#🤝|tech-support
1 messages · Page 46 of 1
yea i did that



Links:
My Website:
https://jordain.ca/blog/threestudio-stablezero123/
Threestudio Repo:
https://github.com/threestudio-project/threestudio
Stable Zero123 Model Download:
https://huggingface.co/stabilityai/stable-zero123/resolve/main/stable_zero123.ckpt?download=true
Photoshop:
https://www.adobe.com/ca/products/photoshop.html
GIMP:
https://w...
this might help
i have never used that
i guess that's the CLI version, might try some time
dissappointed they closed the channel for it here because there's hardly any discussion places for it
Thats okay. i have a dual xeon 256gb of ram and 3 Tesla P40s so i wanted to try to get the most ot of all of them.
What can I use to replace moondream interrogator and show text so I can use my own text as a description?

Can I run stable diffusion on my GTX 950 2GB and ryzen 5 3600?
you might be able to run a stable diffusion 1.5 module on 2GB

hi, when I try to generate something
or do image to image
With sdxl?
What's in your webui-user.bat?
Which one is that?

The one where the filetype is windows batch file
@echo off
set PYTHON="C:\Users\logic\AppData\Local\Programs\Python\Python310\python.exe"
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --no-half-vae --device-id 0
git pull
call webui.bat
screenshot your whole webpage



what's in that controlnet tab ?

What size is your model file?
ok, try updating your extensions then

you can use txt2img fine with this model ?
Have you tried re-downloading?
nope
Seems like a bad model file to me.
I should get the latest version probably too
Yeah, 9 is good.
Same same.
downloading
Do other XL models work for you?
yes
hash does match with what's on civitai so the model is fine
which one should I get? lightning?

Have you completely shut down and restarted A1111?
@onyx solar yes
the problems started occuring after I lost my C: drive
reinstalled windows etc
lighting is faster but quality takes a hit
Regular model would be better than lightning
I see I'll get both haha
I was assuming it's weird, but I don't know why haha
my 3090 is in the second slot, but it's id 0 seems like
looks like it to me
My 3080 is stuck in the motherboard, can't take it out even to sell
can you delete the venv folder and try again ?
Also please provide a full console log, not just screenshot.
Stuck in the motherboard?
copy paste the whole log in a .txt and drop it in there
yeah
let me try
Did you push down the release that is at the back end of the slot?
ok
deleting vnev folder now
will you help me bring back my settings later? haha
your settings are safe

What motherboard do you have in your PC?
I've been away from stable diffusion for 3 weeks probably, is anything new happening?
@onyx solar I don't remember
will this get the correct version now?
Modern PCIe slots have a release you have to press down on to get the card out of the slot.
it's getting as you speak
I know, it's unpressable, broke or something
😄
Anyone living in Glendale, CA feel free to come by and take it out lol
can I get 4090 if I sell my 3090 and 3080? how are the prices now?
definitely not :p
got my 3090 overpriced for 2500 back than
not good not good lol
4090 is still "I hope you're born with 3 kidneys" price level.
snap
just checked, it's not too far off
I could sell both add a few hundred and get 4090 prolly
I mean sure
it's probably not worth it though
if you have "a few hundreds" lying around
haha
Honestly, I think you need to try to remove that 3080 just for my sanity. If the clip was broken, you'd be able to just pull the card out of the slot. The clip is pushed downward, toward the motherboard to release.
come to my office take it out, I tried
I mean sure I can use all my strength, but I'm sure if I do that, the earth will change it's orbit axis
I'm halfway across the country...but I assure you, if the clip is there it's probably that you didn't push the clip down enough.
I will break everything
I can take out my 3090 easily
Are you sure you unscrewed both sets of screws on the mounting bracket where things plug in?
I've literally worked on hundreds of performance PCs in my life...those are typically the only things I've run into that would stop you from removing the card.
how is that auto1111 venv rebuild going ?
yeah I don't even know what screws are you talking about, but maybe we should go live and try it 😄

The ones that hold the card in the case at the back plate.
very close to the end
I don't wanna touch my PC anymore. I live it be as is, I'm afrain to f it up
it's making noises and stuff
Your PC is closer to Lego than a complex machine at this point. It's actually rather difficult to fuck it up.
hahaha

lmaoooo
free 3080
Exactly
closed beta for now

let it be, give it a minute
Patience, Daniel-san.

something is wrong with mmyolo's adetailer stuff but let's ignore it for now
even if I disable it give me an error
okay let's not ignore it then
can you disable the extension altogether in the extension tab ?
restart sdwebui afterwards
Still seems like the 8 file has an issue, especially if 9 works.
urgh that's just weirder then
restarting (reloading UI)
but it's 2:00 am and I need a freaking shower.
You caught me right after my workout with the "disable-nan-check" stuff
that just triggered me enough to sit here and deal with it
😄

No wonder it stinks here.
disabled adetailer from extensions
ok screw JN8 I hope that's the only thing that doesn't work
tldr btw: disable-nan-check is just gonna remove some "safety check" from SD's pipeline.... So in case there's a problem with the generation it will ignore them and continue as if nothing happened.... sure you won't get an error.... but also 99% you also won't get an output
I'm not gonna disable that
So you'll be sitting here looking at a totally black output, without any error message, with nothing to investigate
Every time someone suggest using --disable-nan-check it adds 1 day of delay to the release of sd3
there I spilled the beans

tbh that's what I'm afraid of.
perfect adetailing the screwed face
if it was only a JN8 issue then .... weird but ok I can live with it....
Well, that was fun...lost power due to a lightning strike for a moment.
if anything comes up, I will let you know
but I'm afraid we'll see each other again in a couple of days with some similar issues
hahaha
before you go
any cool things with SD in the past 3 weeks I was missing?
any new cool tools?
not much, there's some cool papers but nothing big has been released.
the spotlight is on sd3
any update to Instant_ID maybe?
it's been released for quite a while by now
I was hoping to get Instand ID with higher CFG scale
so I don't get boring pictures
Most of the official manuals for AMD involves --disable-nan-check as a remedy at some point, don't blame the common folk for that 😂

AMD cpu?
GPU, you are safe, don't worry
🙂
Those AMD install instructions haven't been updated for months if not a year by now.
Check pinned for more updated ones. (there's two AMD guides over there, the zluda being the more complex but fastest option)
The only legit usage I can image for --disable-nan-check if is someone is running a metric ton of generation. Let's say he launched a deforum batch for 1000 frames.
And then they let their computer do the work at night.
Then yeah ok maybe... why not.... you don't want it to stop at the first error.

its like this
and I still get the issue
someone told me this too

but idk how to find the torch and cuda version
if youre using a1 then its at the very bottom
looks like this
i think there is a torch 2.1/cuda121 binary, but yeah its a losing game keeping up with xformers. im constantly gushing about forge, but if you've a low end pc the optimizations in forge over a1111 make xformers pointless and i think in general its a bit "old hat" now. the issue is, old guides send you to old install links etc and what was bleeding edge 8 months ago is slow as hell compared to modern things
sometimes the face detailer just outputs a black square, is there a solution?

