it was the default downloaded model sadly.. 😩
oh then try it at 512x512
because the default is an 1.5 based model
not made for 1024x1024
waiting on few installs on forge
did you retried after purging the cache and deleting the venv folder?
yup same thing
whats in your webui-user.bat?

a vrooming 18-24it/s at 512x512 for default model
thats good!
so no issues here
at the line COMMANDLINE_ARGS= add:
--xformers --medvram-sdxl --no-half-vae
Sure
I ran a benchmark via System Info extension in forge to get some info, the it/s looks fine there, but I don't know the parameters its using for genning. Maybe any info in this can help https://gyazo.com/7344f00615b28fc950a59e7f5f51dc2b

what i also would suggest is to open up a cmd as admin
and run
sfc /scannow
that will try to fix system errors.
after its done restart the PC.
alrighty
looks okay, but no infos on the steps, sampler or resolution
same issue with the adding commands but I'll try the scan now
It does say their is a pending thing which a pc reboot is needed for
so I'll restart my pc in a minute and ping you when I'm back or just say back
oh okay, then reboot and then run the check, also make any windows updates before
Yeah. So I gen at 1024x1024, default dpm++ 2m karras, 7cfg, 20steps. sdxl v10 checkpoint. prompt "a chair", 1.45it/s
on forge or auto1111 ?
forge
1.45 its is to slow for sdxl on a 4090
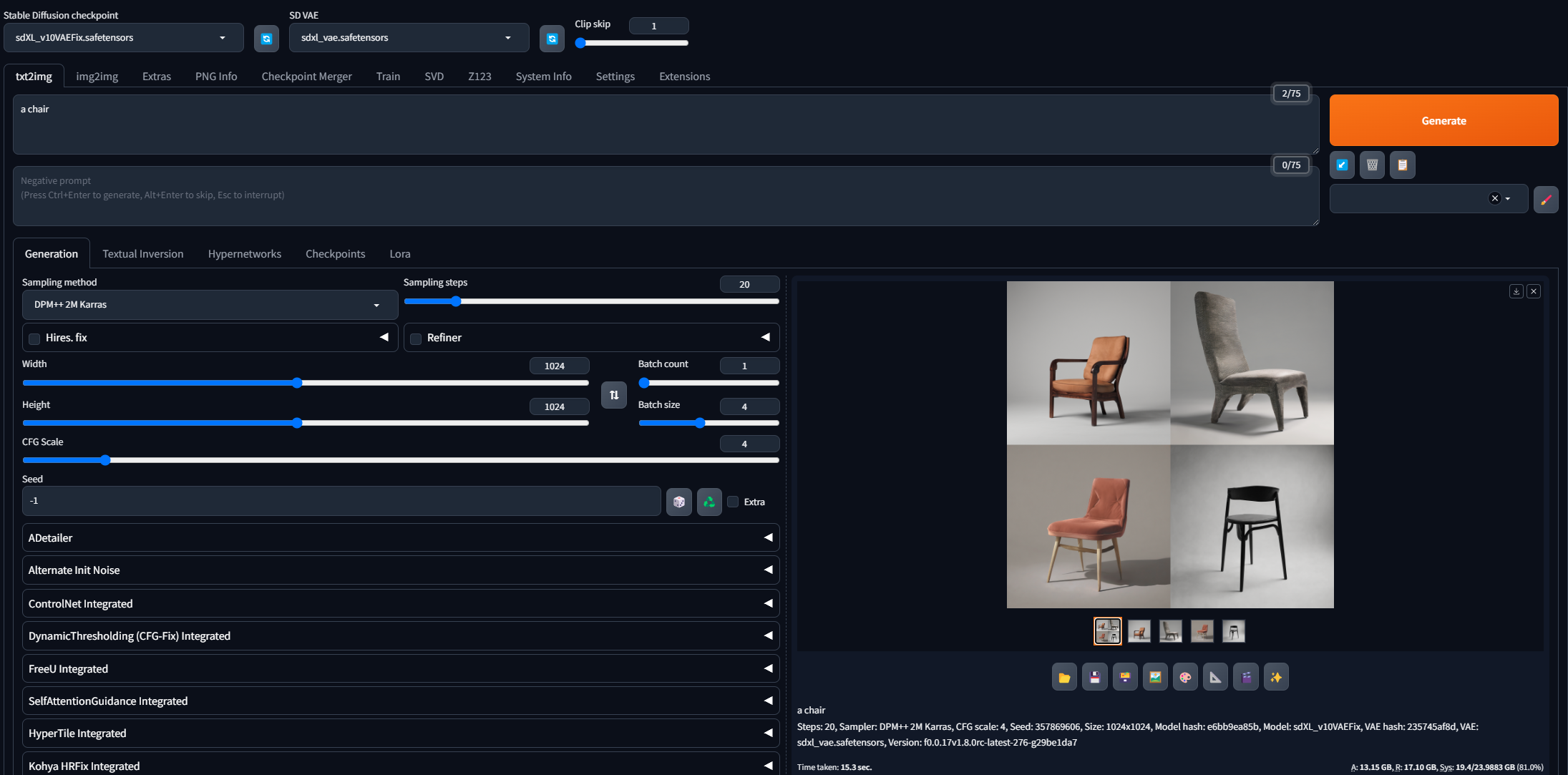
6its
yea thats better
batch size means "generating at the same time, using more vram"
while batch count is "generate each image after image"
so today, whether from an old installation or from scratch, it's impossible for me to download torch...