Does anyone know of a way (maybe with a plugin) that I can change how the search for node functionality works in comfyui (double right click).
I am trying to create workflows using a wearing a VR Headset, but because the keyboard is separate in VR and makes the mouse move out of the search box bounds it will always disappear before I can use my VR keyboard.
It would be nice if there was a setting to disable it disappearing when the mouse goes out of the bounds.
My workaround for now is just learning where all the nodes are in the node tree, or by using the suggested nodes when you drag on an output/input.
what app is this looks so good
when trying to img2img,
resize: from 768x432 to 960x540
using 1.25 scale
it returns
TypeError: 'NoneType' object is not iterable
Time taken: 8.4 sec.
but it works at 1.5 scale, once that is done i can use 1.25 with no issue
seems that resolution should be fine im not sure what the problem is

File "D:\SD-ForgeUI\system\python\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context return func(*args, **kwargs) File "D:\SD-ForgeUI\webui\ldm_patched\modules\utils.py", line 439, in tiled_scale out[:,:,round(y*upscale_amount):round((y+tile_y)*upscale_amount),round(x*upscale_amount):round((x+tile_x)*upscale_amount)] += ps * mask RuntimeError: The size of tensor a (12) must match the size of tensor b (11) at non-singleton dimension 2 The size of tensor a (12) must match the size of tensor b (11) at non-singleton dimension 2
sounds like some type of resolution rounding error but they are even numbers ><
disabling tiled VAE seems to fix the issue,, SD-forge
Sorry a bit off topic, anyone has experience using and installing QWEN-VL locally on Windows? I could use some help.
try to stick with multiples of 8 (540/8 = 67.5) => go with 544
https://www.youtube.com/watch?v=1Ef_nu7DGwk The video im using sorry if this is advertisement. But the first 2 step, pip update and xformer just doesnt work and it hurts

In this video, I explain:
- Essentials extensions and settings for Stable Diffusion for the use with Civit AI.
- Civit AI Models
- How to use Civit AI Models
- Tips and Tricks on Prompting with Civit AI
Relevant Links / Commands:
Channel Support (YouTube Membership): https://www.youtube.com/@controlaltai/join
Xfo...
to ugrade pip (not needed), you just have to copy paste the green line it gives you at startup when warning you about a pip update. not sure why he made it more complicated than it needed to be.
and for xformers I need more informations than just "it doesnt work"
ok I figured this had something to do with it, was hoping multiples of 2 would be enough
or like I'll tuse manual resolution instead of the slider hmm
although just disabling the never oom tired vae thing worked
tiled*
whats in your webui-user.bat?
and whats the error you get?
they never answered me so I think they figured it out :p
I tried the --xreforms still give me no module
then I tried the the update pip
and it said I didnt have it
can you screenshot the webui-user.bat? and tell your gpu model

you also need to add --medvram --no-half-vae
after that launch the webui-user.bat
sorry I didnt see I assume people pings. I don't understand the upgrade, it just says I dont have it installed

?
yes
that s not gonna fix your "xformers issue" tho
start your sdwebui and give is the full console log (put it in a .txt and drop said file in here)
make sure to launch the webui-user.bat and not the webui.bat

looks good
yes always the webui-user.bat
ok ty
the next step is pip upgrade
what am I suppose to do with that
you explained it, but I didnt quite get it
you should install python 3.10.11 64 bit first, then the pip will be updated too
sorry not questioning you, but why? I thought the video specifically said to use this version

This video describes the basic steps of installing stable diffusion v1.5 and v2.1 on Windows.
Relevant Links / Commands:
Channel Support (YouTube Membership): https://www.youtube.com/@controlaltai/join
Python 3.10.6 Download: https://www.python.org/downloads/release/python-3106/
Git: https://git-scm.com/download/win
...
this video is 11 months old xD in AI time thats years, a lot changed
0nce you ve updated to 3.10.11, you ll have to delete your stable-diffusion-master/venv folder (it will rebuild itself using the new python)
That make alot of sense
so uninstall this python and get new
or just install new
Please do not use python 3.11, 3,.12, etc
download
ok
everything you need to know is here in my install guide: (also direct links to python)
#🤝|tech-support message
I currently have 3.10
you have 3.10.6
any info on what 'selfattentionguidance integrated' and 'stylealign align' options do in sd-forge?
@ornate elkdoes this mean wait

It been like this for a while
nvm ok its done
and continues following the tutorial or should I follow your?
my guide is only for the installation part, if your now on the webui in browser, your done
but i would say, check for more updated guides and not videos older than 6 months
do you have a recommendation? I dont want to choose a video and eat sht again @ornate elk
no i dont know any recent basic videos
ok what if I follow this video and if theres problem I come nag you? lol
please dont follow that 11 months old video
it suggest a bad model version you dont need
also it only covers the installation, and your done with that already
what about lycoris and wildcard extension
not needed
what did it used to do?
lycoris is outdated and got integrated into lora
so get lora or
wildcard can still be used but your new, so dont xD start easy
get a model (checkpoint)
if you watch that video, you can follow up from minute 6:04
that should be fine
ty
ok ty
at minute 17, you shouldnt do that (setting ESDN) , and hes wrong, it doesnt improve anything
alright
also i would recommend try out the werbui for yourself instead of copy images and reproduce them
you will learn more with just trying out
Thats what im thinking but I need to learn prompts and neg prompt
for negative you can try these basics:
disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, blurry, b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms, fashion photos (collage:1.25), meme, deformed, elongated, twisted fingers, strabismus, closed eyes, blurred, watermark
ty
*If possible, it would be easier to notice if you write in a reply.
oh, my bad. actually for training, finetunning related question. You might be better off asking in #🔧|finetune
Oh… Thank you, I understand.
Copy and paste it over there.
my lora files arent working and im not sure what is the problem because i only get error messages for some but none for others
whats the error you get?
RuntimeError: The size of tensor a (32) must match the size of tensor b (64) at non-singleton dimension 3
im not sure if thats the whole error
make sure the loras you try are for the spcific model version
sdxl and 1.5 need different loras
yes they all say that their base model is sd 1.5
which is what im running
am i wrong?
can you screenshot the full error and your used settings?
is your webui updated?
no its okay, if you installed it today
can you share me the link to the model and lora ?
hi
where are the bots on this server?
i dont have a gpu but i love stable diffusion where have they gone ;-;
Hi all,
I'm trying to install Automatic1111 on a reinstalled PC, and I'm having troubles to install torch:
Installing torch and torchvision
Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu121
Collecting torch==2.1.2
Using cached https://download.pytorch.org/whl/cu121/torch-2.1.2%2Bcu121-cp310-cp310-win_amd64.whl (2473.9 MB)
ERROR: THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE. If you have updated the package versions, please update the hashes. Otherwise, examine the package contents carefully; someone may have tampered with them.
torch==2.1.2 from https://download.pytorch.org/whl/cu121/torch-2.1.2%2Bcu121-cp310-cp310-win_amd64.whl#sha256=9925143dece0e63c5404a72d59eb668ef78795418e96b576f94d75dcea6030b9:
Expected sha256 9925143dece0e63c5404a72d59eb668ef78795418e96b576f94d75dcea6030b9
Got 8bcfe0b97168c713c041994fcc1774031d22ca72daf9d84796425b268a81aa2d
I tried a manual installation with pip:
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
with the same result
I tried to instal the 2.1.1 version and it was sucessful so I suspect the isuue is in the original repo.
Do you know any other way to install torch 2.1.2?
whats the best image tagger tool to implement in comfyui workflow?
Can anyone help me by explaining how the supermerger extension works (the Merge Block Weights function and the LoRA merging)?
Can anybody help me with this problem, the image mophes constantly. Im with a 1111 web ui

RuntimeError: don't know how to restore data location of torch.storage.UntypedStorage (tagged with privateuseone:0)
I think controlnet is causing this issue because i've never had this happen prior to it
run pip cache purge to get rid of your corrupted torch package and try again
Is there a version of https://github.com/Stability-AI/generative-models/blob/main/scripts/sampling/simple_video_sample.py that works with 24 GB VRAM or less?
I don't want to use diffusers because it hides too much of the detail and I've been bitten by not being able to repeat my environment nicely when huggingface is down. (further if I get around to training a finetune, I'd like to be able to handle just keeping track of the relevant safetensors file rather than the full huggingface repo deal)
sorry to ask but python 3.10.9 work with controlnet because i dont have preview ?
Yes should work
Do you have the models
yes
Did you clicked the explosion icon?
???
wait
lol so it was that ... 1 day lost ...lol thanks
i m running on a old laptop with a gtx1060 ti 6g of vram (wort 700$) ... it amazing it work locally
RuntimeError: don't know how to restore data location of torch.storage.UntypedStorage (tagged with privateuseone:0)
I think controlnet is causing this issue because i've never had this happen prior to it
Nice, make sure to use --xformers --medvram --no-half-vae for the best performance
happens when I try to use highres fix
ok thanks i ll add your arg 🙂
yes it work with your arg thanks
Nice np 🙂
which is more important, that height and width are divisible by 64 or that the resolution is? (assuming using standard aspect ratios, nothing wacky)
a other one ? ok it show me my skeleton full body like this

but when i edit the skeleton it give me this ...no face ?

it try to add one but it ask me a json file ?
its mostly for adding expressions from other images

ok i dont have any 😦
make one with controlnet, press the json button it will save it


hi, i was wondering if anyone could help me with a quick question. i just got a1111 and when i generate images, it says it runs out of VRAM at 3GB. But my computer has 8GB of Vram and isn't using anything else. is there any way i can allocate more to the program so it stops failing?
Hey everyone, new here and following the pinned AMD tutorial, when installing the HIP SDK I'm getting error 215, any idea why? My graphics card is a Radeon 6600xt

(clicking get more details gets me here)

umm help I reinstall window and when I try reinstall SD at first I use python 3.12 which doesn't work so I uninstall it and install 3.10 now it got this how do I fix it?

it still seems to want to use old path
to wrong version
I even deleted the 312 from path here

ya know what I just reinstall the whole thing and it just work so yea
Hey install the latest Adrenalin driver
Then install the hip SDK
Hey, checkout my guide at Step 5 for the vram optimisation you need:
#🤝|tech-support message
Deleting the venv would have fixed it
thanks will try to remember that next time similar problem arise
thanks! just to be clear, it should look like this?

It appears I'm getting errors even trying to update my adrelanin drivers, might update to w11 while we're at it and clean c drive 
ok i figure a way out ... adding a face is not easy you need a view where you can see all the dot a there proper place open mouth is better to move the dots. thanks to you

you can update but win11 is not needed for SD.
but in any case open up a cmd as admin and run
sfc /scannow
that will check windows for os file corruptions
Oh thanks, it said that it did find some corrupt files and repaired them
Lets try updating drivers again
run windows update and restart the pc
before trying
ohh alr
Seems like I'm getting another error on windows update 😅

"Retry" gives the same error after too 🤔
Should I just try and format the PC? Idk if there's any quick way to fix that
nah thats a common error fro ma few weeks ago
there's a windows 10 update that has some problems with some computers for the past few weeks
I had it too. Let it be for now, there's probably gonna be another update to replace this one in a couple of weeks
Oh I see
Then I should just reboot and try installing the drivers right? (On this alr)

Should I try to uninstall "AMD Software" and try installing drivers again?

Um hello im new in python also in stable difussion but I already searching the solution of my eror in here but nothing works, I watching this guy video
https://youtu.be/onmqbI5XPH8?si=uLDZdhrTTD0Rh_de
um maybe there's any new updates turtorial?
Btw this is my trouble
C\Unstable-diffusion\stable-diffusion-webui>git pull
Already up to date.
exit code: 1
stderr:
C:\msys64\ucrt64\bin\python.exe: No module named pip
Launch unsuccessful. Exiting.
Press any key to continue . . .

In this step-by-step tutorial, learn how to download and run Stable Diffusion to generate images from text descriptions.
📚 RESOURCES
- Stable Diffusion web demo: https://huggingface.co/spaces/stabilityai/stable-diffusion
- Install Git: https://git-scm.com/download/win
- Install Python: https://www.python.org/downloads/release/python-3106/
- Sta...
dont install the pro driver
the blue one
Okay! Installed the right one this time

Should I remove the HIP SDK stuff since it gave an error last time?

And try to re-install it? Or just go with it
no you can leave them as is
Alrighty, I'm gonna keep following the pinned tutorial let's see if I can complete it ><
Thanks for the help ^^
use the pinned tutorials please, this video is almost old enough to drive.
Okayy
Hello, today i wanted to train an stable diffusion model, but, When i tried to extract the stable diffusion model into the working folder for dreambooth, It gave me some error regarding githubcontent, for some reason i cant extract my models when yesterday it seemed fine?
Note to self: do not upgrade your Mac!

It looks like, for some strange reason, some samplers are not working correctly on Macs updated to Sonoma 14.4 🤯
I use windows, but if i ever get a macbook ill keep it in mind, thanks
This basically happend if i try to train an stable diffusion model, please help!
socket.gaierror: [Errno 11004] getaddrinfo failed
those are connection problem, address cannot be resolved
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x0000025A8C2FB940>: Failed to resolve 'raw.githubusercontent.com' ([Errno 11004] getaddrinfo failed)"))
I already thought that, but i find it odd how theres a connection problem, 2 days ago everything worked fine, even the extension list wont load
connection to raw.githubusercontent.com fails
i can try to help with python and webui issues, but i cant help here, sorry
Thats okay, maybe this site is down and it will probaly work tommorow or another day, i guess ill try tommorow, thanks 😄
mac updated your python ?
No, Mac OS update (14.4) breaks the samplers!
i am still on 14.3.1
and it works fine for me
yup connection issues, ditch wifi for a cable. depending of your region get a better dns, or turn it off. Also why using auto1111 1.8.0 RC ?
im suprised apple let you update. they like to make mobile devices obsolete and useless