yea, i guess so
Lol, well I guess that's what I get for trying to be efficient. I've always ran 4 batch size. I took over a year break from SD, used 4 batch size back on a 3090 too. I guess i turned it into a muscle memory default
Many thanks for the help! I'll be able to pass on this wisdom now 😎
and just get another 3 4090, so I can run a pseudo 4 batch size that way
no problem 🙂 you can still use batch size, but you have to compare what is faster, batch size 4 with sdxl or batch count 4 with sdxl, also check how much vram is used
hey, open up a cmd and type
pip cache purge
then delete the venv folder and relaunch the webui-user.bat
It's just 1second difference of time taken for the gen and ram stays the same. But now I know that it splits the vram for the genning, so big prompts with loras and extensions should run better on batch count 👌
it's already been done
hm what you can try is update to python 3.10.11, delete the venv folder and relaunch
you can try update your python to 3.10.11 too then delete the venv folder again
alrighty
@trim raven if the python update wont help, try this command inside the venv
pip install torch==2.2.1 torchvision --index-url https://download.pytorch.org/whl/cu118
should I do the same if this does not pan out once it's finished?
Also yeah doesn't work
nope, you should reinstall your nvidia driver probably
alright I'll just try that a different time
if that doesn't work I'll just wait for stable diffusion to update and try their newer version
thank you, solved
its not the fault of stable diffusion, as for my GTX1080 it works perfectly
mostly it didnt recognised your gpu or driver
so the clean reinstall could fix that
what you can also try is to make a new folder and git clone the repo again
Hi, I'm a member of the community with subscription, I use AI for artist projects.
I just now read that the outputs generated on your site are public and you publish them on the bulletin board and I would like to delete my creations, is it possible?
Alternatively, can I delete my profile?
Thanks if you can help me
On this site https://stability.ai/stable-video
Stability AI
Stability AI’s first open generative AI video model based on the image model Stable Diffusion.
Please send that question to the stability.ai support, we can not help you here
I sent several emails and also wrote in the chat on the site but I never got a response. Others told me to write here :/
Open a #1010934719455707218 ticket and ill see what I can do
ok thanks I'll try now because I've never made a tiket :/
Good morning ! Excuse me for disturbing you but I have a little problem with the stable installation.... can someone help me quickly? :3
Hey, please follow the install guide of the pinned messages of this channel depending on your gpu
Then make sure you have a good internet connection and that your PC time and date is right.
If your from asia, Russia, or Iran you may need a VPN for the install
did anyone know why that happened?

I know, it worked like a dime for me before, I will 100% reinstall my driver though tomorrow
I know it only takes a few seconds but not interesting in stable diffusion right now, I'm gaming 🥹
Make sure you whitelist the webui in any adblocker
Also what does the CMD shows?
cmd did not showing anything

i just launched webui and then it shows this error immediately
did you used the install script for MAC ?
yes
this from here?
https://github.com/viking1304/a1111-setup
no i used this https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
then use the one from my link, it will do everything automaticly and also sets the best parameters needed for mac
ok! THANKS!!
no problem 🙂 read the description on github how it works
been trying to install the zluda version on my pc but i get this error

seems like a bug with the latest update a few hours ago,
try to run this command inside a cmd inside the stable-diffusion-webui-directml folder
pip install torch==2.2.1 torchvision --index-url https://download.pytorch.org/whl/cu118
it's currently downloading torch
did it, it said success but still the same

go inside the venv
and rerun that command

looks okay
still the same
did you followed my zluda guide?
i did
okay
whats the cmd showing now?