GitHub
Mac users: Please provide feedback on if these instructions do or don't work for you, and if anything is unclear or you are otherwise still having problems with your install that are not curren...
I used kohya before to train an re:zero checkpoint, but it showed a black image if i generated, and to me, dreambooth ui for stable diffusion was the best option
APPLE MacBook Pro 14 M3 Pro 18GB/1TB
purchased this month 🙂
as much as I love to take a dump on apple that would be the worst move on their part to turn off updates this early :p
there was probably errors in your kohya_ss setup then
but I was more questioning the why sticking to the RC version ?
did you simply not rename the folder ?
Too lazy, to me, image gen is image gen, i dont care much about the name since the image generator is what matters 🙂
There weren't, if i train, no errors show up if it saves the checkpoint, thats the weird thing, it always shows black images for sm reason
i am installing MacOS 14.4 in VM, so I can test this myself
What webui auto 11 extension is best for connecting to civitAI? I recently got civitai browser+. I connected the api key and everything, and It worked at first, but now i cannot search for anything in webui. getting, KeyError: 'totalPages', but was getting a different error before restarting. Any help with settings would be appreciated, or should I use a different one?
api key in civitai browser plus?
for "normal" use to download models, you do not need that
i have never set it
hmm, kk ill remove it
Feature: Filter option to show favorited models. (requires personal API key)
Useful for CivitAI supporters, you can use your own API Key to allow downloading Early Access models
Im still getting this error:
File "C:\stable-diffusion\stable-diffusion-webui-directml\extensions\sd-civitai-browser-plus\scripts\civitai_api.py", line 535, in update_model_list
(hasPrev, hasNext, current_page, total_pages) = pagecontrol(gl.json_data)
File "C:\stable-diffusion\stable-diffusion-webui-directml\extensions\sd-civitai-browser-plus\scripts\civitai_api.py", line 482, in pagecontrol
total_pages = f"{json_data['metadata']['totalPages']}"
KeyError: 'totalPages'
have you tried to update extensions?
is there anything i should change?

looks fine, try to update the extension
i can't check my settings, since i am running test instance of forge in vm 🙈
@vocal burrow i cant make a1111 work in vm, but i managed to run forge and i am getting normal images

nevermind, extension broke from Civitai Api change as per git, 2 hours ago
I mean I can go back to my parent's place and try on their apple 2. No not an m2, an apple 2. Surely one letter in the name won't matter that much.
Jokes aside it looks like the sampler did absolutely nothing. It's just noise.
The lack of log does not help figuring out what could be going wrong,
did you try to run a x/y script output ?
I don't know why it would cause it. But maybe ?
and in cpu only mode
i cant make it work with gpu in vm 😦
i even tried to mess with memory limit
i have a question, is there a way i can locally host a chatbot and connect it to comfyui/any other ui, and have it generate images for me while also being able to chat with it, like bingAI, but locally on my pc without limitations
sorry for the ping but ik u guys might probably have an answer @ornate elk @vocal burrow
like a pygmalion model connected to stable diffusion
There are many solutions for that, eg : https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/9708/files , https://github.com/hallatore/stable-diffusion-webui-chatgpt-utilities , etc
Not sure why you d want to use them unless you re generating hundreds of images like a some kind of factory. If you re putting the effort to ask chatgpt what you want.... then just put it directly into a1111.... plus none of those solutions are gonna know about the lora/embeddings/regional prompter/controlnet, etc
There is no "read my mind cause even I don`t know what I want exactly myself" extension yet
@zinc arrow
Nono i mean like a normal chatbot using a pygmalionai model, but like if i tell it to generate an image, it actually outputs one
alright ty
oh, yes you can
you can have it set to trigger writing a prompt and sending it to A1111 from textgen ui and then show it inline
you can also show it a picture and it will BLIP interrogate and tell you what it "sees" 🙂
but llms locally are still kinda pointless
I have Stable diffusion set up how it was before and it keeps generating really terrible images of just Noise I am using the same model that worked before but i dont know what i have done 😂

that s not what they want tho
they want an all in one solution, a model capable of llm and image generation
and being a chatbot? that makes no sense. but all those things can be done
i suppose hooking it in as a chatbot to a server would be the only thing
they want chatgpt at home basically. Probably running on a toaster with 2gb of vram too
not happening nowadays
well....6gb vram and i can run quantized 7billion models. 🙂
i do
:3
they just take turns, you can run both at once 🙂
no, its quickly loading offloading
depends of the hardware
not noticably really. though i havent tried hooking with forge which does a lot of loading foo
if you only have 16gb you ll run out of place to store those models relatively fast
nvidia/cuda stream does help a lot for fast loading, not sure if there s an amd solution for that
etc
what settings ?
I m betting that the cfg value is through the roof
No, I have it at 7, i have tried moving it around but still bad
ok but what settings then ?
i solved it, Just bad model version
you were using a lora as a sd model, weren t you.
no
It was the correct format
Just bad version
I just went back a version on the model and it works fine now ;))
that doesn't make much sense but ok.
hello i already tried pinned turtorial but found some problems
exit code: 1
stderr:
C:\msys64\ucrt64\bin\python.exe: No module named pip
Launch unsuccessful. Exiting.
Press any key to continue . . .
is there any solution please
Thank you sir
hy guys, i have problem with IP-adapter , anybody can help? and the result of image is blurry too. I use dreamshaper XL as the checkpoint. thankss

looks like a clash in models or summin, i dunno, just guessing, maybe you can screen shot your setup

or is it because I'm wrong at placing the model in the folder?
damn bro i dunno, have to wait for someone else 😅 can you show yr control net
so im really new to all of this and have been having some problems with SDLX ive downloaded the stable diffusion local UI and also the SD_XL_base and the SD_XL_refiner models form hugging face. i got all of it to download and run however the images im getting form it are underwheming to say the least. my pc is by no means a beast but i do have 8GB of VRAM i was wonding if anyone might know the problem and if there is a fix for it. ive included the image the model has put out and can give more info on the models if needed any help would be great. Cheers!

Did you download the SDXLVAE?
i think thats defos the problem here
what is that? 😛
do i add it the same way i did for the other two models?
yea to yr vae folder
oh ok i checked it and its empty so i was def missing that
and then go to settings and make sure you can set custom VAE or summin like that
ok ill do download and update that then report back! thanks for the help
holding thumbs
Guys, what do I do if SDXL takes too long to load?
I was generating quickly in the usual SD then I switched to SDXL there it is very slow loading do you think if I remove venv everything will work out?
already did
no idea but it will reinstall the venv folder
what do you mean by loading?
like loading the model?
I mean generating the image in txt2img
ahh yea
depends on yr setup but SDXL is slower for less fortunate setups like mine
check mine
Steps: 10, Sampler: DPM++ 2S a Karras, CFG scale: 1.5, Seed: 3892332, Size: 1024x1024
Time taken: 50 min. 37.5 sec.
bbrrrruuuhhh
Maybe it's because I have 4gb
and thats the turbo model
yea mine is too
What's your average generation time
this 😂
yea some guy said so the other day that the 4gb'ers suffer with the XL models
So we're losers with 4gb😂
well we lose time thats for sure, but we can still participate so feeling grateful 😂
😂
well hmm this was the result.... idk what happened

like the ui?
yea

ok i set it to that having it redraw it
(it might take a min) even with 8GB of VRAM 😐
bro try find the settings where you can see models and vae on thr side
see the left side of mine

what ui is that?
"quick setting"
Lobe theme
I dont have Vae cause dreamshaperXL has it already apparently
also dont see your refiner
should i have dreamshaperXL? i never added it
its faster LCM model
DreamShaper XL - Now Turbo! Also check out the 1.5 DreamShaper page Check the version description below (bottom right) for more info and add a ❤️ to...
im looking under the VAE settings but this is all i see

under extensions
ok im downloading it now


ok i got it loaded and added to the side bar


i don't see the "refiner" tab is is disabled by default?
under steps
oh im blind i see it now
bro its got ,me a few times lol
should i go head and test it now? or are there any other steps i need to do before testing

kkkk
Careful, there. One less "k" and you'll need to prompt for a white hooded outfit.
literally thought that as i typed it 😅
(this make take a min) will report back with result
thx so much for the help so far i would have been at this for days without it
trial and error bro
happy to help 
ok update i messed and forgot to add the refiner model so i got to restart 
whats that
.>
control net is the genies gift
oooh do tell
like you keep the design but change the reuslt

not just random images but more controlled images
YES PLS
a whole world of technical headaches to go with it too
lol
not really but def worth learning
yea one thing at a time
ETA says and hour and 30
what gpu you got?
yea xl takes longer
true true
well ima go get something to eat while i wait
ill either update ya later if your here or just talk to you tommow

Hi. I'm training an embeddings right now. This is the first time I have done such a thing. I am using 100 images of shoes and socks on peoples feet to see if that will help with weird toes. However as I just hit 3,000 steps. I was scouting for more images, and came across another batch of really good images. My question is, can I Add more images to the embedding training, or would I have to start over with the new images? I want to proccess the images, and drop them into the same folder as the Dataset directory and reboot the training but I am unsure if doing that would currupt the proccess and make it worse.
so i have tried to fix this problem from the existing ways,i found the same case but im confused how do i add the path inside webui-user.bat

My case is the same as this, only I am confused about adding paths to webui-user. bat
open bat file in notepad
add to command args

@solemn moon update if your still here... so its taking forever to render even a 680x680 size image ima have to do some research on a way to either speed it up or just find a differant model. thx again for all your help! ❤️
So I already follow quick guide for Nvidia but when I want to start I found
Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
I have gpu 0 nvidia,
gpu 1 amd Radeon
should i use amd tutorial instead of nvidia?
Sorry my English was bad
I got a Deep Learning VM on Google Cloud, a n1-standard-8 machine with 30 GB RAM, T4 GPU. I have set up generative models repo, and use port forwarding for the Streamlit demo/sampling.py app to run in my browser. First attempt was with 15 GB RAM instance, the Streamlit sampling example from the repo got killed due to maxed out RAM. I upgraded instance to 30GB RAM, and watching top while running the demo. During downloading of the CLIP model, the process maxed out ram and got killed. Should I upgrade to even more RAM, or adjust settings?
I have seen https://github.com/Stability-AI/generative-models/issues/36, but this happens before the app is loaded.
EDIT 2: Should I just drop the sampling demos, and use ComfyUI instead?
EDIT 3: on my Windows PC with 32 GB RAM, 2080 Super GPU 8GB VRAM, low VRAM mode,the Streamlit app loading process actually peaks RAM usage on 99% for a few minutes, and the process is not killed. The app loads as expected, and I can run the default txt2img sample with 1.85 it/s.

GitHub
Generative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub.
Does anyone know what type of model this guy uses?
https://www.youtube.com/shorts/f5L-9kzmiLU
is it even SD?

#shorts #history #alexander #ancientgreece
what does that mean
OutOfMemoryError: CUDA out of memory. Tried to allocate 40.50 GiB. GPU 0 has a total capacty of 11.99 GiB of which 0 bytes is free. Of the allocated memory 12.26 GiB is allocated by PyTorch, and 1.24 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Hey, you need some performance arguments in your webui-user.bat
--xformers --medvram-sdxl --no-half-vae
Add them to the line COMMANDLINE_ARGS=
Then relaunch the webui-user.bat
Can you list your gpu models?
What's your GPU and what's inside your webui-user.bat?
Here we go.
Hello, I have a question. I can't install SD because of error 3, it doesn't find the path.
C:\Users\Jeremy
Creating venv in directory C:\Users\Jéremy\stable-diffusion-webui\venv using python "C:\Users\JÚremy\AppData\Local\Programs\Python\Python310\python.exe"
Unable to create venv in directory "C:\Users\Jéremy\stable-diffusion-webui\venv"
exit code: 3
stderr:
The system cannot find the path specified.
Launch unsuccessful. Exiting.
Press any key to continue . . ."
I’m running python 3.10.11 and enabled path and I think it's because my user folder has "strange" characters.
I was able to change the administrator name but I can't change the user folder name.
Could you help me, please?
Hi, I need some help please to fix my stable diffusion webui. I use it in local on my windows 11. I have a deprecated message about pytorch_lightning.utilities.distributed.rank_zero_only, But I don't know what I can do. In the same time I have this message to at the launch.
I don't know how solve all issues... Can you help me please ?




You need to change your user name then restart the PC
Do you need Dreambooth?
Cause thats the problem here
@ornate elk not really, I think it's used to train model, right ?
@ornate elk I would like to try to train model, to test how do that it's why I have install it, but... in fact I use model from civitai. The install of dreambooth was for a test and see how work models training
Ah okay. I Wouldn't recommend using dreambooth in Stable-diffusion-webui because it breaks it often.
Would recommend using Khoya_ss for training as its a seperate tool.
To fix your issue. Delete the dreambooth extension of the Extension folder.
Then delete the venv folder and then relaunch
it will fix that too ?

Yes
anyone knows?
@ornate elkok I m going to try it, thx to you 😉
Looks like SD, but not any special model. I guess Photon, Juggernaut or realisticvision can do that
Is it only one? or he has many merged
And I would also want to know how can he make such complex scenes
where do i look it up?
I did it! 😕
We dont know but its mostly just a good prompt. Then he upscaled it and fixed the faces maybe
Can you show me the error again now?
In the taskmanager under performance GPU
And for the webui-user.bat. eight click and edit it
Creating venv in directory C:\Users\Jéremy\stable-diffusion-webui\venv using python "C:\Users\JÚremy\AppData\Local\Programs\Python\Python310\python.exe"
Unable to create venv in directory "C:\Users\Jéremy\stable-diffusion-webui\venv"
exit code: 3
stderr:
El sistema no puede encontrar la ruta especificada.
Launch unsuccessful. Exiting.
Presione una tecla para continuar . . .
Ah okay please delete the stable diffusion folder and then follow my install guide.
#🤝|tech-support message
Important is that you need to create a new folder like in step 1
Thanks!
On the other hand, the system offers me to upgrade to win 11, is it a good idea, is it worth it, could it help me to change the name of the user folder?
For now its not worth it. Win11 is still buggy
@ornate elk sorry... this error still remain during the launching without Dreambooth

After removing Dreambooth this is the launch log

What's your gpu? And is the driver updated?
I have a Nvidia RTX4080 with 551.76 drv
Is it the latest?
Hmm okay.
Its hard to troubleshoot stability matrix installations and I wouldn't recommend using it.
Because it just adds a layer of stuff that can break
I use this extensions :
Ohhhh
Tensor rt
Thats it
That extension causes problems
You would have to delete it too and then the venv folder again
Then the cudnn error should be gone
sorry I past new screenshot without my hotbar 😛

Okay xD
Its not needed. Its an experimental speedup thing for nvidia cards. But that thing isn't compatible with most of the SD stuff
How would i do that as a person with barely any coding experience
That’s not what i want
I also have an ryx3070 with 8gb
And what the other person said was exactly what i was looking for, a normal chatbot that automatically runs a prompt on a1111 when it hears a trigger word like generate
Not both in the same model
@ornate elk I still get this 3 errors, is it a problem or can be ignored ?
- Error caught was: No module named 'triton'
- E:\Stability Matrix\Packages\Stable Diffusion WebUI\venv\lib\site-packages\pytorch_lightning\utilities\distributed.py:258: LightningDeprecationWarning:
pytorch_lightning.utilities.distributed.rank_zero_onlyhas been deprecated in v1.8.1 and will be removed in v2.0.0. You can import it frompytorch_lightning.utilitiesinstead. - ERROR - failed to import mmyolo - MMCV==2.1.0 is used but incompatible. Please install mmcv>=2.0.0rc4, <2.1.0.