oh thats not how you run a command in the venv
@timber coyote you need to run the Activate.bat via a cmd inside the SD-Zluda-webui\stable-diffusion-webui-directml\venv\Scripts

that should work
it seems to be working
should i do anything for the SD.Next?

nope, sd next is not needed
it launched in my browser but after generating

whats your gpu?
7900xtx
okay, same as me,
how does your paths looke like? in the environment settings

running at 24.3.1, says up to date
which zluda verison did you downloaded?
v3.7
okay whats your cpu?
7950x3d
okay you may need to disable the Igpu from the cpu
in the devicemanager
the selected one right?

yes
still the same, also

that looks okay

when do you get this?
after pressing generate
also i hope you have skipped the step with the rocm library folder (because for a 7900xtx its not needed)
i did skip that
try restart the PC
@timber coyote
if it still crashes then do this:
go into the C:\ZLUDA\ Folder.
There copy the cublas.dll and the cusparse.dll and paste them inside it again.
Rename the copys to cublas64_11.dll and cusparse64_11.dll
Copy these two files to stable-diffusion-webui\venv\Lib\site-packages\torch\lib, and overwrite if asked.
then relaunch the webui-user.bat
seems to be stuck on this

it launched -> generating now
perfect, let it run
it can take up 15-40 mins
for the first gen
is that for every new model or just the very first gen?
only for the very first gen
and if you update zluda versions
it's already done

perfect
thank you very much for your help
no problem 🙂
can someone help me please? why is this impaint thing NOT IMPAINTING at ALL

this should have been a dragon , but seems like torch is failed how can i fix it ? pip uninistall not working

what settings did you used?
make sure to selecte Inpaint Area to "only masked" and then set the resolution to 768x768
still doesn't work btw
uninstalled my driver in device manager rebooted, did a fresh install of the whole thing
still not working
@ornate elk got anymore suggestions
or should I try a reset of the pc
What's your pyhton version?
Hey folks, installed stable diffusion webui yesterday. Did a few generations that worked well but were EXTREMELY slow, like 70 second per iteration. I'm running an rtx 3070, 48gb of ram and a 3700x processor. I'm not entirely sure what I'm doing wrong, I've updated my drivers and I've ran the userwebui bat code to install xformers.
(Also included a test generation I did with 512x512, 8 interations and some generic peramaters just to test speed. Even that was super slow)


idk nothing about anything but use your task manager to see if it is using your cpu

that's it at full use
you need to edit your webui-user.bat
at the line COMMANDLINE_ARGS=
you need to add: --xformers --medvram-sdxl --no-half-vae
then save and relaunch the webui-user.bat
I'll try that
testing now with a 10 it generation
That's alot better, it's now at 1it/s
I'm using a complex model and I think that's around where it's normal to get
btw guys any help for not making her in white top all the time?


is that better?
That's the best for 8gb vram cards
Because your using an sdxl model
Oh, should I be looking at lower end models?
You don't need to, but if you want faster speed then try out some 1.5 models, these are usually 2gb in size and much faster
Sdxl models are trained on 1024x1024 resolution, while 1.5 models are trained on 512x512
So use upscaling for 1.5 models to get higher res
There is one
Gotcha
can you send it to me?

Pony Diffusion V6 is a versatile SDXL finetune capable of producing stunning SFW and NSFW visuals of various anthro, feral, or humanoids species an...
cheers!
I'm looking for a checkpoint, lora, etc... which may be able to generate cartoonish facial expressions like this. At the moment I'm using 3DAnimationDiffusion, but I get a lot of struggle on giving my characters expressions like this.

White woman triggers the top color
@ornate elknothing just standart settings
Hey folks, I just tried to run an image with a new workflow. and I get the following:
Error occurred when executing KSampler SDXL (Eff.):
module 'efficiency-nodes-comfyui.py.smZ_cfg_denoiser' has no attribute 'SDKSampler'
File "C:\ComfyUI\ComfyUI\execution.py", line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "C:\ComfyUI\ComfyUI\execution.py", line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "C:\ComfyUI\ComfyUI\execution.py", line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "C:\ComfyUI\ComfyUI\custom_nodes\efficiency-nodes-comfyui\efficiency_nodes.py", line 2246, in sample_sdxl
return super().sample(sdxl_tuple, noise_seed, steps, cfg, sampler_name, scheduler,
File "C:\ComfyUI\ComfyUI\custom_nodes\efficiency-nodes-comfyui\efficiency_nodes.py", line 713, in sample
samples, images, gifs, preview = process_latent_image(model, seed, steps, cfg, sampler_name, scheduler,
File "C:\ComfyUI\ComfyUI\custom_nodes\efficiency-nodes-comfyui\efficiency_nodes.py", line 483, in process_latent_image
comfy.samplers.KSampler = smZ_cfg_denoiser.SDKSampler

NotImplementedError: No operator found for memory_efficient_attention_forward with inputs: query : shape=(1, 4096, 1, 512) (torch.float16) key : shape=(1, 4096, 1, 512) (torch.float16) value : shape=(1, 4096, 1, 512) (torch.float16) attn_bias : <class 'NoneType'> p : 0.0 cutlassF is not supported because: xFormers wasn't build with CUDA support Operator wasn't built - see python -m xformers.info for more info flshattF is not supported because: xFormers wasn't build with CUDA support max(query.shape[-1] != value.shape[-1]) > 128 Operator wasn't built - see python -m xformers.info for more info tritonflashattF is not supported because: xFormers wasn't build with CUDA support max(query.shape[-1] != value.shape[-1]) > 128 Operator wasn't built - see python -m xformers.info for more info triton is not available requires A100 GPU smallkF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float16 (supported: {torch.float32}) max(query.shape[-1] != value.shape[-1]) > 32 Operator wasn't built - see python -m xformers.info for more info unsupported embed per head: 512
Time taken: 0.7 sec
Can you try an other model?
For example dreamshaper v8 from civitai.com
Also what's your gpu and what's inside your webui-user.bat?
You need to look backwards at the node connected before that where sdxl_tuple is connected and check that everything there is correct. Also, having "refine_at_step" as a negative number is weird to me...you might need to set that to a normal number. (Though I'd recommend not using Efficiency Nodes at all anyway, but that's just me.)
Is there anyway you would be ok with sharing your workflow? I don't really care what workflow I use as long as it is good. and has a spot for loras
It would also be nice if it had a spot for a base checkpoint and refiner checkpoint
If you're using a good SDXL model, you don't really need a refiner. You can, but you don't need to.
But you should learn howthe stuff works. Start with something very basic. I have a super simple basic workflow to start people off with. No refiner, but works great with decent models.
You can start here:
Discord is being stupid.
I was able to download it.

So...to add LoRA support, simply stick a "Load LoRA" node in between the "Load Checkpoint" and "Positive" & "Negative" nodes in that flow.
(Note that there are a ton of ways you can do this kind of thing and many little tiny changes will result in different end images.)

Yeah, that will work.
Once you understand little bits of things, swap orders of things or adjust settings to one extreme in one place to see what will happen. Learn what each setting does, what the vocabulary is, etc. Then you can make much better images and experiment easier since you'll really understand what you're doing. Comfy isn't as difficult as some people think and a super easy workflow like the one I shared can help you learn.
Essentially, that workflow only has 8 nodes that are actually doing anything and technically, one of them is redundant, depending upon the model. (The "Load VAE" node could be taken out if your model has the VAE included.)
I leave it in because some models don't embed the VAE.
the issue i see is that there is no option for none. and when you bypass it. it throws an error. For the VAE box
You always have to have a VAE; that's what decodes the image from the latent noise. If you have a model with the VAE built in, you simply connect the VAE dot in the Load Model node directly to the VAE dot in the VAE Decoder node.
If you want to get fancy, you can drop in one of several "switch" nodes from people that will allow you to connect 2 or more VAE node sources into one where you pick which one you want. (One of my favorites is from rgthree that automatically chooses the first non-null input.)
Oh...and the other thing to understand is that although workflows tend to feel logically like they should be from left-to-right or top-to-bottom, they actually first look at the end result and work backwards to ensure there's a full path of execution.
that kinda makes sense... its like making sure there is a bridge ahead before driving over the water.
hello i just wanna ask what are the chances of getting a virus from --disable-safe-unpickle
i trusted the models i downloaded but needed the command just to be capable of running training
Not sure which VAE Switch you were referring to but is this essentially what it would look like?