my stable diffusion strucked with "Commit hash:" command line
how can i fix it?
what is the missing image at the bottom of SD

If I have a specific promt, generate 20 images, find 4 seeds that I like and want to rerun all 4 of them with hires. fix. Is there any way to input all 4 seeds to run them in the same go? Or do I need to generate one at the time?
help me 🥲
it's not moving forward 🥲

how can i fix this bug ?
give it a minute
That step takes time.
xyz script
look for it at the bottom of the txt2img in the scripts section
there you'd want to set one column.row to seeds, input your seeds and voila
Amazing, thanks
If you dont get any issues you can ignore them.
But if something is broken you may need to disable all of the Extensions and then delete the venv again.
And then reenable them one by one
good day all and hope doing well. Does anybody know/use DeepFashion (ADetailer) ? Hugging face says This model has 5 files that have been marked as unsafe. so i dont want to just click download
The final step of having it work as a chatbot in say a discord would require programming, (or to find a repo that does links them up but i dont know of one nor have i written one).
But if you'd be happy enough having a local chatbot that you have 1-1 convos with the AI then the first step is to install text generation webui. I'd suggest looking up recent videos about its install and reading through its github for assistance, it can either be quick and painless or a weekends work. https://github.com/oobabooga/text-generation-webui that will let you do step one, run a local LLM. it already has inbuilt hooks and extensions for both working with the SD api to fetch/generate images.
I have oobagooba and a 7b model installed
oobabooga*
oh nice
Wait it already supports that??
and it doesnt require tokens or anything like that to link it to a discord bot right
I worded that wrong
It doesnt require payment*
no, you'd have to have someone do that part. thats the jump. but you CAN set it up to work locally and fetch from a1111's api to generate images
Okay thats exactly what i was looking for ty
I can use forge instead of a1111 right
yeah same thing
Ight bet tysm
in your settings tab there should be a tickbox currently unticked called somelike like SD-pictures-api. tick it
sorry, the settings tab is called "session" in this. for some reason. anyway, tick it.
when you reload the UI that should add this menu below the text input box. final step. for that to work, you need to make sure that forge is running its API so they can talk.

to add the API is simple enough. just put --api at the end of whatever your COMMANDLINE_ARGS are in webui-user.bat in forge\webui\ heres mine:

then run forge. once its booted up you can check if the connection works by pressing that big "get list of checkpoints" button
the rest should be self explanatory. you can just naturally ask it to send you a photo or pic. depending on the temperature settings it should always send you an image.

with forge, the first image send might take a good ~1min or so but after that it'll be just as fast as if you were to type into its UI yourself.
weirdly there is a lot less lag from the original a1111.
oh just be mindful of one thing: both textgen and forge run on gradio so whichever one is open first gets port 7860, when you load the second thing it gets port 7861 so you might have to change the port number on the api
oh shit i didnt see all that
im not gome rn but as soon as i am ill try it and get baxk to u
no problem. its all pretty self explanatory, and i think ive said everything you need, the rest is just playing around yourself. good luck!
Does Stability AI REST API work in China?

i did a bit of looking around and haven't seen stability's name pop up in any block lists. the likes of openai bing and huggingface are however closed off
I am drawing on stabble diffusion but it is taking too long, I think my computer is good enough, can you help me why is it taking so long?
32 GB RAM
RTX 4050 6VRAM
i5-13th Gen
Checkout my guide at Step 5 for the performance increasing settings needed:
#🤝|tech-support message
good day all and hope doing well. Does anybody know/use DeepFashion (ADetailer) ? Hugging face says This model has 5 files that have been marked as unsafe. so i dont want to just click download

dont download non safetensors versions of files
i have an example of a model.bin which when loaded can open calc. e: its not mine, should make that clear lol.
and it is still sitting on huggingface (though put up for research purposes by someone else)
hi, no idea what open calc is lol. Shame really like what i read about the deepfashion features but safety first. Super thks
calc.exe is your computer's calculator. its commonly used as an example in exploits to show that something malicious can run a program without you allowing it.
so Adetailer models risk in general it looks EEK glad did not download then. Thks again really helped
What about replicate?
i honestly dont know what china currently blocks as im not in china
.safetensors is fine
i just installed comfyui , after restart macbook, how can i run comfyui? please help
does forge webui use --listen just like a1111 or do i have to add something extra
Someone on the pygmalionAI server is telling me to use kobald, would kobald have a feature like this?
i know that having tried kobold for llms, it was - as of ~1 year ago - terrible on low end machines for memory and if IIRC you have an 8gb vram card which puts you in the low/medium end. it does pointless things like mounting itself separately and doubt it would be very efficient in terms of loading/offloading models on the fly. it might work nicer over a network but you had asked for two concurrent things locally. also that whole pygmalionAI scene isnt SFW and i'd rather not give tech support for it on this discord, questions about that might be better asked to them. 🙂
i think llms in general are out of the scope of this channel, i was just helping because there happened to be an existing tie in with SD from something i was familiar with. you could try the koboldAI discord i guess.
Ah okay mb ty tho
Understandable
no harm in trying with koboldAI
Another question, actually related to sd this time,
why does --listen not work for me on forge
I think im just gonna forget about it for now as its too much for me 😭 but ill try later tho
are you trying to run it as a server? if so you need to allow it through your router to work as a server
Wdym as a server
I just want to be able to access it thru my phone locally
my args --listen --xformers --api
you still might need to play with your switch to allow devices on your network access each other.
It works on a1111 but i recently switched to forge and it isnt working
oh that might be firewall. open up your firewall and allow inbound rule for local network 7860 and 7861
by default even on your network it wont let any old thing just connect
Like this?

try it and see, you might need a UDP rule too
--listen uses my local ip right, like 192.168.1.1
local yes
Oh my god i was using the wrong ip this whole time im so stupuid
😭
i was using the "default gateway" instead of the ipv4 address from ipconfig /all
🙂 well now you have learned how to do this for other things too.
it works now thankfully i was so mad i thought forge didnt have it
yeah xd
most programs do this behind the scenes for new devices, but its handy to know a bit yourself
if nothing else you're learning networking
dont forget that those rules only apply to your machine youre on, so for anything else you need to change on your router
but for local network it should all work nice
so does it all work?
if you've set up everything correctly you should now have a local AI which when asked, will generate and send your phone an SD image
if it all works, then, for a flex, tick this. first time you use it it will install BLIP and clip interrogate an image. that means that you can take a photo on your phone and ask your local AI what it thinks of the photo

i'd just like to point out that this stuff, although janky, was introduced in open source before the big guns did demos of it.

im not sure if textgeneration webui is as mobile friendly for uploads, but still
Anyone have a better picture that shows the differences between all sampling methods?
is 0.1 avr_loss good or bad?

what is pony diffusion?
i download a lora of a character which is pony version but what do i do with that
Put it in your Lora folder under models

its an SDXL version of anime only trained models trained on only things from image boards. it has its own prompting syntax. its very good for drawings of that kind but veers towards nsfw stuff.
thats interessting, didnt know that
but i cant use it because i can't find
turn on "Always show all networks on the Lora page (otherwise, those detected as for incompatible version of Stable Diffusion will be hidden)" in settings
I had to do the same, they still work mostly
i dont know if using loras from those models work very well, in general they mangle photorealism
where do i find this option?
Settings lol
i found a silly setting the other day. if you put a soundfile into your webui root called notification.mp3 it will make that little noise when its finished
yup there is also support for browser notifications
re our convo last night you were right about running both at the same time. BUT if you keep doing it, you CAN run a small llm and stable together with similar latency to just asking the SD client to do a thing. just as long as you never move models. 🙂
useless practically, but locally a fun toy
Hi, I tried to create a new folder but
"You go into the folder you created in this case Ai, then click in the File Explorer bar (not searchbar) and type cmd then press enter."