my files corrupted so i deleted the whole thing but now im kinda scared of the possibilty of one of them being a virus
Comfyroll's VAE switch is just fine and an easy way to implement a switch like that.
Did you say the one you use does this automatically? What is the node called? Also I would really like to add a refiner model. How would I do that?
I'm sorry for asking so many questions... Its just I never really find anyone that breaks things down like this for specific things like this.
Look for the package from rgthree for the various switches he's got. But beware that he's got several things in his package that are pretty advanced.
As far as refinement for SDXL, it's really not used excessively anymore. But ultimately, you can do it several ways. If you wa;nt further examples, you can find a bunch of them here, directly from Comfy:
https://comfyanonymous.github.io/ComfyUI_examples/
That includes several examples for SDXL; with refinement if you insist:
https://comfyanonymous.github.io/ComfyUI_examples/sdxl/
For me the refinement is not as important and I agree with you... However my wife uses it and almost leverages the refinement process like a LoRA in itself where it allows the secondary model to change some of the finer details towards the end of the process. For example usually we would use an Anime style Checkpoint for the base and then a detailed checkpoint like Nightvision as the refiner... It makes some amazing results.
Instead of treating it like SDXL-specific refinement, you should use an Advanced KSampler node and learn to tune the denoising, passing that latent into another KSampler node for the "refinement" that you are doing now. From there, it's going to be easier to understand how you can make even more improvements by inserting other nodes into that mix.
In fact, you can take a fully denoised image, re-encode it into a latent, tune denoising down to between .5 and .8 to really play with styles.
Do you inject new prompts into the new latent space for the refinement? This is where I get confused.
You can, but keep in mind that when you use Comfy, it's all about doing whatever you want to do. Sometimes you'll get what you expect, sometimes you'll learn a lesson. Sometimes you'll stumble upon amazing results. But that's what makes it great; you can do just about whatever you want.
Hell, I have a workflow that doesn't have anything to do with image creation or manipulation at all. All it does is read in a directory of files, go through the images in the directory, & create a matching file with all the booru tags for the images.
You can even setup workflows that do complex math and have nothing to do with images at all, if you're so inclined and find the nodes you need.
I have so much to learn.
Hi guys, can someone send me some basic .toml settings for a standard SD model for LoRA training
So I feel like my process is really redundant and I still dont even have upscaling or hires fix I do think I'm starting to understand a bit about how this pasta dish is coming together though... Any thoughts on how I can consolidate or add upscaling and hires fix or implement some of the above things you mentioned?
I think I got the upscaler figured out possibly.
If you're patient, you could look into SUPIR. It's my favorite upscaler, but it does take a while to render. (Obviously depending upon hardware, resolution, & settings.)
I have a 4090 128gb DDR5 i9 etc... I really cant wait for the 5090 to launch
You should look into SUPIR, then. Go find the node pack in the manager, click on the link in the manager to go to the git site and read up on it there.
I suggest keeping the upscaler workflow separate once you figure out how it works, though. That way you can just pass images into it when you want.
sure hope it has the rumored 32gb
I don't even get out of bed for less than 48GB of GDDR7.
This is the look I have at the thought of that.

According to Anandtech, GDDR7 supports non-power-of-two capacities, including 24Gbit & 48Gbit chips. Max spec for GDDR7 is 64Gbit, though.
What's killer is the prefetch per-pin architecture. Each channel supports up to 32x8b per pin!
damn
yeah if it's a vram upgrade over the 4090 i'll buy it immediately (and keep the 4090)
4090 will remain as an inference card


awesome
What's up! Im having trouble with the stable diffusion 1.5 my computer is pretty slow but i have a school project to do with this and im running into some issues... I have an intel i7 processor with 16Gb of ram and a small NVIDIA GTX 750Ti... What could i do to make it work? i tried to run with --lowvram in the webui-user thing but that dosent seem to work since it dosent show anything when i try to generate a cat.. Could someone help troubleshoot this please? thanks!