Type only cmd
Remove the C:\ai before it
alternatively, you can open the windows menu and type cmd
Thanks, the cmd part worked BUT...😥
Creating venv in directory C:\IA\stable-diffusion-webui\venv using python "C:\Users\JosÚ Antonio\AppData\Local\Programs\Python\Python310\python.exe"
Unable to create venv in directory "C:\IA\stable-diffusion-webui\venv"
exit code: 3
stderr:
El sistema no puede encontrar la ruta especificada.
Launch unsuccessful. Exiting.
Presione una tecla para continuar . . .
which step are you in?
your username has still the unsupported character
i think it should not be a problem
Yes, I told you, I cant change it!
is it bound to an microsoft account maybe?
Win10 or Win11?
After editing, save and launch the webui-user.bat inside the stable-diffusion-webui folder.
I don't know, maybe.
I was able to change the user name but not the folder name.
win 10 pro
try to install the python to a different location and make the webui-user.bat use it
you will specify the full python path here
i dont remember how the python path is on windows, but i guess it will be something like this
On C?
I moved the python folder to C\ and specified the full python path, same result...
Couldn't launch python
exit code: 9009
stderr:
"C:\Python\Python310" no se reconoce como un comando interno o externo,
programa o archivo por lotes ejecutable.
Launch unsuccessful. Exiting.
Presione una tecla para continuar . . .
add the \python.exe part
i was training my lora and i was wondering why it wasnt working. The image folder was named 30_wb17myself person and if i put wb17myself in the prompt, it would show nothing. Only now I realised that if I put one of the captions I used, the output image would work correctly. How can I make my lora not to need a whole prompt to be triggered, but only a word?
Did it! Is working!!!!!!😊
nevermind
ight you probably heard this seven billion times but I'm trying to make a short film which will use AI video for artistic statement purposes, I am struggling to get SD running
because it either keeps giving me errors or keeps downloading things
so who's up to help me step by step
help is for specific errors, whats your first one?
I will try again and show you my errors
hello, i am following along to this video to try a train SD on a face. in the video @6:52, the guy is in the "Train Tab" and clicked on "Preprocess Images". I dont have that under my "Train" tab. I am on version v1.8.0, can someone help me. Also if anyone has a better face model trainer method, I'd love to check it out. Trying to make a hyper realistic woman

Any ETA on the api issues? https://stabilityai.instatus.com/
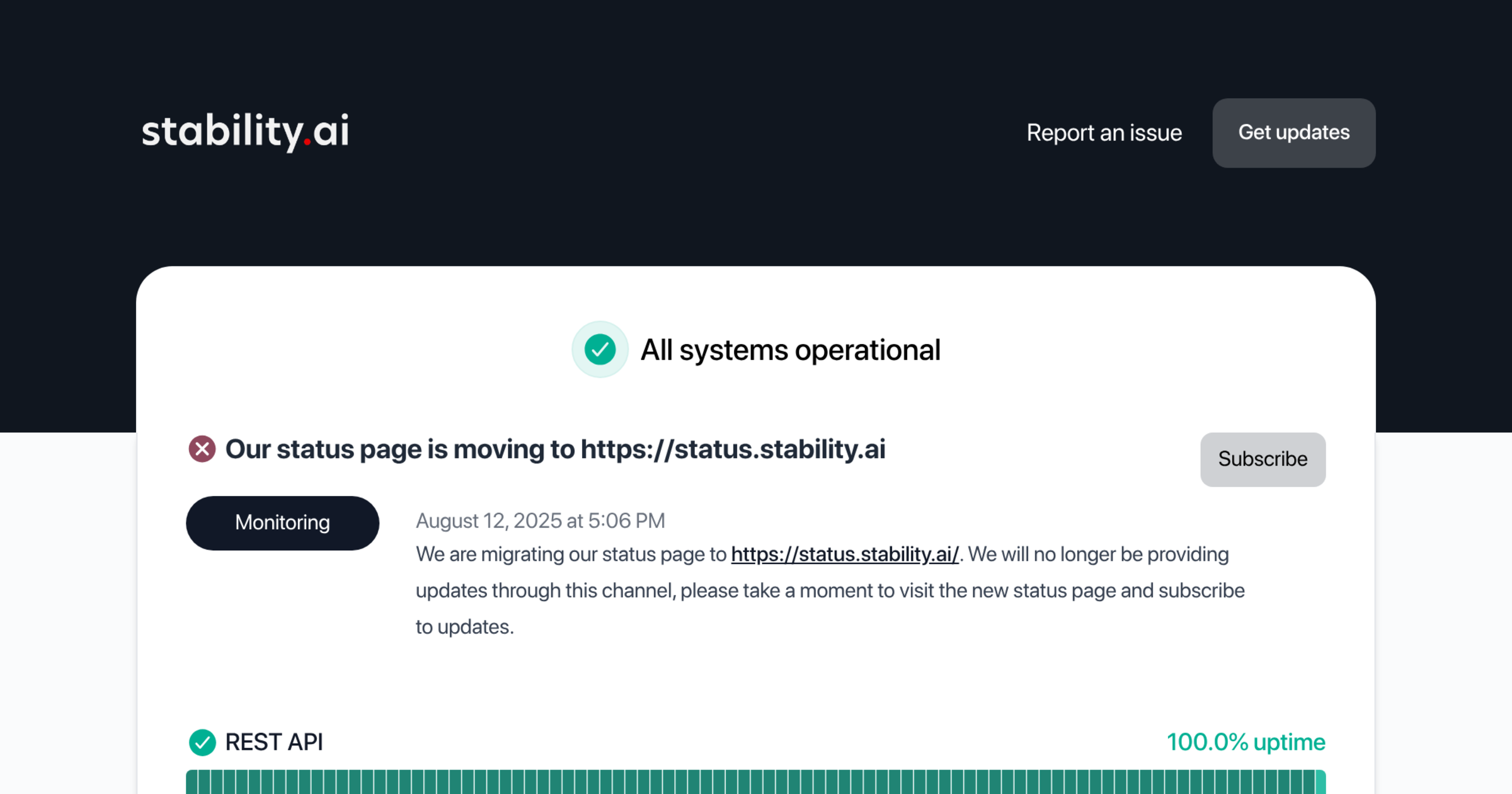
Stability AI Platform Status
Get this everytime I do highres
RuntimeError: don't know how to restore data location of torch.storage.UntypedStorage (tagged with privateuseone:0)
Hey guys
Is possible to Fine-tuning the SDXL model to handle image captions exceeding the standard 75-token limit?
What settings do you use? (Resolution, steps, etc)
What's your GPU?
GPU: RX6700xt
Resolution: 512 x 744
Steps: 25
and then with hires I was upscaling it by 1.7 with 20 steps
Ok so I ran it again with the upscaler being 4x-UltraSharp this time and it worked
Previous time I was using one of the ergans
Both should work. But make sure your using 10 hires steps and not 0
Also if you want better performance and less vram limit you should switch to the zluda version of directml
I tried to but I think I messed up because it didnt work
one example being the SD-Zluda folder I had made somehow got deleted during the process
I followed the guide in the pinned msg btw
I can give it another try
oh word
maybeit was the arguments?
I had mine setup like set COMMANDLINE_ARGS= --use-directml --zluda or something --medvram --no-half-vae --opt-sub-quad-attention --opt-split-attention-v1 --disable-nan-check --autolaunch
no nvm
Ill try the guide again
That won't work
Yea please follow the guide step by step
Alright btw what gpu do u have
Im running a 7900XTX
oh nice
Ah, yeah i definitely did something wrong then
Probably. I'm AFK now, (20mins) but feel free to @ me in chat, if your stuck
Sure thing, thank you
Hey so Im now at step 5 of the guide and Ive done the instructions in the red area but im not sure if I still have to install SD Next