that thing loaded for about 10 mins, before i tried to run it with the lowvram thing...
Isn't that only 2gb of vram?! 😂
You're gonna need a newer GPU
I'm amazed you can run it at all
idk man its a bad one lol
Yeahhhh nothing you can do
its running on overclock
You can't use fancy options to get around the fact your GPU is a decade old with like 1/4th what's generally seen as the minimum amount of vram
okok so basically, my thing ain't gon work? xD
Yeah you need a better GPU
Vram is the most important part
I don't think you can run it at all with less than 4gb and it'll suck ass at that
damn... allright welp that's bad lmao
What're you trying to do anywayw
basically, for college i need to make a video of presenting a local stored ai to a certain client.
and i thought that it would work on the school computers, but they dont run on NVIDIA so i thought well mine had one itll work xD
Hi
But allright, thank's for the help anyways, have a good one!
Yikes
They assigned you a project without providing a system that can run it? That sucks
It does, but hey its Quebec and a public college.. they dont even have the budget to get the IOS program for us to learn the language. We only do Android xD
they expect us to make up for their shitty budget lmao
but hey, would a 1660TI work?
with AMD?
or 2060 and Intel?
yes
both of those would work
they'd be a bit slow but they will work
ouch
sad that public education doesn't get funded too well
perfect, ill borrow my friends computer tomorrow and ill make the video there. Can i tag you in here if i ever get any problems?
you can try, but i'm usually away from here most of thurs and fri due to my work sched
I know, theyre money laudering tf out of us xD
there's a lot of ppl here who are usually glad to help
Allright well perfect, thanks a lot man, I wouldve wasted so mutch time xD realy thank you!
also real quick
if teh quality of what you get out of it matters at all
don't use the default model

SURPRISE ;) Merry Christmas, everyone. As a little Christmas gift for you all, I've been working on a new version for the SD 1.5 version of Juggern...
what do you mean by that?
the whole 1.5ema pruned blah blah safetensors thing at the top
that's the default sd15 model
it's pretty horrendous
you'll download this one and drop it in your stable diffusion folder... models/stable-diffusion
lmao, so this one would be worse quality but would still work?
refresh with the blue arrow
the edfault one will technically work but it looks like total ass

oh XDD

well my client is a tattoo artist, so i just need black lines on white background basically
client *
here's a high res one for ya in case you need it

looks trippy af

would it be able to create simple things like an outline of a shark? basically a drawing (tattoo style)
absolutely
just give it a shot
"tattoo art style, blah blah blah"
i'll warn ya though, if those generations are coming back quickly enough, you start to feel like a rat pushing a lever for cocaine
lmao, allright well ill try that out tomorrow and if i get back with something cool ill send it here lmao, thanks for the tips!
yup!
no prob
hopefully you get horribly addicted and you join the rest of us in a state of perpetual ruin and gratification
Hi, I just reinstalled Ubuntu, and now I'm having trouble running Automatic1111

bro,its my error, somebody know why error?


Is there a tutorial to instal comfyui on windows, amd rx6600 gpu? I have tried zluda a1111, but its still not good enough for my job(clothing)
Couldn't launch python
exit code: 9009
stderr:
Python was not found; run without arguments to install from the Microsoft Store, or disable this shortcut from Settings > Manage App Execution Aliases.
Launch unsuccessful. Exiting.
Press any key to continue . . .
Keep getting this error when starting webui-user.bat. Ive already installed SD fully and it worked the first time no problem but upon restarting its been doing this
What's your python version?
3.10.6
Then run the installer again and click modify, next, and then check "add python to system variables"
it has been
Okay then delete the venv folder and relaunch the webui-user.bat
Wheres that again?
Or install python 3.10.11 64bit
Also when i type python in cmd it redirects me to MS Store
Type in a cmd
where python

that windows python exe is a blank exe. IDK what it is but its locked behind alot of security
Try uninstall it via the App section of the system settings
its not there. Probably just a remnant
Ok
i installed 3.10.11 and its still not working
@ornate elk i deselected the app alias's for python 1 and 3 in settings and python works now
somehow they where asigned to the microsoft page
Okay strange but good that it works now
Completely works now
Don't forget to add the performance args to the webui-user.bat
Can you elaborate on what those are. I havent touched SD in a while
What's your gpu?
nvideia RTX 3050 TI 4GB(Laptop)
Ah then you need
--xformers --medvram --no-half-vae
Add these to the line COMMANDLINE_Args=
thanks!
Np, with that you get the best performance and have less vram usage. So you can do higher resolution generations
Also in the SD settings you should activate FP8 support for sdxl models
k