No you dont need SD.next
very nice
So I got it set up but when i try to generate an immage I get this in the cmd
RuntimeError: invalid argument to memory_allocated
Can you show the whole error in cmd?
yeah one sec
Traceback (most recent call last):
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\blocks.py", line 1431, in process_api
result = await self.call_function(
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\blocks.py", line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\anyio_backends_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(args, **kwargs)
File "C:\SD-Zluda\stable-diffusion-webui-directml\modules\call_queue.py", line 95, in f
mem_stats = {k: -(v//-(10241024)) for k, v in shared.mem_mon.stop().items()}
File "C:\SD-Zluda\stable-diffusion-webui-directml\modules\memmon.py", line 99, in stop
return self.read()
File "C:\SD-Zluda\stable-diffusion-webui-directml\modules\memmon.py", line 81, in read
torch_stats = torch.cuda.memory_stats(self.device)
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\torch\cuda\memory.py", line 258, in memory_stats
stats = memory_stats_as_nested_dict(device=device)
File "C:\SD-Zluda\stable-diffusion-webui-directml\venv\lib\site-packages\torch\cuda\memory.py", line 270, in memory_stats_as_nested_dict
return torch._C._cuda_memoryStats(device)
RuntimeError: invalid argument to memory_allocated
Thats Strange. Do you have any other Programm running?
Maybe restart the PC and try again
No no other program I dont think, will restart pc
So I restarted my pc and after running webui.bat again I notice there are errors even before I generate an img
img
Want me to screenshot them?
Wait
Don't run webui.bat
Always run webui-user.bat
Yeah that’s the one I initially ran but I tried webui bat too





can you show me your paths in system varaibles?

looks ok
Yeah I’m not sure what’s going on with it
did you copied the dll files over to the torch/lib ?
Yeah
and you have doen this correctly?

it means this path:

rename the library folder and paste the other one in there
so that you have two different folders in the rocblas folder and the new one needs to be library
Might’ve done that wrong
after you tried it again, restart the PC
before launching the webui-user.bat
I did do it the correct way this time and restarted my pc but now that I think about it, I forgot to run the AMD HIP SDK 5.7 file which might be the issue
which file? the installer?
Yeah, but I just ran it and restarted my pc and it still doesn't work so i dont think that was it
you may need to delete the venv folder again and then relaunch the webui-user.bat
also make sure you replaced the librarys folder after you installed the hip sdk
Oh alright
I cant use ReActor in Krita AI right?
hi thinking about buying stable diffusion but is it just too sensitive? can it not handle jokes? gave it this prompt "digital art style image of many bankers, dressed in suits and all based on a greedy pig character and have dollars in their pockets, are running scared of one giant bitcoin in the background. This takes place on wall street." and it gave this images. tried countless times and they are always smiling rather than be scared or worried, etc. whats up with that?

i mean i love the art style it gave me but its useless cos its the opposite of what i asked emotions wise
tired a million times and have now run out of my free credits. not once it gave me the emotion i was after.
Hey guys, can somone help me with the "workflow" settings for comfyui ? I managed to install SD XL Turbo, but i try all this samplers, cfg number, steps and things, but i dont get good pictures.
i want to get pictures like in this free sdxl turbo online page: https://stablediffusion.fr/xl-turbo

Stable Diffusion AI online
Free Stable Diffusion turbo demonstration, an artificial intelligence generating images from a single prompt.
anyone got any tips for using anything v3 on stable diffusion? trying to recreate something like this

what could be a possible reason for my backend showing error, when using a refiner. I can't use refiner to generate a image
yep it works now
Thanks for all the help man
Perfekt np
anyone know some good models that can produce an image of this quality???
Which webui?
divinieanimemix
MacOS 14.4 definitely fu...d Euler A, for some unknown reason 🤯 fortunately new samplers Euler A SGMUniform and Euler A Turbo in forge work without any problem



where do i put my own upscaling models in auto1111 sd?
Can I bug you for a sec? I'm getting the following during first image gen:
RuntimeError: invalid argument to memory_allocated
post more details, copy text from cmd or make a screenshot
---
Traceback (most recent call last):
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\blocks.py", line 1431, in process_api
result = await self.call_function(
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\blocks.py", line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\anyio\_backends\_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\anyio\_backends\_asyncio.py", line 807, in run
result = context.run(func, *args)
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(*args, **kwargs)
File "G:\Stable Diffusion\stable-diffusion-webui-directml\modules\call_queue.py", line 95, in f
mem_stats = {k: -(v//-(1024*1024)) for k, v in shared.mem_mon.stop().items()}
File "G:\Stable Diffusion\stable-diffusion-webui-directml\modules\memmon.py", line 99, in stop
return self.read()
File "G:\Stable Diffusion\stable-diffusion-webui-directml\modules\memmon.py", line 81, in read
torch_stats = torch.cuda.memory_stats(self.device)
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\torch\cuda\memory.py", line 258, in memory_stats
stats = memory_stats_as_nested_dict(device=device)
File "G:\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\torch\cuda\memory.py", line 270, in memory_stats_as_nested_dict
return torch._C._cuda_memoryStats(device)
RuntimeError: invalid argument to memory_allocated
whats your gpu?
Got the RX 6800 XT
Oh I'm seeing some more errors above the one I posted:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
did you do every step correctly?
show me your paths in sys variables
oh
Let me try adding to both
First error
Will try now. Should I remove venv or anything or try starting the ui?

yes, delete the venv folder and relauch thr webui-user.bat
CPU is Ryzen 7 5700G
okay, what settings did you tried?
Hello, what are the best settings to train an stable diffusion checkpoint for anime? It keeps getting messed up faces
I just tried running this, I'm currently tinkering and trying to get it, I'm trying to generate videos based on image but make them look clearly AI generated for a personal project, I was trying to merge 2 images

just installed FYI
I may need models
you need to use models that are 2gb
and not larger
then dont use a too high resolution
did it worked?
I'm not getting an error now- however image generation doesn't work and not getting an error or anything. Sec.
just stays in queue. Not sure if it's doing anything or not

the first image takes 15-40 minutes
Shouldn't there be a progress bar of sorts?
I'll let it sit like this for a while
Alright thanks!
yeah, looks good

cmd will show nothing for a long time